Mi nombre es Marko y di una charla en
Gophercon Rusia este año sobre un tipo muy interesante de índices llamados "índices de mapa de bits". Quería compartirlo con la comunidad, no solo en formato de video, sino también como un artículo. Es una versión en inglés y puedes leer ruso
aquí . Por favor disfruta!

Materiales adicionales, diapositivas y todo el código fuente se pueden encontrar aquí:
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Grabación de video original:
¡Comencemos!
Introduccion

Hoy voy a hablar sobre
- Qué índices son
- Qué es un índice de mapa de bits;
- Donde se usa Por qué no se usa donde no se usa.
- Vamos a ver una implementación simple en Go y luego ir al compilador.
- Luego, veremos una implementación un poco menos simple, pero notablemente más rápida, en el ensamblaje Go.
- Y después de eso, voy a abordar los "problemas" de los índices de mapas de bits uno por uno.
- Y finalmente, veremos qué soluciones existentes hay.
Entonces, ¿qué son los índices?
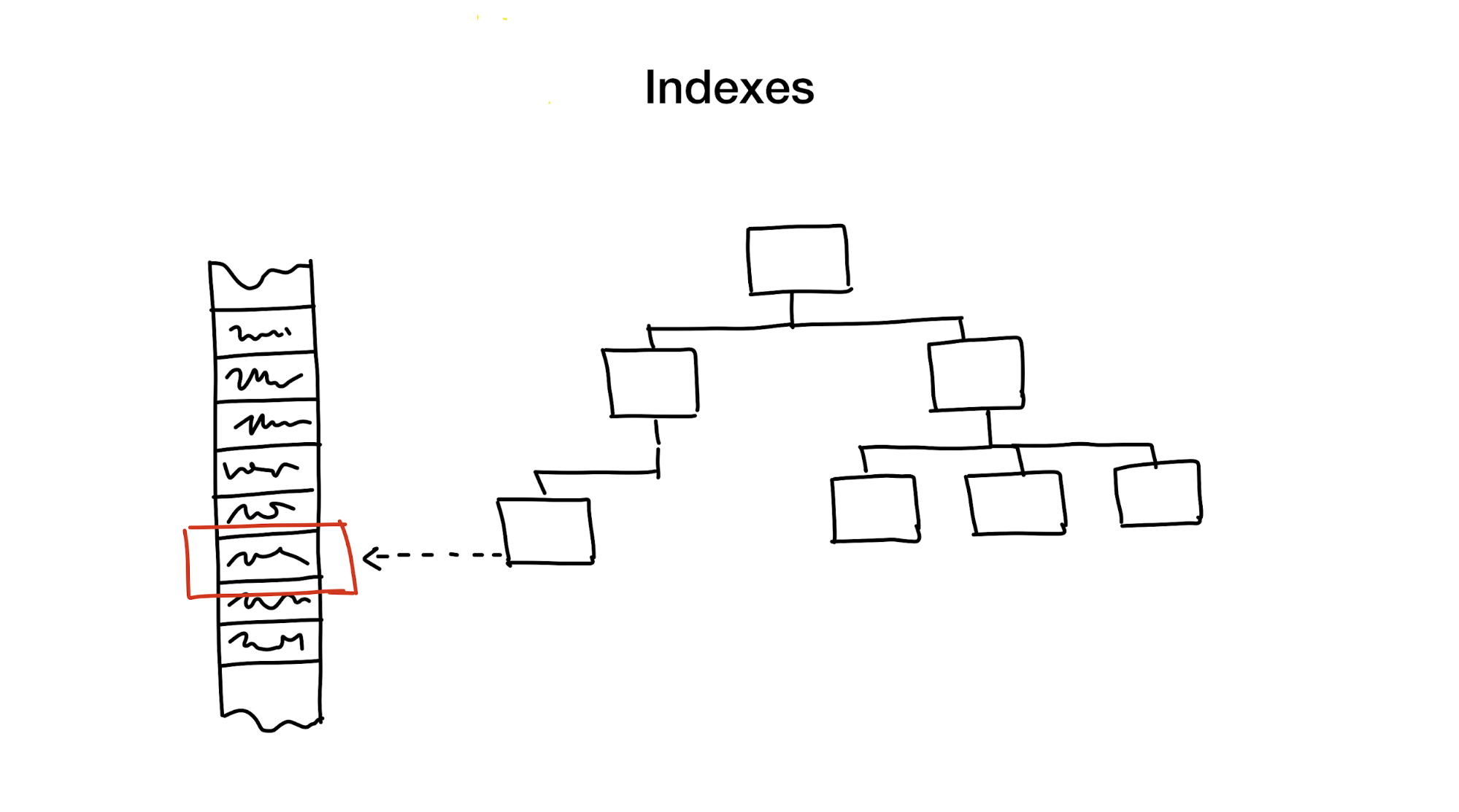
Un índice es una estructura de datos distinta que se mantiene actualizada además de los datos principales, utilizada para acelerar las solicitudes de búsqueda. Sin índices, la búsqueda implicaría revisar todos los datos (en un proceso también conocido como "exploración completa") y ese proceso tiene una complejidad algorítmica lineal. Pero las bases de datos generalmente contienen grandes cantidades de datos, por lo que la complejidad lineal es demasiado lenta. Idealmente, nos gustaría alcanzar velocidades de complejidad logarítmica o incluso constante.
Este es un tema enorme y complejo que involucra muchas compensaciones, pero mirando hacia atrás durante décadas de implementaciones de bases de datos e investigaciones, argumentaría que solo hay unos pocos enfoques que se usan comúnmente:

Primero, está reduciendo el área de búsqueda cortando el área entera en partes más pequeñas, jerárquicamente.
En general, esto se logra utilizando árboles. Es similar a tener cajas de cajas en tu armario. Cada caja contiene materiales que se clasifican en cajas más pequeñas, cada una para un uso específico. Si necesitamos materiales, sería mejor buscar la caja etiquetada "material" en lugar de una caja etiquetada como "cookies".
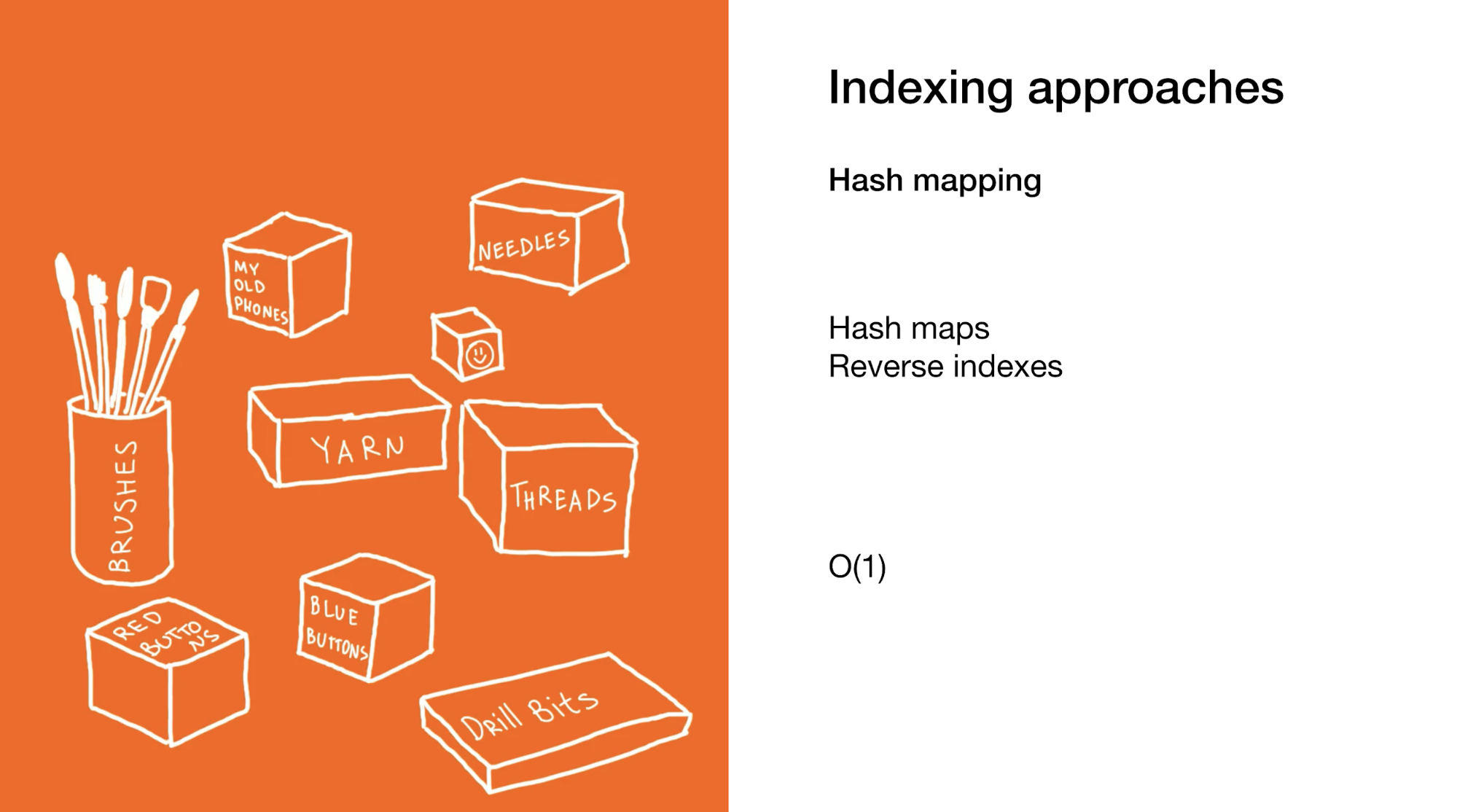
El segundo es identificar instantáneamente un elemento específico o un grupo de elementos como en mapas hash o índices inversos. El uso de mapas hash es similar al del ejemplo anterior, pero utiliza muchos cuadros más pequeños que no contienen cuadros en sí, sino elementos finales.

El tercer enfoque es eliminar la necesidad de buscar en absoluto como en filtros de floración o filtros de cuco. Los filtros Bloom pueden darle una respuesta de inmediato y ahorrarle el tiempo que de lo contrario se dedicaría a la búsqueda.
El último es acelerar la búsqueda haciendo un mejor uso de nuestras capacidades de hardware como en los índices de mapa de bits. Los índices de mapa de bits a veces implican revisar todo el índice, sí, pero se hace de una manera muy eficiente.
Como ya dije, la búsqueda tiene un montón de compensaciones, por lo que a menudo usamos varios enfoques para mejorar aún más la velocidad o para cubrir todos nuestros tipos de búsqueda potenciales.
Hoy me gustaría hablar sobre uno de estos enfoques que es menos conocido: los índices de mapas de bits.
¿Pero quién soy yo para hablar sobre este tema?
Soy un líder de equipo en Badoo (tal vez conoces otra de nuestras marcas: Bumble). ¡Tenemos más de 400 millones de usuarios en todo el mundo y muchas de las funciones que tenemos incluyen la búsqueda de la mejor combinación para usted! Para estas tareas usamos servicios personalizados que usan índices de mapas de bits, entre otros.
Ahora, ¿qué es un índice de mapa de bits?
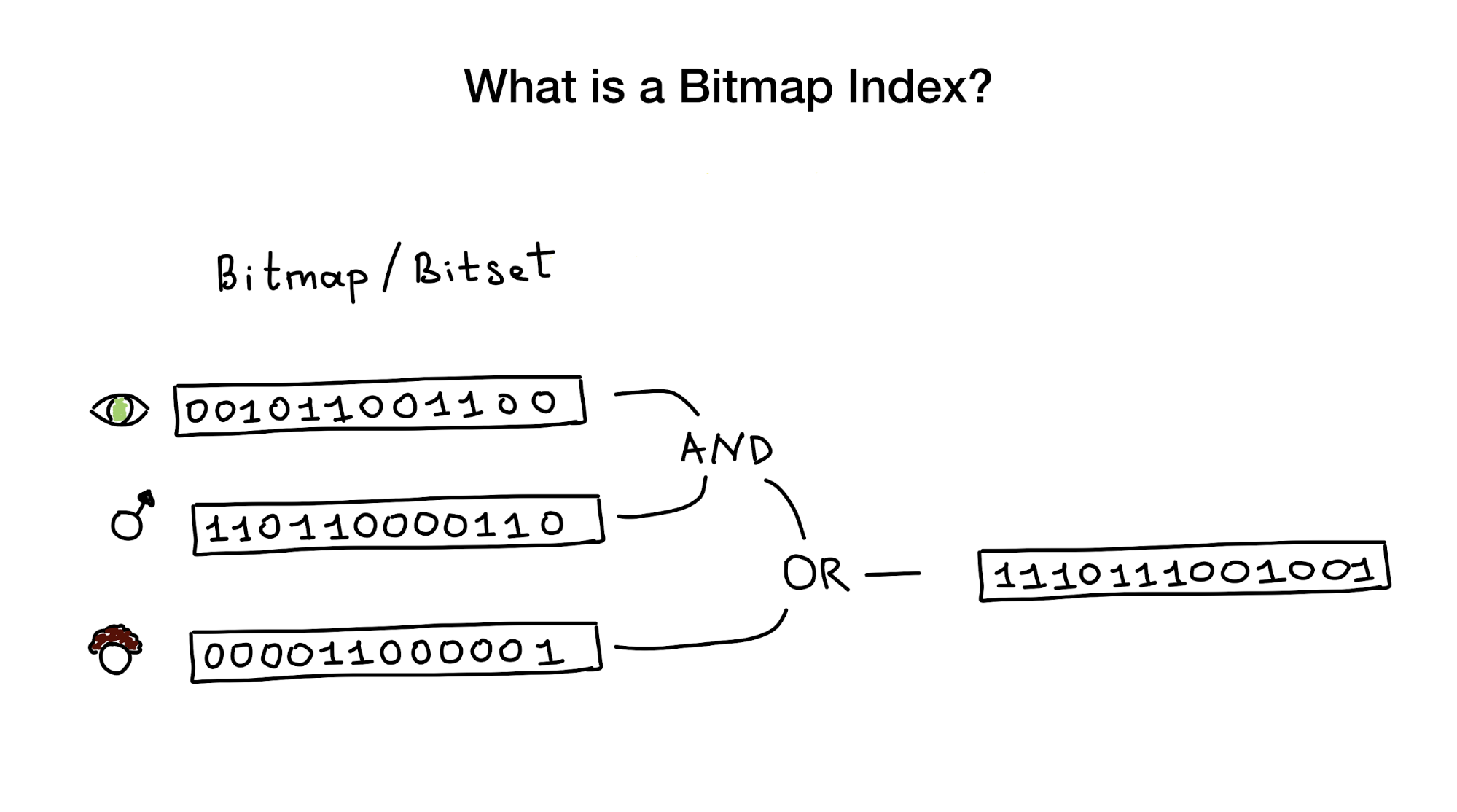
Como su nombre lo indica, los índices de mapa de bits utilizan mapas de bits, también conocidos como conjuntos de bits, para implementar el índice de búsqueda. Desde el punto de vista de pájaro, este índice consta de uno o varios mapas de bits que representan entidades (por ejemplo, personas) y sus parámetros (por ejemplo, edad o color de ojos) y un algoritmo para responder consultas de búsqueda utilizando operaciones bit a bit como AND, OR, NOT, etc. .

