Edición empresarial de C ++
¿Qué es la "edición empresarial"?
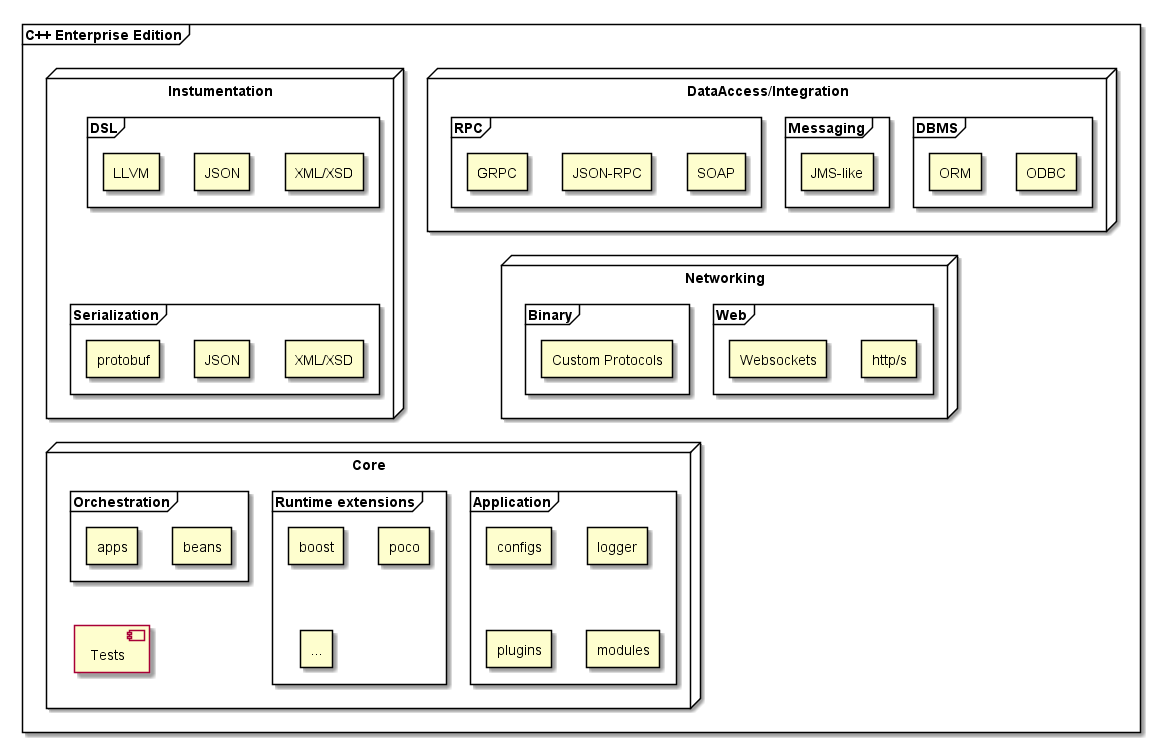
Sorprendentemente, durante todo el tiempo que he estado trabajando en TI, nunca escuché a nadie decir "edición empresarial" sobre un lenguaje de programación, excepto Java. Pero después de todo, la gente escribe aplicaciones para el segmento corporativo en muchos lenguajes de programación, y las entidades en las que operan los programadores, si no son idénticas, son similares. Y para c ++ en particular, me gustaría llenar el vacío de emprendimiento, al menos contarlo.
Aplicada a C ++, la "edición empresarial" es un subconjunto del lenguaje y las bibliotecas que le permite desarrollar "rápidamente" aplicaciones [multiplataforma] para sistemas modulares acoplados libremente con arquitectura distribuida y / o de clúster y con lógica empresarial aplicada y, como regla, alta carga.
Para continuar nuestra conversación, en primer lugar, es necesario presentar los conceptos de aplicación , módulo y complemento.
- Una aplicación es un archivo ejecutable que puede funcionar como un servicio del sistema, tiene su propia configuración, puede aceptar parámetros de entrada y puede tener una estructura de complemento modular.
- Un módulo es una implementación de una interfaz que vive dentro de una aplicación o lógica empresarial.
- Un complemento es una biblioteca cargada dinámicamente que implementa una o más interfaces, o parte de una lógica de negocios.
