En un
artículo anterior, dije que es hora de que pasemos a los protocolos de transmisión. Pero después de comenzar a preparar una historia sobre ellos, me di cuenta de que yo mismo estoy nadando en un tema muy importante. Como ya se señaló, mi relación con Linux es bastante peculiar. En general, me di cuenta de que yo mismo no puedo crear desde cero una aplicación C ++ que satisfaga todos los principios de programación para Redd. Podrías pedirle a alguien que haga esto y luego usar la plantilla ya preparada, pero la serie de artículos está diseñada para enseñar a todos cómo desarrollarse bajo Redd desde cero. Por lo tanto, le pregunté a mi jefe (un gran especialista en Linux), y él me explicó en qué hacer clic. Luego pensé un poco en sus palabras y ahora considero necesario arreglar todo el conocimiento por escrito. Esto salvará a las personas como yo de pensamientos dolorosos: "Entonces ... Lo que hizo es comprensible, pero ¿cómo puedo repetir esto?" En general, cualquier persona que trabaje con Linux puede ejecutar las siguientes dos secciones en diagonal. Es poco probable que encuentre algo nuevo allí (encontrará más). Y por lo demás, ofrezco una opción de dos métodos de desarrollo que corresponden a los principios declarados de trabajar bajo Redd: bajos costos laborales para el desarrollo y depuración remota.

Todos los artículos del ciclo:
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd, y depuración utilizando la prueba de memoria como ejemplo
- Desarrollo del "firmware" más simple para FPGAs instalados en Redd. Parte 2. Código del programa
- Desarrollo de su propio núcleo para incrustar en un sistema de procesador basado en FPGA
Trabajar con herramientas de Visual Studio
Resulta que puede llevar a cabo el desarrollo para Linux remoto, sin tenerlo en su máquina local y sin instalar ninguna herramienta de software que no sea de Microsoft. Aquí se muestra cómo se coloca en Visual Studio (lo instalé en la versión 2019, pero parece que apareció en 2015)
docs.microsoft.com/ru-ru/cpp/linux/download-install-and-setup- the-linux-development-workload? view = vs-2019Y aquí está la
teoría del trabajo .
Bueno, allí puedes caminar por las pestañas, mucha teoría y todo en ruso.
Genial Intentemos utilizar los conocimientos adquiridos para acceder al chip FT2232H, a través del cual el procesador central Redd se conecta al FPGA. Es este canal en el futuro el que formará la base de nuestro trabajo de transmisión. Abra Visual Studio, seleccione "Crear proyecto". En los filtros, seleccione "Lenguaje - C ++", "Plataforma - Linux", "Tipo de proyecto - Consola". Mostraré dónde se encuentra esto para el tipo de proyecto. De lo que hemos filtrado, seleccionamos la "Aplicación de consola":
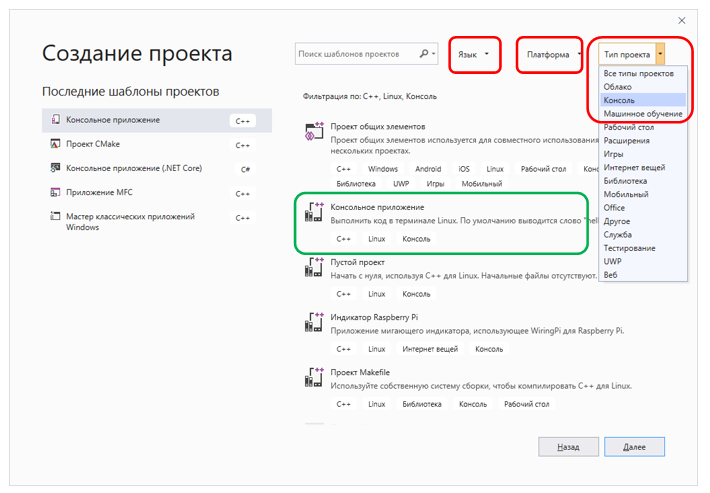
Llamémoslo, digamos, SimpleConsole. Hemos creado un código fuente tan espartano:
#include <cstdio> int main() { printf("hello from SimpleConsole!\n"); return 0; }
Intentemos recogerlo. Y se nos hace una pregunta muy interesante sobre el establecimiento de una conexión. Esta es una característica del desarrollo en Visual Studio. El entorno no contiene un compilador cruzado y ninguna biblioteca. Simplemente crea un directorio de origen en la máquina remota, después de lo cual para cada compilación copia los archivos actualizados y comienza la compilación allí. Es por eso que la conexión con la máquina remota no debe establecerse para comenzar, sino ya para el ensamblaje normal del proyecto.
Completamos los parámetros para el usuario de Redd, en nombre de quién se realizará el trabajo en el proyecto.
