 Parte 1. Acerca de la CPUParte 3. Acerca del almacenamiento
Parte 1. Acerca de la CPUParte 3. Acerca del almacenamientoEn este artículo, hablaremos sobre los contadores de rendimiento de RAM en vSphere.
Parece que la memoria es cada vez más inequívoca que con el procesador: si hay problemas de rendimiento en la VM, es difícil no notarlos. Pero si aparecen, tratar con ellos es mucho más difícil. Pero lo primero es lo primero.
Poco de teoría
La RAM de las máquinas virtuales se toma de la memoria del servidor en el que se ejecutan las máquinas virtuales. Esto es bastante obvio :). Si la RAM del servidor no es suficiente para todos, ESXi comienza a aplicar técnicas de recuperación de memoria. De lo contrario, los sistemas operativos VM se bloquearían con errores de acceso a RAM.
Qué técnicas usar ESXi decide según la carga de RAM:
FuenteminFree es la RAM necesaria para que funcione el hipervisor.
Antes de ESXi 4.1 inclusive, minFree se reparaba de manera predeterminada: 6% de la RAM del servidor (el porcentaje se podía cambiar a través de la opción Mem.MinFreePct en ESXi). En versiones posteriores, debido al aumento en los volúmenes de memoria en los servidores minFree, comenzó a calcularse en función del tamaño de la memoria del host y no como un valor de porcentaje fijo.
El valor minFree (predeterminado) se calcula de la siguiente manera:
FuentePor ejemplo, para un servidor con 128 GB de RAM, el valor MinFree sería:
MinFree = 245.76 + 327.68 + 327.68 + 1024 = 1925.12 MB = 1.88 GB
El valor real puede diferir en un par de cientos de MB, depende del servidor y la RAM.
Típicamente, para rodales productivos, solo Alto puede considerarse normal. Para bancos de pruebas y desarrollo, pueden ser aceptables condiciones claras / suaves. Si queda menos del 64% de MinFree de RAM en el host, entonces las máquinas virtuales que se ejecutan en él definitivamente experimentarán problemas de rendimiento.
En cada estado, se aplican ciertas técnicas de recuperación de memoria comenzando con TPS, que prácticamente no afecta el rendimiento de la VM, y termina con Swapping. Te contaré más sobre ellos.
Uso compartido de página transparente (TPS). TPS es, en términos generales, deduplicación de las páginas de RAM de máquinas virtuales en un servidor.
ESXi busca páginas idénticas de RAM de máquina virtual, contando y comparando la suma de hash de páginas, y elimina páginas duplicadas, reemplazándolas con enlaces a la misma página en la memoria física del servidor. Como resultado, se reduce el consumo de memoria física y se puede volver a suscribir la memoria con poca o ninguna pérdida de rendimiento.
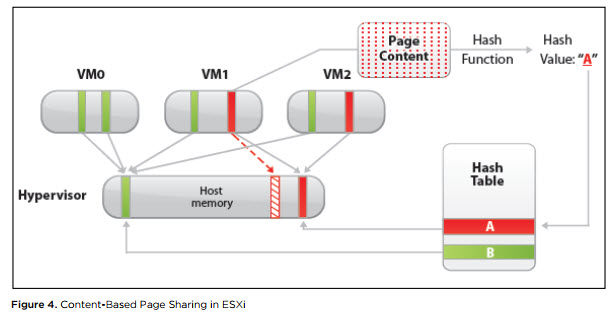 Fuente
FuenteEste mecanismo funciona solo para páginas de 4 kB (páginas pequeñas). Páginas de 2 MB de tamaño (páginas grandes) que el hipervisor ni siquiera intenta deduplicar: la posibilidad de encontrar páginas idénticas de este tamaño no es grande.
Por defecto, ESXi asigna memoria a páginas grandes. La división de páginas grandes en pequeñas comienza cuando se alcanza el umbral del estado Alto y se fuerza cuando se alcanza el estado Borrar (consulte la tabla de estados del hipervisor).
