Un importante trabajo científico de 2012 transformó el campo del software de reconocimiento de imágenes.

Hoy puedo, por ejemplo, abrir Google Photos, escribir "playa" y ver un montón de mis fotos de varias playas que visité en la última década. Y nunca firmé mis fotos: Google reconoce playas en ellas en función de su contenido. Esta característica aparentemente aburrida se basa en una tecnología llamada "red neuronal convolucional profunda", que permite a los programas comprender imágenes utilizando un método complejo, inaccesible a las tecnologías de generaciones anteriores.
En los últimos años, los investigadores han descubierto que la precisión del software mejora a medida que construyen redes neuronales (NS) más profundas y las capacitan en conjuntos de datos cada vez más grandes. Esto creó una necesidad insaciable de potencia informática y enriqueció a los fabricantes de GPU como Nvidia y AMD. Hace unos años, Google desarrolló sus propios chips especiales para la Asamblea Nacional, mientras que otras compañías están tratando de mantenerse al día.
En Tesla, por ejemplo, Andrei Karpati, un experto en aprendizaje profundo, ha sido nombrado jefe del proyecto Piloto automático. Ahora el fabricante de automóviles está desarrollando su propio chip para acelerar el trabajo del NS en futuras versiones del piloto automático. O tome Apple: los chips A11 y A12, centrales para los últimos iPhones, tienen un "
procesador neuronal " Neural Engine que acelera el NS y permite que las aplicaciones de reconocimiento de imagen y voz funcionen mejor.
Los expertos que entrevisté para este artículo siguen el comienzo del auge del aprendizaje profundo en un trabajo específico: AlexNet, que lleva el nombre del autor principal, Alex Krizhevsky. "Creo que 2012 fue un año histórico cuando salió el trabajo de AlexNet", dijo Sean Gerrish, experto en defensa y autor del libro "
Cómo piensan los autos inteligentes ".
Hasta 2012, las redes neuronales profundas (GNS) eran un poco atrasados en el mundo de la región de Moscú. Pero luego Krizhevsky y sus colegas de la Universidad de Toronto participaron en la prestigiosa competencia para el reconocimiento de imágenes, y su programa superó dramáticamente en precisión todo lo que se desarrolló antes. Casi al instante, STS se convirtió en la tecnología líder en reconocimiento de imágenes. Otros investigadores que utilizan esta tecnología pronto demostraron nuevas mejoras en la precisión del reconocimiento.
En este artículo, profundizaremos en el aprendizaje profundo. Explicaré qué es NS, cómo están capacitados y por qué requieren tales recursos informáticos. Y luego explicaré por qué cierto tipo de NS (redes de convolución profunda) entienden las imágenes tan bien. No te preocupes, habrá muchas fotos.
Un ejemplo simple con una neurona
El concepto de una "red neuronal" puede parecerle vago, así que comencemos con un ejemplo simple. Suponga que desea que la Asamblea Nacional decida si conducir un automóvil en función de las señales de tráfico verdes, amarillas y rojas. NS puede resolver este problema con una sola neurona.

Una neurona recibe datos de entrada (1 - encendido, 0 - apagado), se multiplica por el peso apropiado y suma todos los valores de los pesos. Luego, la neurona agrega un desplazamiento que define el valor umbral para la "activación" de la neurona. En este caso, si la salida es positiva, creemos que la neurona se ha activado, y viceversa. La neurona es equivalente a la desigualdad "verde - rojo - 0.5> 0". Si resulta ser cierto, es decir, el verde está encendido y el rojo no está encendido, entonces el automóvil debe irse.
En NS real, las neuronas artificiales dan otro paso. Al sumar una entrada ponderada y agregar un desplazamiento, la neurona usa una función de activación no lineal. A menudo se usa una función sigmoidea, en forma de S, que siempre produce un valor de 0 a 1.
El uso de la función de activación no cambiará el resultado de nuestro modelo simple de semáforo (solo necesitamos usar un valor umbral de 0.5, no 0). Pero la no linealidad de las funciones de activación es necesaria para que las NS modelen funciones más complejas. Sin la función de activación, cada NS arbitrariamente complejo se reduce a una combinación lineal de datos de entrada. Una función lineal no puede simular fenómenos complejos en el mundo real. La función de activación no lineal permite al NS aproximar
cualquier función matemática .
Ejemplo de red
Por supuesto, hay muchas formas de aproximar una función. NS destaca por el hecho de que sabemos cómo "entrenarlos" utilizando un poco de álgebra, un montón de datos y un mar de potencia informática. En lugar de indicarle al programador que desarrolle el NS para una tarea específica, podemos crear un software que comience con un NS bastante general, estudie un montón de ejemplos marcados y luego cambie el NS para que proporcione la etiqueta correcta para tantos ejemplos como sea posible. La expectativa es que el NS final resumirá los datos y producirá las etiquetas correctas para ejemplos que no estaban previamente en la base de datos.
El proceso que condujo a este objetivo comenzó mucho antes que AlexNet. En 1986, un trío de investigadores publicó un
trabajo histórico sobre la propagación hacia atrás, una tecnología que ayudó a hacer realidad el aprendizaje matemático de las NS complejas.
Para imaginar cómo funciona la propagación hacia atrás, veamos un NS simple descrito por Michael Nielsen en su excelente
libro de texto GO en línea . El propósito de la red es procesar la imagen de un número escrito a mano en una resolución de 28x28 píxeles y determinar correctamente si se escribe el número 0, 1, 2, etc.
