Gestión de clústeres eficiente y confiable a cualquier escala con Tupperware

Hoy, en la conferencia Systems @Scale, presentamos Tupperware, nuestro sistema de administración de clúster que organiza contenedores en millones de servidores, donde funcionan casi todos nuestros servicios. Lanzamos Tupperware por primera vez en 2011, y desde entonces nuestra infraestructura ha crecido de 1 centro de datos a 15 centros de datos geodistribuidos . Todo este tiempo Tupperware no se detuvo y se desarrolló con nosotros. Le diremos en qué situaciones Tupperware proporciona una administración de clúster de primera clase, que incluye soporte conveniente para servicios con estado, un solo panel de control para todos los centros de datos y la capacidad de distribuir energía entre servicios en tiempo real. Y compartiremos las lecciones que aprendimos a medida que nuestra infraestructura se desarrolló.
Tupperware realiza varias tareas. Los desarrolladores de aplicaciones lo usan para entregar y administrar aplicaciones. Empaqueta el código y las dependencias de la aplicación en una imagen y la entrega a los servidores en forma de contenedores. Los contenedores proporcionan aislamiento entre aplicaciones en el mismo servidor para que los desarrolladores estén ocupados con la lógica de la aplicación y no piensen en cómo encontrar servidores o controlar las actualizaciones. Tupperware también monitorea el rendimiento del servidor y, si encuentra una falla, transfiere los contenedores del servidor problemático.
Los ingenieros de planificación de capacidad utilizan Tupperware para distribuir las capacidades del servidor en equipos de acuerdo con el presupuesto y las limitaciones. También lo usan para mejorar la utilización del servidor. Los operadores de centros de datos recurren a Tupperware para distribuir adecuadamente los contenedores entre los centros de datos y detener o mover contenedores durante el mantenimiento. Debido a esto, el mantenimiento de servidores, redes y equipos requiere una participación humana mínima.
Arquitectura Tupperware
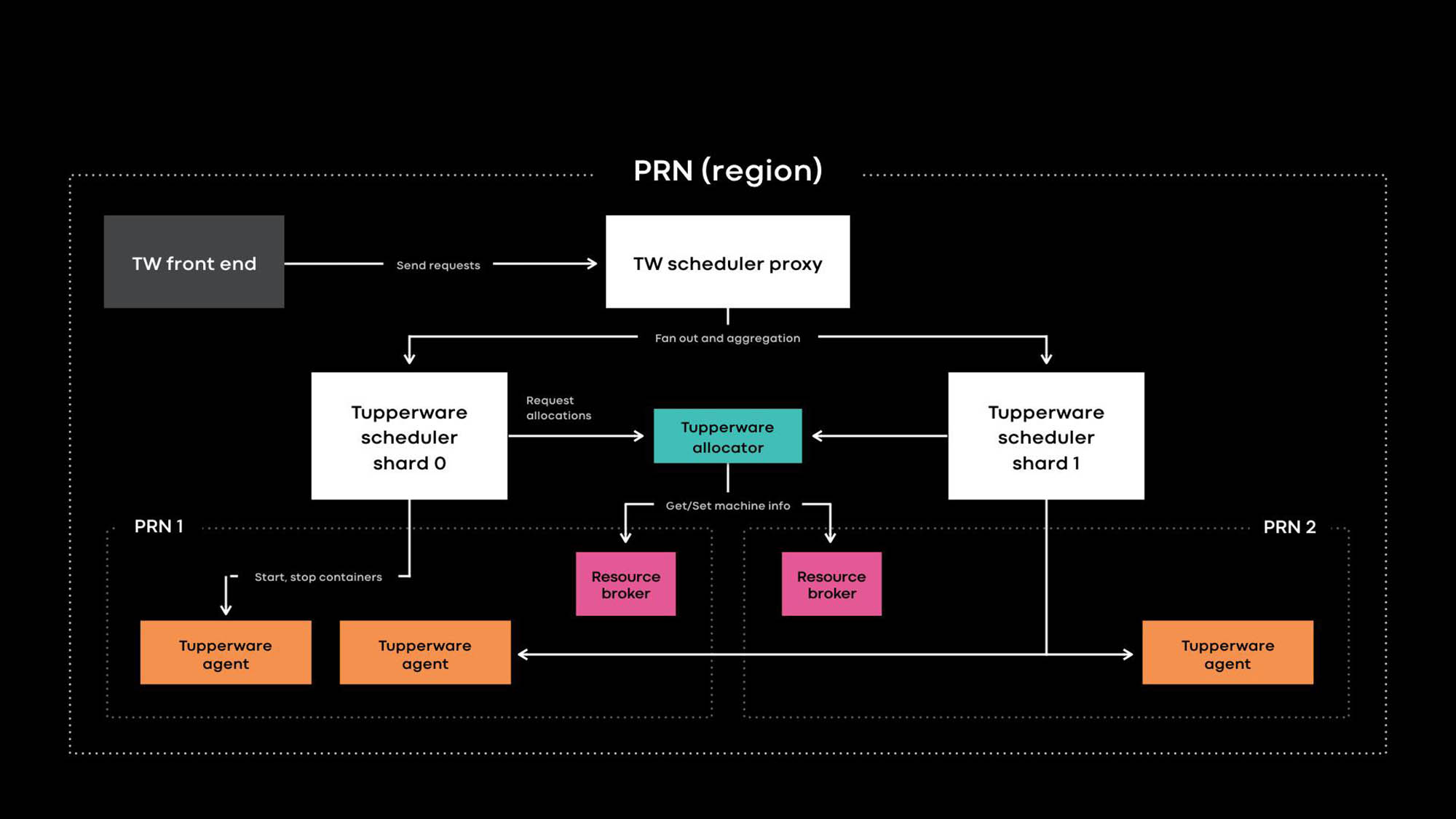
Arquitectura Tupperware PRN es una de las regiones de nuestros centros de datos. La región consta de varios edificios de centros de datos (PRN1 y PRN2) ubicados cerca. Planeamos hacer un panel de control que gestionará todos los servidores en una región.