Si desea que TPS comience a funcionar sin esperar a que se llene la RAM del host, en Advanced Options ESXi debe establecer el valor
"Mem.AllocGuestLargePage" en 0 (el valor predeterminado es 1). Luego, se deshabilitará la asignación de páginas grandes de memoria para máquinas virtuales.
Desde diciembre de 2014, en todas las versiones de ESXi, el TPS entre máquinas virtuales se ha deshabilitado de forma predeterminada, ya que se ha encontrado una vulnerabilidad que teóricamente permite acceder a la RAM de otra máquina virtual desde una máquina virtual. Detalles aquí Información sobre la implementación práctica de la explotación de la vulnerabilidad TPS que no he conocido.
La política de TPS se controla a través de la opción avanzada
"Mem.ShareForceSalting" en ESXi:
0: TPS entre máquinas virtuales. TPS funciona para páginas de diferentes máquinas virtuales;
1 - TPS para máquinas virtuales con el mismo valor "sched.mem.pshare.salt" en VMX;
2 (predeterminado): Intra-VM TPS. TPS funciona para páginas dentro de una VM.
Definitivamente tiene sentido apagar páginas grandes y habilitar Inter-VM TPS en bancos de prueba. También se puede usar para stands con una gran cantidad de máquinas virtuales del mismo tipo. Por ejemplo, en stands con VDI, el ahorro de memoria física puede alcanzar decenas de por ciento.
Globos de memoria. El globo ya no es una técnica tan inofensiva y transparente para el sistema operativo VM como TPS. Pero con el uso adecuado con el globo puede vivir e incluso trabajar.
Junto con Vmware Tools, se instala un controlador especial en la VM, llamado Balloon Driver (también conocido como vmmemctl). Cuando el hipervisor comienza a quedarse sin memoria física y entra en el estado suave, ESXi le pide a la máquina virtual que devuelva la RAM no utilizada a través de este controlador de globo. El controlador, a su vez, funciona a nivel del sistema operativo y solicita memoria libre de él. El hipervisor ve qué páginas de memoria física ha tomado Balloon Driver, toma la memoria de la máquina virtual y la devuelve al host. No hay problemas con el funcionamiento del sistema operativo, ya que a nivel del sistema operativo la memoria está ocupada por Balloon Driver. De forma predeterminada, Balloon Driver puede ocupar hasta el 65% de la memoria de VM.
Si las herramientas de VMware no están instaladas en la máquina virtual o la función de globo está desactivada (no lo recomiendo, pero hay
KB :), el hipervisor cambia inmediatamente a métodos más estrictos para eliminar la memoria. Conclusión: asegúrese de que las herramientas de VMware en la VM lo sean.
 La operación de Balloon Driver se puede verificar desde el sistema operativo a través de VMware Tools
La operación de Balloon Driver se puede verificar desde el sistema operativo a través de VMware Tools .
Compresión de la memoria Esta técnica se usa cuando ESXi llega a Hard. Como su nombre indica, ESXi está tratando de comprimir 4 KB de páginas RAM a 2 KB y, por lo tanto, liberar algo de espacio en la memoria física del servidor. Esta técnica aumenta significativamente el tiempo de acceso a los contenidos de las páginas de la memoria RAM de la máquina virtual, ya que la página debe limpiarse primero. A veces, no todas las páginas se pueden comprimir y el proceso en sí lleva algo de tiempo. Por lo tanto, esta técnica no es muy efectiva en la práctica.
Intercambio de memoria. Después de una breve fase, Memory Compression ESXi casi inevitablemente (si las máquinas virtuales no fueron a otros hosts o se cerraron) va a Swapping. Y si queda muy poca memoria (estado bajo), el hipervisor también deja de asignar páginas de memoria de VM, lo que puede causar problemas en las máquinas virtuales invitadas.
Así es como funciona el intercambio. Cuando enciende la máquina virtual, se crea un archivo con la extensión .vswp. En tamaño, es igual a la RAM no reservada de la VM: esta es la diferencia entre la memoria configurada y reservada. Cuando se trabaja con Swapping, ESXi descarga las páginas de memoria de la máquina virtual en este archivo y comienza a trabajar con él en lugar de la memoria física del servidor. Por supuesto, tal memoria "RAM" es varios órdenes de magnitud más lenta que la memoria real, incluso si .vswp está en almacenamiento rápido.