Cada imagen es 28 * 28 = 784 cantidades de entrada, cada una de las cuales es un número real de 0 a 1, que indica cuánto es el píxel claro u oscuro. Nielsen creó el NA de este tipo:
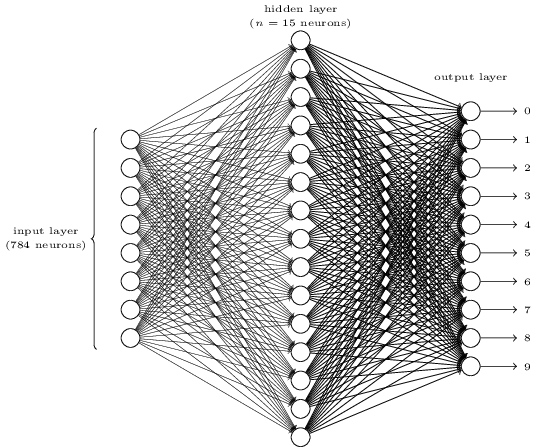
Cada círculo en el centro y en la columna derecha es una neurona similar a la que examinamos en la sección anterior. Cada neurona toma un promedio ponderado de la entrada, agrega un desplazamiento y aplica una función de activación. Los círculos de la izquierda no son neuronas; representan los datos de entrada de la red. Y aunque la imagen muestra solo 8 círculos de entrada, de hecho hay 784 de ellos, uno para cada píxel.
Cada una de las 10 neuronas de la derecha debe "disparar" su propio número: la primera debe activarse cuando se ingresa un 0 escrito a mano (y solo en este caso), la segunda cuando la red ve un 1 escrito a mano (y solo él), y así sucesivamente.
Cada neurona percibe la entrada de cada neurona de la capa anterior. Entonces, cada una de las 15 neuronas en el medio recibe 784 valores de entrada. Cada una de estas 15 neuronas tiene un parámetro de peso para cada uno de los 784 valores de entrada. Esto significa que solo esta capa tiene 15 * 784 = 11 760 parámetros de peso. De manera similar, la capa de salida contiene 10 neuronas, cada una de las cuales recibe información de las 15 neuronas de la capa intermedia, lo que agrega otros 15 * 10 = 150 parámetros de peso. Además, la red tiene 25 variables de desplazamiento, una para cada una de las 25 neuronas.
Entrenamiento de redes neuronales
El objetivo del entrenamiento es ajustar estos 11,935 parámetros para maximizar la probabilidad de que la neurona de salida deseada, y solo ella, se active cuando las redes dan una imagen de un dígito escrito a mano. Podemos hacer esto con el conocido conjunto de imágenes MNIST, donde hay 60,000 imágenes marcadas con una resolución de 28x28 píxeles.
 160 de 60,000 imágenes del conjunto MNIST
160 de 60,000 imágenes del conjunto MNISTNielsen demuestra cómo entrenar una red usando 74 líneas de código python regular, sin ninguna biblioteca para MO. El aprendizaje comienza eligiendo valores aleatorios para cada uno de estos 11,935 parámetros, pesos y compensaciones. Luego, el programa pasa por ejemplos de imágenes, pasando por dos etapas con cada una de ellas:
- El paso de propagación directa calcula la salida de la red en función de la imagen de entrada y los parámetros actuales.
- El paso de retropropagación calcula la desviación del resultado de los datos de salida correctos y cambia los parámetros de la red para mejorar ligeramente su eficiencia en esta imagen.
Un ejemplo Digamos que la red recibió la siguiente imagen:
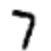
Si está bien calibrado, entonces el pin "7" debería ir a 1, y las otras nueve conclusiones deberían ir a 0. Pero, digamos que en cambio, la red en la salida "0" da un valor de 0.8. ¡Esto es demasiado! El algoritmo de entrenamiento cambia los pesos de entrada de la neurona responsable de "0" para que se acerque a 0 la próxima vez que se procese esta imagen.
Para esto, el algoritmo de retropropagación calcula un gradiente de error para cada peso de entrada. Esta es una medida de cómo cambiará el error de salida para un cambio dado en el peso de entrada. Luego, el algoritmo usa el gradiente para decidir cuánto cambiar cada peso de entrada: cuanto mayor sea el gradiente, más fuerte será el cambio.
En otras palabras, el proceso de entrenamiento "entrena" a las neuronas de la capa de salida para prestar menos atención a aquellas entradas (neuronas en la capa intermedia) que las empujan a la respuesta incorrecta, y más a las entradas que empujan en la dirección correcta.
El algoritmo repite este paso para todas las demás neuronas de salida. Reduce los pesos de entrada para las neuronas "1", "2", "3", "4", "5", "6", "8" y "9" (pero no "7") para reducir el valor de estos neuronas de salida. Cuanto mayor sea el valor de salida, mayor será el gradiente del error de salida con respecto al peso de entrada, y más disminuirá su peso.
Y viceversa, el algoritmo aumenta el peso de los datos de entrada para la salida "7", lo que hace que la neurona produzca un valor más alto la próxima vez que reciba esta imagen. Una vez más, las entradas con valores mayores aumentarán más los pesos, lo que hará que la neurona de salida "7" preste más atención a estas entradas la próxima vez.
Luego, el algoritmo debe realizar los mismos cálculos para la capa intermedia: cambie cada peso de entrada en una dirección que reducirá los errores de red, nuevamente, acercando la salida "7" a 1, y el resto a 0. Pero cada neurona media tiene una conexión con los 10 días libres, lo que complica las cosas en dos aspectos.
En primer lugar, el gradiente de error para cada neurona promedio depende no solo del valor de entrada, sino también de los gradientes de error en la siguiente capa. El algoritmo se denomina retropropagación porque los gradientes de error de las capas posteriores de la red se propagan en la dirección opuesta y se utilizan para calcular los gradientes en las capas anteriores.
Además, cada neurona media es una entrada para los diez días libres. Por lo tanto, el algoritmo de entrenamiento tiene que calcular el gradiente de error, que refleja cómo un cambio en un cierto peso de entrada afecta el error promedio para todas las salidas.
La retropropagación es un algoritmo para subir una colina: cada pasada acerca los valores de salida a los valores correctos para una imagen determinada, pero solo un poco. Cuantos más ejemplos mire el algoritmo, más alto subirá la colina hacia el conjunto óptimo de parámetros que clasifican correctamente la cantidad máxima de ejemplos de entrenamiento. Para lograr una alta precisión, se requieren miles de ejemplos, y el algoritmo puede necesitar recorrer cada imagen en este conjunto docenas de veces antes de que su efectividad deje de crecer.
