Recuerde que Elastic Stack se basa en la base de datos no relacional Elasticsearch, la interfaz web de Kibana y los recopiladores de datos (el Logstash más famoso, varios Beats, APM y otros). Una de las buenas adiciones a toda la pila de productos enumerados es el análisis de datos utilizando algoritmos de aprendizaje automático. En el artículo, entendemos cuáles son estos algoritmos. Pedimos gato.
El aprendizaje automático es una función paga del shareware Elastic Stack y forma parte del X-Pack. Para comenzar a usarlo, es suficiente después de la activación para activar la prueba de 30 días. Después de que expire el período de prueba, puede solicitar asistencia para su extensión o comprar una suscripción. El costo de la suscripción se calcula no a partir de la cantidad de datos, sino a partir del número de nodos utilizados. No, la cantidad de datos afecta, por supuesto, la cantidad de nodos requeridos, pero aún así este enfoque de licencia es más humano en relación con el presupuesto de la compañía. Si no es necesario un alto rendimiento, puede ahorrar.
ML en Elastic Stack está escrito en C ++ y funciona fuera de la JVM, que ejecuta Elasticsearch. Es decir, el proceso (que, por cierto, se llama autodetección) consume todo lo que la JVM no se traga. En el stand de demostración, esto no es tan crítico, pero en un entorno productivo es importante resaltar nodos separados para tareas de ML.
Los algoritmos de aprendizaje automático se dividen en dos categorías:
con y
sin profesor . En Elastic Stack, el algoritmo es de la categoría "sin profesor".
Este enlace le permite ver el aparato matemático de los algoritmos de aprendizaje automático.
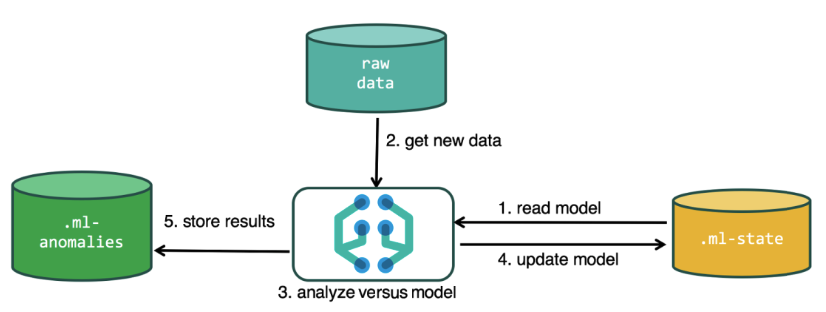
Para realizar el análisis, el algoritmo de aprendizaje automático utiliza los datos almacenados en los índices de Elasticsearch. Puede crear tareas para el análisis tanto desde la interfaz de Kibana como a través de la API. Si haces esto a través de Kibana, entonces algunas cosas no son necesarias para saber. Por ejemplo, índices adicionales que el algoritmo usa en el proceso.