Los índices de mapa de bits se consideran muy útiles y de alto rendimiento si tiene una búsqueda que tiene que combinar consultas de varias columnas con baja cardinalidad (tal vez, color de ojos o estado civil) frente a algo como la distancia al centro de la ciudad que tiene una cardinalidad infinita.
Pero más adelante en el artículo mostraré que los índices de mapas de bits incluso funcionan con columnas de alta cardinalidad.
Veamos el ejemplo más simple de un índice de mapa de bits ...

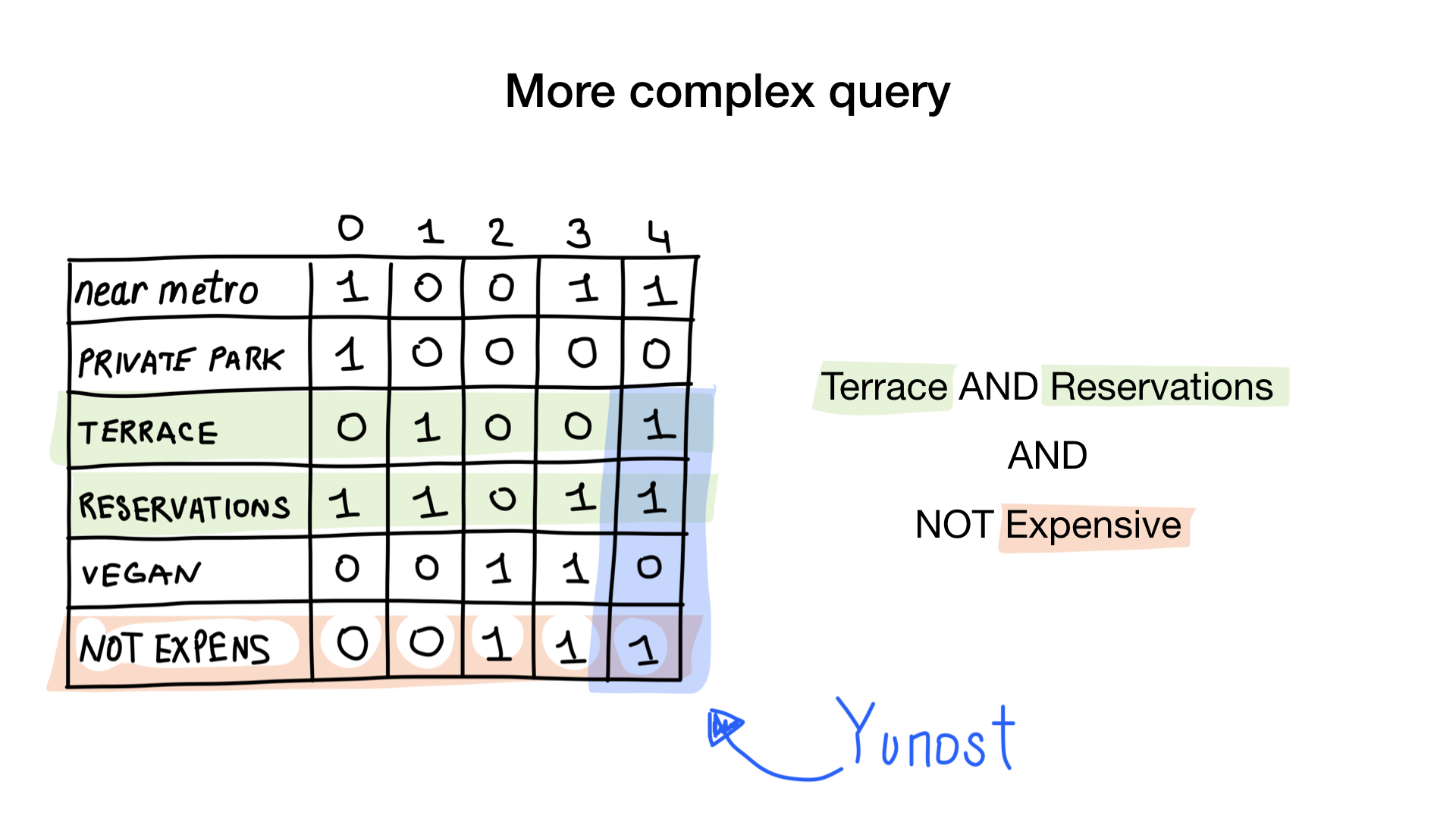
Imagine que tenemos una lista de restaurantes de Moscú con características binarias:
- cerca del metro
- tiene estacionamiento privado
- tiene terraza
- acepta reservas
- vegano amigable
- caro
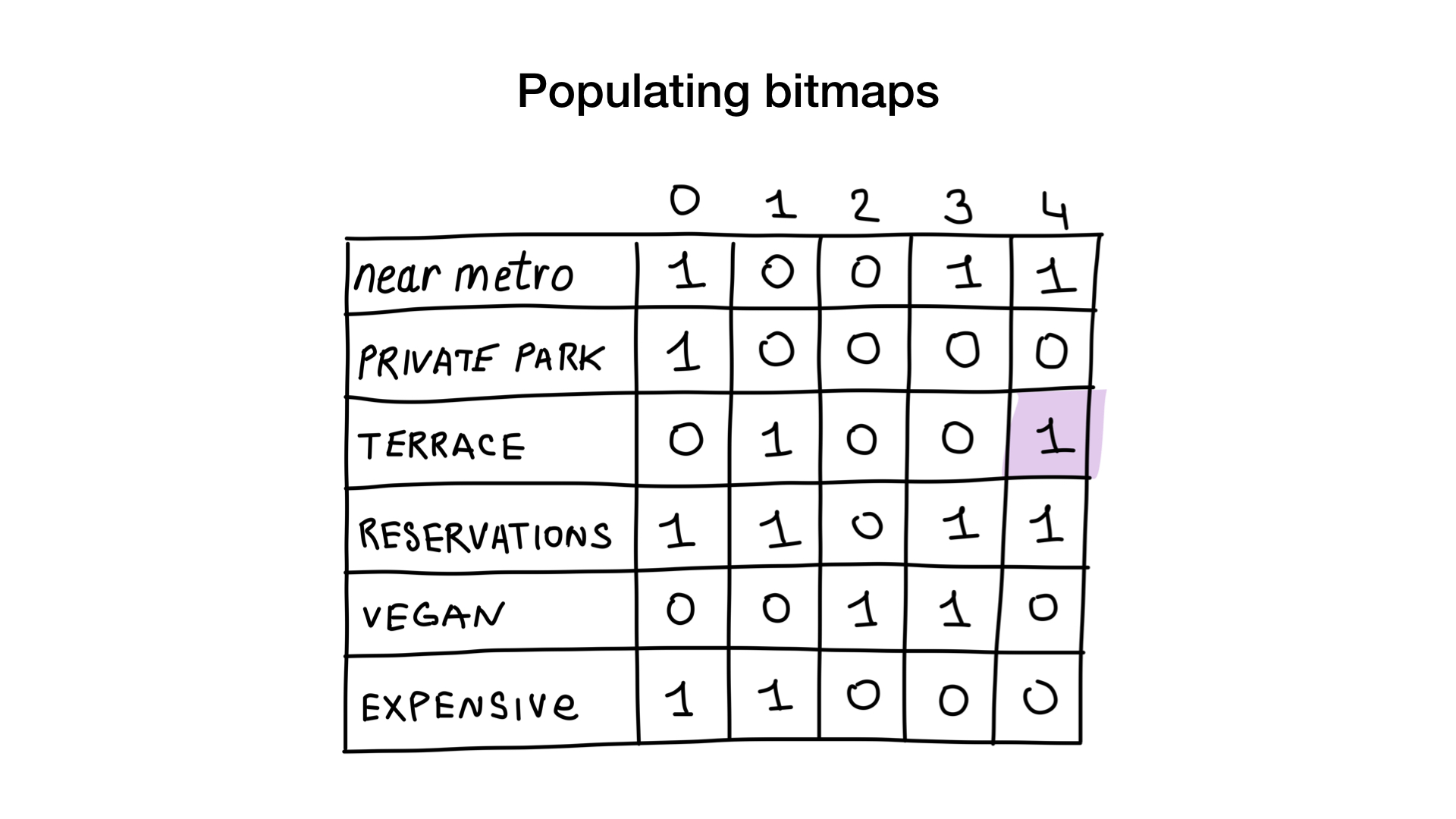
Vamos a dar a cada restaurante un índice a partir de 0 y asignar 6 mapas de bits (uno para cada característica). Luego, rellenaríamos estos mapas de bits según si el restaurante tiene una característica específica o no. Si el restaurante número 4 tiene la terraza, el bit número 4 en el mapa de bits "terraza" se establecerá en 1 (0 si no).

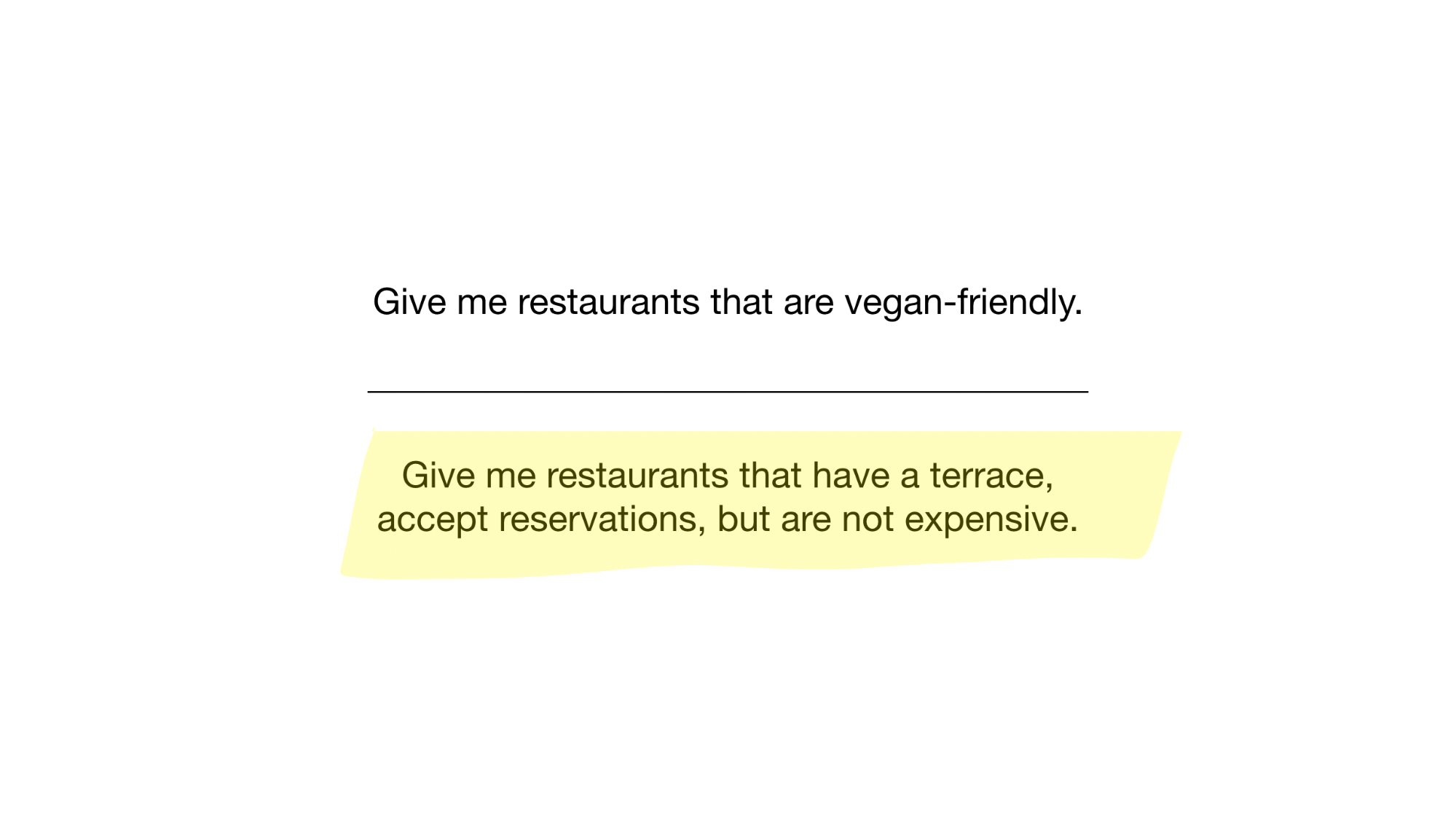
Ahora tenemos el índice de mapa de bits más simple posible que podemos usar para responder preguntas como
- Dame restaurantes que sean veganos
- Dame restaurantes con una terraza que acepten reservas, pero que no sean caras.