Los desarrolladores de aplicaciones brindan servicios en forma de trabajos Tupperware. Una tarea consta de varios contenedores, y todos ellos generalmente ejecutan el mismo código de aplicación.
Tupperware es responsable del aprovisionamiento de contenedores y la gestión del ciclo de vida. Se compone de varios componentes:
- Tupperware Frontend proporciona una API para la interfaz de usuario, CLI y otras herramientas de automatización a través de las cuales puede interactuar con Tupperware. Ocultan toda la estructura interna de los propietarios de trabajos de Tupperware.
- El Programador Tupperware es el panel de control responsable de administrar el contenedor y el ciclo de vida del trabajo. Se implementa a nivel regional y global, donde un planificador regional gestiona servidores en una región, y un planificador global gestiona servidores de diferentes regiones. El planificador se divide en fragmentos, y cada fragmento controla un conjunto de tareas.
- El proxy del planificador en Tupperware oculta el fragmentación interna y proporciona un panel de control unificado conveniente para los usuarios de Tupperware.
- El distribuidor Tupperware asigna contenedores a los servidores. El planificador es responsable de detener, iniciar, actualizar y fallar los contenedores. Actualmente, un único distribuidor puede administrar una región completa sin dividirse en fragmentos. (Observe la diferencia en la terminología. Por ejemplo, el planificador en Tupperware corresponde al panel de control en Kubernetes , y el distribuidor de Tupperware se llama el planificador en Kubernetes).
- El agente de recursos almacena la fuente de la verdad para el servidor y los eventos de servicio. Ejecutamos un agente de recursos para cada centro de datos, y almacena toda la información del servidor en este centro de datos. Un agente de recursos y un sistema de gestión de capacidad, o un sistema de asignación de recursos, deciden dinámicamente qué suministro del planificador controla qué servidor. El servicio de comprobación de estado supervisa los servidores y almacena datos sobre su estado en el intermediario de recursos. Si el servidor tiene problemas o necesita servicio, el agente de recursos le dice al distribuidor y al planificador que detenga los contenedores o los transfiera a otros servidores.
