En una implementación real de ML, el aprendizaje en sí requiere una cuarta parte del esfuerzo. Los tres trimestres restantes son preparación de datos a través del dolor y la burocracia, un despliegue complejo a menudo en un circuito cerrado sin acceso a Internet, configuración de infraestructura, pruebas y monitoreo. Documentos en cientos de hojas, modo manual, conflictos de versión de modelo, código abierto y empresa dura: todo esto le espera a un científico de datos. Pero no está interesado en estos problemas operativos "aburridos", quiere desarrollar un algoritmo, lograr alta calidad, retribuir y no recordar más.
Quizás, en algún lugar, ML se implemente más fácil, más simple, más rápido y con un solo botón, pero no hemos visto tales ejemplos. Todo lo que está arriba es la experiencia de Front Tier en fintech y telecomunicaciones. Sergey Vinogradov, experto en arquitectura de sistemas altamente cargados, en grandes almacenes y en análisis de datos pesados, habló sobre él en
HighLoad ++ .

Ciclo de vida modelo
Por lo general, el ciclo de vida en nuestra área temática consta de tres partes. En el primero
, una tarea proviene del negocio . En el segundo, un
ingeniero de datos y / o científico de datos prepara datos , construye un modelo. En la tercera parte, comienza el
caos . En los dos últimos, suceden diferentes situaciones interesantes.
Jack de todos los oficios
La primera situación frecuente es que un científico de datos o ingeniero de datos tiene acceso a los productos, por lo que le dicen: "Hiciste todo esto, lo apostaste".
Una persona toma un
cuaderno Jupyter o un paquete de cuadernos, los considera únicamente como un artefacto de una implementación y comienza a replicarse con alegría en algunos servidores.
Todo parece estar bien, pero no siempre. Más tarde te diré por qué.
Explotación despiadada
La segunda historia es más compleja, y generalmente ocurre en empresas donde la explotación ha alcanzado un estado de locura leve. El científico de datos trae su solución a la operación. Abren esta caja negra y ven algo terrible:
- cuadernos
- pepinillo de diferentes versiones;
- montón de scripts: no está claro dónde y cuándo ejecutarlos, dónde guardar los datos que generan.
En este rompecabezas, la explotación encuentra incompatibilidad de versiones. Por ejemplo, un científico de datos no especificó una versión específica de la biblioteca, y la operación tomó la última. Después de un tiempo, el científico de datos recurre:
- Estableciste scikit-learn en la versión incorrecta, ¡ahora todas las métricas se han ido! Necesita volver a la versión anterior.Esto rompe completamente la producción y la explotación sufre.
Burocracia
En las empresas con logotipos verdes, cuando el científico de datos entra en funcionamiento y trae el modelo, generalmente recibe un documento de 800 hojas en respuesta: "Siga estas instrucciones, de lo contrario su producto nunca verá la luz del día".
El triste científico de datos se va, tira todo a la mitad y luego renuncia: no está interesado en hacer esto.
Implementar
Supongamos que un científico de datos ha pasado por todos los círculos y al final todo se ha implementado. Pero no podrá entender que todo funciona como debería. En mi experiencia, en los mismos bancos bendecidos no hay monitoreo de productos de ciencia de datos.
Es bueno si el especialista escribe los resultados de su trabajo en la base de datos. Después de un tiempo, los recibirá y verá qué sucede dentro. Pero esto no siempre sucede. Cuando una empresa y un científico de datos simplemente creen que todo está funcionando bien y es maravilloso, se traduce en casos fallidos.
IMF
De alguna manera, desarrollamos un motor de puntuación para una gran organización de microfinanzas. No los dejaron ir al producto, sino que simplemente nos quitaron una cascada de modelos, la instalaron y la lanzaron. Los resultados de las pruebas de los modelos los satisfacen. Pero después de 6 meses volvieron:
- Todo está mal. El negocio no va, estamos empeorando cada vez más. Parece que los modelos son excelentes, pero los resultados están cayendo, el fraude y el incumplimiento cada vez más, y menos dinero. ¿Por qué te pagamos? Vamos a hacerlo bien.Al mismo tiempo, el acceso al modelo nuevamente no se da. Los registros se descargaron durante un mes, además, hace seis meses. Estudiamos la descarga durante otro mes y llegamos a la conclusión de que en algún momento el departamento de TI de la IMF cambió los datos de entrada y, en lugar de documentos en json, comenzaron a enviar documentos en xml. El modelo esperaba json, pero recibió xml, estaba triste y pensó que no había datos en la entrada.