Nielsen muestra cómo implementar estas 74 líneas en python. Sorprendentemente, una red capacitada con un programa tan simple puede reconocer más del 95% de los números escritos a mano de la base de datos MNIST. Con mejoras adicionales, una red simple de dos capas puede reconocer más del 98% de los números.
Avance AlexNet
Se podría pensar que se suponía que el desarrollo del tema de la propagación hacia atrás tendría lugar en la década de 1980 y daría lugar a un rápido progreso en el MO basado en la Asamblea Nacional, pero esto no sucedió. En la década de 1990 y principios de 2000, algunas personas trabajaron en esta tecnología, pero el interés en la Asamblea Nacional no ganó impulso hasta principios de 2010.
Esto se remonta a
la competencia ImageNet , una
competencia anual de MO organizada por Stanford Fay Fay Lee, un especialista en TI. Cada año, los rivales reciben el mismo conjunto de más de un millón de imágenes para entrenamiento, cada una de las cuales se etiqueta manualmente en categorías de más de 1000, desde "camión de bomberos" y "hongo" hasta "guepardo". El software de los participantes se juzga por la posibilidad de clasificar otras imágenes que no estaban en el conjunto. Un programa puede hacer algunas conjeturas, y su trabajo se considera exitoso si al menos una de las primeras cinco conjeturas coincide con la marca de una persona.
La competencia comenzó en 2010, y los NS profundos no jugaron un papel importante en ella en los primeros dos años. Los mejores equipos usaron diferentes técnicas de MO y lograron resultados bastante promedio. En 2010, el equipo ganó con un porcentaje de errores igual a 28. En 2011, con un error del 25%.
Y luego vino el 2012. Un equipo de la Universidad de Toronto hizo una
oferta , más tarde apodada AlexNet en honor del autor principal, Alex Krizhevsky, y dejó a los rivales muy por detrás. Usando NS profundo, el equipo logró una tasa de error del 16%. Para el competidor más cercano, esta cifra era 26.
El NS descrito en el artículo para el reconocimiento de escritura a mano tiene dos capas, 25 neuronas y casi 12,000 parámetros. AlexNet era mucho más grande y complejo: ocho capas entrenadas, 650,000 neuronas y 60 millones de parámetros.
Se requiere una potencia de procesamiento enorme para entrenar NS de este tamaño, y AlexNet fue diseñado para aprovechar la paralelización masiva disponible con las GPU modernas. Los investigadores descubrieron cómo dividir el trabajo de capacitación de la red en dos GPU, que duplicaron el poder. Y aún así, a pesar de la estricta optimización, la capacitación de la red tomó de 5 a 6 días en el hardware que estaba disponible en 2012 (en un par de Nvidia GTX 580 con 3 Gb de memoria).
Es útil estudiar ejemplos de los resultados de AlexNet para comprender cuán serio fue este avance. Aquí hay una imagen de un artículo científico que muestra ejemplos de imágenes y las primeras cinco conjeturas de la red según su clasificación:

AlexNet pudo reconocer la marca en la primera imagen, aunque solo hay una pequeña forma en la esquina. El software no solo identificó correctamente al leopardo, sino que también ofreció otras opciones cercanas: un jaguar, un guepardo, un leopardo de las nieves y un Mau egipcio. AlexNet etiquetó la foto de carpe como "agárico". Simplemente "hongo" fue la segunda versión de la red.
"Errores" AlexNet también son impresionantes. Marcó la foto con un dálmata parado detrás de un montón de cerezas como "dálmata", aunque la etiqueta oficial era "cereza". AlexNet reconoció que había algún tipo de baya en la foto, entre las cinco primeras opciones estaban "uvas" y "saúco", simplemente no reconoció la cereza. En una foto de un lémur de Madagascar sentado en un árbol, AlexNet dio una lista de pequeños mamíferos que viven en los árboles. Creo que muchas personas (incluyéndome a mí) habrían puesto la firma incorrecta aquí.
La calidad del trabajo fue impresionante y demostró que el software es capaz de reconocer objetos comunes en una amplia gama de sus orientaciones y entornos. GNS se convirtió rápidamente en la técnica más popular para el reconocimiento de imágenes, y desde entonces el mundo de MO no la ha abandonado.
"Tras el éxito en 2012 del método basado en GO, la mayoría de los participantes en la competencia de 2013 cambiaron a redes neuronales convolucionales profundas", escribieron los patrocinadores de ImageNet. En los años siguientes, esta tendencia continuó, y posteriormente los ganadores trabajaron sobre la base de tecnologías básicas, aplicadas por primera vez por el equipo de AlexNet. Para 2017, los rivales, utilizando NS más profundos, redujeron seriamente la tasa de error a menos de tres. Dada la complejidad de la tarea, las computadoras han aprendido hasta cierto punto a resolverla mejor que muchas personas.
