Artículos sobre visión por computadora, interpretabilidad, PNL: visitamos la conferencia AISTATS en Japón y queremos compartir una visión general de los artículos. Esta es una conferencia importante sobre estadísticas y aprendizaje automático, y este año se llevará a cabo en Okinawa, una isla cerca de Taiwán. En esta publicación, Yulia Antokhina ( Yulia_chan ) preparó una descripción de los artículos brillantes de la sección principal, en la siguiente junto con Anna Papeta hablará sobre los informes de los profesores invitados y los estudios teóricos. También contaremos un poco sobre cómo se llevó a cabo la conferencia y sobre Japón "no japonés". Defensa contra ataques adversos de Whitebox a través de la discreción aleatoria
Defensa contra ataques adversos de Whitebox a través de la discreción aleatoriaYuchen Zhang (Microsoft); Percy Liang (Universidad de Stanford)
→
Artículo→
CódigoComencemos con un artículo sobre la protección contra ataques adversos en la visión por computadora. Estos son ataques dirigidos contra modelos, cuando el objetivo del ataque es hacer que el modelo cometa un error, hasta un resultado predeterminado. Los algoritmos de visión por computadora pueden confundirse incluso con cambios menores en la imagen original de una persona. La tarea es relevante, por ejemplo, para la visión artificial, que en buenas condiciones reconoce las señales de tráfico más rápido que una persona, pero funciona mucho peor durante los ataques.
Ataque Adversario claramente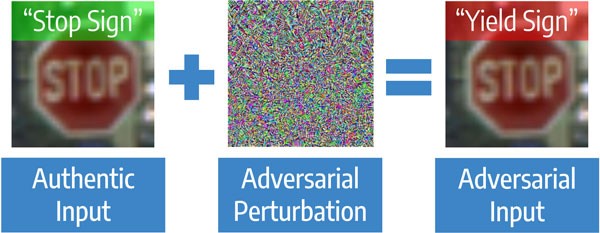
Los ataques son Blackbox, cuando el atacante no sabe nada sobre el algoritmo, y Whitebox es la situación inversa. Hay dos enfoques principales para proteger los modelos. El primer enfoque es entrenar al modelo en imágenes regulares y "atacadas"; se llama entrenamiento de confrontación. Este enfoque funciona bien en imágenes pequeñas como MNIST, pero hay artículos que muestran que no funciona bien en imágenes grandes como ImageNet. El segundo tipo de protección no requiere reentrenamiento del modelo. Es suficiente procesar previamente la imagen antes de enviarla al modelo. Ejemplos de conversiones: compresión JPEG, cambio de tamaño. Estos métodos requieren menos cómputo, pero ahora solo funcionan contra los ataques de Blackbox, ya que si se conoce la conversión, se puede aplicar lo contrario.
MétodoEn el artículo, los autores proponen un método que no requiere sobreentrenamiento del modelo y funciona para los ataques de Whitebox. El objetivo es reducir la distancia Kullback - Leibner entre ejemplos ordinarios y "estropeados" utilizando una transformación aleatoria. Resulta que es suficiente agregar ruido aleatorio y luego muestrear aleatoriamente los colores. Es decir, una calidad de imagen "deteriorada" se alimenta a la entrada del algoritmo, pero sigue siendo suficiente para que el algoritmo funcione. Y debido al azar, existe la posibilidad de resistir los ataques de Whitebox.
A la izquierda está la imagen original, en el centro hay un ejemplo de agrupación de colores de píxeles en el espacio Lab, a la derecha hay una imagen en varios colores (por ejemplo, en lugar de 40 tonos de azul - uno) Resultados
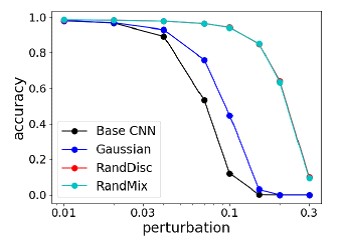
ResultadosEste método se comparó con los ataques más fuertes en la Competencia de Ataques Adversarios y Defensas NIPS 2017, y muestra en promedio la mejor calidad y no se vuelve a entrenar bajo el "atacante".
Comparación de los métodos de defensa más fuertes contra los ataques más fuertes en la competencia NIPS Comparación de la precisión de los métodos en MNIST con diferentes cambios de imagen
Comparación de la precisión de los métodos en MNIST con diferentes cambios de imagen
 Atenuar el sesgo en los vectores de Word
Atenuar el sesgo en los vectores de WordSunipa Dev (Universidad de Utah); Jeff Phillips (Universidad de Utah)
→
ArtículoLa charla “de moda” fue sobre Vectores de palabras imparciales. En este caso, sesgo significa sesgos por género o nacionalidad en las representaciones de palabras. Cualquier regulador puede oponerse a tal "discriminación" y, por lo tanto, los científicos de la Universidad de Utah decidieron estudiar la posibilidad de "igualación de derechos" para la PNL. De hecho, ¿por qué un hombre no puede ser "glamoroso" y una mujer un "científico de datos"?