- Tupperware Agent es un demonio que se ejecuta en cada servidor que prepara y elimina contenedores. Las aplicaciones funcionan dentro del contenedor, lo que les da más aislamiento y reproducibilidad. En la conferencia Systems @Scale del año pasado, ya describimos cómo se crean contenedores Tupperware individuales usando imágenes, btrfs, cgroupv2 y systemd.
Características distintivas de Tupperware
Tupperware es muy similar a otros sistemas de administración de clúster, como Kubernetes y Mesos , pero hay algunas diferencias:
- Soporte nativo para servicios con estado.
- Un único panel de control para servidores en diferentes centros de datos para automatizar la entrega de contenedores según la intención, el desmantelamiento de clústeres y el mantenimiento.
- Separación clara del panel de control para hacer zoom.
- Los cálculos flexibles le permiten distribuir la energía entre los servicios en tiempo real.
Diseñamos estas características geniales para admitir una variedad de aplicaciones sin estado y con estado en un enorme parque global de servidores compartidos.
Soporte nativo para servicios con estado.
Tupperware gestiona muchos servicios críticos con estado que almacenan datos de productos persistentes para Facebook, Instagram, Messenger y WhatsApp. Estos pueden ser grandes pares clave-valor (por ejemplo, ZippyDB ) y almacenes de datos de monitoreo (por ejemplo, ODS Gorilla y Scuba ). Mantener servicios con estado no es fácil, porque el sistema debe garantizar que las entregas de contenedores puedan soportar fallas a gran escala, incluyendo un corte de energía o un corte de energía. Aunque los métodos convencionales, como la distribución de contenedores a través de dominios de falla, son adecuados para servicios sin estado, los servicios con estado necesitan soporte adicional.
Por ejemplo, si como resultado de una falla del servidor, una réplica de la base de datos no está disponible, ¿es necesario permitir el mantenimiento automático que actualizará los núcleos en 50 servidores de un grupo de 10 milésimas? Depende de la situación. Si en uno de estos 50 servidores hay otra réplica de la misma base de datos, es mejor esperar y no perder 2 réplicas a la vez. Para tomar decisiones dinámicas sobre el mantenimiento y el estado del sistema, necesita información sobre la replicación interna de datos y la lógica de ubicación de cada servicio con estado.
La interfaz TaskControl permite que los servicios con estado influyan en las decisiones que afectan la disponibilidad de datos. Usando esta interfaz, el planificador notifica a las aplicaciones externas de las operaciones del contenedor (reinicio, actualización, migración, mantenimiento). El servicio Stateful implementa un controlador que le dice a Tupperware cuándo cada operación puede realizarse de manera segura, y estas operaciones pueden intercambiarse o retrasarse temporalmente. En el ejemplo anterior, el controlador de la base de datos puede indicar a Tupperware que actualice 49 de los 50 servidores, pero hasta ahora no toque un servidor específico (X). Como resultado, si el período de actualización del kernel pasa y la base de datos aún no puede restaurar la réplica del problema, Tupperware aún actualizará el servidor X.

Muchos servicios con estado en Tupperware no usan TaskControl directamente, sino a través de ShardManager, una plataforma común para crear servicios con estado en Facebook. Con Tupperware, los desarrolladores pueden indicar su intención sobre cómo se deben distribuir los contenedores entre los centros de datos. Con ShardManager, los desarrolladores indican su intención sobre cómo se deben distribuir los fragmentos de datos entre los contenedores. ShardManager conoce el alojamiento de datos y la replicación de sus aplicaciones e interactúa con Tupperware a través de la interfaz TaskControl para planificar las operaciones de contenedor sin la participación directa de la aplicación. Esta integración simplifica enormemente la administración de servicios con estado, pero TaskControl es capaz de más. Por ejemplo, nuestro extenso nivel web no tiene estado y utiliza TaskControl para ajustar dinámicamente la velocidad de las actualizaciones en los contenedores. Como resultado, el nivel web puede completar rápidamente varias versiones de software por día sin comprometer la disponibilidad.
