Hola Habr! Le presento la traducción gratuita de "Guía para la arquitectura de aplicaciones" de
JetPack . Le pido que deje todos los comentarios sobre la traducción en los comentarios, y se corregirán. Además, los comentarios de quienes utilizaron la arquitectura presentada con recomendaciones para su uso serán útiles para todos.
Esta guía cubre las mejores prácticas y la arquitectura recomendada para construir aplicaciones robustas. Esta página asume una introducción básica al Android Framework. Si es nuevo en el desarrollo de aplicaciones de Android, consulte nuestras
guías para
desarrolladores para comenzar y aprender más sobre los conceptos mencionados en esta guía. Si está interesado en la arquitectura de aplicaciones y desea familiarizarse con los materiales de esta guía desde una perspectiva de programación de Kotlin, consulte el curso de Udacity,
"Desarrollo de aplicaciones para Android con Kotlin" .
Experiencia de usuario de la aplicación móvil
En la mayoría de los casos, las aplicaciones de escritorio tienen un único punto de entrada desde el escritorio o el iniciador, y luego se ejecutan como un solo proceso monolítico. Las aplicaciones de Android tienen una estructura mucho más compleja. Una aplicación típica de Android contiene varios
componentes de la aplicación , que incluyen
Actividades ,
Fragmentos ,
Servicios ,
Proveedores de contenido y
BroadcastReceivers .
Usted declara todos o algunos de estos componentes de la aplicación en el
manifiesto de la aplicación. Luego, Android utiliza este archivo para decidir cómo integrar su aplicación en la interfaz de usuario común del dispositivo. Dado que una aplicación de Android bien escrita contiene varios componentes, y los usuarios a menudo interactúan con varias aplicaciones en un corto período de tiempo, las aplicaciones deben adaptarse a diferentes tipos de flujos de trabajo y tareas dirigidas por los usuarios.
Por ejemplo, considere lo que sucede cuando comparte una foto en su aplicación de redes sociales favorita:
- La aplicación desencadena la intención de la cámara. Android lanza una aplicación de cámara para procesar la solicitud. Por el momento, el usuario ha dejado la aplicación para las redes sociales, y su experiencia como usuario es impecable.
- Una aplicación de cámara puede desencadenar otras intenciones, como iniciar un selector de archivos, que puede iniciar otra aplicación.
- Al final, el usuario vuelve a la aplicación de red social y comparte la foto.
En cualquier momento del proceso, el usuario puede ser interrumpido por una llamada telefónica o notificación. Después de la acción asociada con esta interrupción, el usuario espera poder regresar y reanudar este proceso para compartir fotos. Este comportamiento de cambio de aplicación es común en dispositivos móviles, por lo que su aplicación debe manejar correctamente estos puntos (tareas).
Recuerde que los dispositivos móviles también tienen recursos limitados, por lo que en cualquier momento el sistema operativo puede destruir algunos procesos de aplicación para liberar espacio para otros nuevos.
Dadas las condiciones de este entorno, los componentes de su aplicación pueden iniciarse individualmente y no en orden, y el sistema operativo o el usuario pueden destruirlos en cualquier momento. Dado que estos eventos no están bajo su control,
no debe almacenar ningún dato o estado en los componentes de su aplicación, y los componentes de su aplicación no deben depender el uno del otro.
Principios arquitectónicos generales
Si no debe utilizar los componentes de la aplicación para almacenar datos y el estado de la aplicación, ¿cómo debe desarrollar su aplicación?
División de responsabilidad
El principio más importante a seguir es
compartir responsabilidades . Un error común es cuando escribe todo su código en
Actividad o
Fragmento . Estas son clases de interfaz de usuario que deben contener solo el procesamiento lógico de la interacción de la interfaz de usuario y el sistema operativo. Al compartir la responsabilidad tanto como sea posible en estas clases
(SRP) , puede evitar muchos de los problemas asociados con el ciclo de vida de la aplicación.