Si no hay datos, entonces la evaluación de lo que está sucediendo es diferente. Sin monitoreo, esto no se puede detectar.
Nueva versión, cascada y pruebas.
A menudo nos enfrentamos al hecho de que el modelo funciona bien, pero por alguna razón
se ha desarrollado una
nueva versión . El modelo nuevamente necesita ser traído de alguna manera, y nuevamente para atravesar todos los círculos del infierno. Es bueno si las versiones de la biblioteca son las mismas que en el modelo anterior, y si no, la implementación comienza de nuevo ...
A veces, antes de poner una nueva versión en la batalla, queremos
probarla : ponerla en el producto, mirar el mismo flujo de tráfico, asegurarnos de que sea bueno. Esta es nuevamente la cadena de implementación completa. Además, configuramos los sistemas para que, de acuerdo con este modelo, no se produzcan resultados reales, si se trata de puntuación, sino que solo hubo monitoreo y análisis de los resultados para un análisis posterior.
Hay situaciones en las
que se usa una
cascada de modelos. Cuando los resultados de los siguientes modelos dependen de los anteriores, de alguna manera debe establecer la interacción entre ellos y, en algún lugar, todo esto debe guardarse.
¿Cómo resolver tales problemas?
A menudo, una persona resuelve problemas
manualmente , especialmente en pequeñas empresas. Sabe cómo funciona todo, tiene en cuenta todas las versiones de modelos y bibliotecas, sabe dónde y qué scripts funcionan, qué escaparates construyen. Todo esto es maravilloso Particularmente hermosas son las historias que deja el modo manual.
La historia de la herencia . Un buen hombre trabajaba en un pequeño banco. Una vez fue a un país del sur y no regresó. Después de eso, obtuvimos una herencia: un montón de código que genera escaparates en los que funcionan los modelos de modelos. El código es hermoso, funciona, pero no sabemos la versión exacta del script que genera este o aquel escaparate. En la batalla, todos los escaparates están presentes y todos se lanzan. Pasamos dos meses tratando de distinguir esta intrincada maraña y estructurarla de alguna manera.
En una empresa dura, las personas no quieren molestarse con todo tipo de Python, Júpiter, etc. Dicen:
- Compremos IBM SPSS, instálelo y todo estará genial. Problemas con el control de versiones, con las fuentes de datos, con la implementación allí resuelta de alguna manera.Este enfoque tiene derecho a existir, pero no todos pueden permitírselo. En cualquier caso, esta es una aguja dentada de alta calidad. Se sientan en él, pero no funciona para salir - muescas. Y generalmente cuesta mucho.
El código abierto es lo opuesto al enfoque anterior. Los desarrolladores navegaron por Internet, encontraron muchas soluciones de código abierto que resuelven sus tareas en diversos grados. Esta es una excelente manera, pero para nosotros no encontramos soluciones que satisfagan nuestros requisitos al 100%.
Por lo tanto, hemos elegido la opción clásica:
nuestra decisión . Sus muletas, bicicletas, todas propias, nativas.
¿Qué queremos de nuestra decisión?
No escribas todo tú mismo . Queremos tomar componentes, especialmente los de infraestructura, que han demostrado ser buenos y están familiarizados con la operación en las instituciones con las que trabajamos. Simplemente escribimos un entorno que aislará fácilmente el trabajo del científico de datos del trabajo de DevOps.
Procese datos en dos modos: ambos en modo por lotes: lote y en tiempo real . Nuestras tareas incluyen ambos modos de operación.
Facilidad de despliegue, y en un perímetro cerrado . Cuando se trabaja con datos privados confidenciales, no hay conexión a Internet. En este momento, todo debería llegar rápida y exactamente a la producción. Por lo tanto, comenzamos a mirar hacia Gitlab, la tubería de CI / CD dentro de él y Docker.