Administración de servidores en centros de datos.
Cuando Tupperware apareció por primera vez en 2011, un programador separado controlaba cada clúster de servidores. Luego, el clúster de Facebook era un grupo de bastidores de servidores conectados a un conmutador de red, y el centro de datos contenía varios clústeres. El planificador podría administrar servidores en un solo clúster, es decir, la tarea no podría extenderse a varios clústeres. Nuestra infraestructura estaba creciendo, estábamos anulando cada vez más los clústeres. Dado que Tupperware no pudo transferir la tarea desde el clúster fuera de servicio a otros clústeres sin cambios, se requirió mucho esfuerzo y una cuidadosa coordinación entre los desarrolladores de aplicaciones y los operadores de centros de datos. Este proceso condujo a una pérdida de recursos cuando los servidores estuvieron inactivos durante meses debido al procedimiento de desmantelamiento.
Creamos un agente de recursos para resolver el problema del desmantelamiento de clústeres y coordinar otros tipos de tareas de mantenimiento. El intermediario de recursos supervisa toda la información física asociada con el servidor y decide dinámicamente qué programador gestiona cada servidor. La vinculación dinámica de servidores a planificadores permite que el planificador administre servidores en diferentes centros de datos. Dado que el trabajo de Tupperware ya no se limita a un clúster, los usuarios de Tupperware pueden especificar cómo se deben distribuir los contenedores entre los dominios de falla. Por ejemplo, un desarrollador puede declarar su intención (por ejemplo: "ejecutar mi tarea en 2 dominios de falla en la región PRN") sin especificar zonas de disponibilidad específicas. El propio Tupperware encontrará los servidores correctos para encarnar esta intención incluso en el caso de desmantelar un clúster o servicio.
Escalado para soportar todo el sistema global
Históricamente, nuestra infraestructura se ha dividido en cientos de grupos de servidores dedicados para equipos individuales. Debido a la fragmentación y la falta de estándares, tuvimos altos costos de transacción y los servidores inactivos fueron más difíciles de usar nuevamente. En la conferencia Systems @Scale del año pasado, presentamos la Infraestructura como servicio (IaaS) , que debería integrar nuestra infraestructura en una flota de servidores unificada de gran tamaño. Pero una sola flota de servidores tiene sus propias dificultades. Debe cumplir ciertos requisitos:
- Escalabilidad. Nuestra infraestructura creció con la adición de centros de datos en cada región. Los servidores se han vuelto más pequeños y más eficientes energéticamente, por lo que en cada región hay mucho más. Como resultado, un único programador para una región no puede hacer frente a la cantidad de contenedores que se pueden ejecutar en cientos de miles de servidores en cada región.
- Fiabilidad Incluso si la escala del planificador se puede aumentar de esta manera, debido al gran alcance del planificador, el riesgo de errores será mayor y toda la región de contenedores puede volverse inmanejable.
- Tolerancia a fallas. En el caso de una gran falla en la infraestructura (por ejemplo, debido a una falla de la red o un corte de energía, los servidores donde se ejecuta el planificador fallarán), solo una parte de los servidores de la región tendrá consecuencias negativas.
- Facilidad de uso. Puede parecer que necesita ejecutar varios programadores independientes en una región. Pero en términos de conveniencia, un único punto de entrada a un grupo común en la región simplifica la capacidad y la gestión del trabajo.
Dividimos el planificador en fragmentos para resolver problemas al admitir un gran grupo compartido. Cada fragmento del planificador gestiona su conjunto de tareas en la región, y esto reduce el riesgo asociado con el planificador. A medida que crece el grupo total, podemos agregar más fragmentos de planificador. Para los usuarios de Tupperware, los fragmentos y los programadores proxy se ven como un panel de control. No tienen que trabajar con un montón de fragmentos que orquestan tareas. Los fragmentos del planificador son fundamentalmente diferentes de los planificadores de clúster que utilizamos antes, cuando el panel de control se dividió sin separación estática del grupo de servidores común de acuerdo con la topología de la red.
