
El 14 de mayo, cuando Trump se estaba preparando para lanzar todos los perros en Huawei, me senté pacíficamente en Shenzhen en el Huawei STW 2019, una gran conferencia para 1000 participantes, que incluyó informes de
Philip Wong , vicepresidente de investigación de TSMC sobre las perspectivas de la computación no von Neumann arquitecturas, y Heng Liao, becario de Huawei, científico jefe del laboratorio de Huawei 2012, sobre el desarrollo de una nueva arquitectura de procesadores de tensor y neuroprocesadores. TSMC, si lo sabe, fabrica aceleradores neuronales para Apple y Huawei con tecnología de 7 nm (que
pocas personas poseen ), y Huawei está listo para competir con Google y NVIDIA en términos de neuroprocesadores.
Google en China está prohibido, no me molesté en poner una VPN en la tableta, así que usé
patriotamente Yandex para ver cuál es la situación con otros fabricantes de hierro similar y qué sucede generalmente. En general, observé la situación, pero solo después de estos informes me di cuenta de lo grande que se estaba preparando la revolución en las entrañas de las compañías y el silencio de las salas científicas.
Solo el año pasado, se invirtieron más de $ 3 mil millones en el tema. Google ha declarado durante mucho tiempo que las redes neuronales son un área estratégica, está construyendo activamente su soporte de hardware y software. NVIDIA, sintiendo que el trono es asombroso, está haciendo esfuerzos fantásticos en bibliotecas de aceleración de redes neuronales y nuevo hardware. Intel en 2016 gastó 0.8 mil millones para comprar dos compañías involucradas en la aceleración de hardware de redes neuronales. Y esto a pesar del hecho de que las compras principales aún no han comenzado, y el número de jugadores ha superado los cincuenta y está creciendo rápidamente.
TPU, VPU, IPU, DPU, NPU, RPU, NNP: ¿qué significa todo esto y quién ganará? Tratemos de resolverlo. ¿A quién le importa? ¡Bienvenido al gato!
Descargo de responsabilidad: el autor tuvo que reescribir completamente los algoritmos de procesamiento de video para una implementación efectiva en ASIC, y los clientes hicieron prototipos en FPGA, por lo que hay una idea de la profundidad de la diferencia en las arquitecturas. Sin embargo, el autor no ha trabajado directamente con el hierro recientemente. Pero él anticipa que tendrá que profundizar.
Antecedentes de problemas
El número de cálculos requeridos está creciendo rápidamente, a la gente le encantaría tomar más capas, más opciones de arquitectura, jugar más activamente con hiperparámetros, pero ... depende del rendimiento. Al mismo tiempo, por ejemplo, con el crecimiento de la productividad de los viejos procesadores buenos, grandes problemas. Todo lo bueno llega a su fin: la ley de Moore, como saben, se está agotando y la tasa de crecimiento del rendimiento del procesador cae:
Cálculos del rendimiento real de operaciones enteras en SPECint en comparación con VAX11-780 , en lo sucesivo a menudo una escala logarítmicaSi desde mediados de los 80 hasta mediados de los 2000, en los años bendecidos del apogeo de las computadoras, el crecimiento fue a una tasa promedio de 52% por año, en los últimos años ha disminuido a 3% por año. Y esto es un problema (una traducción de un artículo reciente del patriarca John Hennessey sobre los problemas y las perspectivas de la arquitectura moderna
estaba en Habré ).
Hay muchas razones, por ejemplo, la frecuencia de los procesadores ha dejado de crecer:
Se hizo más difícil reducir el tamaño de los transistores. La última desgracia que reduce drásticamente el rendimiento (incluido el rendimiento de las CPU ya lanzadas) es (redoble de tambores) ... correcto, seguridad.
Meltdown ,
Spectre y
otras vulnerabilidades causan un daño enorme a la tasa de crecimiento de la potencia de procesamiento de la CPU (
un ejemplo de deshabilitación de hyperthreading (!)). El tema se ha vuelto popular y se encuentran nuevas vulnerabilidades de este tipo
casi mensualmente . Y esto es una especie de pesadilla, porque duele en términos de rendimiento.
Al mismo tiempo, el desarrollo de muchos algoritmos está firmemente vinculado al crecimiento familiar en la potencia del procesador. Por ejemplo, muchos investigadores de hoy en día no están preocupados por la velocidad de los algoritmos; se les ocurrirá algo. Y sería bueno cuando se aprende: las redes se vuelven grandes y "difíciles" de usar. Esto es especialmente evidente en el video, para el cual la mayoría de los enfoques, en principio, no son aplicables a alta velocidad. Y a menudo tienen sentido solo en tiempo real. Esto también es un problema.
Asimismo, se están desarrollando nuevos estándares de compresión que implican un aumento en la potencia del decodificador. ¿Y si la potencia del procesador no crece? La generación anterior recuerda cómo en la década de 2000 hubo problemas para reproducir videos de alta definición en la entonces nueva
H.264 en computadoras más antiguas. Sí, la calidad era mejor con un tamaño más pequeño, pero en escenas rápidas la imagen se colgaba o el sonido se rasgaba. Tengo que comunicarme con los desarrolladores del nuevo
VVC / H.266 (se planea un lanzamiento para el próximo año). No los envidiarás.
Entonces, ¿qué nos prepara el próximo siglo a la luz de la disminución en la tasa de crecimiento del rendimiento del procesador aplicado a las redes neuronales?
CPU
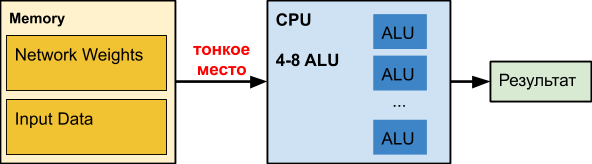
Una
CPU normal es una gran trituradora que se ha perfeccionado durante décadas. Por desgracia, para otras tareas.