Un modelo no es un fin en sí mismo. No resolvemos el problema de construir un modelo, resolvemos un problema de negocios.
Dentro de la tubería, debe haber reglas y un conglomerado de modelos con soporte para
versionar todos los componentes de la tubería.
¿Qué se entiende por tubería? En Rusia, la Ley Federal 115 sobre la lucha contra el lavado de dinero y la financiación del terrorismo está en vigor. Solo el índice de las recomendaciones del Banco Central ocupa 16 pantallas. Estas son reglas simples que un banco puede cumplir si tiene tales datos, o no puede hacerlo si no tiene datos.
La evaluación de un prestatario, una transacción financiera u otro proceso comercial es un flujo de datos que procesamos. Una secuencia debe pasar por este tipo de regla. Estas reglas son descritas de manera fácil por el analista. No es un científico de datos, pero conoce bien la ley u otras instrucciones. El analista se sienta y, en lenguaje sencillo, describe las comprobaciones de los datos.
Construye cascadas de modelos . A menudo surge una situación cuando el siguiente modelo utiliza para su trabajo los valores obtenidos en modelos anteriores.
Probar hipótesis rápidamente. Repito la tesis anterior: un científico de datos hizo algún tipo de modelo, gira en la batalla y funciona bien. Por alguna razón, el especialista encontró una solución mejor, pero no quiere arruinar el flujo de trabajo establecido. El científico de datos está colgando un nuevo modelo en el mismo tráfico de combate en el sistema de combate. Ella no participa directamente en la toma de decisiones, pero sirve el mismo tráfico, considera algunas conclusiones y estas conclusiones se almacenan en algún lugar.
Función de reutilización fácil. Muchas tareas tienen el mismo tipo de componentes, especialmente los relacionados con la extracción de características o reglas. Queremos arrastrar estos componentes a otras tuberías.
¿Qué decidiste hacer?
Primero queremos monitoreo. Y dos de su tipo.
Monitoreo
Monitoreo técnico. Si se implementan componentes de la tubería, en funcionamiento deberían ver qué sucede con el componente: cómo consume memoria, CPU, disco.
Monitoreo de negocios. Esta es una herramienta científica de datos que le permite abstraerse de los matices técnicos de la implementación. A nivel de diseño, la construcción ayuda a determinar qué métricas del modelo deberían estar disponibles en el monitoreo, por ejemplo, distribución de características o resultados de servicios de puntuación.
Un científico de datos define las métricas y no debe preocuparse por cómo ingresan al sistema de monitoreo. Lo único importante es que definió estas métricas y la apariencia del panel en el que se mostrarán las métricas. Luego, el especialista lanzó todo lo relacionado con la producción, la implementación y, después de un tiempo, las métricas se volcaron en el monitoreo. Entonces, un científico de datos sin acceso al producto puede ver lo que está sucediendo dentro del modelo.
Prueba
Probar la
tubería para la consistencia . Dados los detalles de la tubería, este es un tipo de gráfico de computación. Queremos entender que estamos implementando un gráfico, podemos evitarlo y encontrar una manera de salir de él.
El gráfico tiene componentes - módulos. Todos los módulos deben pasar la unidad y las pruebas de integración. El proceso debe ser transparente y fácil para un científico de datos.
El desarrollador describe el modelo y las pruebas por sí solo o con la ayuda de otra persona. Pone todo en Gitlab, la canalización configurada por Continuous Integration aumenta, prueba, ve resultados. Si todo está bien, va más allá, no, comienza de nuevo.
El científico de datos se centra en el modelo y no sabe qué hay debajo del capó. Para esto, se le dan varias cosas.
- Una API para la integración con el núcleo del sistema a través del bus de datos - bus de mensajes. En este caso, el especialista debe describir qué está entrando y qué está saliendo de su modelo, el punto de entrada y la unión con diferentes componentes dentro de la tubería.
- Después de entrenar al modelo, aparece un artefacto: un archivo XGBoost o pickle . El científico de datos tiene un ejecutor para trabajar con artefactos: debe integrar los componentes de la tubería en su interior.
