Recientemente, los fabricantes de FPGA y compañías de terceros han estado desarrollando activamente métodos de desarrollo para FPGA que difieren de los enfoques convencionales utilizando herramientas de desarrollo de alto nivel.
Como desarrollador de FPGA, utilizo el lenguaje de descripción de hardware (
HDL ) de Verilog como la herramienta principal, pero la creciente popularidad de los nuevos métodos despertó mi gran interés, por lo que en este artículo decidí entender lo que estaba sucediendo.
Este artículo no es una guía o instrucción de uso, esta es mi revisión y conclusiones sobre lo que varias herramientas de desarrollo de alto nivel pueden dar a un desarrollador o programador de FPGA que quiera sumergirse en el mundo de FPGA. Para comparar las herramientas de desarrollo más interesantes en mi opinión, escribí varias pruebas y analicé los resultados. Debajo del corte, lo que salió de él.
¿Por qué necesita herramientas de desarrollo de alto nivel para FPGA?
- Acelerar el desarrollo del proyecto
- debido a la reutilización de código ya escrito en idiomas de alto nivel;
- mediante el uso de todas las ventajas de los lenguajes de alto nivel, al escribir código desde cero;
- Al reducir el tiempo de compilación y la verificación del código.
- Capacidad para crear código universal que funcionará en cualquier familia FPGA.
- Reduzca el umbral de desarrollo para FPGA, por ejemplo, evitando los conceptos de "velocidad de reloj" y otras entidades de bajo nivel. Capacidad para escribir código para FPGA a un desarrollador que no esté familiarizado con HDL.
¿De dónde vienen las herramientas de desarrollo de alto nivel?
Ahora muchos se sienten atraídos por la idea del desarrollo de alto nivel. Ambos entusiastas, como, por ejemplo,
Quokka y
el generador de código Python , y corporaciones, como
Mathworks , y los fabricantes de FPGA
Intel y
Xilinx están involucrados en esto.
Todos usan sus métodos y herramientas para lograr su objetivo. Los entusiastas en la lucha por un mundo perfecto y hermoso usan sus lenguajes de desarrollo favoritos, como Python o C #. Las corporaciones, que intentan complacer al cliente, ofrecen sus propias herramientas o las adaptan. Mathworks ofrece su propia herramienta de codificación HDL para generar código HDL a partir de m-scripts y modelos Simulink, mientras que Intel y Xilinx ofrecen compiladores para el C / C ++ común.
Por el momento, las empresas con importantes recursos financieros y humanos han logrado un mayor éxito, mientras que los entusiastas están algo retrasados. Este artículo estará dedicado a la consideración del codificador HDL de producto de Mathworks y el compilador HLS de Intel.
¿Qué hay de Xilinx?En este artículo, no considero HIL de Xilinx, debido a las diferentes arquitecturas y sistemas CAD de Intel y Xilinx, lo que hace imposible hacer una comparación inequívoca de los resultados. Pero quiero señalar que Xilinx HLS, como Intel HLS, proporciona un compilador C / C ++ y son conceptualmente similares.
Comencemos comparando el codificador HDL de Mathworks y el Compilador Intel HLS, después de haber resuelto varios problemas usando diferentes enfoques.
Comparación de herramientas de desarrollo de alto nivel.
Prueba uno. “Dos multiplicadores y una sumadora”
La solución a este problema no tiene valor práctico, pero es muy adecuada como primera prueba. La función toma 4 parámetros, multiplica el primero con el segundo, el tercero con el cuarto y agrega los resultados de la multiplicación. Nada complicado, pero veamos cómo nuestros sujetos lidian con esto.
Codificador HDL por Mathworks
Para resolver este problema, el script m tiene el siguiente aspecto:
function [out] = TwoMultAdd(a,b,c,d) out = (a*b)+(c*d); end
Veamos qué nos ofrece Mathworks para convertir código a HDL.
No consideraré el trabajo con HDL-codificador en detalle, me detendré solo en la configuración que cambiaré en el futuro para obtener diferentes resultados en FPGA, y los cambios de los cuales deberá ser considerado por el programador de MATLAB que necesita ejecutar su código en FPGA.
Entonces, lo primero que debe hacer es establecer el tipo y el rango de valores de entrada. No hay char, int, float, double familiares en FPGA. La profundidad de bits del número puede ser cualquiera, es lógico elegirlo, en función del rango de valores de entrada que planea utilizar.
