
Los motores de búsqueda no tienen mucha lógica, esto es un hecho. Pero lo están intentando. Y los especialistas en SEO intentan responder: intentan alcanzar la máxima relevancia de las páginas, basándose en conjeturas y experimentación.
Google recientemente se complació con un nuevo factor de clasificación: Neural Matching. Leímos que los expertos escriben sobre esto y recopilamos algunos trucos que lo ayudarán a escribir textos más relevantes para las solicitudes.
Y, por cierto, NM no es LSI para ti, es un poco más complicado.
En septiembre de 2018, Danny Sullivan tuiteó que en los últimos meses, Google ha estado utilizando el método AI Neural Matching para asociar mejor las palabras con los conceptos. Este algoritmo influyó en los resultados del 30% de las solicitudes en todo el mundo.

No teníamos prisa por escribir sobre el nuevo algoritmo, estábamos esperando las aclaraciones de Google y la investigación en esta área. Pero las cosas siguen ahí: la mayoría de los comentaristas muestran las mismas capturas de pantalla y hablan sobre la transición de buscar por palabras a buscar por intención. También se refieren al Modelo de coincidencia de relevancia profunda (DRMM) .
Intentemos averiguar qué tipo de animal es este Neural Matching y cómo adaptar el contenido en el sitio.
Ejemplos de emparejamiento neuronal
Danny Sullivan describe qué es Neural Matching. Dio un ejemplo de emitir la pregunta "por qué mi televisor se ve extraño". El usuario ingresa dicha consulta cuando aún no sabe cuál es el efecto de telenovela. Pero Google, gracias al nuevo algoritmo, sabe exactamente lo que necesita:

En ruso, una historia similar:

Otro ejemplo. Conociste un insecto "hermoso" en el apartamento y no tienes idea de cómo se llama:

Vamos a Google, ingresamos un conjunto de características y en la primera posición obtenemos la respuesta relevante:

La implementación de Neural Matching se debe al hecho de que los usuarios no siempre saben lo que están buscando y no siempre formulan correctamente las solicitudes. Danny Sullivan mostró varias consultas "incorrectas":

La tarea de Neural Matching es determinar la verdadera intención de búsqueda (intención) y producir los resultados correctos.

Para determinar la intención, no se usan palabras separadas, sino esencias y relaciones entre ellas. Vea cómo funciona: en el ejemplo de las consultas "se emborrachó qué hacer" y "se emborrachó en la noche".
Cada solicitud contiene la misma entidad: "se emborrachó". Pero combinarlo con la esencia de "durante la noche" le indica al motor de búsqueda que el usuario quiere decir comer en exceso. Y la esencia de "qué hacer" probablemente se asocia con la intoxicación.