A diferencia del globo, cuando las páginas no utilizadas se seleccionan de una VM, las páginas que el sistema operativo o las aplicaciones usan activamente dentro de la VM pueden ir al disco durante el intercambio. Como resultado, el rendimiento de la VM disminuye hasta que se bloquea. VM funciona formalmente y al menos se puede desactivar correctamente desde el sistema operativo. Si vas a ser paciente;)
Si las máquinas virtuales se han cambiado, esta es una situación anormal que es mejor evitar si es posible.
Contadores básicos de rendimiento de memoria de máquina virtual
Entonces llegamos a lo principal. Para monitorear el estado de la memoria en la VM, están disponibles los siguientes contadores:
Activo : muestra la cantidad de RAM (Kbytes) a la que la VM obtuvo acceso en el período de medición anterior.
El uso es el mismo que Activo, pero como un porcentaje de la memoria de VM configurada. Se calcula usando la siguiente fórmula: activo ÷ tamaño de memoria configurado de máquina virtual.
High Usage y Active, respectivamente, no siempre son indicativos de problemas de rendimiento de VM. Si una VM usa agresivamente memoria (al menos tiene acceso a ella), esto no significa que no hay suficiente memoria. Más bien, esta es una ocasión para ver lo que está sucediendo en el sistema operativo.
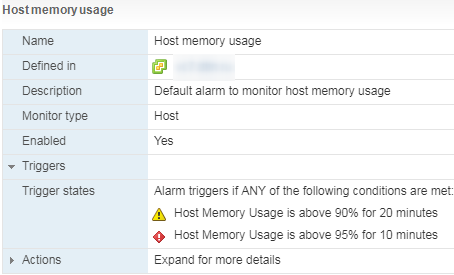
Hay una alarma estándar sobre el uso de memoria para máquinas virtuales:
 Compartido
Compartido : la cantidad de RAM en una VM deduplicada usando TPS (dentro de una VM o entre VM).
Concedido : la cantidad de memoria física del host (Kbytes) que se le dio a la VM. Incluye Compartido.
Consumido (concedido - compartido): la cantidad de memoria física (Kbytes) que la VM consume del host. No incluye Compartido.
Si parte de la memoria de la VM no se asigna desde la memoria física del host, sino desde el archivo de intercambio o la memoria se tomó de la VM a través del controlador de globo, esta cantidad no se tiene en cuenta en Granted and Consumed.
Los valores altos de Concedido y Consumido son perfectamente normales. El sistema operativo elimina gradualmente la memoria del hipervisor y no devuelve. Con el tiempo, con una VM que trabaja activamente, los valores de estos contadores se acercan a la cantidad de memoria configurada y permanecen allí.
Cero : la cantidad de RAM en la VM (Kbytes), que contiene ceros. Dicha memoria se considera un hipervisor gratuito y se puede dar a otras máquinas virtuales. Después de que el SO huésped lo recibió, escribió algo en la memoria nula, va a Consumed y no regresa.
Gastos generales reservados : la cantidad de RAM en la VM (Kbytes) reservada por el hipervisor para que la VM funcione. Esta es una cantidad pequeña, pero debe estar disponible en el host, de lo contrario, la VM no se iniciará.
Globo : la cantidad de RAM (KB) incautada de la VM utilizando el controlador de globo.
Comprimido : la cantidad de RAM (KB) que se pudo comprimir.
Intercambiado : la cantidad de RAM (Kbytes), que por falta de memoria física en el servidor se movió al disco.
Los contadores de globo y otras técnicas de recuperación de memoria son cero.
Así es como se ve el gráfico con los contadores de memoria de una VM que funciona normalmente con 150 GB de RAM.