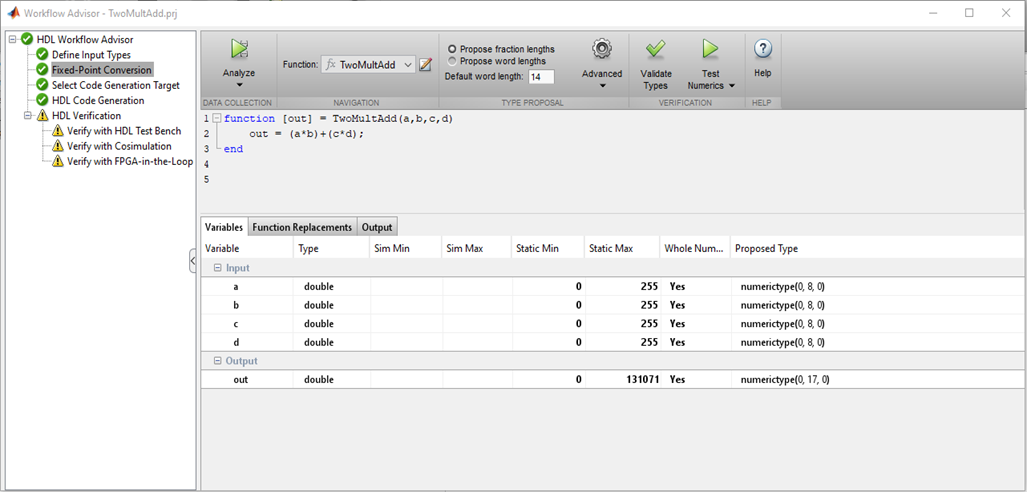 Figura 1
Figura 1MATLAB verifica los tipos de variables, sus valores y selecciona los tamaños de bits correctos para buses y registros, lo cual es realmente conveniente. Si no hay problemas con la profundidad de bits y la escritura, puede pasar a los siguientes puntos.
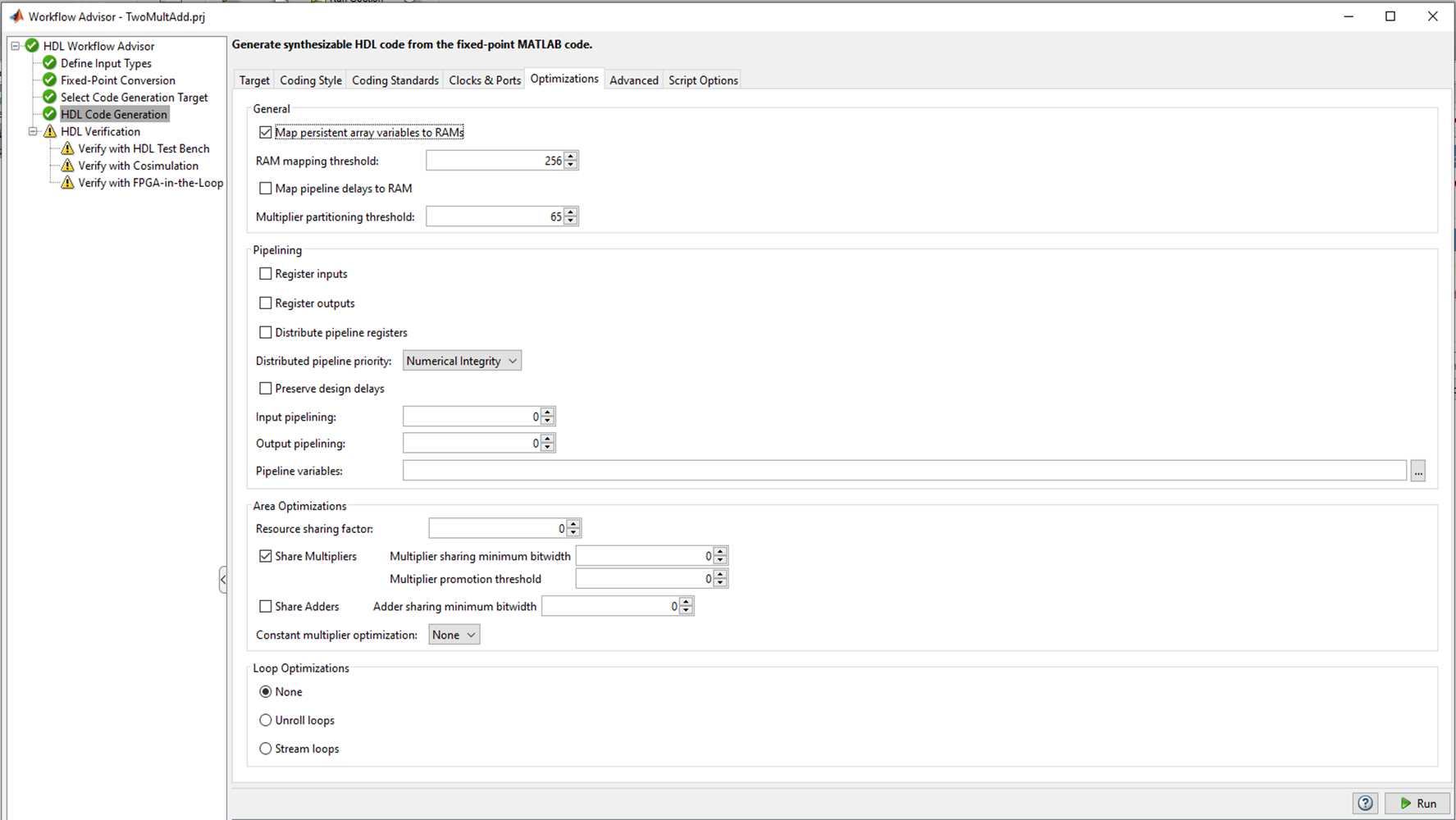 Figura 2
Figura 2Hay varias pestañas en la Generación de código HDL donde puede elegir el idioma para convertir (Verilog o VHDL); estilo de código nombres de señales. La pestaña más interesante, en mi opinión, es Optimización, y experimentaré con ella, pero más adelante, por ahora, dejemos todos los valores predeterminados y veamos qué sucede con el codificador HDL "listo para usar".
