Recientemente, se ha publicado
un artículo que muestra una buena tendencia en el aprendizaje automático en los últimos años. En resumen: el número de nuevas empresas en el campo del aprendizaje automático ha disminuido considerablemente en los últimos dos años.
Pues que. Analicemos "si estalló la burbuja", "cómo vivir" y hablemos de dónde vino ese garabato.
Primero, hablemos sobre cuál fue el refuerzo de esta curva. ¿De dónde vino ella? Probablemente todos recordarán la
victoria del aprendizaje automático en 2012 en el concurso ImageNet. Después de todo, ¡este es el primer evento mundial! Pero en realidad esto no es así. Y el crecimiento de la curva comienza un poco antes. Lo dividiría en varios puntos.
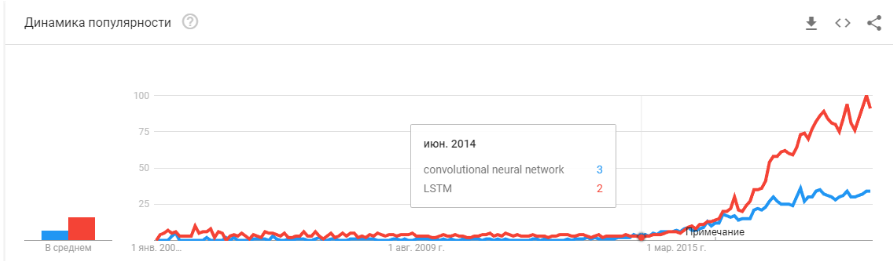
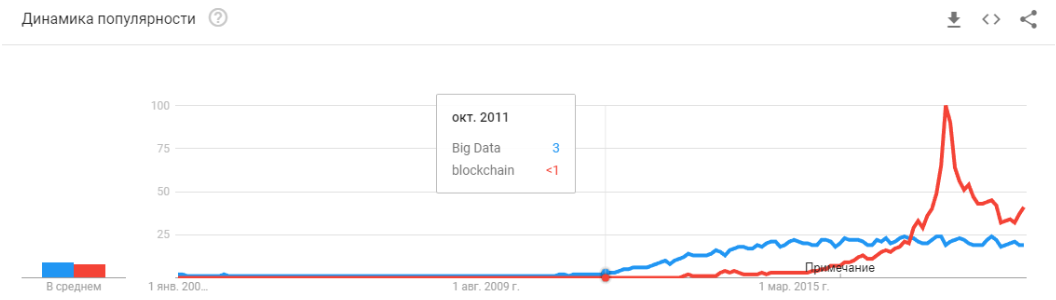
- 2008 es la aparición del término "big data". Los productos reales comenzaron a aparecer en 2010. Big data está directamente relacionado con el aprendizaje automático. Sin big data, el funcionamiento estable de los algoritmos que existían en ese momento es imposible. Y estas no son redes neuronales. Hasta 2012, las redes neuronales son la minoría marginal. Pero entonces comenzaron a funcionar algoritmos completamente diferentes, que habían existido durante años, o incluso décadas: SVM (1963, 1993), Random Forest (1995), AdaBoost (2003), ... Las nuevas empresas de esos años se asocian principalmente con el procesamiento automático de datos estructurados. : taquillas, usuarios, publicidad, mucho más.
La derivada de esta primera ola es un conjunto de marcos como XGBoost, CatBoost, LightGBM, etc.
- En 2011-2012, las redes neuronales convolucionales ganaron una serie de concursos de reconocimiento de imágenes. Su uso real fue algo retrasado. Diría que las nuevas empresas y soluciones masivamente significativas comenzaron a aparecer en 2014. Se necesitaron dos años para digerir que las neuronas aún funcionan, para crear marcos convenientes que se puedan instalar y ejecutar en un período de tiempo razonable, para desarrollar métodos que estabilicen y aceleren el tiempo de convergencia.