- API fácil y transparente para el científico de datos para monitorear el funcionamiento de los componentes de la tubería: monitoreo técnico y comercial.
- Una infraestructura simple y transparente para integrarse con fuentes de datos y preservar los resultados del trabajo.
A menudo, los modelos funcionan para nosotros, y después de un tiempo llega una auditoría que quiere elevar toda la historia del servicio. La auditoría quiere verificar la corrección del trabajo, la ausencia de fraude de nuestra parte. Se necesitan herramientas simples para que cualquier auditor que conozca SQL pueda ingresar a un repositorio especial y ver cómo funciona todo, qué decisiones se tomaron y por qué.
Pusimos las bases para dos historias importantes para nosotros.
Viaje del cliente. Esta es una oportunidad para utilizar los mecanismos para preservar todo el historial del cliente, lo que le sucedió como parte de los procesos comerciales que se implementan en este sistema.
Es posible que tengamos fuentes de datos externas, por ejemplo, plataformas DMP. De ellos obtenemos información sobre el comportamiento humano en la red y en dispositivos móviles. Esto puede afectar el LTV de su modelo y los modelos de puntuación. Si el prestatario se atrasa en el pago, podemos predecir que esta no es una intención maliciosa, simplemente hay problemas. En este caso, aplicamos métodos suaves de exposición al prestatario. Cuando se resuelven los problemas, el cliente cerrará el préstamo. Cuando venga la próxima vez, sabremos toda su historia. El científico de datos obtendrá una historia visual del modelo y realizará una puntuación en modo de luz.
Identificación de anomalías . Nos enfrentamos constantemente a un mundo muy complejo. Por ejemplo, los puntos débiles dentro de la evaluación acelerada de las IMF pueden ser una fuente de fraude automático.
Customer Journey es un concepto de acceso rápido y fácil al flujo de datos que atraviesa el modelo. El modelo facilita la detección de anomalías que son características del fraude en el momento de su ocurrencia masiva.
¿Cómo se arregla todo?
Sin dudarlo, tomamos
Kafka como un parche de Message Bus. Esta es una buena solución que utilizan muchos de nuestros clientes, la operación puede trabajar con ella.
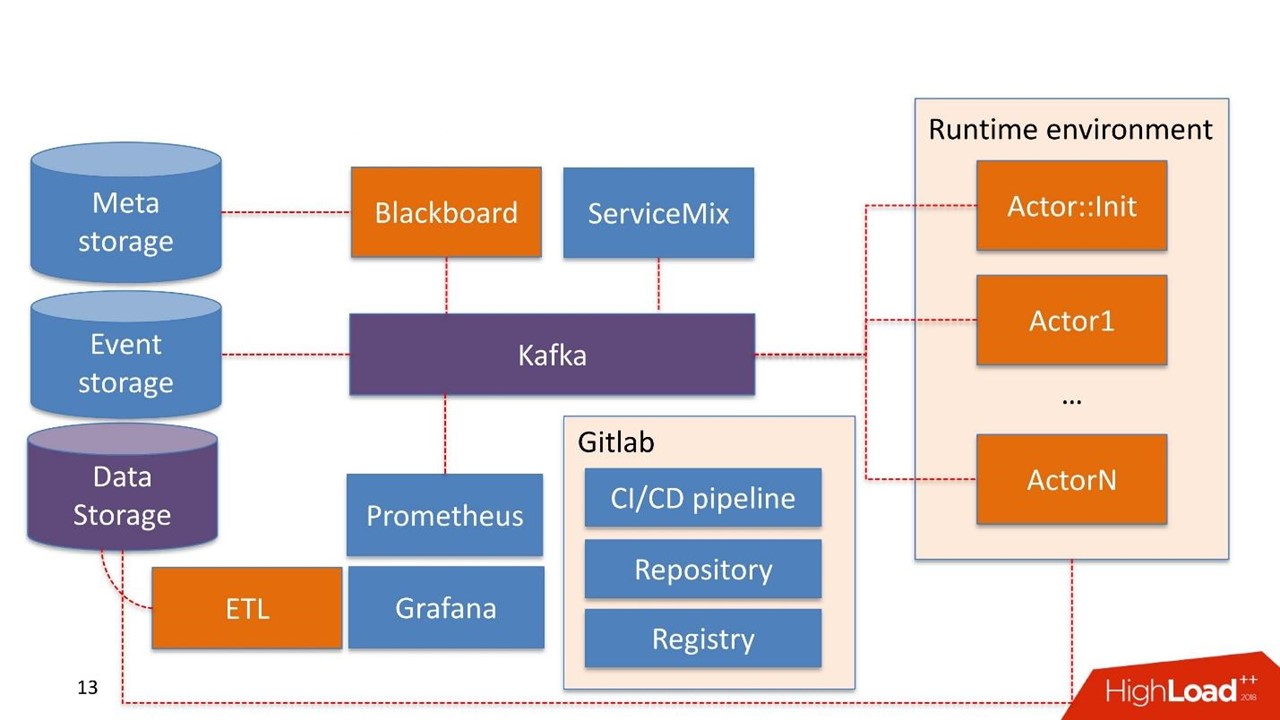
Es posible que algunos componentes del sistema ya se utilicen en la propia empresa. No estamos construyendo el sistema nuevamente, sino reutilizando lo que ya tienen.
El almacenamiento de datos en este caso es el almacenamiento que el cliente generalmente ya tiene. Puede ser Hadoop, bases de datos relacionales y no relacionales. Podemos trabajar de forma nativa con HDFS, Hive, Impala, Greenplum y PostgreSQL. Consideramos estos almacenes como una fuente de escaparates.
