Parte 1 >>
Parte 2 >>
Parte 3
Uno de los procesadores más populares de la última década fue el Intel Core i7-2600K. El diseño fue revolucionario, ya que ofreció un salto significativo en el rendimiento y la eficiencia de un procesador de un solo núcleo, y el procesador en sí también respondió bien al overclocking. Las siguientes generaciones de procesadores Intel ya no parecían tan interesantes, y a menudo no daban a los usuarios una razón para actualizar, por lo que la frase "Me quedaré con mi 2600K" se ha vuelto omnipresente en los foros y suena incluso hoy. En esta revisión, sacudimos el polvo de la caja con los viejos procesadores y condujimos al veterano a través de un conjunto de puntos de referencia en 2019, tanto en los parámetros de fábrica como en el overclocking, para asegurarnos de que todavía sea el campeón.
 Family Photo Core i7
Family Photo Core i7¿Por qué el 2600K se ha vuelto crucial para la generación?
Siéntate en una silla, siéntate e imagínate en 2010. Este fue el año en que examinó su antiguo sistema Core 2 Duo o Athlon II y se dio cuenta de que era hora de una actualización. Ya está familiarizado con la arquitectura de Nehalem, y sabe que el Core i7-920 acelera bien y hace competidores. Fue un buen momento, pero de repente Intel reequilibró la industria y creó un producto verdaderamente revolucionario. Los ecos de nostalgia por los cuales todavía se escuchan.
 Core i7-2600K: el Sandy Bridge más rápido (hasta 2700K)
Core i7-2600K: el Sandy Bridge más rápido (hasta 2700K)Este nuevo producto fue Sandy Bridge. AnandTech lanzó una revisión exclusiva, y los resultados fueron casi imposibles de creer, por muchas razones. Según nuestras pruebas de esa época, el procesador era simplemente incomparablemente más alto que todo lo que vimos antes, especialmente teniendo en cuenta los monstruos térmicos Pentium 4 que salieron unos años antes. Una actualización central basada en el proceso de 32nm de Intel fue el mayor punto de inflexión en el rendimiento x86, y desde entonces no hemos visto tales avances. AMD necesitará otros 8 años para obtener su momento de fama con la serie Ryzen. Intel logró aprovechar el éxito de su mejor producto y obtener un lugar de campeón.
En este diseño básico, Intel no escatimó en innovación. Uno de los elementos clave fue el caché de microoperación. Esto significaba que las instrucciones recién decodificadas, que se requerían nuevamente, se toman ya decodificadas, en lugar de desperdiciar energía en la decodificación. Para Intel con Sandy Bridge, y mucho más tarde para AMD con Ryzen, habilitar el caché microoperativo fue un milagro para el rendimiento de un solo subproceso. Intel también ha comenzado a mejorar el subprocesamiento múltiple simultáneo (que durante varias generaciones se ha denominado HyperThreading), trabajando gradualmente en la asignación dinámica de subprocesos informáticos.
El diseño de cuatro núcleos del mejor procesador en el lanzamiento, el Core i7-2600K, se convirtió en la base de los productos en las próximas cinco generaciones de arquitectura Intel, incluidos Ivy Bridge, Haswell, Broadwell, Skylake y Kaby Lake. Desde Sandy Bridge, aunque Intel cambió a un proceso más pequeño y aprovechó el menor consumo de energía, la corporación no ha podido recrear este salto excepcional en el ancho de banda neto de los equipos. Más tarde, el crecimiento para el año fue de 1-7%, debido principalmente al aumento de los amortiguadores operativos, los puertos de ejecución y el soporte de comando.
Dado que Intel no pudo replicar el avance de Sandy Bridge, y la microarquitectura central fue la clave del rendimiento x86, los usuarios que compraron el Core i7-2600K (compré dos) permanecieron en él durante mucho tiempo. En gran parte debido a la expectativa de otro gran salto en el rendimiento. Y a lo largo de los años, su frustración está creciendo: ¿por qué invertir en un Kaby Lake Core i7-7700K de cuatro núcleos con velocidad de 4.7 GHz cuando su Sandy Bridge Core i7-2600K de cuatro núcleos todavía está overclockeado a 5.0 GHz?