Como? A ver La primera pregunta es simple. Simplemente tomamos un mapa de bits "apto para veganos" y devolvemos todos los índices que tienen un bit establecido.

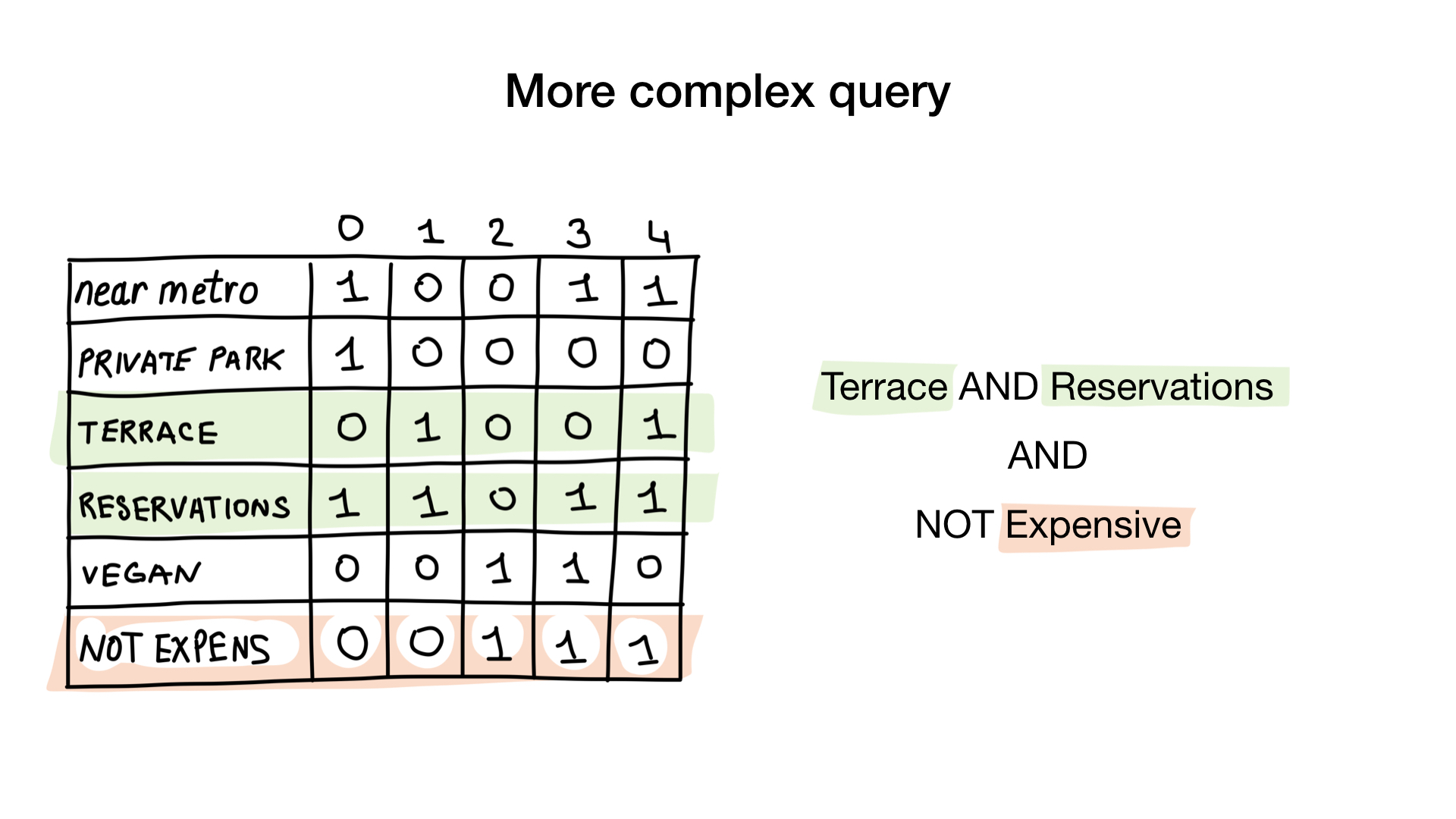
La segunda pregunta es un poco más complicada. Utilizaremos la operación bit a bit NO en mapas de bits "caros" para obtener restaurantes no caros, Y con el mapa de bits "aceptar reserva" y Y con "tiene mapa de bits de terraza". El mapa de bits resultante consistirá en restaurantes que tienen todas estas características que queríamos. Aquí vemos que solo Yunost tiene todas estas características.
Esto puede parecer un poco teórico, pero no se preocupe, llegaremos al código en breve.
Donde se usan los índices de mapa de bits

Si busca en Google "índice de mapa de bits", el 90% de los resultados apuntará a Oracle DB, que tiene índices básicos de mapa de bits. Pero, seguramente, otros DBMS también usan índices de mapa de bits, ¿no? No, en realidad no lo hacen. Repasemos a los sospechosos habituales uno por uno.


- Pero hay un nuevo chico en la cuadra: Pilosa. Pilosa es un nuevo DBMS escrito en Go (observe que no hay R, no es relacional) que basa todo en índices de mapas de bits. Y hablaremos de Pilosa más tarde.
Implementación en marcha
Pero por que? ¿Por qué se usan tan raramente los índices de mapa de bits? Antes de responder a esa pregunta, me gustaría guiarlo a través de la implementación básica del índice de mapa de bits en Go.

El mapa de bits se representa como un fragmento de memoria. En Go, usemos una porción de bytes para eso.
Tenemos un mapa de bits por característica de restaurante. Cada bit en un mapa de bits representa si un restaurante en particular tiene esta característica o no.

Necesitaríamos dos funciones auxiliares. Uno se usa para llenar el mapa de bits al azar, pero con una probabilidad específica de tener la característica. Por ejemplo, creo que hay muy pocos restaurantes que no aceptan reservas y aproximadamente el 20% son veganos.
Otra función nos dará la lista de restaurantes de un mapa de bits.


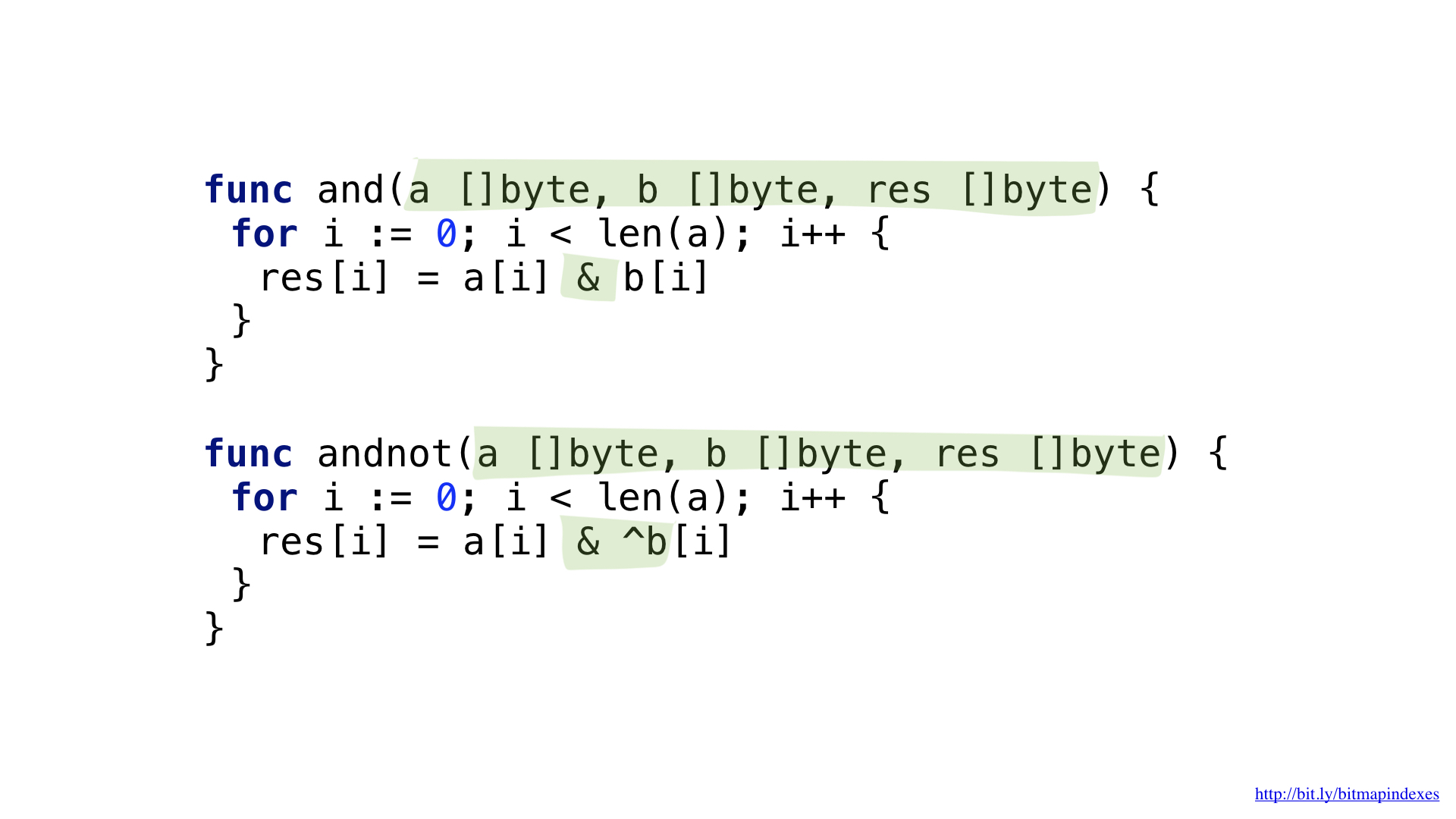
Para responder a la pregunta "dame restaurantes con una terraza que acepten reservas pero no son caros", necesitaríamos dos operaciones: NO y AND.
Podemos simplificar ligeramente el código introduciendo operaciones complejas Y NO.
Tenemos las funciones para cada uno de estos. Ambas funciones pasan por nuestros segmentos tomando los elementos correspondientes de cada uno, haciendo la operación y escribiendo el resultado en el segmento resultante.
Y ahora podemos usar nuestros mapas de bits y nuestras funciones para obtener la respuesta.

El rendimiento no es tan bueno aquí a pesar de que nuestras funciones son realmente simples y ahorramos mucho en asignaciones al no devolver un nuevo segmento en cada invocación de función.
Después de algunos perfiles con pprof, noté que el compilador de go perdió una de las optimizaciones más básicas: la función en línea.
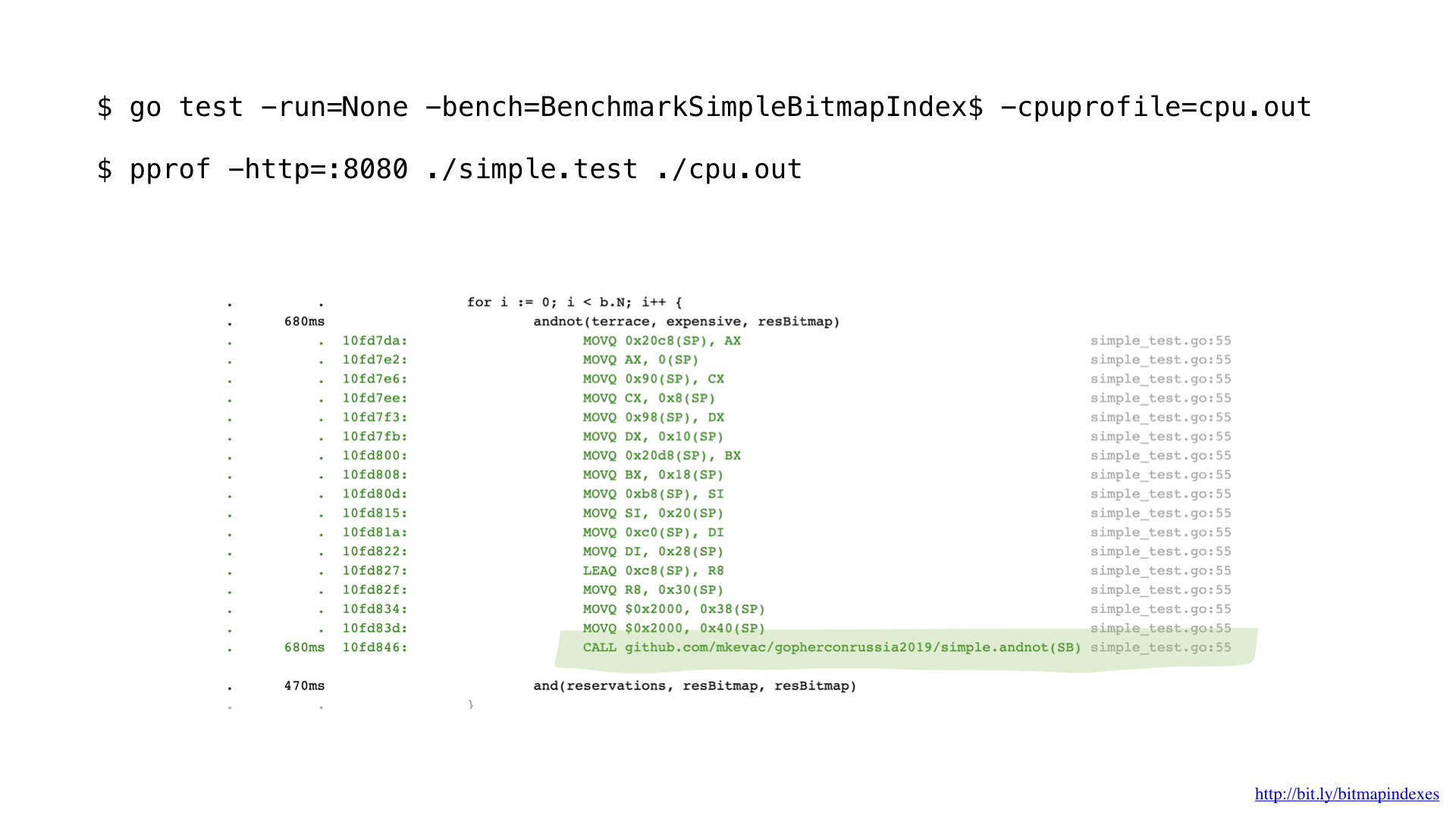
Verá, el compilador Go teme patológicamente los bucles a través de sectores y se niega a incorporar cualquier función que tenga esos.
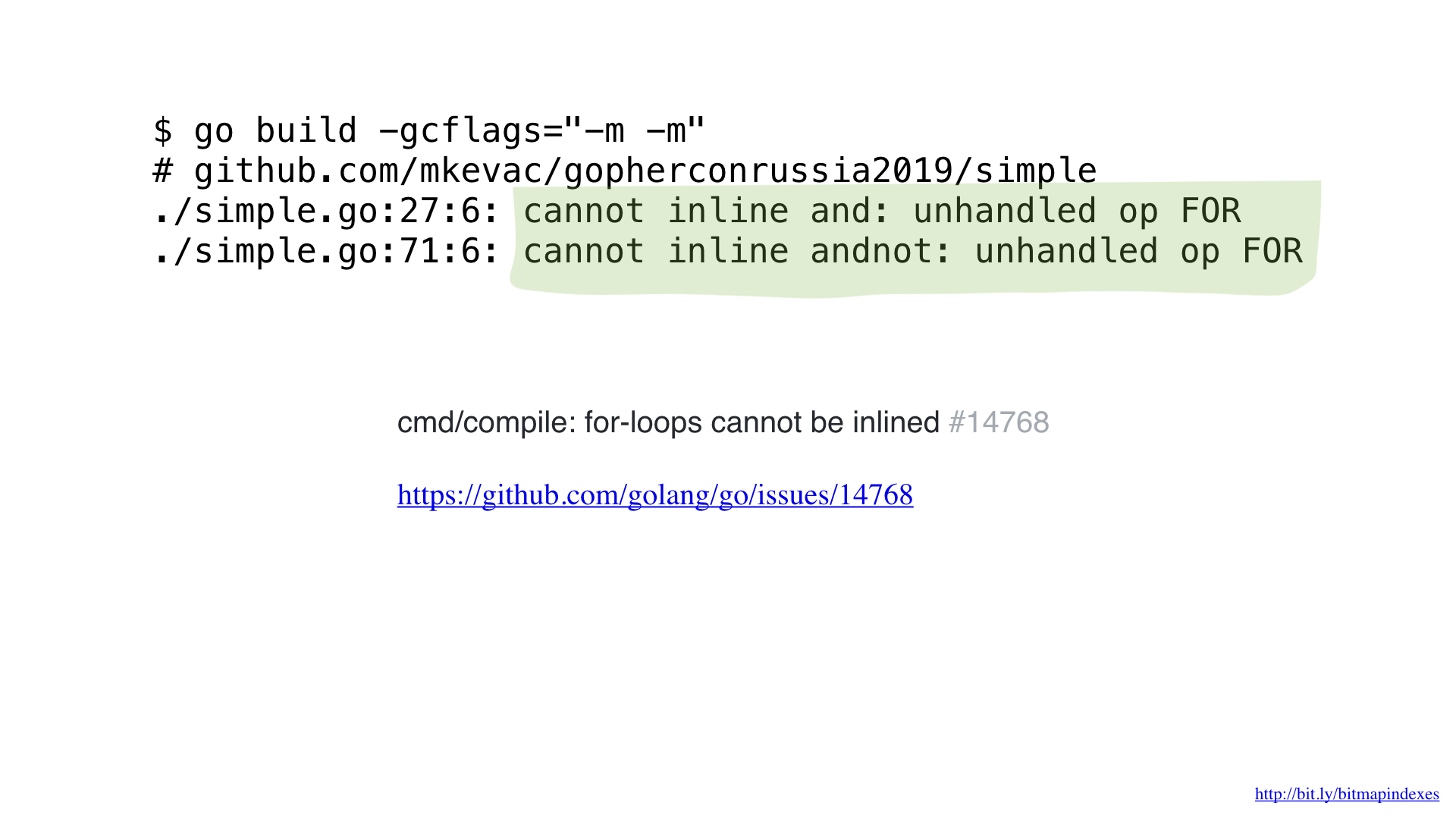
Pero no les tengo miedo y puedo engañar al compilador usando goto para mi bucle.


Como puede ver, la alineación nos ahorró unos 2 microsegundos. No esta mal!

Otro cuello de botella es fácil de detectar cuando observa de cerca la salida del ensamblaje. Ir compilador incluyó controles de rango en nuestro bucle Go es un lenguaje seguro y el compilador teme que mis tres mapas de bits puedan tener longitudes diferentes y que pueda haber un desbordamiento del búfer.
Calmemos el compilador y demostremos que todos mis mapas de bits tienen la misma longitud. Para hacer eso, podemos agregar una simple verificación al comienzo de la función.
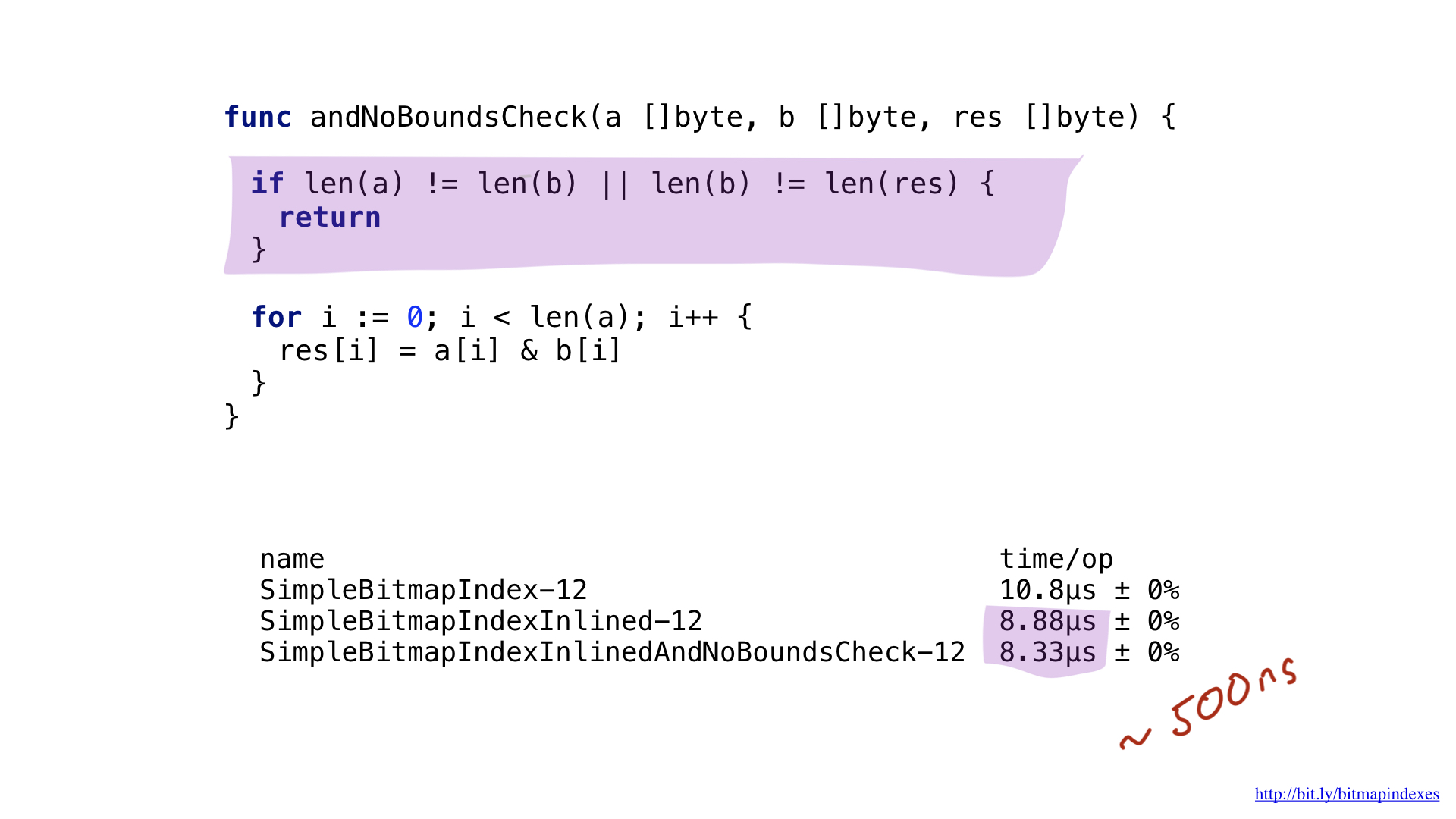
Con esta comprobación, go compiler saltará felizmente las comprobaciones de rango y ahorraremos unos pocos nanosegundos.
Implementación en montaje
Muy bien, así que logramos exprimir un poco más el rendimiento con nuestra implementación simple, pero este resultado es mucho peor de lo que es posible con el hardware actual.
Verá, lo que estamos haciendo son operaciones bit a bit muy básicas y nuestras CPU son muy efectivas con ellas.
Desafortunadamente, estamos alimentando nuestra CPU con muy pequeños trozos de trabajo. Nuestra función realiza operaciones byte a byte. Podemos ajustar fácilmente nuestra implementación para trabajar con fragmentos de 8 bytes mediante el uso de segmentos de uint64.

Como puede ver aquí, obtuvimos un rendimiento de aproximadamente 8x para un tamaño de lote de 8x, por lo que las ganancias de rendimiento son bastante lineales.
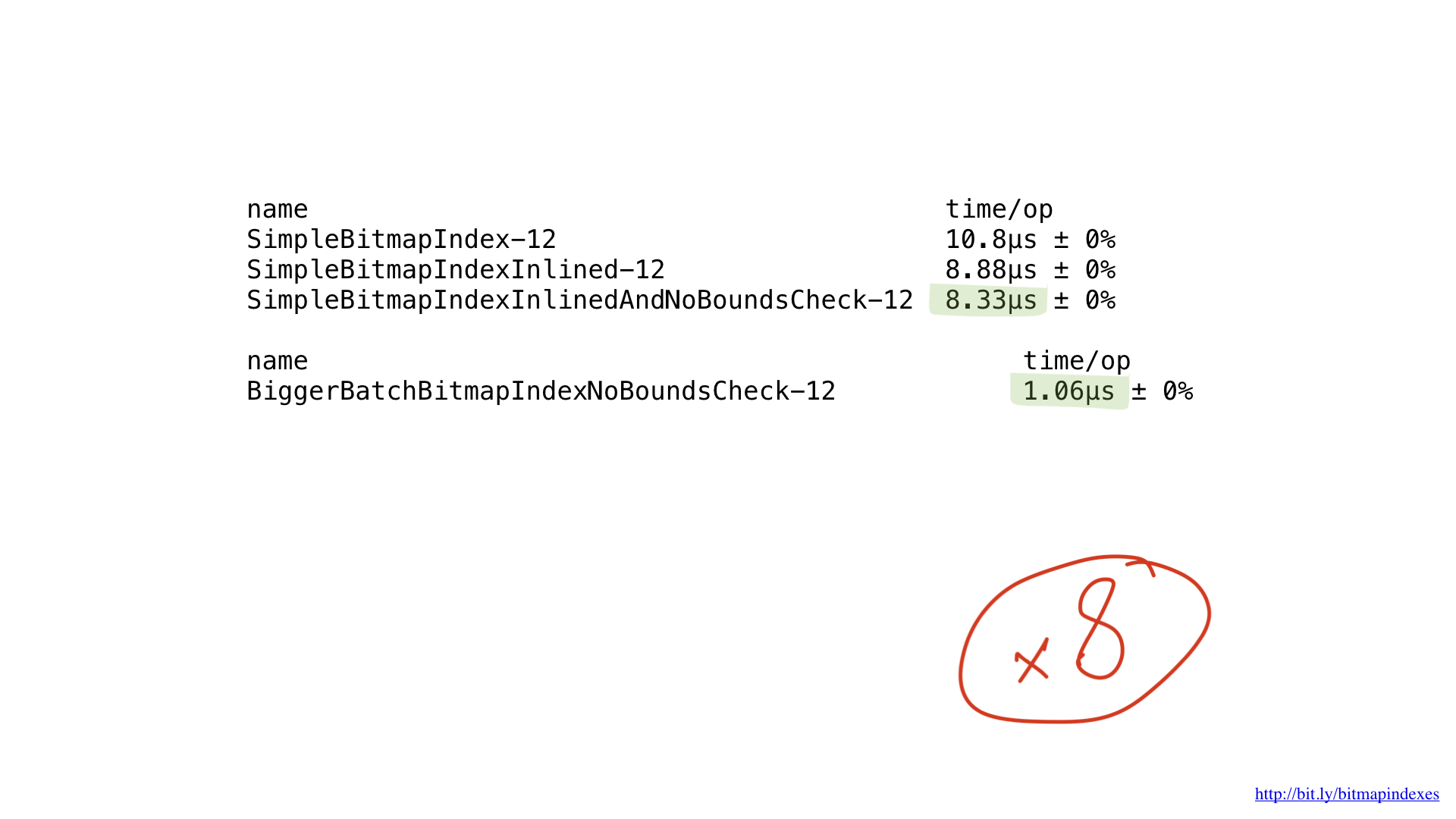

Pero este no es el final del camino. Nuestras CPU tienen la capacidad de trabajar con fragmentos de 16 bytes, 32 bytes e incluso con fragmentos de 64 bytes. Estas operaciones se denominan SIMD (Datos múltiples de instrucción única) y el proceso de uso de tales operaciones de CPU se denomina vectorización.
Desafortunadamente, el compilador Go no es muy bueno con la vectorización. Y lo único que podemos hacer hoy en día para vectorizar nuestro código es usar el ensamblaje Go y agregar estas instrucciones SIMD nosotros mismos.

Ir a la asamblea es una bestia extraña. Se podría pensar que el ensamblaje es algo que está vinculado a la arquitectura para la que está escribiendo, pero el ensamblaje de Go es más como IRL (lenguaje de representación intermedio): es independiente de la plataforma. Rob Pike dio una increíble charla sobre esto hace unos años.
Además, Go utiliza un formato plan9 inusual que es diferente a los formatos AT&T e Intel.

Es seguro decir que escribir el código de ensamblaje Go no es divertido.
Afortunadamente para nosotros, ya hay dos herramientas de nivel superior para ayudar a escribir el ensamblaje Go: PeachPy y avo. Ambos generan el ensamblaje go a partir de un código de nivel superior escrito en Python y Go respectivamente.

Estas herramientas simplifican cosas como la asignación de registros y los bucles y, en general, reducen la complejidad de ingresar al ámbito de la programación de ensamblaje para Go.
Usaremos evitar para esta publicación para que nuestros programas se vean casi como el código Go normal.

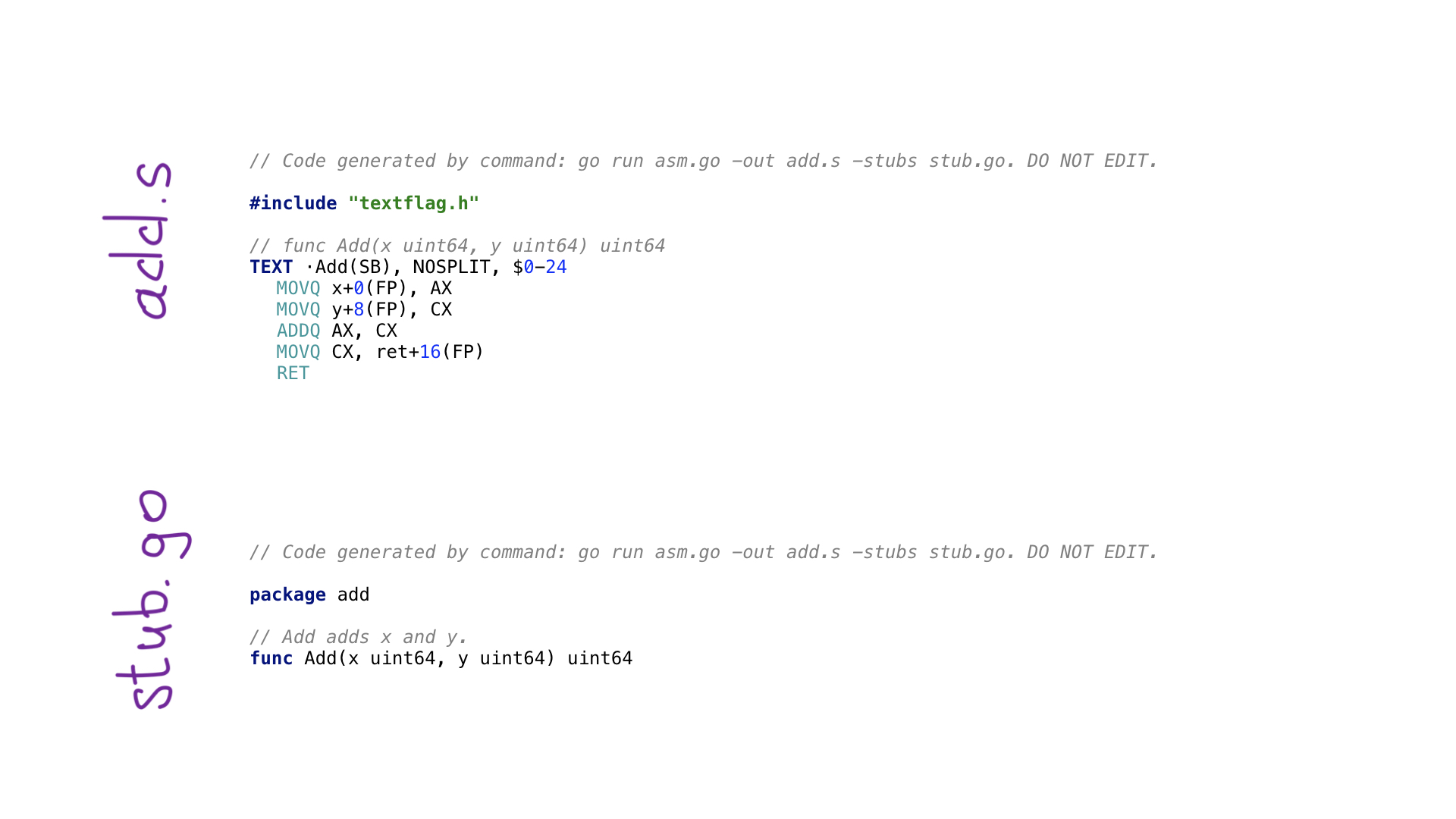
Este es el ejemplo más simple de un programa avo. Tenemos una función main () que define una función llamada Add () que agrega dos números. Hay funciones auxiliares para obtener parámetros por nombre y obtener uno de los registros generales disponibles. Aquí hay funciones para cada operación de ensamblaje como ADDQ, y hay funciones auxiliares para guardar el resultado de un registro en el valor resultante.

Llamar a go generate ejecutará este programa avo y se crearán dos archivos
- add.s con código de ensamblaje generado
- stub.go con encabezados de función que son necesarios para conectar nuestro código de inicio y ensamblaje
Ahora que hemos visto lo que hace avo, veamos nuestras funciones. He implementado versiones escalares y SIMD (vector) de nuestras funciones.
Veamos primero cómo se ve la versión escalar.

Como en un ejemplo anterior, podemos solicitar un registro general y evitar darnos el correcto que está disponible. No necesitamos rastrear compensaciones en bytes para nuestros argumentos, evitando esto para nosotros.

Anteriormente cambiamos de bucles a usar goto por razones de rendimiento y para engañar al compilador. Aquí, estamos usando goto (saltos) y etiquetas desde el principio porque los bucles son construcciones de nivel superior. En montaje solo tenemos saltos.

Otro código debería ser bastante claro. Emulamos el ciclo con saltos y etiquetas, tomamos una pequeña parte de nuestros datos de nuestros dos mapas de bits, lo combinamos con una de las operaciones a nivel de bits e insertamos el resultado en el mapa de bits resultante.

Este es un código asm resultante que obtenemos. No tuvimos que calcular desplazamientos y tamaños (en verde), no tuvimos que lidiar con registros específicos (en rojo).
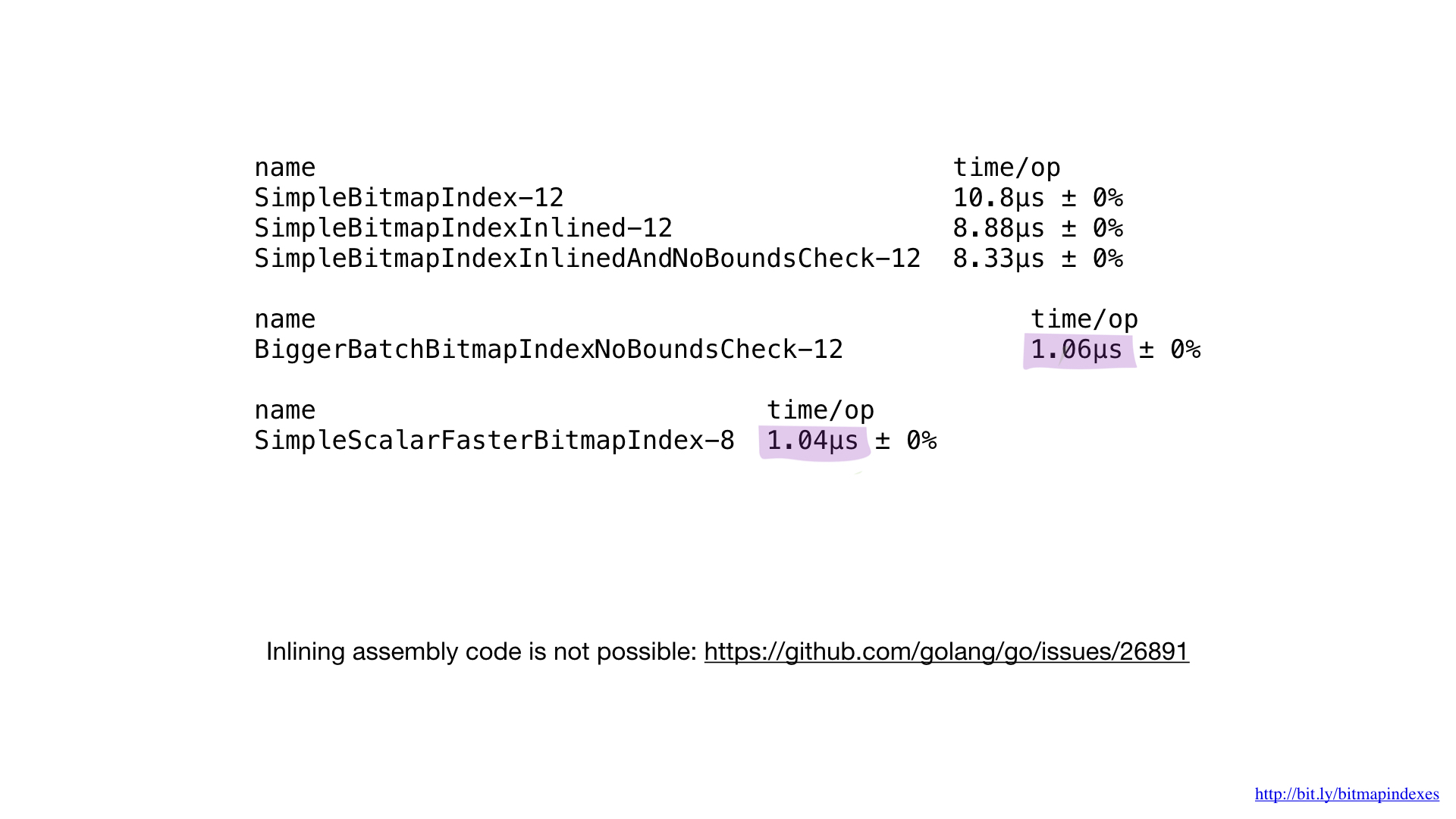
Si comparamos esta implementación en ensamblaje con la mejor versión anterior escrita, veríamos que el rendimiento es el mismo que el esperado. No hicimos nada diferente.
Desafortunadamente, no podemos obligar al compilador Go a incorporar nuestras funciones escritas en asm. Carece completamente de soporte y la solicitud de esta característica ha existido desde hace algún tiempo. Es por eso que las funciones asm pequeñas en go no dan ningún beneficio. Necesita escribir funciones más grandes, usar nuevos paquetes matemáticos / bits u omitir asm por completo.
Escribamos la versión vectorial de nuestras funciones ahora.

Elegí usar AVX2, por lo que vamos a usar fragmentos de 32 bytes. Es muy similar al escalar en estructura. Cargamos parámetros, solicitamos registros generales, etc.
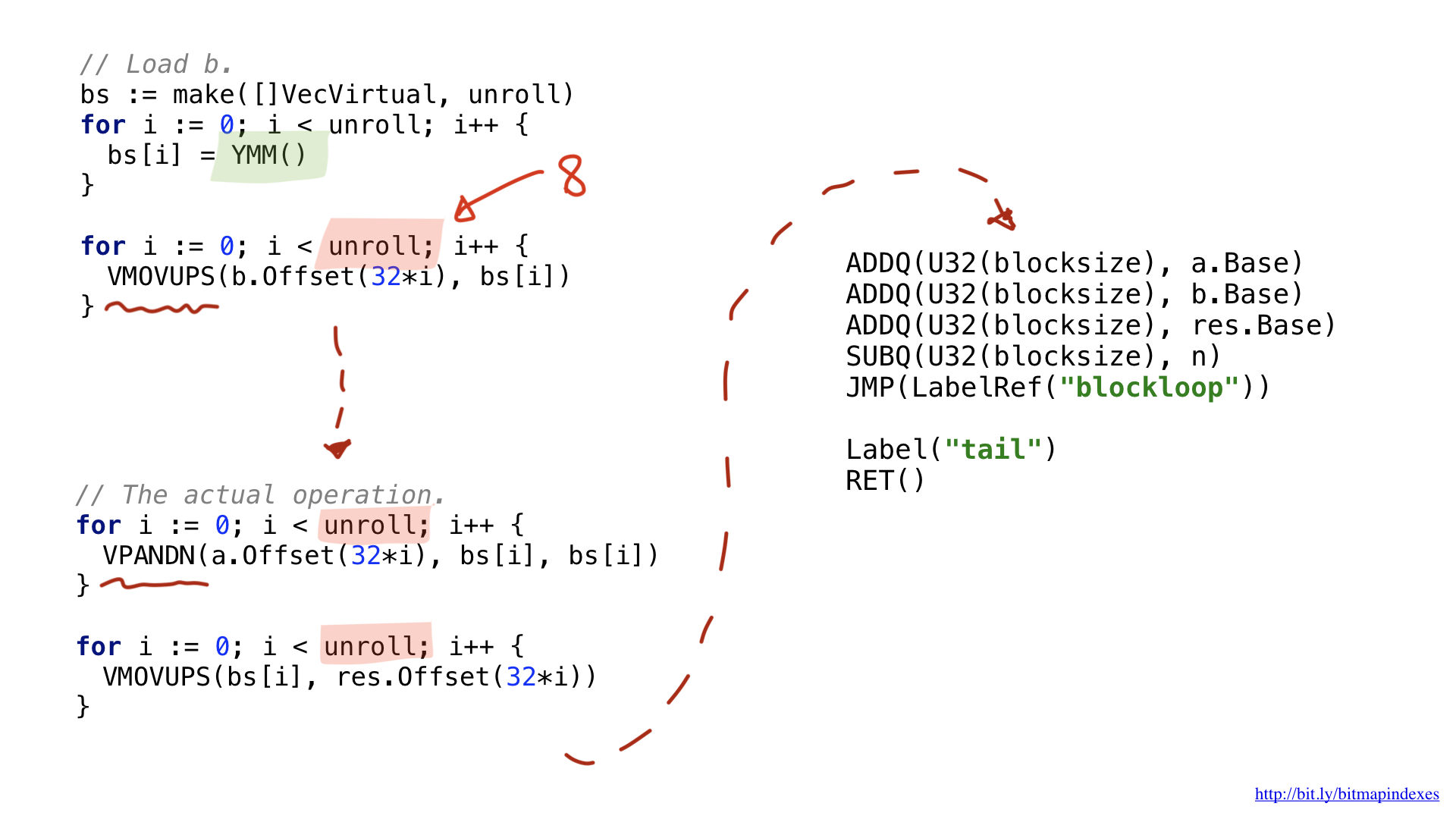
Uno de los cambios tiene que ver con el hecho de que las operaciones vectoriales utilizan registros anchos específicos. Para 32 bytes tienen el prefijo Y, es por eso que ves YMM () allí. Para 64 bytes habrían tenido el prefijo Z.
Otra diferencia tiene que ver con la optimización que realicé llamada desenrollamiento o desenrollamiento de bucle. Elegí desenrollar parcialmente nuestro bucle y hacer 8 operaciones de bucle en secuencia antes de regresar. Esta técnica acelera el código al reducir las ramas que tenemos y está bastante limitado por la cantidad de registros que tenemos disponibles.
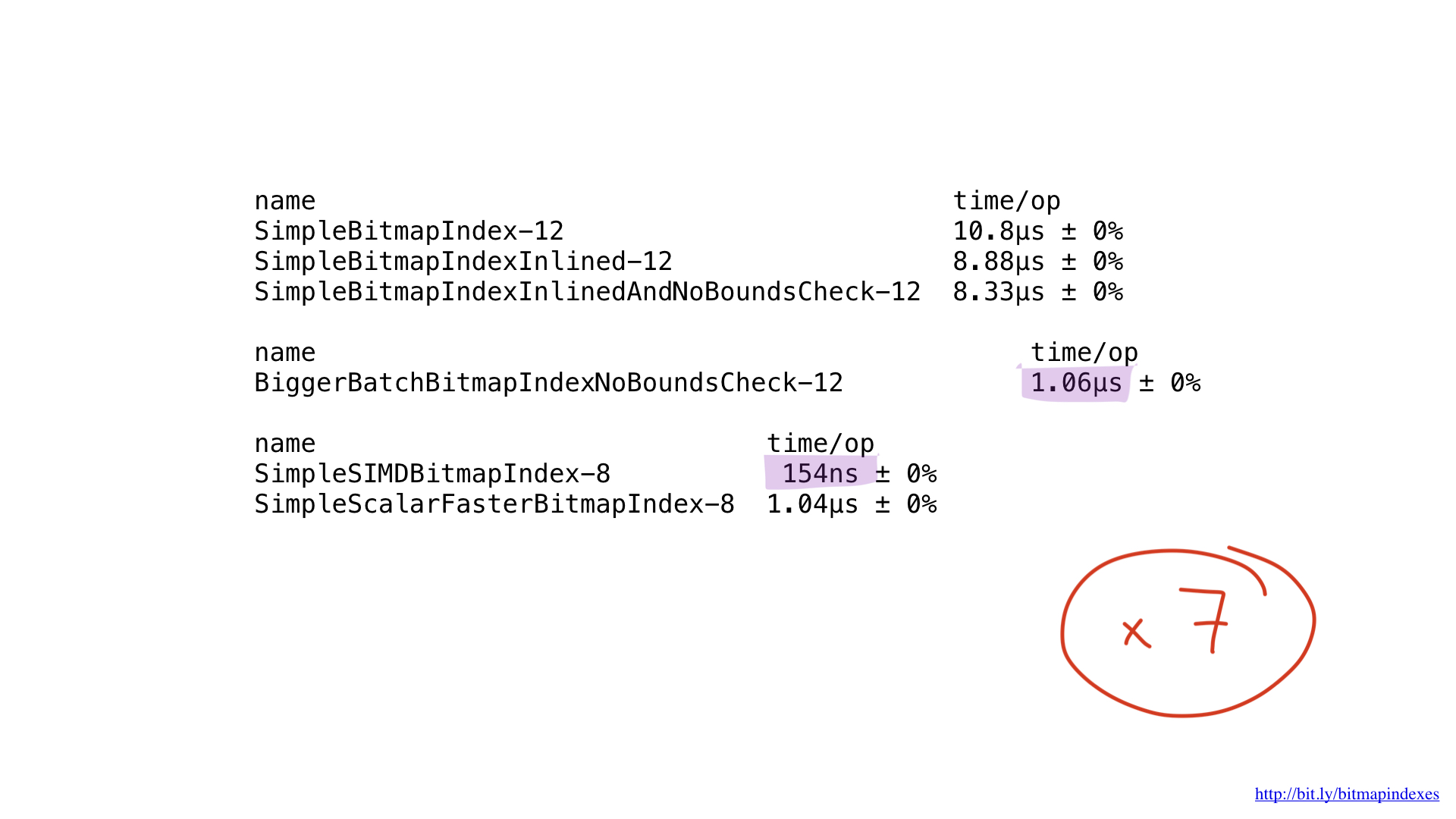
En cuanto al rendimiento ... es increíble. Obtuvimos una mejora de aproximadamente 7 veces en comparación con la mejor anterior. Bastante impresionante, ¿verdad?
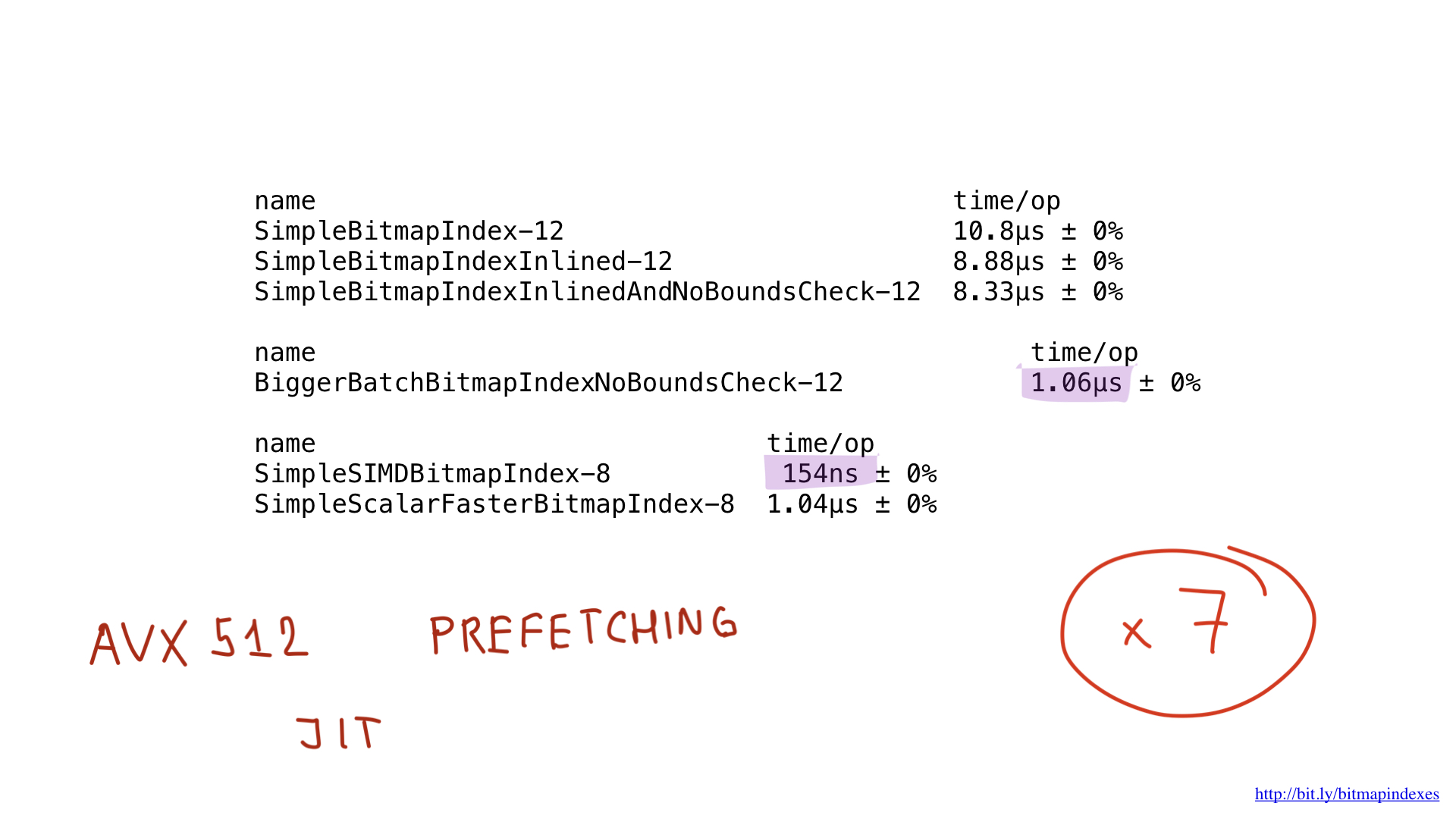
Debería ser posible mejorar estos resultados aún más utilizando AVX512, captando previamente y tal vez incluso utilizando la compilación JIT (justo a tiempo) en lugar del generador de planes de consulta "manual", pero eso sería un tema para una publicación totalmente diferente.
Problemas de índice de mapa de bits
Ahora que hemos visto la implementación básica y la impresionante velocidad de implementación de asm, hablemos del hecho de que los índices de mapa de bits no se usan mucho. ¿Por qué es eso?