Los datos llegan al almacén, pasan a través de nuestro ETL o el ETL del cliente, si tiene uno. Estamos construyendo escaparates que se utilizan aún más dentro de los modelos. El almacenamiento de datos se usa en modo de solo lectura.
Nuestros desarrollos
Pizarra El nombre se toma de una práctica bastante extraña de matemáticos de los años 30-40. Este es el administrador de las tuberías que viven en el sistema de administración. Blackboard tiene algún tipo de Meta Storage. Almacena las tuberías en sí y las configuraciones necesarias para inicializar todos los componentes.
Todo el trabajo del sistema comienza con Blackboard. Por algún milagro, la tubería terminó en Meta Storage, Blackboard después de un tiempo comprende esto, saca la versión actual de la tubería, la inicializa y envía una señal dentro de Kafka.
Hay un
entorno de tiempo de ejecución . Está construido en Dockers y se puede replicar en servidores, incluso en la nube privada del cliente.
Fuera de la caja viene el
Actor principal
:: Init - este es el inicializador. Este es un genio que solo puede hacer dos cosas:
construir y
destruir componentes . Recibe un comando de Blackboard: "Aquí está la canalización, debe iniciarse en tales servidores con tales recursos en cantidades tales, ¡trabajo!" Entonces el actor comienza todo.
Matemáticamente, un actor es una función que toma uno o más objetos como entrada, en su interior cambia el estado de los objetos según algún algoritmo, en la salida crea un nuevo objeto o cambia el estado de uno existente.
Técnicamente, un actor es un programa de Python. Se ejecuta en un contenedor Docker con su entorno.
El actor no sabe sobre la existencia de otros actores. La única entidad que sabe que, además del actor, existe toda la tubería en su conjunto: esto es Blackboard. Monitorea el estado de ejecución de todos los actores dentro del sistema y mantiene el estado actual, que se expresa en el monitoreo como una imagen de todo el proceso comercial en su conjunto.
Actor :: Init genera muchos contenedores Docker. Además, los actores pueden trabajar con el almacenamiento de datos.
El sistema en sí tiene un componente de
almacenamiento de eventos . Como almacenamiento de eventos usamos
ClickHouse . Su tarea es simple: toda la información intercambiada entre el actor a través de Kafka se almacena en ClickHouse. Esto se hace
para una auditoría adicional . Este es el registro de operaciones de canalización.
Los actores también se pueden desarrollar para
Customer Journey . Ven cambios en el registro de la tubería y pueden reconstruir sobre la marcha las ventanas necesarias para que los modelos o componentes trabajen con las reglas, que ya están dentro de la tubería. Este es un proceso continuo de cambio de datos.
El monitoreo se construye de manera bastante primitiva en
Prometeo . El actor recibe una API básica, y en un modo cerrado, pero lo suficientemente transparente para el desarrollador, envía mensajes con métricas a Kafka. Prometheus lee las métricas de Kafka y las guarda en su repositorio.
Para la visualización usamos
Grafana .
Dos puntos de integracion
El primero es el punto de integración con las fuentes de datos que pasan por ETL al almacén de datos. El segundo punto de integración cuando un consumidor de datos ya utiliza un servicio, por ejemplo, un servicio de puntuación.
Tomamos
Apache ServiceMix. Por experiencia, estos puntos de integración son del mismo tipo con el mismo tipo de protocolos: SOAP, RESTful, colas con menos frecuencia. Cada vez que no queremos desarrollar nuestro propio constructor o servicio para generar el próximo servicio SOAP. Por lo tanto, tomamos ServiceMix, lo describimos en el SDL, en el que se construyen los modelos de datos de este servicio y los métodos que existen en él. Luego empujamos a través del enrutador dentro de ServiceMix, y genera el servicio en sí.
De nosotros mismos, agregamos una difícil conversión síncrono-asíncrona. Todas las solicitudes que viven dentro del sistema son asíncronas y pasan por el bus de mensajes.
La mayoría de los servicios de puntuación son sincrónicos. Las solicitudes de ServiceMix vienen a través de REST o SOAP. En este punto, pasa a través de nuestro Gateway, que retiene el conocimiento de la sesión HTTP. Luego envía un mensaje a Kafka, se ejecuta a través de una tubería y se genera una solución.
Sin embargo, aún puede no haber solución. Por ejemplo, algo se cayó, o hay un SLA difícil de tomar una decisión, y Gateway monitorea: "OK, recibí una solicitud, él vino a mí en otro tema de Kafka, o no me llegó nada, pero mi disparador de tiempo de espera funcionó". Por otra parte, la conversión de síncrono a asíncrono continúa, y dentro de la misma sesión HTTP, hay una respuesta al consumidor con el resultado del trabajo. Esto puede ser un error o un pronóstico normal.
En este lugar, por cierto, comimos un perro sin sabor gracias al gran y poderoso Open Source. Utilizamos ServiceMix de una de las últimas versiones y Kafka de versiones anteriores y todo funcionó perfectamente. Escribimos en este Gateway, basado en esos cubos que ya estaban en ServiceMix. Cuando salió la nueva versión de Kafka, la agarramos felizmente, pero resultó que el apoyo a los encabezados dentro del mensaje en Kafka que existía anteriormente había cambiado. Gateway dentro de ServiceMix ya no puede trabajar con ellos. Para entender esto, pasamos mucho tiempo. Como resultado, creamos nuestro Gateway, que puede funcionar con nuevas versiones de Kafka. Escribimos sobre el problema a los desarrolladores de ServiceMix y recibimos la respuesta: "¡Gracias, definitivamente lo ayudaremos en las próximas versiones!"
Por lo tanto, nos vemos obligados a monitorear las actualizaciones y cambiar regularmente algo.
La infraestructura es Gitlab. Usamos casi todo lo que contiene.
- Repositorio de código.
- Continúa la integración / Continúa la entrega de la tubería.
- Registro para mantener un registro de contenedores Docker.
Componentes
Hemos desarrollado 5 componentes:
- Pizarra : gestión del ciclo de vida de la tubería. Dónde, qué y con qué parámetros ejecutar desde la tubería.
- El extractor de características funciona de manera simple: informamos al extractor de características que obtenemos tal o cual modelo de datos en la entrada, seleccionamos los campos necesarios de los datos y los asignamos a ciertos valores. Por ejemplo, obtenemos la fecha de nacimiento del cliente, la convertimos a la edad, la usamos como una característica en nuestro modelo. El extractor de funciones es responsable del enriquecimiento de datos.
- Motor basado en reglas : verificación de datos de acuerdo con las reglas. Este es un lenguaje de descripción simple que le permite a una persona familiarizada con la construcción de <code> if, si no, <code /> bloquea describir las reglas para verificar dentro del sistema.