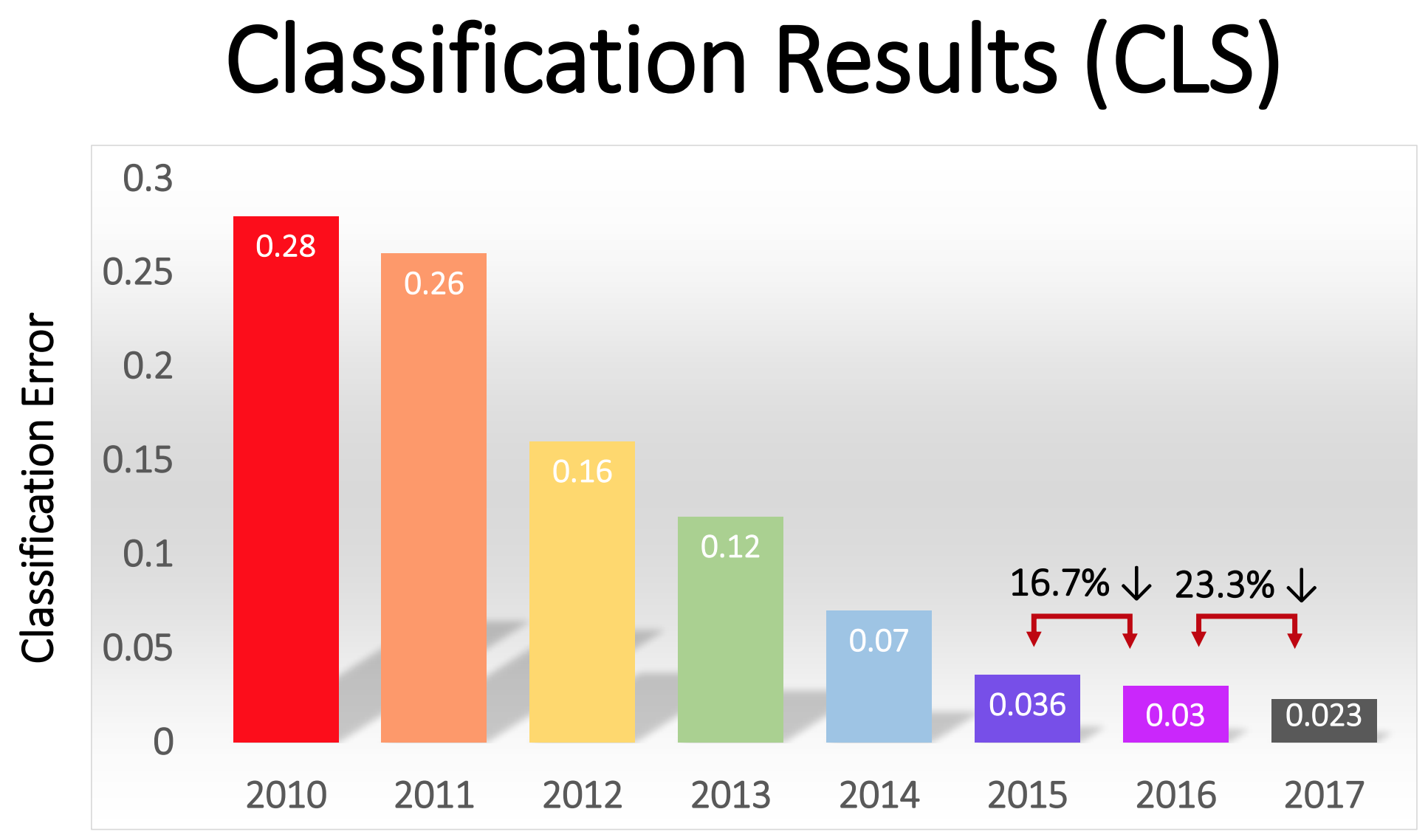 El porcentaje de errores en la clasificación de imágenes en diferentes años.
El porcentaje de errores en la clasificación de imágenes en diferentes años.Redes de convolución: un concepto
Técnicamente, AlexNet era un NS convolucional. En esta sección, explicaré lo que hace la red neuronal convolucional (SNA) y por qué esta tecnología se ha vuelto críticamente importante para los algoritmos modernos de reconocimiento de patrones.
La red simple anteriormente discutida para el reconocimiento de escritura a mano estaba completamente conectada: cada neurona de la primera capa era una entrada para cada neurona de la segunda capa. Dicha estructura funciona bastante bien en tareas simples con reconocimiento de números en imágenes de 28x28 píxeles. Pero no escala bien.
En la base de datos de dígitos manuscritos MNIST, todos los caracteres están centrados. Esto simplifica enormemente el aprendizaje, porque, por ejemplo, los siete siempre tendrán varios píxeles oscuros en la parte superior y derecha, y la esquina inferior izquierda siempre es blanca. Zero casi siempre tendrá una mancha blanca en los píxeles medios y oscuros en los bordes. Una red simple y totalmente conectada puede reconocer tales patrones con bastante facilidad.
Pero supongamos que desea crear un NS capaz de reconocer números que puedan ubicarse en cualquier lugar de una imagen más grande. Una red totalmente conectada no funcionará tan bien con esta tarea, ya que no tiene una forma efectiva de reconocer características similares en formularios ubicados en diferentes partes de la imagen. Si en su conjunto de datos de entrenamiento, la mayoría de los sietes se encuentran en la esquina superior izquierda, entonces su red será mejor para reconocer los sietes en la esquina superior izquierda que en cualquier otra parte de la imagen.
Teóricamente, este problema puede resolverse asegurando que su conjunto tenga muchos ejemplos de cada dígito en cada una de las posiciones posibles. Pero en la práctica esto será un gran desperdicio de recursos. Con el aumento del tamaño de la imagen y la profundidad de la red, la cantidad de enlaces, y la cantidad de parámetros de peso, aumentará explosivamente. Necesitará muchas más imágenes de entrenamiento (y potencia informática) para lograr una precisión adecuada.