Índices adicionales utilizados en el proceso de análisis..ml-state: información sobre modelos estadísticos (configuraciones de análisis);
.ml-anomalies- * - resultados del trabajo de algoritmos ML;
Notificaciones .ml: configuración de notificaciones basada en resultados de análisis.
La estructura de datos en la base de datos Elasticsearch consta de índices y documentos almacenados en ellos. Si se compara con una base de datos relacional, el índice se puede comparar con el esquema de la base de datos y un documento con una entrada en la tabla. Esta comparación es condicional y se proporciona para simplificar la comprensión de material adicional para aquellos que solo han escuchado sobre Elasticsearch.
La misma funcionalidad está disponible a través de la API como a través de la interfaz web, por lo que para mayor claridad y comprensión de los conceptos, le mostraremos cómo configurar a través de Kibana. Hay una sección de Machine Learning en el menú a la izquierda donde puede crear un nuevo trabajo. En la interfaz de Kibana, se ve como la imagen de abajo. Ahora analizaremos cada tipo de tarea y mostraremos los tipos de análisis que se pueden construir aquí.
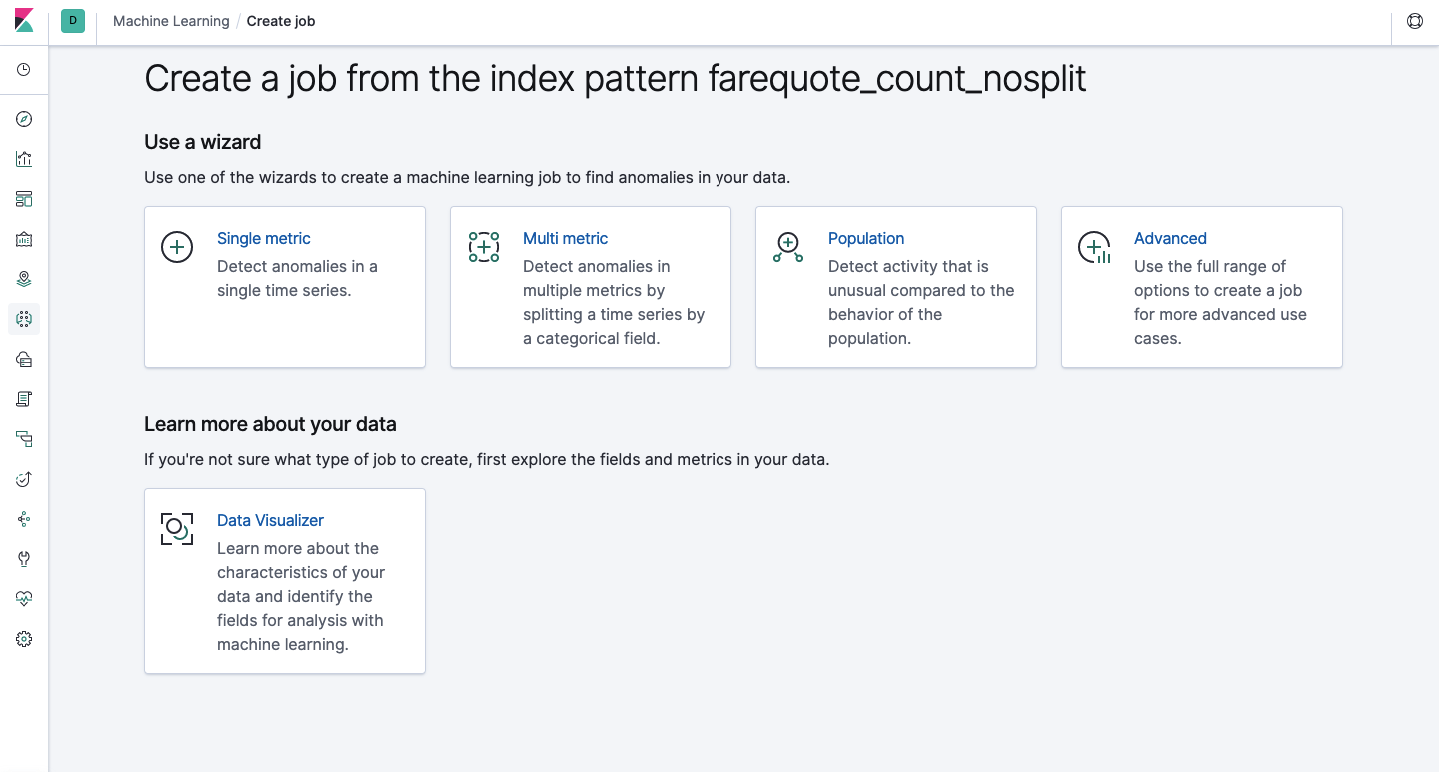
Métrica única: análisis de una métrica, métrica múltiple: análisis de dos o más métricas. En ambos casos, cada métrica se analiza en un entorno aislado, es decir, el algoritmo no tiene en cuenta el comportamiento de las métricas analizadas en paralelo, como podría parecer en el caso de la métrica múltiple. Para llevar a cabo el cálculo teniendo en cuenta la correlación de varias métricas, puede aplicar el análisis de población. Y Advanced es un ajuste de algoritmos con opciones adicionales para ciertas tareas.
Métrica individual
El análisis de los cambios en una sola métrica es lo más simple que puede hacer aquí. Después de hacer clic en Crear trabajo, el algoritmo buscará anomalías.
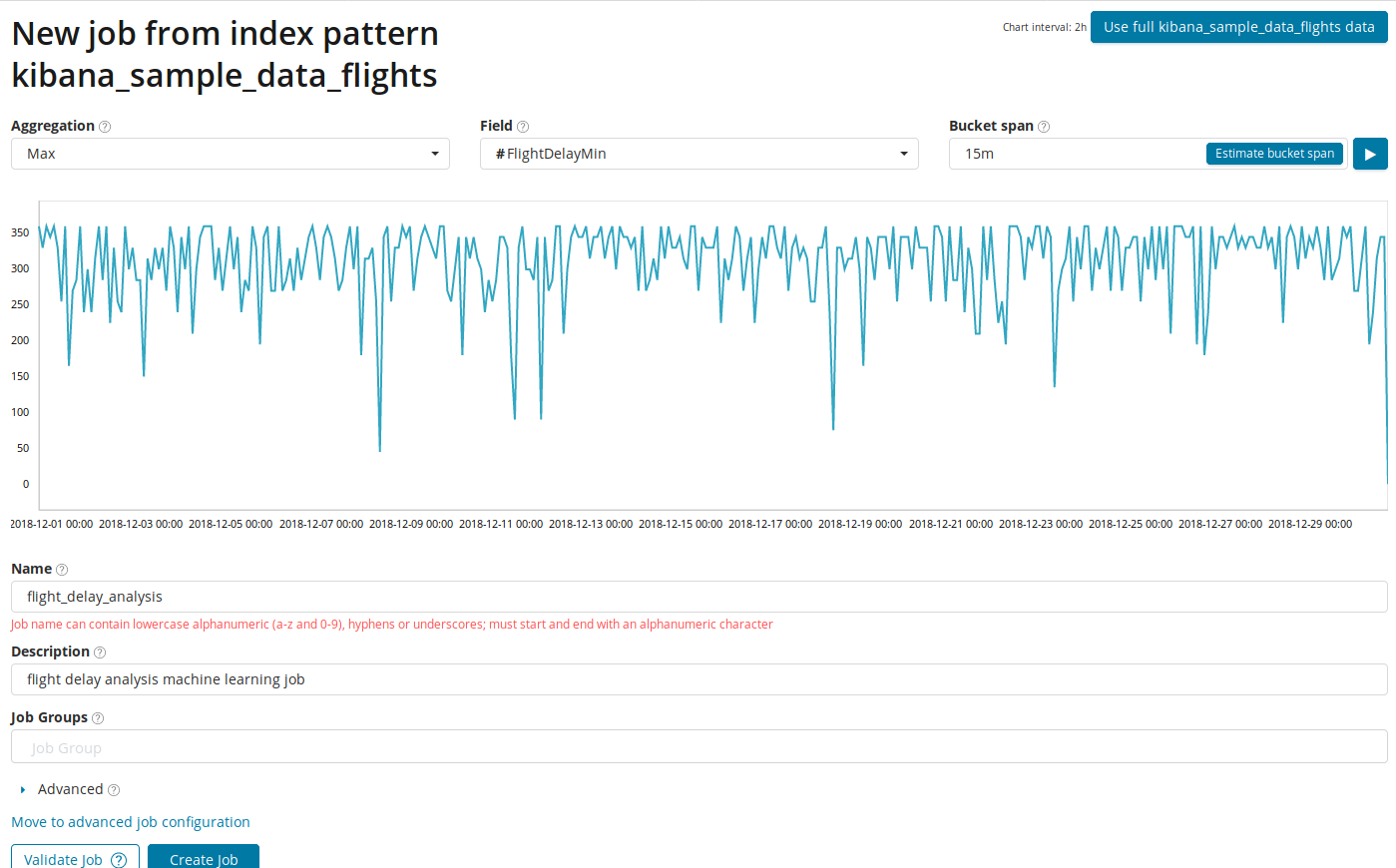
En el campo
Agregación , puede elegir un enfoque para buscar anomalías. Por ejemplo, con
Min, los valores anormales se considerarán inferiores a los típicos. Hay
Max, Hign Mean, Low, Mean, Distinct y otros. La descripción de todas las funciones se puede encontrar
aquí .
El campo Campo indica el campo numérico en el documento por el cual analizaremos.
En el campo
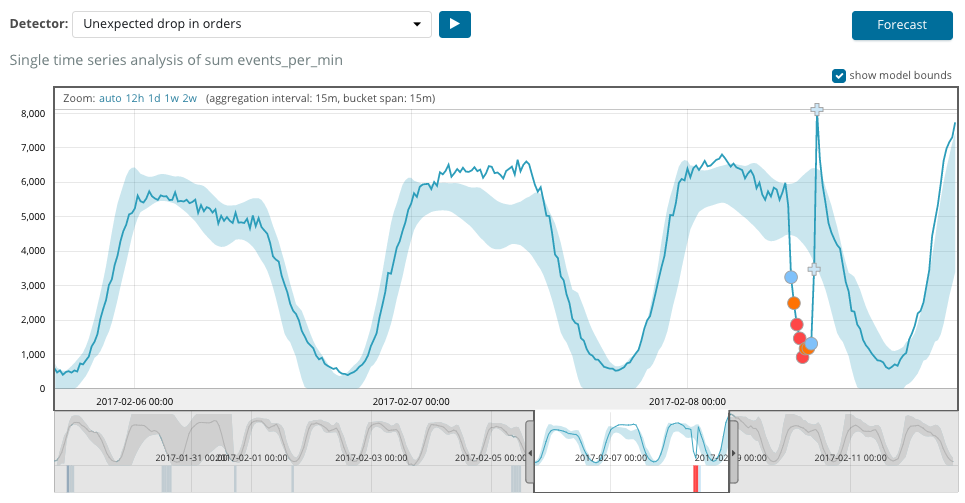
Bucket span , la granularidad de los intervalos en la línea de tiempo sobre la cual se realizará el análisis. Puede confiar en la automatización o elegir manualmente. La imagen a continuación muestra un ejemplo de granularidad demasiado baja: puede omitir la anomalía. Con esta configuración, puede cambiar la sensibilidad del algoritmo a las anomalías.

La duración de los datos recopilados es una cosa clave que afecta la efectividad del análisis. En el análisis, el algoritmo determina los intervalos de repetición, calcula el intervalo de confianza (líneas de base) e identifica anomalías, desviaciones atípicas del comportamiento habitual de la métrica. Solo por ejemplo:
Líneas de base con un pequeño rango de datos:
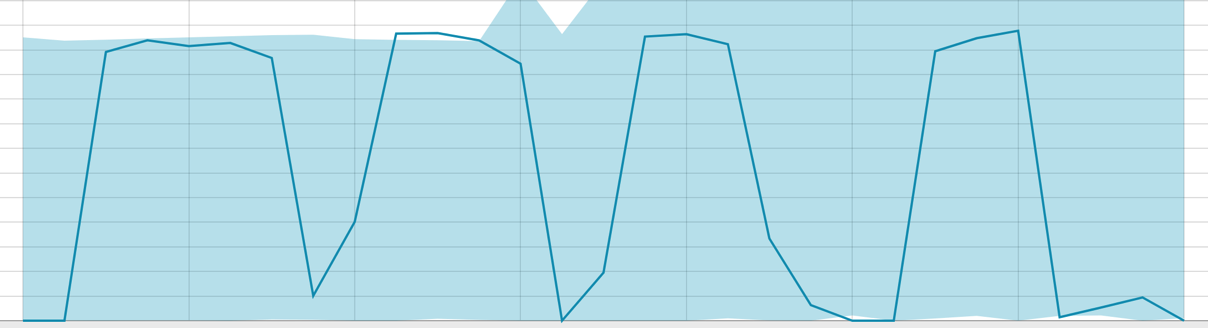
Cuando el algoritmo tiene algo que aprender, la línea de base se ve así:
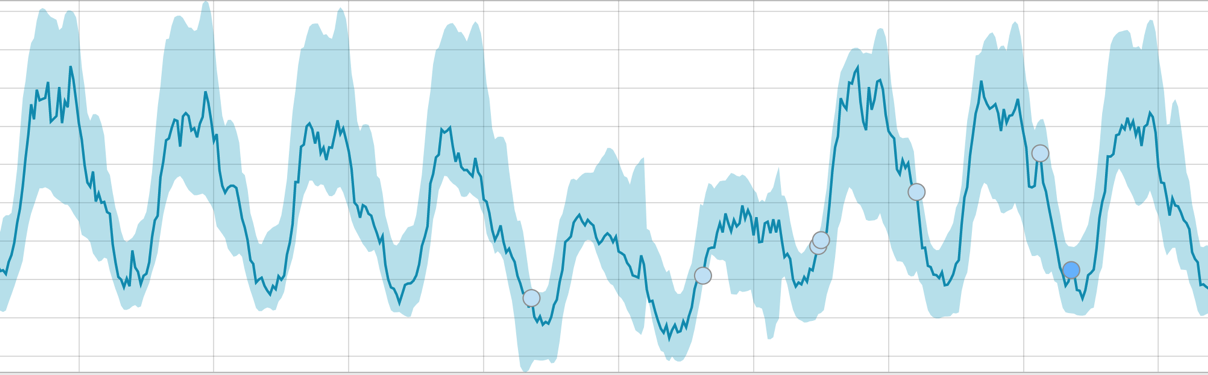
Después de comenzar la tarea, el algoritmo determina las desviaciones anómalas de la norma y las clasifica según la probabilidad de la anomalía (el color de la etiqueta correspondiente se indica entre paréntesis):
Advertencia (cian): menos de 25
Menor (amarillo): 25-50
Mayor (naranja): 50-75
Crítico (rojo): 75-100
El siguiente cuadro muestra un ejemplo de anomalías encontradas.
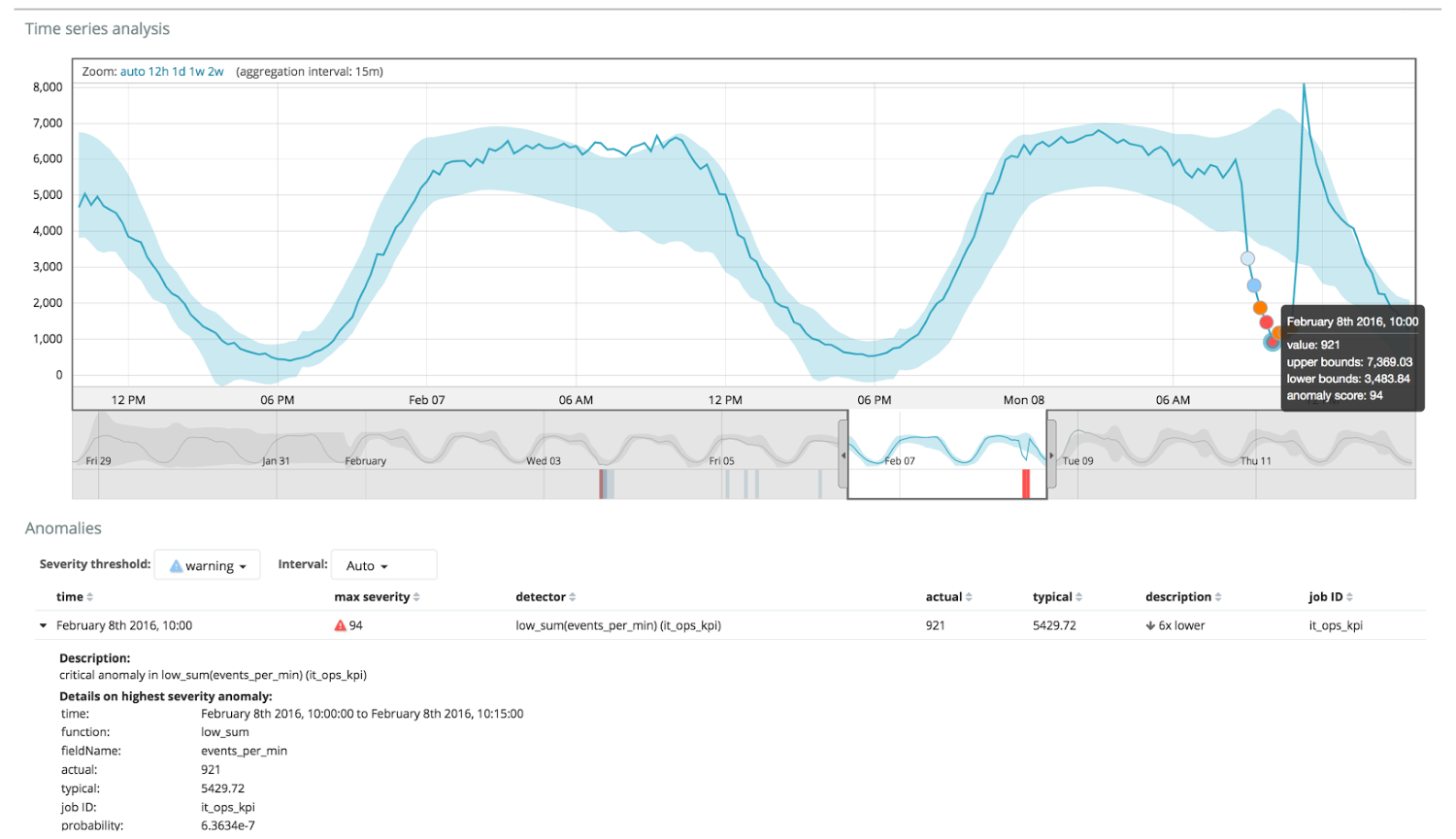
Aquí puede ver el número 94, que indica la probabilidad de una anomalía. Está claro que dado que el valor es cercano a 100, significa una anomalía. La columna debajo del gráfico muestra una probabilidad despectiva de 0.000063634% de la aparición del valor métrico allí.
Además de buscar anomalías en Kibana, puede ejecutar pronósticos. Esto se hace de manera elemental y desde la misma vista con anomalías: el botón
Pronóstico en la esquina superior derecha.

El pronóstico se basa en un máximo de 8 semanas de anticipación. Incluso si realmente quieres, ya no puedes por diseño.
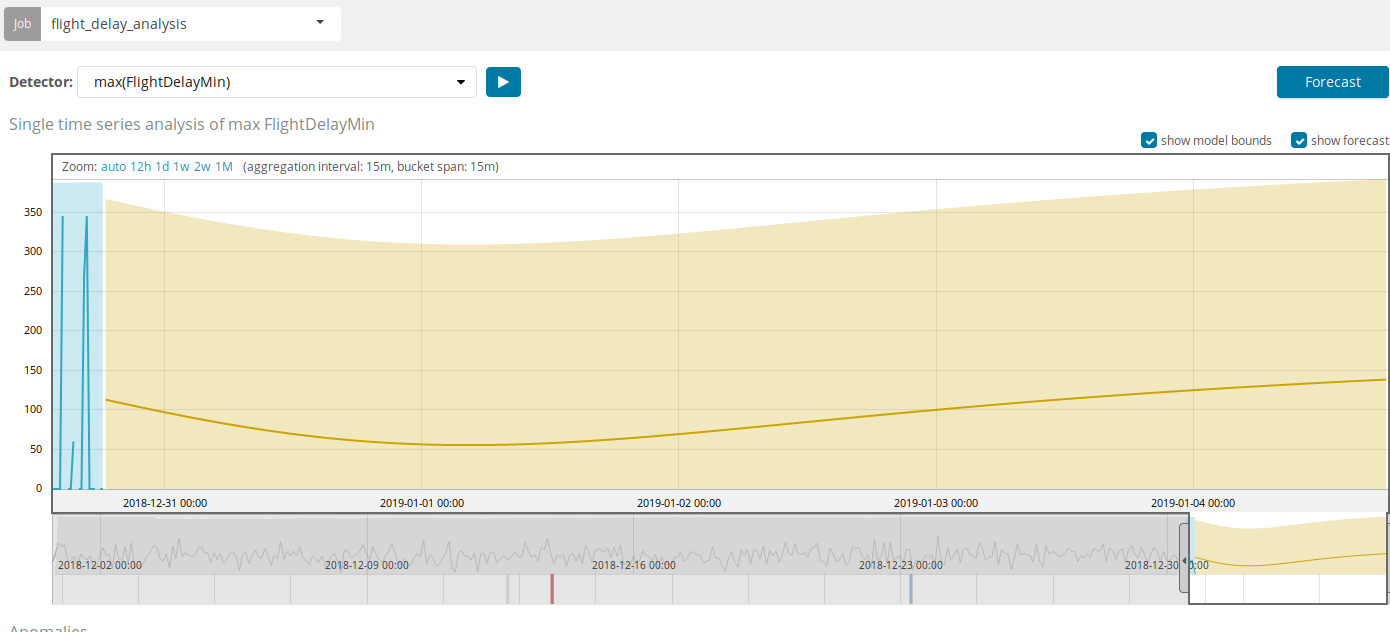
En algunas situaciones, el pronóstico será muy útil, por ejemplo, cuando se supervisa la carga del usuario en la infraestructura.
Multi métrica
Pasamos a la siguiente característica de ML en Elastic Stack: análisis de varias métricas en un paquete. Pero esto no significa que se analizará la dependencia de una métrica de otra. Esto es lo mismo que Single Metric con solo muchas métricas en una pantalla para una fácil comparación de los efectos de una en la otra. Hablaremos sobre el análisis de la dependencia de una métrica de otra en la parte de Población.
Después de hacer clic en el cuadrado con Multi Metric, aparecerá una ventana de configuración. Nos detendremos en ellos con más detalle.
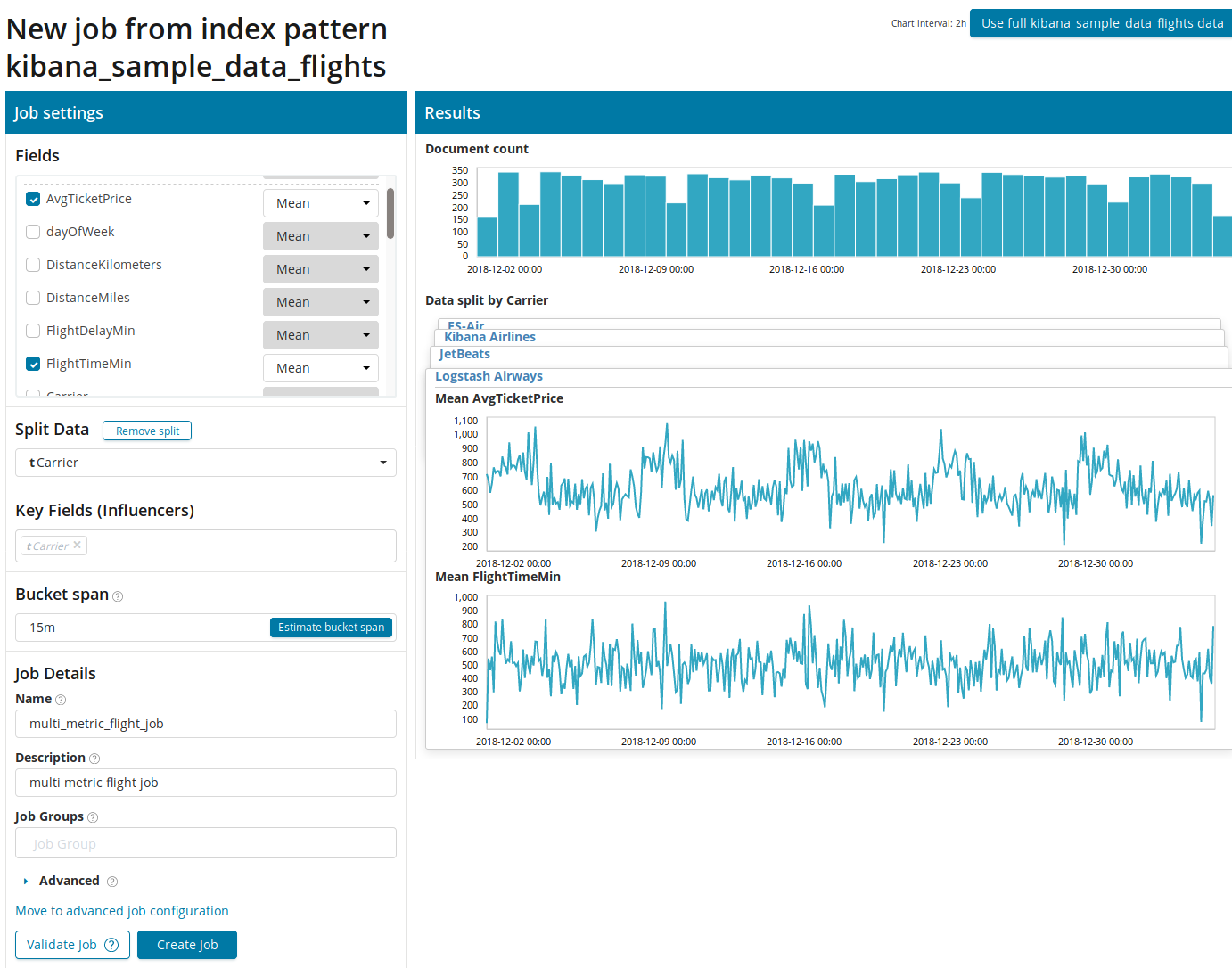
Primero debe seleccionar los campos para el análisis y la agregación de datos sobre ellos. Las opciones de agregación aquí son las mismas que para Métrica simple (
Máx., Media de Hign, Baja, Media, Distinta y otras). Además, los datos se dividen opcionalmente en uno de los campos (campo
Dividir datos ). En el ejemplo, hicimos esto usando el campo
OriginAirportID . Tenga en cuenta que el gráfico de métricas de la derecha ahora se presenta como varios gráficos.
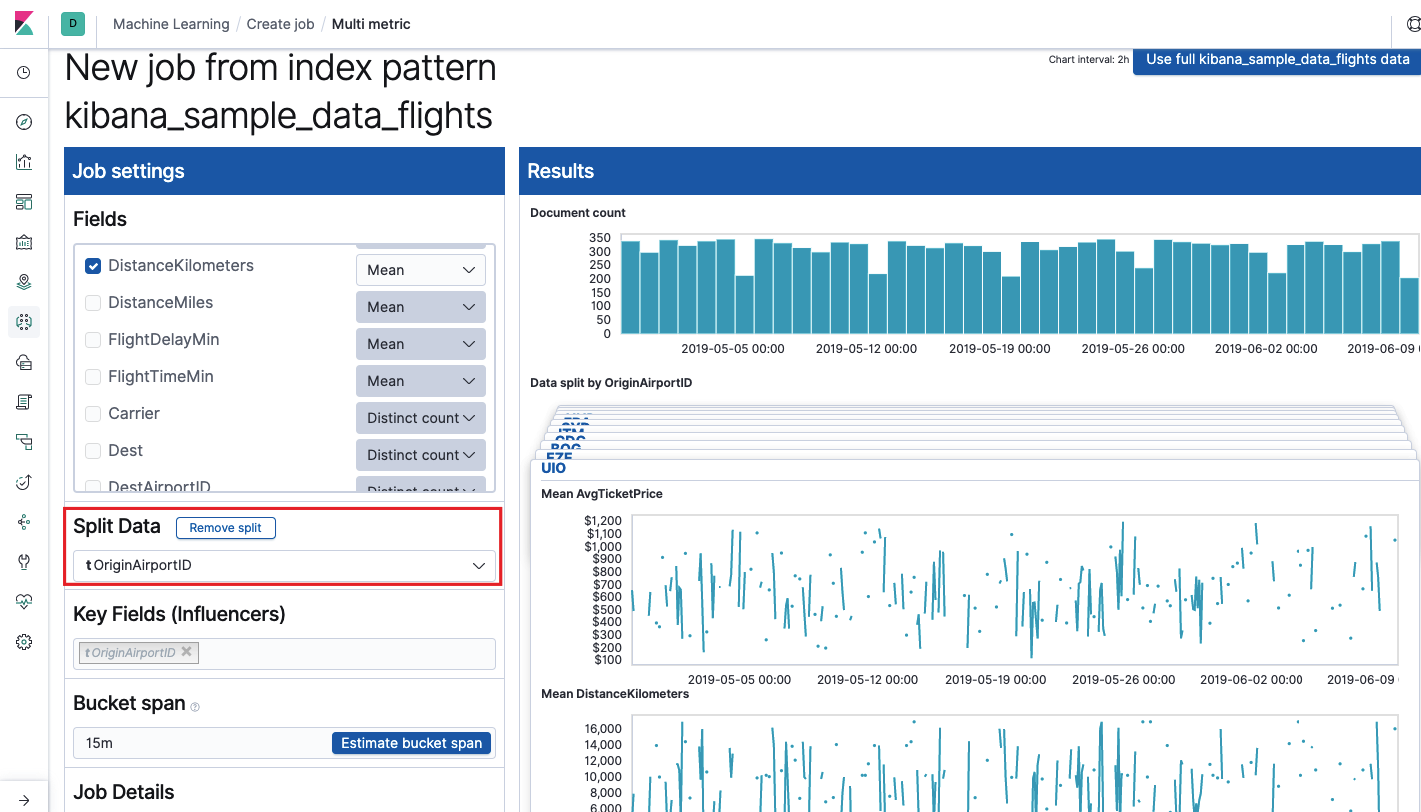
El campo
Campos clave (influenciadores) afecta directamente las anomalías encontradas. Por defecto, siempre habrá al menos un valor, y puede agregar otros. El algoritmo tendrá en cuenta la influencia de estos campos en el análisis y mostrará los valores más "influyentes".
Después del lanzamiento, la interfaz de Kibana mostrará algo como esto.
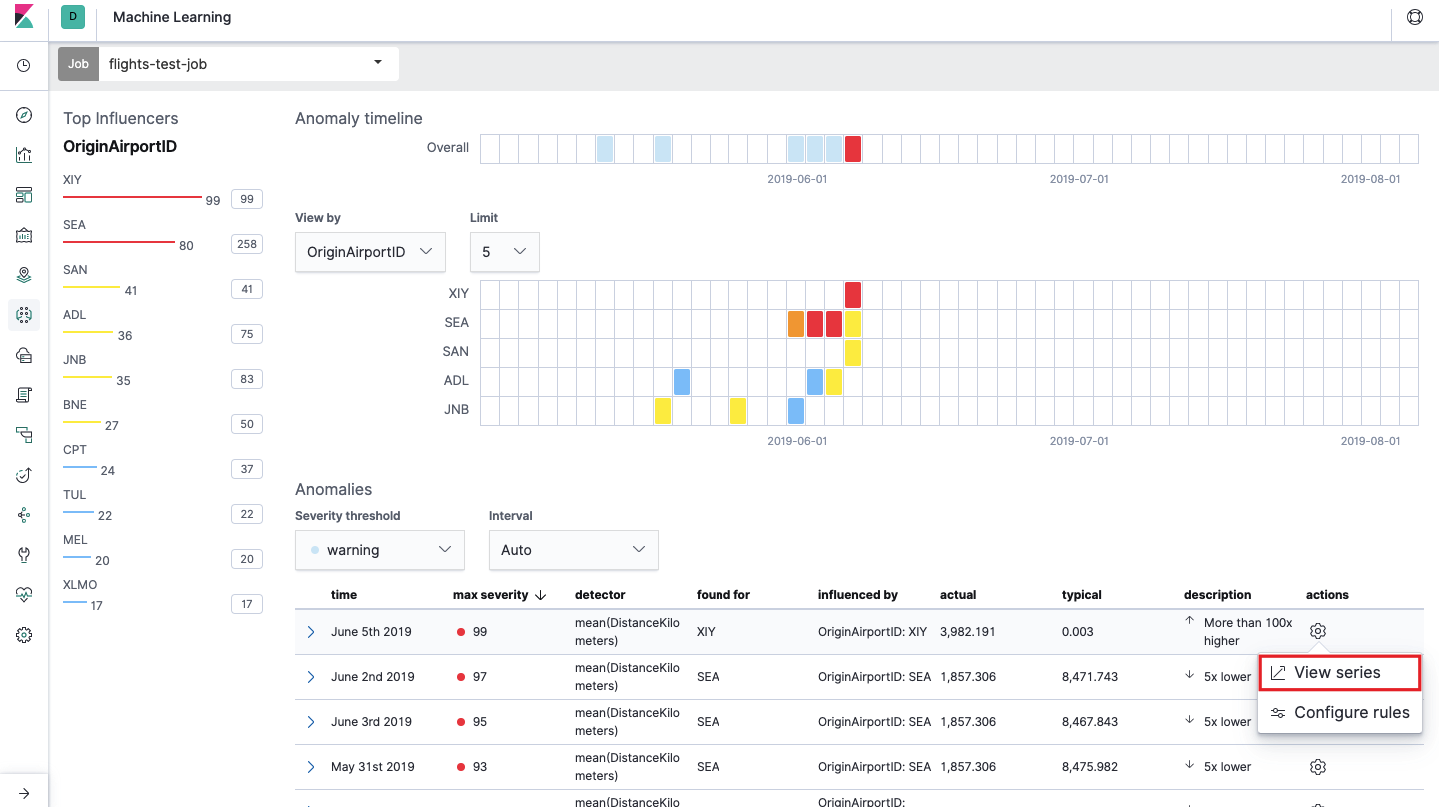
Este es el llamado mapa de calor de anomalías para cada valor del campo
OriginAirportID que especificamos en los
datos divididos . Al igual que con Single Metric, el color indica el nivel de desviación anormal. Es conveniente hacer un análisis similar, por ejemplo, en estaciones de trabajo para rastrear aquellas donde hay muchas autorizaciones sospechosas, etc. Ya escribimos
sobre eventos sospechosos en EventLog Windows , que también se pueden recopilar y analizar aquí.
Debajo del mapa de calor hay una lista de anomalías, desde cada una de ellas puede ir a la vista Métrica única para un análisis detallado.
Población
Para buscar anomalías entre las correlaciones entre diferentes métricas, Elastic Stack tiene un análisis de población especializado. Con la ayuda de este, puede buscar valores anómalos en el rendimiento de un servidor en comparación con otros con, por ejemplo, un aumento en el número de solicitudes al sistema de destino.