Las redes convolucionales permitieron resolver problemas de visión artificial: clasificación de imágenes y objetos en una imagen, detección de objetos, reconocimiento de objetos y personas, mejora de imágenes, etc., etc. - 2015-2017 años. El auge de los algoritmos y proyectos vinculados a las redes de recurrencia o sus análogos (LSTM, GRU, TransformerNet, etc.). Han aparecido algoritmos de voz a texto y sistemas de traducción automática que funcionan bien. En parte, se basan en redes convolucionales para resaltar características básicas. Parcialmente por el hecho de que aprendieron a recopilar conjuntos de datos realmente grandes y buenos.
"¿Ha estallado la burbuja?" ¿Hype se está sobrecalentando? ¿Murieron como una cadena de bloques?
Pues bien! Mañana Siri dejará de funcionar en su teléfono, y pasado mañana Tesla no distinguirá un giro de un canguro.
Las redes neuronales ya están funcionando. Están en docenas de dispositivos. Realmente te permiten ganar, cambiar el mercado y el mundo que te rodea. Hype se ve un poco diferente:
Es solo que las redes neuronales han dejado de ser algo nuevo. Sí, muchas personas tienen altas expectativas. Pero una gran cantidad de compañías han aprendido a usar sus neuronas y a fabricar productos basados en ellas. Las neuronas dan una nueva funcionalidad, pueden reducir trabajos, reducir el precio de los servicios:
- Las empresas manufactureras integran algoritmos para el análisis de rechazos en el transportador.
- Las granjas ganaderas están comprando sistemas para controlar las vacas.
- Cosechadoras automáticas.
- Centros de llamadas automatizados.
- Filtros en Snapchat. (
bueno, al menos algo sensato! )
Pero lo principal, y no lo más obvio: "No hay más ideas nuevas, o no traerán capital instantáneo". Las redes neuronales han resuelto docenas de problemas. Y ellos decidirán aún más. Todas las ideas obvias que fueron - generaron muchas nuevas empresas. Pero todo lo que estaba en la superficie ya ha sido recolectado. En los últimos dos años, no he encontrado una sola idea nueva para el uso de redes neuronales. No hay un solo enfoque nuevo (bueno, está bien, hay algunos problemas con las GAN).
Y cada próxima puesta en marcha es cada vez más complicada. Ya no se requieren dos tipos que entrenen a una neurona en datos abiertos. Requiere programadores, un servidor, un equipo de redactores, soporte complejo, etc.
Como resultado, hay menos startups. Pero la producción es más. ¿Necesita adjuntar el reconocimiento de matrícula? Hay cientos de profesionales con experiencia relevante en el mercado. Puede contratar y en un par de meses su empleado creará un sistema. O compre uno terminado. Pero haciendo una nueva startup? .. Locura!
Necesitamos crear un sistema para rastrear a los visitantes: ¿por qué pagar por un montón de licencias? Si puede hacer las suyas durante 3-4 meses, agudícelas para su negocio.
Ahora las redes neuronales siguen el mismo camino que docenas de otras tecnologías.
¿Recuerdas cómo ha cambiado el concepto de "desarrollador de sitios" desde 1995? Si bien el mercado no está saturado de especialistas. Hay muy pocos profesionales. Pero puedo apostar que en 5-10 años no habrá mucha diferencia entre un programador de Java y un desarrollador de redes neuronales. Y esos y esos especialistas serán suficientes en el mercado.
Simplemente habrá una clase de tareas para las que las neuronas resuelven. Había una tarea: contratar a un especialista.
“¿Y luego qué? ¿Dónde está la inteligencia artificial prometida?Y aquí hay un pequeño pero interesante neponyatchka :)
La pila de tecnología que existe hoy, aparentemente, todavía no nos llevará a la inteligencia artificial. Las ideas, su novedad, se han agotado en gran medida. Hablemos de lo que mantiene el nivel actual de desarrollo.
Limitaciones
Comencemos con los drones automáticos. Parece entenderse que es posible fabricar automóviles totalmente autónomos con las tecnologías actuales. Pero después de cuántos años esto sucederá no está claro. Tesla cree que esto sucederá en un par de años.
Hay muchos otros
especialistas que califican esto como 5-10 años.