Todas las aplicaciones, que realizan su trabajo único, generalmente necesitan mecanismos de todo el sistema, como acceso a datos (DBMS), intercambio de información a través de un bus común (JMS), ejecución de scripts distribuidos y locales con preservación de consistencia (Transacciones), procesamiento de solicitudes por ejemplo, a través del protocolo http (s) (fastcgi) o mediante sockets web, etc. Cada aplicación debe tener la capacidad de orquestar sus módulos (OSGI), y en un sistema distribuido debe poder orquestar aplicaciones.
Un ejemplo de un sistema distribuido débilmente conectado
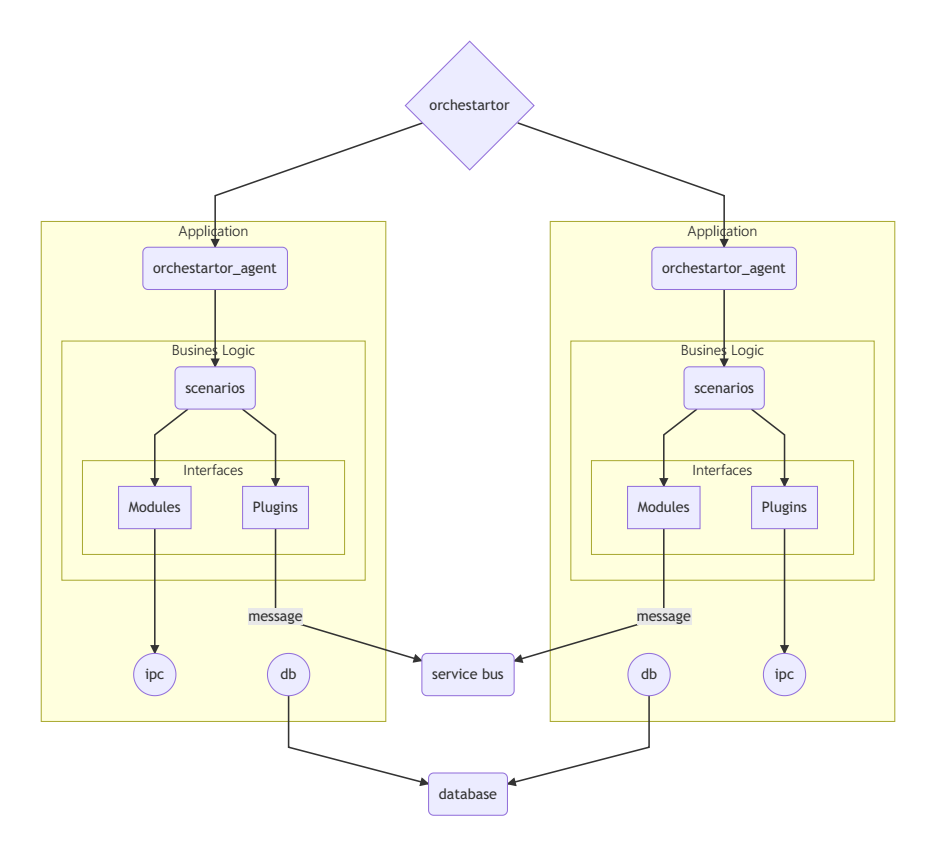
App
Un ejemplo de un esquema de aplicación de servidor empresarial corporativo.

Ya he dado una definición general de la aplicación, así que veamos qué hay ahora en el mundo de C ++ para la implementación de este concepto. Los primeros en mostrar la implementación de la aplicación fueron marcos gráficos como Qt y GTK, pero sus versiones de la aplicación inicialmente suponían que la aplicación era una "ventana" gráfica con su contexto y solo después de un tiempo apareció una visión general de la aplicación, incluso como un servicio del sistema, por ejemplo, qtservice Pero realmente no quiero arrastrar un marco gráfico condicional para una tarea de servicio, así que echemos un vistazo a las bibliotecas no gráficas. Y el impulso viene primero ... Pero desafortunadamente, la lista de bibliotecas oficiales no incluye Boost.Application y similares. Hay un proyecto separado Boost.Application . El proyecto es muy interesante, pero, en mi opinión, detallado, aunque se respeta la ideología del impulso. Aquí hay una aplicación de ejemplo de Boost.
#define BOOST_ALL_DYN_LINK #define BOOST_LIB_DIAGNOSTIC #define BOOST_APPLICATION_FEATURE_NS_SELECT_BOOST #include <fstream> #include <iostream> #include <boost/application.hpp> using namespace boost; // my application code class myapp { public: myapp(application::context& context) : context_(context) {} void worker() { // ... while (st->state() != application::status::stopped) { boost::this_thread::sleep(boost::posix_time::seconds(1)); if (st->state() == application::status::paused) my_log_file_ << count++ << ", paused..." << std::endl; else my_log_file_ << count++ << ", running..." << std::endl; } } // param int operator()() { // launch a work thread boost::thread thread(&myapp::worker, this); context_.find<application::wait_for_termination_request>()->wait(); return 0; } bool stop() { my_log_file_ << "Stoping my application..." << std::endl; my_log_file_.close(); return true; // return true to stop, false to ignore } private: std::ofstream my_log_file_; application::context& context_; }; int main(int argc, char* argv[]) { application::context app_context; // auto_handler will automatically add termination, pause and resume (windows) // handlers application::auto_handler<myapp> app(app_context); // to handle args app_context.insert<application::args>( boost::make_shared<application::args>(argc, argv)); // my server instantiation boost::system::error_code ec; int result = application::launch<application::server>(app, app_context, ec); if (ec) { std::cout << "[E] " << ec.message() << " <" << ec.value() << "> " << std::endl; } return result; }
El ejemplo anterior define la aplicación myapp con su hilo de trabajo principal y el mecanismo para iniciar esta aplicación.
Como complemento, daré un ejemplo similar del marco pocoproject
#include <iostream> #include <sstream> #include "Poco/AutoPtr.h" #include "Poco/Util/AbstractConfiguration.h" #include "Poco/Util/Application.h" #include "Poco/Util/HelpFormatter.h" #include "Poco/Util/Option.h" #include "Poco/Util/OptionSet.h" using Poco::AutoPtr; using Poco::Util::AbstractConfiguration; using Poco::Util::Application; using Poco::Util::HelpFormatter; using Poco::Util::Option; using Poco::Util::OptionCallback; using Poco::Util::OptionSet; class SampleApp : public Application { public: SampleApp() : _helpRequested(false) {} protected: void initialize(Application &self) { loadConfiguration(); Application::initialize(self); } void uninitialize() { Application::uninitialize(); } void reinitialize(Application &self) { Application::reinitialize(self); } void defineOptions(OptionSet &options) { Application::defineOptions(options); options.addOption( Option("help", "h", "display help information on command line arguments") .required(false) .repeatable(false) .callback(OptionCallback<SampleApp>(this, &SampleApp::handleHelp))); } void handleHelp(const std::string &name, const std::string &value) { _helpRequested = true; displayHelp(); stopOptionsProcessing(); } void displayHelp() { HelpFormatter helpFormatter(options()); helpFormatter.setCommand(commandName()); helpFormatter.setUsage("OPTIONS"); helpFormatter.setHeader( "A sample application that demonstrates some of the features of the " "Poco::Util::Application class."); helpFormatter.format(std::cout); } int main(const ArgVec &args) { if (!_helpRequested) { logger().information("Command line:"); std::ostringstream ostr; logger().information(ostr.str()); logger().information("Arguments to main():"); for (const auto &it : args) { logger().information(it); } } return Application::EXIT_OK; } private: bool _helpRequested; }; POCO_APP_MAIN(SampleApp)
Le llamo la atención sobre el hecho de que la aplicación debe contener mecanismos para iniciar sesión, descargar configuraciones y opciones de procesamiento.
Por ejemplo, para procesar opciones hay:
Para configurar:
Para escribir en el diario:
Debilidad, módulos y complementos.