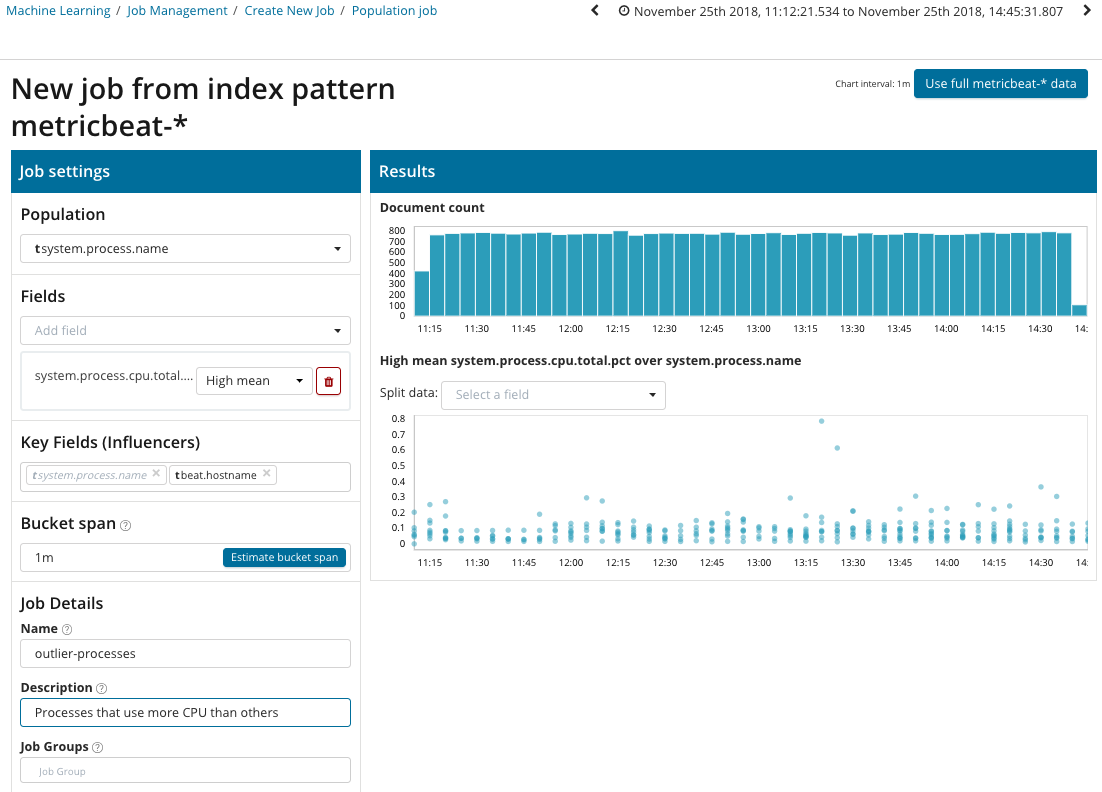
En esta ilustración, el campo Población indica el valor con el que se relacionarán las métricas analizadas. Este es el nombre del proceso. Como resultado, veremos cómo la carga del procesador por cada uno de los procesos se influyó mutuamente.
Tenga en cuenta que el gráfico de los datos analizados es diferente de los casos con Single Metric y Multi Metric. Esto se hace en Kibana por diseño para una mejor percepción de la distribución de valores de los datos analizados.

El gráfico muestra que el proceso de
estrés (por cierto, generado por una utilidad especial) en el servidor
poipu se comportó de manera anormal , lo que afectó (o resultó ser un
factor de influencia) la aparición de esta anomalía.
Avanzado
Análisis afinado. Con el Análisis avanzado, aparecen configuraciones adicionales en Kibana. Después de hacer clic en el menú Crear en el mosaico Avanzado, aparece una ventana con pestañas. La pestaña
Detalles del trabajo se omitió deliberadamente, allí la configuración básica no está directamente relacionada con la configuración del análisis.
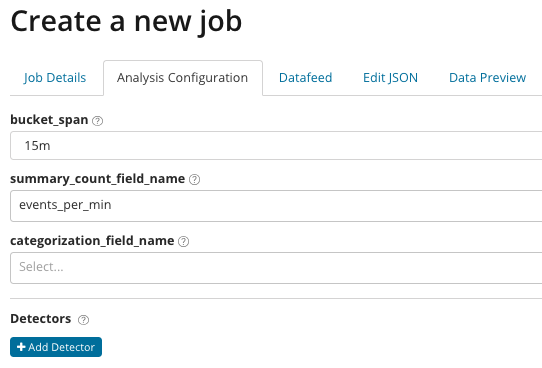
En
summary_count_field_name, puede especificar opcionalmente el nombre del campo a partir de documentos que contienen valores agregados. En este ejemplo, el número de eventos por minuto.
Categorization_field_name indica el nombre del valor del campo del documento, que contiene algún tipo de valor variable. Por máscara en este campo, puede dividir los datos analizados en subconjuntos. Preste atención al botón
Agregar detector en la ilustración anterior. A continuación se muestra el resultado de hacer clic en este botón.

Aquí hay un bloque de configuración adicional para configurar el detector de anomalías para una tarea específica. Planeamos analizar casos de uso específicos (especialmente por seguridad) en los siguientes artículos. Por ejemplo,
mire uno de los casos desmontados. Se asocia con la búsqueda de valores que rara vez aparecen y se implementa
mediante la función rara .
En el campo de
función , puede seleccionar una función específica para buscar anomalías. Además de
raro , hay un par de funciones interesantes:
time_of_day y time_of_week . Identifican anomalías en el comportamiento de las métricas a lo largo del día o la semana, respectivamente. El resto de las funciones de análisis
están en la documentación .
Field_name indica el campo del documento que se analizará.
By_field_name se puede usar para separar los resultados del análisis para cada valor individual del campo del documento especificado aquí. Si completa
over_field_name obtendrá el análisis de población, que examinamos anteriormente. Si especifica un valor en
division_field_name , en este campo del documento se calcularán líneas de base individuales para cada valor (por ejemplo, el nombre del servidor o el proceso en el servidor pueden desempeñar el papel del valor). En
exclude_frequent, puede seleccionar
todo o
ninguno , lo que significará la exclusión (o inclusión) de los valores de campo de documento que se encuentran con frecuencia.
En el artículo tratamos de dar la idea más concisa sobre las posibilidades de aprendizaje automático en Elastic Stack, todavía hay muchos detalles detrás de escena. Díganos en los comentarios qué casos logró resolver con la ayuda de Elastic Stack y para qué tareas lo utiliza. Para contactarnos, puede usar mensajes personales en Habré o el
formulario de comentarios en el sitio .