Cuantos más usuarios de su servicio, mayor será la probabilidad de que necesiten ayuda. El chat de soporte técnico es una solución obvia pero bastante costosa. Pero si usa la tecnología de aprendizaje automático, puede ahorrar algo de dinero.
El bot ahora puede responder preguntas simples. Además, se puede enseñar al chatbot a determinar las intenciones del usuario y a capturar el contexto para que pueda resolver la mayoría de los problemas de los usuarios sin intervención humana. Cómo hacer esto, Vladislav Blinov y Valery Baranova, desarrolladores del popular asistente Oleg, ayudarán a resolverlo.
Pasando de métodos simples a otros más complicados en la tarea de desarrollar un bot de chat, analizaremos problemas prácticos de implementación y veremos qué ganancia de calidad puede obtener y cuánto costará.
Vladislav Blinov es un desarrollador senior de sistemas de diálogo en
Tinkoff , a menudo abreviaciones: ML, NLP, DL, etc. Además, la escuela de posgrado examina el modelado del humor a través del aprendizaje automático y las redes neuronales.
Valeria Baranova ha estado escribiendo cosas interesantes en el campo de la PNL en Python durante más de 5 años. Ahora, en el equipo de sistemas interactivos, Tinkoff crea bots de chat y enseña un curso de Machine Learning para estudiantes. También se dedica a la investigación en el campo del humor computacional, es decir, enseña a la inteligencia artificial a comprender los chistes y crear nuevos. Valeria y Vladislav
hablarán sobre esto en UseData Conf.
Los servicios de Tinkoff Bank son utilizados por millones de personas. Para proporcionar asistencia las 24 horas del día a tal cantidad de usuarios, se necesita un gran personal, lo que conlleva un alto costo del servicio. Parece lógico que las preguntas populares de los usuarios puedan responderse automáticamente usando el bot de chat.
Intención o intención del usuario
Lo primero que necesita un chatbot es entender
lo que quiere el usuario . Esta tarea se llama clasificación de intenciones o intenciones. Además, todos los modelos y enfoques serán considerados en el marco de esta tarea.
Veamos un ejemplo de clasificación de intenciones. Si escribe: "Transfiera cientos de Lera", el bot de chat Oleg comprenderá que esta es la intención de una transferencia de dinero, es decir, la intención del usuario de transferir dinero. O más bien, que Lera necesita transferir la cantidad de 100 rublos.
Compararemos métodos y probaremos la calidad de su trabajo en una muestra de prueba, que consiste en diálogos reales con los usuarios. Nuestra muestra contiene más de 30,000 ejemplos marcados y 170 intenciones, por ejemplo: ir al cine, buscar restaurantes, abrir o cerrar un depósito, etc. Oleg también tiene su propia opinión sobre muchas cosas y solo puede chatear contigo.
Clasificación de diccionario
Lo más simple que se puede hacer en la tarea de clasificar intentos es
usar un diccionario . Por ejemplo, si la palabra "traducir" aparece en la frase de un usuario, considere que debe hacerse una transferencia de dinero.
Veamos la calidad de un enfoque tan simple.
Si el clasificador simplemente define la intención del usuario como "transferencia de dinero" con la palabra "traducir", entonces la calidad ya será bastante alta. Precisión: 88%, mientras que la integridad es baja, igual a solo el 23%. Esto es comprensible: la palabra "traducir" no describe todas las posibilidades de decir "transferir dinero a alguien".
Sin embargo, este enfoque tiene ventajas:
- No se necesita muestreo etiquetado (si no estudia el modelo, entonces no se necesita muestreo).
- Puede obtener una alta precisión si compila bien los diccionarios (pero llevará tiempo y recursos).
Sin embargo, la integridad de tal solución es probable que sea baja, ya que todas las variaciones de cualquier clase son difíciles de describir.
Considere un contraejemplo. Si además de la intención de transferencia de dinero, "transferencia" también puede incluir la segunda intención: "transferencia al operador". Cuando agregamos una nueva intención de traducción al operador, obtenemos resultados diferentes.
La precisión se reduce en 18 puntos, mientras que, por supuesto, la integridad no crece. Esto muestra que se necesita un enfoque más avanzado.
Análisis de texto
Antes de utilizar el aprendizaje automático, debe comprender cómo presentar el texto como un vector. Uno de los enfoques más fáciles es
usar un vector tf-idf .
El vector tf-idf tiene en cuenta la aparición de cada palabra en la frase del usuario y tiene en cuenta la aparición total de palabras en la colección. Las palabras que a menudo se encuentran en diferentes textos tienen menos peso en esta representación vectorial.
Veamos la calidad del modelo lineal en representaciones tf-idf (en nuestro caso, regresión logística).
Como resultado,
la integridad aumentó bruscamente y la precisión se mantuvo comparable con el uso del diccionario, la medida f1 (media armónica ponderada entre precisión e integridad) también aumentó. Es decir, el modelo en sí ya comprende qué palabras son importantes para cada intento; no es necesario que invente nada usted mismo.
Visualización de datos
La visualización de datos ayuda a comprender cómo se ven los intentos, qué tan bien están agrupados en el espacio. Pero no podemos visualizar directamente las representaciones de tf-idf debido a la gran dimensión, por lo que utilizaremos
el método de compresión de dimensiones - t-SNE .