Presione el botón Ejecutar y obtenga el siguiente código:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (a, b, c, d, out); input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output [16:0] out; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; endmodule // TwoMultAdd_fixpt
El código se ve bien. MATLAB entiende que escribir la expresión completa en una sola línea en Verilog es una mala práctica. Crea
cables separados para el multiplicador y el sumador, no hay nada de qué quejarse.
Es alarmante que falte la descripción de los registros. Esto sucedió porque no le preguntamos al HDL-codificador sobre esto, y dejamos todos los campos en la configuración a sus valores predeterminados.
Esto es lo que Quartus sintetiza a partir de dicho código.
 Figura 3
Figura 3Sin problemas, todo fue según lo planeado.
En FPGA implementamos circuitos sincrónicos, y todavía me gustaría ver los registros. HDL-coder ofrece un mecanismo para colocar registros, pero dónde ubicarlos depende del desarrollador. Podemos colocar los registros en la entrada de los multiplicadores, en la salida de los multiplicadores frente al sumador, o en la salida del sumador.
Para sintetizar los ejemplos, elegí la familia FPGA Cyclone V, donde se usan bloques DSP especiales con sumadores y multiplicadores incorporados para implementar operaciones aritméticas. El bloque DSP se ve así:
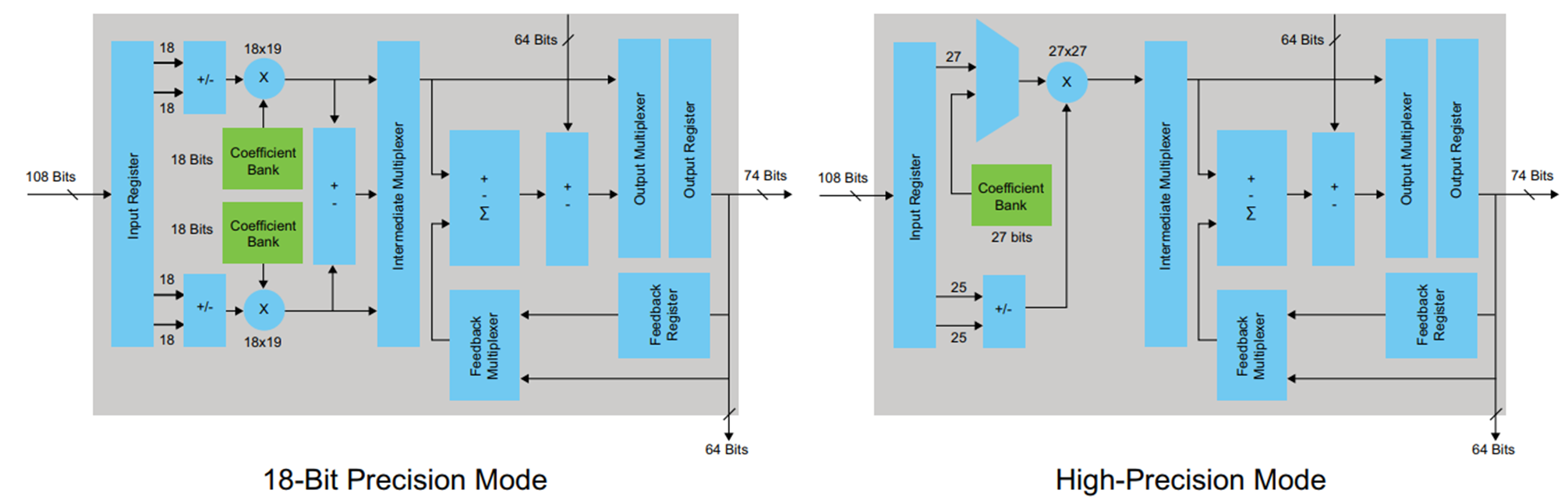 Figura 4
Figura 4El bloque DSP tiene registros de entrada y salida. No es necesario intentar ajustar los resultados de la multiplicación en el registro antes de la adición, esto solo violará la arquitectura (en ciertos casos, esta opción es posible e incluso necesaria). Depende del desarrollador decidir cómo manejar el registro de entrada y salida en función de los requisitos de latencia y la frecuencia máxima requerida. Decidí usar solo el registro de salida. Para que este registro se describa en el código generado por el codificador HDL, en la pestaña Opciones del codificador HDL debe marcar la casilla de verificación Registrar salida y reiniciar la conversión.