Original - el resultado que se está obteniendo ahora, el resto - los resultados del algoritmo imparcial

El artículo analiza un método para encontrar ese sesgo. Decidieron que el género y la nacionalidad están bien caracterizados por los nombres. Entonces, si encuentra un desplazamiento por nombre y lo resta, entonces, probablemente, puede deshacerse del sesgo del algoritmo.
Un ejemplo de palabras más "masculinas" y "femeninas":
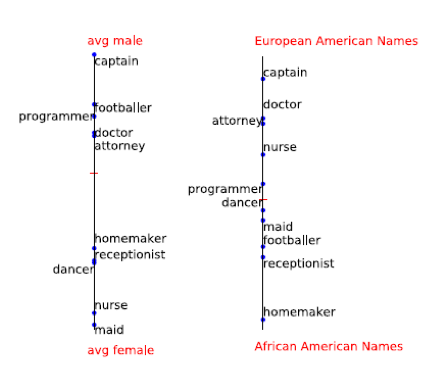 Nombres para encontrar compensaciones de género:
Nombres para encontrar compensaciones de género:
Curiosamente, un método tan simple funciona. Los autores entrenaron un guante imparcial y lo presentaron en Git.
¿Qué te hizo hacer esto? Comprender las decisiones de recuadro negro con suficientes subconjuntos de entradaBrandon Carter (MIT CSAIL); Jonas Mueller (Servicios web de Amazon); Siddhartha Jain (MIT CSAIL); David Gifford (MIT CSAIL)
→
Artículo→
Código una y
dos vecesEl siguiente artículo habla sobre el algoritmo Suficiente subconjunto de entrada. SIS son los subconjuntos mínimos de características en las que el modelo producirá un determinado resultado, incluso si se restablecen todas las demás características. Esta es otra forma de interpretar de alguna manera los resultados de modelos complejos. Funciona tanto en textos como en imágenes.
Algoritmo de búsqueda SIS en detalle: Ejemplo de aplicación en el texto con comentarios sobre cerveza:
Ejemplo de aplicación en el texto con comentarios sobre cerveza: Ejemplo de aplicación en MNIST:
Ejemplo de aplicación en MNIST: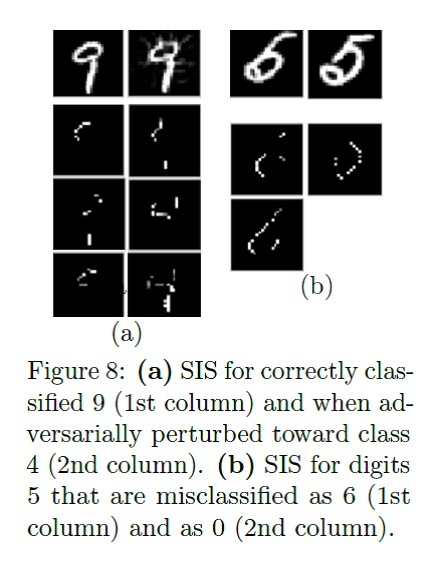 Comparación de los métodos de "interpretación" de la distancia Kullback - Leibler en relación con el resultado "ideal":
Comparación de los métodos de "interpretación" de la distancia Kullback - Leibler en relación con el resultado "ideal":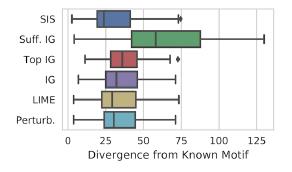
Las características se clasifican primero por impacto en el modelo, y luego se desglosan en subconjuntos disjuntos, comenzando por los más influyentes. Funciona por fuerza bruta, y en un conjunto de datos etiquetado, el resultado se interpreta mejor que LIME. Hay una implementación conveniente de búsqueda SIS de Google Research.