Las publicaciones más antiguas nos dan estas tres razones. Pero los recientes y yo argumentamos que ya se han "arreglado" o tratado. No voy a entrar en muchos detalles sobre esto aquí porque no tenemos mucho tiempo, pero ciertamente vale la pena echar un vistazo rápido.
Problema de alta cardinalidad
Entonces, nos han dicho que los índices de mapas de bits son factibles solo para campos de baja cardinalidad. es decir, campos que tienen pocos valores distintos, como género o color de ojos. La razón es que la representación común (un bit por valor distinto) puede ser bastante grande para valores de alta cardinalidad. Y, como resultado, el mapa de bits puede volverse enorme incluso si está escasamente poblado.
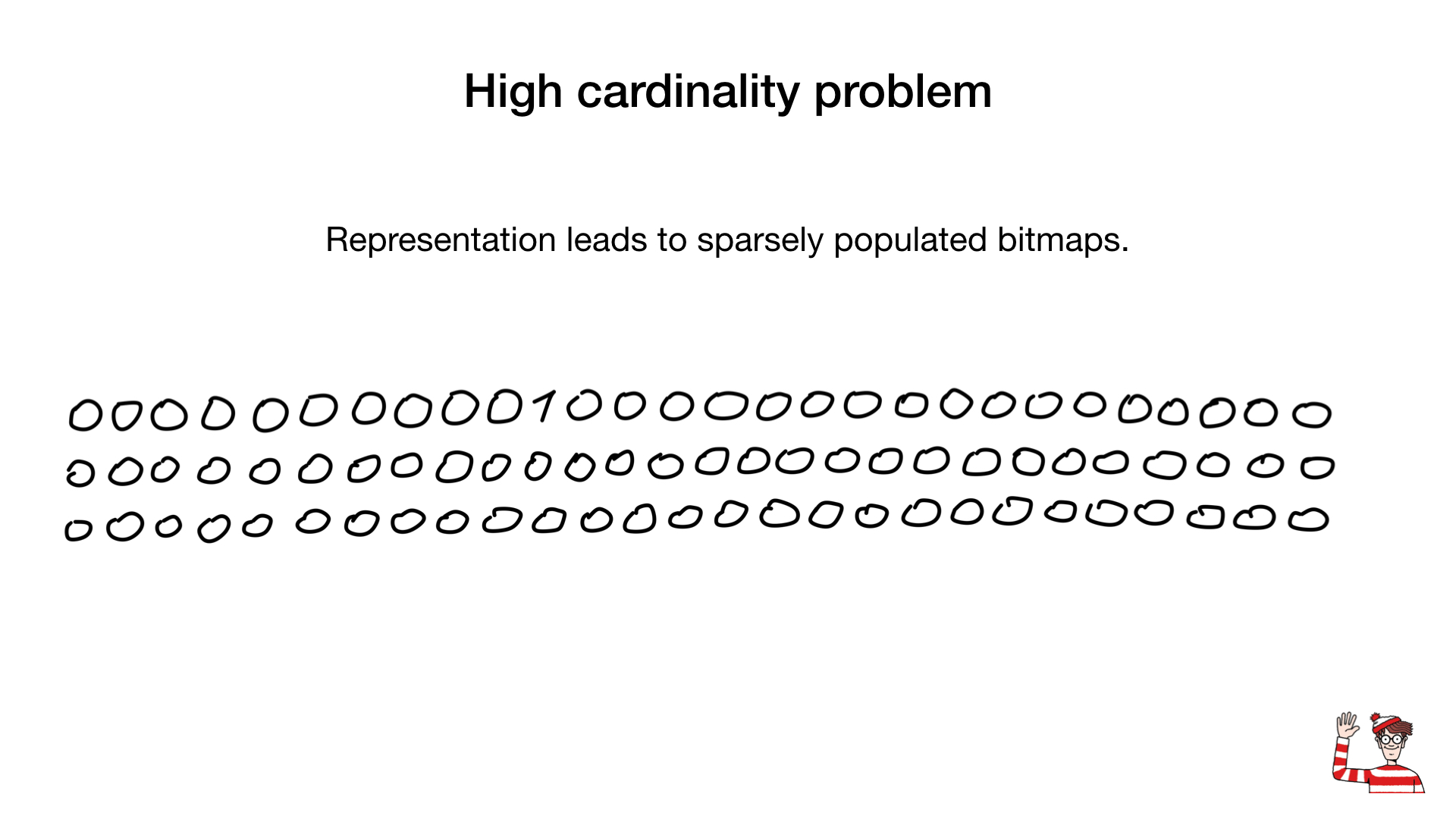
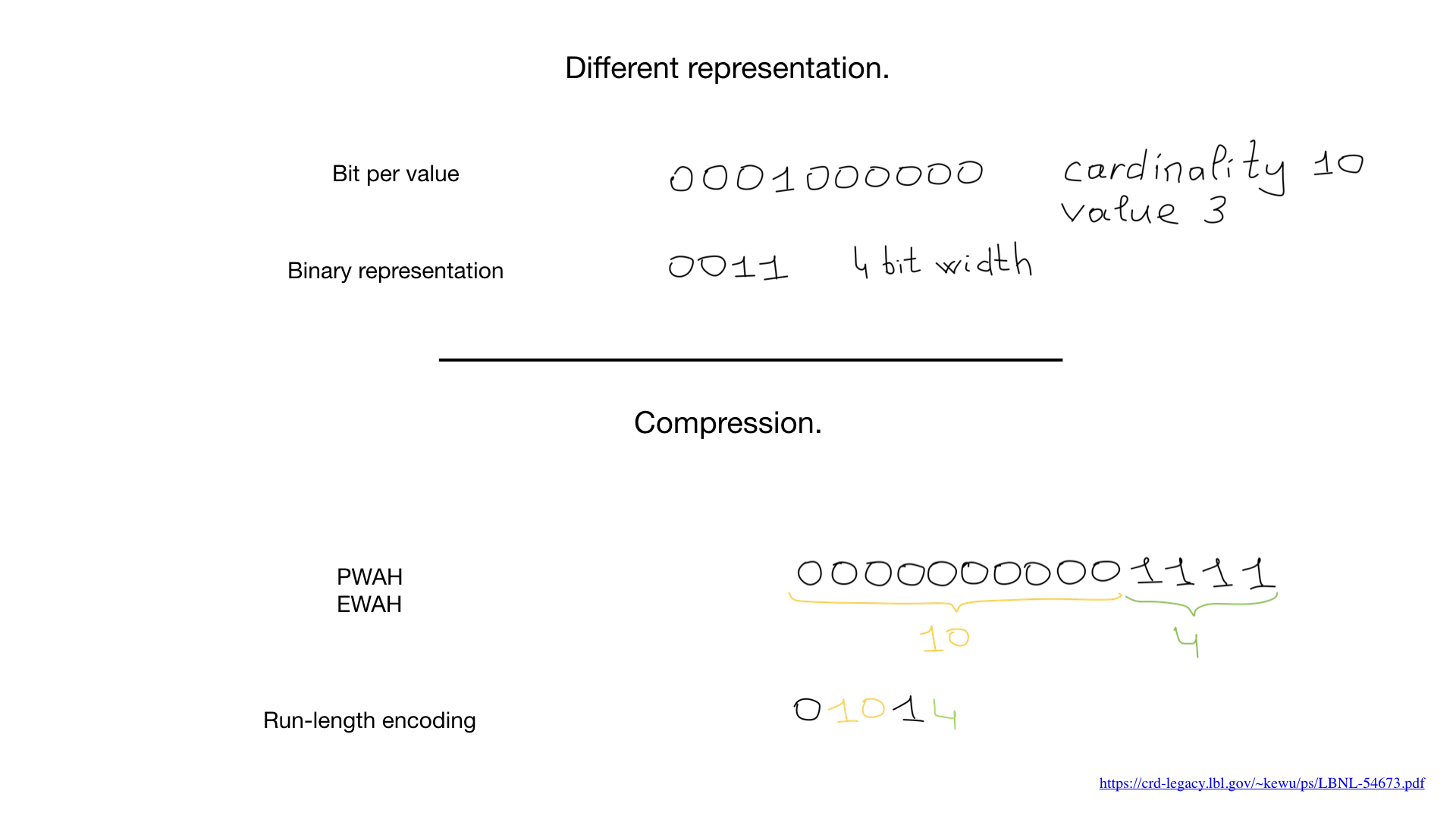
A veces, se puede usar una representación diferente para estos campos, como una representación de número binario como se muestra aquí, pero el mayor cambio de juego es una compresión. Los científicos han creado asombrosos algoritmos de compresión. Casi todos se basan en algoritmos de longitud de ejecución generalizados, pero lo que es más sorprendente es que no necesitamos descomprimir mapas de bits para realizar operaciones bit a bit en ellos. Las operaciones normales a nivel de bits funcionan en mapas de bits comprimidos.