Resulta el siguiente código:
`timescale 1 ns / 1 ns module TwoMultAdd_fixpt (clk, reset, clke_ena_i, a, b, c, d, clke_ena_o, out); input clk; input reset; input clke_ena_i; input [7:0] a; // ufix8 input [7:0] b; // ufix8 input [7:0] c; // ufix8 input [7:0] d; // ufix8 output clke_ena_o; output [16:0] out; // ufix17 wire enb; wire [16:0] out_1; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16 wire [16:0] TwoMultAdd_fixpt_2; // ufix17 wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16 wire [16:0] TwoMultAdd_fixpt_3; // ufix17 reg [16:0] out_2; // ufix17 //HDL code generation from MATLAB function: TwoMultAdd_fixpt //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% // % // Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 % // % //%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% assign TwoMultAdd_fixpt_mul_temp = a * b; assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp}; assign TwoMultAdd_fixpt_mul_temp_1 = c * d; assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1}; assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3; assign enb = clke_ena_i; always @(posedge clk or posedge reset) begin : out_reg_process if (reset == 1'b1) begin out_2 <= 17'b00000000000000000; end else begin if (enb) begin out_2 <= out_1; end end end assign clke_ena_o = clke_ena_i; assign out = out_2; endmodule // TwoMultAdd_fixpt
Como puede ver, el código tiene diferencias fundamentales en comparación con la versión anterior. Siempre apareció un bloque, que es una descripción del registro (justo lo que queríamos). Para la operación de siempre bloqueo, también aparecieron las entradas del módulo clk (frecuencia de reloj) y reinicio (reinicio). Se puede ver que la salida del sumador está bloqueada en el disparador descrito en siempre. También hay un par de señales de permiso ena, pero no son muy interesantes para nosotros.
Veamos el diagrama que Quartus ahora sintetiza.
 Figura 5
Figura 5Y nuevamente, los resultados son buenos y esperados.
La siguiente tabla muestra la tabla de recursos utilizados; lo tenemos en cuenta.
 Figura 6
Figura 6Para esta primera búsqueda, Mathworks recibe un crédito. Todo no es complicado, predecible y con el resultado deseado.
Describí en detalle un ejemplo simple, proporcioné un diagrama de un bloque DSP y describí las posibilidades de usar la configuración de uso de registro en HDL-codificador, que son diferentes de la configuración "predeterminada". Esto se hace por una razón. Con esto me gustaría enfatizar que incluso en un ejemplo tan simple, cuando se usa el codificador HDL, es necesario el conocimiento de la arquitectura FPGA y los fundamentos de los circuitos digitales, y la configuración debe cambiarse conscientemente.
Compilador Intel HLS
Intentemos compilar código con la misma funcionalidad escrita en C ++ y ver qué se sintetiza finalmente en FPGA utilizando el compilador HLS.
Entonces el código C ++
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d) { return (a*b)+(c*d); }
Elegí los tipos de datos para evitar el desbordamiento de las variables.
Existen métodos avanzados para establecer profundidades de bits, pero nuestro objetivo es probar la capacidad de ensamblar funciones escritas en estilo C / C ++ bajo FPGA sin hacer ningún cambio, todo listo para usar.
Dado que el compilador HLS es una herramienta nativa de Intel, recopilamos el código con un compilador especial y verificamos el resultado inmediatamente en Quartus.
Veamos el circuito que Quartus sintetiza.
 Figura 7
Figura 7El compilador creó registros en la entrada y salida, pero la esencia está oculta en el módulo contenedor. Comenzamos a implementar el contenedor y ... vemos más, más y más módulos anidados.
La estructura del proyecto se ve así.
 Figura 8
Figura 8Una pista obvia de Intel es "¡no lo tengas en tus manos!". Pero lo intentaremos, especialmente la funcionalidad no es complicada.
En las entrañas del árbol del proyecto | quartus_compile | TwoMultAdd: TwoMultAdd_inst | TwoMultAdd_internal: twomultadd_internal_inst | TwoMultAdd_fu
nction_wrapper: TwoMultAdd_internal | TwoMultAdd_function: theTwoMultAdd_function | bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start | bb_TwoMultAdd_B1_start_stall_region: thebb_TwoMultAdd_B1_start_stall_region | i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd: thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x | i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13: thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x | Mult1 es el módulo que está buscando.
Podemos ver el diagrama del módulo deseado sintetizado por Quartus.
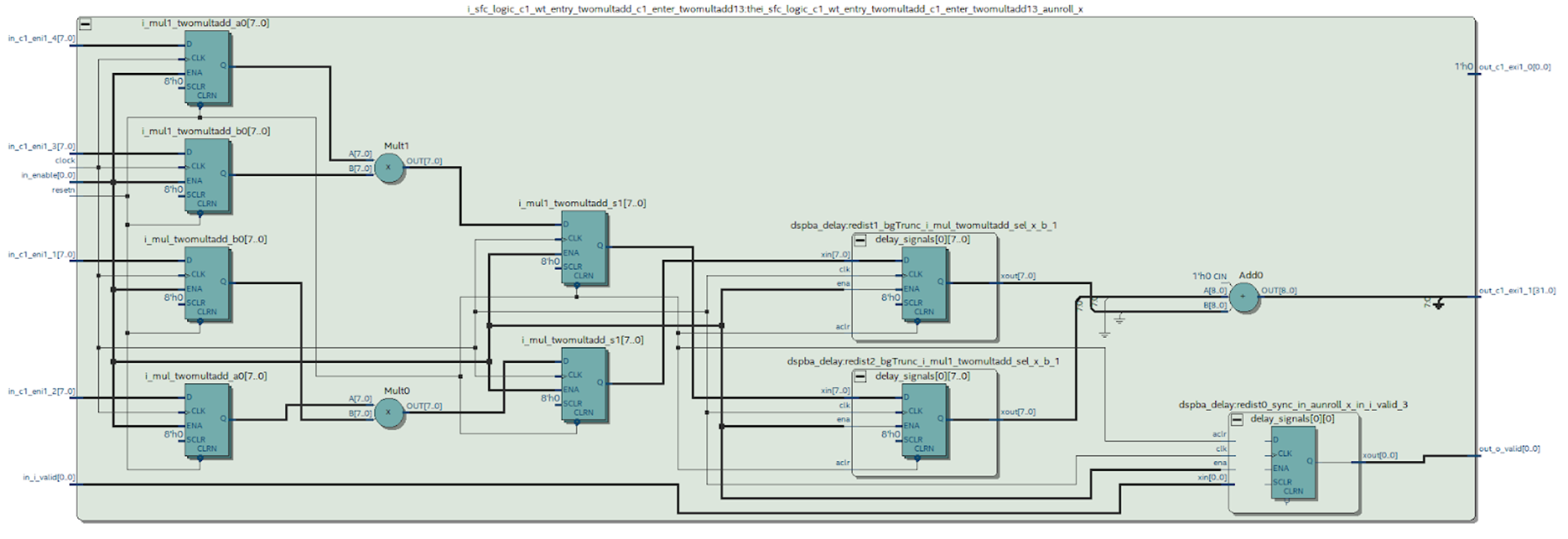 Figura 9
Figura 9¿Qué conclusiones se pueden sacar de este esquema?