Cuando una red neuronal aprende a reconocer una forma ubicada en un lugar de una imagen, debe poder aplicar este conocimiento para reconocer la misma forma en otras partes de la imagen. SNA proporciona una solución elegante a este problema."Es como si tomaras una plantilla y la adjuntases a todos los lugares de la imagen", dijo el investigador de IA Jai Teng. - ¿Tiene una plantilla con una imagen de un perro y primero la coloca en la esquina superior derecha de la imagen para ver si hay un perro allí? Si no, estás cambiando un poco la plantilla. Y así para toda la imagen. No importa dónde esté la foto del perro. La plantilla coincidirá con ella. No necesita cada parte de la red para aprender su propia clasificación de perros ".Imagine que tomamos una imagen grande y la dividimos en cuadrados de 28x28 píxeles. Luego podemos alimentar cada cuadrado de una red totalmente conectada que reconoce la escritura a mano que estudiamos antes. Si la salida "7" se activa en al menos uno de los cuadrados, esto será un signo de que hay un siete en toda la imagen. Esto es exactamente lo que hacen las redes convolucionales.Cómo funcionaban las redes convolucionales en AlexNet
En las redes convolucionales, tales "plantillas" se conocen como detectores de características, y el área que estudian se conoce como el campo receptivo. Los detectores de características reales funcionan con campos mucho más pequeños que un cuadrado con un lado de 28 píxeles. En AlexNet, los detectores de características en la primera capa convolucional trabajaron con un campo receptivo de 11x11 píxeles de tamaño. En las capas posteriores, los campos receptivos tenían 3-5 unidades de ancho.Durante el recorrido, el detector de signos de la imagen de entrada produce un mapa de signos: una red bidimensional, en la que se observa la intensidad con la que se activó el detector en diferentes partes de la imagen. Las capas convolucionales generalmente tienen más de un detector, y cada una de ellas escanea la imagen en busca de diferentes patrones. AlexNet tenía 96 detectores de funciones en la primera capa, entregando 96 tarjetas de funciones. Para comprender mejor esto, considere una representación visual de los patrones estudiados por cada uno de los 96 detectores de primera capa AlexNet después de entrenar la red. Hay detectores que buscan líneas horizontales o verticales, transiciones de claro a oscuro, patrones de ajedrez y muchas otras formas.Una imagen en color generalmente se representa como un mapa de píxeles con tres números para cada píxel: el valor de rojo, verde y azul. La primera capa de AlexNet toma esta vista y la convierte en una vista con 96 números. Cada "píxel" en esta imagen tiene 96 valores, uno para cada detector de características.En este ejemplo, el primero de los 96 valores indica si algún punto de la imagen coincide con este patrón:
Para comprender mejor esto, considere una representación visual de los patrones estudiados por cada uno de los 96 detectores de primera capa AlexNet después de entrenar la red. Hay detectores que buscan líneas horizontales o verticales, transiciones de claro a oscuro, patrones de ajedrez y muchas otras formas.Una imagen en color generalmente se representa como un mapa de píxeles con tres números para cada píxel: el valor de rojo, verde y azul. La primera capa de AlexNet toma esta vista y la convierte en una vista con 96 números. Cada "píxel" en esta imagen tiene 96 valores, uno para cada detector de características.En este ejemplo, el primero de los 96 valores indica si algún punto de la imagen coincide con este patrón: El segundo valor indica si algún punto de imagen coincide con dicho patrón:
El segundo valor indica si algún punto de imagen coincide con dicho patrón: el tercer valor indica si algún punto de imagen coincide con dicho patrón:
el tercer valor indica si algún punto de imagen coincide con dicho patrón: y así sucesivamente para 93 detectores de características en la primera capa AlexNet. La primera capa produce una nueva representación de la imagen, donde cada píxel es un vector en 96 dimensiones (explicaré más adelante que esta representación se reduce 4 veces).Esta es la primera capa de AlexNet. Luego hay cuatro capas convolucionales más, cada una de las cuales toma la salida de la anterior como entrada.Como vimos, la primera capa revela patrones básicos, como líneas horizontales y verticales, transiciones de claro a oscuro y curvas. El segundo nivel los usa como un bloque de construcción para reconocer formas ligeramente más complejas. Por ejemplo, la segunda capa podría tener un detector de características que encuentre círculos utilizando una combinación de las salidas de los detectores de características de la primera capa que encuentren curvas. La tercera capa encuentra formas aún más complejas combinando características de la segunda capa. El cuarto y quinto encuentran patrones aún más complejos.Los investigadores Matthew Zeiler y Rob Fergus publicaron un excelente trabajo en 2014 , que proporciona formas muy útiles para visualizar patrones reconocidos por una red neuronal de cinco capas similar a ImageNet.En la siguiente presentación de diapositivas tomada de su trabajo, cada imagen, excepto la primera, tiene dos mitades. A la derecha, verá ejemplos de miniaturas que han activado fuertemente un detector de características en particular. Se recogen en nueve, y cada grupo corresponde a su propio detector. A la izquierda hay un mapa que muestra exactamente qué píxeles en esta miniatura son los más responsables de la coincidencia. Esto es especialmente evidente en la quinta capa, ya que hay detectores de características que reaccionan fuertemente a los perros, logotipos, ruedas, etc.
y así sucesivamente para 93 detectores de características en la primera capa AlexNet. La primera capa produce una nueva representación de la imagen, donde cada píxel es un vector en 96 dimensiones (explicaré más adelante que esta representación se reduce 4 veces).Esta es la primera capa de AlexNet. Luego hay cuatro capas convolucionales más, cada una de las cuales toma la salida de la anterior como entrada.Como vimos, la primera capa revela patrones básicos, como líneas horizontales y verticales, transiciones de claro a oscuro y curvas. El segundo nivel los usa como un bloque de construcción para reconocer formas ligeramente más complejas. Por ejemplo, la segunda capa podría tener un detector de características que encuentre círculos utilizando una combinación de las salidas de los detectores de características de la primera capa que encuentren curvas. La tercera capa encuentra formas aún más complejas combinando características de la segunda capa. El cuarto y quinto encuentran patrones aún más complejos.Los investigadores Matthew Zeiler y Rob Fergus publicaron un excelente trabajo en 2014 , que proporciona formas muy útiles para visualizar patrones reconocidos por una red neuronal de cinco capas similar a ImageNet.En la siguiente presentación de diapositivas tomada de su trabajo, cada imagen, excepto la primera, tiene dos mitades. A la derecha, verá ejemplos de miniaturas que han activado fuertemente un detector de características en particular. Se recogen en nueve, y cada grupo corresponde a su propio detector. A la izquierda hay un mapa que muestra exactamente qué píxeles en esta miniatura son los más responsables de la coincidencia. Esto es especialmente evidente en la quinta capa, ya que hay detectores de características que reaccionan fuertemente a los perros, logotipos, ruedas, etc. La primera capa: patrones y formas simples. La
La primera capa: patrones y formas simples. La segunda capa: comienzan a aparecer pequeñas estructuras. Los detectores de características
segunda capa: comienzan a aparecer pequeñas estructuras. Los detectores de características en la tercera capa pueden reconocer formas más complejas, como ruedas de automóviles, panales e incluso siluetas de personas.
en la tercera capa pueden reconocer formas más complejas, como ruedas de automóviles, panales e incluso siluetas de personas. La cuarta capa es capaz de distinguir formas complejas, como las caras de los perros o las patas de los pájaros.