¿Cómo define Google la intención? ¿La semántica es similar? El motor de búsqueda compara con qué frecuencia las entidades combinadas en la solicitud se encuentran lado a lado en las páginas. Además, las estadísticas sobre las solicitudes se tienen en cuenta (los usuarios al ingresar la solicitud "se emborracharon por la noche" con mayor frecuencia hacen clic en artículos específicos sobre comer en exceso).
Otro ejemplo. El usuario ingresa la frase "poner ventanas". Esta es solo la solicitud "incorrecta" de la que habla Danny Sullivan. Google entiende que una persona por "poner" significa algo más que una simple instalación de ventanas, y muestra en la PARTE SUPERIOR los resultados correctos desde su punto de vista:
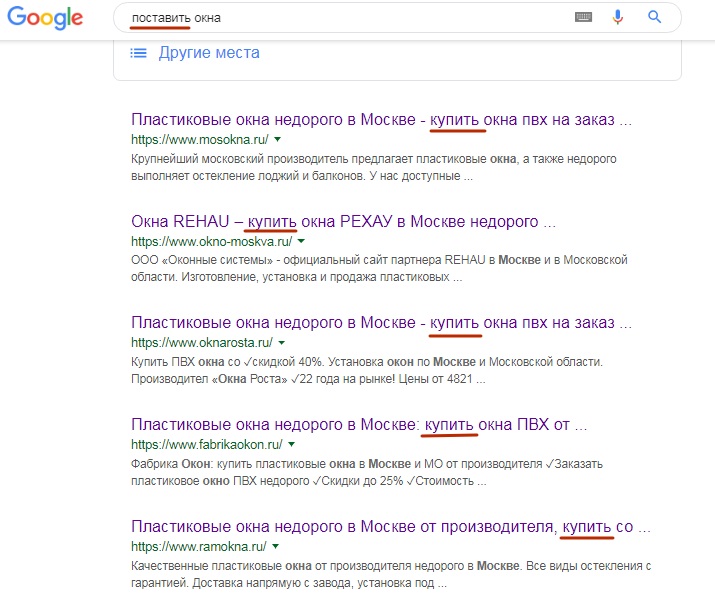
En este caso, solo una página del TOP-6 contiene la palabra "entregar" (en el sentido de "proveedor de ventanas", y no "instalar ventanas usted mismo"). En las páginas restantes del TOP-6 no hay una palabra "put", ni siquiera palabras raíz. Aunque los resultados como "Cómo instalar Windows usted mismo", etc., ya se mezclan a continuación.
Esto lleva a una conclusión aparentemente paradójica: para ocupar posiciones altas en muchas palabras, no es necesario saturar los textos con una semántica similar a una consulta de búsqueda. La relevancia del contenido es evaluada por un conjunto de entidades (frases marcadoras), que tienen muchas probabilidades de satisfacer la intención de búsqueda.
Esto cambia el enfoque para escribir textos de SEO: antes las claves eran el punto de referencia, ahora las necesidades de la audiencia.
Clasificación de relevancia de documentos y coincidencia neuronal: ¿cómo afectará esto al SEO?
Roger Montti sugirió en un artículo para Search Engine Journal que el algoritmo de Neural Matching podría funcionar según el método de Clasificación de Relevancia de Documentos (DRR). El método se describe en el artículo " Clasificación de relevancia profunda utilizando interacciones mejoradas de consulta de documentos " publicado en Google AI.
La esencia del método DRR es que al determinar la relevancia de un documento, su texto se usa exclusivamente. Otros factores (enlaces, anclas, menciones, SEO en la página) no importan.
¿Qué, los enlaces ya no son necesarios? Realmente no es así. La clasificación según el método DRR descrito es parte del algoritmo de clasificación general. En la primera etapa, la emisión se forma teniendo en cuenta todos los factores de clasificación (enlaces, claves, "movilidad", geolocalización, etc.). Por lo tanto, el motor de búsqueda elimina el contenido base e identifica sitios de buena reputación. En la segunda etapa, la RRD ingresa al trabajo; entre los mejores resultados, selecciona los más relevantes (pero solo tiene en cuenta el texto).
En la práctica, puede verse así. Hay dos sitios: uno muy respetable y joven. El sitio joven contiene súper contenido que no tiene análogos en el nicho, lleno de detalles y detalles. Pero dado que hay más enlaces a un sitio autorizado, su página ocupa el primer lugar y la página de un sitio joven ocupa el décimo. Y aquí entra en funcionamiento la RRD: el motor de búsqueda escanea los textos y se da cuenta de que el contenido del sitio joven es más significativo que el de un sitio autorizado. La consecuencia es el movimiento del sitio joven a una posición más alta.
Cómo hacer contenido en Neural Matching
Si Neural Matching funciona en función de la RRD o no, no es tan importante. Es importante que la intención de búsqueda "conduzca" aquí. No largos "paños", ni la densidad de palabras clave, ni sinónimos.

Antes de crear contenido, decida:
- para quién es él (lo mejor es realizar una investigación, hacer retratos de los usuarios y escribir para ellos);
- por qué es necesario (qué tarea cierra);
- qué contiene lo que los competidores no tienen (qué valor aporta).
Para aumentar la relevancia de los textos, además de las consultas básicas, utilice entidades estrechamente relacionadas. Si el texto está escrito por un experto, entonces esas entidades probablemente estarán en el texto. Otra cuestión es cuando el redactor recibe TK; en este caso, es necesario determinar las entidades e indicarlas en la tarea.
Consideremos los métodos de recopilación de entidades utilizando el ejemplo de una categoría de la tienda en línea "Generadores de gasolina".
1. Buscar preguntas / respuestas
Puede identificar las necesidades de los usuarios mediante foros, comentarios en artículos de blogs y debates en redes sociales. Todo funciona Pero es más fácil ir a Answers@Mail.ru (o la contraparte occidental: Quora ), ingresar una consulta de búsqueda, revisar las preguntas y resaltar las entidades asociadas con las teclas principales.
A pedido de "generadores de gasolina" mail.ru emite 1624 preguntas. Revisamos la lista y seleccionamos las entidades que caracterizan las necesidades del público objetivo.


Después de seleccionar las entidades, pensamos qué contenido es adecuado para ellas. Por ejemplo, el consumo de gasolina por 1 hora y los métodos de uso del generador (para soldar, para una caldera, para la iluminación, etc.) deben indicarse en la descripción de productos específicos. En la descripción de la rúbrica “Generadores de gasolina”, puede describir brevemente en qué se diferencian los generadores de gasolina del gas, el inversor, etc. En el artículo del blog se describe un problema con el funcionamiento de los generadores.
El procesamiento de preguntas en los servicios de control de calidad es minucioso, pero le permite resaltar las necesidades reales de la audiencia, de lo que es posible que no haya adivinado.
Puede intentar simplificar el trabajo utilizando el servicio Responder al público . Recopila preguntas, comparaciones y diversas formulaciones que ocurren en la red con la aparición de una frase dada.

El único inconveniente es el servicio en inglés. La traducción de la frase deseada resuelve parcialmente el problema. Pero en el segmento comercial, vale la pena recordar las peculiaridades de los mercados (lo que preocupa a los indios puede ser inútil para los rusos).
2. Analizar frases de asociación
Debajo de los resultados de búsqueda, se muestra el bloque "Junto con ... a menudo buscado": aquí se recopilan las frases que el propio motor de búsqueda asocia con la frase original ("generadores de gasolina").