Mejora de la utilización con computación elástica
Cuanto más grande es nuestra infraestructura, más importante es usar eficientemente nuestros servidores para optimizar los costos de infraestructura y reducir la carga. Hay dos formas de mejorar la utilización del servidor:
- Computación flexible: reduzca la escala de los servicios en línea durante las horas de silencio y use los servidores liberados para cargas fuera de línea, por ejemplo, para tareas de aprendizaje automático y MapReduce.
- Carga excesiva: aloje servicios en línea y cargas de trabajo por lotes en los mismos servidores para que las cargas por lotes se ejecuten con baja prioridad.
El cuello de botella en nuestros centros de datos es el consumo de energía . Por lo tanto, preferimos servidores pequeños y de bajo consumo que, en conjunto, brinden más potencia de procesamiento. Desafortunadamente, en servidores pequeños con una pequeña cantidad de recursos de procesador y memoria, la carga excesiva es menos eficiente. Por supuesto, podemos colocar varios contenedores de pequeños servicios en un pequeño servidor de bajo consumo que consume pocos recursos de procesador y memoria, pero los servicios grandes tendrán un bajo rendimiento en esta situación. Por lo tanto, aconsejamos a los desarrolladores de nuestros grandes servicios que los optimicen para que utilicen todo el servidor.
Básicamente, mejoramos la utilización con la informática elástica. La intensidad del uso de muchos de nuestros grandes servicios, por ejemplo, noticias, funciones de mensajes y nivel web front-end, depende de la hora del día. Reducimos intencionalmente la escala de los servicios en línea durante las horas de silencio y utilizamos los servidores liberados para cargas fuera de línea, por ejemplo, para el aprendizaje automático y las tareas de MapReduce.
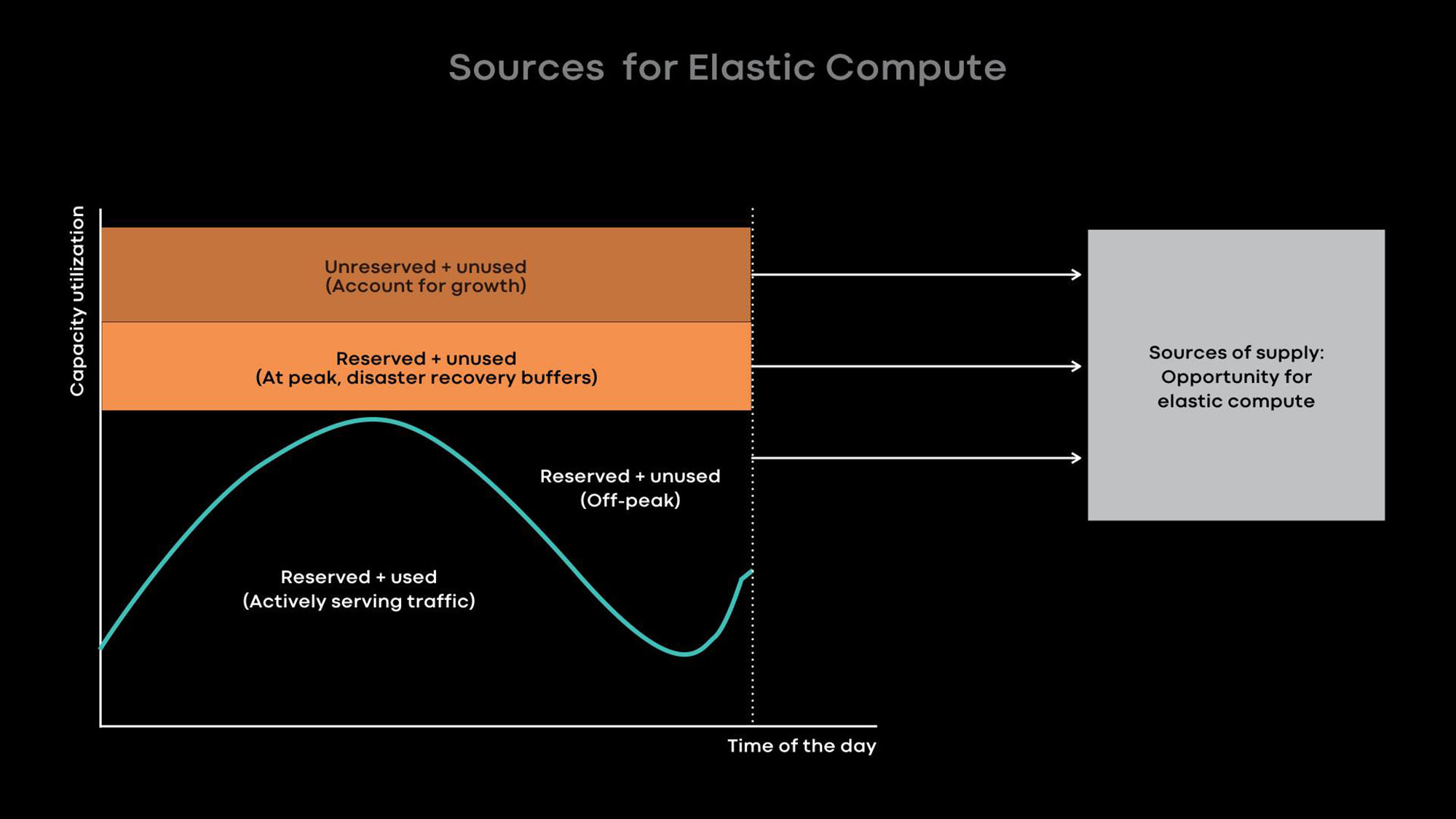
Por experiencia, sabemos que es mejor proporcionar servidores completos como unidades de energía elástica, porque los grandes servicios son tanto los principales donantes como los principales consumidores de energía elástica, y están optimizados para el uso de servidores completos. Cuando el servidor se libera del servicio en línea en las horas de silencio, el agente de recursos entrega el servidor al planificador para uso temporal para que ejecute cargas fuera de línea en él. Si se produce un pico de carga en un servicio en línea, el agente de recursos recupera rápidamente el servidor prestado y, junto con el planificador, lo devuelve al servicio en línea.
