En lugar de unirse
Anteriormente en nuestro blog escribimos
lo que IPONWEB está
haciendo : automatizamos la visualización de anuncios en Internet. Nuestros sistemas toman decisiones no solo sobre la base de datos históricos, sino que también utilizan activamente la información obtenida en tiempo real. En el caso de DSP (Demand Side Platform - una plataforma publicitaria para anunciantes), el anunciante (o su representante) debe crear y cargar un banner publicitario (creativo) en uno de los formatos (imagen, video, banner interactivo, imagen + texto, etc.) , seleccione la audiencia de usuarios a los que se mostrará este banner, determine cuántas veces es posible mostrar publicidad a un usuario, en qué países, en qué sitios, en qué dispositivos, y reflejar esto (y mucho más) en la configuración de orientación de la campaña publicitaria, así como distribuir publicidad el presupuesto s. Para SSP (Supply Side Platform - una plataforma publicitaria para propietarios de plataformas publicitarias), el propietario del sitio (aplicación móvil, cartelera, canal de televisión) debe determinar los anuncios publicitarios en su sitio e indicar, por ejemplo, qué categorías de publicidad está listo para mostrar en ellos. Todos estos ajustes se realizan de forma manual por adelantado (no al momento de mostrar anuncios) utilizando la interfaz de usuario. En este artículo hablaré sobre nuestro enfoque para construir tales interfaces, siempre que haya muchas, son similares entre sí y al mismo tiempo tienen características individuales.
Como empezó todo
Comenzamos el negocio de publicidad en 2007, pero no hicimos interfaces de inmediato, sino solo en 2014. Tradicionalmente, nos dedicamos al desarrollo de plataformas personalizadas que están completamente diseñadas de acuerdo con los detalles específicos del negocio de cada cliente individual: entre las docenas de plataformas que construimos, no hay dos idénticas. Y dado que nuestras plataformas publicitarias se diseñaron sin restricciones en cuanto a las posibilidades de personalización, la interfaz de usuario tenía que cumplir los mismos requisitos.
Cuando recibimos la primera solicitud de una interfaz publicitaria para DSP hace cinco años, nuestra elección recayó en la pila de tecnología popular y conveniente: JavaScript y AngularJS en el front-end, y el back-end en Python, Django y Django Rest Framework (DRF). A partir de esto, se realizó el proyecto más común, cuya tarea principal era proporcionar la funcionalidad CRUD. El resultado de su trabajo fue un archivo de configuración para el sistema de publicidad en formato XML. Ahora, tal protocolo de interacción puede parecer extraño, pero, como ya comentamos, comenzamos a construir los primeros sistemas de publicidad (incluso sin la interfaz de usuario) en el "cero", y este formato se ha conservado hasta nuestros días.
Después del exitoso lanzamiento del primer proyecto, el siguiente no tardó mucho. También eran la interfaz de usuario para el DSP y los requisitos para ellos eran los mismos que para el primer proyecto. Casi. A pesar de que todo era muy similar, el diablo se escondía en los detalles: hay una jerarquía de objetos ligeramente diferente, se agregan un par de campos allí ... La forma más obvia de obtener el segundo proyecto, muy similar al primero, pero con mejoras, fue el método de replicación, que utilizamos . Y conllevaba problemas familiares para muchos: junto con el código "bueno", también se copiaban errores, parches para los cuales había que distribuirlos a mano. Lo mismo sucedió con todas las nuevas características que se implementaron en todos los proyectos activos.
En este modo, era posible trabajar mientras había pocos proyectos, pero cuando su número excedía de 20, el enfoque familiar dejó de escalar. Por lo tanto, decidimos transferir las partes comunes de los proyectos a la biblioteca, desde la cual el proyecto conectará los componentes que necesita. Si se detecta un error, se repara una vez en la biblioteca y se distribuye automáticamente a los proyectos cuando se actualiza la versión de la biblioteca, y lo mismo sucede con la reutilización de nuevas funciones.
