En teoría, el uso del aprendizaje automático (ML) ayuda a reducir la participación humana en procesos y operaciones, reasignar recursos y reducir costos. ¿Cómo funciona esto en una empresa e industria en particular? Como muestra nuestra experiencia, funciona.
En una determinada etapa de desarrollo, en VTB Capital nos enfrentamos a una necesidad urgente de reducir el tiempo que lleva procesar solicitudes de soporte técnico. Después de analizar las opciones, se decidió utilizar la tecnología ML para clasificar las llamadas de los usuarios comerciales de Calypso, la plataforma de inversión clave de la compañía. El procesamiento rápido de tales solicitudes es crucial para la alta calidad del servicio de TI. Pedimos a nuestros socios clave,
EPAM, que nos ayuden a resolver este problema.

Entonces, las solicitudes de soporte se reciben por correo electrónico y se transforman en tickets en Jira. Luego, los especialistas de soporte los clasifican manualmente, los priorizan, ingresan datos adicionales (por ejemplo, de qué departamento y ubicación se recibió una solicitud, a qué unidad funcional del sistema pertenece) y designan a los artistas. En total, se utilizan alrededor de 10 categorías de consultas. Esto, por ejemplo, puede ser una solicitud para analizar algunos datos y proporcionar información al solicitante, agregar un nuevo usuario, etc. Además, las acciones pueden ser estándar o no estándar, por lo que es muy importante determinar inmediatamente de forma correcta el tipo de solicitud y asignar la ejecución al especialista adecuado.
Es importante tener en cuenta: VTB Capital no solo quería desarrollar una solución tecnológica aplicada, sino también evaluar las capacidades de varias herramientas y tecnologías en el mercado. Una tarea, dos enfoques diferentes, dos plataformas tecnológicas y tres semanas y media: ¿cuál fue el resultado?
Prototipo No. 1: tecnologías y modelos.
La base para el desarrollo del prototipo fue el enfoque propuesto por el equipo de EPAM y los datos históricos: alrededor de 10,000 boletos de Jira. La atención principal se centró en los 3 campos obligatorios que contiene cada ticket: Tipo de problema (tipo de problema), Resumen ("encabezado" de la carta o asunto de la solicitud) y Descripción (descripción). En el marco del proyecto, se planeó resolver el problema de analizar el texto de los campos Resumen y Descripción y determinar automáticamente el tipo de solicitud a partir de sus resultados.
Las características del texto en estos dos campos de tickets son las principales dificultades técnicas para analizar datos y desarrollar modelos de ML. Por lo tanto, el campo Resumen puede contener texto bastante "limpio", pero incluye palabras y términos específicos (por ejemplo, los
informes de CWS no se ejecutan). El campo Descripción, por el contrario, se caracteriza por un texto más "sucio" con una gran cantidad de caracteres especiales, símbolos, barras invertidas y residuos de elementos no textuales:
Dera colegas,
¿Podría explicarnos cuál es la diferencia entre las medidas de riesgo FX_Opt_delta_all y FX_Opt_delta_cash?
! 01D39C59.62374C90_image001.png! )
Además, el texto a menudo combina varios idiomas (principalmente, naturalmente, ruso e inglés), se puede encontrar terminología de negocios, ruglish y jerga de programador. Y, por supuesto, dado que las solicitudes a menudo se escriben con prisa, en ambos casos no se descartan errores tipográficos y ortográficos.
Las tecnologías elegidas por el equipo de EPAM incluyeron Python 3.5 para el desarrollo de prototipos, NLTK + Gensim + Re para el procesamiento de texto, Pandas + Sklearn para el análisis de datos y desarrollo de modelos, y Keras + Tensorflow como un marco de aprendizaje profundo y backend.
Teniendo en cuenta las posibles características de los datos iniciales, se construyeron tres representaciones para la extracción de caracteres del campo Resumen: a nivel de símbolo, combinación de símbolos y palabras individuales. Cada una de las representaciones se utilizó como entrada a una red neuronal recurrente.
A su vez, las estadísticas de caracteres de servicio (importantes para procesar texto usando signos de exclamación, barras, etc.) y los valores promedio de las cadenas después de filtrar los caracteres de servicio y la basura (para preservación compacta de la estructura del texto) se eligieron como una representación para el campo Descripción; así como representación a nivel de palabra después de filtrar palabras de parada. Cada representación sirvió como una entrada a una red neuronal: estadísticas en una línea completamente conectada, línea por línea y al nivel de las palabras, en una recursiva.
