
Hoy hablaré sobre cómo surgió y se hizo realidad la idea de crear una nueva red interna para nuestra empresa. Puesto directivo: para usted mismo, debe realizar el mismo proyecto completo que para el cliente. Si lo hacemos bien por nosotros mismos, podremos invitar al cliente y mostrarle qué tan bien organizado y funciona lo que le ofrecemos. Por lo tanto, abordamos el desarrollo del concepto de una nueva red para la oficina de Moscú muy a fondo, utilizando el ciclo de producción completo: análisis de las necesidades de los departamentos → elección de solución técnica → diseño → implementación → prueba. Entonces aquí vamos.
Elección de solución técnica: reserva de mutantes
Hasta ahora, el procedimiento para trabajar en un sistema automatizado complejo se describe mejor en GOST 34.601-90 "Sistemas automatizados. Las etapas de la creación ”, así que trabajamos en ello. Y ya en las etapas de formación de requisitos y desarrollo de un concepto, encontramos las primeras dificultades. Organizaciones de varios perfiles (bancos, compañías de seguros, desarrolladores de software, etc.) para sus tareas y estándares, se necesitan ciertos tipos de redes, cuyos detalles son claros y estandarizados. Sin embargo, esto no funcionará con nosotros.
Por qué
Jet Infosystems es una gran empresa multidisciplinaria de TI. Al mismo tiempo, nuestro departamento de soporte interno es pequeño (pero orgulloso), asegura la disponibilidad de servicios y sistemas básicos. La compañía contiene muchas divisiones que realizan diferentes funciones: incluye varios poderosos equipos de outsourcing, y sus propios desarrolladores de sistemas de negocios y seguridad de la información, y arquitectos de complejos informáticos, en general, quien no sea. En consecuencia, sus tareas, sistemas y políticas de seguridad también son diferentes. Lo que se esperaba creaba dificultades en el proceso de análisis de necesidades y su estandarización.
Por ejemplo, el departamento de desarrollo: sus empleados escriben y prueban el código para una gran cantidad de clientes. A menudo existe la necesidad de organizar rápidamente los entornos de prueba y, francamente, no siempre es posible que cada proyecto forme requisitos, solicite recursos y cree un entorno de prueba separado de acuerdo con todas las regulaciones internas. Esto da lugar a situaciones curiosas: una vez que su humilde servidor examinó la sala de desarrolladores y encontró un clúster de 20 escritorios Hadoop que funcionaba correctamente debajo de la mesa y que estaba inexplicablemente conectado a una red común. Creo que no vale la pena especificar que el departamento de TI de la empresa no sabía de su existencia. Esta circunstancia, como muchas otras, se convirtió en los culpables del hecho de que durante el desarrollo del proyecto, nació el término "reserva mutante", que describe el estado de la infraestructura de oficinas sufrida durante mucho tiempo.
O aquí hay otro ejemplo. Periódicamente, se instala un banco de pruebas dentro de una unidad. Este fue el caso de Jira y Confluence, que el Centro de Desarrollo de Software utilizó de forma limitada en algunos proyectos. Después de un tiempo, estos recursos útiles se descubrieron en otras divisiones, se evaluaron y, a fines de 2018, Jira y Confluence pasaron del estado de "programadores de juguetes locales" al estado de "recursos de la compañía". Ahora se debe asignar al propietario a estos sistemas, SLA, políticas de acceso / seguridad, políticas de respaldo, políticas de monitoreo, reglas de enrutamiento para la resolución de problemas de aplicaciones; en general, todos los atributos de un sistema de información completo deben estar presentes.
Cada una de nuestras unidades es también una incubadora que produce sus propios productos. Algunos de ellos mueren en la etapa de desarrollo, algunos de los cuales usamos durante el período de trabajo en los proyectos, mientras que otros se arraigan y se convierten en soluciones replicadas que comenzamos a aplicar y vender a los clientes. Para cada uno de estos sistemas, es deseable tener su propio entorno de red, donde se desarrollará sin interferir con otros sistemas, y en algún momento puede integrarse en la infraestructura de la compañía.