Recientemente, hemos visto enfoques híbridos que aparecen como "mapas de bits rugientes". Los mapas de bits rugientes usan tres representaciones separadas para mapas de bits: mapas de bits, matrices y "ejecuciones de bits" y equilibran el uso de estas tres representaciones tanto para maximizar la velocidad como para minimizar el uso de memoria.
Se pueden encontrar mapas de bits en algunas de las aplicaciones más utilizadas y existen implementaciones para muchos idiomas, incluidas varias implementaciones para Go.
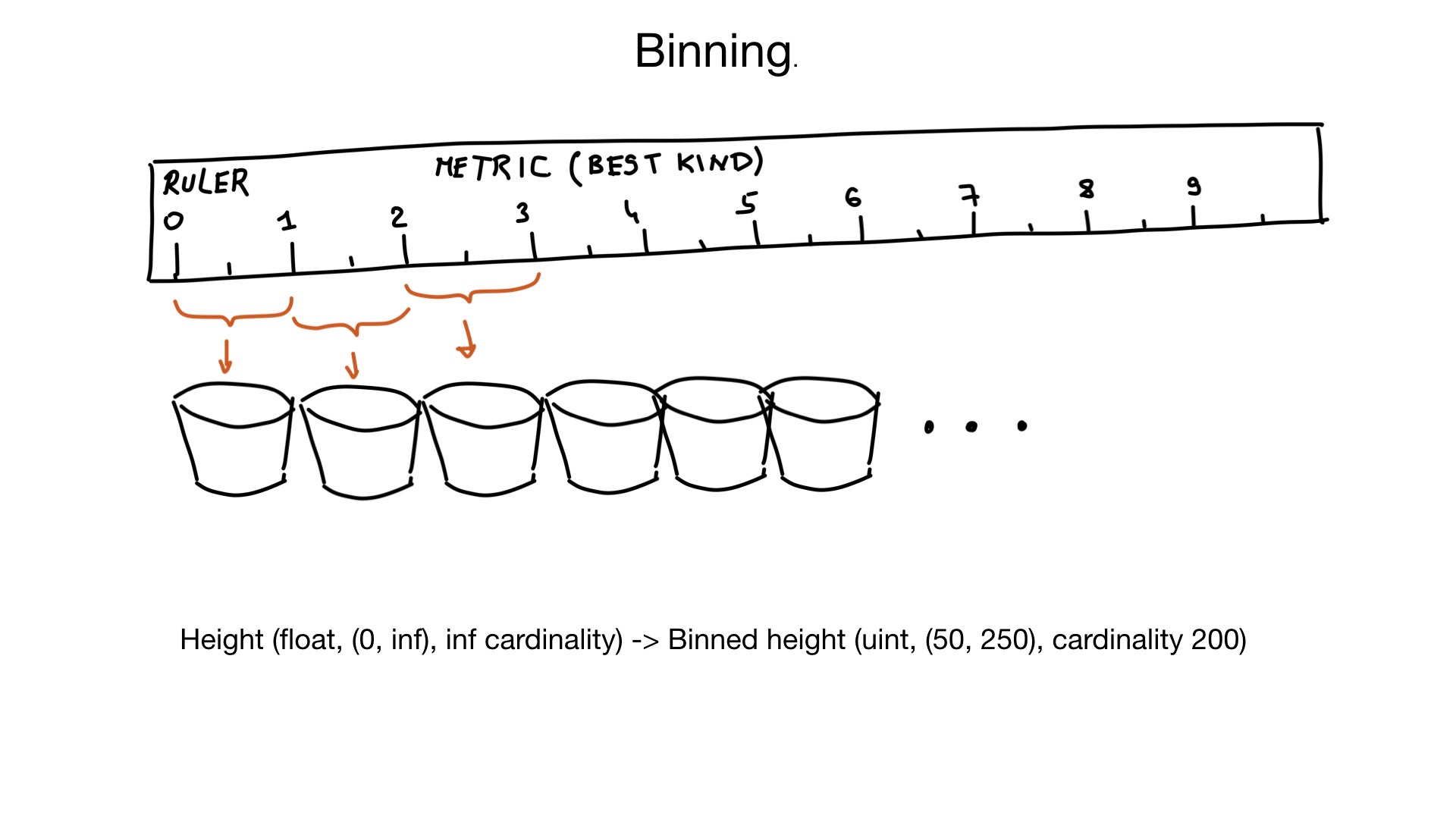
Otro enfoque que puede ayudar con los campos de alta cardinalidad se llama binning. Imagine que tenemos un campo que representa la altura de una persona. La altura es un flotador, pero no pensamos de esa manera. A nadie le importa si tu altura es de 185,2 o 185,3 cm. Por lo tanto, podemos usar "contenedores virtuales" para exprimir alturas similares en el mismo contenedor: el contenedor de 1 cm, en este caso. Y si supone que hay muy pocas personas con una altura de menos de 50 cm, o más de 250 cm, podemos convertir nuestra altura en el campo con una cardinalidad de aproximadamente 200 elementos, en lugar de una cardinalidad casi infinita. Si es necesario, podríamos hacer un filtrado adicional en los resultados más adelante.
Problema de alto rendimiento
Otra razón por la cual los índices de mapas de bits son malos es que puede ser costoso actualizar mapas de bits.
Las bases de datos realizan actualizaciones y búsquedas en paralelo, por lo que debe poder actualizar los datos mientras puede haber cientos de subprocesos pasando por mapas de bits haciendo una búsqueda. Las cerraduras serían necesarias para evitar carreras de datos o problemas de consistencia de datos. Y donde hay una gran cerradura, hay contención de cerradura.
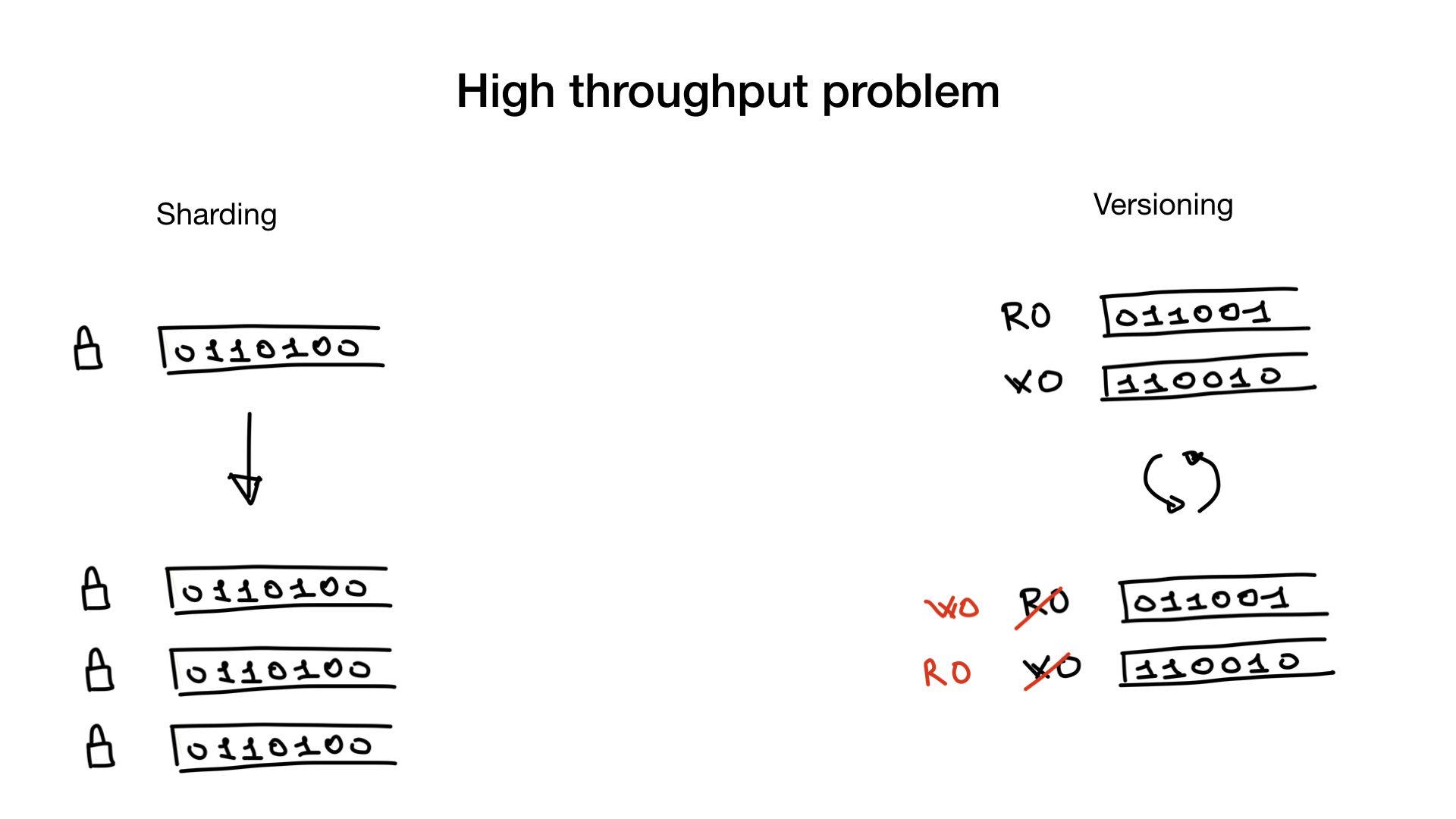
Este problema, si lo tiene, puede solucionarse fragmentando sus índices o teniendo versiones de índice, si corresponde.
Fragmentar es sencillo. Los fragmentará como fragmentaría a los usuarios en una base de datos y ahora, en lugar de un bloqueo, tiene múltiples bloqueos, lo que reduce en gran medida su contención de bloqueo.
Otro enfoque que a veces es factible es tener índices versionados. Tiene el índice que usa para la búsqueda y tiene un índice que usa para las escrituras, para las actualizaciones. Y los copia y los cambia a baja frecuencia, por ejemplo, 100 o 500 ms.
Pero este enfoque solo es factible si su aplicación puede tolerar índices de búsqueda obsoletos que son un poco obsoletos.
Por supuesto, estos dos enfoques también se pueden usar juntos. Puede tener índices versionados fragmentados.
Consultas no triviales
Otro problema de índice de mapa de bits tiene que ver con el uso de índices de mapa de bits con consultas de rango. Y a primera vista, las operaciones bit a bit como AND y OR no parecen ser muy útiles para consultas de rango como "darme habitaciones de hotel que cuestan de 200 a 300 dólares por noche".

Una solución ingenua y muy ineficiente sería obtener resultados para cada punto de precio de 200 a 300 y O los resultados.

Un enfoque un poco mejor sería usar binning y colocar nuestros hoteles en rangos de precios con anchos de rango de, digamos, 50 dólares. Este enfoque reduciría nuestros gastos de búsqueda en aproximadamente 50x.
Pero este problema también se puede resolver muy fácilmente mediante el uso de una codificación especial que hace que las consultas de rango sean posibles y rápidas. En la literatura, tales mapas de bits se denominan mapas de bits codificados por rango.

En los mapas de bits codificados por rango, no solo establecemos bits específicos para, digamos, el valor 200, sino que establecemos todos los bits en 200 y superiores. Lo mismo para 300.
Por lo tanto, al usar esta representación de mapa de bits codificada por rango, la consulta de rango se puede responder con solo dos pasos a través del mapa de bits. Obtenemos todos los hoteles que cuestan menos de, o igual a, 300 dólares y eliminamos del resultado todos los hoteles que cuestan menos de, o igual a, 199 dólares. Hecho

Se sorprenderá, pero incluso las consultas geográficas son posibles utilizando mapas de bits. El truco consiste en utilizar una representación como Google S2 o similar que encierra una coordenada en una figura geométrica que se puede representar como tres o más líneas indexadas. Si usa dicha representación, puede representar la consulta geográfica como varias consultas de rango en estos índices de línea.
Soluciones listas
Bueno, espero haber despertado un poco tu interés. Ahora tiene una herramienta más en su haber y si alguna vez necesita implementar algo como esto en su servicio, sabrá dónde buscar.
Eso está muy bien, pero no todos tienen el tiempo, la paciencia y los recursos para implementar el índice de mapa de bits, especialmente cuando se trata de cosas más avanzadas como las instrucciones SIMD.
No temas, hay dos productos de código abierto que pueden ayudarte en tu esfuerzo.

Rugir
Primero, hay una biblioteca que ya he mencionado llamada "mapas de bits rugientes". Esta biblioteca implementa un "contenedor" rugiente y todas las operaciones bit a bit que necesitarías si implementaras un índice de mapa de bits completo.
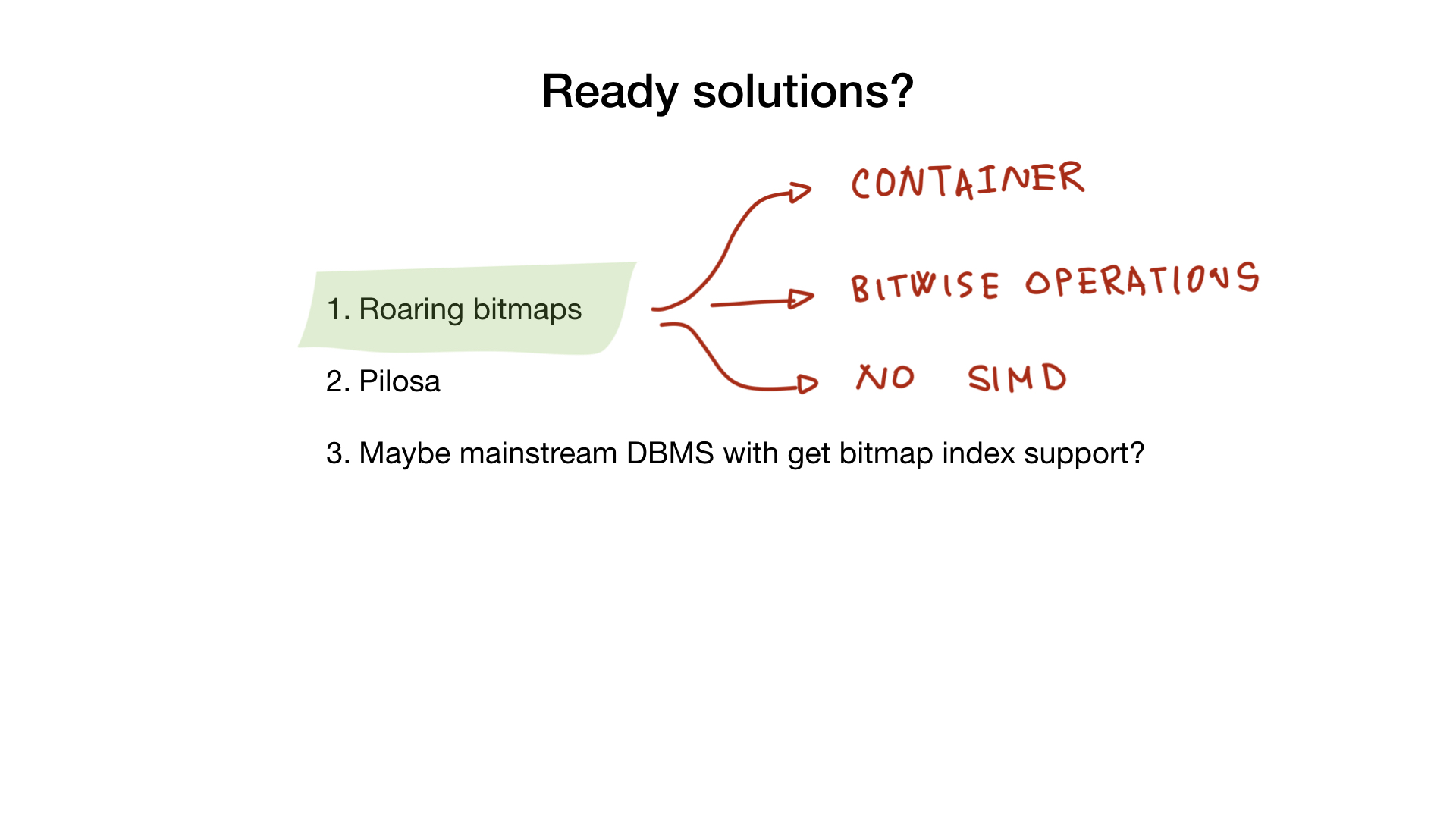
Desafortunadamente, las implementaciones de go no usan SIMD, por lo que ofrecen un rendimiento algo menor que, por ejemplo, la implementación de C.
Pilosa
Otro producto es un DBMS llamado Pilosa que solo tiene índices de mapa de bits. Es un proyecto reciente, pero últimamente ha ganado mucha tracción.
E-d3BCvTn1CSSDr5Vj6W_9e5_GC1syQ9qSrwdS0 ">
Pilosa utiliza mapas de bits rugosos debajo y da, simplifica o explica casi todas las cosas que le he estado diciendo hoy: binning, mapas de bits codificados por rango, la noción de campos, etc.
Veamos brevemente un ejemplo de Pilosa en uso ...

El ejemplo que ves es muy, muy similar al que vimos anteriormente. Creamos un cliente para el servidor pilosa, creamos un índice y campos para nuestras características. Rellenamos los campos con datos aleatorios con algunas probabilidades como lo hicimos anteriormente y luego ejecutamos nuestra consulta de búsqueda.
Ves el mismo patrón básico aquí. NO costoso intersectado o AND-ed con terraza e intersectado con reservas.
El resultado es el esperado.

Y, por último, espero que en algún momento en el futuro, las bases de datos como mysql y postgresql obtengan un nuevo tipo de índice: índice de mapa de bits.

Palabras de cierre

Y si todavía estás despierto, te lo agradezco. La escasez de tiempo ha significado que tuve que leer muchas de las cosas en esta publicación, pero espero que haya sido útil e incluso inspirador.
Los índices de mapa de bits son algo útil para conocer y comprender, incluso si no los necesita en este momento. Guárdelos como otra herramienta más en su cartera.
Durante mi charla, hemos visto varios trucos de rendimiento que podemos usar y cosas con las que Go tiene dificultades en este momento. Definitivamente, estas son cosas que todo programador de Go necesita saber.
Y esto es todo lo que tengo para ti por ahora. Muchas gracias