Control de interfaz de usuario del modelo
Otro principio importante es que debe
controlar su interfaz de usuario desde un modelo , preferiblemente desde un modelo permanente. Los modelos son los componentes responsables del procesamiento de los datos para la aplicación. Son independientes de los objetos
View y los componentes de la aplicación, por lo tanto, no se ven afectados por el ciclo de vida de la aplicación y los problemas relacionados.
Un modelo permanente es ideal por las siguientes razones:
- Sus usuarios no perderán datos si el sistema operativo Android destruye su aplicación para liberar recursos.
- Su aplicación continúa funcionando cuando la conexión de red es inestable o no está disponible.
Al organizar la base de su aplicación en clases modelo con una responsabilidad claramente definida para la gestión de datos, su aplicación se vuelve más comprobable y compatible.
Arquitectura de aplicación recomendada
Esta sección muestra cómo estructurar una aplicación utilizando
componentes arquitectónicos , trabajando en un
escenario de uso de extremo a
extremo .
Nota No es posible tener una forma de escribir aplicaciones que funcione mejor para cada escenario. Sin embargo, la arquitectura recomendada es un buen punto de partida para la mayoría de las situaciones y flujos de trabajo. Si ya tiene una buena manera de escribir aplicaciones de Android que cumplan con los principios arquitectónicos generales, no debe cambiarla.Imagine que estamos creando una interfaz de usuario que muestra un perfil de usuario. Utilizamos una API privada y una API REST para recuperar datos de perfil.
Revisar
Para comenzar, considere el esquema de interacción de los módulos de la arquitectura de la aplicación terminada:
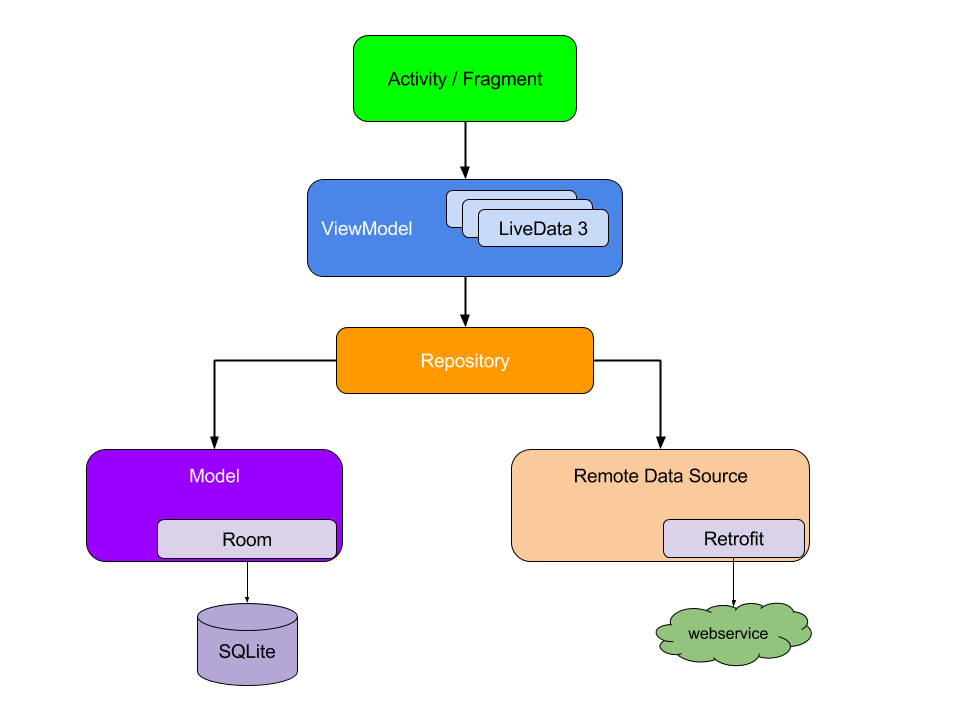
Tenga en cuenta que cada componente solo depende del componente un nivel por debajo de él. Por ejemplo, Actividad y Fragmentos dependen solo del modelo de vista. El repositorio es la única clase que depende de muchas otras clases; En este ejemplo, el almacenamiento depende de un modelo de datos persistente y una fuente de datos interna remota.