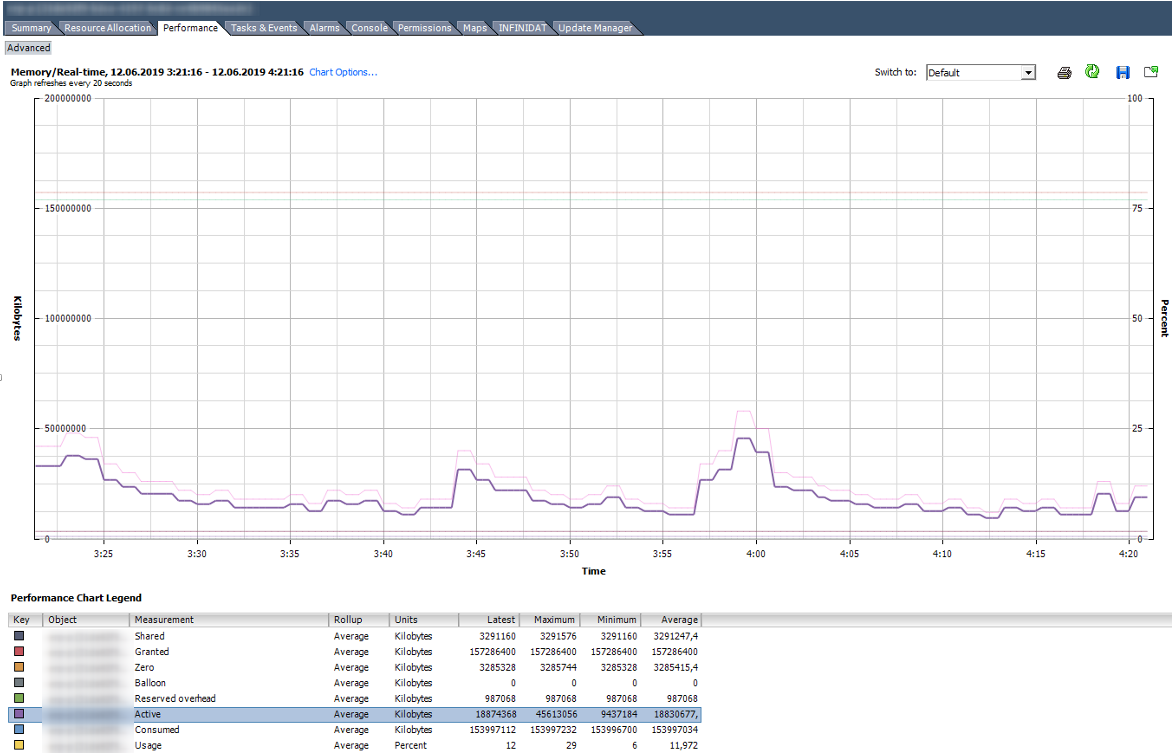
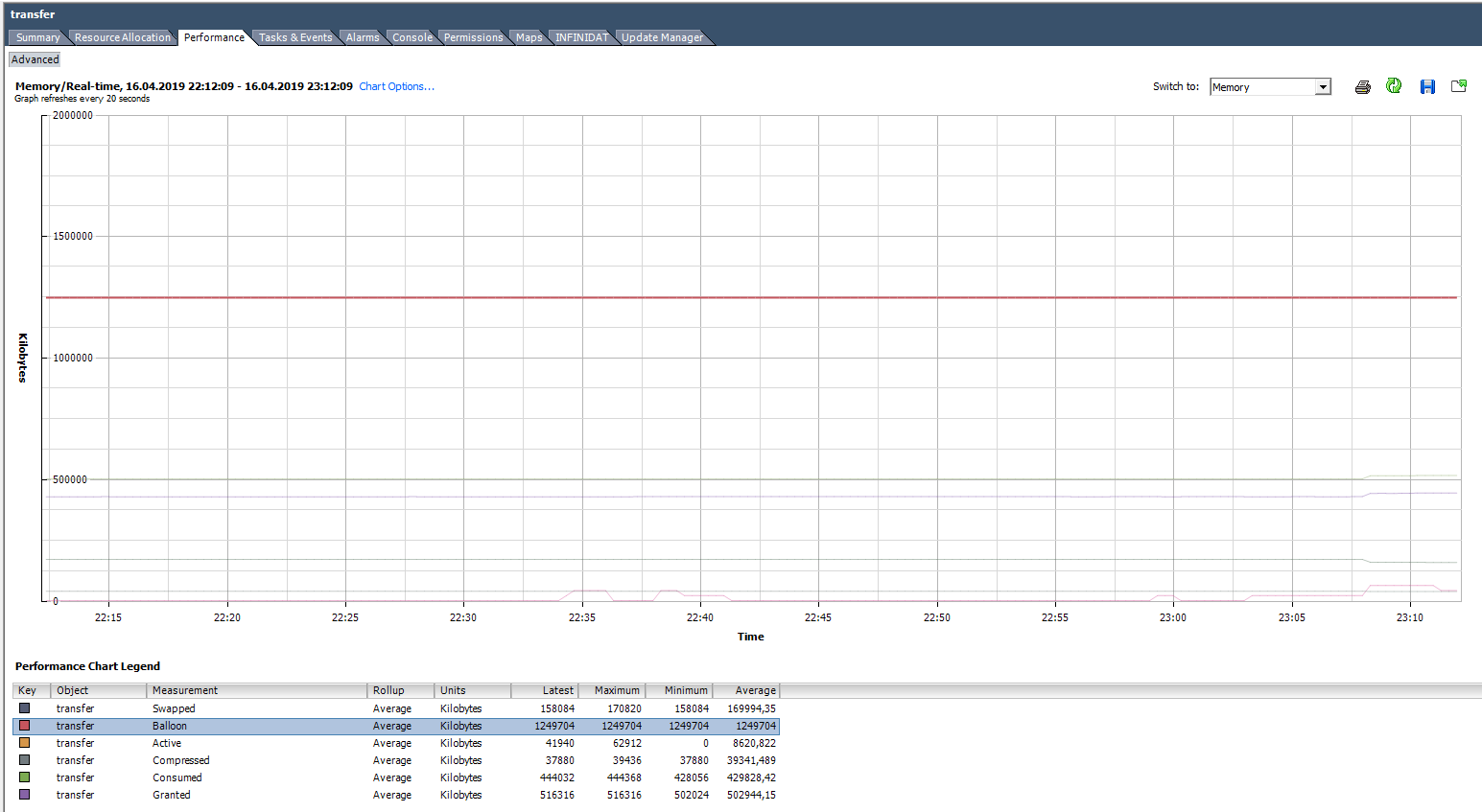
En el gráfico a continuación, la VM tiene problemas obvios. El gráfico muestra que para esta VM se utilizaron todas las técnicas descritas para trabajar con RAM. El globo para esta VM es mucho más grande que Consumido. De hecho, la VM está más probablemente muerta que viva.
ESXTOP
Al igual que con la CPU, si desea evaluar rápidamente la situación en el host, así como su dinámica con un intervalo de hasta 2 segundos, vale la pena usar ESXTOP.
La pantalla ESXTOP Memory se llama con la tecla "m" y tiene este aspecto (campos B, D, H, J, K, L, O seleccionados):

Los siguientes parámetros nos serán interesantes:
Promedio de exceso de memoria: el valor promedio de una suscripción excesiva de memoria en un host durante 1, 5 y 15 minutos. Si está por encima de cero, esta es una ocasión para ver qué sucede, pero no siempre es un indicador de la presencia de problemas.
En las líneas
PMEM / MB y
VMKMEM / MB : información sobre la memoria física del servidor y la memoria disponible para VMkernel. Desde lo interesante aquí puede ver el valor minfree (en MB), el estado del host desde la memoria (en nuestro caso, alto).
En la línea
NUMA / MB, puede ver la distribución de RAM por NUMA-nodos (sockets). En este ejemplo, la distribución es desigual, lo que en principio no es muy bueno.
El siguiente es un resumen de las estadísticas del servidor para las técnicas de recuperación de memoria:
PSHARE / MB es estadísticas TPS;
SWAP / MB : estadísticas sobre el uso de Swap;
ZIP / MB : estadísticas de compresión de páginas de memoria;
MEMCTL / MB : estadísticas de uso del controlador de globo.