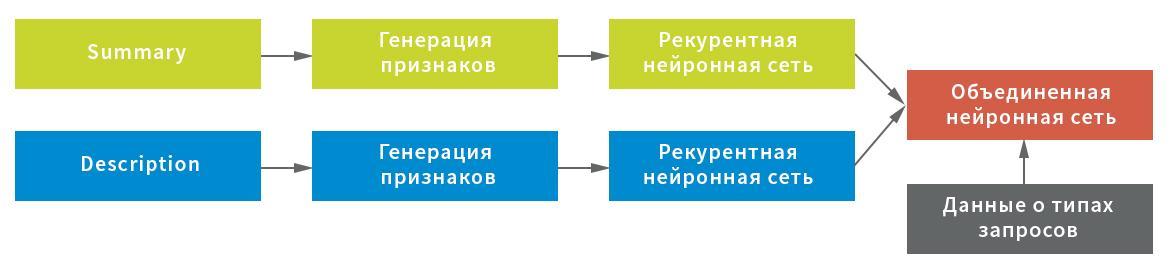
En este esquema, se utilizó una red neuronal como una red recurrente, que consta de una capa GRU bidireccional con un abandono recurrente y normal, un grupo de estados ocultos de la red recurrente utilizando la capa GlobalMaxPool1D y una capa totalmente conectada (Densa) con un abandono. Para cada una de las entradas, se construyó su propia "cabeza" de la red neuronal, y luego se combinaron mediante concatenación y se bloquearon en la variable objetivo.
Para obtener el resultado final, la red neuronal combinada devolvió las probabilidades de una solicitud particular que pertenece a cada tipo. Los datos se dividieron en cinco bloques sin intersecciones: el modelo se construyó en cuatro de ellos y se probó en el quinto. Como a cada solicitud se le puede asignar solo un tipo de solicitud, la regla para tomar una decisión era simple: por el valor de probabilidad máxima.
Prototipo No. 2: algoritmos y principios de trabajo.
El segundo prototipo, para el cual se tomó la propuesta preparada por el equipo de VTB Capital, es una aplicación en Microsoft .NET Core con bibliotecas Microsoft.ML para implementar algoritmos de aprendizaje automático y Atlassian.Net SDK para interactuar con Jira a través de la API REST. La base para construir modelos ML también se convirtió en datos históricos: 50,000 boletos Jira. Como en el primer caso, el aprendizaje automático cubrió los campos Resumen y Descripción. Antes de su uso, ambos campos también fueron "limpiados". Saludos, firmas, historial de correspondencia y elementos no textuales (por ejemplo, imágenes) se eliminaron de la carta del usuario. Además, al usar la funcionalidad incorporada en Microsoft ML, las palabras de detención que no eran relevantes para procesar y analizar el texto se borraron del texto en inglés.
Perceptron promediado (clasificación binaria) se eligió como un algoritmo de aprendizaje automático, que se complementa con el método One Versus All para proporcionar clasificación multiclase
Evaluación de los resultados.
Ningún modelo de ML puede (posiblemente, todavía) proporcionar un 100% de precisión del resultado.
El algoritmo Prototipo No. 1 proporciona la proporción de la clasificación correcta (Precisión), igual a 0.8003 del número total de solicitudes, o el 80%. Además, el valor de una métrica similar en una situación en la que se supone que la persona elegirá la respuesta correcta de las dos presentadas por la solución alcanza 0.901, o 90%. Por supuesto, hay casos en los que la solución desarrollada funciona peor o no puede dar la respuesta correcta, como regla, debido a un conjunto muy corto de palabras o especificidad de la información en la solicitud misma. El papel todavía lo juega la cantidad insuficientemente grande de datos utilizados en el proceso de aprendizaje. Según estimaciones preliminares, un aumento en el volumen de información procesada permitirá aumentar la precisión de la clasificación en otros 0.01-0.03 puntos.