Además del desarrollo, tenemos un
centro de servicio muy grande con más de 500 empleados, formado en equipos para cada cliente. Se dedican al mantenimiento de redes y otros sistemas, monitoreo remoto, liquidación de aplicaciones, etc. Es decir, la infraestructura del
SC es, de hecho, la infraestructura del cliente con el que está trabajando actualmente. La peculiaridad de trabajar con esta parte de la red es que sus estaciones de trabajo para nuestra empresa son en parte externas y en parte internas. Por lo tanto, para SC implementamos el siguiente enfoque: la compañía proporciona a la unidad correspondiente la red y otros recursos, considerando las estaciones de trabajo de estas unidades como conexiones externas (similares a sucursales y usuarios remotos).
Diseño de carreteras: somos el operador (sorpresa)
Después de evaluar todas las dificultades, nos dimos cuenta de que estábamos obteniendo la red de un operador de telecomunicaciones dentro de una oficina, y comenzamos a actuar en consecuencia.
Creamos una red troncal, con la ayuda de la cual cualquier consumidor interno y, a largo plazo, externo, cuenta con el servicio requerido: L2 VPN, L3 VPN o enrutamiento L3 convencional. Algunos departamentos necesitan acceso seguro a Internet, mientras que otros necesitan acceso limpio sin firewalls, pero con la protección de nuestros recursos corporativos y la red central contra su tráfico.
Con cada división, informalmente "concluimos un SLA". De acuerdo con esto, todos los incidentes que hayan surgido deben eliminarse en un determinado período de tiempo previamente acordado. Los requisitos de la compañía para su red resultaron ser difíciles. El tiempo máximo de respuesta a incidentes para fallas telefónicas y de correo electrónico fue de 5 minutos. El tiempo de recuperación de la red durante fallas típicas no es más de un minuto.
Dado que tenemos una red de clase de operador, puede conectarse a ella solo de acuerdo con las reglas. Los departamentos de servicio establecen políticas y brindan servicios. Ni siquiera necesitan información sobre las conexiones de servidores específicos, máquinas virtuales y estaciones de trabajo. Pero al mismo tiempo, se necesitan mecanismos de protección, porque ninguna conexión debería deshabilitar la red. Al crear un bucle accidentalmente, otros usuarios no deberían notar esto, es decir, es necesaria una respuesta de red adecuada. Cualquier operador de telecomunicaciones resuelve constantemente tareas aparentemente complejas dentro de su red principal. Brinda servicio a muchos clientes con diferentes necesidades y tráfico. Al mismo tiempo, diferentes suscriptores no deberían experimentar inconvenientes por el tráfico de otros.
En casa, resolvimos este problema de la siguiente manera: construimos una red básica L3 con redundancia completa utilizando el
protocolo IS-IS . Se construyó una red superpuesta basada en tecnología
EVPN /
VXLAN en la parte superior de la red troncal, utilizando el
protocolo de enrutamiento
MP-BGP . Para acelerar la convergencia de los protocolos de enrutamiento, se utilizó la tecnología
BFD .
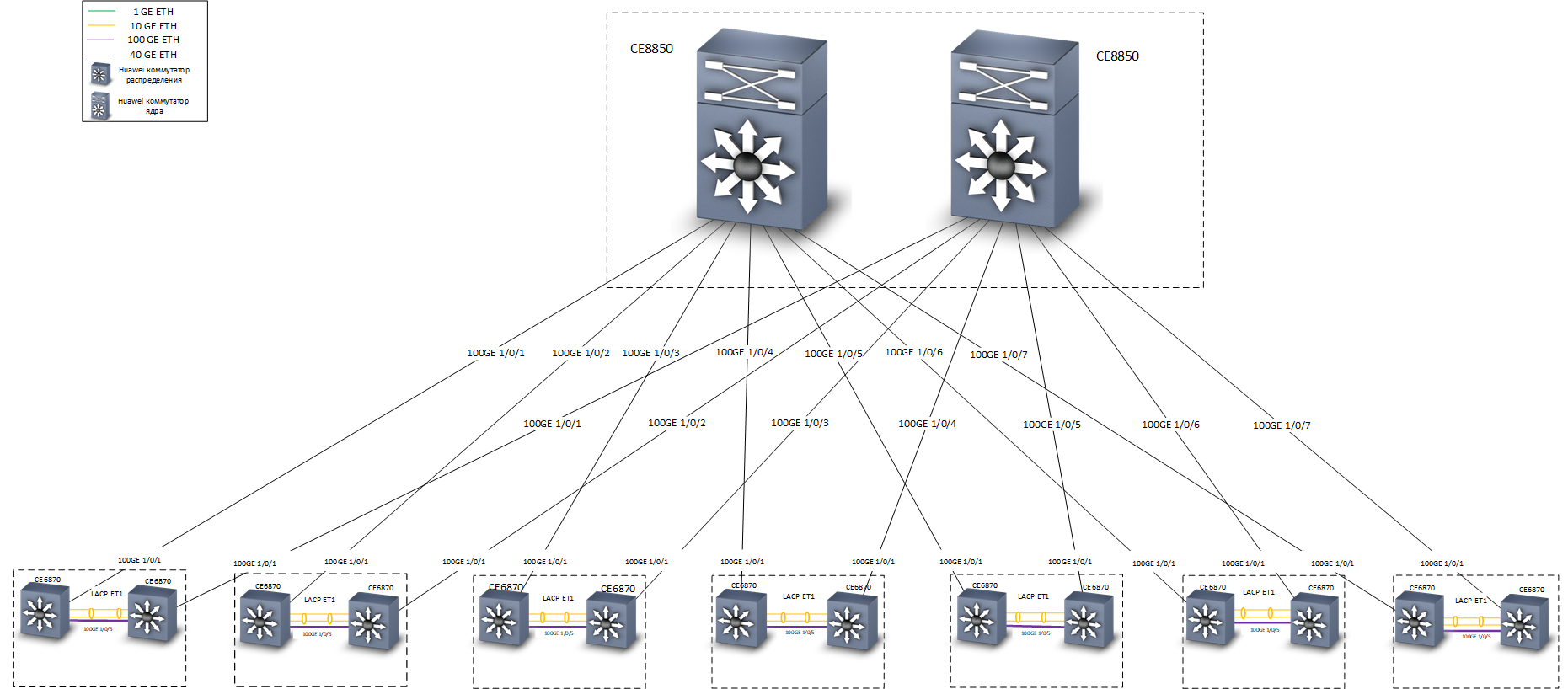 Estructura de red
Estructura de redEn las pruebas, dicho esquema demostró ser excelente: cuando se apaga cualquier canal o conmutador, el tiempo de convergencia no es más de 0.1-0.2 s, se pierde un mínimo de paquetes (a menudo ninguno), las sesiones TCP no se interrumpen, las conversaciones telefónicas no se interrumpen.
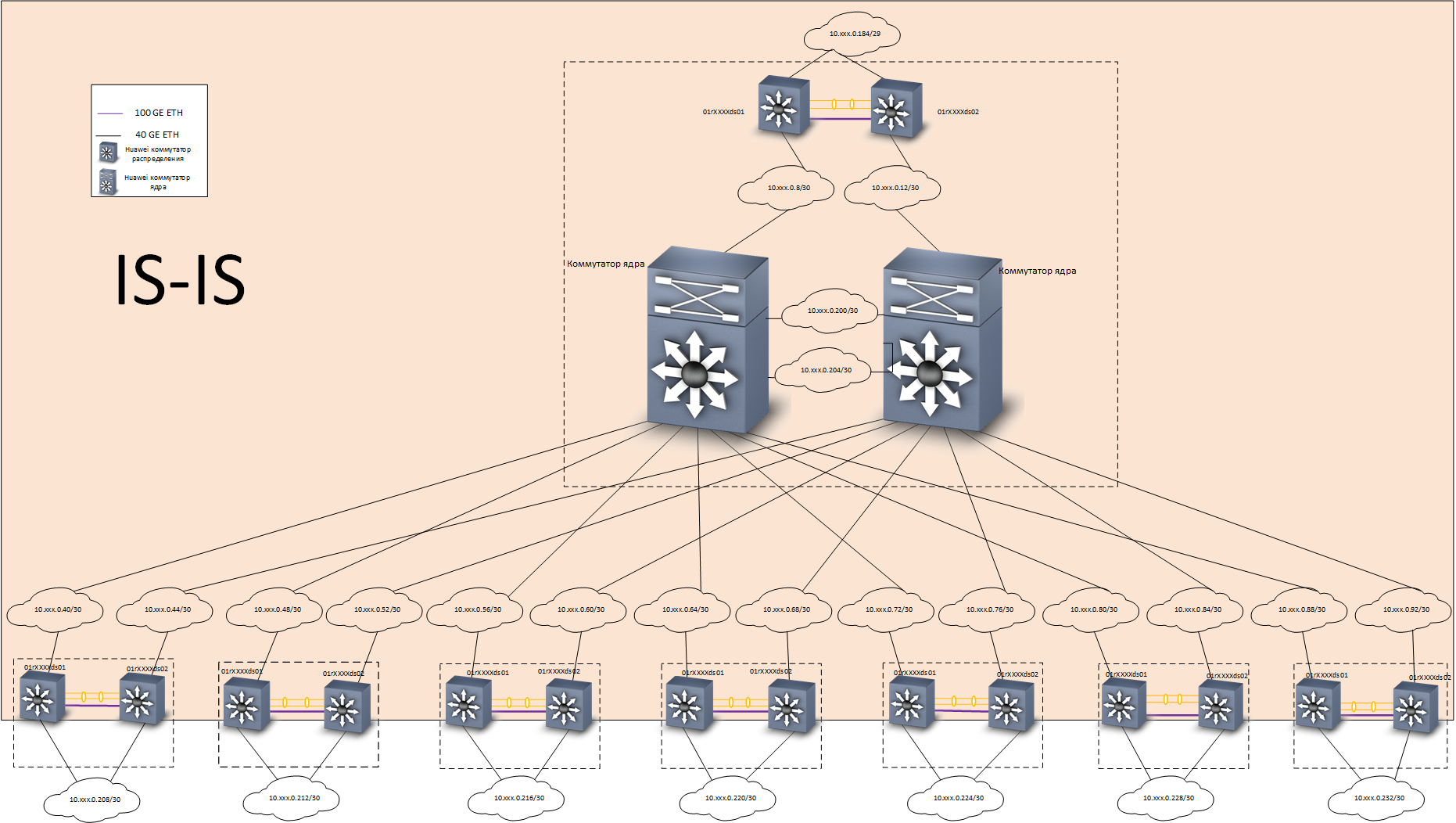 Nivel subyacente: enrutamiento
Nivel subyacente: enrutamiento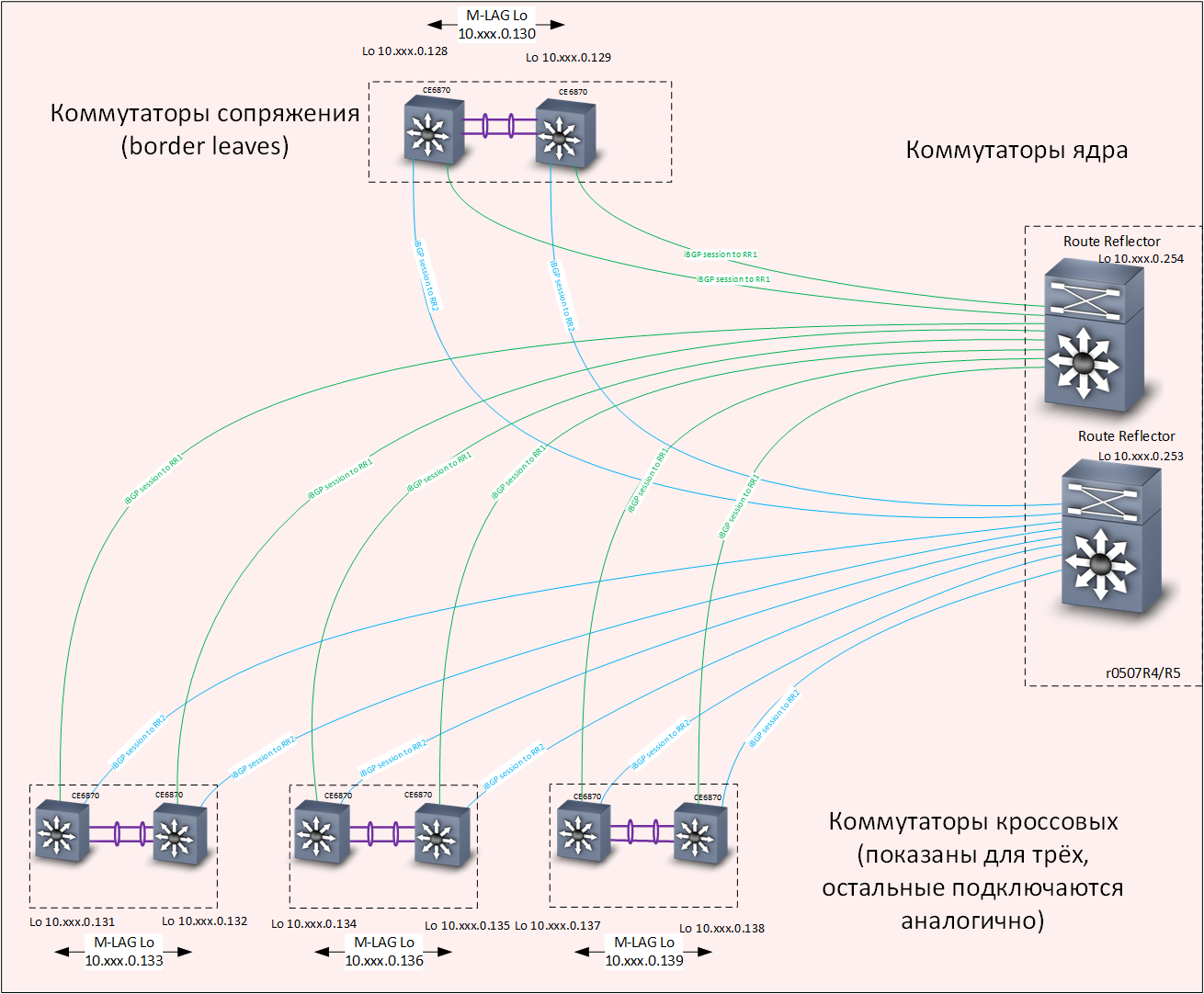 Level Overlay - Enrutamiento
Level Overlay - EnrutamientoComo conmutadores de distribución, se utilizaron los conmutadores Huawei CE6870 con licencias VXLAN. Este dispositivo tiene una combinación óptima de precio / calidad, le permite conectar suscriptores a una velocidad de 10 Gbit / s, y conectarse a la troncal a velocidades de 40-100 Gbit / s, dependiendo de los transceptores utilizados.
 Interruptores Huawei CE6870
Interruptores Huawei CE6870Como los interruptores principales, se utilizaron los interruptores Huawei CE8850. Desde la tarea: para transmitir tráfico de manera rápida y confiable. No hay dispositivos conectados a ellos, excepto los conmutadores de distribución, no saben nada sobre VXLAN, por lo que se eligió un modelo con 32 puertos de 40/100 Gbit / s, con una licencia básica que proporciona enrutamiento L3 y soporte para protocolos IS-IS y MP-BGP .
 El más bajo es el interruptor central Huawei CE8850
El más bajo es el interruptor central Huawei CE8850En la etapa de diseño, estalló una discusión dentro del equipo sobre tecnologías con las que puede implementar una conexión a prueba de fallas a los nodos de la red central. Nuestra oficina de Moscú está ubicada en tres edificios, tenemos 7 salas cruzadas, en cada una de las cuales se instalaron dos interruptores de distribución Huawei CE6870 (solo se instalaron unos pocos interruptores de acceso en varias salas cruzadas). Al desarrollar el concepto de red, se consideraron dos opciones de respaldo:
- La combinación de distribución cambia a una pila a prueba de fallas en cada habitación transversal. Pros: simplicidad y facilidad de configuración. Contras: hay una mayor probabilidad de falla de toda la pila cuando se manifiestan errores en el firmware de los dispositivos de red ("pérdidas de memoria" y similares).
- Aplique las tecnologías de puerta de enlace M-LAG y Anycast para conectar dispositivos a conmutadores de distribución.