Este patrón de diseño crea una experiencia de usuario consistente y agradable. Independientemente de si el usuario vuelve a la aplicación unos minutos después de cerrarla o unos días después, verá instantáneamente la información del usuario de que la aplicación se guarda localmente. Si estos datos no están actualizados, el módulo de almacenamiento de la aplicación comienza a actualizar los datos en segundo plano.
Crear una interfaz de usuario
La interfaz de usuario consta del fragmento
UserProfileFragment y el correspondiente
user_profile_layout.xml diseño
user_profile_layout.xml .
Para administrar la interfaz de usuario, nuestro modelo de datos debe contener los siguientes elementos de datos:
- ID de usuario : ID de usuario. La mejor solución es pasar esta información al fragmento utilizando los argumentos del fragmento. Si el sistema operativo Android destruye nuestro proceso, esta información se guarda, por lo que el identificador estará disponible la próxima vez que lancemos nuestra aplicación.
- Objeto de usuario: una clase de datos que contiene información del usuario.
Utilizamos un
UserProfileViewModel basado en un componente de la arquitectura ViewModel para almacenar esta información.
El objeto ViewModel proporciona datos para un componente específico de la interfaz de usuario, como un fragmento o actividad, y contiene lógica de procesamiento de datos empresariales para interactuar con el modelo. Por ejemplo, ViewModel puede llamar a otros componentes para cargar datos y puede reenviar las solicitudes de los usuarios para cambios de datos. ViewModel no conoce los componentes de la interfaz de usuario, por lo que no se ve afectado por los cambios de configuración, como la recreación de la actividad cuando se gira el dispositivo.Ahora hemos identificado los siguientes archivos:
user_profile.xml : diseño de interfaz de usuario definido.UserProfileFragment : describe un controlador de interfaz de usuario que es responsable de mostrar información al usuario.UserProfileViewModel : una clase responsable de preparar los datos para mostrarlos en UserProfileFragment y responder a la interacción del usuario.
Los siguientes fragmentos de código muestran el contenido inicial de estos archivos. (El archivo de diseño se omite por simplicidad).
class UserProfileViewModel : ViewModel() { val userId : String = TODO() val user : User = TODO() } class UserProfileFragment : Fragment() { private val viewModel: UserProfileViewModel by viewModels() override fun onCreateView( inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle? ): View { return inflater.inflate(R.layout.main_fragment, container, false) } }
Ahora que tenemos estos módulos de código, ¿cómo los conectamos? Después de establecer el campo de usuario en la clase UserProfileViewModel, necesitamos una forma de informar a la interfaz de usuario.
Nota SavedStateHandle permite que ViewModel acceda al estado guardado y a los argumentos del fragmento o acción asociados.
Ahora necesitamos informar a nuestro Fragmento cuando se recibe el objeto de usuario. Aquí es donde aparece el componente de la arquitectura LiveData.
LiveData es un titular de datos observable. Otros componentes en su aplicación pueden rastrear los cambios en los objetos usando este soporte, sin crear rutas de dependencia explícitas y difíciles entre ellos. El componente LiveData también tiene en cuenta el estado del ciclo de vida de los componentes de su aplicación, como Actividades, Fragmentos y Servicios, e incluye lógica de limpieza para evitar fugas de objetos y consumo excesivo de memoria.
Nota Si ya usa bibliotecas como RxJava o Agera, puede continuar usándolas en lugar de LiveData. Sin embargo, cuando use bibliotecas y enfoques similares, asegúrese de manejar adecuadamente el ciclo de vida de su aplicación. En particular, asegúrese de suspender sus secuencias de datos cuando se detiene el LifecycleOwner asociado, y destruya estas secuencias cuando se destruye el LifecycleOwner asociado. También puede agregar el artefacto android.arch.lifecycle: corrientes en chorro para usar LiveData con otra biblioteca de corrientes en chorro como RxJava2.Para incluir el componente LiveData en nuestra aplicación, cambiamos el tipo de campo en
UserProfileViewModel a LiveData.