La debilidad en el sistema "corporativo" es la posibilidad de una sustitución rápida e indolora de ciertos mecanismos. Esto se aplica tanto a los módulos dentro de la aplicación como a las aplicaciones mismas, así como a las implementaciones, por ejemplo, microservicios. ¿Qué tenemos, desde el punto de vista de C ++? Todo está mal con los módulos, aunque implementan interfaces, pero viven dentro de una aplicación "compilada", por lo que no habrá cambios rápidos, ¡pero los complementos vienen al rescate! Con la ayuda de bibliotecas dinámicas, no solo puede organizar la sustitución rápida, sino también la operación simultánea de dos versiones diferentes. Hay todo un mundo de "llamada a procedimiento remoto", también conocido como RPC. Los mecanismos de búsqueda para implementaciones de interfaz, junto con RPC, generaron algo similar a OSGI del mundo Java. Es genial tener soporte para esto en el ecosistema C ++ y hay uno, aquí hay un par de ejemplos:
Módulo de muestra para el "servidor de aplicaciones" POCO OSP
#include "Poco/OSP/BundleActivator.h" #include "Poco/OSP/BundleContext.h" #include "Poco/ClassLibrary.h" namespace HelloBundle { class BundleActivator: public Poco::OSP::BundleActivator { public: void start(Poco::OSP::BundleContext::Ptr pContext) { pContext->logger().information("Hello, world!"); } void stop(Poco::OSP::BundleContext::Ptr pContext) { pContext->logger().information("Goodbye!"); } }; }
Módulo de muestra para el "servidor de aplicaciones" Apache Celix
#include "Bar.h" #include "BarActivator.h" using namespace celix::dm; DmActivator* DmActivator::create(DependencyManager& mng) { return new BarActivator(mng); } void BarActivator::init() { std::shared_ptr<Bar> bar = std::shared_ptr<Bar>{new Bar{}}; Properties props; props["meta.info.key"] = "meta.info.value"; Properties cProps; cProps["also.meta.info.key"] = "also.meta.info.value"; this->cExample.handle = bar.get(); this->cExample.method = [](void *handle, int arg1, double arg2, double *out) { Bar* bar = static_cast<Bar*>(handle); return bar->cMethod(arg1, arg2, out); }; mng.createComponent(bar) //using a pointer a instance. Also supported is lazy initialization (default constructor needed) or a rvalue reference (move) .addInterface<IAnotherExample>(IANOTHER_EXAMPLE_VERSION, props) .addCInterface(&this->cExample, EXAMPLE_NAME, EXAMPLE_VERSION, cProps) .setCallbacks(&Bar::init, &Bar::start, &Bar::stop, &Bar::deinit); }
Cabe señalar que en los sistemas distribuidos débilmente conectados es necesario tener mecanismos que aseguren las operaciones transaccionales, pero por el momento no hay nada similar para C ++. Es decir así como no hay forma dentro de una aplicación para hacer una solicitud a la base de datos, archivo y esb dentro de una transacción, tampoco existe tal forma para las operaciones distribuidas. Por supuesto, todo se puede escribir, pero no hay nada generalizado. Alguien dirá que hay software transactional memory , sí, por supuesto, pero solo facilitará la escritura de los mecanismos de transacción por sí solo.
Kit de herramientas
De todas las herramientas auxiliares, quiero destacar la serialización y DSL, porque su presencia le permite implementar muchos otros componentes y scripts.
Serialización
La serialización es el proceso de traducir una estructura de datos en una secuencia de bits. La inversa de la operación de serialización es la operación de deserialización (estructuración), que restaura el estado inicial de la estructura de datos a partir de la secuencia de bits de wikipedia . En el contexto de C ++, es importante comprender que hoy no hay forma de serializar objetos y transferirlos a otro programa que previamente no sabía nada sobre este objeto. En este caso, me refiero a un objeto como una implementación de una determinada clase con campos y métodos. Por lo tanto, destacaré dos enfoques principales utilizados en el mundo C ++:
- serialización a formato binario
- serialización a formato formal
En la literatura y en Internet, a menudo hay una separación en formato binario y de texto, pero creo que esta separación no es del todo correcta, por ejemplo, MsgPack no guarda información sobre el tipo de objeto, por lo tanto, el programador tiene el control sobre la pantalla correcta y el formato MsgPack es binario. Protobuf , por el contrario, guarda toda la metainformación en una representación intermedia, lo que permite su uso entre diferentes lenguajes de programación, mientras que Protobuf también es binario.
Entonces, el proceso de serialización, ¿por qué lo necesitamos? Para revelar todos los matices, necesitamos otro artículo, intentaré explicarlo con ejemplos. La serialización permite, mientras permanece en términos de un lenguaje de programación, "empacar" entidades de software (clases, estructuras) para transferirlas a través de la red, para el almacenamiento persistente, por ejemplo, en archivos y otros scripts, que, sin serialización, nos obligan a inventar nuestros propios protocolos y tener en cuenta el hardware y plataforma de software, codificación de texto, etc.