La cuarta capa es capaz de distinguir formas complejas, como las caras de los perros o las patas de los pájaros. La quinta capa puede reconocer formas muy complejas.Al observar las imágenes, puede ver cómo cada capa posterior puede reconocer patrones cada vez más complejos. La primera capa reconoce patrones simples que no son como nada. El segundo reconoce texturas y formas simples. En la tercera capa, se hacen visibles formas reconocibles como ruedas y esferas rojo anaranjado (tomates, mariquitas, algo más).En la primera capa, el lado del campo receptivo es 11, y en las posteriores, de tres a cinco. Pero recuerde, las capas posteriores reconocen mapas de características generados por capas anteriores, por lo que cada uno de sus "píxeles" denota varios píxeles de la imagen original. Por lo tanto, el campo receptivo de cada capa incluye una mayor parte de la primera imagen que las capas anteriores. Esto es parte de la razón por la cual las miniaturas en las capas posteriores se ven más complejas que en las anteriores.La quinta y última capa de la red es capaz de reconocer una impresionante variedad de elementos. Por ejemplo, mira esta imagen que seleccioné en la esquina superior derecha de la imagen correspondiente a la quinta capa:
La quinta capa puede reconocer formas muy complejas.Al observar las imágenes, puede ver cómo cada capa posterior puede reconocer patrones cada vez más complejos. La primera capa reconoce patrones simples que no son como nada. El segundo reconoce texturas y formas simples. En la tercera capa, se hacen visibles formas reconocibles como ruedas y esferas rojo anaranjado (tomates, mariquitas, algo más).En la primera capa, el lado del campo receptivo es 11, y en las posteriores, de tres a cinco. Pero recuerde, las capas posteriores reconocen mapas de características generados por capas anteriores, por lo que cada uno de sus "píxeles" denota varios píxeles de la imagen original. Por lo tanto, el campo receptivo de cada capa incluye una mayor parte de la primera imagen que las capas anteriores. Esto es parte de la razón por la cual las miniaturas en las capas posteriores se ven más complejas que en las anteriores.La quinta y última capa de la red es capaz de reconocer una impresionante variedad de elementos. Por ejemplo, mira esta imagen que seleccioné en la esquina superior derecha de la imagen correspondiente a la quinta capa: Las nueve imágenes de la derecha pueden no ser iguales. Pero si observa los nueve mapas de calor de la izquierda, verá que este detector de funciones no se enfoca en los objetos en primer plano de las fotos. ¡En cambio, se concentra en la hierba en el fondo de cada uno de ellos!Obviamente, un detector de hierba es útil si una de las categorías que está tratando de identificar es "hierba", pero puede ser útil para muchas otras categorías. Después de cinco capas convolucionales, AlexNet tiene tres capas conectadas completamente, como nuestra red para el reconocimiento de escritura a mano. Estas capas examinan cada uno de los mapas de características emitidos por cinco capas convolucionales, tratando de clasificar la imagen en una de las 1000 categorías posibles.Entonces, si hay hierba en el fondo, entonces con una alta probabilidad habrá un animal salvaje en la imagen. Por otro lado, si hay hierba en el fondo, es menos probable que sea una imagen de muebles en la casa. Estos y otros detectores de características de quinta capa proporcionan una tonelada de información sobre el contenido probable de la foto. Las últimas capas de la red sintetizan esta información para proporcionar una suposición basada en hechos sobre lo que generalmente se representa en la imagen.