UserProfileFragment ahora
UserProfileFragment informado sobre las actualizaciones de datos. Además, dado que este campo
LiveData admite el ciclo de vida, borra automáticamente los enlaces cuando ya no son necesarios.
class UserProfileViewModel( savedStateHandle: SavedStateHandle ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = TODO() }
Ahora modificamos el
UserProfileFragment para observar los datos en
ViewModel y actualizar la interfaz de usuario de acuerdo con los cambios:
override fun onViewCreated(view: View, savedInstanceState: Bundle?) { super.onViewCreated(view, savedInstanceState) viewModel.user.observe(viewLifecycleOwner) {
Cada vez que se actualizan los datos del perfil de usuario, se llama a la devolución de llamada
onChanged () y se actualiza la interfaz de usuario.
Si está familiarizado con otras bibliotecas que usan devoluciones de llamada observables, es posible que se haya dado cuenta de que no redefinimos el método
onStop () del fragmento para dejar de observar datos. Este paso es opcional para LiveData porque admite el ciclo de vida, lo que significa que no llamará a la
onChanged() llamada
onChanged() si el fragmento está en un estado inactivo; es decir, recibió una llamada a
onStart () , pero aún no ha recibido
onStop() ). LiveData también elimina automáticamente el observador cuando llama al método
onDestroy () en el fragmento.
No hemos agregado ninguna lógica para manejar los cambios de configuración, como la rotación de la pantalla del dispositivo por parte del usuario.
UserProfileViewModel restaura automáticamente cuando se cambia la configuración, por lo que tan pronto como se crea un nuevo fragmento, recibe la misma instancia de
ViewModel y se llama a la devolución de llamada inmediatamente utilizando los datos actuales. Dado que los objetos
ViewModel están diseñados para sobrevivir a los objetos
View correspondientes que actualizan, no debe incluir referencias directas a los objetos
View en su implementación ViewModel. Para obtener más información sobre la vida útil de
ViewModel corresponde al ciclo de vida de los componentes de la interfaz de usuario, consulte
Ciclo de vida de ViewModel.Recuperación de datos
Ahora que hemos utilizado LiveData para conectar
UserProfileViewModel a
UserProfileFragment , ¿cómo podemos obtener los datos del perfil de usuario?
En este ejemplo, suponemos que nuestro backend proporciona una API REST. Utilizamos la biblioteca Retrofit para acceder a nuestro backend, aunque puede usar una biblioteca diferente que tenga el mismo propósito.
Aquí está nuestra definición de un servicio
Webservice que se vincula a nuestro backend:
interface Webservice { @GET("/users/{user}") fun getUser(@Path("user") userId: String): Call<User> }
Una primera idea para implementar un
ViewModel podría implicar llamar a
Webservice para recuperar los datos y asignarlos a nuestro objeto
LiveData . Este diseño funciona, pero usarlo hace que nuestra aplicación sea más difícil de mantener a medida que crece. Esto le da demasiada responsabilidad a la clase
UserProfileViewModel , lo que viola el principio de
separación de intereses . Además, el alcance de ViewModel está asociado con el ciclo de vida
Actividad o
Fragmento , lo que significa que los datos del Servicio
Webservice pierden cuando finaliza el ciclo de vida del objeto de interfaz de usuario asociado. Este comportamiento crea una experiencia de usuario indeseable.
En cambio, nuestro
ViewModel delega el proceso de recuperación de datos a un nuevo módulo de almacenamiento.
Los módulos de repositorio manejan las operaciones de datos. Proporcionan una API limpia para que el resto de la aplicación pueda obtener fácilmente estos datos. Saben de dónde obtener los datos y qué llamadas API hacer al actualizar los datos. Puede pensar en los repositorios como intermediarios entre diferentes fuentes de datos, como modelos persistentes, servicios web y cachés.Nuestra clase
UserRepository , que se muestra en el siguiente fragmento de código, utiliza una instancia de
WebService para recuperar datos de usuario:
class UserRepository { private val webservice: Webservice = TODO()
Aunque el módulo de almacenamiento parece innecesario, tiene un propósito importante: abstrae las fuentes de datos del resto de la aplicación. Ahora nuestro
UserProfileViewModel no sabe cómo recuperar datos, por lo que podemos proporcionar modelos de presentación con datos obtenidos de varias implementaciones diferentes de extracción de datos.