El análisis de frases de asociación le permite identificar entidades relacionadas: 5 kW, 3 kW, 10 kW, inversor, 1 kW.
Queda por pensar cómo incluirlos en el contenido. Por ejemplo, en la descripción de la columna de "generadores impulsados por gasolina", vale la pena decir para qué fines son adecuados los generadores de diferente potencia (1, 3, 5, 10 kW) y tipo (inversor, convencional, etc.).
Si tiene muchas solicitudes iniciales, recopile manualmente las asociaciones durante mucho tiempo; use el analizador .
3. Analizando sugerencias de búsqueda
Las sugerencias son otra fuente para hacer coincidir entidades relacionadas.

Reponemos la lista de entidades recopiladas de las asociaciones: con ejecución automática, diesel, 380 voltios, silencioso. Estas son palabras que caracterizan bien los problemas del usuario.
También hay un analizador para recopilar pistas.
En principio, los métodos discutidos son suficientes para tener una idea de las necesidades de la audiencia. Pero si desea resolver la semántica aún más profundamente, aquí hay dos formas opcionales.
4. Selección de cuasi-sinónimos
Los cuasinónimos (asociaciones semánticas) son palabras que tienen un significado cercano, pero no intercambiables en diferentes contextos. Por ejemplo, las palabras "generador" y "generador automático" son sinónimos en el texto sobre repuestos de automóviles, pero no lo serán en el texto sobre tipos de generadores.
Los cuasinónimos se determinan en función de la frecuencia de su aparición en los textos. Para resolver este problema, hay un servicio de RusVectōr (sección "Palabras similares"). Ingrese la palabra de interés, marque todos los modelos y partes del discurso disponibles, y comience la búsqueda.

Como resultado, obtendrá los 10 asociados más importantes para cada modelo de búsqueda. Usarlos a ciegas en la formación de TK no vale la pena: aquí habrá mucha "basura" (aún es preferible analizar asociaciones basadas en datos de motores de búsqueda). Sin embargo, puedes identificar palabras interesantes. Por ejemplo, vemos que las palabras "generador de gas", "inversor", "generador de gas", "contactor", etc. están asociadas con la palabra "generador".
5. Análisis de textos de la competencia
Para identificar las necesidades de la audiencia, este método no es el mejor. En primer lugar, no se sabe cuándo se creó el contenido en los sitios web de los competidores (durante este tiempo, las preferencias de búsqueda podrían cambiar). En segundo lugar, no hay garantía de que los competidores hayan analizado cuidadosamente los problemas de la audiencia y hayan creado textos basados en ellos.
Por otro lado, si usa este método como auxiliar, existe la posibilidad de identificar entidades que podría perderse.
Entonces, ingresamos la consulta principal "generadores de gasolina" en la búsqueda, copiamos los textos relevantes de los sitios al TOP-10 y seleccionamos la semántica usando Advego :

Complementamos la lista de entidades relevantes: 4 tiempos, emergencia, autónoma, ininterrumpida, para casa de verano, para la naturaleza, etc.
Poniendo todo junto y obteniendo un TK optimizado para Neural Matching.
TK para letras: haz Neural Matching, no LSI
Después de recopilar las entidades relevantes, debe escribir el texto. Pero no basta con especificar las claves y una lista de sinónimos y palabras relacionadas en los TOR, como suele hacerse al ordenar textos LSI .

Ejemplo de TK para texto LSI
Sobre la base de tales conocimientos tradicionales, simplemente con una lista de palabras, a veces se obtienen textos bastante extraños.
Una práctica común entre los redactores es escribir un texto, y solo luego ingresar las palabras dadas en él. Esto es más fácil, ya que no necesita interrumpir la selección e inserción de palabras en el proceso de redacción del texto. Pero tales inserciones retroactivamente pueden romper, y a menudo romper, la lógica y el estilo del texto.
El texto debajo de Neural Matching trata sobre los usuarios y sus necesidades, no sobre las claves y las palabras más. Por lo tanto, las características puramente de marketing aparecen en TK: descripciones de los consumidores y sus motivos. Las teclas y las palabras más se desvanecen en el fondo: se usan como marcadores y no como elementos obligatorios. Su lugar está ocupado por las necesidades de información de la audiencia.

Ejemplo TK bajo Neural Matching
Tal TK le permite al autor entender claramente para quién es el texto, por qué y bajo qué circunstancias será leído. Tal TK no solo deletrea las palabras que se usarán, sino que da instrucciones sobre qué escribir para usar estas palabras.
Neural Matching, al optimizar las páginas para la búsqueda, cambia el énfasis de la mecánica puramente SEO al marketing. De hecho, esta tendencia se ha observado durante varios años. Neural Matching es solo un paso más hacia la optimización de motores de búsqueda con rostro humano.
Optimizar el contenido para Neural Matching requiere tiempo y trabajo de cabeza. Es mucho más fácil soltar las claves del AX en el TK, analizar más palabras y decirle al redactor: "Escribir para la gente". Pero con el desarrollo de la búsqueda de IA, este enfoque será cada vez menos efectivo.