Como resultado, nos decidimos por la segunda opción. Es algo más difícil de configurar, pero en la práctica ha demostrado su rendimiento y alta fiabilidad.
Considere primero conectar dispositivos terminales a conmutadores de distribución:
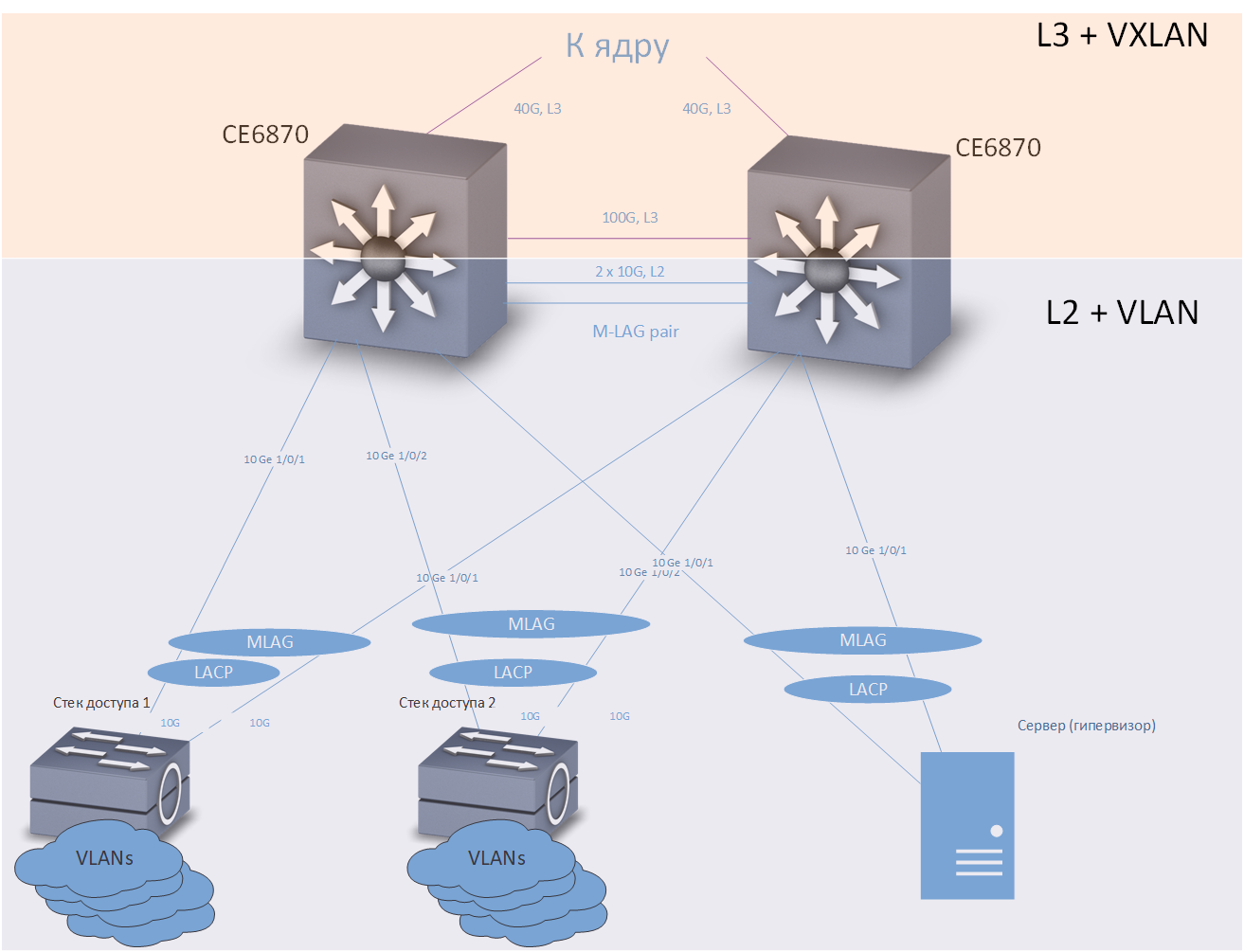 Cruz
CruzUn conmutador de acceso, servidor o cualquier otro dispositivo que requiera una conexión de conmutación por error se incluye en dos conmutadores de distribución. La tecnología M-LAG proporciona redundancia de enlace. Se supone que dos interruptores de distribución se parecen a un dispositivo para el equipo conectado. La redundancia y el equilibrio de carga se realizan utilizando el protocolo LACP.