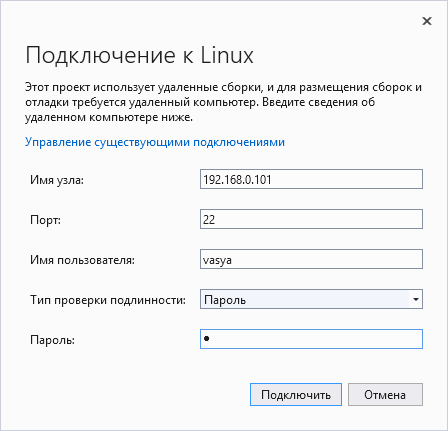
En todo caso, los parámetros se pueden cambiar aquí en este lugar secreto (no intente cambiar las propiedades del proyecto, no dará lugar a nada bueno):
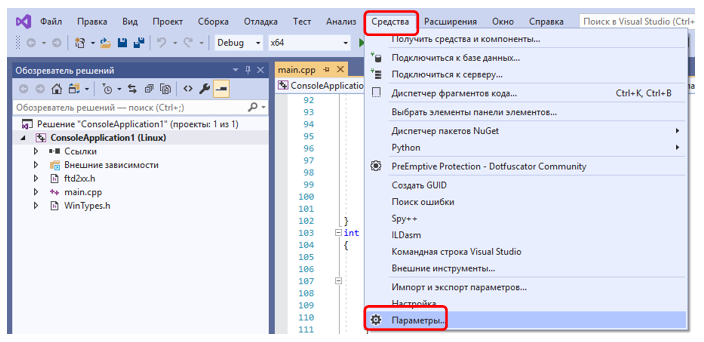
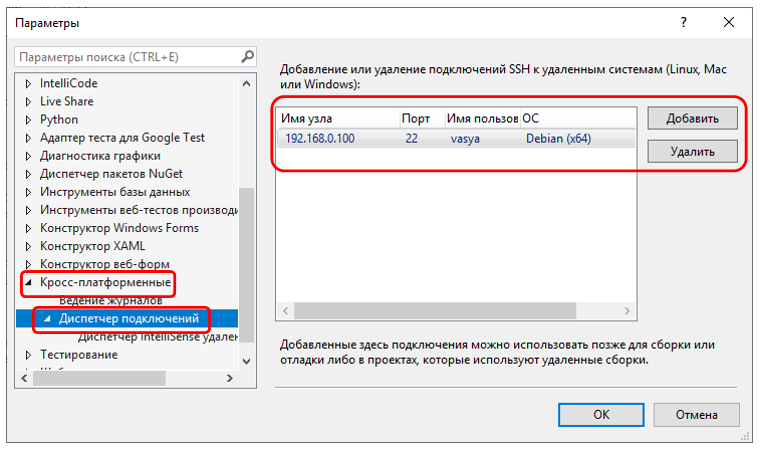
En realidad, puede poner un punto de interrupción en una sola línea y verificar que el proyecto comience y funcione. Pero esto es trivial. Por lo tanto, pasamos a una tarea más interesante: trabajar con FT2232. Surge la pregunta: ¿dónde obtener las bibliotecas necesarias? Para Linux, todo está incluido en el paquete del controlador. Existe el controlador en sí, las bibliotecas y ejemplos de aplicaciones para trabajar con ellos, e incluso una breve instrucción. En general, conducimos al motor de búsqueda:
FTDI D2XX drivers
Él mostrará dónde se pueden descargar. Es cierto, específicamente, todo fue malo para mí. Mi proveedor bloquea el sitio web de FTDI (así como reprap, 7zip e incluso osronline), refiriéndose a RosKomNadzor. ILV, en respuesta a declaraciones, envía cancelaciones de suscripciones, diciendo que no estamos bloqueando nada, sino que trata con el proveedor usted mismo. Donde solo en estas bajas no me ofrecieron recurrir, incluso a la policía. Son muy bajas. Los intentos de quejarse por la inacción de ILV terminan siendo enviados a ILV, de donde provienen las siguientes bajas. En general, puede resultar que su proveedor también bloquee el acceso. No se alarme, solo busque otras formas de descargar, pasando tiempo en esto. Y luego se sorprenden de que el desarrollo de los misiles se haya retrasado durante décadas ... Comencé a mantener correspondencia con ILV en noviembre pasado, ahora es junio, excepto por las bajas, ninguna acción ... Pero me distraje.
Puede encontrar cómo usar los controladores en el archivo Léame, en el paquete mismo. También puede encontrar el documento
AN_220 FTDI Drivers Installation Guide for Linux . Finalmente, puede encontrar en YouTube un video de la
Guía de instalación del controlador Linux d2xx de FTDI Chips. También hay un enlace a él en la página de descarga del controlador. En general, FTDI no escatimó en opciones para informar a los usuarios. En realidad, si recibió un paquete Redd listo, los controladores ya están instalados y configurados en él. Y nos interesarán los archivos de encabezado y ejemplos.