(Las respuestas de Intel generalmente se relacionan con el consumo de energía y las nuevas características, como GPU y unidades a través de PCIe 3.0. Pero algunos usuarios no están satisfechos con estas explicaciones).
Es por eso que el Core i7-2600K ha definido una generación. Seguía siendo válido, al principio para la alegría de Intel, y luego para la decepción cuando los usuarios no querían actualizar. Ahora, en 2019, entendemos que Intel ya ha ido más allá de los cuatro núcleos en sus procesadores principales, y si el usuario es demasiado caro para DDR4, puede cambiar al nuevo sistema Intel o elegir la ruta AMD. Pero aquí está la pregunta de cómo el Core i7-2600K maneja las cargas de trabajo y los juegos de 2019; o, más precisamente, ¿cómo se las arregla el Core i7-2600K overclockeado?
Encuentra las diferencias: Sandy Bridge, Kaby Lake, Coffee Lake
En verdad, el Core i7-2600K no era el procesador Sandy Bridge convencional más rápido. Unos meses más tarde, Intel lanzó un 2700K un poco más de "alta frecuencia" en el mercado. Funcionó casi igual y aceleró de manera similar a 2600K, pero costó un poco más. En este momento, los usuarios que vieron un salto en el rendimiento y actualizaron ya estaban en 2600K, y se quedaron con él.
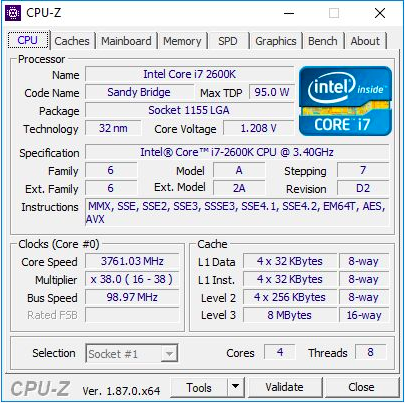
El Core i7-2600K era un procesador de cuatro núcleos de 32 nm con tecnología HyperThreading, con una frecuencia base de 3,4 GHz, una frecuencia turbo de 3,8 GHz y un TDP nominal de 95 vatios. Entonces, el TDP de Intel aún no se había divorciado de la realidad: en nuestras pruebas para este artículo, vimos un consumo de energía máximo de 88 W en una CPU desbloqueada. El procesador viene con gráficos integrados Intel HD 3000 y memoria DDR3-1333 compatible de forma predeterminada. Intel estableció un precio de $ 317 al lanzar el chip.
Para este artículo, utilicé el segundo i7-2600K, que compré cuando aparecieron por primera vez. Se probó tanto en la frecuencia estándar como en overclock a 4.7 GHz en todos los núcleos. Este es el overclocking promedio: el mejor de estos chips funciona a una frecuencia de 5.0 GHz - 5.1 GHz en modo diario. De hecho, recuerdo muy bien cómo mi primer Core i7-2600K funcionó a 5.1 GHz en todos los núcleos, e incluso a 5.3 GHz (también en todos los núcleos), cuando durante las competiciones de overclocking en pleno invierno, a temperatura ambiente a una temperatura de aproximadamente 2 ° C, utilicé un potente enfriador de líquidos y radiadores de 720 mm. Desafortunadamente, con el tiempo, dañé este chip y ahora no se carga ni siquiera a la frecuencia y voltaje nominales. Por lo tanto, deberíamos usar mi segundo chip, que no era tan bueno, pero aún así podía dar una idea del procesador overclockeado. Cuando hicimos overclocking, también usamos la memoria overclockeada, DDR3-2400 C11.