- Motor de aprendizaje automático : le permite ejecutar el ejecutor, inicializar el modelo entrenado y enviarlo a los datos de entrada. En la salida, el modelo toma datos.
- Motor de decisión: motor de decisión, salir del gráfico. Al tener una cascada de modelos, por ejemplo, diferentes ramas de la evaluación del prestatario, debe decidir sobre el tema del dinero en alguna parte. El conjunto de reglas para la solución debe ser simple. , LTV- — , , .
. — , . — , .
pipeline .
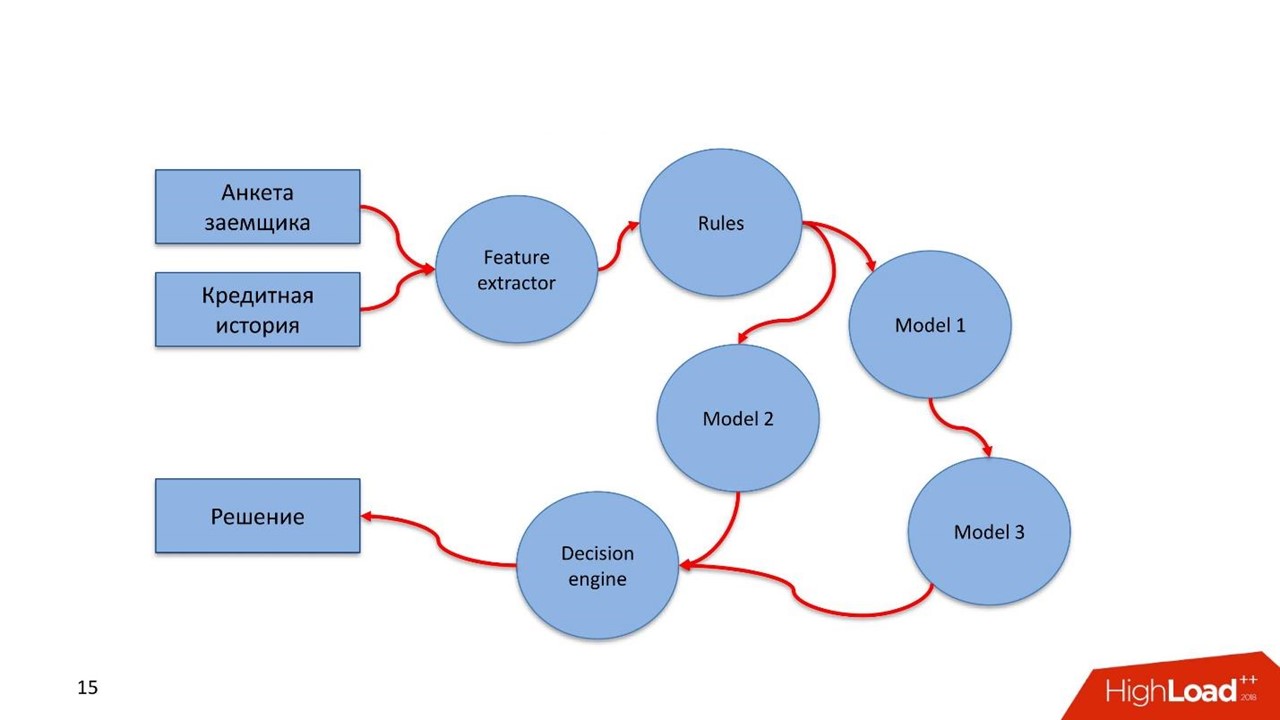
- Feature extractor : , , .
- . , -: , , 18.
- . , . , , pipeline.
- Decision engine . .
- .
yaml. . , , . yaml.
pipeline, , : feature extractor, rules, models, decision engine, . —
Docker- . Registry, Docker-. -, , . , , Docker- .
Tubería
,
Python — . Feature extractor, , decision engine Python.
Pipeline
yaml. meta storage —
.
Runtime environment 10 , Blackboard , pipeline 10 . , : , , IP- Kafka, , . .