Aquí hay un par de bibliotecas de muestra para la serialización:
DSL
Lenguaje específico de dominio: un lenguaje de programación para su área temática. De hecho, cuando nos dedicamos a la automatización de una determinada empresa, nos enfrentamos con el área temática del cliente y describimos todos los procesos comerciales en términos del área temática, pero tan pronto como se trata de programación, los programadores, junto con los analistas, se dedican a mapear los conceptos de procesos comerciales en conceptos marco y lenguaje de programación. Y si no hay un cierto número de procesos de negocio, y el área temática se define estrictamente, tiene sentido crear su propio DSL, implementar la mayoría de los escenarios existentes y agregar otros nuevos. En el mundo de C ++, no hay muchas oportunidades para la implementación "rápida" de su DSL. Hay, por supuesto, mecanismos para incrustar lua, javascript y otros lenguajes de programación en C ++, un programa, pero ¿quién necesita vulnerabilidades y un motor de ejecución potencialmente no controlado para "todo"? Así que analizaremos las herramientas que le permiten hacer DSL usted mismo.
La biblioteca Boost.Proto está diseñada para crear su propio DSL, este es su propósito directo, aquí hay un ejemplo
#include <iostream> #include <boost/proto/proto.hpp> #include <boost/typeof/std/ostream.hpp> using namespace boost; proto::terminal< std::ostream & >::type cout_ = { std::cout }; template< typename Expr > void evaluate( Expr const & expr ) { proto::default_context ctx; proto::eval(expr, ctx); } int main() { evaluate( cout_ << "hello" << ',' << " world" ); return 0; }
Flex y Bison se utilizan para generar lexers y analizadores para su gramática. La sintaxis no es simple, pero resuelve el problema de manera eficiente.
Código de muestra para generar un lexer
%{ #include <math.h> %} DIGIT [0-9] ID [az][a-z0-9]* %% {DIGIT}+ { printf( "An integer: %s (%d)\n", yytext, atoi( yytext ) ); } {DIGIT}+"."{DIGIT}* { printf( "A float: %s (%g)\n", yytext, atof( yytext ) ); } if|then|begin|end|procedure|function { printf( "A keyword: %s\n", yytext ); } {ID} printf( "An identifier: %s\n", yytext ); "+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext ); "{"[^}\n]*"}" /* eat up one-line comments */ [ \t\n]+ /* eat up whitespace */ . printf( "Unrecognized character: %s\n", yytext ); %% main( argc, argv ) int argc; char **argv; { ++argv, --argc; /* skip over program name */ if ( argc > 0 ) yyin = fopen( argv[0], "r" ); else yyin = stdin; yylex(); }
Y, sin embargo, existe la especificación SCXML : XML de gráfico de estado: notación de máquina de estado para abstracción de control, una descripción de una máquina de estado en marcado similar a XML. Esto no es exactamente DSL, sino también un mecanismo conveniente para automatizar procesos sin programación. Qt SCXML tiene una excelente implementación. Hay otras implementaciones, pero no son tan flexibles.
Este es un ejemplo de un cliente FTP en notación SCXML, un ejemplo tomado del sitio de documentación Qt
<scxml xmlns="http://www.w3.org/2005/07/scxml" version="1.0" name="FtpClient" datamodel="ecmascript"> <state id="G" initial="I"> <transition event="reply" target="E"/> <transition event="cmd" target="F"/> <state id="I"> <transition event="reply.2xx" target="S"/> </state> <state id="B"> <transition event="cmd.DELE cmd.CWD cmd.CDUP cmd.HELP cmd.NOOP cmd.QUIT cmd.SYST cmd.STAT cmd.RMD cmd.MKD cmd.PWD cmd.PORT" target="W.general"/> <transition event="cmd.APPE cmd.LIST cmd.NLST cmd.REIN cmd.RETR cmd.STOR cmd.STOU" target="W.1xx"/> <transition event="cmd.USER" target="W.user"/> <state id="S"/> <state id="F"/> </state> <state id="W"> <onentry> <send eventexpr=""submit." + _event.name"> <param name="params" expr="_event.data"/> </send> </onentry> <transition event="reply.2xx" target="S"/> <transition event="reply.4xx reply.5xx" target="F"/> <state id="W.1xx"> <transition event="reply.1xx" target="W.transfer"/> </state> <state id="W.transfer"/> <state id="W.general"/> <state id="W.user"> <transition event="reply.3xx" target="P"/> </state> <state id="W.login"/> </state> <state id="P"> <transition event="cmd.PASS" target="W.login"/> </state> </state> <final id="E"/> </scxml>
Y así se ve en el visualizador SCXML

Acceso a datos e integración
Este es quizás uno de los temas más "doloridos" del mundo con ++. El mundo de los datos para un desarrollador de c ++ siempre está conectado con la necesidad de poder mostrarlos en la esencia de un lenguaje de programación. Una fila en una tabla está en un objeto o estructura, json está en una clase, y así sucesivamente. En ausencia de reflexión, este es un gran problema, pero nosotros, con ++, apodos, no nos desesperamos y encontramos varias formas de salir de la situación. Comencemos con el DBMS.