Insertemos un ejemplo slice
\ release \ examples \ EEPROM \ read . El comienzo de la función
principal , donde se abre el dispositivo y se toma su tipo. Esto será suficiente para asegurarse de que todo funcione. Odio las etiquetas, pero como arrastramos y soltamos rápidamente el código que dura 10 minutos, arrastraré la etiqueta que estaba en el ejemplo original para ahorrar tiempo. Resulta así:
#include <cstdio> #include <stdio.h> #include <stdlib.h> #include <sys/time.h> #include "ftd2xx.h" int main(int argc, char* argv[]) { printf("hello from ConsoleApplication1!\n"); FT_STATUS ftStatus; FT_HANDLE ftHandle0; int iport; static FT_PROGRAM_DATA Data; static FT_DEVICE ftDevice; DWORD libraryVersion = 0; int retCode = 0; ftStatus = FT_GetLibraryVersion(&libraryVersion); if (ftStatus == FT_OK) { printf("Library version = 0x%x\n", (unsigned int)libraryVersion); } else { printf("Error reading library version.\n"); return 1; } if (argc > 1) { sscanf(argv[1], "%d", &iport); } else { iport = 0; } printf("Opening port %d\n", iport); ftStatus = FT_Open(iport, &ftHandle0); if (ftStatus != FT_OK) { /* This can fail if the ftdi_sio driver is loaded use lsmod to check this and rmmod ftdi_sio to remove also rmmod usbserial */ printf("FT_Open(%d) failed\n", iport); return 1; } printf("FT_Open succeeded. Handle is %p\n", ftHandle0); ftStatus = FT_GetDeviceInfo(ftHandle0, &ftDevice, NULL, NULL, NULL, NULL); if (ftStatus != FT_OK) { printf("FT_GetDeviceType FAILED!\n"); retCode = 1; goto exit; } printf("FT_GetDeviceInfo succeeded. Device is type %d.\n", (int)ftDevice); exit: return 0; }
Tratando de recolectar, no voy a hacerlo. No hay suficientes archivos de encabezado.
1>main.cpp 1>D:\Work\SimpleConsole\SimpleConsole\main.cpp(5,20): error : ftd2xx.h: 1>D:\Work\SimpleConsole\SimpleConsole\main.cpp(5,20): error : #include "ftd2xx.h" 1>D:\Work\SimpleConsole\SimpleConsole\main.cpp(5,20): error : ^ 1>D:\Work\SimpleConsole\SimpleConsole\main.cpp(5,20): error : compilation terminated.
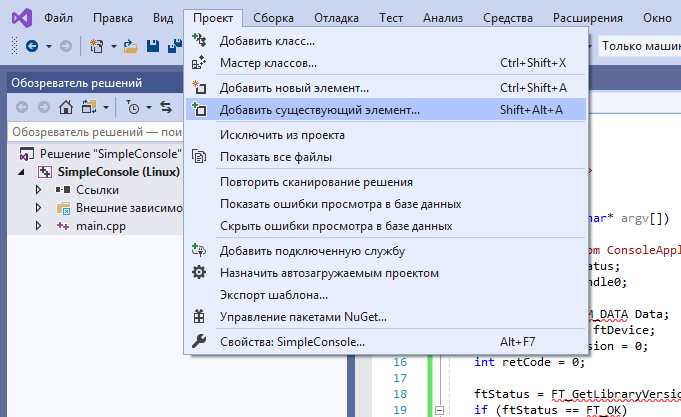
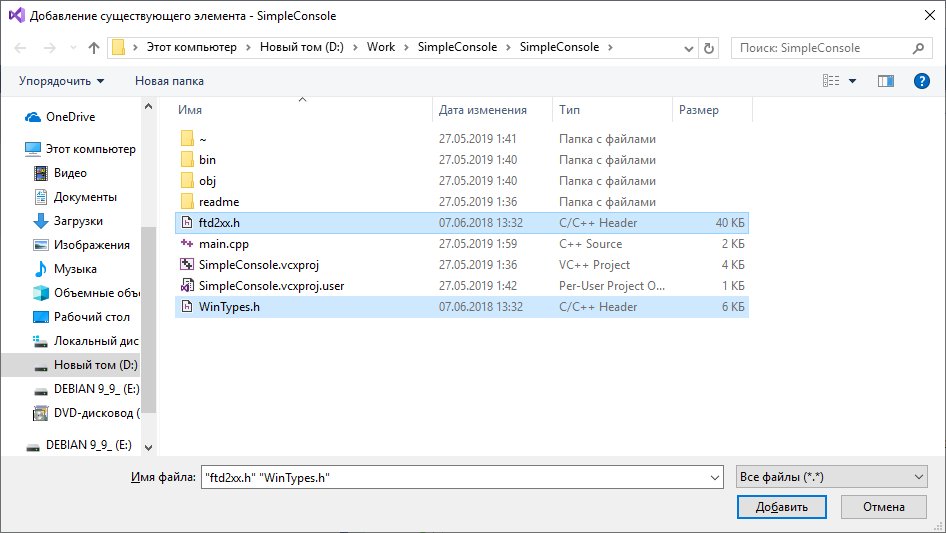
¡Pero los puse a continuación! Todo es simple A nivel local, están cerca, pero el montaje se realiza de forma remota. Para que Studio los transfiera a una máquina remota, debe agregarlos al proyecto. Además, desde el archivo
main.cpp agrego solo
ftd2xx.h , pero aún
extrae WinTypes.h en tránsito . Tienes que agregar ambos.