GitLab. Ansible. , . , 50 000 Ansible .
?
GitLab pipeline. GitLab. CI , , , .
GitLab Runner , Docker- , pipeline. — Registry.
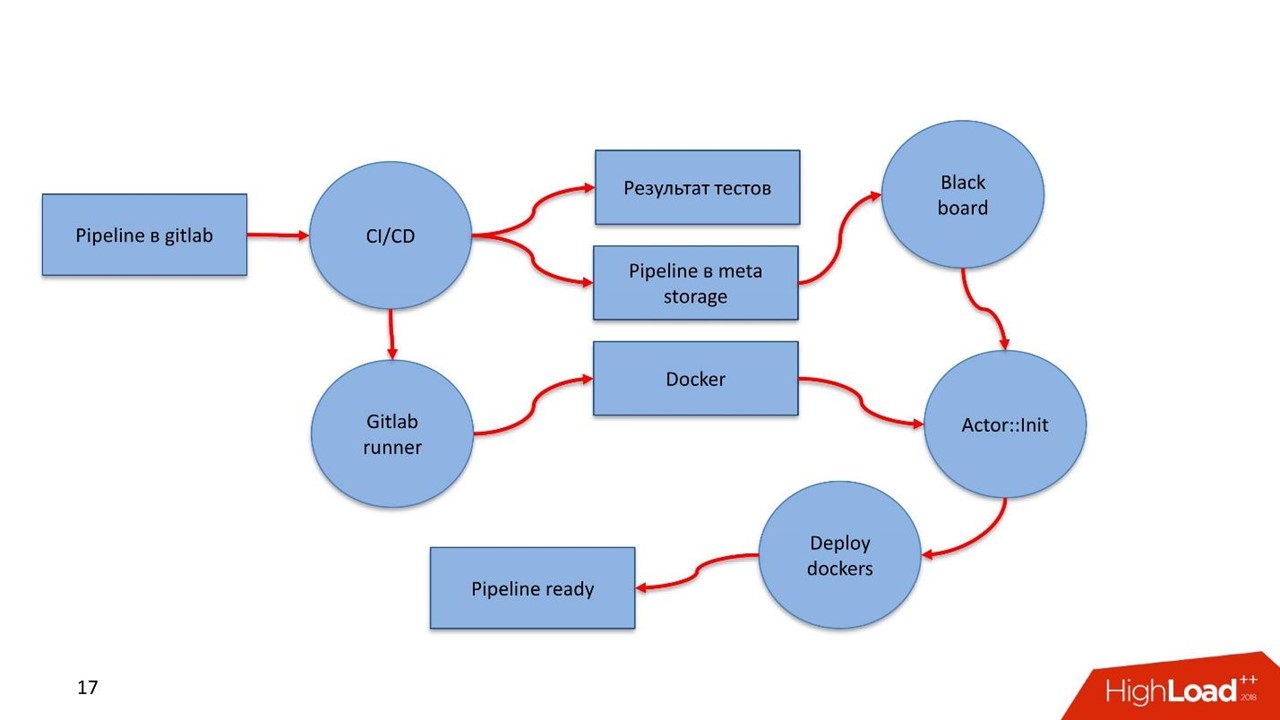
Docker , . Docker- . CI pipeline pipeline - Meta Storage, Blackboard.
Blackboard Meta Storage — , , , -. Docker- , , .
- Blackboard Meta Storage : , Kafka, . , , Docker- , .
, Docker-, — pipeline !
DigitalOcean. AWS Scaleway, .
, . pipeline . , .
?
— . , pipeline, real-time .
- 2 Feature extractor . 1 , .. json .
- 8 — 8 ML engine. XGBoost.
- 18 RB engine (115 ). 1000 .
- 1 decision engine.
200 . 2 Feature extractor, 8 , 18 1 decision engine 1,2 .
Discovery . , - . , , . . Meta Storage.
pipeline . ,
BPM . yaml , , .
. Java, Scala, R. Python, , . API , pipeline .
Cual es el resultado?
— . — .
, . , . — 2018 .
, . — , , .
, . , , notebook , .
, - , , . , , UseData Conf . , , , 16 .