Las nueve imágenes de la derecha pueden no ser iguales. Pero si observa los nueve mapas de calor de la izquierda, verá que este detector de funciones no se enfoca en los objetos en primer plano de las fotos. ¡En cambio, se concentra en la hierba en el fondo de cada uno de ellos!Obviamente, un detector de hierba es útil si una de las categorías que está tratando de identificar es "hierba", pero puede ser útil para muchas otras categorías. Después de cinco capas convolucionales, AlexNet tiene tres capas conectadas completamente, como nuestra red para el reconocimiento de escritura a mano. Estas capas examinan cada uno de los mapas de características emitidos por cinco capas convolucionales, tratando de clasificar la imagen en una de las 1000 categorías posibles.Entonces, si hay hierba en el fondo, entonces con una alta probabilidad habrá un animal salvaje en la imagen. Por otro lado, si hay hierba en el fondo, es menos probable que sea una imagen de muebles en la casa. Estos y otros detectores de características de quinta capa proporcionan una tonelada de información sobre el contenido probable de la foto. Las últimas capas de la red sintetizan esta información para proporcionar una suposición basada en hechos sobre lo que generalmente se representa en la imagen.Lo que hace que las capas convolucionales sean diferentes: pesos de entrada comunes
Vimos que los detectores de características en capas convolucionales muestran un reconocimiento de patrones impresionante, pero hasta ahora no he explicado cómo funcionan realmente las redes convolucionales.La capa convolucional (SS) consta de neuronas. Ellos, como cualquier neurona, toman un promedio ponderado en la entrada y usan la función de activación. Los parámetros se entrenan utilizando técnicas de propagación hacia atrás.Pero, a diferencia del NS anterior, el SS no está completamente conectado. Cada neurona recibe información de una pequeña fracción de las neuronas de la capa anterior. Y, lo que es más importante, las neuronas de red convolucionales tienen pesos de entrada comunes.Veamos la primera neurona del primer AlexNet SS con más detalle. El campo receptivo de esta capa tiene un tamaño de 11x11 píxeles, por lo que la primera neurona estudia un cuadrado de 11x11 píxeles en una esquina de la imagen. Esta neurona recibe información de estos 121 píxeles, y cada píxel tiene tres valores: rojo, verde y azul. Por lo tanto, en general, la neurona tiene 363 parámetros de entrada. Como cualquier neurona, esta toma un promedio ponderado de 363 parámetros y les aplica una función de activación. Y, dado que los parámetros de entrada son 363, los parámetros de peso también necesitan 363.La segunda neurona de la primera capa es similar a la primera. También estudia los cuadrados de 11x11 píxeles, pero su campo receptivo se desplaza cuatro píxeles en relación con el primero. Los dos campos tienen una superposición de 7 píxeles, por lo que la red no pierde de vista los patrones interesantes que caen en la unión de dos cuadrados. La segunda neurona también toma 363 parámetros que describen el cuadrado 11x11, multiplica cada uno de ellos por peso, agrega y aplica la función de activación.Pero en lugar de usar un conjunto separado de 363 pesos, la segunda neurona usa los mismos pesos que la primera. El píxel superior izquierdo de la primera neurona usa los mismos pesos que el píxel superior izquierdo de la segunda. Por lo tanto, ambas neuronas están buscando el mismo patrón; sus campos receptivos simplemente se desplazan 4 píxeles entre sí.Naturalmente, hay más de dos neuronas: en la red 55x55 hay 3025 neuronas. Cada uno de ellos usa el mismo conjunto de 363 pesos que los dos primeros. Juntas, todas las neuronas forman un detector de características que "escanea" la imagen en busca del patrón deseado, que puede ubicarse en cualquier lugar.Recuerde que la primera capa AlexNet tiene 96 detectores de características. Las 3025 neuronas que acabo de mencionar forman uno de estos 96 detectores. Cada uno de los 95 restantes es un grupo separado de 3025 neuronas. Cada grupo de 3025 neuronas usa un conjunto común de 363 pesos; sin embargo, para cada uno de los 95 grupos tiene el suyo.Los HF se entrenan utilizando la misma propagación hacia atrás que se usa para redes completamente conectadas, pero la estructura convolucional hace que el proceso de aprendizaje sea más eficiente y efectivo."Usar la convolución realmente ayuda: los parámetros se pueden reutilizar", dijo Sean Gerrish, experto en defensa y autorización. Esto reduce drásticamente la cantidad de pesos de entrada que la red tiene que aprender, lo que le permite producir mejores resultados con menos ejemplos de capacitación.Aprender en una parte de la imagen da como resultado un reconocimiento mejorado del mismo patrón en otras partes de la imagen. Esto permite que la red logre un alto rendimiento en una cantidad mucho menor de ejemplos de capacitación.La gente rápidamente se dio cuenta del poder de las redes convolucionales profundas.
El trabajo de AlexNet se convirtió en una sensación en la comunidad académica de la región de Moscú, pero su importancia se entendió rápidamente en la industria de TI. Google estaba especialmente interesado en ella.
En 2013, Google adquirió una startup fundada por los autores AlexNet. La compañía utilizó esta tecnología para agregar una nueva función de búsqueda de fotos a Google Photos. "Tomamos la investigación avanzada y la pusimos en funcionamiento poco más de seis meses después", escribió Chuck Rosenberg de Google.
Mientras tanto, en 2013, se describió cómo Google usa GSS para reconocer direcciones de fotos de Google Street View. "Nuestro sistema nos ayudó a extraer casi 100 millones de direcciones físicas de estas imágenes", escribieron los autores.
Los investigadores descubrieron que la eficacia de NS crece con una profundidad creciente. "Descubrimos que la eficacia de este enfoque aumenta con la profundidad del SCN, y las arquitecturas más profundas que entrenamos muestran los mejores resultados", escribió el equipo de Google Street View. "Nuestros experimentos sugieren que las arquitecturas más profundas pueden producir una mayor precisión, pero con una desaceleración en la eficiencia".
Entonces, después de AlexNet, las redes comenzaron a profundizarse. El equipo de Google hizo una oferta en la competencia en 2014, solo dos años después de que AlexNet ganó en 2012. También se basó en un SNA profundo, pero Goolge utilizó una red mucho más profunda de 22 capas para lograr una tasa de error de 6,7%: esta fue una mejora importante en comparación con el 16% de AlexNet.
Pero al mismo tiempo, las redes más profundas funcionaron mejor solo con conjuntos más grandes de datos de entrenamiento. Por lo tanto, Gerrish dice que el conjunto de datos y la competencia ImageNet jugaron un papel importante en el éxito del SNA. Recuerde que en la competencia ImageNet, los participantes reciben un millón de imágenes y se les pide que las clasifiquen en 1,000 categorías.
"Si tiene un millón de imágenes para capacitación, cada clase incluye 1,000 imágenes", dijo Gerrish. Sin un conjunto de datos tan grande, dijo, "tendrías demasiadas opciones para entrenar la red".
En los últimos años, los expertos se están concentrando cada vez más en recopilar una gran cantidad de datos para capacitar redes más profundas y más precisas. Es por eso que las compañías que desarrollan automóviles robóticos se concentran en correr en la vía pública: las imágenes y videos de estos viajes se envían a la sede y se utilizan para entrenar a las empresas NS.
Auge de la computación de aprendizaje profundo
El descubrimiento del hecho de que las redes más profundas y los conjuntos de datos más grandes pueden mejorar el rendimiento de NS ha creado una sed insaciable por una potencia informática cada vez mayor. Uno de los componentes principales del éxito de AlexNet fue la idea de que el entrenamiento matricial se usa en el entrenamiento NS, que se puede realizar de manera eficiente en GPU bien paralelizables.
"Los NS están bien paralelos", dijo Jai Ten, un investigador de MO. Las tarjetas gráficas, que proporcionan una enorme potencia de procesamiento en paralelo para videojuegos, han demostrado ser útiles para las NS.
"La parte central de la GPU, una multiplicación matricial muy rápida, resultó ser la parte central para el trabajo de la Asamblea Nacional", dijo Ten.
Todo esto ha sido exitoso para los principales fabricantes de GPU, Nvidia y AMD. Ambas compañías han desarrollado nuevos chips específicamente adaptados a las necesidades de la aplicación MO, y ahora las aplicaciones de IA son responsables de una parte importante de las ventas de GPU de estas compañías.
En 2016, Google anunció la creación de un chip especial, la Unidad de Procesamiento de Tensor (TPU), diseñada para operar en la Asamblea Nacional. "Aunque Google estaba considerando la posibilidad de crear circuitos integrados de propósito especial (ASIC) en 2006, esta situación se volvió urgente en 2013",
escribió un representante de la compañía el año pasado. "Fue entonces cuando nos dimos cuenta de que los requisitos de rápido crecimiento de la Asamblea Nacional para la potencia informática pueden requerir que dupliquemos la cantidad de centros de datos que tenemos".
Al principio, solo los propios servicios de Google tenían acceso a TPU, pero luego la compañía permitió que todos usaran esta tecnología a través de una plataforma de computación en la nube.
Por supuesto, Google no es la única compañía que trabaja en chips de inteligencia artificial. Solo algunos ejemplos: en las últimas versiones de los chips de iPhone
hay un "núcleo neuronal" optimizado para operaciones con el NS. Intel está
desarrollando su propia línea de chips optimizados para GO. Tesla
anunció recientemente el rechazo de los chips de Nvidia a favor de sus propios chips NS. También se rumorea que Amazon está
trabajando en sus chips de inteligencia artificial.
¿Por qué las redes neuronales profundas son difíciles de entender?
Le expliqué cómo funcionan las redes neuronales, pero no le expliqué por qué funcionan tan bien. No está claro cómo exactamente la inmensa cantidad de cálculos matriciales permite que un sistema informático distinga un jaguar de un guepardo y el saúco de la grosella.
Quizás la cualidad más notable de la Asamblea Nacional es que no lo hacen. La convolución permite que el NS entienda la separación silábica: pueden determinar si la imagen de la esquina superior derecha de la imagen es similar a la imagen en la esquina superior izquierda de otra imagen.
Pero al mismo tiempo, el SCN no tiene idea de la geometría. No pueden reconocer la similitud de las dos imágenes si se giran 45 grados o se duplican. SNA no intenta comprender la estructura tridimensional de los objetos y no puede tener en cuenta las diferentes condiciones de iluminación.
Pero al mismo tiempo, los NS pueden reconocer fotos de perros tomadas tanto de frente como de lado, y no importa si el perro ocupa una pequeña parte de la imagen o una grande. Como lo hacen Resulta que si hay suficientes datos, un enfoque estadístico con enumeración directa puede hacer frente a la tarea. El SNA no está diseñado para que pueda "imaginar" cómo se vería una imagen en particular desde un ángulo diferente o en diferentes condiciones, pero con un número suficiente de ejemplos etiquetados, puede aprender todas las variaciones posibles de la imagen por simple repetición.
Hay evidencia de que el sistema visual de las personas funciona de manera similar. Mire un par de imágenes: primero estudie cuidadosamente la primera y luego abra la segunda.
 Primera foto
Primera fotoEl creador de la imagen tomó la fotografía de alguien y puso los ojos y la boca al revés. La imagen parece relativamente normal cuando la miras al revés, porque el sistema visual humano está acostumbrado a ver los ojos y la boca en esta posición. Pero si observa la imagen en la orientación correcta, puede ver inmediatamente que la cara está extrañamente distorsionada.
Esto sugiere que el sistema visual humano se basa en las mismas técnicas de reconocimiento de patrones crudos que el NS. Si observamos algo que casi siempre es visible en una orientación, el ojo humano, podemos reconocerlo mucho mejor en su orientación normal.
Los NS reconocen bien las imágenes utilizando todo el contexto disponible en ellas. Por ejemplo, los automóviles generalmente circulan por carreteras. Los vestidos generalmente se usan en el cuerpo de una mujer o se cuelgan en un armario. Las aeronaves generalmente se disparan contra el cielo o gobiernan en la pista. Nadie enseña específicamente al NS estas correlaciones, pero con un número suficiente de ejemplos etiquetados, la red misma puede aprenderlos.
En 2015, los investigadores de Google intentaron comprender mejor el NS, "ejecutándolos al revés". En lugar de usar imágenes para entrenar NS, usaron NS entrenado para cambiar las imágenes. Por ejemplo, comenzaron con una imagen que contenía ruido aleatorio, y luego la cambiaron gradualmente para que activara fuertemente una de las neuronas de salida del NS; de hecho, le pidieron al NS que "dibujara" una de las categorías que se le enseñó a reconocer. En un caso interesante, forzaron al NS a generar imágenes que activan el NS, entrenados para reconocer las pesas.

"Por supuesto, hay pesas aquí, pero ni una sola imagen de pesas parece completa sin la presencia de un cuerpo muscular muscular que las levante", escribieron los investigadores de Google.
A primera vista parece extraño, pero en realidad no es tan diferente de lo que hace la gente. Si vemos un objeto pequeño o borroso en la imagen, buscamos una pista en su entorno para comprender lo que puede suceder allí. Las personas, obviamente, hablan de las imágenes de manera diferente, utilizando una comprensión conceptual compleja del mundo que las rodea. Pero al final, el STS reconoce bien las imágenes porque aprovechan al máximo todo el contexto representado en ellas, y esto no es muy diferente de cómo las personas lo hacen.