Lo más probable, en mi opinión, después de 15 años, la infraestructura de las ciudades en sí misma cambiará para que la aparición de automóviles autónomos sea inevitable, será su continuación. Pero esto no puede considerarse inteligencia. Modern Tesla es una tubería muy compleja para filtrar datos, buscarlos y volver a capacitarlos. Estas son reglas, reglas, reglas, recopilación de datos y filtros sobre ellos (
aquí escribí un poco más al respecto, o mire desde
este punto).
Primer problema
Y es aquí donde vemos el
primer problema fundamental . Big data Esto es exactamente lo que generó la ola actual de redes neuronales y aprendizaje automático. Ahora, para hacer algo complejo y automático, necesita muchos datos. No solo mucho, sino mucho, mucho. Necesitamos algoritmos automatizados para su recopilación, marcado, uso. Queremos hacer que el automóvil vea camiones contra el sol; primero debemos recoger un número suficiente de ellos. Queremos que el auto no se vuelva loco con una bicicleta atornillada a la cajuela - más muestras.
Además, un ejemplo no es suficiente. Cientos? Miles?

Segundo problema
El segundo problema es la visualización de lo que ha entendido nuestra red neuronal. Esta es una tarea muy no trivial. Hasta ahora, pocas personas entienden cómo visualizar esto. Estos artículos son muy recientes, estos son solo algunos ejemplos, incluso remotos:
Visualización de fijación en texturas. Muestra bien lo que la neurona tiende a ir en ciclos + lo que ella percibe como información inicial.
 Visualización de
Visualización de atenuación durante las
traducciones . Realmente, la atenuación a menudo se puede usar con precisión para mostrar qué causó tal reacción de red. Conocí tales cosas para depurar y para soluciones de productos. Hay muchos artículos sobre este tema. Pero cuanto más complejos son los datos, más difícil es comprender cómo lograr una visualización sostenible.

Bueno, sí, el viejo conjunto de "mira lo que hay dentro de la rejilla en los
filtros ". Estas imágenes eran populares hace unos 3-4 años, pero todos se dieron cuenta rápidamente de que las imágenes son hermosas, pero no tienen mucho sentido.

No mencioné docenas de otras lociones, métodos, hacks, estudios sobre cómo mostrar el interior de la red. ¿Estas herramientas funcionan? ¿Te ayudan a entender rápidamente cuál es el problema y a depurar la red? ... ¿Sacar el último porcentaje? Bueno, algo como esto:

Puedes ver cualquier concurso en Kaggle. Y una descripción de cómo las personas toman las decisiones finales. ¡Llegamos al modelo 100-500-800 mulenov y funcionó!
Por supuesto, exagero. Pero estos enfoques no dan respuestas rápidas y directas.
Teniendo suficiente experiencia, después de haber elegido diferentes opciones, puede emitir un veredicto sobre por qué su sistema tomó tal decisión. Pero corregir el comportamiento del sistema será difícil. Coloque una muleta, mueva el umbral, agregue un conjunto de datos, tome otra red de fondo.
Tercer problema
El tercer problema fundamental es que las cuadrículas no enseñan lógica, sino estadística. Estadísticamente esta
persona :

Lógicamente, no muy similar. Las redes neuronales no aprenden algo complicado si no son forzadas. Siempre aprenden los síntomas más simples. Tiene ojos, nariz, cabeza? Entonces esta cara! O dé un ejemplo donde los ojos no signifiquen la cara. Y de nuevo, millones de ejemplos.
Hay mucho espacio en la parte inferior
Diría que son estos tres problemas globales los que hoy limitan el desarrollo de las redes neuronales y el aprendizaje automático. Y donde estos problemas no se limitaron ya se usa activamente.
¿Es este el final? Las redes neuronales se levantaron?Desconocido Pero, por supuesto, todos esperan que no.
Hay muchos enfoques y direcciones para resolver los problemas fundamentales que he cubierto anteriormente. Pero hasta ahora, ninguno de estos enfoques nos ha permitido hacer algo fundamentalmente nuevo, resolver algo que aún no se ha resuelto. Hasta ahora, todos los proyectos fundamentales se realizan sobre la base de enfoques estables (Tesla), o siguen siendo proyectos de prueba de institutos o corporaciones (Google Brain, OpenAI).
En términos generales, la dirección principal es la creación de una representación de alto nivel de los datos de entrada. En cierto sentido, "memoria". El ejemplo más simple de memoria son las diversas representaciones de "incrustación" de imágenes. Bueno, por ejemplo, todos los sistemas de reconocimiento facial. La red aprende a obtener de la cara una cierta idea estable que no depende de la rotación, la iluminación y la resolución. De hecho, la red minimiza la métrica de "caras diferentes - lejos" e "idéntico - cerca".

Tal entrenamiento requiere decenas y cientos de miles de ejemplos. Pero el resultado trae algunos rudimentos de "Aprendizaje único". Ahora no necesitamos cientos de caras para recordar a una persona. Solo una cara, y eso es todo, ¡lo
descubriremos !
Solo aquí está el problema ... La cuadrícula solo puede aprender objetos bastante simples. Cuando se trata de distinguir no caras, sino, por ejemplo, "personas vestidas" (la
tarea de redentificación ), la calidad falla en muchos órdenes de magnitud. Y la red ya no puede aprender suficientes cambios de ángulo obvios.
Y aprender de millones de ejemplos también es de alguna manera un entretenimiento regular.
Hay trabajo para reducir significativamente las elecciones. Por ejemplo, puede recuperar de inmediato uno de los primeros
trabajos de Google OneShot Learning :
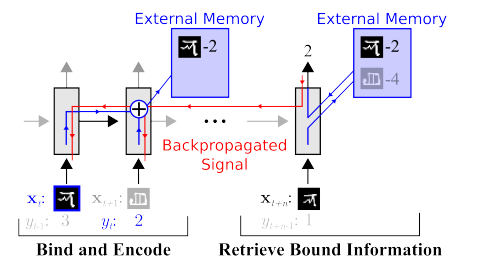
Hay muchos de estos trabajos, por ejemplo
1 o
2 o
3 .
Hay una desventaja: por lo general, el entrenamiento funciona bien en algunos "ejemplos MNIST'ovskie" simples. Y en la transición a tareas complejas, necesita una base grande, un modelo de objetos o algún tipo de magia.
En general, el trabajo en el entrenamiento One-Shot es un tema muy interesante. Encuentras muchas ideas. Pero en su mayor parte, los dos problemas que he enumerado (capacitación previa en un gran conjunto de datos / inestabilidad en datos complejos) están obstaculizando el aprendizaje.
Por otro lado, GAN - redes generativamente competitivas - se acerca a la integración. Probablemente leyó un montón de artículos sobre este tema en Habré. (
1 ,
2 ,
3 )
Una característica de la GAN es la formación de un espacio de estado interno (esencialmente la misma incrustación), que le permite dibujar una imagen. Pueden ser
personas , puede haber
acciones .
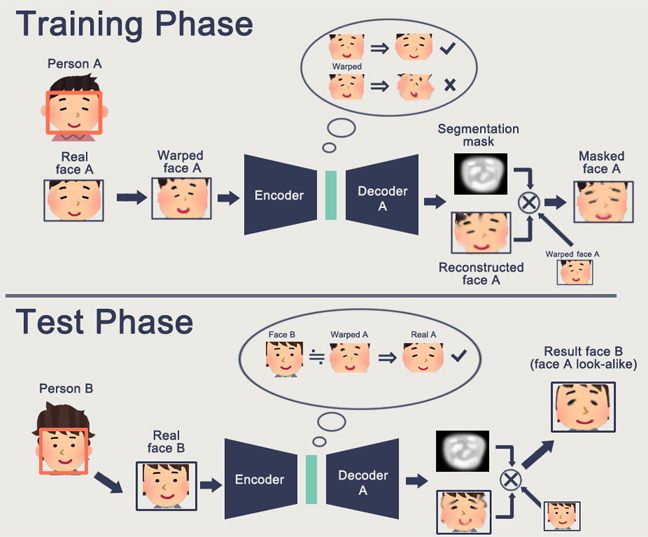
El problema de GAN es que cuanto más complejo es el objeto generado, más difícil es describirlo en la lógica del "generador-discriminador". Como resultado, a partir de aplicaciones reales de GAN, que solo se escuchan DeepFake, que, nuevamente, manipula las representaciones de los individuos (para lo cual existe una base enorme).
He encontrado muy pocas otras aplicaciones útiles. Por lo general, una especie de silbato falso con dibujos.
Y de nuevo. Nadie comprende cómo esto nos permitirá avanzar hacia un futuro más brillante. Representar la lógica / espacio en una red neuronal es bueno. Pero necesitamos una gran cantidad de ejemplos, no entendemos cómo esta neurona se representa a sí misma, no entendemos cómo hacer que la neurona recuerde alguna idea realmente complicada.
El aprendizaje por refuerzo es un enfoque completamente diferente. Seguramente recuerdas cómo Google venció a todos en Go. Victorias recientes en Starcraft y Dota. Pero aquí todo está lejos de ser tan optimista y prometedor. Lo mejor de RL y su complejidad es
este artículo .
Para resumir brevemente lo que escribió el autor:
- Los modelos listos para usar no se ajustan / funcionan mal en la mayoría de los casos
- Las tareas prácticas son más fáciles de resolver de otras maneras. Boston Dynamics no usa RL debido a su complejidad / imprevisibilidad / complejidad computacional
- Para que RL funcione, necesita una función compleja. A menudo es difícil crear / escribir.
- Es difícil entrenar modelos. Tenemos que pasar mucho tiempo para balancearnos y salir de optima local
- Como resultado, es difícil repetir el modelo, la inestabilidad del modelo al más mínimo cambio.
- A menudo se sobrellena en algunos patrones izquierdos, hasta el generador de números aleatorios
El punto clave es que RL aún no funciona en producción. Google tiene algún tipo de experimentos (
1 ,
2 ). Pero no he visto un solo sistema de abarrotes.
Memoria La desventaja de todo lo que se describe arriba no está estructurada. Un enfoque para tratar de ordenar todo esto es proporcionar a la red neuronal acceso a una memoria separada. Para que pueda grabar y reescribir los resultados de sus pasos allí. Entonces la red neuronal se puede determinar por el estado actual de la memoria. Esto es muy similar a los procesadores y computadoras clásicos.
El artículo más famoso y popular es de DeepMind:
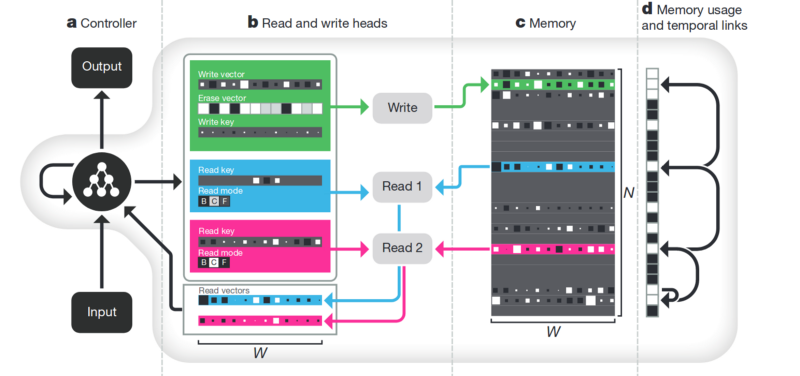
Parece que aquí está, ¿la clave para entender la inteligencia? Pero más bien, no. El sistema todavía necesita una gran cantidad de datos para la capacitación. Y funciona principalmente con datos tabulares estructurados. Al mismo tiempo, cuando Facebook
resolvió un problema similar, siguieron el camino "ven la memoria, solo hacen que la neurona sea más complicada, pero más ejemplos, y se aprenderá por sí misma".
Desenredamiento . Otra forma de crear una memoria significativa es tomar las mismas incrustaciones, pero al aprender a introducir criterios adicionales que les permitan resaltar "significados" en ellos. Por ejemplo, queremos entrenar una red neuronal para distinguir entre el comportamiento de una persona en una tienda. Si siguiéramos el camino estándar, tendríamos que hacer una docena de redes. Uno está buscando a una persona, el segundo determina lo que está haciendo, el tercero es su edad, el cuarto es el género. La lógica separada mira la parte de la tienda donde la hace / aprende. El tercero determina su trayectoria, etc.
O, si hubiera una cantidad infinita de datos, entonces sería posible entrenar una red para todo tipo de resultados (es obvio que tal conjunto de datos no se puede escribir).
El enfoque de desinserción nos dice, y capacitemos a la red para que pueda distinguir entre conceptos. Para que ella pueda integrarse en el video, donde un área determinaría la acción, una, la posición en el piso a tiempo, una, la altura de la persona y otra, su género. Al mismo tiempo, durante el entrenamiento, me gustaría sugerir casi nunca tales conceptos clave a la red, sino para que identifique y agrupe las áreas. Hay pocos artículos de este tipo (algunos de ellos son
1 ,
2 ,
3 ) y en general son bastante teóricos.
Pero esta dirección, al menos teóricamente, debería cubrir los problemas enumerados al principio.
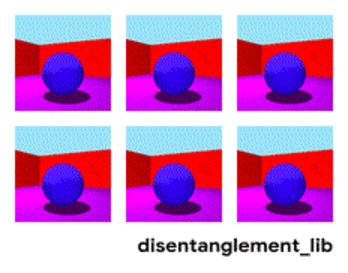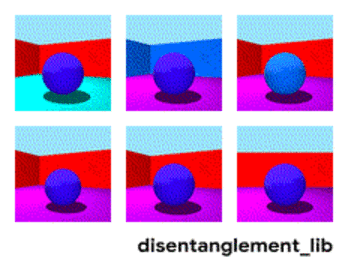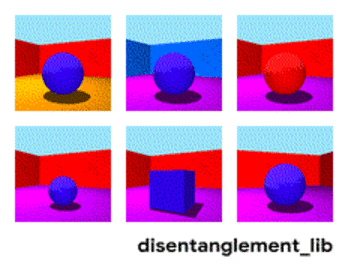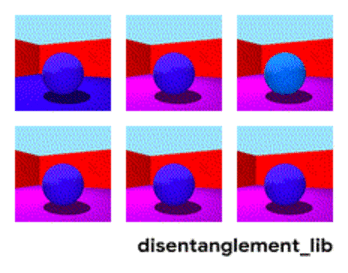
Descomposición de la imagen según los parámetros "color de pared / color de piso / forma de objeto / color de objeto / etc."

Descomposición de la cara según los parámetros "tamaño, cejas, orientación, color de piel, etc."
Otros
Hay muchas otras direcciones no tan globales que nos permiten reducir de alguna manera la base, trabajar con datos más heterogéneos, etc.
Atencion Probablemente no tenga sentido aislar esto como un método separado. Solo un enfoque que refuerza a los demás. Se le han dedicado muchos artículos (
1 ,
2 ,
3 ). El significado de Atención es fortalecer la respuesta de la red a objetos importantes durante el entrenamiento. A menudo por alguna designación de destino externo, o una pequeña red externa.
Simulación 3D Si haces un buen motor 3D, a menudo puedes cerrar el 90% de los datos de entrenamiento con él (incluso vi un ejemplo en el que casi el 99% de los datos se cerró con un buen motor). Hay muchas ideas y trucos sobre cómo hacer que una red entrenada en un motor 3D funcione con datos reales (ajuste fino, transferencia de estilo, etc.). Pero a menudo, hacer un buen motor es varios órdenes de magnitud más difícil que recopilar datos. Ejemplos al hacer motores:
Entrenamiento de robots (
google ,
braingarden )
Aprendiendo a
reconocer los productos en una tienda (pero en dos proyectos que hicimos, lo dispensamos con calma).
Entrenamiento en Tesla (nuevamente, el video que estaba arriba).
Conclusiones
Todo el artículo es, en cierto sentido, conclusiones. Probablemente el mensaje principal que quería hacer era "se acabó el obsequio, las neuronas no dan soluciones más simples". Ahora tenemos que trabajar duro para construir soluciones complejas. O trabajar duro haciendo informes científicos complejos.
En general, el tema es discutible. ¿Quizás los lectores tienen ejemplos más interesantes?