Ahora el enlazador jura.
1> 1>D:\Work\SimpleConsole\SimpleConsole\obj\x64\Debug\main.o : error : In function `main': 1>D:\Work\SimpleConsole\SimpleConsole\main.cpp(18): error : undefined reference to `FT_GetLibraryVersion' 1>D:\Work\SimpleConsole\SimpleConsole\main.cpp(37): error : undefined reference to `FT_Open' 1>D:\Work\SimpleConsole\SimpleConsole\main.cpp(55): error : undefined reference to `FT_GetDeviceInfo' 1>collect2 : error : ld returned 1 exit status
Está claro que no hay suficiente biblioteca. Al inspeccionar los
archivos MAKE del ejemplo, me di cuenta de que necesitaba agregar un par de parámetros a la configuración del enlazador:


Ahora el proyecto va con éxito. Ponemos un punto de interrupción en la última línea, intentamos correr. Vemos el siguiente texto:
hello from ConsoleApplication1! Library version = 0x10408 Opening port 0 FT_Open succeeded. Handle is 0x555555768540 FT_GetDeviceInfo succeeded. Device is type 10.
En general, no está mal. Algo abierto, incluso se encontró algún dispositivo. ¿Qué es el tipo 10? En el archivo de encabezado de FTDI encontramos:
enum { FT_DEVICE_BM, FT_DEVICE_AM, FT_DEVICE_100AX, FT_DEVICE_UNKNOWN, FT_DEVICE_2232C, FT_DEVICE_232R, FT_DEVICE_2232H, FT_DEVICE_4232H, FT_DEVICE_232H, FT_DEVICE_X_SERIES, FT_DEVICE_4222H_0, FT_DEVICE_4222H_1_2, FT_DEVICE_4222H_3, FT_DEVICE_4222_PROG, };
Contamos el dedo de arriba a abajo: delante de nosotros está FT4222H. Sí, Redd tiene muchos dispositivos FTDI. Ahora solo diré brevemente que necesitamos clasificar el número del dispositivo pasado a la función
FT_Open () , este número se pasa a la función
main () como argumento. Se puede establecer en las propiedades de depuración del proyecto.
Es útil colocar un plato con problemas típicos. En general, dice "configurar Redd" en todas partes sin detalles. El hecho es que los complejos se distribuirán de manera personalizada, por lo que todos los lectores no necesitan reglas de configuración. En caso de problemas, los administradores generalmente se encargarán de la configuración. Resulta que, por supuesto, puede describir las reglas de configuración, pero ocupará mucho espacio. Tiene sentido gastar energía en esto solo si alguien realmente lo necesita. Así que aquí me limitaré solo a indicar problemas, y cómo solucionarlos describiré si hay aplicaciones en los comentarios.
Genial Estamos listos para los logros utilizando exclusivamente herramientas de Microsoft. En general, esto puede ser suficiente, pero por si acaso, te contaré sobre una alternativa que mi jefe me enseñó.
Trabajando con Linux corriendo en una máquina virtual
La principal desventaja del método anterior es el ensamblaje remoto. Puede pensar en mil y una razones por las cuales el ensamblaje debe hacerse localmente, y solo el archivo binario terminado se transferirá a la máquina remota. Estos son todo tipo de restricciones paranoicas (aunque los archivos se transfieren utilizando un protocolo seguro y puede separar su almacenamiento de otros usuarios con políticas de seguridad), esto es solo el cuidado de que la unidad Redd no se desborde de todo tipo de bibliotecas, esta es también la renuencia a registrar cada archivo de encabezado, si hay miles de ellos ... Bueno, y mucho, mucho más. En general, la técnica de ensamblaje local puede ser útil, así que considérelo.
En primer lugar, colocamos el programa VirtualBox de Oracle en la máquina local. Si hay algún problema de licencia (lo uso de forma gratuita, como individuo, pero no sé exactamente qué está sucediendo con las entidades legales), seleccione una máquina física separada y coloque Linux allí. Cual? Es más fácil para mí, los entiendo a todos por igual. Quiero decir, casi no entiendo uno. Por lo tanto, el jefe me dijo que necesita usar Debian, instalé Debian. Puede seguir el mismo camino (use el principio "¿Por qué no?"). Al menos en el futuro confiaré en trabajar con él.
Al trabajar con Linux, debe cumplir con dos reglas que facilitan enormemente la vida:
- Si, en respuesta a un comando, nos dicen que no hay suficientes derechos, vale la pena repetirlo, agregando el hechizo mágico sudo al principio.
- Si en respuesta a un comando se nos dice que no existe, vale la pena intentar instalarlo lanzando el hechizo mágico apt-get install <cosa perdida> .
Entonces Acabamos de instalar el sistema operativo. Inmediatamente agregue soporte C ++ allí instalando el compilador g ++, así como el depurador gdb. Como? Entonces, usando la regla 2:
apt-get install g ++
apt-get install gdb¿No dio? Genial Repita usando la regla 1:
sudo apt-get install g ++
sudo apt-get install gdbAhora vamos a Internet, en el motor de búsqueda escribimos:
Eclipse IDEEncontramos un enlace a eclipse.org, donde las primeras opciones son para Java, encontramos y descargamos una opción para C / C ++:

Descargar y descomprimir, digamos, en casa.
En realidad, no se requiere instalación. Simplemente vaya al directorio donde acaba de desempaquetar todo y ejecute el archivo eclipse:
Estamos en un entorno de desarrollo. Bueno, si ya ha trabajado con microcontroladores e incluso núcleos de procesador para FPGA, entonces probablemente ya sepa qué es Eclipse. Entonces las cosas desconocidas están casi completas. Comenzamos a mirar alrededor en cosas más o menos familiares. Creamos el proyecto C ++. Debo decir de inmediato que hay dos formas. Uno conducirá al éxito, el segundo a un callejón sin salida. Por lo tanto, sigue cuidadosamente el camino que camino:
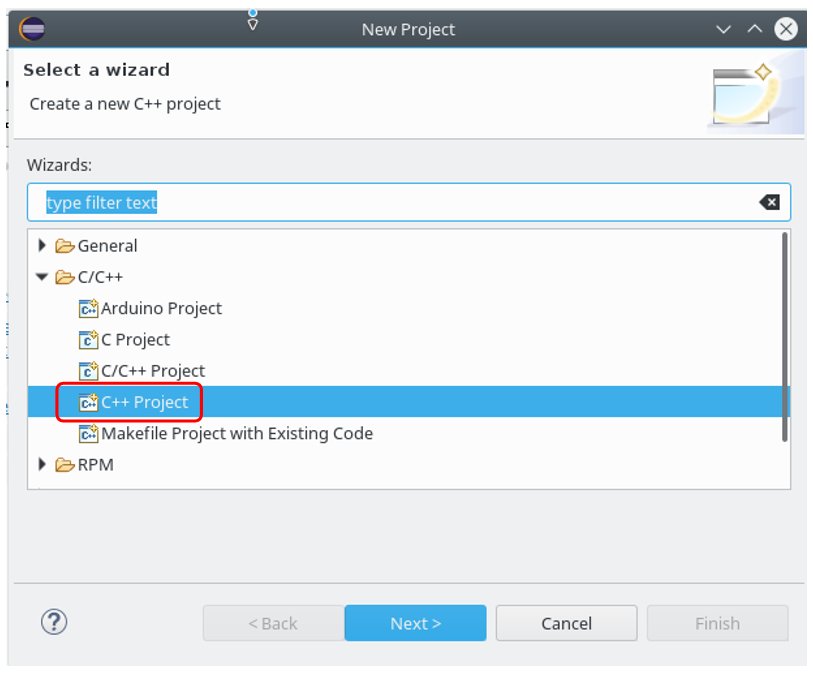
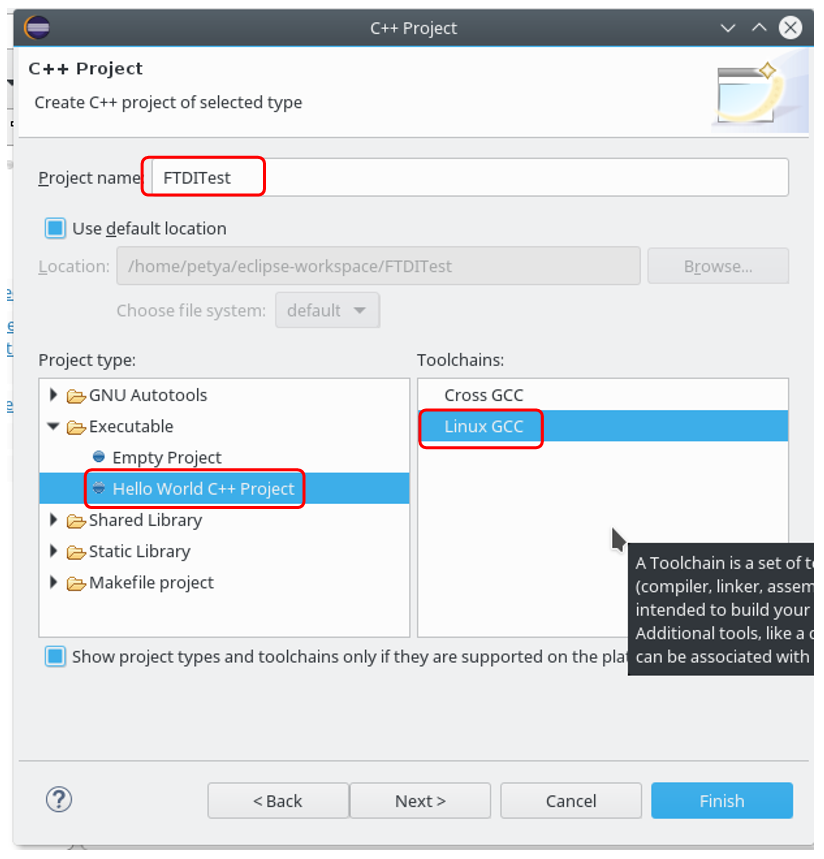
Hemos creado un proyecto que va bien. Para configurar su depuración, vaya a las propiedades de GDB:
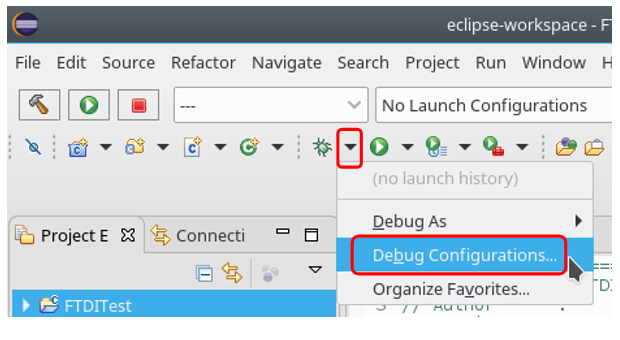
Cree una configuración de aplicación remota tipo C / C ++, en el grupo Conexión, haga clic en Nuevo:
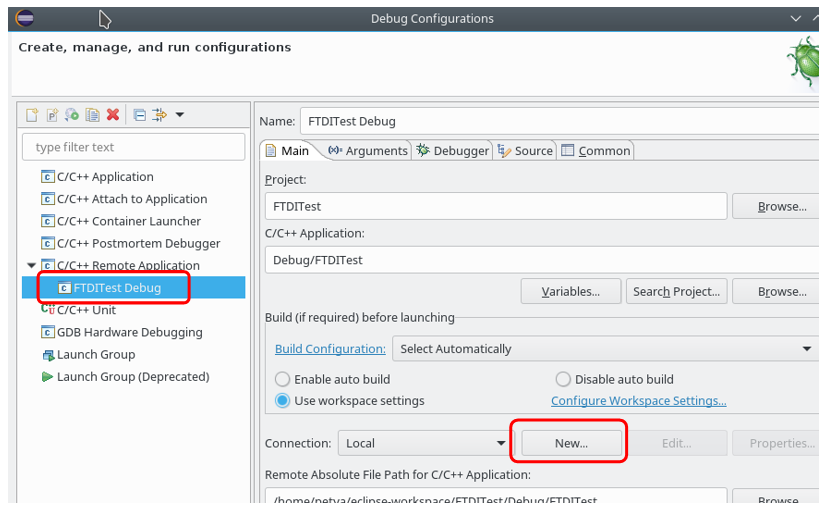
Elija una conexión como SSH:
Completamos las propiedades de conexión cambiando el botón de opción del tipo de autorización a autorización de contraseña:
En realidad, el sistema está listo para la depuración. Después de asegurarnos de que el texto de bienvenida se muestra realmente, intentamos transferir el código del ejemplo anterior (que estaba en Visual Studio) aquí. Para registrar bibliotecas adicionales, seleccione las propiedades del proyecto:

Además, dado que el ensamblaje se realiza localmente, las bibliotecas también deben estar en el directorio local usr / local / lib. Le recuerdo que las bibliotecas se descargan con el controlador y que la forma de instalarlas es el archivo Léame, así como los videos de AN220 y YouTube. Para obtener detalles, consulte la sección sobre Visual Studio.
Después de toda esta preparación, obtenemos las líneas familiares. Es decir, el código completamente idéntico al considerado en la sección anterior se ejecuta no menos idénticamente.
Eso es todo. Ahora, dependiendo de la situación, podemos ejecutar el código tanto a través de Visual Studio como a través de una máquina virtual. Como puede ver, puramente en términos de configuración, Visual Studio es más simple, por lo tanto, ceteris paribus, lo elegiré. Pero es mejor tener ambas tecnologías, ya que trabajar a través de Studio tiene sus inconvenientes relacionados con el hecho de que no solo la depuración, sino también el ensamblaje son remotos allí.
Medición de velocidad de escritura FPGA a través de FT2232H
Pues que. Arreglemos las habilidades adquiridas en un proyecto más o menos real. Por supuesto, comenzar algo muy serio ya no es posible; todos ya están cansados. Pero obtenemos un resultado más o menos práctico. Por ejemplo, medimos con qué velocidad máxima podemos transferir datos al FPGA a través del chip FT2232H. El protocolo no es el más fácil, por lo que no lo transmitiremos por ambos lados, sino que nos limitaremos a transmitir desde nosotros al canal, en el otro extremo del cual está instalado el FPGA. El documento
AN_130 FT2232H utilizado en un modo FIFO síncrono estilo FT245 nos ayudará con esto, ya que en el complejo el controlador se enciende precisamente en este modo (FIFO síncrono). Este documento también contiene una descripción de las conclusiones, en la forma en que se utilizan en este modo, y diagramas de tiempo, e incluso ejemplos de código, de los cuales nos inspiraremos.
Entonces Queremos grabar en FIFO usando el controlador. ¿Qué vendrá de nosotros? Lo intenté, lo sé. Tomará 1 kilobyte de datos, después de lo cual el controlador se bloqueará. Se negará a aceptar datos adicionales. El caso es que un kilobyte es el tamaño de su búfer interno. Si bien es posible, los datos se tomarán de USB y se almacenarán en este espacio. Pero para que puedan ir al canal sincrónico, debe informar sobre la disposición para recibirlos. Nos fijamos en el improvisado correspondiente.

Entonces Cuando el controlador tiene datos en FIFO, deja caer la señal RXF. En respuesta a esto, primero debemos soltar la señal OE y mantenerla en cero durante al menos un ciclo de reloj (esto se deduce más de la descripción del diagrama que del diagrama en sí). Se nos darán datos en el bus, debemos confirmar su recepción con un bajo nivel de señal RD. Y así, para todo el marco. Cuando el controlador eleva la línea RXF, debemos eliminar el OE y el RD. No usaremos los datos hoy. Para medir la velocidad, simplemente simule la recepción de datos en el FPGA desde FT2232H. Pues bien. Para una operación tan simple, no se necesita un sistema de procesador. Es suficiente para hacer un autómata degenerado, cuyo desarrollo llevará mucho menos tiempo que simplemente preocuparse por la preparación del procesador y el programa. Por lo tanto, creamos un proyecto que contiene solo un archivo SystemVerilog con los siguientes contenidos:
module JustRead( input logic clk, input logic rxf_n, output logic oe_n, output logic rd_n ); enum {IDLE,TRANSFER} state = IDLE; always @ (posedge clk) begin oe_n <= 1; rd_n <= 1; case (state) IDLE: begin if (rxf_n == 0) begin oe_n <= 0; state <= TRANSFER; end end TRANSFER: begin if (rxf_n == 0) begin oe_n <= 0; rd_n <= 0; end else begin state <= IDLE; end end endcase end endmodule
La máquina tiene dos estados. En este caso, la duración de la señal OE está determinada por el hecho de que se activa inmediatamente después del pulso del reloj y se mantiene hasta el siguiente. Esto se puede verificar utilizando el siguiente modelo:
module JustReadTB( output logic clk, output logic rxf_n, input logic oe_n, input logic rd_n ); JustRead dut ( .clk, .rxf_n, .oe_n, .rd_n ); always begin clk = 1; #16; clk = 0; #16; end initial begin rxf_n = 1; #120; rxf_n = 0; #120; rxf_n = 1; end endmodule
El tiempo que tomé es el primero disponible, lo importante es la secuencia de conmutación que se adjunta a la señal del reloj. Obtenemos el siguiente diagrama de tiempo:

En una primera aproximación, esto corresponde a lo que requiere el documento. Pero no procesaremos los datos reales de todos modos.
La asignación de piernas FPGA en este proyecto tampoco causa dificultades incluso para editar a través de una tabla (llevará más tiempo transferir las asignaciones del archivo * .QSF, y constantemente enfatizo que cuando se desarrollan sistemas de un día en Redd, ahorrar tiempo es una prioridad).

Recolectamos, llenamos, antes de apagar el complejo, puede trabajar con el programa, ya no se bloqueará después de un desbordamiento del búfer.
En el programa, hice dos funciones. El primero busca y abre el dispositivo. Tomé algo de la última prueba, tomé prestado algo de
AN130 :
FT_HANDLE OpenFT2232H() { FT_HANDLE ftHandle0; static FT_DEVICE ftDevice; // int nDevice = 0; while (true) { // if (FT_Open(nDevice, &ftHandle0) != FT_OK) { // , return 0; } // ? if (FT_GetDeviceInfo(ftHandle0, &ftDevice, NULL, NULL, NULL, NULL) == FT_OK) { // , if (ftDevice == FT_DEVICE_2232H) { // , AN130 FT_SetBitMode(ftHandle0, 0xff, 0x00); usleep(1000000); //Sync FIFO mode FT_SetBitMode(ftHandle0, 0xff, 0x40); FT_SetLatencyTimer(ftHandle0, 2); FT_SetUSBParameters(ftHandle0, maxBlockSize, maxBlockSize); return ftHandle0; } } // FT_Close(ftHandle0); // nDevice += 1; } }
Como fanático de Windows, tuve que escribir la función de medición de velocidad, revisando constantemente Internet, ya que generalmente uso los temporizadores clásicos de alta resolución de la API WIN32. Quizás pueda escribir de manera más eficiente, pero este es un programa de un día.