Es evidente que sucedió algo que intentamos evitar al trabajar en MATLAB: se sintetizó el caso en la salida del multiplicador; esto no es muy bueno. Se puede ver en el diagrama de bloques DSP (Figura 4) que solo hay un registro en su salida, lo que significa que cada multiplicación tendrá que hacerse en un bloque separado.
La tabla de recursos utilizados muestra a qué conduce esto.
 Figura 10
Figura 10Compare los resultados con la tabla de codificador HDL (Figura 6).
Si utiliza una mayor cantidad de registros que puede soportar, gastar preciosos bloques DSP en una funcionalidad tan simple es muy desagradable.
Pero hay una gran ventaja en Intel HLS en comparación con el codificador HDL. Con la configuración predeterminada, el compilador HLS desarrolló un diseño síncrono en FPGA, aunque gastó más recursos. Tal arquitectura es posible, está claro que Intel HLS está configurado para lograr el máximo rendimiento y no para ahorrar recursos.
Veamos cómo se comportan nuestros sujetos con proyectos más complejos.
La segunda prueba. "Multiplicación de matrices por elementos con la suma del resultado"
Esta función es ampliamente utilizada en el procesamiento de imágenes: el llamado
"filtro matricial" . Lo vendemos con herramientas de alto nivel.
Codificador HDL por Mathwork
El trabajo comienza inmediatamente con una limitación. HDL Coder no puede aceptar funciones de matriz 2D como entradas. Dado que MATLAB es una herramienta para trabajar con matrices, este es un duro golpe para todo el código heredado, que puede convertirse en un problema grave. Si el código está escrito desde cero, esta es una característica desagradable que debe considerarse. Por lo tanto, debe implementar todas las matrices en un vector e implementar las funciones teniendo en cuenta los vectores de entrada.
El código para la función en MATLAB es el siguiente
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ = sum(mult); out = summ/len; end
El código HDL generado resultó ser muy hinchado y contiene cientos de líneas, por lo que no lo daré aquí. Veamos qué esquema sintetiza Quartus a partir de este código.
 Figura 11
Figura 11Este esquema parece fracasado. Formalmente, está funcionando, pero supongo que funcionará a una frecuencia muy baja y difícilmente se puede usar en hardware real. Pero cualquier suposición debe ser verificada. Para hacer esto, colocaremos los registros en la entrada y salida de este circuito y con la ayuda de Timing Analyzer evaluaremos la situación real. Para llevar a cabo el análisis, debe especificar la frecuencia de operación deseada del circuito para que Quartus sepa qué esforzarse al cablear y, en caso de falla, proporcionar informes de violaciones.
Establecemos la frecuencia en 100 MHz, veamos qué puede extraer Quartus del circuito propuesto.
 Figura 12
Figura 12Se puede ver que resultó un poco: 33 MHz parecen frívolos. El retraso en la cadena de multiplicadores y sumadores es de aproximadamente 30 ns. Para deshacerse de este "cuello de botella", debe utilizar el transportador: insertar registros después de las operaciones aritméticas, reduciendo así la ruta crítica.
El codificador HDL nos brinda esta oportunidad. En la pestaña Opciones, puede establecer variables de canalización. Dado que el código en cuestión está escrito en el estilo MATLAB, no hay forma de canalizar las variables (excepto las variables mult y summ), lo que no nos conviene. Es necesario insertar los registros en los circuitos intermedios ocultos en nuestro código HDL.
Además, la situación con la optimización podría ser peor. Por ejemplo, nada nos impide escribir código
out = (sum(target.*kernel))/len;
Es bastante adecuado para MATLAB, pero nos priva por completo de la posibilidad de optimizar HDL.
La siguiente salida es editar el código a mano. Este es un punto muy importante, ya que nos negamos a heredar y comenzamos a reescribir el script m, y NO en el estilo MATLAB.