Nota Perdimos el caso de los errores de red por simplicidad. Para una implementación alternativa que expone los errores y el estado de descarga, consulte el Apéndice: Divulgación del estado de la red.
Gestión de dependencias entre componentesLa clase
UserRepository anterior necesita una instancia de
Webservice para recuperar los datos del usuario. Simplemente podría crear una instancia, pero para esto también necesita conocer las dependencias de la clase de servicio
Webservice . Además,
UserRepository probablemente no sea la única clase que necesita un servicio web. Esta situación requiere que dupliquemos el código, ya que cada clase que necesita un enlace al servicio
Webservice necesita saber cómo crearlo y sus dependencias. Si cada clase crea un nuevo servicio web, nuestra aplicación puede requerir muchos recursos.
Para resolver este problema, puede usar los siguientes patrones de diseño:
- Inyección de dependencia (DI) . La inyección de dependencias permite a las clases definir sus dependencias sin crearlas. En tiempo de ejecución, otra clase es responsable de proporcionar estas dependencias. Recomendamos la biblioteca Dagger 2 para implementar la inyección de dependencia en aplicaciones de Android. Dagger 2 crea automáticamente objetos, sin pasar por el árbol de dependencias, y proporciona garantías en tiempo de compilación para las dependencias.
- (Ubicación del servicio) Localizador del servicio : la plantilla del localizador del servicio proporciona un registro en el que las clases pueden obtener sus dependencias en lugar de crearlas.
Implementar un registro de servicio es más fácil que usar DI, por lo tanto, si es nuevo en DI, use la plantilla: ubicación del servicio.
Estas plantillas le permiten escalar su código porque proporcionan plantillas claras para administrar dependencias sin duplicar o complicar el código. Además, estas plantillas le permiten cambiar rápidamente entre implementaciones de prueba y producción de muestreo de datos.
Nuestra aplicación de muestra usa
Dagger 2 para administrar las dependencias del objeto de servicio
Webservice .
Conecte ViewModel y almacenamiento
Ahora modificamos nuestro
UserProfileViewModel para usar el objeto
UserRepository :
class UserProfileViewModel @Inject constructor( savedStateHandle: SavedStateHandle, userRepository: UserRepository ) : ViewModel() { val userId : String = savedStateHandle["uid"] ?: throw IllegalArgumentException("missing user id") val user : LiveData<User> = userRepository.getUser(userId) }
Almacenamiento en caché
La implementación de
UserRepository abstrae la invocación del objeto de servicio
Webservice , pero como se basa en una sola fuente de datos, no es muy flexible.
El principal problema con la implementación de
UserRepository es que después de recibir datos de nuestro backend, estos datos no se almacenan en ningún lado. Por lo tanto, si el usuario deja
UserProfileFragment y luego vuelve a él, nuestra aplicación debe recuperar los datos, incluso si no han cambiado.
Este diseño no es óptimo por las siguientes razones:
- Gasta valiosos recursos de tráfico.
- Esto hace que el usuario espere a que se complete una nueva solicitud.
Para abordar estas deficiencias, agregamos una nueva fuente de datos a nuestro
UserRepository , que almacena en caché los objetos del
User en la memoria:
Datos persistentes
Usando nuestra implementación actual, si el usuario gira el dispositivo o se va e inmediatamente regresa a la aplicación, la interfaz de usuario existente se vuelve inmediatamente visible, porque la tienda recupera datos de nuestro caché en la memoria.
Sin embargo, ¿qué sucede si un usuario abandona la aplicación y regresa unas horas después de que el sistema operativo Android complete el proceso? Confiando en nuestra implementación actual en esta situación, necesitamos obtener datos de la red nuevamente. Este proceso de actualización no es solo una mala experiencia de usuario; También es un desperdicio porque consume valiosos datos móviles.
Puede resolver este problema almacenando en caché las solicitudes web, pero esto crea un nuevo problema clave: ¿qué sucede si se muestran los mismos datos de usuario en una solicitud de un tipo diferente, por ejemplo, al recibir una lista de amigos? La aplicación mostrará datos conflictivos, lo cual es confuso en el mejor de los casos. Por ejemplo, nuestra aplicación puede mostrar dos versiones diferentes de los datos del mismo usuario si el usuario envió una solicitud de lista de amigos y una solicitud de usuario único en diferentes momentos. Nuestra aplicación tendría que descubrir cómo combinar estos datos en conflicto.
La forma correcta de lidiar con esta situación es usar un modelo constante. La Biblioteca de datos permanentes (DB) de la
sala nos ayuda.
Room es una biblioteca de mapeo de objetos que proporciona almacenamiento local de datos con un código estándar mínimo. En el momento de la compilación, verifica que cada consulta cumpla con su esquema de datos, por lo que las consultas SQL dañadas producen errores durante la compilación y no se bloquean en el tiempo de ejecución. Resumen de sala a partir de algunos detalles básicos de implementación de tablas y consultas SQL sin procesar. También le permite observar cambios en los datos de la base de datos, incluidas colecciones y solicitudes de conexión, exponiendo dichos cambios utilizando objetos LiveData. Incluso define explícitamente restricciones de ejecución que resuelven problemas comunes de subprocesos, como el acceso al almacenamiento en el subproceso principal.
Nota Si su aplicación ya usa otra solución, como el mapeo relacional de objetos SQLite (ORM), no necesita reemplazar la solución existente con Room. Sin embargo, si está escribiendo una nueva aplicación o reorganizando una aplicación existente, le recomendamos usar Room para guardar los datos de su aplicación. Por lo tanto, puede aprovechar la abstracción de la biblioteca y la validación de consultas.Para usar Room, necesitamos definir nuestro diseño local. Primero, agregamos la anotación
@Entity a nuestra clase de modelo de datos de
User y la anotación
@PrimaryKey en el campo
id clase. Estas anotaciones marcan al
User como una tabla en nuestra base de datos, y la
id como la clave principal de la tabla:
@Entity data class User( @PrimaryKey private val id: String, private val name: String, private val lastName: String )
Luego creamos la clase de base de datos implementando
RoomDatabase para nuestra aplicación:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase()
Tenga en cuenta que
UserDatabase es abstracto. La biblioteca de salas proporciona automáticamente una implementación de esto. Consulte la documentación de
Room para más detalles.
Ahora necesitamos una forma de insertar datos de usuario en la base de datos. Para esta tarea, creamos
un objeto de acceso a datos (DAO) .
@Dao interface UserDao { @Insert(onConflict = REPLACE) fun save(user: User) @Query("SELECT * FROM user WHERE id = :userId") fun load(userId: String): LiveData<User> }
Tenga en cuenta que el método de
load devuelve un objeto de tipo LiveData. Room sabe cuándo se cambia la base de datos y notifica automáticamente a todos los observadores activos los cambios en los datos. Como Room usa
LiveData , esta operación es eficiente; actualiza los datos solo si hay al menos un observador activo.
Nota: La sala verifica la invalidación en función de las modificaciones de la tabla, lo que significa que puede enviar notificaciones de falsos positivos.Habiendo definido nuestra clase
UserDao , luego hacemos referencia al DAO de nuestra clase de base de datos:
@Database(entities = [User::class], version = 1) abstract class UserDatabase : RoomDatabase() { abstract fun userDao(): UserDao }
Ahora podemos cambiar nuestro
UserRepository para incluir la fuente de datos de Room:
Tenga en cuenta que incluso si cambiamos la fuente de datos en
UserRepository , no necesitamos cambiar nuestro
UserProfileViewModel o
UserProfileFragment . Esta pequeña actualización demuestra la flexibilidad que proporciona nuestra arquitectura de aplicaciones. También es excelente para las pruebas, ya que podemos proporcionar un
UserRepository falso y probar nuestra producción
UserProfileViewModel al mismo tiempo.