Configuracion y terminologia
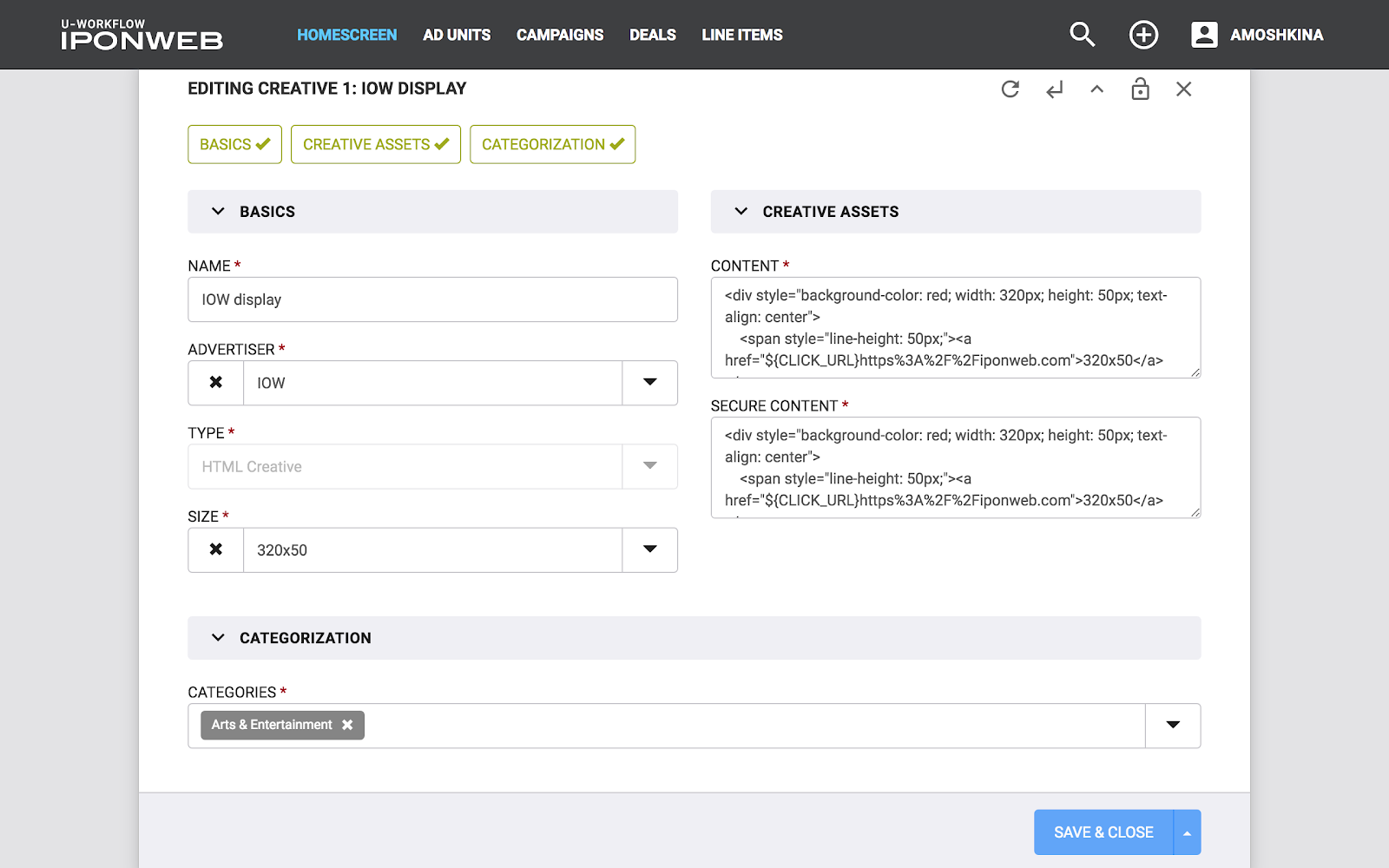
Tuvimos varias iteraciones en la implementación de este enfoque, y todos fluyeron entre sí evolutivamente, comenzando con nuestro proyecto habitual en DRF puro. En la última implementación, nuestro proyecto se describe utilizando DSL basado en JSON (ver imagen). Este JSON describe tanto la estructura de los componentes del proyecto como sus interconexiones, y tanto el frontend como el backend pueden leerlo.
Después de inicializar la aplicación Angular, el frontend solicita una configuración JSON del backend. El back-end no solo regala un archivo de configuración estático, sino que además lo procesa, completándolo con varios metadatos o eliminando partes de la configuración que son responsables de partes del sistema inaccesibles para el usuario. Esto le permite mostrar a los diferentes usuarios la interfaz de diferentes maneras, incluidos formularios interactivos, estilos CSS de toda la aplicación y elementos de diseño específicos. Esto último es especialmente cierto para las interfaces de usuario de plataformas que utilizan diferentes tipos de clientes con diferentes roles y niveles de acceso.

El backend, a diferencia del frontend, lee la configuración una vez en la etapa de inicialización de la aplicación Django. Por lo tanto, la cantidad total de funcionalidad se registra en el back-end, y el acceso a varias partes del sistema se verifica sobre la marcha.