const int maxBlockSize = 0x100000; uint8_t buf[maxBlockSize]; … // BlockSize , 1 double TestSpeed(FT_HANDLE ftHandle0,int totalSize, int blockSize) { if (blockSize > maxBlockSize) { return -1; } DWORD dwWrittenTotal = 0; timespec before; clock_gettime(CLOCK_REALTIME, &before); for (int i = 0; i < totalSize; i += blockSize) { DWORD dwWritten; FT_Write(ftHandle0, buf, blockSize, &dwWritten); // dwWrittenTotal += dwWritten; } timespec after; clock_gettime(CLOCK_REALTIME, &after); if (dwWrittenTotal < (DWORD)totalSize) { return -2; } // uint64_t nsBefore = before.tv_nsec; uint64_t nsAfter = after.tv_nsec; // nsAfter += (after.tv_sec - before.tv_sec) * 1000000000; // nsAfter -= nsBefore; // double res = ((double)nsAfter)/((double)1000000000); // - return ((double)dwWrittenTotal) / res; }
Bueno, el código que realiza la funcionalidad básica resultó así:
int main(int argc, char* argv[]) { FT_HANDLE ftHandle0 = OpenFT2232H(); if (ftHandle0 == 0) { printf("Cannot open device\n"); return -1; } const int totalSize = 0x100000; static const int blockSizes[] = { 0x10,0x20,0x40,0x80,0x100,0x200,0x400,0x800,0x1000,0x2000, 0x4000,0x8000,0x10000,0x20000,0x40000,0x80000,0 }; for (int i = 0; blockSizes[i] != 0; i++) { double speed = TestSpeed(ftHandle0, totalSize, blockSizes[i]); printf("%d,%d\n", blockSizes[i], (int)(speed/1000.)); int stop = 0; } // , FT_Close(ftHandle0); return 0; }
Sé que en USB, la velocidad depende en gran medida del tamaño del bloque que se envía, por lo que compruebo la velocidad para varias opciones. La enumeración lineal apenas es necesaria. Acabo de presentar una lista de tamaños típicos. Saco los datos en kilobytes por segundo. Los bytes son incómodos para los ojos, los megabytes tienen baja resolución con un tamaño de bloque pequeño. Kilobytes por segundo es un compromiso razonable. Obtenemos los siguientes resultados:
16,59 32,110 64,237 128,490 256,932 512,1974 1024,3760 2048,5594 4096,10729 8192,16109 16384,20170 32768,24248 65536,26664 131072,28583 262144,29370 524288,29832
Los guardamos en un archivo * .csv, los cargamos en Excel, construimos un gráfico de la velocidad versus el tamaño del bloque.
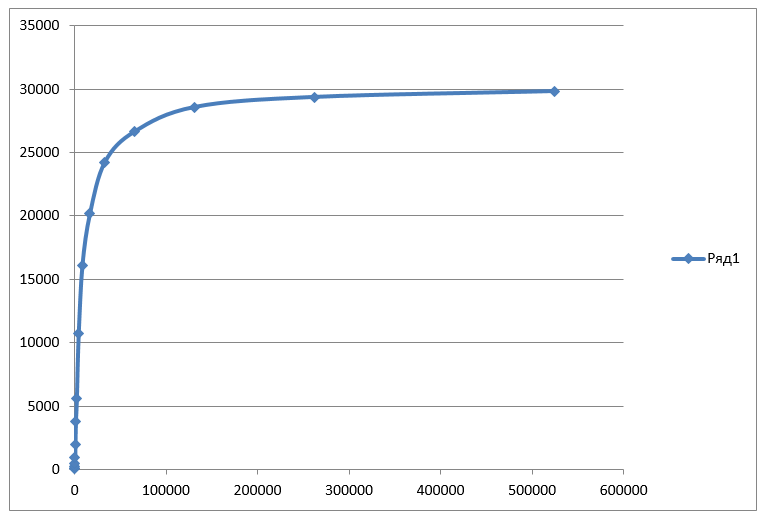
El límite es de 30 megabytes por segundo. Hasta un máximo teórico de 52 MB / s lejos. Quizás pueda acelerar de alguna manera, pero dejarlo a los lectores en forma de trabajo práctico. Lo principal es que hemos dominado todos los pasos para trabajar con el canal y estamos listos para conectar la FPGA con el procesador central en un solo sistema.
Mientras se
compilaba el artículo, se encontró el documento
AN_165 , que decía que la velocidad máxima en modo FIFO síncrono es de 35 MB / s. Es decir, espacio para el crecimiento, hasta un tamaño determinado. Pero todavía está ahí.
Conclusión
Conocimos dos estrategias para desarrollar y depurar código de programa ejecutado en el procesador central del complejo Redd (usando las herramientas de Microsoft Visual Studio y en una máquina virtual con sistema operativo Linux). También adquirimos habilidades prácticas al trabajar con el canal a través del cual el procesador central del complejo se comunica con el FPGA.
Aparentemente, ahora nada nos impide transmitir datos significativos de la CPU a la FPGA y viceversa (aunque en el último artículo escribí estas palabras).
Aquí se puede descargar un ejemplo que contiene el "firmware" más simple para FPGA y un programa que mide la velocidad de escritura en USB .