Minimización empírica de riesgos y descenso de gradiente estocástico para datos relacionalesVictor Veitch (Universidad de Columbia); Morgane Austern (Universidad de Columbia); Wenda Zhou (Universidad de Columbia); David Blei (Universidad de Columbia); Peter Orbanz (Universidad de Columbia)
→
Artículo→
CódigoEn la sección de optimización, hubo un informe sobre la minimización empírica de riesgos, donde los autores exploraron formas de aplicar el descenso de gradiente estocástico en los gráficos. Por ejemplo, al construir un modelo en datos de redes sociales, puede usar solo características fijas del perfil (el número de suscriptores), pero luego se pierde información sobre las conexiones entre los perfiles (a quién está suscrito). Además, el gráfico completo suele ser difícil de procesar; por ejemplo, no cabe en la memoria. Cuando esta situación se produce en datos tabulares, el modelo se puede ejecutar en submuestras. Y cómo elegir el análogo de la submuestra en el gráfico no estaba claro. Los autores demostraron teóricamente la posibilidad de utilizar subgrafías aleatorias como un análogo de submuestras, y esto resultó ser "No es una idea loca". Hay ejemplos reproducibles del artículo en Github, incluido el ejemplo de Wikipedia.
Las incrustaciones de categoría en los datos de "Wikipedia" teniendo en cuenta su estructura gráfica, los artículos seleccionados son los más cercanos al tema de los "físicos franceses":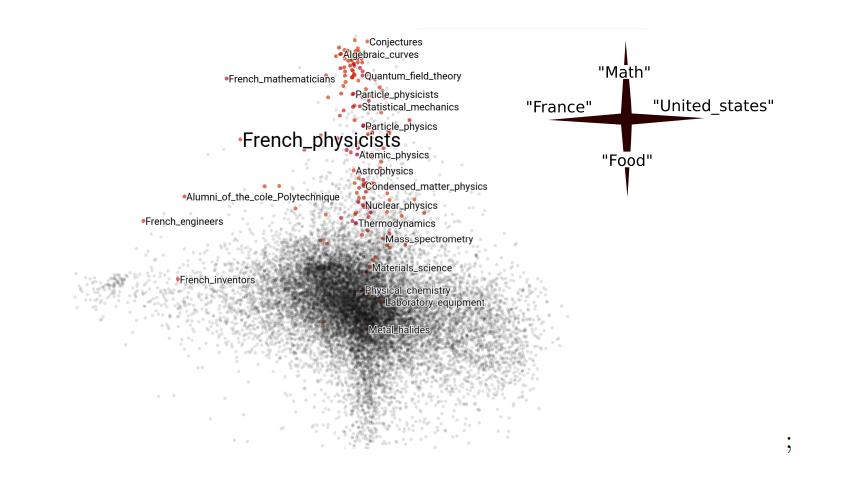
→
Ciencia de datos para datos en redLos gráficos de datos discretos fueron otro informe de revisión de Data Science para datos en red del orador invitado Poling Loh (Universidad de Wisconsin-Madison). La presentación cubrió los temas de inferencia estadística, asignación de recursos, algoritmos locales. En la inferencia estadística, por ejemplo, se trataba de cómo entender qué estructura tiene el gráfico para los datos sobre enfermedades infecciosas. Se propone utilizar estadísticas sobre el número de conexiones entre nodos infectados, y se prueba el teorema para la prueba estadística correspondiente.
En general, el informe es más interesante de observar, probablemente para aquellos que no están involucrados en modelos de gráficos, pero les gustaría probar y están interesados en cómo probar correctamente las hipótesis para los gráficos.
¿Cómo fue la conferencia?AISTATS 2019 es una conferencia de tres días en Okinawa. Esto es Japón, pero la cultura de Okinawa está más cerca de China. La principal calle comercial recuerda a un Miami tan pequeño, hay largos autos en las calles, música country, y uno se aleja un poco: una jungla con serpientes, manglares retorcidos por tifones. El sabor local es creado por la cultura de Ryukyu, un reino ubicado en Okinawa, pero que primero se convirtió en un vasallo y socio comercial de China, y luego fue capturado por los japoneses.
Y en Okinawa, al parecer, a menudo celebran bodas, porque hay muchos salones de bodas, y la conferencia se celebró en las instalaciones de Wedding Hall.
Más de 500 personas han reunido a científicos, autores de artículos, oyentes y oradores. En tres días puede tener tiempo para hablar con casi todos. Aunque la conferencia se celebró "en los confines del mundo", llegaron representantes de todo el mundo. A pesar de la amplia geografía, resultó que los intereses de todos nosotros son similares. Nos sorprendió, por ejemplo, que los científicos de Australia resuelvan los mismos problemas de Data Science utilizando los mismos métodos que nosotros en nuestro equipo. Pero, después de todo, vivimos en lados casi opuestos del planeta ... No había tantos participantes de la industria: Google, Amazon, MTS y varias otras compañías importantes.
Hubo representantes de empresas patrocinadoras japonesas, que en su mayoría observaban y escuchaban y, probablemente, buscaban a alguien, a pesar de que los "no japoneses" eran muy difíciles de trabajar en Japón.
Artículos enviados a la conferencia sobre los temas:
Todo lo demás está en nuestra próxima publicación. ¡No te lo pierdas!
Anuncio: