Les traigo a su atención una traducción del informe de Alexander Kuzmenko (desde abril de este año trabaja oficialmente como desarrollador del compilador Haxe) sobre los cambios en el lenguaje Haxe que se han producido desde el lanzamiento de Haxe 3.4.

Han pasado más de dos años y medio desde el lanzamiento de Haxe 3.4. Durante este tiempo, se lanzaron 7 lanzamientos de parches, 5 lanzamientos preliminares de Haxe 4 y 2 candidatos de lanzamiento de Haxe 4. Era un largo camino hacia la nueva versión y está casi listo (quedan unos 20 problemas por resolver).

Alexander agradeció a la comunidad Haxe por informar de errores, por su deseo de participar en el desarrollo del lenguaje. Gracias al proyecto haxe-evolution , cosas como las siguientes aparecerán en Haxe 4:
- marcado en línea
- funciones en línea en la ubicación de la llamada
- funciones de flecha

Además, en el marco de este proyecto, se están celebrando debates sobre posibles innovaciones tales como: promesas , esto polimórfico y tipos predeterminados (parámetros de tipo predeterminados).
Luego, Alexander habló sobre los cambios en la sintaxis del lenguaje .

La primera es la nueva sintaxis para describir la sintaxis de los tipos de función. La vieja sintaxis era un poco extraña.
Haxe es un lenguaje de programación multi-paradigmático, siempre tuvo soporte para funciones de primera clase, pero la sintaxis para describir los tipos de funciones fue heredada de un lenguaje funcional (y difiere del adoptado en otros paradigmas). Y los programadores familiarizados con la programación funcional esperan que las funciones con esta sintaxis admitan el curry automático. Pero en Haxe esto no es así.
El principal inconveniente de la sintaxis anterior, según Alexander, es la incapacidad para determinar los nombres de los argumentos, por lo que debe escribir comentarios de anotación largos con una descripción de los argumentos.
Pero ahora tenemos una nueva sintaxis para describir los tipos de función (que, por cierto, se agregó al lenguaje como parte de la iniciativa haxe-evolution), donde existe esa oportunidad (aunque esto es opcional, pero recomendado). La nueva sintaxis es más fácil de leer e incluso puede considerarse parte de la documentación del código.
Otro inconveniente de la sintaxis anterior para describir los tipos de función era su inconsistencia: la necesidad de especificar el tipo de argumentos de la función incluso cuando la función no acepta ningún argumento: Void->Void (esta función no toma argumentos y no devuelve nada).
En la nueva sintaxis, esto se implementa con más elegancia: ()->Void

El segundo es funciones de flecha o expresiones lambda, una forma corta para describir funciones anónimas. La comunidad ha estado pidiendo durante mucho tiempo agregarlos al idioma, ¡y finalmente sucedió!
En tales funciones, en lugar de la palabra clave return , -> la secuencia de caracteres -> (de ahí que el nombre de sintaxis sea "función de flecha").
En la nueva sintaxis, sigue siendo posible establecer los tipos de argumentos (ya que el sistema automático de inferencia de tipos no siempre puede hacerlo de la manera que el programador quiere, por ejemplo, el compilador puede decidir usar Float lugar de Int ).
La única limitación de la nueva sintaxis es la incapacidad de establecer explícitamente el tipo de retorno. Si es necesario, tiene la opción de usar la sintaxis anterior o la sintaxis de tipo de verificación en el cuerpo de la función, que le indicará al compilador el tipo de retorno.

Las funciones de flecha no tienen una representación especial en el árbol de sintaxis; se procesan de la misma manera que las funciones anónimas normales. La secuencia -> se reemplaza por la palabra clave return .

El tercer cambio: final ahora se final convertido en una palabra clave (en Haxe 3 final fue una de las metaetiquetas integradas en el compilador).
Si lo aplica a una clase, prohibirá su herencia, lo mismo se aplica a las interfaces. Aplicar el calificador final a un método de clase evitará que se anule en las clases secundarias.
Sin embargo, en Haxe, había una manera de sortear las restricciones impuestas por la palabra clave final : puede usar la metaetiqueta @:hack para esto (pero solo debe hacerlo si es absolutamente necesario).
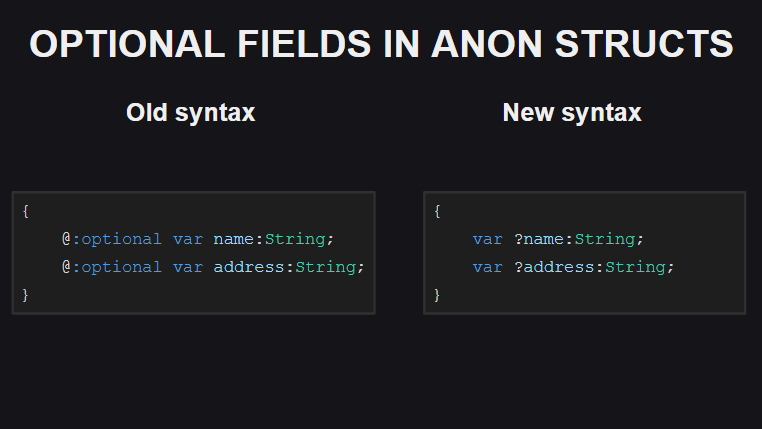
El cuarto cambio es una forma de declarar campos opcionales en estructuras anónimas. Anteriormente, se usaba la metaetiqueta @:optional para esto, ahora solo agregue un signo de interrogación delante del nombre del campo.

Quinto, las enumeraciones abstractas se han convertido en un miembro completo de la familia de tipos Haxe, y en lugar de la metaetiqueta @:enum palabra clave @:enum ahora se usa para declararlas.
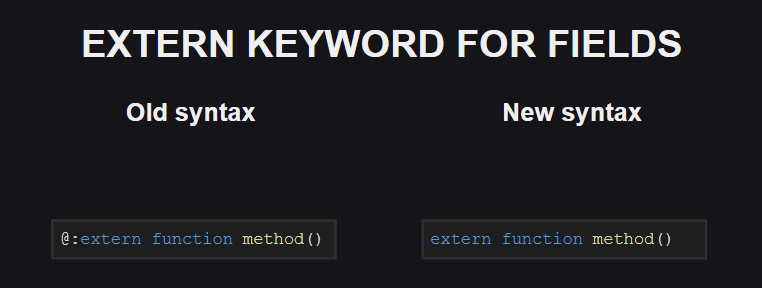
Un cambio similar afectó a la metaetiqueta @:extern .

El séptimo es un nuevo tipo de sintaxis de intersección que refleja mejor la esencia de las estructuras en expansión.
La misma sintaxis nueva se usa para limitar las restricciones de los parámetros de tipo; transmite con mayor precisión las restricciones impuestas a un tipo. Para una persona que no está familiarizada con Haxe, la sintaxis anterior MyClass<T:(Type1, Type2)> podría percibirse como un requisito para que el tipo del parámetro T sea Type1 o Type2 . La nueva sintaxis nos dice explícitamente que T debe ser Type1 y Type2 al mismo tiempo.
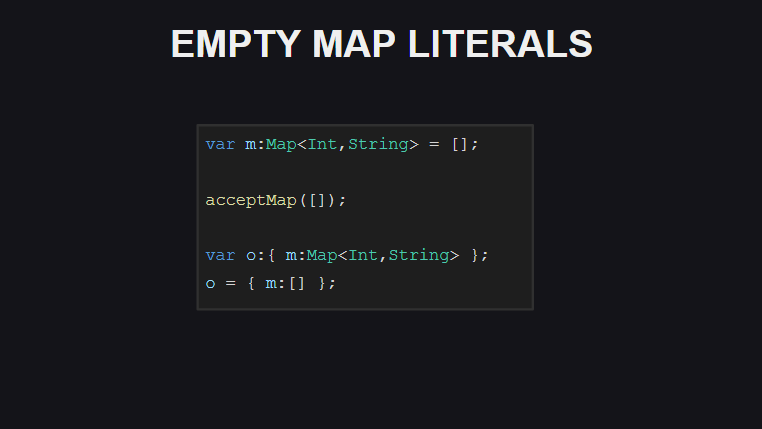
La octava es la capacidad de usar [] para declarar un contenedor Map vacío (sin embargo, si no especifica explícitamente el tipo de la variable, el compilador generará el tipo como una matriz para este caso).
Habiendo hablado sobre los cambios en la sintaxis, pasemos a la descripción de nuevas funciones en el lenguaje .
Comencemos con los nuevos iteradores clave-valor
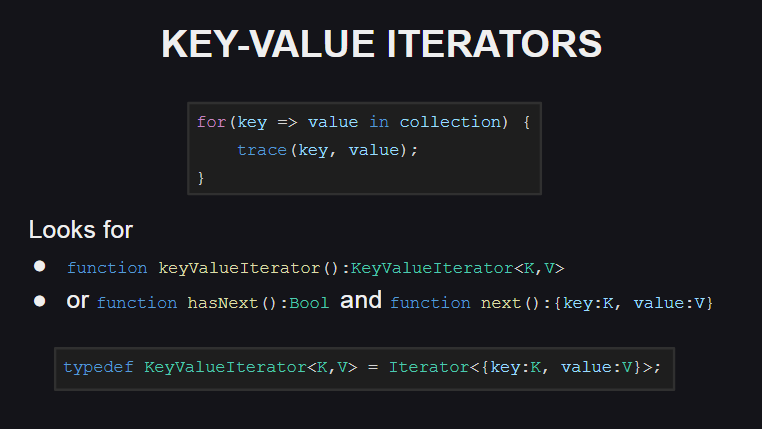
Se ha agregado una nueva sintaxis para su uso.
Para admitir dichos iteradores, el tipo debe implementar el método keyValueIterator():KeyValueIterator<K, V> o los métodos hasNext():Bool y next():{key:K, value:V} . Al mismo tiempo, el tipo KeyValueIterator<K, V> es sinónimo de un iterador regular en la estructura anónima Iterator<{key:K, value:V}> .
Los iteradores de valores clave se implementan para algunos tipos de la biblioteca estándar de Haxe ( String , Map , DynamicAccess ), y también se está trabajando para implementarlos en matrices.
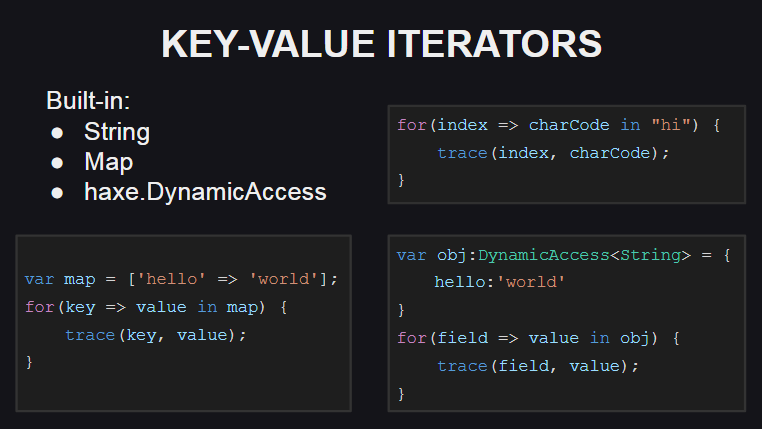
Para las cadenas, el índice de caracteres en la cadena se usa como la clave, y el código de caracteres en el índice dado se usa como el valor (si se necesita el propio carácter, se puede usar el método String.fromCharCode() ).
Para el contenedor Map , el nuevo iterador funciona igual que el método de iteración anterior, es decir, recibe una matriz de claves en el contenedor y lo atraviesa, solicitando valores para cada una de las claves.
Para DynamicAccess (un contenedor para objetos anónimos), el iterador funciona usando la reflexión (para obtener una lista de campos de un objeto usando el método Reflect.fields() y para obtener valores de campo por sus nombres usando el método Reflect.field() ).

Haxe 4 usa un intérprete de macros completamente nuevo, "eval". Simon Krajewski, el autor del intérprete, lo describió con cierto detalle en el blog oficial de Haxe , así como en su informe de progreso del año pasado .
Los principales cambios en el trabajo del intérprete:
- es varias veces más rápido que el antiguo intérprete de macros (4 veces en promedio)
- admite depuración interactiva (anteriormente, para macros, solo se podía usar la salida de la consola)
- se usa para ejecutar el compilador en modo intérprete (anteriormente se usaba neko para esto. Por cierto, eval también supera a neko en velocidad).

El soporte Unicode para todas las plataformas (con la excepción de neko) es uno de los mayores cambios en Haxe 4. Simon habló sobre esto en detalle el año pasado . Pero aquí hay una breve descripción del estado actual del soporte de cadenas Unicode en Haxe:
- para Lua, PHP, Python y eval (intérprete de macros) se implementa soporte completo Unicode (codificación UTF8)
- Para otras plataformas (JavaScript, C #, Java, Flash, HashLink y C ++), se utiliza la codificación UTF16.
Por lo tanto, las líneas en Haxe funcionan de la misma manera para los caracteres incluidos en el plano multilingüe principal , pero para los caracteres fuera de este plano (por ejemplo, para emoji), el código para trabajar con líneas puede producir diferentes resultados dependiendo de la plataforma (pero esto es aún mejor, que la situación que tenemos en Haxe 3, cuando cada plataforma tenía su propio comportamiento).

Para cadenas codificadas en Unicode (tanto en UTF8 como en UTF16), se han agregado iteradores especiales a la biblioteca estándar de Haxe que funcionan igualmente en TODAS las plataformas para todos los caracteres (tanto dentro del plano multilingüe principal como más allá):
haxe.iterators.StringIteratorUnicode haxe.iterators.StringKeyValueIteratorUnicode

Debido al hecho de que la implementación de cadenas varía de una plataforma a otra, es necesario tener en cuenta algunos de los matices de su trabajo. En UTF16, cada carácter toma 2 bytes, por lo que acceder a un carácter en una cadena por índice es rápido, pero solo dentro del plano multilingüe principal. Por otro lado, en UTF8 todos los caracteres son compatibles, pero esto se logra a costa de una búsqueda lenta de un carácter en una cadena (dado que los caracteres pueden ocupar diferentes números de bytes en la memoria, acceder a un carácter por índice requiere iterar a través de la línea cada vez desde el principio). Por lo tanto, cuando trabaje con cadenas grandes en Lua y PHP, debe tener en cuenta que el acceso a un carácter arbitrario funciona bastante lento (también en estas plataformas, la longitud de la cadena se calcula nuevamente cada vez).
Sin embargo, aunque se declara el soporte completo de Unicode para Python, esta restricción no se aplica porque las líneas se implementan de una manera ligeramente diferente: para los caracteres dentro del plano multilingüe principal, utiliza la codificación UTF16 y para caracteres más anchos (3 y más bytes) Python usa UTF32.
Se implementan optimizaciones adicionales para el intérprete de macros eval: la cadena "sabe" si contiene caracteres Unicode. En el caso de que no contenga tales caracteres, la cadena se interpreta como compuesta por caracteres ASCII (donde cada carácter toma 1 byte). El acceso secuencial por índice en eval también está optimizado: la posición del último carácter al que se accede se almacena en caché en la línea. Entonces, si primero pasa al décimo carácter de la cadena, luego, cuando vuelva al próximo vigésimo carácter, eval lo buscará no desde el comienzo de la línea, sino a partir del décimo. Además, la longitud de la cadena en eval se almacena en caché, es decir, se calcula solo en la primera solicitud.
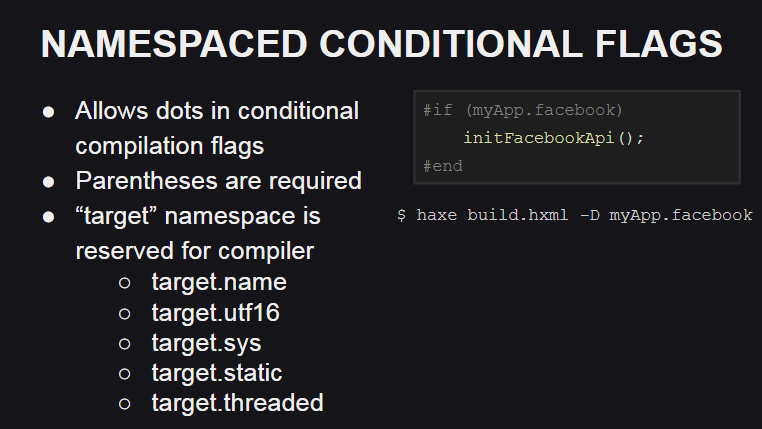
Haxe 4 presenta soporte para espacios de nombres para indicadores de compilación, que pueden ser útiles, por ejemplo, para organizar código al escribir bibliotecas personalizadas.
Además, apareció un espacio de nombres reservado para los indicadores de compilación: target , que el compilador utiliza para describir la plataforma de destino y su comportamiento:
target.name : nombre de la plataforma (js, cpp, php, etc.)target.utf16 : dice que el soporte Unicode se implementa usando UTF16target.sys : indica si las clases del paquete sys están disponibles (por ejemplo, para trabajar con el sistema de archivos)target.static : indica si la plataforma es estática (en plataformas estáticas, los tipos base Int , Float y Bool no pueden tener un valor null )target.threaded : indica si la plataforma admite subprocesos target.threaded
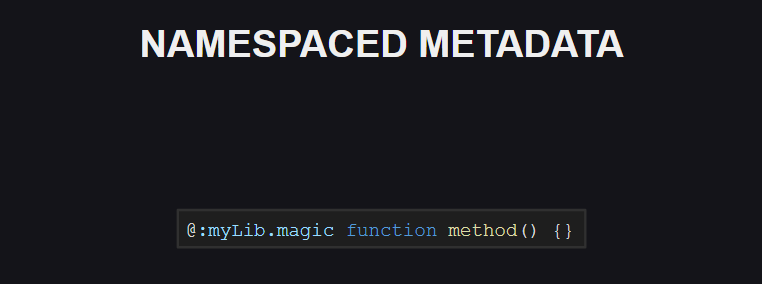
Del mismo modo, ha aparecido el espacio de nombres para metaetiquetas. Hasta ahora no hay espacios de nombres reservados para metaetiquetas en el idioma, pero la situación puede cambiar en el futuro.

El tipo ReadOnlyArray agrega a la biblioteca estándar de Haxe, una abstracción sobre una matriz regular, en la que los métodos solo están disponibles para leer datos de la matriz.

Otra innovación en el lenguaje son los campos finales y las variables locales.
Si final usa final lugar de la palabra clave var al declarar un campo de clase o una variable local, esto significará que el campo o la variable dados no se pueden reasignar (si el compilador intenta hacer esto, arrojará un error). Pero al mismo tiempo, su estado se puede cambiar, por lo que el campo o variable final no es una constante.
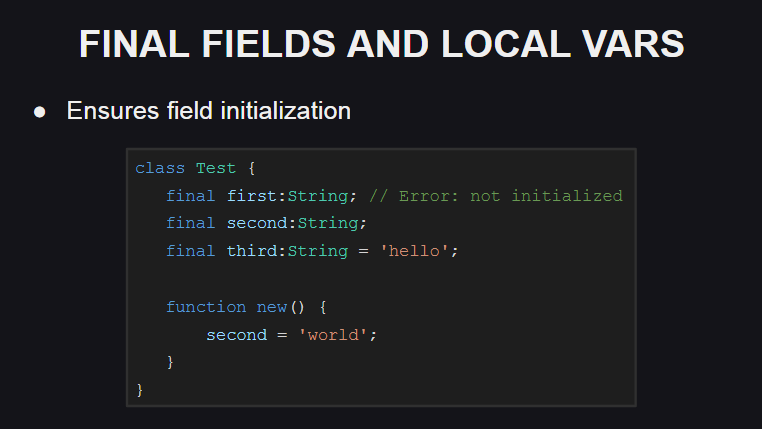
Los valores de los campos finales deben inicializarse cuando se declaran o en el constructor, de lo contrario, el compilador arrojará un error.

HashLink es una nueva plataforma con su propia máquina virtual, creada específicamente para Haxe. HashLink admite la llamada "compilación dual": el código se puede compilar en bytecode (que es muy rápido, acelera el proceso de depuración de las aplicaciones desarrolladas) o en código C (que se caracteriza por un mayor rendimiento). Nicholas dedicó HashLink a varias publicaciones en el blog de Haxe y también habló sobre él en la conferencia de Seattle del año pasado . La tecnología HashLink se usa en juegos populares como Dead Cells y Northgard.

Otra nueva característica interesante de Haxe 4 es la seguridad nula, que aún se encuentra en la etapa experimental (debido a falsos positivos y controles de seguridad de código insuficientes).
¿Qué es la seguridad nula? Si su función no declara explícitamente que puede aceptar valores null como valores de parámetros, cuando intente pasarle valores null , el compilador arrojará el error correspondiente. Además, para los parámetros de función que pueden tomar null como valor, el compilador requerirá que escriba código adicional para verificar y manejar tales casos.
Esta funcionalidad está deshabilitada de manera predeterminada, pero no afecta la velocidad de ejecución del código (si lo habilita, sin embargo), ya que las comprobaciones descritas se realizan solo en la etapa de compilación. Se puede habilitar para todo el código, así como gradualmente para campos, clases y paquetes individuales (lo que proporciona una transición gradual a un código más seguro). Puede usar metaetiquetas y macros especiales para esto.
Los modos en los que puede funcionar la seguridad nula son: Strict (el más estricto), Loose (el modo predeterminado) y Off (utilizado para deshabilitar las comprobaciones de paquetes y tipos individuales).

Para la función que se muestra en la diapositiva, la comprobación de seguridad nula está habilitada. Vemos que esta función tiene un parámetro opcional s , es decir, podemos pasar null como un valor de parámetro. Al intentar compilar código con dicha función, el compilador producirá una serie de errores:
- al intentar acceder a algún campo del objeto
s (ya que puede ser null ) - al intentar asignar una variable str, que, como vemos, no debería ser
null (de lo contrario, deberíamos haberla declarado no como String , sino como Null<String> ) - al intentar devolver un objeto
s de una función (ya que la función no debe devolver null )
¿Cómo arreglar estos errores?
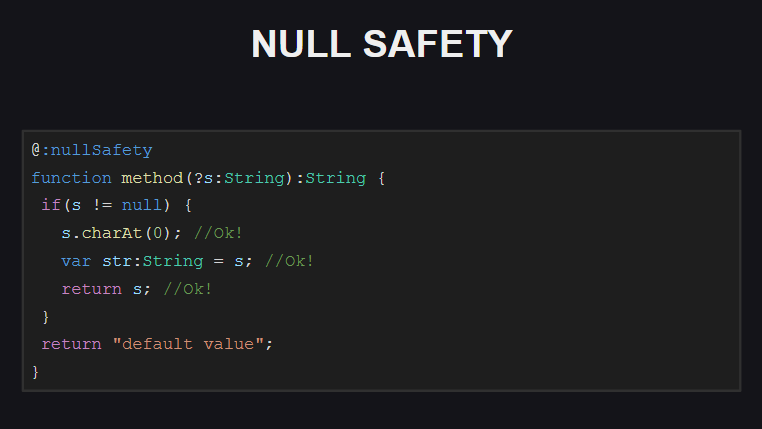
Solo necesitamos agregar una verificación null al código (dentro del bloque con verificación null , el compilador "sabe" que s no puede ser null y puede usarse con seguridad con él), ¡y también asegurarse de que la función no devuelva null !

Además, al realizar comprobaciones de seguridad nula, el compilador tiene en cuenta el orden en que se ejecutan los programas. Por ejemplo, si después de verificar el valor del parámetro s como nulo para terminar la función (o lanzar una excepción), el compilador "sabrá" que después de tal verificación, el parámetro s ya no puede ser null , y que puede usarse de manera segura.

Si el compilador habilita el modo estricto de comprobaciones para la seguridad nula, requerirá comprobaciones adicionales para null en los casos en que entre la comprobación inicial del valor null y un intento de acceder al campo del objeto se ejecutó cualquier código que pudiera establecerlo como null .
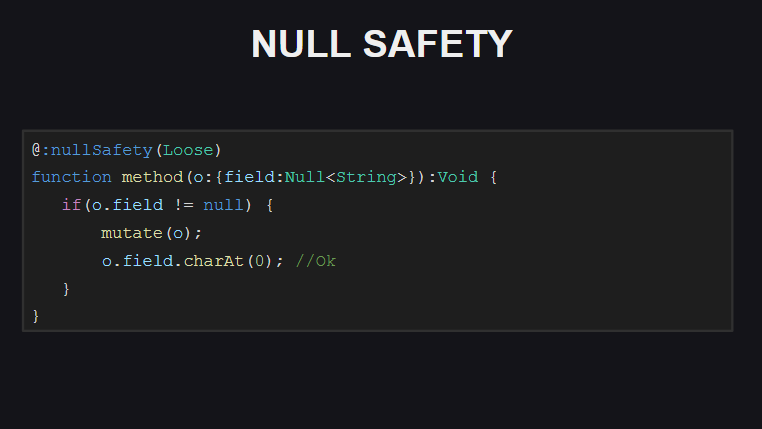
En el modo Loose (usado por defecto), el compilador no requerirá tales verificaciones (por cierto, este comportamiento también se usa por defecto en TypeScript).

Además, cuando se activan las comprobaciones de seguridad nula, el compilador comprueba si los campos de las clases se inicializan (directamente cuando se declaran o en el constructor). De lo contrario, el compilador arrojará errores al intentar pasar un objeto de dicha clase, así como al intentar llamar a métodos en dichos objetos, hasta que se inicialicen todos los campos del objeto. Dichas comprobaciones pueden desactivarse para campos individuales de la clase marcándolos con la metaetiqueta @:nullSafety(Off)
Alexander habló más sobre la seguridad nula en Haxe en octubre pasado .

Haxe 4 introdujo la capacidad de generar clases ES6 para JavaScript; se habilita utilizando el indicador de compilación js-es=6 .
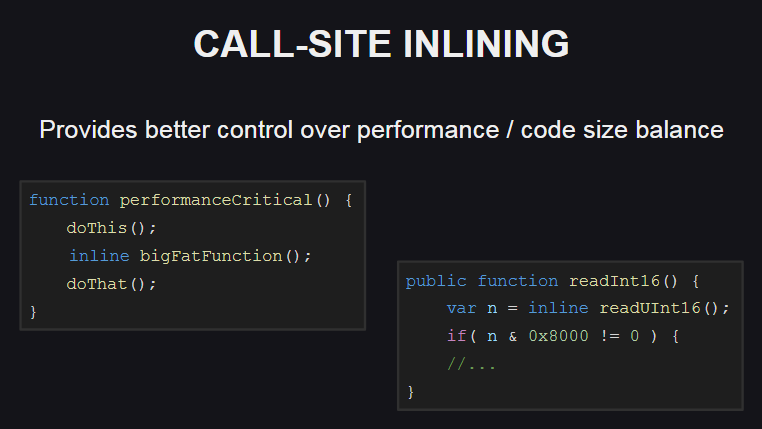
Las funciones de incrustación en el lugar de una llamada (en línea del sitio de la llamada) proporcionan más opciones para controlar el equilibrio entre el rendimiento y el tamaño del código. Esta funcionalidad también se usa en la biblioteca estándar de Haxe.
Como es ella Le permite incrustar el cuerpo de la función (usando la inline ) solo en aquellos lugares donde es necesario para garantizar un alto rendimiento (por ejemplo, si es necesario, llame a un método suficientemente voluminoso en el bucle), mientras que en otros lugares el cuerpo de la función no está incrustado. Como resultado, el tamaño del código generado aumentará ligeramente.
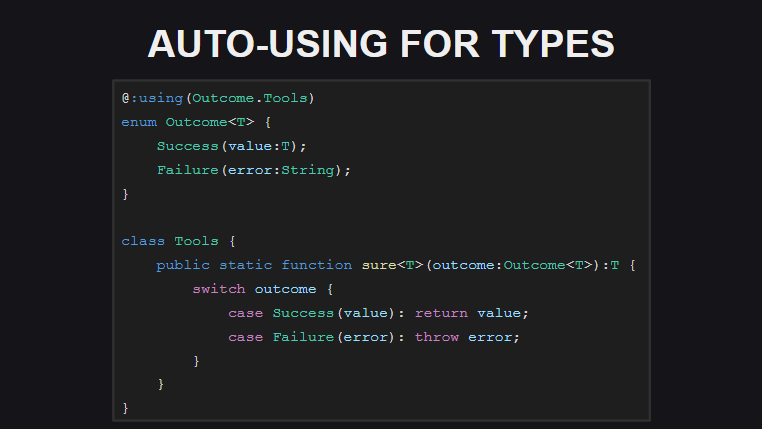
El uso automático (extensiones automáticas para tipos) significa que ahora para los tipos puede declarar extensiones estáticas en el lugar de la declaración de tipo. Esto elimina la necesidad de utilizar el using type; construcción cada vez using type; en cada módulo donde se utilizan los métodos de tipo y extensión. Por el momento, este tipo de extensión se implementa solo para transferencias, pero en la versión final (y en versiones nocturnas) puede usarse no solo para transferencias.