Para máquinas virtuales individuales, podemos estar interesados en la siguiente información. Escondí los nombres de las máquinas virtuales para no avergonzar a la audiencia :). Si la métrica ESXTOP es la misma que el contador en vSphere, cito el contador correspondiente.
MEMSZ es la cantidad de memoria configurada en la VM (MB).
MEMSZ = GRANT + MCTLSZ + SWCUR + sin tocar.
CONCESIÓN - Concedida en MB.
TCHD : activo en MB.
MCTL? - está instalado en VM Balloon Driver.
MCTLSZ - Globo en MB.
MCTLGT es la cantidad de RAM (MB) que ESXi desea eliminar de la VM a través del controlador de globo (Destino de Memctl).
MCTLMAX : la cantidad máxima de RAM (MB) que ESXi puede eliminar de la VM a través del controlador de globo.
SWCUR : la cantidad actual de RAM (MB) dada a la VM desde el archivo de intercambio.
SWGT : la cantidad de RAM (MB) que ESXi quiere dar a las máquinas virtuales desde un archivo de intercambio (Swap Target).
También a través de ESXTOP puede ver información más detallada sobre la topología de VM NUMA. Para hacer esto, seleccione los campos D, G:
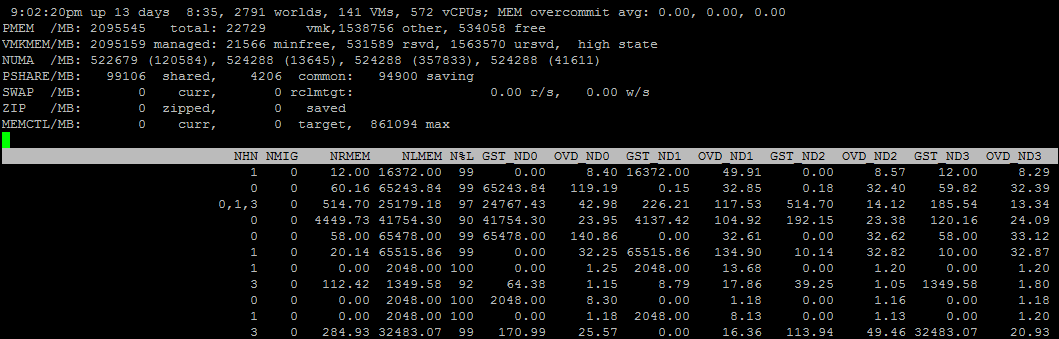 NHN
NHN : nodos NUMA en los que se encuentra la VM. Aquí puede ver inmediatamente una amplia vm que no cabe en un nodo NUMA.
NRMEM : cuántos megabytes de memoria ocupa la VM del nodo NUMA remoto.
NLMEM : cuántos megabytes de memoria ocupa la máquina virtual del nodo NUMA local.
N% L : porcentaje de memoria de VM en el nodo NUMA local (si es inferior al 80%, pueden producirse problemas de rendimiento).
Memoria en el hipervisor.
Si los contadores de CPU en el hipervisor generalmente no son de especial interés, entonces la situación es lo contrario con la memoria. Un uso elevado de memoria en la VM no siempre indica un problema de rendimiento, pero un uso elevado de memoria en el hipervisor solo inicia al técnico de administración de memoria y causa problemas con el rendimiento de la VM. Las alarmas de uso de la memoria del host deben monitorearse y las máquinas virtuales no deben ingresar a Swap.
Unswap
Si la VM entró en Swap, su rendimiento se reduce considerablemente. Los rastros de globo y compresión desaparecen rápidamente después de la aparición de RAM libre en el host, pero la máquina virtual no tiene prisa por volver de Swap a la RAM del servidor.
Antes de ESXi 6.0, la única forma confiable y rápida de sacar las máquinas virtuales de Swap era reiniciando (más precisamente, apagando / encendiendo el contenedor). Comenzando con ESXi 6.0, apareció una forma no tan oficial pero confiable y funcional de sacar las máquinas virtuales de Swap. En una de las conferencias, logré hablar con uno de los ingenieros de VMware responsables del Programador de CPU. Confirmó que el método funciona bastante y es seguro. En nuestra experiencia, tampoco se notaron problemas con él.