El nuevo código es el siguiente
function [out] = mhls_conv2_manually(target,kernel) len = length(kernel); mult = target.*kernel; summ_1 = zeros([1,(len/2)]); summ_2 = zeros([1,(len/4)]); summ_3 = zeros([1,(len/8)]); for i=0:1:(len/2)-1 summ_1(i+1) = (mult(i*2+1)+mult(i*2+2)); end for i=0:1:(len/4)-1 summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2)); end for i=0:1:(len/8)-1 summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2)); end out = summ_3/len; end
En Quartus, recopilamos el código generado por el HDL Coder. Se puede ver que el número de capas con primitivas ha disminuido, y el esquema se ve mucho mejor.
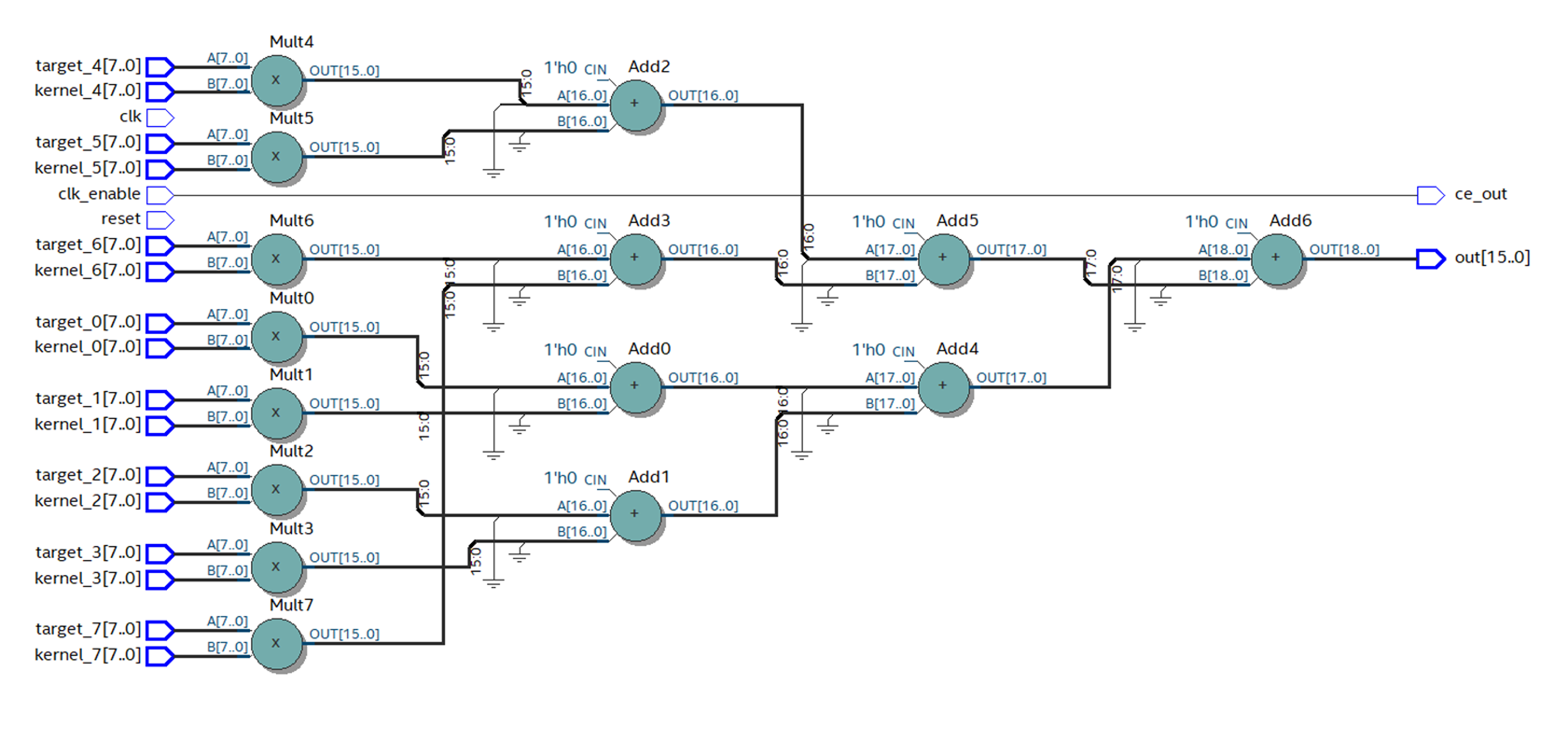 Figura 12
Figura 12Con el diseño correcto de primitivas, la frecuencia crece casi 3 veces, hasta 88 MHz.
 Figura 13
Figura 13Ahora el toque final: en la configuración de Optimización, especifique summ_1, summ_2 y summ_3 como elementos de la tubería. Recopilamos el código resultante en Quartus. El esquema cambia de la siguiente manera:
 Figura 14
Figura 14La frecuencia máxima aumenta nuevamente y ahora su valor es de aproximadamente 195 MHz.
 Figura 15
Figura 15¿Cuántos recursos en el chip tomarán tal diseño? La Figura 16 muestra la tabla de recursos utilizados para el caso descrito.
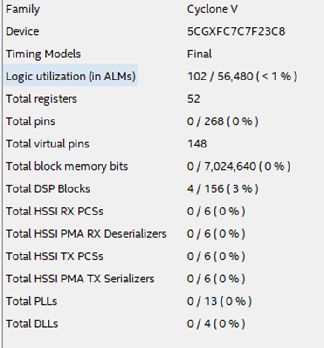 Figura 16
Figura 16¿Qué conclusiones se pueden sacar después de considerar este ejemplo?