Los resultados del mejor modelo en las métricas de precisión (Precisión) e integridad (Recuperación) se evalúan de la siguiente manera:

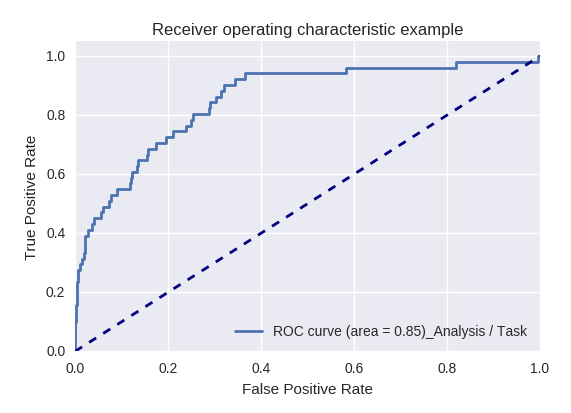
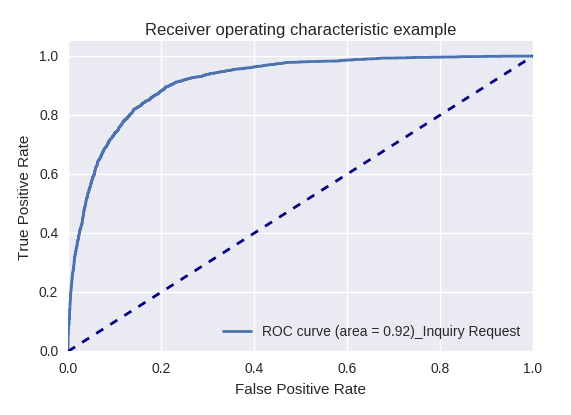
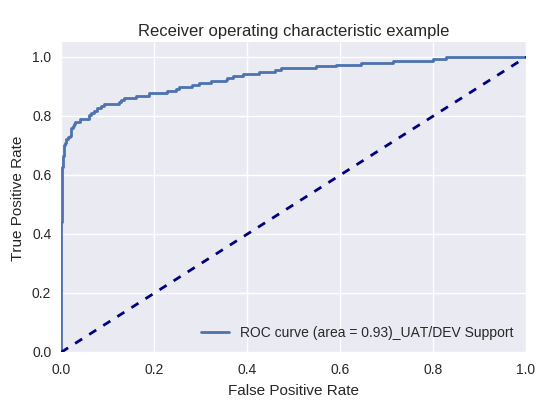
Si evaluamos la calidad del modelo en su conjunto para varios tipos de consultas utilizando curvas ROC-AUC, los resultados son los siguientes.
Solicitudes de acción (Solicitud de acción) y análisis de información (Análisis / Solicitud de tarea)
 Solicitudes de cambios en los datos comerciales (Solicitud de datos comerciales) y cambios (Solicitud de cambios)
Solicitudes de cambios en los datos comerciales (Solicitud de datos comerciales) y cambios (Solicitud de cambios)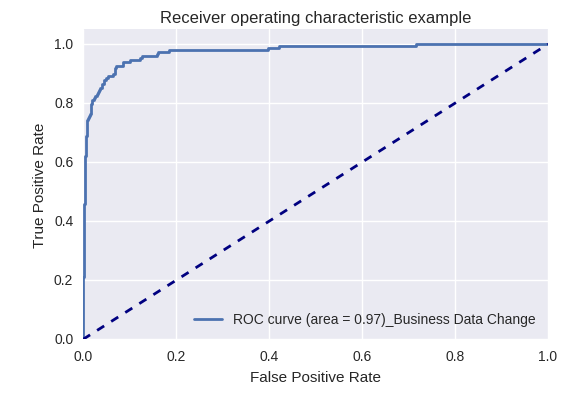
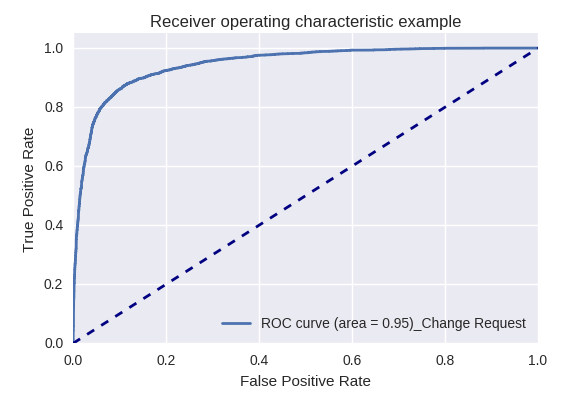 Solicitud de desarrollo y solicitud de consulta
Solicitud de desarrollo y solicitud de consulta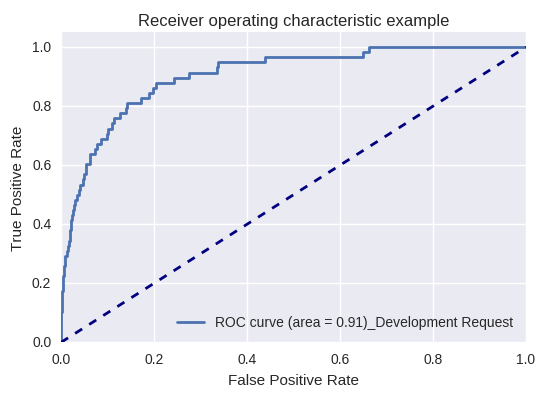
 Solicitudes para crear un nuevo objeto (Nueva solicitud de objeto) y agregar un nuevo usuario (Nueva solicitud de usuario)
Solicitudes para crear un nuevo objeto (Nueva solicitud de objeto) y agregar un nuevo usuario (Nueva solicitud de usuario)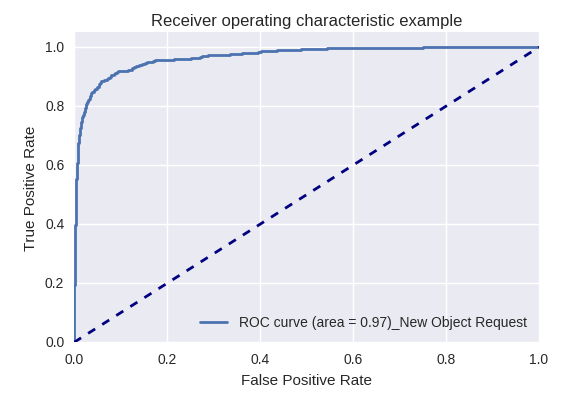
 Solicitud de producción y solicitud de soporte UAT / DEV (solicitud de soporte UAT / Dev)
Solicitud de producción y solicitud de soporte UAT / DEV (solicitud de soporte UAT / Dev)
A continuación se dan ejemplos de clasificación correcta e incorrecta para algunos tipos de consultas:
Solicitud de consulta
Solicitud de cambio
Clasificación correcta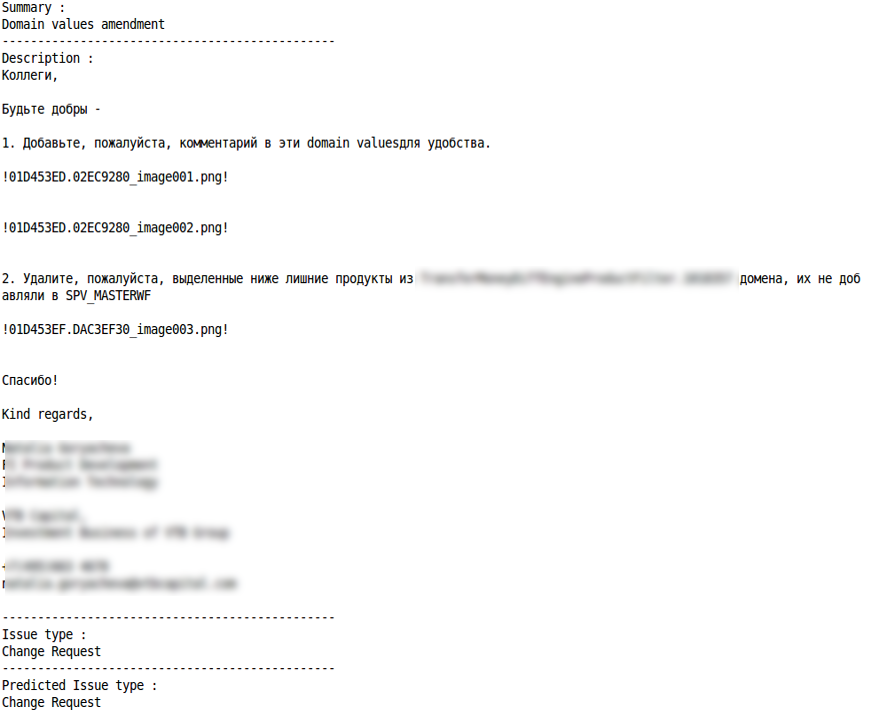 Clasificación errónea
Clasificación errónea Solicitud de acciónClasificación correcta
Solicitud de acciónClasificación correcta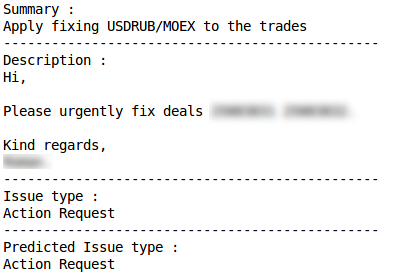 Clasificación erróneaProblema de producciónClasificación correcta
Clasificación erróneaProblema de producciónClasificación correcta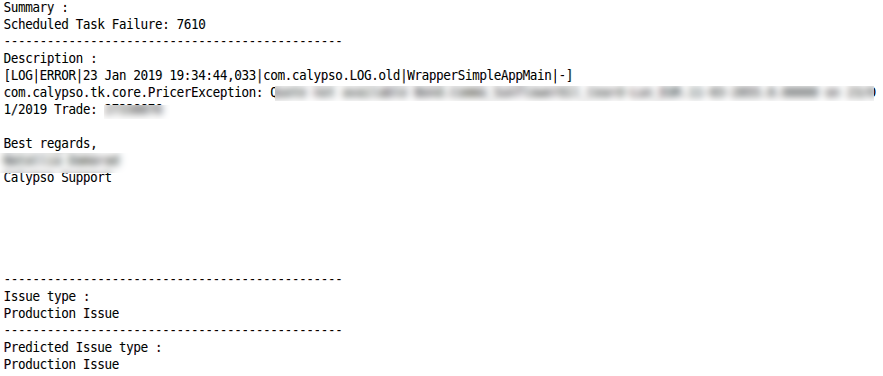 Clasificación errónea
Clasificación errónea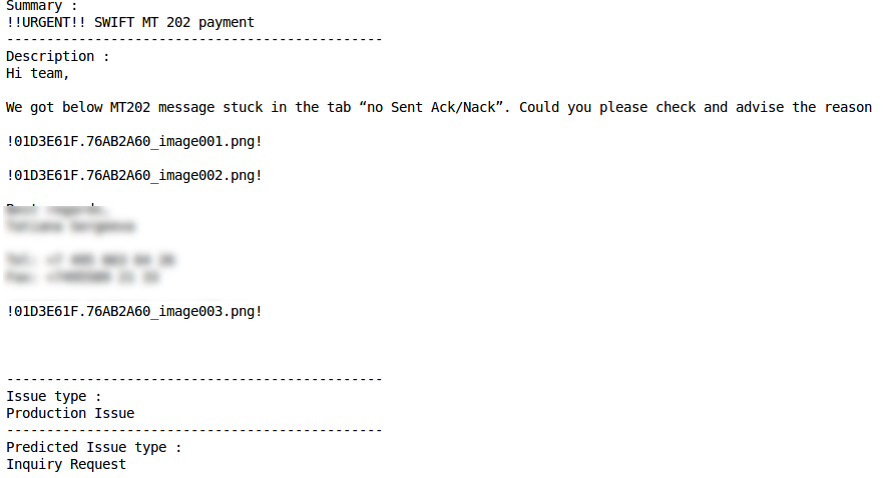
El segundo prototipo también mostró buenos resultados: en aproximadamente el 75% de los casos, ML determina correctamente el tipo de consulta (métrica de precisión). La oportunidad de mejorar el indicador está asociada con la mejora de la calidad de los datos de origen, en particular, eliminando casos en los que se asignaron las mismas consultas a diferentes tipos.
Para resumir
Cada uno de los prototipos implementados ha demostrado su efectividad, y ahora se ha lanzado una combinación de dos prototipos desarrollados en la producción piloto en VTB Capital. Un pequeño experimento con ML en menos de un mes y a un costo mínimo permitió a la empresa familiarizarse con las herramientas de aprendizaje automático y resolver un importante problema de aplicación para clasificar las solicitudes de los usuarios.
La experiencia adquirida por los desarrolladores de EPAM y VTB Capital, además de utilizar algoritmos implementados para procesar las solicitudes de los usuarios para un mayor desarrollo, se puede reutilizar para resolver una variedad de problemas relacionados con el procesamiento continuo de información. El movimiento en pequeñas iteraciones y la cobertura de un proceso tras otro le permite dominar y combinar gradualmente diversas herramientas y tecnologías, eligiendo opciones bien probadas y abandonando las menos efectivas. Esto es interesante para el equipo de TI y al mismo tiempo ayuda a obtener resultados importantes para la administración y los negocios.