En Haxe 4, será posible redefinir el operador para acceder a los campos de un objeto para tipos abstractos (solo para campos que no existen en el tipo). Para hacer esto, use los métodos marcados con la metaetiqueta @:op(ab) .

El marcado incorporado es otra característica experimental en Haxe. El compilador no procesa el código de marcado incorporado como un documento xml: el compilador lo ve como una cadena envuelta en la metaetiqueta de @:markup .
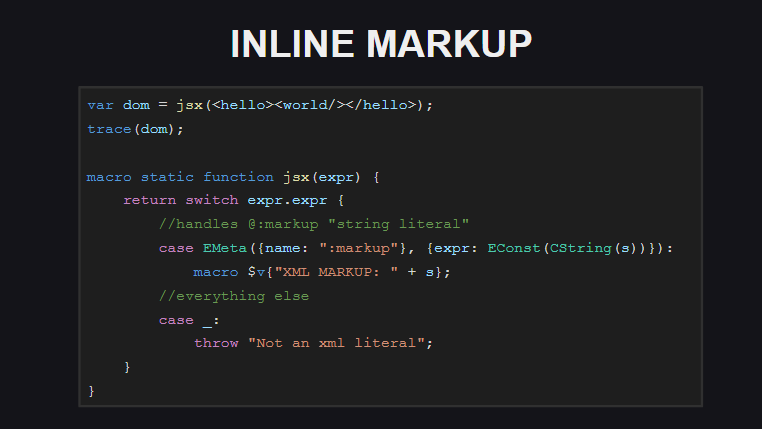
-, - @:markup , .

( untyped ). . , , Js.build() - @:markup , <js> , js-.

Haxe 4 - - , — .

. , . , Int , , C.
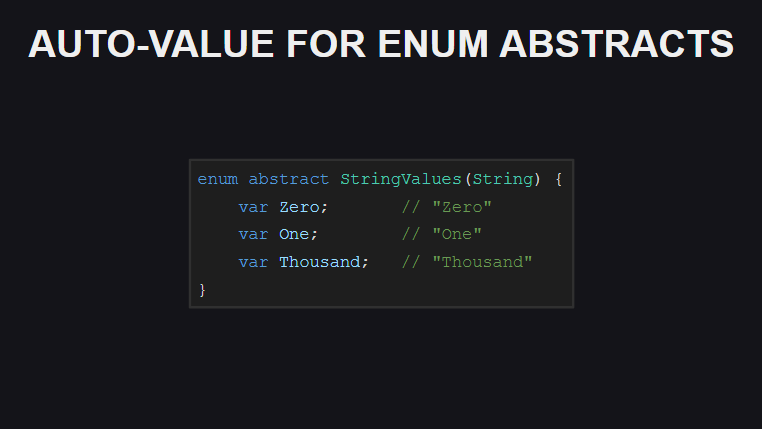
— .
:

JVM- JDK, Java-. . .

, async / await yield . ( C#, ). Haxe github.

Haxe , . ( ) . , .

API . , , API .
Haxe 4 !