Vale la pena señalar que desde el lanzamiento del Core i7-2600K cambiamos de Windows 7 a Windows 10. El Core i7-2600K no admite las instrucciones AVX2 y no fue creado para Windows 10, por lo que será especialmente interesante ver cómo se muestra esto en los resultados.

 Core i7-7700K: el último procesador de cuatro núcleos Intel Core i7 con tecnología HyperThreading
Core i7-7700K: el último procesador de cuatro núcleos Intel Core i7 con tecnología HyperThreadingEl procesador Quad-core más rápido y nuevo (¿y el último?) Con HyperThreading, lanzado por Intel, fue el Core i7-7700K, un miembro de la familia Kaby Lake. Este procesador se basa en la tecnología de proceso mejorada de 14 nm de Intel, funciona a una frecuencia base de 4,2 GHz y una frecuencia turbo de 4,5 GHz. Su TDP con una potencia nominal de 91 vatios en nuestra prueba mostró un consumo de energía de 95 vatios. Viene con gráficos Intel Gen9 HD 630 y admite memoria DDR4-2400 estándar. Intel lanzó un chip con un precio declarado de 339 dólares.
Junto con el 7700K, Intel también lanzó su primer procesador de doble núcleo overclockeado con hypertreading: Core i3-7350K. En el transcurso de esta revisión, overclockeamos un Core i3 y lo comparamos con el Core i7-2600K en la configuración de fábrica, tratando de responder a la pregunta de si Intel logró lograr un rendimiento de procesador de doble núcleo similar a su antiguo buque insignia de cuatro núcleos. Como resultado, aunque i3 prevaleció en el rendimiento de un solo subproceso y trabajando con memoria, la falta de un par de núcleos en la cuenta hizo que la mayoría de las tareas fueran demasiado difíciles para Core i3.

 Core i7-9700K: la última versión de Intel Core i7 (ahora con 8 núcleos)
Core i7-9700K: la última versión de Intel Core i7 (ahora con 8 núcleos)Nuestro último procesador para pruebas es el Core i7-9700K. En la generación actual, ya no es el buque insignia de Coffee Lake (ahora es i9-9900K), pero tiene ocho núcleos sin hipertensión. La comparación con el 9900K, que tiene el doble de núcleos e hilos, parece inútil, especialmente cuando el precio de i9 es de $ 488. En contraste, el Core i7-9700K se vende a granel a "solo" $ 374, con una frecuencia base de 3.6 GHz y una frecuencia turbo de 4.9 GHz. Intel define su TDP a 95 vatios, pero en la placa base del consumidor, el chip consume ~ 125 vatios a plena carga. La memoria DDR4-2666 es compatible como estándar.
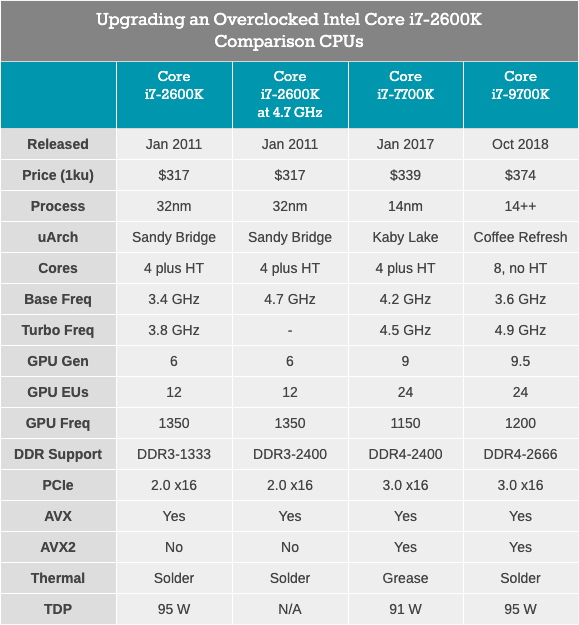
Core i7-2600K se ve obligado a trabajar con DDR3, admite PCIe 2.0, no PCIe 3.0, y no está diseñado para funcionar con unidades NVMe (que no están involucradas en esta prueba). Será interesante ver qué tan cerca está el veterano overclockeado del Core i7-7700K, y qué tipo de crecimiento veremos cuando cambiemos a algo como el Core i7-9700K.