La tecnología de puerta de enlace Anycast proporciona redundancia a nivel de red. En cada uno de los conmutadores de distribución, se configura un número suficientemente grande de VRF (cada VRF está diseñado para sus propios fines, por separado para usuarios "comunes", por separado, para telefonía, por separado, para diferentes entornos de prueba y desarrollo, etc.) y en cada VRF configuró varias VLAN. En nuestra red, los conmutadores de distribución son las puertas de enlace predeterminadas para todos los dispositivos conectados a ellos. Las direcciones IP correspondientes a las VLAN son las mismas para ambos conmutadores de distribución. El tráfico se enruta a través del interruptor más cercano.
Ahora considere conectar los conmutadores de distribución al núcleo:
La tolerancia a fallos se proporciona a nivel de red, de acuerdo con el protocolo IS-IS. Tenga en cuenta que entre los interruptores se proporciona una línea de comunicación L3 separada, a una velocidad de 100G. Físicamente, esta línea de comunicación es un cable de acceso directo, se puede ver a la derecha en la foto de los interruptores Huawei CE6870.
Una alternativa sería organizar una topología de doble estrella "honesta" totalmente conectada, pero, como se mencionó anteriormente, tenemos 7 salas cruzadas en tres edificios. En consecuencia, si elegimos la topología de "doble estrella", necesitaríamos exactamente el doble de transceptores 40G de "largo alcance". Los ahorros aquí son muy sustanciales.
Necesito decir algunas palabras sobre cómo las tecnologías de puerta de enlace VXLAN y Anycast funcionan juntas. VXLAN, si no entra en detalles, es un túnel para transportar tramas Ethernet dentro de paquetes UDP. Las interfaces de bucle de retorno de los conmutadores de distribución se utilizan como la dirección IP de destino del túnel VXLAN. Cada conmutador tiene dos conmutadores con las mismas direcciones de interfaz de bucle invertido, respectivamente, un paquete puede llegar a cualquiera de ellos y se puede extraer una trama de Ethernet.
Si el conmutador conoce la dirección MAC de destino de la trama extraída, la trama se entregará correctamente a su destino. El mecanismo M-LAG, que proporciona la sincronización de las tablas de direcciones MAC (así como las tablas ARP) en ambos, es responsable de garantizar que ambos conmutadores de distribución instalados en un cruce tengan información actualizada sobre todas las direcciones MAC que "llegan" de los conmutadores de acceso Par de interruptores M-LAG.
El equilibrio del tráfico se logra debido a la presencia en la red subyacente de varias rutas a las interfaces de bucle de retorno de los conmutadores de distribución.
En lugar de una conclusión
Como se mencionó anteriormente, durante las pruebas y durante la operación, la red mostró una alta confiabilidad (tiempo de recuperación para fallas típicas de no más de cientos de milisegundos) y un buen rendimiento, cada uno conectado de forma cruzada con el núcleo por dos canales de 40 Gbit / s. Los conmutadores de acceso en nuestra red están apilados y conectados a los conmutadores de distribución a través de LACP / M-LAG con dos canales de 10 Gb / s. La pila generalmente tiene 5 conmutadores con 48 puertos cada uno, hasta 10 pilas de acceso están conectadas a la distribución en cada cruce. Por lo tanto, la red troncal proporciona aproximadamente 30 Mbit / s por usuario, incluso con la carga teórica máxima, que en el momento de la escritura es suficiente para todas nuestras aplicaciones prácticas.
La red le permite organizar fácilmente el emparejamiento de cualquier dispositivo conectado arbitrariamente en L2 o L3, proporcionando un aislamiento completo del tráfico (que es preferido por el servicio de seguridad de la información) y dominios de falla (que es preferido por el servicio operativo).
En la
siguiente parte , describiremos cómo migramos a una nueva red. Estén atentos!
Maxim Klochkov
Consultor Senior, Auditoría de Red y Proyectos Integrados
Centro de soluciones de red
Jet Infosystems