Si los usuarios regresan en unos días, es probable que una aplicación que use esta arquitectura muestre información desactualizada hasta que el repositorio reciba información actualizada. Dependiendo de su caso de uso, es posible que no muestre información desactualizada. En su lugar, puede mostrar datos de
marcador de posición , que muestra valores ficticios e indica que su aplicación está descargando y cargando información actualizada.
La única fuente de verdad: por logeneral, diferentes puntos finales de la API REST devuelven los mismos datos. Por ejemplo, si nuestro backend tiene otro punto final que devuelve una lista de amigos, el mismo objeto de usuario puede provenir de dos puntos finales API diferentes, posiblemente incluso utilizando diferentes niveles de detalle. Si UserRepositorydevolvimos la respuesta de la solicitud Webservicetal como está, sin verificar la coherencia, nuestras interfaces de usuario podrían mostrar información confusa, porque la versión y el formato de los datos del almacenamiento dependerían del último punto final llamado.Por esta razón, nuestra implementación UserRepositoryalmacena las respuestas del servicio web en una base de datos. Los cambios en la base de datos desencadenan devoluciones de llamada para objetos LiveData activos. Con este modelo, la base de datos sirve como la única fuente de verdad , y otras partes de la aplicación acceden a ella a través de la nuestra UserRepository. Independientemente de si utiliza un caché de disco, le recomendamos que su repositorio identifique la fuente de datos como la única fuente de verdad para el resto de su aplicación.Mostrar progreso de la operación
En algunos casos de uso, como pull-to-refresh, es importante que la interfaz de usuario muestre al usuario que una operación de red está actualmente en progreso. Se recomienda que la acción de la interfaz de usuario se separe de los datos reales, ya que los datos pueden actualizarse por varias razones. Por ejemplo, si obtenemos una lista de amigos, el mismo usuario puede seleccionarse nuevamente mediante programación, lo que conducirá a una actualización de LiveData. Desde el punto de vista de la interfaz de usuario, el hecho de tener una solicitud en vuelo es solo otro punto de datos, similar a cualquier otro dato en el objeto mismo User.Podemos usar una de las siguientes estrategias para mostrar el estado de actualización de datos acordado en la interfaz de usuario, independientemente de dónde provenga la solicitud de actualización de datos:En la sección sobre separación de intereses, mencionamos que una de las ventajas clave de seguir este principio es la capacidad de prueba.La siguiente lista muestra cómo probar cada módulo de código de nuestro ejemplo extendido:- Interfaz de usuario e interacción : use el kit de herramientas de prueba de la interfaz de usuario de Android . La mejor manera de crear esta prueba es usar la biblioteca Espresso . Puede crear un fragmento y proporcionarle un diseño
UserProfileViewModel. Dado que el fragmento está asociado solo con UserProfileViewModel, la burla (imitación) de solo esta clase es suficiente para probar completamente la interfaz de usuario de su aplicación. - ViewModel:
UserProfileViewModel JUnit . , UserRepository . - UserRepository:
UserRepository JUnit. Webservice UserDao . :
Webservice , UserDao , .- UserDao: DAO . - , . , , , …
: Room , DAO, JSQL SupportSQLiteOpenHelper . , SQLite SQLite . - -: . , -, . , MockWebServer , .
- : maven .
androidx.arch.core : JUnit:
InstantTaskExecutorRule: .CountingTaskExecutorRule: . Espresso .