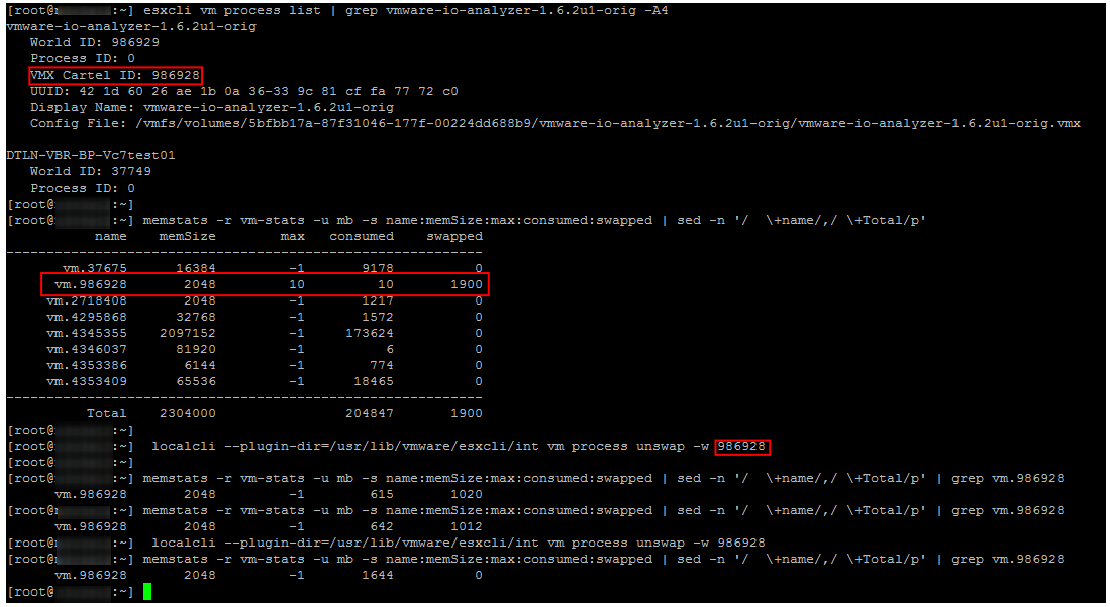
Duncan Epping
describió los comandos reales para generar máquinas virtuales desde Swap. No repetiré la descripción detallada, solo daré un ejemplo de su uso. Como se puede ver en la captura de pantalla, algún tiempo después de la ejecución de los comandos de intercambio especificados en la VM desaparece.
Consejos para administrar RAM en ESXi
En conclusión, le daré algunos consejos para ayudarlo a evitar problemas con el rendimiento de la VM debido a la RAM:
- Evite la suscripción excesiva en RAM en clústeres productivos. Siempre es aconsejable tener ~ 20-30% de memoria libre en el clúster, de modo que DRS (y el administrador) tengan espacio para maniobrar, y las máquinas virtuales no vayan a Swap durante la migración. Además, no olvide el margen de tolerancia a fallas. Es desagradable cuando, cuando falla un servidor y la VM se reinicia usando HA, algunas de las máquinas también van a Swap.
- En infraestructuras altamente consolidadas, intente NO crear máquinas virtuales con más de la mitad de la memoria del host. Esto, nuevamente, ayudará a DRS a distribuir máquinas virtuales entre los servidores del clúster sin ningún problema. Esta regla, por supuesto, no es universal :).
- Tenga cuidado con la alarma de uso de memoria del host.
- No olvide poner VMware Tools en la VM y no desactive el globo.
- Considere habilitar TPS entre máquinas virtuales y deshabilitar páginas grandes en VDI y entornos de prueba.
- Si la VM está experimentando problemas de rendimiento, verifique si está usando memoria de un nodo NUMA remoto.
- ¡Obtenga máquinas virtuales de Swap lo más rápido posible! Entre otras cosas, si la VM está en Swap, por razones obvias, el sistema de almacenamiento sufre.
Eso es todo por RAM. A continuación hay artículos relacionados para aquellos que desean profundizar en los detalles.
El próximo artículo estará dedicado a la historia.