Ahora seré un lugar común, pero ODBC es el único mecanismo universal para acceder a DBMS relacionales, todavía no se han inventado otras opciones, pero C ++: la comunidad no se detiene y hoy existen bibliotecas y marcos que proporcionan interfaces de acceso generalizadas a varios DBMS.
En primer lugar, mencionaré bibliotecas que proporcionan acceso unificado al DBMS utilizando bibliotecas cliente y SQL.
Todos son buenos, pero te hacen recordar los matices de mostrar datos de la base de datos en objetos y estructuras de C ++, además de que la eficiencia de las consultas SQL recae inmediatamente en tus hombros.
Los siguientes ejemplos son ORM en C ++. Si los hay! Y, por cierto, SOCI admite mecanismos ORM a través de la especialización soci :: type_conversion, pero intencionalmente no lo incluí, ya que este no es su propósito directo.
- LiteSQL C ++ - ORM, que le permite interactuar con DBMS SQLite3, PostgreSQL, MySQL. Esta biblioteca requiere que el programador prediseñe archivos xml con una descripción de objetos y relaciones para generar fuentes adicionales usando litesql-gen.
- ODB de Code Synthesis es un ORM muy interesante, le permite permanecer dentro de C ++, sin usar archivos de descripción intermedios, aquí hay un pequeño ejemplo:
#pragma db object class person {
- Wt ++ es un gran marco, puede escribir un artículo separado sobre él en general, también contiene ORM que puede interactuar con DBMS Sqlite3, Firebird, MariaDB / MySQL, MSSQL Server, PostgreSQL y Oracle.
- También me gustaría mencionar ORM sobre sqlite sqlite_orm e hiberlite . Dado que sqlite es un DBMS incorporado, y ORM para él verifica las consultas, y de hecho toda interacción con la base de datos, en tiempo de compilación, la herramienta se vuelve muy conveniente para una rápida implementación y creación de prototipos.
- QHibernate - ORM para Qt5 con soporte Postgresql. Empapado de ideas hibernadas de Java.
Aunque la integración a través de un DBMS se considera "integración", prefiero dejarla fuera de los corchetes y pasar a la integración a través de protocolos y API.
RPC - llamada remota porocess, una técnica bien conocida para la interacción del "cliente" con el "servidor". Como en el caso de ORM, la dificultad principal es escribir / generar varios archivos auxiliares para vincular el protocolo con funciones reales en el código. No mencionaré intencionalmente los diversos RPC implementados directamente en el sistema operativo, pero me enfocaré en soluciones multiplataforma.
- grpc es un marco de Google para llamadas a procedimientos remotos, un marco muy popular y eficiente de google. Básicamente usa Google Protobuf, lo mencioné en la sección de serialización, admite muchos lenguajes de programación, pero es nuevo en el entorno corporativo.
- json-rpc: RPC, donde se usa JSON como protocolo, un buen ejemplo de implementación es la biblioteca libjson-rpc-cpp , aquí hay un ejemplo de un archivo de descripción:
[ { "name": "sayHello", "params": { "name": "Peter" }, "returns" : "Hello Peter" }, { "name" : "notifyServer" } ]
Según esta descripción, se generan códigos de cliente y servidor que se pueden utilizar en su aplicación. En general, hay una especificación para JSON-RPC 1.0 y 2.0 . Por lo tanto, llamar a una función desde una aplicación web y procesarla en C ++ no es difícil.