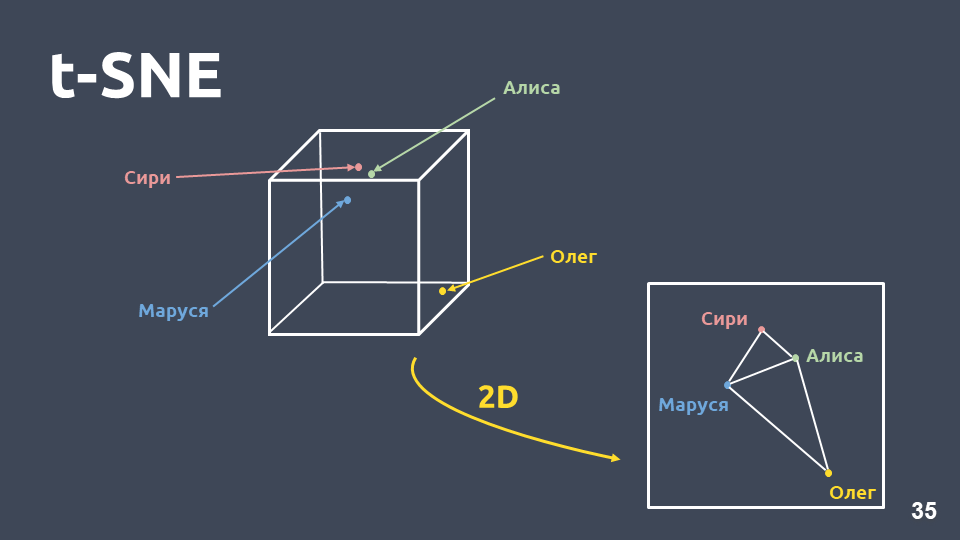
La principal diferencia entre este método y PCA es que cuando se transfiere al espacio bidimensional,
se preserva la
distancia relativa entre los objetos .
t-SNE en tf-idf (10 intentos principales), puntaje F1 0.92Los 10 principales intentos por ocurrencia en nuestra colección se presentan arriba. Hay puntos verdes que no pertenecen a ninguna intención, y 10 grupos que están marcados con diferentes colores son intenciones diferentes. Se puede ver que algunos de ellos están muy bien agrupados.
La medida ponderada de
f1 es 0,92 ; esto es bastante, ya puedes trabajar con ella.
Entonces, con un clasificador lineal sobre tf-idf:
- integridad mucho mayor que el uso de un diccionario, con una precisión comparable;
- no es necesario pensar qué palabras corresponden a qué intención.
Pero también hay desventajas:
- vocabulario limitado, puede obtener peso solo para aquellas palabras que están presentes en la muestra de entrenamiento;
- la reformulación no se tiene en cuenta;
- el orden en que aparecen las palabras en el texto no se tiene en cuenta.
Reformulación
Consideremos con más detalle el problema de la reformulación.
Los vectores Tf-idf solo pueden estar cerca para textos que se cruzan en palabras. La proximidad entre los vectores se puede calcular a través del coseno del ángulo entre ellos. La proximidad del coseno en la representación vectorial tf-idf se calcula para ejemplos específicos.
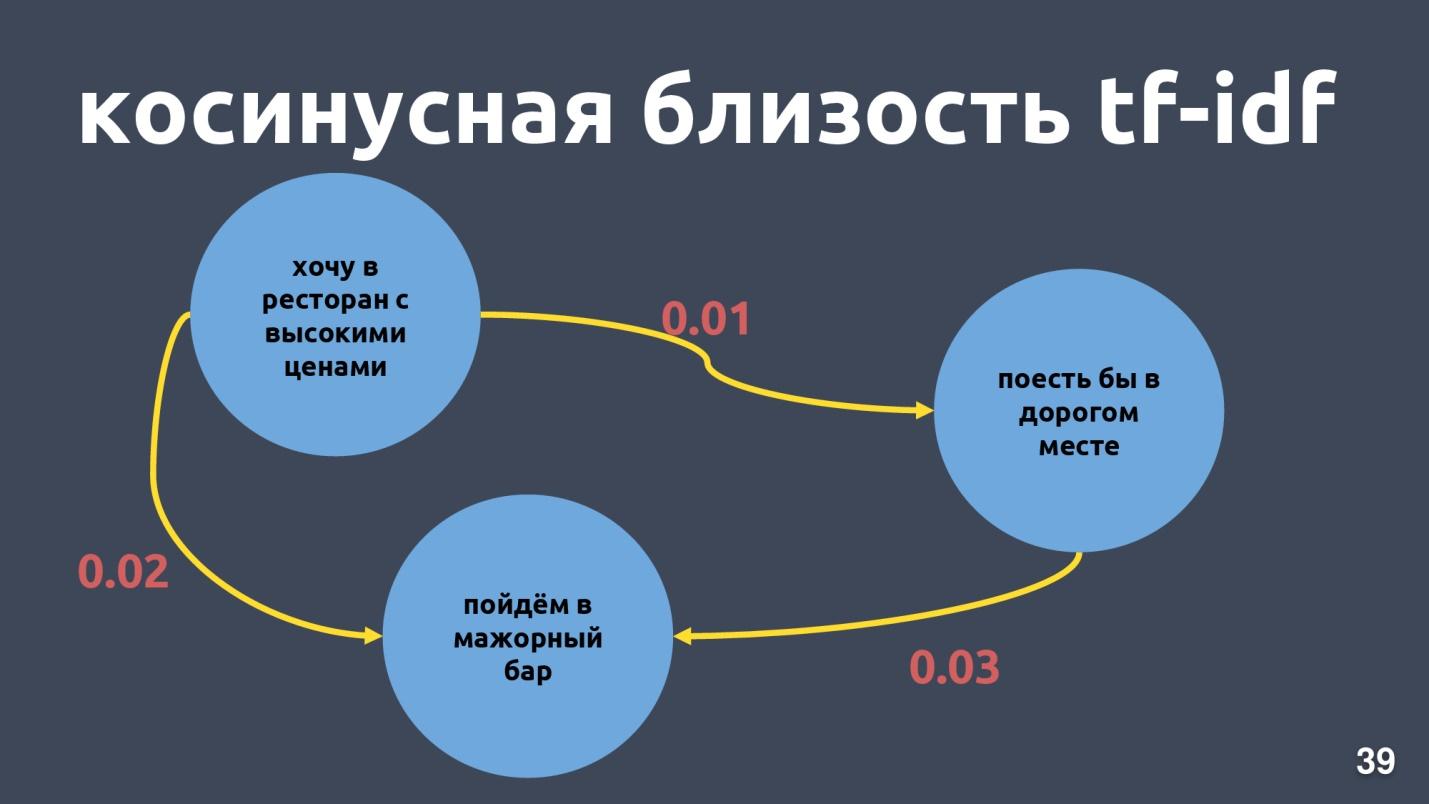
Estas no son frases muy cercanas para la representación vectorial tf-idf, aunque para nosotros es la misma intención y la misma clase.
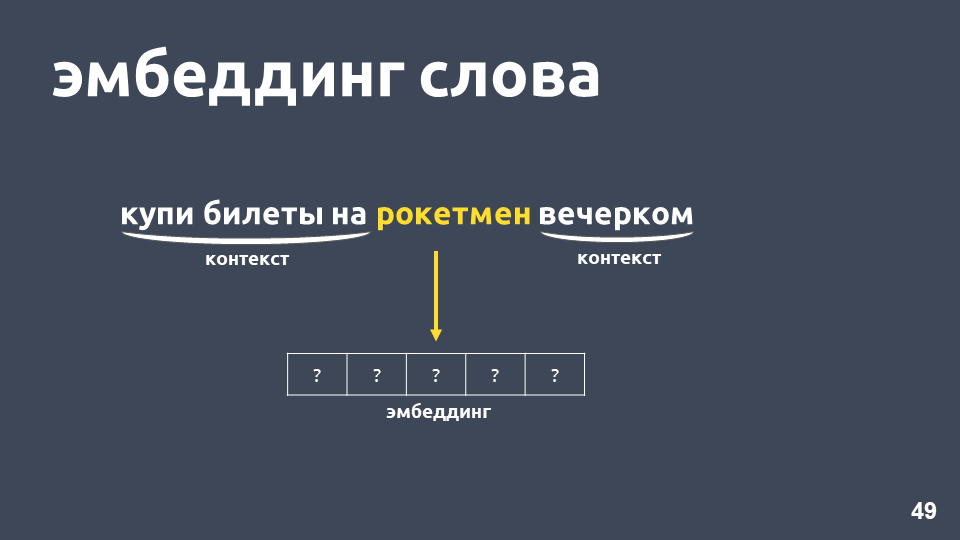
¿Qué se puede hacer al respecto? Por ejemplo, en lugar de un número, puede representar una palabra como un vector completo; esto se denomina "incrustación de palabras".
Uno de los modelos más populares para resolver este problema se propuso en 2013. Se llama
word2vec y se ha usado ampliamente desde entonces.
Una de las formas de aprender Word2vec funciona aproximadamente de la siguiente manera: tomamos el texto, tomamos algunas palabras del contexto y las descartamos, luego tomamos otra palabra al azar del contexto y presentamos ambas palabras como vectores únicos. One-hot vector es un vector de acuerdo con la dimensión del diccionario, donde solo la coordenada correspondiente al índice de la palabra en el diccionario tiene el valor 1, el 0 restante.
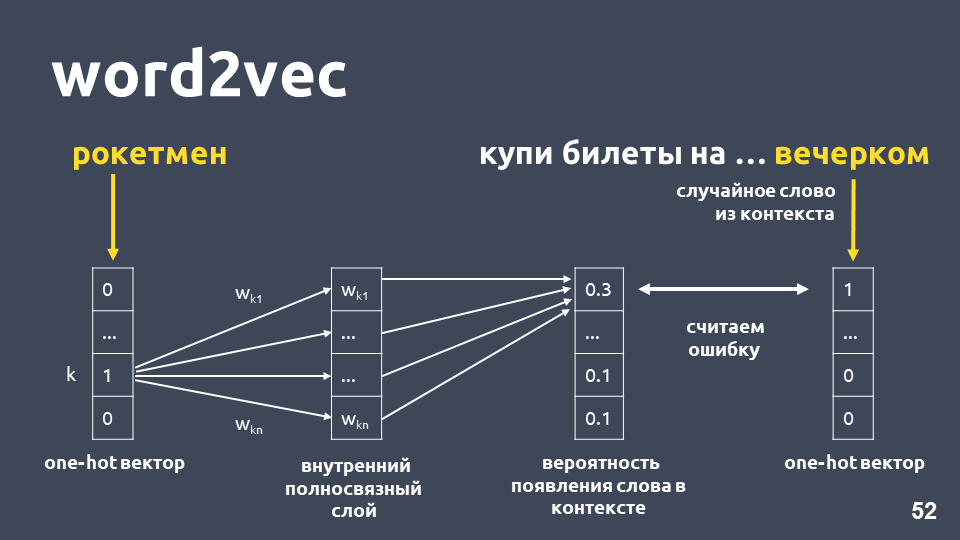
A continuación, entrenamos una red neuronal simple de una sola capa sin activación en la capa interna para predecir la siguiente palabra en contexto, es decir, para predecir la palabra "en la noche" usando la palabra "cohete". En la salida, obtenemos la distribución de probabilidad para todas las palabras del diccionario de la siguiente manera. Como sabemos cuál era realmente la palabra, podemos calcular el error, actualizar los pesos, etc.

Los pesos actualizados obtenidos como resultado de la capacitación en nuestra muestra son la palabra incrustación.
La ventaja de usar incrustación en lugar de número es, en primer lugar,
que se tiene en cuenta ese contexto . Un ejemplo popular: Trump y Putin son cercanos en word2vec porque ambos son presidentes y a menudo se usan juntos en textos.
Para las palabras que se encontraron en la muestra de capacitación, simplemente tome la matriz de incrustación, tome su vector por el índice de la palabra y obtenga la incrustación.
Parece que todo está bien, excepto que algunas palabras en su matriz pueden no estarlo, porque el modelo no las vio durante el entrenamiento. Para abordar el problema de las palabras desconocidas (fuera del vocabulario), en 2014 se les ocurrió una modificación de word2vec -
fasttext .
Fasttext funciona de la siguiente manera: si la palabra no está en el diccionario, se divide en n-gramos simbólicos, por cada incrustación de n-gramas se toma de la matriz de incrustaciones de n-gramos (que se entrenan como word2vec), las incrustaciones se promedian y se obtiene un vector.
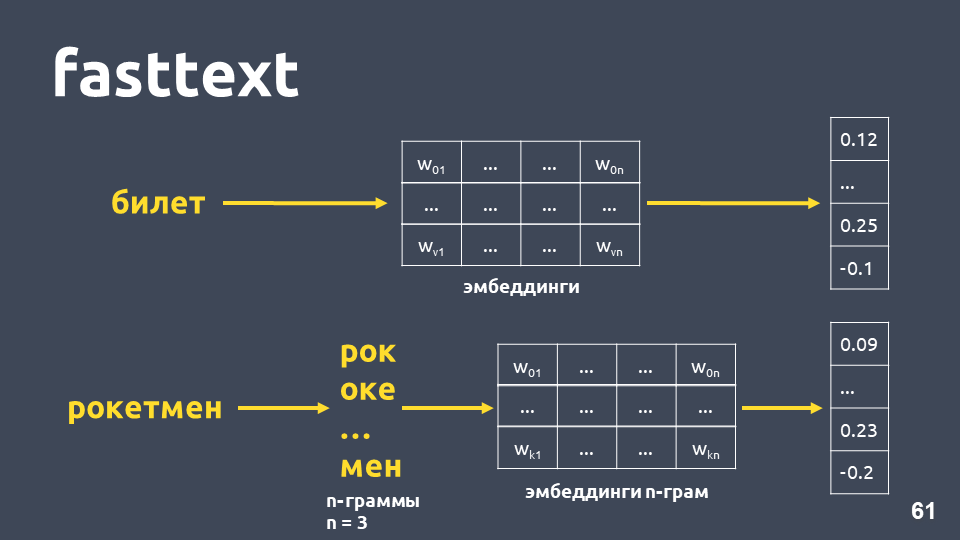
Total, obtenemos vectores para palabras que no están en nuestro diccionario. Ahora podemos
calcular similitudes incluso para palabras desconocidas . Y, lo que es más importante, hay modelos entrenados para ruso, inglés y chino, por ejemplo, Facebook y el proyecto
DeepPavlov , por lo que puede incluirlo rápidamente en su cartera.
Pero las desventajas permanecen:- El modelo no se utiliza para todo el vector de texto. Para obtener un vector de texto común, debe pensar en algo: promedio o promedio con multiplicación por pesos idf, y esto puede funcionar de manera diferente en diferentes tareas.
- El vector para una palabra sigue siendo uno, independientemente del contexto. Word2vec entrena un vector de palabra para cualquier contexto en el que aparece la palabra. Para palabras de valores múltiples (como, por ejemplo, lenguaje) habrá un mismo vector.
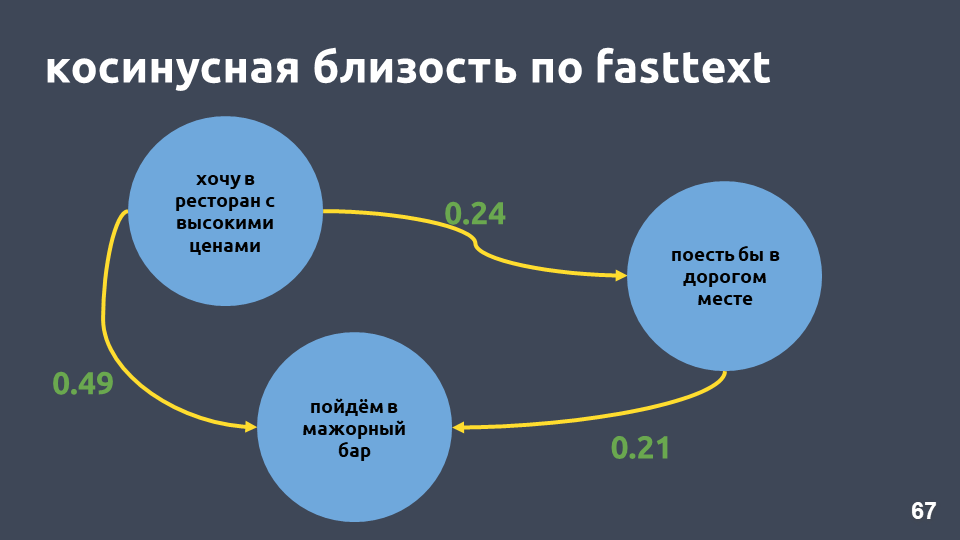
De hecho, la proximidad del coseno en nuestro ejemplo en texto rápido es mayor que la proximidad del coseno en tf-idf, aunque las frases en estas frases son solo "in".
t-SNE en texto rápido (10 intentos principales), puntaje F1: 0.86Sin embargo, al visualizar los resultados de texto rápido en la descomposición de t-SNE, los clústeres de intención se destacan mucho peor que para tf-idf. La medida F1 aquí es 0.86 en lugar de 0.92.
Realizamos un experimento: combinados tf-idf y vectores de texto rápido. La calidad es absolutamente la misma que cuando se usa solo tf-idf. Esto no es cierto para todas las tareas, hay problemas en los que tf-idf y fasttext combinados funcionan mejor que solo tf-idf, o donde fasttext funciona mejor que tf-idf. Necesitas experimentar e intentarlo.
Intentemos aumentar el número de intenciones (recuerde que tenemos 170 de ellas). A continuación se presentan los clústeres para las 30 principales intenciones en los vectores tf-idf.
t-SNE en tf-idf (30 intenciones principales), puntaje F1 0, 85 (a 10 fue 0.92)La calidad cae en 7 puntos, y ahora no vemos una estructura de clúster pronunciada.
Veamos ejemplos de textos que comenzaron a confundirse, porque se agregaron más intentos que se cruzan semánticamente y en palabras.
Por ejemplo: "Y si abre un depósito, ¿cuáles son los intereses?" y "Y quiero abrir una contribución al 7 por ciento". Frases muy similares, pero estas son intenciones diferentes. En el primer caso, una persona quiere saber las condiciones para los depósitos, y en el segundo caso, para abrir un depósito. Para separar dichos textos en diferentes clases, necesitamos algo más complejo:
aprendizaje profundo .
Modelo de idioma
Queremos obtener un vector de texto y, en particular, un vector de una palabra, que dependerá del contexto de uso. La forma estándar de obtener dicho vector es
usar incrustaciones del modelo de lenguaje .
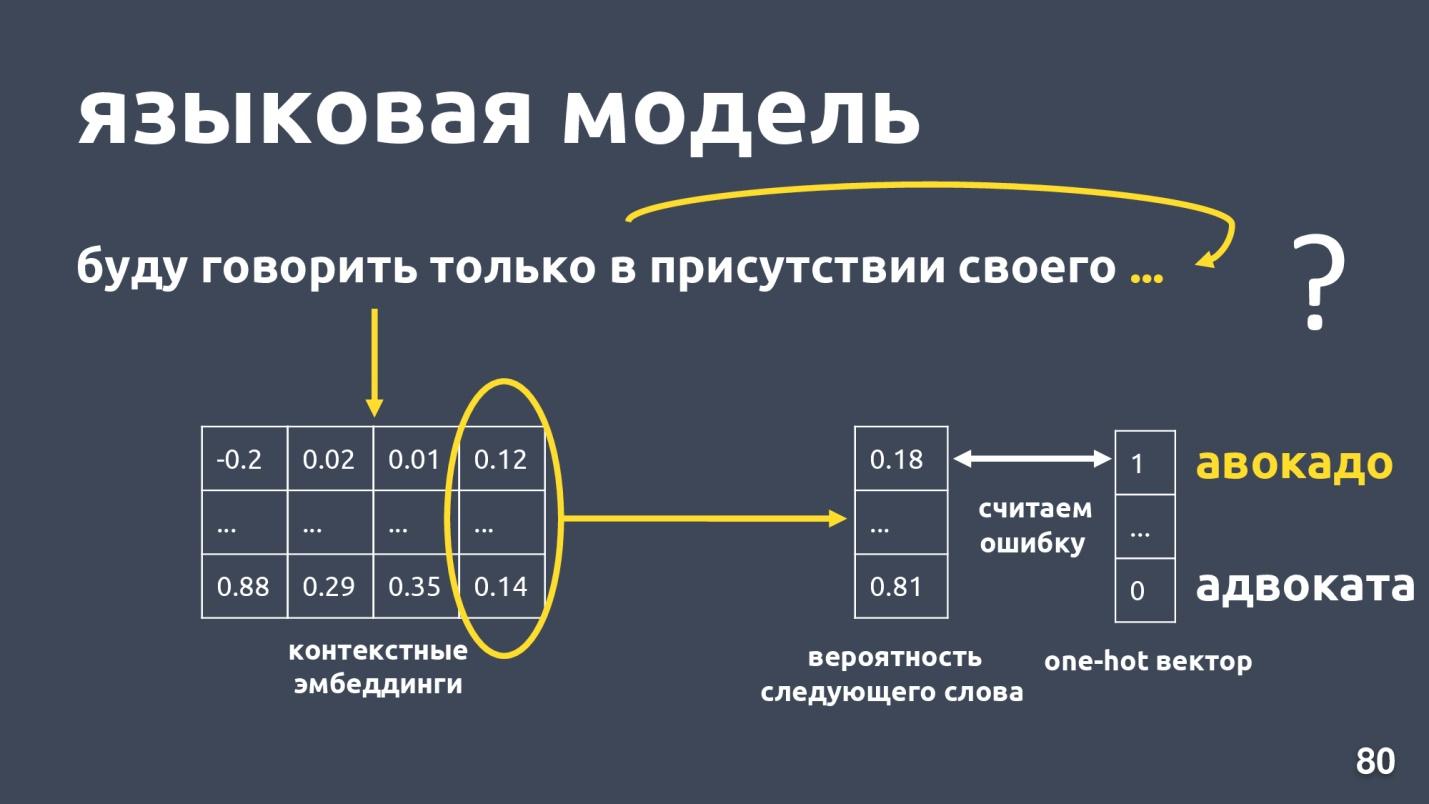
El modelo de lenguaje resuelve el problema del modelado de lenguaje. ¿Y cuál es esta tarea? Que haya una secuencia de palabras, por ejemplo: "Solo hablaré en presencia de mi propia ...", y estamos tratando de predecir la siguiente palabra en la secuencia. El modelo de lenguaje proporciona contexto para incrustaciones. Habiendo obtenido incrustaciones contextuales y vectores para cada palabra, uno puede predecir la probabilidad de la siguiente palabra.
Hay un vector de dimensión de diccionario, y a cada palabra se le asigna la probabilidad de ser el siguiente. Nuevamente sabemos qué palabra era en realidad, consideramos un error y entrenamos el modelo.
Hay bastantes modelos de idiomas, ¿hubo un auge el año pasado? y se han propuesto muchas arquitecturas diferentes. Uno de ellos es
ELMo .
ELMo
La idea del modelo ELMo es construir primero una incrustación simbólica de palabras para cada palabra en el texto, y luego aplicar una
red LSTM para ellas de tal manera que se tengan en cuenta las incrustaciones que tengan en cuenta el contexto en el que se produce la palabra.
Examinemos cómo se obtiene la incrustación simbólica: dividimos la palabra en símbolos, aplicamos una capa de incrustación para cada símbolo y obtenemos una matriz de incrustación. Cuando se trata solo de símbolos, la dimensión de dicha matriz es pequeña. Luego, se aplica una convolución unidimensional a la matriz de incrustación, como generalmente se hace en PNL, con una agrupación máxima al final, se obtiene un vector. Se aplica a este vector una llamada
red de autopistas de dos capas, que calcula el
vector general de una palabra .
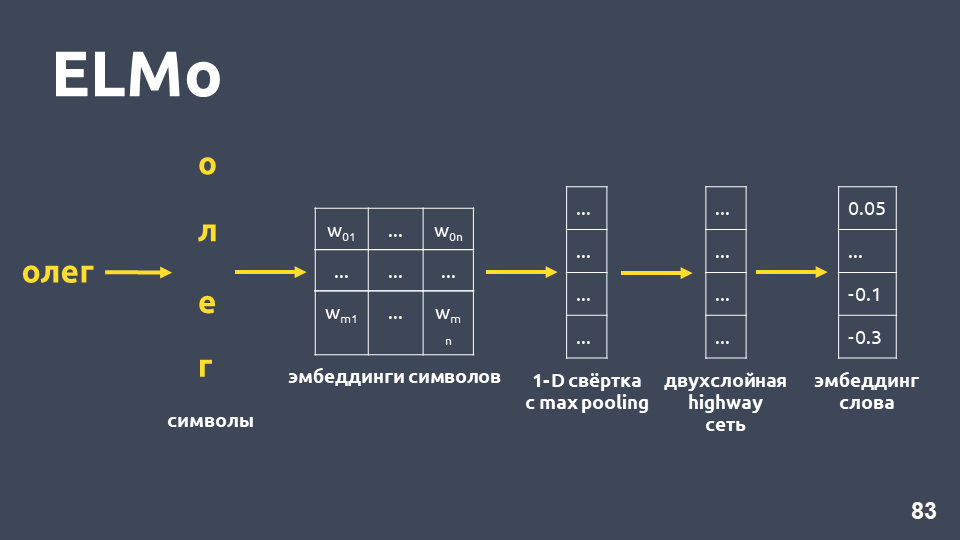
Además, el modelo construirá algún tipo de hipótesis de inclusión incluso para una palabra que no se encontró en el conjunto de entrenamiento.
Después de haber recibido incrustaciones simbólicas para cada palabra, les aplicamos una red BiLSTM de dos capas.
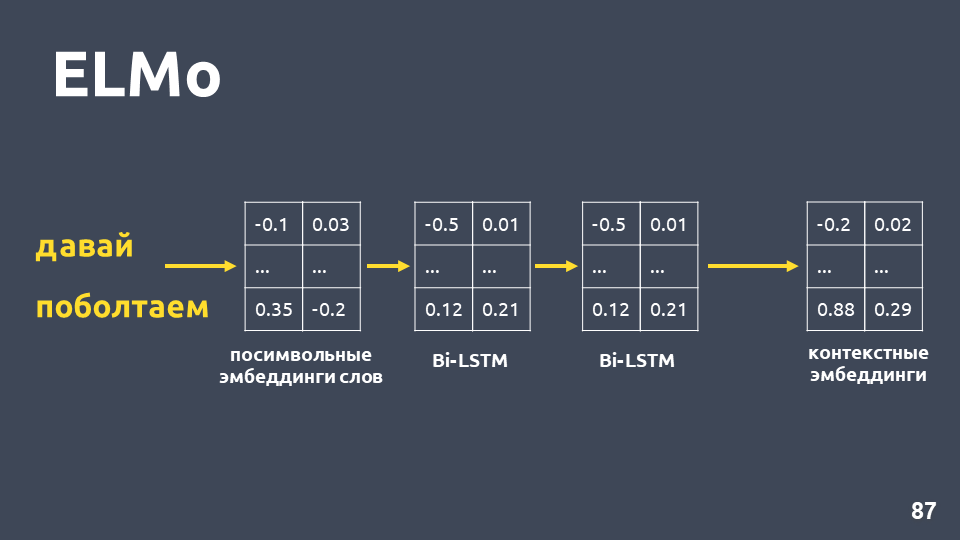
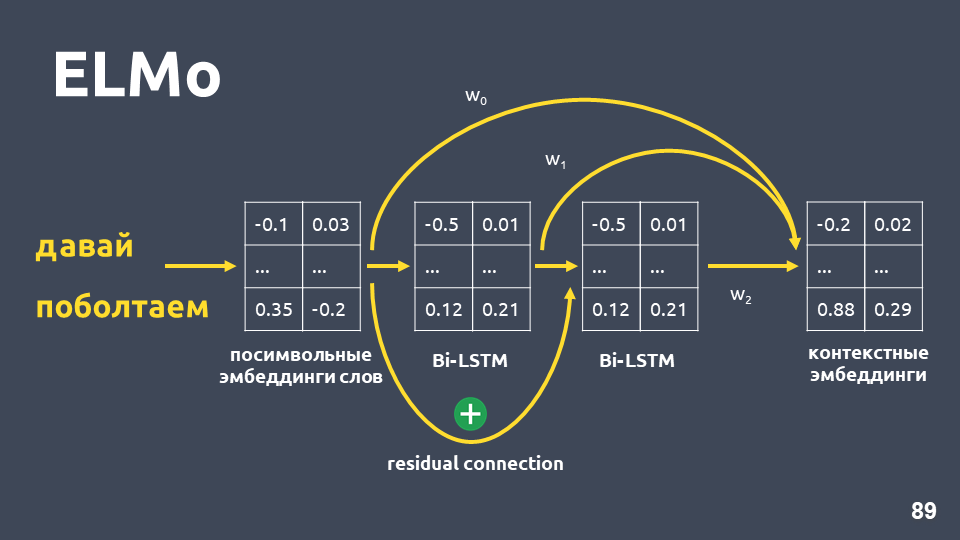
Después de aplicar una red BiLSTM de dos capas, generalmente se toman los estados ocultos de la última capa, y se cree que esto es incrustación contextual. Pero ELMo tiene dos características:
- Conexión residual entre la entrada de la primera capa LSTM y su salida. La entrada LSTM se agrega a la salida para evitar el problema de gradientes de desvanecimiento.
- Los autores de ELMo proponen combinar la incrustación simbólica para cada palabra, la salida de la primera capa LSTM y la salida de la segunda capa LSTM con algunos pesos seleccionados para cada tarea. Esto es necesario para tener en cuenta las características de bajo nivel y las características de nivel superior que proporcionan la primera y segunda capa de LSTM.
En nuestro problema, utilizamos un promedio simple de estas tres incrustaciones y, por lo tanto, obtuvimos la incrustación contextual para cada palabra.
El modelo de lenguaje proporciona los siguientes beneficios:
- El vector de una palabra depende del contexto en el que se usa la palabra. Es decir, por ejemplo, para la palabra "lenguaje" en el significado de la parte del cuerpo y el término lingüístico, obtenemos diferentes vectores.
- Como en el caso de word2vec y fasttext, hay muchos modelos entrenados, por ejemplo, del proyecto DeepPavlov . Puede tomar el modelo terminado e intentar aplicarlo en su tarea.
- Ya no necesita pensar en cómo promediar los vectores de palabras. El modelo ELMo produce inmediatamente un vector de todo el texto.
- Puede volver a capacitar el modelo de idioma para su tarea, hay varias formas de hacerlo, por ejemplo, ULMFiT.
El único signo negativo sigue siendo que el
modelo de lenguaje no garantiza que los textos que pertenecen a la misma clase, es decir, con un solo propósito, estén cerca en el espacio vectorial.
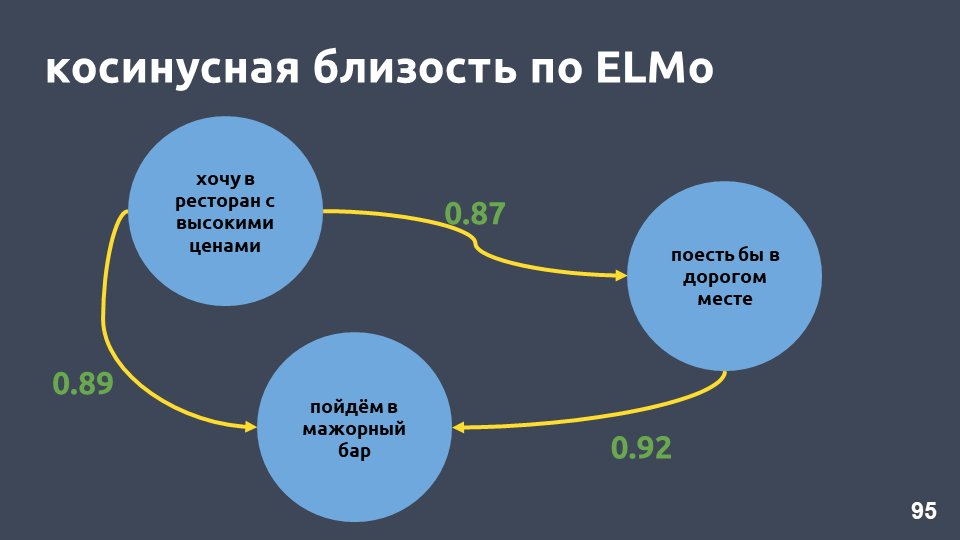
En nuestro ejemplo de restaurante, los valores del coseno según el modelo ELMo realmente se volvieron más altos.
t-SNE en ELMo (10 intenciones principales), puntaje F1 0.93 (0.92 por tf-idf)Los grupos con 10 intenciones principales también son más pronunciados. En la figura anterior, los 10 grupos son claramente visibles, mientras que la precisión ha aumentado ligeramente.
t-SNE en ELMo (30 intenciones principales) Puntaje F1 0.86 (0.85 por tf-idf)Para las 30 principales intenciones, la estructura del clúster aún se conserva, y también hay un aumento de la calidad en un punto.
Pero en ese modelo no hay garantía de que las propuestas "Y si abre un depósito, ¿cuáles son los intereses en ellas?" y "Y quiero abrir una contribución al 7 por ciento" estarán lejos el uno del otro, aunque se encuentran en diferentes clases. Con ELMo, simplemente aprendemos el modelo de lenguaje, y si los textos son semánticamente similares, entonces estarán cerca.
ELMo no sabe nada acerca de nuestras clases , pero puede reunir vectores de texto de la misma intención en el espacio utilizando etiquetas de clase.
Red siamesa
Tome su arquitectura de red neuronal favorita para la vectorización de texto y dos ejemplos de intenciones. Para cada uno de los ejemplos obtenemos incrustaciones, y luego calculamos la distancia del coseno entre ellos.
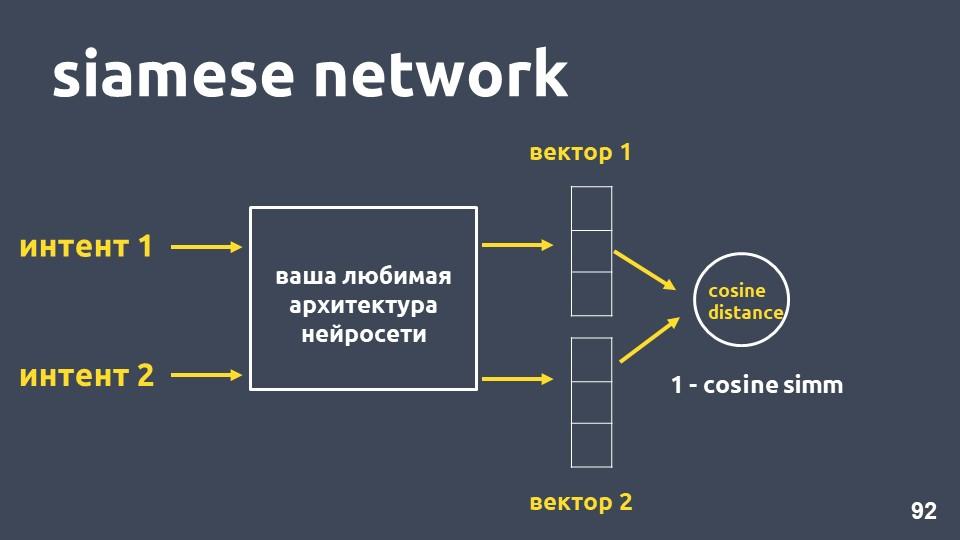
La distancia del coseno es igual a uno menos la proximidad del coseno que conocimos anteriormente.
Este enfoque se llama la
red siamesa .
Queremos que los textos de la misma clase, por ejemplo, "hacer una transferencia" y "tirar dinero", estén cerca en el espacio. Es decir, la distancia del coseno entre sus vectores debe ser lo más pequeña posible, idealmente cero. Y los textos relacionados con diferentes intenciones deben estar lo más separados posible.
Pero en la práctica, este método de entrenamiento no funciona tan bien, porque los objetos de diferentes clases no se alejan lo suficiente entre sí. La función de pérdida llamada
"pérdida de triplete" funciona mucho mejor. Utiliza triples de objetos llamados trillizos.
La ilustración muestra un triplete: un objeto de anclaje en un círculo azul, un objeto positivo en verde y un objeto negativo en un círculo rojo. El objeto negativo y el ancla están en diferentes clases, y el positivo y el ancla están en uno.

Queremos asegurarnos de que, después del entrenamiento, el objeto positivo esté más cerca del ancla que el negativo. Para hacer esto, consideramos la distancia del coseno entre los pares de objetos e ingresamos el hiperparámetro - "margen" - la distancia que esperamos que esté entre los objetos positivos y negativos.

La función de pérdida se ve así:
En otras palabras, durante el entrenamiento, logramos que el objeto positivo esté más cerca del ancla que el negativo, al menos margen. Si la función de pérdida es cero, entonces funciona, y terminamos el entrenamiento, de lo contrario, continuamos minimizando la función objetivo.
Después de haber entrenado el modelo, todavía no obtenemos un clasificador, es solo un método para obtener tales incrustaciones que los objetos que se encuentran en la misma intención probablemente tengan vectores cercanos.
Cuando obtuvimos el modelo, podemos usar un método de clasificación diferente además de las incrustaciones.
KNN es una buena opción, ya que hemos logrado que las incrustaciones tengan una estructura de clúster distinta.
Recuerde cómo funciona kNN para los textos: tome un elemento del texto, incrústelo, traduzca al espacio vectorial y luego vea quién es su vecino. Entre los vecinos, consideramos la clase más frecuente y concluimos que el nuevo objeto pertenece a esta clase.
La dimensión de las incrustaciones que utilizamos es de 300, y en la muestra de entrenamiento hay alrededor de 500,000 objetos. Los métodos estándar para encontrar a los vecinos más cercanos no nos convienen en términos de rendimiento. Utilizamos el método
HNSW :
Hierarchical Navigable Small World .
Navigable Small World es un gráfico conectado en el que hay pocos bordes entre vértices que están a una gran distancia y muchos bordes entre vértices cercanos. En nuestro caso, la longitud del borde estará determinada por la distancia del coseno, es decir , , .
, Hierarchical. , , , . .
, , , , .
, , , , , . , , ,
— 0,95-0,99 , .
, , , ,
. .
, . , . .
t-SNE siamese (-10 ), F1 score 0,95 (0,93 ELMo)t-SNE siamese (-30 ), F1 score 0,87 (0,86 ELMo)10 ELMo, 30 — , .
Resumen
, , , 2-5, . , , , 20-30 . , .
, , , tf-idf . , , , .
, word2vec fasttext. , , . , , , .
, , ELMo. , , , , , .
ELMo, , .
, - . . , . , , . , , .. , .
:— «Deep Learning vs common sense» — UseData Conf . , - , 18 , , .
, , , , 16 UseData Conf .