Sandy Bridge: arquitectura central
En 2019, estamos hablando de chips de 100-200 mm2 con hasta ocho núcleos de alto rendimiento, y creados con la última tecnología de proceso Intel o AMD GlobalFoundries / TSMC. Pero el Sandy Bridge de 32 nm era una bestia completamente diferente. El proceso de producción todavía era "plano", sin transistores FinFET. En la nueva CPU, se implementó la segunda generación de High-K, y se logró una escala de 0.7x en comparación con la tecnología de proceso anterior de 45 nm más grande. El Core i7-2600K era el chip de cuatro núcleos más grande y contenía 1.16 billones de transistores por 216 mm2. A modo de comparación, el último procesador de Coffee Lake a 14 nm tiene ocho núcleos y más de 2 mil millones de transistores en un área de ~ 170 mm2.
El secreto del gran salto de rendimiento radica en la microarquitectura del procesador. Sandy Bridge prometió (y aseguró) un rendimiento significativo a velocidades de reloj iguales en comparación con los procesadores Westmere de la generación anterior, y también formó el circuito base para los chips Intel para la próxima década. Muchas innovaciones clave aparecieron por primera vez en el comercio minorista con la llegada de Sandy Bridge, y luego se repitieron y mejoraron muchas iteraciones, logrando gradualmente el alto rendimiento que usamos hoy en día.
En la revisión actual, me basé en gran medida en el informe inicial de microarquitectura 2600K de Anandtech, publicado en 2010. Por supuesto, con algunas adiciones basadas en un aspecto moderno de este procesador.
Breve reseña: núcleo de CPU con ejecución extraordinaria de instrucciones
Para aquellos nuevos en el diseño del procesador, aquí hay una descripción general rápida de cómo funciona un procesador de procesador adicional. En resumen, el núcleo se divide en interfaces externas e internas (front-end y back-end), y los datos primero van a la interfaz externa.
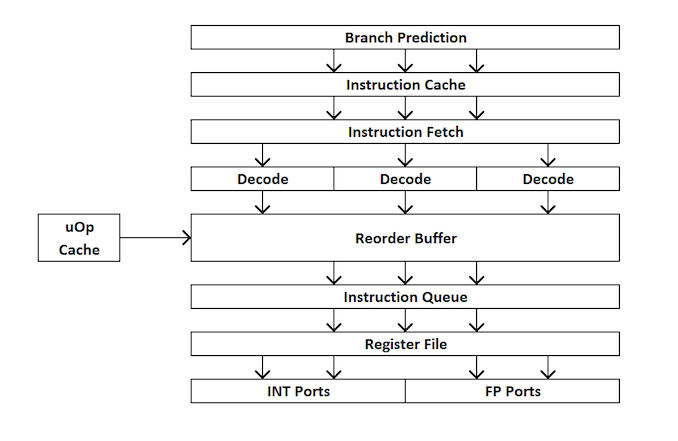
En la interfaz externa, tenemos prefetchers y predictores de rama que predecirán y recuperarán instrucciones de la memoria principal. La idea es que si puede predecir qué datos e instrucciones se necesitarán en el futuro cercano (antes de que se necesiten), puede ahorrar tiempo colocando estos datos cerca del núcleo. Luego, las instrucciones se colocan en un decodificador, que convierte la instrucción de bytecode en una serie de "microoperaciones" que el núcleo puede procesar.
Existen diferentes tipos de decodificadores para instrucciones simples y complejas: las instrucciones simples x86 se asignan fácilmente a una sola micro-operación, mientras que las instrucciones más complejas se pueden decodificar para más operaciones. La situación ideal es el coeficiente de decodificación lo más bajo posible, aunque a veces las instrucciones se pueden dividir en un mayor número de microoperaciones si estas operaciones se pueden realizar en paralelo (paralelismo en el nivel de comando o ILP).