Antes de pasar a la parte más interesante, la estructura de la base de datos, quiero presentar varios conceptos que usamos cuando hablamos de la estructura de nuestros proyectos para estar en la misma onda con el lector.
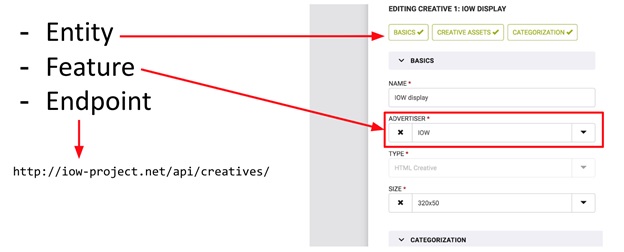
Estos conceptos, Entidad y Característica, están bien ilustrados en el formulario de ingreso de datos (ver imagen). Todo el formulario es Entidad, y los campos individuales en él son Característica. La imagen también muestra Endpoint (por si acaso). Por lo tanto, Entity es un objeto independiente en el sistema en el que se pueden realizar operaciones CRUD, mientras que Feature es solo parte de "algo más", parte de Entity. Con Feature, no puede realizar operaciones CRUD sin estar vinculado a ninguna entidad. Por ejemplo: el presupuesto de una campaña publicitaria sin referencia a la campaña en sí es simplemente un número que no se puede utilizar sin información sobre la campaña principal.
Los mismos conceptos se pueden encontrar en la configuración JSON del proyecto (ver la imagen).

Estructura de la base de datos
La parte más interesante de nuestros proyectos es la estructura de la base de datos y la mecánica que la respalda. Después de haber comenzado a utilizar PostgreSQL para las primeras versiones de nuestros proyectos, hoy seguimos con esta tecnología. Junto con esto, estamos utilizando activamente Django ORM. En las primeras implementaciones, utilizamos el modelo estándar de relaciones entre objetos (entidades) en la clave externa, sin embargo, este enfoque causó dificultades cuando fue necesario cambiar la jerarquía de las relaciones. Entonces, por ejemplo, en la jerarquía estándar de la Unidad de Negocio DSP -> Anunciante -> Campaña, algunos clientes necesitaban ingresar al nivel de Agencia (Unidad de Negocio -> Agencia -> Anunciante -> ...). Por lo tanto, abandonamos gradualmente el uso de la clave externa y organizamos enlaces entre objetos usando enlaces Muchos a Muchos a través de una tabla separada, lo llamamos 'LinkRegistry`.
Además, abandonamos gradualmente el código duro para llenar entidades y comenzamos a almacenar la mayoría de los campos en tablas separadas, vinculándolos también a través de `LinkRegistry` (ver imagen). ¿Por qué se necesitaba esto? Para cada cliente, el contenido de la entidad puede variar: se agregarán o eliminarán algunos campos. Resulta que tendremos que almacenar en cada entidad un superconjunto de campos para todos nuestros clientes. Al mismo tiempo, todos tendrán que hacerse opcionales, para que los campos obligatorios "extraterrestres" no interfieran con el trabajo.

Considere el ejemplo en la imagen: aquí se describe la estructura de la base de datos para la creatividad con un campo adicional: `image_url`. Solo su ID se almacena en la tabla de creatividades, y image_url se almacena en una tabla separada, su relación se describe mediante otra entrada en la tabla LinkRegistry. Por lo tanto, esta creatividad se describirá mediante tres entradas, una en cada una de las tablas. En consecuencia, para guardar una creatividad de este tipo, debe hacer una entrada en cada una de ellas y leerla de la misma manera, visite 3 tablas. Sería muy inconveniente escribir ese procesamiento cada vez desde cero, por lo que nuestra biblioteca extrae todos estos detalles del programador. Para trabajar con datos, Django y DRF utilizan modelos y serializadores descritos por código. En nuestros proyectos, el conjunto de campos en modelos y serializadores se determina en tiempo de ejecución por la configuración JSON, las clases de modelos se crean dinámicamente (usando la función de tipo) y se almacenan en un registro especial, desde donde están disponibles durante la operación de la aplicación. También utilizamos clases base especiales para estos modelos y serializadores, que ayudan a trabajar con una estructura base no estándar.