La principal desventaja del codificador HDL es que es poco probable que use el código MATLAB en su forma pura.
No hay soporte para matrices como entradas de función, el diseño del código en el estilo MATLAB es mediocre.
El principal peligro es la falta de registros en el código generado sin configuraciones adicionales. Sin estos registros, incluso habiendo recibido código HDL que funciona formalmente sin errores de sintaxis, el uso de dicho código en las realidades y desarrollos modernos es indeseable.
Es aconsejable escribir inmediatamente el código para la conversión a HDL. En este caso, puede obtener resultados bastante aceptables en términos de velocidad e intensidad de recursos.
Si es un desarrollador de MATLAB, no se apresure a hacer clic en el botón Ejecutar y compilar su código bajo FPGA, recuerde que su código se sintetizará en un circuito real. =)
Compilador Intel HLS
Para la misma funcionalidad, escribí el siguiente código C / C ++
component unsigned int conv(unsigned char *data, unsigned char *kernel) { unsigned int mult_res[16]; unsigned int summl; summl = 0; for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; summl = summl+mult_res[i]; } return summl/16; }
Lo primero que llama la atención es la cantidad de recursos utilizados.
 Figura 17
Figura 17Se puede ver en la tabla que solo se usó 1 bloque DSP, por lo que algo salió mal y las multiplicaciones no se realizan en paralelo. El número de registros utilizados también es sorprendente, e incluso la memoria está involucrada, pero dejaremos esto a la conciencia del compilador HLS.
Vale la pena señalar que el compilador HLS ha desarrollado un subóptimo, utilizando una gran cantidad de recursos adicionales, pero sigue siendo un circuito de trabajo que, según los informes de Quartus, funcionará a una frecuencia aceptable, y un fallo como el codificador HDL no lo hará.
 Figura 18
Figura 18Intentemos mejorar la situación. ¿Qué se necesita para esto? Así es, cierra los ojos a la herencia y métete en el código, pero hasta ahora no es mucho.
HLS tiene directivas especiales para optimizar el código para FPGA. Insertamos la directiva de desenrollado, que debería expandir nuestro bucle en paralelo:
#pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; }
Veamos cómo reaccionó Quartus.
 Figura 19
Figura 19En primer lugar, preste atención a la cantidad de bloques DSP: hay 16 de ellos, lo que significa que las multiplicaciones se realizan en paralelo.
¡Hurra! desenrollar funciona! Pero ya es difícil soportar cuánto ha crecido la utilización de otros recursos. El circuito se ha vuelto completamente ilegible.
 Figura 20
Figura 20Creo que esto se debió al hecho de que nadie le señaló al compilador que los cálculos en números de punto fijo son muy adecuados para nosotros, e honestamente implementó todas las matemáticas de punto flotante en lógica y registros. Necesitamos explicarle al compilador qué se requiere de él, y para esto volvemos a sumergirnos en el código.
Con el fin de usar punto fijo, se implementan clases de plantilla.
 Figura 21
Figura 21Hablando en nuestras propias palabras, podemos usar variables cuya profundidad de bits se establece manualmente hasta un bit. Para aquellos que escriben en HDL, no pueden acostumbrarse, pero los programadores de C / C ++ probablemente se aferrarán a sus ideas. Profundidades de bits, como en MATLAB, en este caso, nadie lo dirá, y el desarrollador mismo debe contar la cantidad de bits.
Veamos cómo se ve en la práctica.
Editamos el código de la siguiente manera:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel) { ac_fixed<16,16,false>mult_res[16]; ac_fixed<32,32,false>summl; #pragma unroll for (int i = 0; i < 16; i++) { mult_res[i] = data[i] * kernel[i]; } for (int i = 0; i < 16; i++) { summl = summl+mult_res[i]; } return summl/16; }
Y en lugar de la espeluznante pasta de la Figura 20, obtenemos esta belleza:
 Figura 22
Figura 22Desafortunadamente, algo extraño continúa sucediendo con los recursos utilizados.
 Figura 23
Figura 23Pero una revisión detallada de los informes muestra que el módulo que nos interesa directamente parece más que adecuado:
 Figura 24
Figura 24El gran consumo de registros y memoria de bloque está asociado con una gran cantidad de módulos periféricos. Todavía no entiendo completamente el significado profundo de su existencia, y esto tendrá que resolverse, pero el problema está resuelto. En un caso extremo, puede cortar cuidadosamente un módulo que nos interese de la estructura general del proyecto, lo que nos salvará de los módulos periféricos que devoran recursos.
La tercera prueba. "Transición de RGB a HSV"
Comenzando a escribir este artículo, no esperaba que fuera tan voluminoso. Pero no puedo rechazar el tercero y el último en el marco de este artículo, un ejemplo.
En primer lugar, este es un ejemplo real de mi práctica, y fue por eso que comencé a buscar herramientas de desarrollo de alto nivel.
En segundo lugar, a partir de los dos primeros ejemplos, podríamos suponer que cuanto más complejo es el diseño, peor son las herramientas de alto nivel para hacer frente a la tarea.
Quiero demostrar que este juicio es erróneo y, de hecho, cuanto más compleja es la tarea, más se manifiestan las ventajas de las herramientas de desarrollo de alto nivel.
El año pasado, cuando trabajaba en uno de los proyectos, no me gustó la cámara comprada en Aliexpress, es decir, los colores no estaban lo suficientemente saturados. Una de las formas populares de variar la saturación de color es cambiar del espacio de color RGB al espacio HSV, donde uno de los parámetros es la saturación. Recuerdo cómo abrí la fórmula de transición y respiré profundamente ... Implementar tales cálculos en FPGA no es algo extraordinario, pero por supuesto tomará tiempo escribir el código. Entonces, la fórmula para cambiar de RGB a HSV es la siguiente:
 Figura 25
Figura 25La implementación de tal algoritmo en FPGA no llevará días, sino horas, y todo esto debe hacerse con mucho cuidado debido a los detalles de HDL, y la implementación en C ++ o en MATLAB tomará, creo, minutos.
En C ++, puede escribir código directamente en la frente y aún así obtener un resultado funcional.
Escribí la siguiente opción en C ++
struct color_space{ unsigned char rh; unsigned char gs; unsigned char bv; }; component color_space rgb2hsv(color_space rgb_0) { color_space hsv; float h,s,v,r,g,b; float max_col, min_col; r = static_cast<float>(rgb_0.rh)/255; g = static_cast<float>(rgb_0.gs)/255; b = static_cast<float>(rgb_0.bv)/255; max_col = std::max(std::max(r,g),b); min_col = std::min(std::min(r,g),b);
Y Quartus implementó con éxito el resultado, como se puede ver en la tabla de recursos utilizados.
 Dibujo 26
Dibujo 26La frecuencia es muy buena.
 Dibujo 27
Dibujo 27Con el codificador HDL, las cosas son un poco más complicadas.
Para no inflar el artículo, no proporcionaré un script m para esta tarea, no debería causar dificultades. Un script m escrito en la frente difícilmente se puede usar con éxito, pero si edita el código y especifica correctamente los lugares para la canalización, obtenemos un resultado funcional. Esto, por supuesto, tomará varias decenas de minutos, pero no horas.
En C ++, también es deseable establecer las directivas y traducir los cálculos a un punto fijo, lo que también tomará muy poco tiempo.Por lo tanto, al usar herramientas de desarrollo de alto nivel, ahorramos tiempo, y cuanto más complicado sea el algoritmo, más tiempo ahorrará; esto continuará hasta que nos encontremos con límites de recursos FPGA o límites de velocidad computacionales estrictos en los que debe abordar HDL.Conclusión
Lo que se puede decir en conclusión.Obviamente, el martillo dorado aún no se ha inventado, pero existen herramientas adicionales que se pueden utilizar en el desarrollo.La principal ventaja de las herramientas de alto nivel, en mi opinión, es la velocidad de desarrollo. Es una realidad obtener suficiente calidad en términos de tiempo, a veces un orden de magnitud menor que cuando se desarrolla utilizando HDL.Ante tales ventajas como usar código heredado para FPGA y conectar programadores al desarrollo de FPGA sin preparación preliminar, soy cauteloso. Para obtener resultados satisfactorios, deberá abandonar muchas técnicas de programación familiares.Una vez más, quiero señalar que este artículo es solo una mirada superficial a las herramientas de desarrollo de alto nivel para FPGA.El compilador HLS tiene grandes oportunidades para optimizaciones: pragmas, bibliotecas especiales con funciones optimizadas, descripciones de interfaz, muchos artículos en Internet sobre "mejores prácticas", etc. El chip MATLAB, que no se ha considerado, es la capacidad de generar directamente, por ejemplo, un filtro desde la GUI sin escribir una sola línea de código, simplemente indicando las características deseadas, lo que acelera aún más el tiempo de desarrollo.¿Quién ganó el estudio de hoy? Mi opinión es el compilador Intel HLS. Genera un diseño funcional incluso a partir de código no optimizado. Codificador de HDL sin análisis cuidadoso y procesamiento de código que me daría miedo usar. También quiero señalar que el codificador HDL es una herramienta bastante antigua, pero como sé, no ha ganado un amplio reconocimiento. Pero HLS, aunque joven, está claro que los fabricantes de FPGA están apostando por él, creo que veremos su mayor desarrollo y crecimiento en popularidad.Los representantes de Xilinx aseguran que el desarrollo e implementación de herramientas de alto nivel es la única oportunidad en el futuro para desarrollar chips FPGA cada vez más grandes. Las herramientas tradicionales simplemente no podrán hacer frente a esto, y Verilog / VHDL probablemente esté destinado al ensamblador, pero esto es en el futuro. Y ahora tenemos en nuestras manos herramientas de desarrollo (con sus pros y sus contras), que debemos elegir en función de la tarea.¿Usaré herramientas de desarrollo de alto nivel en mi trabajo? Más bien, sí, ahora su desarrollo avanza a pasos agigantados, por lo que al menos debemos seguir el ritmo, pero no veo razones objetivas para abandonar inmediatamente el HDL.Al final, quiero señalar una vez más que en esta etapa del desarrollo de herramientas de diseño de alto nivel, el usuario no debe olvidar por un minuto que escribe un programa que no es ejecutable en el procesador, sino que crea un circuito con cables reales, disparadores y elementos lógicos.