Si el núcleo tiene un caché de microoperación, también es un caché uOp, entonces los resultados de cada instrucción decodificada se almacenan en él. Antes de que se decodifique la instrucción, el núcleo verifica si esta instrucción en particular se ha decodificado recientemente y, si tiene éxito, utiliza el resultado del caché en lugar de la decodificación, que consume energía.
Ahora las microoperaciones ponen "colas para asignación" - cola de asignación. El núcleo moderno puede determinar si las instrucciones son parte de un ciclo simple, o si uOps (microoperaciones) se pueden combinar para acelerar todo el proceso. Luego, uOps se alimentan en el búfer de reordenamiento, que forma el "back end" del núcleo.
En el backend, comenzando con el búfer de reordenamiento, uOps se puede reorganizar dependiendo de dónde se encuentren los datos necesarios para cada microoperación. Este búfer puede renombrar y distribuir microoperaciones dependiendo de dónde deben ir (operaciones enteras o FP) y, dependiendo del núcleo, también puede actuar como un mecanismo para eliminar instrucciones completadas. Después de reordenar, los buffers uOps se envían al planificador en el orden necesario para asegurarse de que los datos estén listos y maximizar el rendimiento de uOp.
El planificador envía uOps a los puertos de ejecución (para realizar cálculos) según sea necesario. Algunos núcleos tienen un único planificador para todos los puertos, pero en algunos casos se divide en un planificador para operaciones de enteros / vectores. La mayoría de los núcleos con ejecución extraordinaria tienen de 4 a 10 puertos (algunos más), y estos puertos realizan los cálculos necesarios para que la instrucción "pase" a través del núcleo. Los puertos de ejecución pueden tomar la forma de un módulo de carga (carga desde un caché), un módulo de almacenamiento (almacenamiento en un caché), un módulo de operaciones matemáticas enteras, un módulo de operaciones matemáticas con coma flotante, así como operaciones matemáticas vectoriales, módulos de división especial y algunos otros para operaciones especiales . Una vez que el puerto de ejecución ha funcionado, los datos se pueden almacenar en una memoria caché para su reutilización, que se coloca en la memoria principal; en este momento, la instrucción se envía a la cola de borrado y finalmente se borra.
Esta descripción general no cubre algunos de los mecanismos que utilizan los núcleos modernos para facilitar el almacenamiento en caché y la recuperación de datos, como los búferes de transacciones, los búferes de flujo, el etiquetado, etc. Algunos mecanismos mejoran iterativamente con cada generación, pero generalmente cuando hablamos de "instrucciones" por reloj "como un indicador de rendimiento, nos esforzamos por" omitir "tantas instrucciones como sea posible a través del núcleo (a través de la interfaz y el servidor). Este indicador depende de la velocidad de decodificación en la interfaz del procesador, las instrucciones de búsqueda previa, el búfer de reordenamiento y el uso máximo de los puertos de ejecución junto con la eliminación del número máximo de instrucciones ejecutadas para cada ciclo de reloj.
En base a lo anterior, esperamos que el lector pueda comprender mejor los resultados de la prueba de Anandtech obtenidos durante el lanzamiento de Sandy Bridge.
Sandy Bridge: Front End
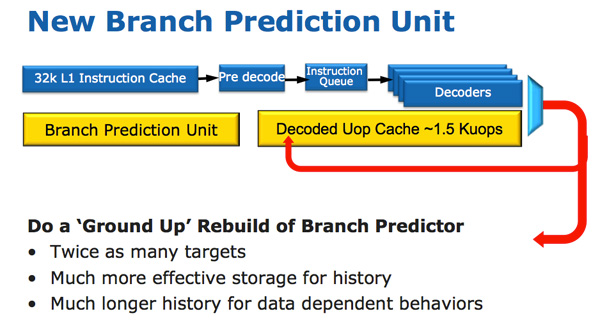
La arquitectura de CPU Sandy Bridge parece evolutiva en un vistazo rápido, pero es revolucionaria en términos de la cantidad de transistores que han cambiado desde Nehalem / Westmere. El cambio más importante para Sandy Bridge (y todas las microarquitecturas posteriores) es el caché microoperativo (caché uOp).