- XML-RPC y SOAP, el líder claro aquí, es gSOAP , una biblioteca muy poderosa, no creo que haya alternativas valiosas . Como en el ejemplo anterior, creamos un archivo intermedio con xml-rpc o contenido de jabón, configuramos el generador, obtenemos el código y lo usamos. Ejemplos típicos de solicitud y respuesta en notación xml-rpc:
<?xml version="1.0"?> <methodCall> <methodName>examples.getState</methodName> <params> <param> <value><i4>41</i4></value> </param> </params> </methodCall> <methodResponse> <params> <param> <value><string>State-Ready</string></value> </param> </params> </methodResponse>
- Poco :: RemotingNG es un proyecto muy interesante de pocoproject. Le permite determinar qué clases, funciones, etc. se puede llamar de forma remota utilizando anotaciones en los comentarios. Aquí hay un ejemplo
typedef unsigned long GroupID; typedef std::string GroupName;
Para generar código auxiliar, se usa su propio "compilador". Durante mucho tiempo, esta funcionalidad solo estaba en la versión paga de POCO Framework, pero con el advenimiento del proyecto macchina.io , puede usarla de forma gratuita.
La mensajería es un concepto algo amplio, pero lo analizaré desde el punto de vista de la mensajería a través de un bus de datos común, es decir, iré a través de bibliotecas y servidores que implementan el Servicio de mensajes Java utilizando varios protocolos, por ejemplo AMQP o STOMP . El bus de datos común, también llamado Enterprise Servise Bus (ESB), es muy común en soluciones de segmento empresarial, ya que le permite integrar rápidamente varios elementos de la infraestructura de TI entre ellos, utilizando un patrón punto a punto y publicar-suscribirse. Hay pocos corredores de mensajes industriales escritos en C ++, conozco dos: Apache Qpid y UPMQ , y el segundo lo escribo yo. Hay Eclipse Mosquitto , pero está escrito en si. La belleza de JMS para Java es que su código no depende del protocolo que utilizan el cliente y el servidor, JMS como ODBC, declara funciones y comportamiento, por lo que puede cambiar el proveedor de JMS al menos una vez al día y no reescribir el código, por C ++, desafortunadamente, no lo es. Deberá reescribir la parte del cliente para cada proveedor. En mi opinión, enumeraré las bibliotecas C ++ más populares para corredores de mensajes no menos populares:
El principio de que estas bibliotecas proporcionan una funcionalidad general es generalmente consistente con la especificación JMS. En este sentido, existe el deseo de reunir un grupo de personas de ideas afines y escribir algún tipo de ODBC, pero para los corredores de mensajes, de modo que cada programador de C ++ sufra un poco menos de lo habitual.
Conectividad de red
Deliberadamente dejé todo lo que estaba conectado directamente con la interacción de la red hasta el final, porque En este campo, los desarrolladores de C ++ tienen los menores problemas, en mi opinión. Solo queda elegir el patrón más cercano a su decisión y el marco que lo implementa. Antes de enumerar las bibliotecas más populares, quiero señalar un detalle importante en el desarrollo de sus propias aplicaciones de red. Si decide crear su propio protocolo a través de TCP o UDP, esté preparado para que todo tipo de herramientas de seguridad "inteligentes" bloqueen su tráfico, así que tenga cuidado al empacar su protocolo, por ejemplo, en https o puede haber problemas. Entonces las bibliotecas:
- Boost.Asio y Boost.Beast : una de las implementaciones más populares para la comunicación de red asíncrona, hay soporte para HTTP y WebSockets
- Poco :: Net también es una solución muy popular, y además de la interacción en bruto, puede usar clases preparadas de TCP Server Framework, Reactor Framework, así como clases de clientes y servidores para HTTP, FTP y correo electrónico. También hay soporte para WebSockets
- ACE : nunca usó esta biblioteca, pero sus colegas dicen que también es una biblioteca digna, con un enfoque integrado para implementar aplicaciones de red y más.
- Red Qt : en Qt, la parte de la red está bien implementada. El único punto controvertido son las señales y las ranuras para las soluciones de servidor, aunque el servidor está en Qt.
Total
Entonces, lo que quería decir es una descripción general de estas bibliotecas. Si tuve éxito, entonces tiene la impresión de que existe, por así decirlo, una "edición empresarial", pero no hay soluciones para su implementación y uso, solo un zoológico de bibliotecas. Entonces realmente lo es. Existen bibliotecas más o menos completas para desarrollar aplicaciones para el segmento corporativo, pero no existe una solución estándar. Por mi cuenta, solo puedo recomendar pocoproject y maccina.io como punto de partida para investigar soluciones para el backend y el impulso para cualquier caso, y, por supuesto, ¡estoy buscando personas con ideas afines para promover el concepto de "C ++ Enterprise Edition"!