Lecciones aprendidas y planes futuros
En los últimos 8 años, hemos desarrollado Tupperware para mantenerse al día con el rápido desarrollo de Facebook. Hablamos de lo que hemos aprendido y esperamos que ayude a otros a gestionar infraestructuras de rápido crecimiento:
- Configure comunicaciones flexibles entre el panel de control y los servidores que administra. Esta flexibilidad permite que el panel de control administre servidores en diferentes centros de datos, ayuda a automatizar el desmantelamiento y el mantenimiento de clústeres y proporciona una distribución dinámica de energía mediante una informática flexible.
- Con un solo panel de control en la región, resulta más conveniente trabajar con tareas y es más fácil administrar una gran flota común de servidores. Tenga en cuenta que el panel de control admite un único punto de entrada, incluso si su estructura interna está dividida por razones de escala o tolerancia a fallas.
- Usando el modelo de complemento, el panel de control puede notificar a las aplicaciones externas de las próximas operaciones de contenedores. Además, los servicios con estado pueden usar la interfaz del complemento para configurar la administración de contenedores. Al usar este modelo de complemento, el panel de control proporciona simplicidad y sirve de manera efectiva a muchos servicios con estado diferentes.
- Creemos que la informática elástica, en la que tomamos servidores completos para trabajos por lotes, aprendizaje automático y otros servicios no urgentes de los servicios de los donantes, es la mejor manera de aumentar la eficiencia del uso de servidores pequeños y eficientes energéticamente.
Recién estamos comenzando a implementar un único parque de servidores común global . Ahora aproximadamente el 20% de nuestros servidores están en el grupo común. Para lograr el 100%, debe resolver muchos problemas, incluido el soporte de un grupo común para sistemas de almacenamiento, la automatización del mantenimiento, la gestión de los requisitos de diferentes clientes, la mejora de la utilización del servidor y la compatibilidad con las cargas de trabajo de aprendizaje automático. No podemos esperar para abordar estas tareas y compartir nuestros éxitos.