Ha aparecido un caché microoperativo en Sandy Bridge, que almacena en caché las instrucciones después de decodificarlas. No hay un algoritmo complicado; las instrucciones decodificadas simplemente se guardan. Cuando el prefetter Sandy Bridge recibe una nueva instrucción, primero se busca la instrucción en la memoria caché de microoperación y, si se encuentra, el resto de la canalización funciona con la memoria caché y la interfaz se desactiva. La decodificación de hardware es una parte muy compleja de la tubería x86, y apagarla ahorra una cantidad significativa de energía.
Este es un caché de mapeo directo y puede almacenar aproximadamente 1.5 KB de microoperaciones, lo que en realidad es equivalente a un caché de instrucciones de 6 KB. El caché de microoperación se incluye en el caché de instrucciones L1, y su índice de aciertos para la mayoría de las aplicaciones alcanza el 80%. El caché de microoperación tiene un ancho de banda ligeramente más alto y más estable en comparación con el caché de instrucciones. La instrucción L1 real y los cachés de datos no han cambiado; todavía son 32 KB cada uno (un total de 64 KB L1).
Todas las instrucciones que provienen del decodificador se pueden almacenar en caché mediante este mecanismo y, como ya dije, hay algunos algoritmos especiales en él, simplemente, todas las instrucciones se almacenan en caché. Los datos no utilizados durante mucho tiempo se eliminan cuando se agota el lugar. La memoria caché microoperativa puede parecer similar a la memoria caché de seguimiento en Pentium 4, pero con una diferencia significativa: no almacena las memorias caché. Esto es simplemente un caché de instrucciones que almacena microoperaciones en lugar de macrooperaciones (instrucciones x86).
Junto con el nuevo caché microoperativo, Intel también introdujo un módulo de predicción de sucursal completamente rediseñado. La nueva BPU es casi la misma que su predecesora, pero mucho más precisa. La mayor precisión es el resultado de tres grandes innovaciones.
El predictor de rama estándar es un predictor de 2 bits. Cada rama está marcada en la tabla como aceptada / no aceptada con la fiabilidad adecuada (fuerte / débil). Intel descubrió que casi todas las ramas predichas por este predictor bimodal tienen una confianza "alta". Por lo tanto, en Sandy Bridge, un predictor de rama bimodal usa un bit de confianza para múltiples ramas, en lugar de un bit de confianza para cada rama. Como resultado, su tabla de historial de sucursales tendrá el mismo número de bits que representan muchas más sucursales, lo que conducirá a pronósticos más precisos en el futuro.
Sandy Bridge: cerca del núcleo
Con el crecimiento de los procesadores multinúcleo, la gestión del flujo de datos entre núcleos y memoria se ha convertido en un tema importante. Hemos visto muchas formas diferentes de mover datos alrededor de la CPU, como barras cruzadas, anillos, mallas y, más tarde, chips de E / S completamente separados. La batalla de la próxima década (2020+), como mencionó anteriormente AnandTech, será una batalla de conexiones internucleares, y ahora ya está comenzando.
Una característica de Sandy Bridge es precisamente que fue la primera CPU de consumo de Intel, que utilizó un bus de anillo que conectaba todos los núcleos, memoria, caché de último nivel y gráficos integrados. Este sigue siendo el mismo diseño que vemos en los procesadores modernos de Coffee Lake.
Neumático de anillo
Nehalem / Westmery Bridge agrega un procesador de gráficos y un motor de transcodificación de video al chip que comparte el caché L3. Y en lugar de tender más cables al L3, Intel presentó el bus de anillo.