Al guardar un nuevo objeto (o actualizar uno existente), los datos recibidos del front-end ingresan al serializador, donde se validan; no hay nada inusual, los mecanismos DRF estándar funcionan. Pero el ahorro y la actualización se redefinen aquí. El serializador siempre sabe con qué modelo trabaja, y de acuerdo con la representación interna de nuestro modelo dinámico, puede entender en qué tabla deben colocarse los datos del siguiente campo. Codificamos esta información en campos de modelos personalizados (recuerde cómo se describe la `ForeignKey` en Django: un modelo relacionado se pasa dentro del campo, nosotros hacemos lo mismo). En estos campos especiales, también resumimos la necesidad de agregar un tercer registro de enlace a LinkRegistry usando el mecanismo descriptor: en el código que escriba `creative.image_url = 'http: // foo.bar' ', y en el método anulado` __set__` registramos en `LinkRegistry`.
Esto se aplica a la escritura en la base de datos. Y ahora lidiemos con la lectura. ¿Cómo se extrae una tupla de una base de datos a una instancia de modelo Django? En el modelo base de Django, hay un método `from_db`, que se llama por cada tupla recibida cuando se ejecuta una consulta en` queryset`. En la entrada, recibe una tupla y devuelve una instancia de modelo Django. Redefinimos este método en nuestro modelo base, donde de acuerdo con la tupla del modelo principal (donde solo entra `id`), obtenemos datos de otras tablas relacionadas y, al tener este conjunto completo, instanciamos el modelo. Por supuesto, también trabajamos para optimizar el mecanismo de captación previa de Django para nuestro caso de uso no estándar.
Prueba
Nuestro marco es bastante complejo, por lo que escribimos muchas pruebas. Tenemos pruebas tanto para el frontend como para el backend. Me detendré en las pruebas de back-end en detalle.
Para ejecutar las pruebas, usamos pytest. En el backend, tenemos dos grandes clases de pruebas: pruebas de nuestro marco (también lo llamamos el "núcleo") y pruebas de proyectos.
En el núcleo, escribimos pruebas unitarias aisladas y funcionales para probar puntos finales utilizando el complemento pytest-django. En general, todo el trabajo con la base de datos se prueba principalmente a través de solicitudes a la API, como sucede en la producción.
Las pruebas funcionales pueden especificar una configuración JSON. Para no adjuntarnos a la terminología del proyecto, utilizamos nombres "ficticios" para entidades con las que probamos nuestras características en el núcleo ("Emma", "Alla", "Karl", "Maria", etc.). Dado que, al escribir la función image_url, no queremos limitar la conciencia del desarrollador al hecho de que solo se puede usar con la entidad Creativa: las funciones y entidades son universales, y se pueden conectar entre sí en cualquier combinación que sea relevante para un cliente en particular.
En cuanto a los proyectos de prueba, en ellos todos los casos de prueba se ejecutan con la configuración de producción, sin entidades ficticias, ya que es importante que verifiquemos exactamente con qué trabajará el cliente. En el proyecto, puede escribir cualquier prueba que cubra las características de la lógica empresarial del proyecto. Al mismo tiempo, las pruebas CRUD básicas se pueden conectar al proyecto desde el núcleo. Están escritos de manera general y se pueden conectar a cualquier proyecto: una prueba de características puede leer la configuración JSON de un proyecto, determinar a qué entidades está conectada esta característica y ejecutar comprobaciones solo para las entidades necesarias. Para la conveniencia de preparar datos de prueba, hemos desarrollado un sistema de ayudantes que también pueden preparar conjuntos de datos de prueba basados en la configuración JSON. Las pruebas E2E en Protractor ocupan un lugar especial en las pruebas del proyecto, que prueban todas las funciones básicas del proyecto. Estas pruebas también se describen con JSON, están escritas y son compatibles con los desarrolladores front-end.
Epílogo
En este artículo, examinamos el enfoque de diseño modular desarrollado por IPONWEB en el departamento de IU. Esta solución ha estado funcionando con éxito en producción durante tres años. Sin embargo, esta solución todavía tiene una serie de limitaciones que no nos permiten descansar en nuestros laureles. En primer lugar, nuestra base de código sigue siendo bastante compleja. En segundo lugar, el código básico que admite modelos dinámicos está asociado con componentes críticos como búsqueda, carga masiva de objetos, derechos de acceso y otros. Debido a esto, los cambios en uno de los componentes pueden afectar significativamente a los demás. En un esfuerzo por eliminar estas limitaciones, continuamos procesando activamente nuestra biblioteca, dividiéndola en muchas partes independientes y reduciendo la complejidad del código. Le informaremos sobre los resultados en los siguientes artículos.
Este artículo es una transcripción extendida de mi presentación en MoscowPythonConf ++ 2019, por lo que también comparto enlaces a
videos y
diapositivas .