Cuando trabajamos con redes neuronales, especialmente las profundas, nuestra red puede ocupar cientos de megabytes. Por ejemplo, los requisitos de memoria de las redes de
detección de
objetos son los siguientes:
En nuestra experiencia, los coeficientes de una red neuronal profunda para procesar
bordes translúcidos pueden ocupar 150-200 MB. Los colegas de la red neuronal determinan la edad y el sexo del tamaño de los coeficientes del orden de 50 MB. Y durante la optimización para la versión móvil de precisión reducida: aproximadamente 25 MB (float32⇒float16).
Al mismo tiempo, el gráfico de retraso al acceder a la memoria, dependiendo del tamaño de los datos, se distribuye
aproximadamente de esta manera (la escala horizontal es logarítmica):
Es decir Con un aumento en el volumen de datos de más de 16 MB, el retraso aumenta en 50 veces o más, lo que afecta fatalmente el rendimiento. De hecho, la mayoría de las veces, la CPU, cuando trabaja con redes neuronales profundas, espera datos
estúpidamente .
Los datos de Intel sobre la aceleración de varias redes son interesantes, donde, de hecho, la aceleración ocurre solo cuando la red se vuelve pequeña (por ejemplo, como resultado de la cuantificación de los pesos), para comenzar a ingresar al menos parcialmente el caché junto con los datos procesados. Tenga en cuenta que el caché de una CPU moderna consume hasta la mitad de la energía del procesador. En el caso de redes neuronales pesadas, es ineficaz y funciona un calentador excesivamente caro.
Para seguidores de redes neuronales en la CPUSegún nuestras pruebas internas, incluso
Intel OpenVINO pierde la implementación del marco de multiplicación de matriz + NNPACK en muchas arquitecturas de red (especialmente en arquitecturas simples donde el ancho de banda es importante para el procesamiento de datos en tiempo real en modo de subproceso único). Tal escenario es relevante para varios clasificadores de objetos en la imagen (donde la red neuronal necesita ejecutarse una gran cantidad de veces, 50-100 en términos de la cantidad de objetos en la imagen) y la sobrecarga de iniciar OpenVINO se vuelve excesivamente alta.
Pros:- "Todo el mundo lo tiene", y generalmente está inactivo, es decir precio de entrada relativamente bajo para facturación e implementación.
- Hay redes separadas que no son CV que se adaptan bien a la CPU, los colegas llaman, por ejemplo, Wide & Deep y GNMT.
Menos:- La CPU es ineficiente cuando se trabaja con redes neuronales profundas (cuando el número de capas de red y el tamaño de los datos de entrada son grandes), todo funciona muy lentamente.
GPU

El tema es bien conocido, por lo que resumimos brevemente lo principal. En el caso de las redes neuronales, la
GPU tiene una ventaja de rendimiento significativa en tareas masivamente paralelas:
Preste atención a cómo se recoce el
Xeon Phi 7290 de 72 núcleos, mientras que el "azul" también es el servidor Xeon, es decir. Intel no se rinde tan fácilmente, lo cual se discutirá a continuación. Pero lo más importante, la memoria de las tarjetas de video fue diseñada originalmente para un rendimiento aproximadamente 5 veces mayor. En las redes neuronales, la computación con datos es extremadamente simple. Algunas acciones elementales, y necesitamos nuevos datos. Como resultado, la velocidad de acceso a los datos es crítica para la operación eficiente de una red neuronal. Una memoria de alta velocidad "integrada" en la GPU y un sistema de administración de caché más flexible que en la CPU pueden resolver este problema:
Tim Detmers ha estado apoyando la interesante revisión
"Qué GPU (s) obtener para el aprendizaje profundo: mi experiencia y consejos para usar GPU en el aprendizaje profundo" desde hace varios años. Está claro que Tesla y Titans gobiernan para el entrenamiento, aunque la diferencia en las arquitecturas puede causar arrebatos interesantes, por ejemplo, en el caso de redes neuronales recurrentes (y el líder en general es TPU, tenga en cuenta para el futuro):
Sin embargo, hay un gráfico de rendimiento extremadamente útil para el dólar, en el caballo
RTX (probablemente debido a
sus núcleos Tensor ), si tiene suficiente memoria para ello, por supuesto:
Por supuesto, el costo de la informática es importante. El segundo lugar de la primera calificación y el último de la segunda:
Tesla V100 se vende por 700 mil rublos, como 10 computadoras "normales" (+ interruptor Infiniband costoso, si desea entrenar en varios nodos). Verdadero V100 y funciona para diez. Las personas están dispuestas a pagar de más por una aceleración tangible del aprendizaje.
Total, resumir!
Pros:- Cardinal - 10-100 veces - aceleración en comparación con la CPU.
- Extremadamente efectivo para el entrenamiento (y algo menos efectivo para el uso).
Menos:- El costo de las tarjetas de video de gama alta (que tienen suficiente memoria para entrenar redes grandes) excede el costo del resto de la computadora ...
FPGA
 FPGA
FPGA ya es más interesante. Esta es una red de varios millones de bloques programables, que también podemos interconectar mediante programación. La red y los bloques se
ven más o menos así (el cuello de botella es el cuello de botella, preste atención, nuevamente frente a la memoria del chip, pero es más fácil, que se describirá a continuación):
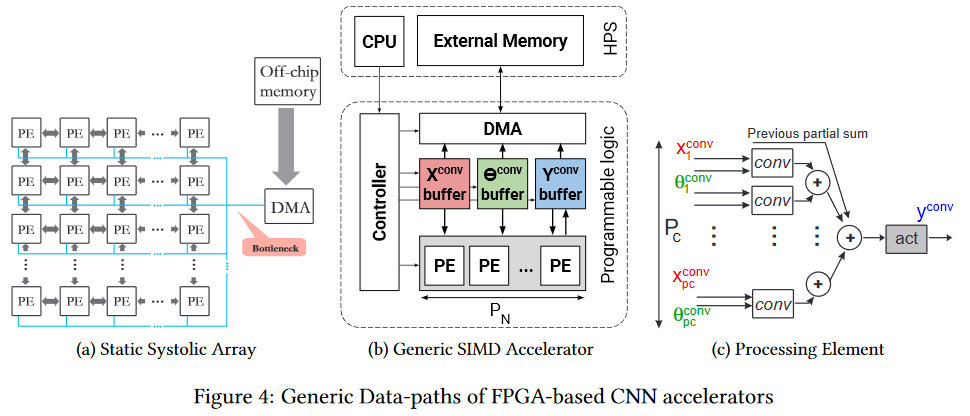
Naturalmente, tiene sentido usar FPGA ya en la etapa de usar una red neuronal (en la mayoría de los casos, no hay suficiente memoria para el entrenamiento). Además, el tema de la ejecución en FPGA ahora ha comenzado a desarrollarse activamente. Por ejemplo, aquí está el
marco fpgaConvNet , que puede acelerar significativamente el uso de CNN en FPGA y reducir el consumo de energía.
La ventaja clave de FPGA es que podemos almacenar la red directamente en las celdas, es decir. desaparece mágicamente un punto delgado en forma de cientos de megabytes de los mismos datos que se transfieren 25 veces por segundo (para video) en la misma dirección. Esto permite una velocidad de reloj más baja y la ausencia de cachés en lugar de un rendimiento más bajo para obtener un aumento notable. Sí, y reduce drásticamente el consumo de energía del
calentamiento global por unidad de cálculo.
Intel se unió activamente al proceso, lanzando el
OpenVINO Toolkit en código abierto el año pasado, que incluye el
Deep Learning Deployment Toolkit (parte de
OpenCV ). Además, el rendimiento de los FPGA en diferentes cuadrículas parece bastante interesante, y la ventaja de los FPGA en comparación con las GPU (aunque las GPU integradas por Intel) es bastante significativa:
Lo que calienta especialmente el alma del autor: se comparan los FPS, es decir fotogramas por segundo es la métrica más práctica para video. Dado que Intel compró
Altera , el segundo jugador más grande en el mercado de FPGA, en 2015, la tabla ofrece buenos motivos para pensar.
Y, obviamente, la barrera de entrada a tales arquitecturas es mayor, por lo que debe pasar algún tiempo antes de que aparezcan herramientas convenientes que tengan en cuenta la arquitectura FPGA fundamentalmente diferente. Pero subestimar el potencial de la tecnología no vale la pena. Borda dolorosamente muchos lugares delgados.
Finalmente, enfatizamos que
programar FPGAs es un arte separado. Como tal, el programa no se ejecuta allí, y todos los cálculos se realizan en términos de flujos de datos, retrasos de flujo (que afecta el rendimiento) y puertas usadas (que siempre faltan). Por lo tanto, para comenzar a programar de manera efectiva, debe
cambiar completamente
su propio firmware (en la red neuronal que está entre sus oídos). Con buena eficiencia, esto no se obtiene en absoluto. Sin embargo, los nuevos marcos pronto ocultarán la diferencia externa de los investigadores.
Pros:- Ejecución de red potencialmente más rápida.
- Consumo de energía significativamente menor en comparación con la CPU y la GPU (esto es especialmente importante para las soluciones móviles).
Contras:- Principalmente ayudan a acelerar la ejecución; la capacitación sobre ellos, a diferencia de la GPU, es notablemente menos conveniente.
- Programación más compleja en comparación con las opciones anteriores.
- Notablemente menos especialistas.
ASIC

El siguiente es
ASIC , que es la abreviatura de Circuito integrado específico de la aplicación, es decir circuito integrado para nuestra tarea. Por ejemplo, realizar una red neuronal colocada en hierro. Sin embargo, la mayoría de los nodos informáticos pueden funcionar en paralelo. De hecho, solo las dependencias de datos y la informática desigual en diferentes niveles de la red pueden evitar que usemos constantemente todas las ALU que funcionan.
Quizás la minería de criptomonedas ha hecho el anuncio ASIC más grande entre el público en general en los últimos años. Al principio, la minería en la CPU fue bastante rentable, luego tuve que comprar una GPU, luego FPGA y luego ASIC especializados, ya que la gente (léase - el mercado) maduró para pedidos en los que su producción se volvió rentable.
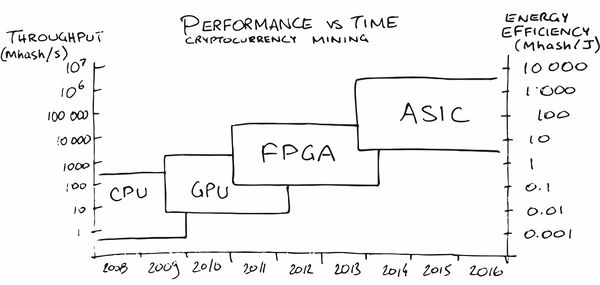
En nuestra área, también han aparecido servicios (¡naturalmente!)
Que ayudan a poner una red neuronal en hierro con las características necesarias para el consumo de energía, FPS y precio. Mágicamente, de acuerdo!
PERO! Estamos perdiendo la personalización de la red. Y, por supuesto, la gente también lo piensa. Por ejemplo, aquí hay un artículo con el dicho: "
¿Puede una arquitectura reconfigurable vencer al ASIC como un acelerador CNN? " ("¿Puede una arquitectura configurable vencer al ASIC como un acelerador CNN?"). Hay suficiente trabajo sobre este tema, porque la pregunta no está inactiva. La principal desventaja de ASIC es que después de que hemos conducido la red al hardware, nos resulta difícil cambiarla. Son más beneficiosos para los casos en que ya necesitamos una red que funcione bien con millones de chips con bajo consumo de energía y alto rendimiento. Y esta situación se está desarrollando gradualmente en el mercado de automóviles de piloto automático, por ejemplo. O en cámaras de vigilancia. O en las cámaras de las aspiradoras robotizadas. O en las cámaras de un refrigerador casero. O en una cámara de cafetera.
O en la cámara de hierro. Bueno, entiendes la idea, en
resumen .
Es importante que en la producción en masa el chip sea barato, funcione rápidamente y consuma un mínimo de energía.
Pros:- El costo de chip más bajo en comparación con todas las soluciones anteriores.
- El menor consumo de energía por unidad de operación.
- Muy alta velocidad (incluido, si lo desea, un registro).
Contras:- Capacidad muy limitada para actualizar la red y la lógica.
- El mayor costo de desarrollo en comparación con todas las soluciones anteriores.
- Usar ASIC es rentable principalmente para grandes corridas.
TPU
Recuerde que cuando se trabaja con redes, hay dos tareas: capacitación y ejecución (inferencia). Si los FPGA / ASIC se centran principalmente en acelerar la ejecución (incluida alguna red fija), entonces la TPU (Unidad de procesamiento de tensor o procesadores de tensor) es una aceleración de aprendizaje basada en hardware o una aceleración relativamente universal de una red arbitraria. El nombre es hermoso, de acuerdo, aunque de hecho, los
tensores de rango 2 con una unidad de multiplicación mixta (MXU) conectada a la memoria de alto ancho de banda (HBM) todavía se están utilizando. A continuación se muestra el diagrama de arquitectura de la segunda y tercera versión de Google TPU:
TPU Google
En general, Google hizo un anuncio para el nombre de TPU, revelando desarrollos internos en 2017:
Comenzaron a trabajar preliminarmente en procesadores especializados para redes neuronales con sus palabras en 2006, en 2013 crearon un proyecto con buena financiación, y en 2015 comenzaron a trabajar con los primeros chips que ayudaron mucho con las redes neuronales para el servicio en la nube de Google Translate y más. Y esto fue, enfatizamos, la aceleración de
la red. Una ventaja importante para los centros de datos es la eficiencia energética de TPU en dos órdenes de magnitud más alta en comparación con las CPU (gráfico para TPU v1):
Además, como regla, en comparación con la GPU, el
rendimiento de la red es 10-30 veces mejor para mejor:
La diferencia es incluso 10 veces significativa. Está claro que la diferencia con la GPU en 20-30 veces determina el desarrollo de esta dirección.
Y, afortunadamente, Google no está solo.
TPU Huawei
Hoy, el sufrido Huawei también comenzó a desarrollar TPU hace varios años bajo el nombre de Huawei Ascend, y en dos versiones a la vez: para centros de datos (como Google) y para dispositivos móviles (que Google también comenzó a hacer recientemente). Si crees en los materiales de Huawei, superaron el nuevo Google TPU v3 de FP16 2.5 veces y NVIDIA V100 2 veces:

Como de costumbre, una buena pregunta: cómo se comportará este chip en tareas reales. En el gráfico, como puede ver, el máximo rendimiento. Además, Google TPU v3 es bueno en muchos sentidos porque puede funcionar eficazmente en grupos de 1024 procesadores. Huawei también anunció clústeres de servidores para el Ascend 910, pero no hay detalles. En general, los ingenieros de Huawei han demostrado ser extremadamente competentes en los últimos 10 años, y existe la posibilidad de que se use un rendimiento máximo 2.8 veces mayor en comparación con Google TPU v3, junto con la última tecnología de proceso de 7 nm.
La memoria y el bus de datos son críticos para el rendimiento, y la diapositiva muestra que se ha prestado considerable atención a estos componentes (incluida la velocidad de comunicación con la memoria mucho más rápida que la de la GPU):
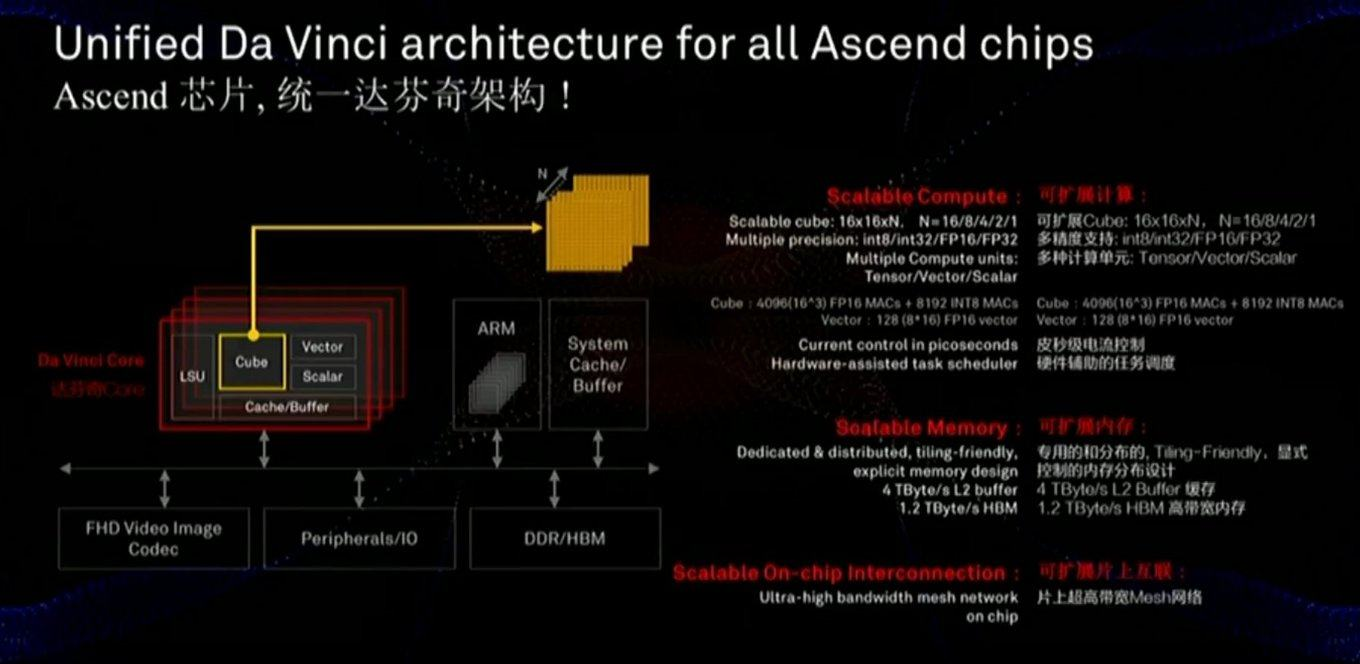
El chip también usa un enfoque ligeramente diferente: no escalas MXU 128x128 bidimensionales, sino cálculos en un cubo tridimensional de un tamaño más pequeño 16x16xN, donde N = {16,8,4,2,1}. Por lo tanto, la pregunta clave es qué tan bien se ubicará en la aceleración real de redes específicas (por ejemplo, los cálculos en un cubo son convenientes para las imágenes). Además, un estudio cuidadoso de la diapositiva muestra que, a diferencia de Google, el chip incorpora de inmediato el trabajo con video FullHD comprimido. Para el autor, ¡esto suena
muy alentador!
Como se mencionó anteriormente, en la misma línea, los procesadores se desarrollan para dispositivos móviles para los que la eficiencia energética es crítica y en los que la red se ejecutará principalmente (es decir, por separado, procesadores para el aprendizaje en la nube y por separado, para la ejecución): y con este parámetro, todo Se ve bien en comparación con NVIDIA al menos (tenga en cuenta que no trajeron una comparación con Google, sin embargo, Google no da a la mano TPU en la nube) Y sus chips móviles competirán con los procesadores de Apple, Google y otras compañías, pero es demasiado pronto para hacer un balance aquí.Se ve claramente que los nuevos chips Nano, Tiny y Lite deberían ser aún mejores. Queda claro
y con este parámetro, todo Se ve bien en comparación con NVIDIA al menos (tenga en cuenta que no trajeron una comparación con Google, sin embargo, Google no da a la mano TPU en la nube) Y sus chips móviles competirán con los procesadores de Apple, Google y otras compañías, pero es demasiado pronto para hacer un balance aquí.Se ve claramente que los nuevos chips Nano, Tiny y Lite deberían ser aún mejores. Queda claro por qué Trump estaba asustado Por qué muchos fabricantes están examinando cuidadosamente los éxitos de Huawei (que superó a todas las empresas de hierro de EE. UU. en ingresos, incluido Intel en 2018).Redes análogas profundas
Como saben, la tecnología a menudo se desarrolla en espiral, cuando los enfoques antiguos y olvidados se vuelven relevantes en una nueva ronda.Algo similar podría suceder con las redes neuronales. Es posible que haya escuchado que una vez que las operaciones de multiplicación y suma se llevaron a cabo mediante tubos de electrones y transistores (por ejemplo, la conversión de espacios de color, una multiplicación típica de matrices, se realizó en todos los televisores en color hasta mediados de los 90). Surgió una buena pregunta: si nuestra red neuronal es relativamente resistente a los cálculos inexactos en el interior, ¿qué pasa si convertimos estos cálculos a forma analógica? Inmediatamente obtenemos una notable aceleración de los cálculos y una reducción potencialmente dramática en el consumo de energía para una operación:Con este enfoque, DNN (Red Neural Profunda) se calcula rápidamente y con eficiencia energética. Pero hay un problema, estos son DAC / ADC (DAC / ADC), convertidores de digital a analógico y viceversa, que reducen tanto la eficiencia energética como la precisión del proceso.Sin embargo, en 2017, IBM Research propuso CMOS analógico para RPU ( Unidades de procesamiento resistivas ), que le permiten almacenar datos procesados también en forma analógica y aumentar significativamente la eficiencia general del enfoque:Además, además de la memoria analógica, puede ser de gran ayuda reducir la precisión de una red neuronal: esta es la clave para miniaturizar las RPU, lo que significa aumentar el número de células computacionales en un chip. Y aquí, IBM también es un líder, y en particular, recientemente este año han mejorado con bastante éxito la red a una precisión de 2 bits y van a llevar la precisión a un bit (y dos bits durante el entrenamiento), lo que potencialmente permitirá 100 veces (!) Incrementar la productividad en comparación con GPU modernas:Es demasiado pronto para hablar de neurochips analógicos en detalle, porque si bien todo esto se está probando a nivel de los primeros prototipos:Sin embargo, la dirección potencial de la computación analógica parece
extremadamente interesante.
Lo único que confunde es que es IBM,
que ya ha presentado docenas de patentes sobre el tema . Según la experiencia, debido a las peculiaridades de la cultura corporativa, cooperan de manera relativamente débil con otras compañías y, al poseer algo de tecnología, es más probable que desaceleren su desarrollo entre otros que compartirlo de manera efectiva. Por ejemplo, IBM alguna vez se negó a otorgar licencias de compresión aritmética para JPEG al comité
ISO , a pesar de que el borrador del estándar era una opción con compresión aritmética. Como resultado, JPEG cobró vida con la compresión Huffman y una picadura del 10-15% peor de lo que podría. La misma situación fue con los estándares de compresión de video. Y la industria cambió masivamente a la compresión aritmética en códecs solo cuando 5 patentes de IBM expiraron 12 años después ... Esperemos que IBM esté más inclinado a cooperar esta vez y, en consecuencia,
deseamos el máximo éxito en el campo para todos los que no están asociados con IBM ,
hay muchas de esas personas y empresas .
Si funciona,
será una revolución en el uso de redes neuronales y una revolución en muchas áreas de la informática.Otras letras misceláneas
En general, el tema de la aceleración de las redes neuronales se ha puesto de moda, todas las grandes empresas y docenas de nuevas empresas están involucradas en él, y
al menos 5 de ellas han atraído más de $ 100 millones en inversiones a principios de 2018. En total, en 2017, se invirtieron $ 1.5 MIL MILLONES en nuevas empresas relacionadas con el desarrollo de chips. A pesar de que los inversores no se dieron cuenta de los fabricantes de chips durante 15 años (porque no había nada que atrapar en el contexto de los gigantes). En general, ahora hay una posibilidad real de una pequeña revolución de hierro. Además, es extremadamente difícil predecir qué arquitectura ganará, la necesidad de revolución ha madurado y las posibilidades de aumentar la productividad son grandes. La clásica situación revolucionaria ha madurado:
Moore ya no puede y
Dean aún no está listo.
Bueno, dado que la ley de mercado más importante, sea diferente, hay muchas cartas nuevas, por ejemplo:
- Unidad de procesamiento neuronal ( NPU ) : un neuroprocesador, a veces maravillosamente, un chip neuromórfico, en términos generales, el nombre general de un acelerador de redes neuronales, que se llaman chips Samsung , Huawei y más en la lista ...
De aquí en adelante en esta sección, se presentarán principalmente diapositivas de presentaciones corporativas como ejemplos de nombres de tecnología.
Está claro que una comparación directa es problemática, pero aquí hay algunos datos interesantes que comparan chips con neuroprocesadores de Apple y Huawei, producidos por TSMC mencionados al principio. Se puede ver que la competencia es dura, la nueva generación muestra un aumento de la productividad de 2 a 8 veces y la complejidad de los procesos tecnológicos:
- Procesador de red neuronal (NNP) : procesador de red neuronal.
Este es el nombre de su familia de chips, por ejemplo, Intel (originalmente era la compañía Nervana Systems , que Intel compró en 2016 por más de $ 400 millones). Sin embargo, en artículos y libros, el nombre NNP también es bastante común.
- Unidad de procesamiento de inteligencia (IPU) - un procesador inteligente - el nombre de los chips promovidos por Graphcore (por cierto, que ya recibió una inversión de $ 310 millones).
Produce tarjetas especiales para computadoras, pero orientadas al entrenamiento de redes neuronales, con un rendimiento de entrenamiento RNN 180–240 veces mayor que el del NVIDIA P100.
- Unidad de procesamiento de flujo de datos (DPU) - procesador de procesamiento de datos - el nombre es promovido por WAVE Computing , que ya recibió una inversión de $ 203 millones. Produce aproximadamente los mismos aceleradores que Graphcore:
Como recibieron 100 millones menos, declaran que el entrenamiento es solo 25 veces más rápido que en la GPU (aunque prometen que será 1000 veces pronto). A ver ...
- Unidad de procesamiento de visión ( VPU ) - Procesador de visión por computadora:
El término se usa en productos de varias compañías, por ejemplo, Myriad X VPU de Movidius (también comprado por Intel en 2016).
- Uno de los competidores de IBM (que, recordamos, usa el término RPU ), Mythic , está moviendo Analog DNN , que también almacena la red en el chip y una ejecución relativamente rápida. Hasta ahora solo tienen promesas, aunque serias :
Y esto enumera solo las áreas más grandes en el desarrollo en las que se han invertido cientos de millones (esto es importante en el desarrollo del hierro).
En general, como vemos, todas las flores florecen rápidamente. Gradualmente, las empresas asimilarán miles de millones de dólares en inversiones (por lo general, toma de 1,5 a 3 años fabricar chips), el polvo se asentará, el líder se aclarará, los ganadores, como de costumbre, escribirán una historia, y el nombre de la tecnología más exitosa en el mercado será generalmente aceptado. Esto ya ha sucedido más de una vez ("IBM PC", "Smartphone", "Xerox", etc.).
Algunas palabras sobre la comparación correcta
Como ya se señaló anteriormente, comparar correctamente el rendimiento de las redes neuronales no es fácil. Esto es exactamente por qué Google publica un gráfico en el que TPU v1 crea el NVIDIA V100. NVIDIA, al ver tal desgracia, publica un cronograma donde Google TPU v1 pierde el V100. (¡Entonces!) Google publica el siguiente cuadro, donde el V100 pierde en Google TPU v2 y v3. Y finalmente, Huawei es el horario en el que todos pierden en el Huawei Ascend, pero el V100 es mejor que el TPU v3. Circo, en resumen. Lo que es característico: ¡
cada gráfico
tiene su propia verdad!
Las causas profundas de la situación son claras:
- Puede medir la velocidad de aprendizaje o la velocidad de ejecución (lo que sea más conveniente).
- Es posible medir diferentes redes neuronales, porque la velocidad de ejecución / entrenamiento de diferentes redes neuronales en arquitecturas específicas puede diferir significativamente debido a la arquitectura de la red y la cantidad de datos requeridos.
- Y puede medir el rendimiento máximo del acelerador (quizás el más abstracto de todos los anteriores).
Como un intento de poner las cosas en orden en este zoológico,
apareció la prueba
MLPerf , que ahora tiene la versión 0.5 disponible, es decir está en el proceso de desarrollar una metodología de comparación, que se planea llevar a la primera versión en el
tercer trimestre de este año :
Dado que los autores son uno de los principales contribuyentes a TensorFlow, existe la posibilidad de descubrir cuál es la mejor manera de entrenar y posiblemente usarlo (porque la versión móvil de TF también se incluirá en esta prueba con el tiempo).
Recientemente, la organización internacional
IEEE , que publica la tercera parte de la literatura técnica mundial sobre electrónica de radio, computadoras e ingeniería eléctrica,
prohibió a Huawei la
cara de un niño, y pronto, sin embargo,
canceló la prohibición. Huawei todavía no está en el ranking
actual de MLPerf, mientras que Huawei TPU es un serio competidor de Google TPU y tarjetas NVIDIA (es decir, además de las políticas, hay razones económicas para ignorar a Huawei, francamente). ¡Con un interés no disimulado seguiremos el desarrollo de eventos!
Todo al cielo! Más cerca de las nubes!
Y, dado que se trataba de capacitación, vale la pena decir algunas palabras sobre sus detalles:
- Con la salida generalizada de la investigación en redes neuronales profundas (con docenas y cientos de capas que realmente desgarran a todos), fue necesario moler cientos de megabytes de coeficientes, lo que inmediatamente hizo ineficaces todos los cachés de procesador de generaciones anteriores. Al mismo tiempo, el clásico ImageNet discute una correlación estricta entre el tamaño de la red y su precisión (cuanto más alta mejor, la derecha, mayor es la red, el eje horizontal es logarítmico):
- El proceso de cálculo dentro de la red neuronal sigue un esquema fijo, es decir, donde todas las "ramificaciones" y "transiciones" (en términos del siglo pasado) se llevarán a cabo en la gran mayoría de los casos se conoce con precisión de antemano, lo que deja la ejecución especulativa de instrucciones sin trabajo, lo que anteriormente aumenta significativamente la productividad:
Esto hace que los mecanismos de predicción superescalares acumulados para la ramificación y los cálculos previos de las décadas anteriores de mejora del procesador sean ineficaces (desafortunadamente, esta parte del chip también contribuye al calentamiento global más bien como DNN en el caché de DNN).
- Además, el entrenamiento de la red neuronal está relativamente escalado horizontalmente . Es decir no podemos tomar 1000 computadoras poderosas y obtener aceleración de aprendizaje 1000 veces. E incluso a 100 no podemos (al menos hasta que se resuelva el problema teórico del deterioro de la calidad de la formación en un gran tamaño del lote). En general, es bastante difícil para nosotros distribuir algo en varias computadoras, porque tan pronto como disminuye la velocidad de acceso a la memoria unificada en la que se encuentra la red, la velocidad de su aprendizaje disminuye catastróficamente. Por lo tanto, si un investigador tiene acceso a 1000 computadoras potentes
de forma gratuita , seguramente las tomará todas pronto, pero lo más probable (si no hay infiniband + RDMA), habrá muchas redes neuronales con diferentes hiperparámetros. Es decir el tiempo total de entrenamiento será solo varias veces menor que con 1 computadora. Allí es posible jugar con los tamaños del lote y la educación superior y otras nuevas tecnologías de moda, pero la conclusión principal es sí, con un aumento en el número de computadoras, la eficiencia del trabajo y la probabilidad de lograr un resultado aumentarán, pero no linealmente. Y hoy, el tiempo de un investigador de Data Science es costoso y, a menudo, si puede gastar muchos automóviles (aunque no sea razonable), pero obtenga aceleración; esto se hace (vea el ejemplo con 1, 2 y 4 V100 caros en las nubes justo debajo).
Exactamente estos puntos explican por qué tanta gente se ha apresurado hacia el desarrollo de hierro especializado para redes neuronales profundas. ¿Y por qué obtuvieron sus miles de millones? Realmente hay luz visible al final del túnel y no solo Graphcore (que, recordemos, 240 veces el entrenamiento RNN se aceleró).
Por ejemplo, los caballeros de IBM Research
son optimistas de que el desarrollo de chips especiales que aumentarán la eficiencia informática en un orden de magnitud en 5 años (y en 10 años en 2 órdenes de magnitud, alcanzando un aumento de 1000 veces en comparación con 2016, en este gráfico, es cierto , en eficiencia por vatio, pero la potencia del núcleo también aumentará):
Todo esto significa la aparición de piezas de hierro, cuya capacitación será relativamente rápida, pero que será costosa, lo que naturalmente lleva a la idea de compartir el tiempo de uso de esta costosa pieza de hierro entre los investigadores. Y esta idea hoy no menos nos lleva naturalmente a la computación en la nube. Y la transición del aprendizaje a las nubes lleva mucho tiempo en marcha.
Tenga en cuenta que ahora la capacitación de los mismos modelos puede diferir en el tiempo en un orden de magnitud de diferentes servicios en la nube. Amazon lidera en el plomo, y Colab gratis de Google viene último. Tenga en cuenta cómo el resultado de la cantidad de V100 cambia entre los líderes: un aumento en la cantidad de tarjetas en 4 veces (!) Aumenta la productividad en menos de un tercio (!!!) de azul a púrpura, y Google tiene aún menos:
Parece que en los próximos años la diferencia crecerá a dos órdenes de magnitud. Señor! Cocinar dinero! Devolveremos amigablemente inversiones multimillonarias a los inversores más exitosos ...
En resumen
Intentemos resumir los puntos clave en la tableta:
Algunas palabras sobre la aceleración de software
Para ser justos, mencionamos que hoy el gran tema es la aceleración de software de la ejecución y capacitación de redes neuronales profundas. La ejecución puede acelerarse significativamente principalmente debido a la llamada cuantización de la red. Quizás esto se deba, en primer lugar, a que el rango de pesos utilizado no es tan grande y, a menudo, es posible aumentar los pesos de un valor de punto flotante de 4 bytes a un entero de 1 byte (y, recordando los éxitos de IBM, aún más fuerte). En segundo lugar, la red capacitada en su conjunto es bastante resistente al ruido computacional y la precisión de la transición a
int8 cae ligeramente. Al mismo tiempo, a pesar del hecho de que el número de operaciones puede incluso aumentar (debido a la escala al calcular), el hecho de que la red se reduzca en tamaño 4 veces y pueda considerarse operaciones vectoriales rápidas aumenta significativamente la velocidad general de ejecución. Esto es especialmente importante para las aplicaciones móviles, pero también funciona en las nubes (un ejemplo de ejecución acelerada en las nubes de Amazon):
Hay otras formas de
acelerar algorítmicamente
la ejecución de la red e incluso más formas de
acelerar el aprendizaje . Sin embargo, estos son grandes temas separados sobre los cuales no esta vez.
En lugar de una conclusión
En sus conferencias, el inversionista y autor
Tony Ceba da un magnífico ejemplo: en 2000, la supercomputadora No. 1 con una capacidad de 1 teraflops ocupó 150 metros cuadrados, costó $ 46 millones y consumió 850 kW:
15 años después, la GPU NVIDIA con un rendimiento de 2.3 teraflops (2 veces más) cabía en una mano, costaba $ 59 (una mejora de aproximadamente un millón de veces) y consumía 15 vatios (una mejora de 56 mil veces):
En marzo de este año,
Google presentó TPU Pods , que en realidad son supercomputadoras refrigeradas por líquido basadas en TPU v3, cuya característica clave es que pueden trabajar juntas en sistemas de 1024 TPU. Se ven bastante impresionantes:
No se dan los datos exactos, pero se dice que el sistema es comparable a las supercomputadoras Top-5 del mundo. TPU Pod puede aumentar dramáticamente la velocidad de aprendizaje de las redes neuronales. Para aumentar la velocidad de interacción, los TPU están conectados por líneas de alta velocidad en una estructura toroidal:

Parece que después de 15 años, este neuroprocesador dos veces más potente también podrá caber en su mano, como el
procesador Skynet (
debe admitir que es algo similar):
Disparo de la versión de director de la película "Terminator 2"Dada la tasa actual de mejora de los aceleradores de hardware de las redes neuronales profundas y el ejemplo anterior, esto es completamente real. Existe la posibilidad en pocos años de adquirir un chip con un rendimiento como el Pod TPU de hoy.
Por cierto, es curioso que en la película los fabricantes de chips (aparentemente, imaginando hacia dónde podría conducir la red de autoformación) desactivaron el reciclaje por defecto. Característicamente, el
T-800 en sí no podía habilitar el modo de entrenamiento y funcionaba en modo de inferencia (ver la
versión más larga del
director ). Además, su
procesador de red neuronal era avanzado y, al activar el reentrenamiento, podía usar los datos acumulados previamente para actualizar el modelo. Nada mal para 1991.
Este texto se inició en el caliente 13 millones de Shenzhen. Me senté en uno de los 27,000 taxis eléctricos de la ciudad y miré las 4 pantallas de cristal líquido del automóvil con gran interés. Uno pequeño, entre los dispositivos frente al conductor, dos, en el centro en el tablero y el último, translúcido, en el espejo retrovisor, combinado con un DVR, una cámara de video vigilancia y un Android a bordo (a juzgar por la línea superior con el nivel de carga y la comunicación con la red). Mostraba los datos del conductor (de quién quejarse, si es así), un pronóstico del tiempo fresco y parecía haber una conexión con la flota de taxis. El conductor no sabía inglés y no logró preguntarle sobre sus impresiones sobre la máquina eléctrica. Por lo tanto, presionó perezosamente el pedal, moviendo ligeramente el automóvil en un atasco. Y miré la ventana con una mirada futurista con interés: los chinos en sus chaquetas conducían desde el trabajo en scooters eléctricos y monowels ... y me preguntaba cómo se vería todo en 15 años ...
En realidad, hoy en día, el espejo retrovisor, que utiliza los datos de la cámara del DVR y la
aceleración de hardware de las redes neuronales , es capaz de controlar el automóvil en el tráfico y establecer la ruta. Por la tarde, al menos). Después de 15 años, el sistema claramente no solo podrá conducir un automóvil, sino que también estará encantado de proporcionarme las características de los vehículos eléctricos chinos nuevos. En ruso, naturalmente (como opción: inglés, chino ... albanés, finalmente). El conductor aquí es superfluo, mal entrenado, un enlace.
Señor!
EXTREMADAMENTE INTERESANTE ¡ 15 años nos esperan!
Estén atentos!
Vuelvo! )))
 UPD:
UPD: Los comentarios más interesantes:
Sobre cuantización y aceleración de cálculos en FPGA
Comentarios @Mirn
En FPGA, no solo se dispone de aritmética de precisión arbitraria, sino también de una gran capacidad para guardar y procesar datos de bits arbitrarios. Por ejemplo, hay demasiados coeficientes en el molesto MobileNetV2 W y B y puede cuantificarlos sin mucha pérdida de precisión a solo 16 bits, o tendrá que volver a entrenar. Pero si observa el interior y recopila estadísticas sobre canales y capas, puede ver que los 16 bits se usan solo a la entrada de los primeros coeficientes de 1000 W, el resto puntual tiene 8-11 bits, de los cuales solo 2-3 bits y signos más significativos son realmente importantes, y estadísticas sobre el uso de canales, de modo que hay muchos canales donde generalmente ceros, o valores pequeños, o canales donde casi todos los valores son 8-11 bits, es decir Es posible clavar al expositor en clavos en tiempo de compilación y no almacenarlo, es decir de hecho, es posible almacenar en la memoria ROM valores no de 16 bits sino de 4 bits, e incluso puede almacenar toda la red neuronal en FPGAs baratos sin mucha pérdida de precisión (menos del 1%), y también procesarla a velocidades de hasta decenas de miles de FPS con latencia de modo que obtengamos una respuesta de red neuronal de inmediato ¿Cómo termina la recepción de la trama?
Sobre la cuantización: mi idea es que si en varias etapas de la computación W los coeficientes para el canal No. 0 cambian solo de +50 a -50, entonces tiene sentido comprimir el bitness a 7, y si de -123 a +124 por ejemplo, entonces a 8 (incluido el signo ) FPGA , 7, 8 ROM . , .
(, , ), RTL , , . GCC AVX256 bitperfect ( FPGA ) FPS ( W B, ).
W fc , .. -100 +100 +10000 255 9 ( ).
! porque dephwise .
u-law ( ! ).
, , 6, , .
( ). — , FixedPoint dot product — Fractional part, — , , fc .
Acerca de la compilación óptima automática de modelos en GPU, FPGA, ASIC y otro hardwareComentario de @BigPack
- TVM ( tvm.ai/about), ( Keras) . , — «»- (bare metal, ISA, FPGA .) edge computing. TVM HLS TVM FPGA. HLS FPGA «» , ( ) FPGA , GPU/TPU .
PS FPGA transparent hardware ( — open-source hardware), , ( «» ) . -. , FPGA —
Sobre el anuncio de innovaciones en la arquitectura FPGA, el uso de Microsoft FPGA y la optimización automática de redes neuronalesGrandes comentarios @ Brak0delFPGA, 2019 , . — . / dsp-
Xilinx Achronix , DDR.
, , , FPGA ASIC-. FPGA : , ASIC , FPGA - . Es decir - . , ASIC-, , . , FPGA , ASIC.
, CPU, FPGA , , .
, GPU , FPGA , : , - , GPU , , , - ( , , , , FPGA , GPU ,
). , FPGA , , , ASIC-.
Microsoft (
Catapult v.2 ), FPGA-. , FPGA. () .
FPGA
Ristretto Deephi , , Deephi FPGA. , , , .
FPGA .
Acerca de la economía de desarrollo de FPGA versus ASICComentario de @Mirn
, FPGA :
, ASIC.
:
FPGA
( ), ( , , IP 30-50 5 ).
, 10 ( ), 5*(N+1)
, , — 10 , , 120*N
( , — )
: (120+50+5)*N, 5 880
ASIC
( 2 )
(3-4 )
ASIC « » — : ,
, ( ), , — , .
: — , , .
( MiT — , , , )
, , 10 3-5 , ( — , , — , — ) , : .
! ! . NEC SONY (c , 10-15 , )
: FPGA ASIC.
Agradecimientos:
- . .. ,
- , , ,
- , , ,
- , , , , , , , , , , , , !