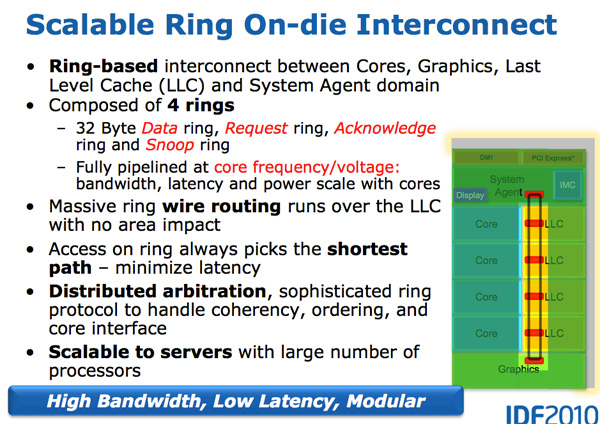
Arquitectónicamente, este es el mismo anillo circular utilizado en Nehalem EX y Westmere EX. Cada núcleo, cada fragmento de la caché L3 (LLC), el procesador de gráficos integrado, el motor de medios y el agente del sistema (un nombre divertido para el puente norte) están conectados al bus de anillo. : , , . 32 . .
L3, Westmere — 96 /. Sandy Bridge 4 , Westmere, , 384 /.
, L3 36 Westmere 26 — 31 Sandy Bridge ( , , ). , Westmere, - L3 — un-Core , Intel « », - L3. ( «un-Core» .)
- L3, , . , L3 , . L3, , L3 , . .
L3 , . Sandy Bridge L3, . , . Westmere , , Sandy Bridge . , . , , . , «», .
- Intel un-core SB, Sandy Bridge « ». (-, un-core , - ). . 16 PCIe 2.0, x8. DDR3, , , Lynnfield (Clarkdale ).
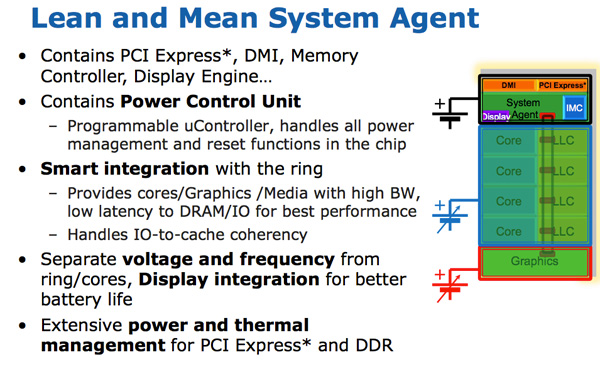
DMI, PCU ( ). SA , , .
Sandy Bridge
Sandy Bridge Westmere . 10-30%, Sandy Bridge , Intel Westmere (Clarkdale / Arrandale). 45 32 , IPC.
Sandy Bridge 32- , . . GPU . , .
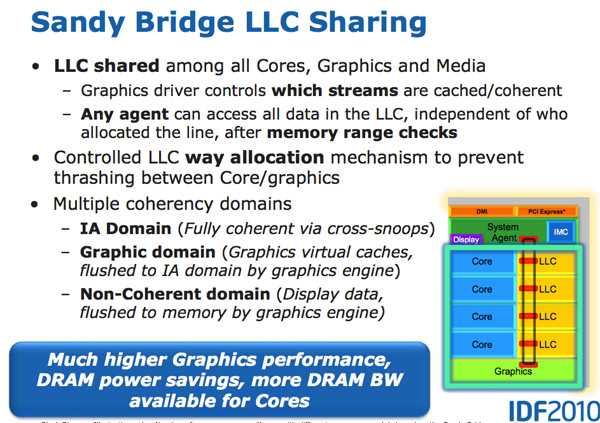
GPU Sandy Bridge, - L3. , L3, , . , , , . .
SNB ( Gen 6) . : , , . – , , .
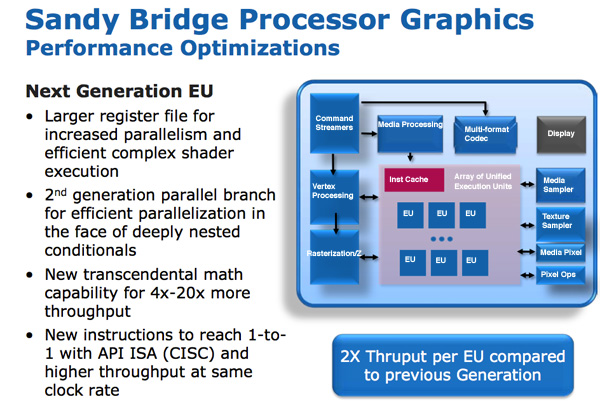
/ / (execution units), Intel EU. EU . ISA -- API DirectX 10, CISC- . - API IPC EU.
EU . EU, . Intel , , Westmere.
Intel « ». , . , , . , . Intel 64 80, , , 120 Sandy Bridge. - .

, EU.
GPU Sandy Bridge: 6 EU 12 EU. ( ) 12 EU, SKU 6 12 . Sandy Bridge Intel, , Intel , GPU. (2019 .) 24 EU (Gen 9.5), 10- ~ 64 EU (Gen11).
Sandy Bridge Media Engine
GPU Sandy Bridge -. SNB : .
: . Intel SNB, EU. Intel , SNB HD-.
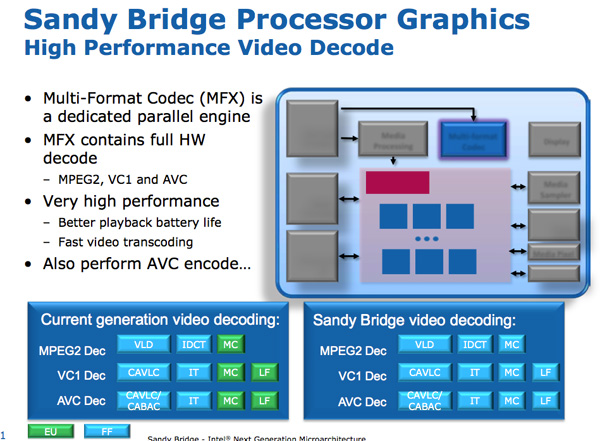
Sandy Bridge. Intel ~ 3- 1080p 30 / iPhone 640 x 360. 14 400 .
/ . Sandy Bridge 3 2 / .
,
Lynnfield Intel, . , TDP 95 , , , -.
, - . , , — , .
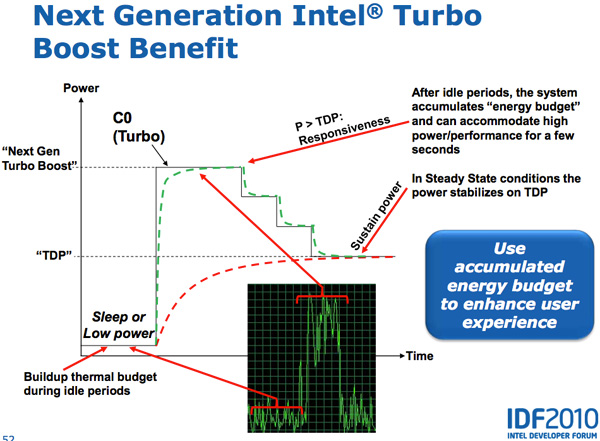
Sandy Bridge , PCU TDP ( 25 ). PCU , . , , TDP. , , TDP, , , TDP. SNB TDP, PCU .

CPU, GPU Turbo . , GPU, SNB, CPU, GPU. , CPU, GPU CPU. Sandy Bridge , , .
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
Dell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV desde $ 199 en los Países Bajos! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - ¡desde $ 99! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?