La programación es un campo creativo, y la creación de aplicaciones de Android no es una excepción. Hay muchas formas de resolver el problema, ya sea transfiriendo datos entre varias acciones o fragmentos, recuperando datos eliminados y guardándolos localmente fuera de línea, o cualquier otro escenario común encontrado por aplicaciones no triviales.Aunque no se requieren las siguientes recomendaciones, nuestra experiencia muestra que su implementación hace que su base de código sea más confiable, comprobable y compatible a largo plazo:Evite designar los puntos de entrada de su aplicación, como acciones, servicios y receptores de transmisión, como fuentes de datos.En cambio, solo necesitan coordinarse con otros componentes para obtener un subconjunto de los datos relacionados con este punto de entrada. Cada componente de la aplicación es de corta duración, dependiendo de la interacción del usuario con su dispositivo y el estado actual general del sistema.Cree líneas claras de responsabilidad entre los diversos módulos de su aplicación.Por ejemplo, no distribuya código que descargue datos de la red a varias clases o paquetes en su base de código. Del mismo modo, no defina múltiples responsabilidades no relacionadas, como el almacenamiento en caché y el enlace de datos, en la misma clase.Exponga lo menos posible de cada módulo.Resista la tentación de crear una etiqueta de "solo uno" que revele los detalles de una implementación interna desde un módulo. Puede ganar algo de tiempo a corto plazo, pero luego incurrirá en una deuda técnica muchas veces a medida que se desarrolle su base de código.Piense en cómo hacer que cada módulo sea comprobable de forma aislada.Por ejemplo, tener una API bien definida para recuperar datos de la red facilita la prueba de un módulo que almacena estos datos en una base de datos local. Si, en cambio, combina la lógica de estos dos módulos en un solo lugar o distribuye su código de red en toda la base de código, las pruebas se vuelven mucho más difíciles, en algunos casos ni siquiera imposibles.Concéntrese en el núcleo único de su aplicación para destacarse de otras aplicaciones.No reinvente la rueda escribiendo el mismo patrón una y otra vez. En cambio, concentre su tiempo y energía en lo que hace que su aplicación sea única, y deje que los componentes de la arquitectura de Android y otras bibliotecas recomendadas hagan frente a un patrón repetitivo.Mantenga la mayor cantidad de datos relevantes y frescos posible.Por lo tanto, los usuarios pueden disfrutar de la funcionalidad de su aplicación, incluso si su dispositivo está fuera de línea. Recuerde que no todos sus usuarios usan una conexión de alta velocidad constante.Designe una única fuente de datos como la única fuente verdadera.Siempre que su aplicación necesite acceso a este dato, siempre debe provenir de esta única fuente de verdad.Anexo: divulgación del estado de la red
En la sección anterior de la arquitectura de aplicación recomendada, omitimos los errores de red y los estados de arranque para simplificar los fragmentos de código.Esta sección muestra cómo mostrar el estado de la red utilizando la clase Resource, que encapsula tanto los datos como su estado.El siguiente fragmento de código proporciona un ejemplo de implementaciónResource:
Dado que la descarga de datos de la red cuando se muestra una copia de estos datos es una práctica común, es útil crear una clase auxiliar que pueda reutilizarse en varios lugares. Para este ejemplo, creamos una clase con el nombre NetworkBoundResource.El siguiente diagrama muestra el árbol de decisión para NetworkBoundResource: Comienza observando la base de datos para el recurso. Cuando se descarga un registro de la base de datos por primera vez,
Comienza observando la base de datos para el recurso. Cuando se descarga un registro de la base de datos por primera vez, NetworkBoundResourceverifica si el resultado es lo suficientemente bueno como para ser enviado, o si necesita ser recuperado de la red. Tenga en cuenta que estas dos situaciones pueden ocurrir simultáneamente, dado que probablemente desee mostrar los datos en caché al actualizarlos desde la red.Si la llamada de red tiene éxito, almacena la respuesta en la base de datos y reinicializa la secuencia. En caso de una NetworkBoundResourcefalla de solicitud de red , envía la falla directamente.. . , .Tenga en cuenta que confiar en una base de datos para enviar cambios implica el uso de efectos secundarios relacionados, lo que no es muy bueno porque el comportamiento indefinido de estos efectos secundarios puede ocurrir si la base de datos no envía los cambios porque los datos no han cambiado.Además, no envíe resultados recibidos de la red, ya que esto viola el principio de una sola fuente de verdad. Al final, es posible que la base de datos contenga disparadores que cambien los valores de los datos durante la operación de guardar. Del mismo modo, no envíe "ÉXITO" sin nuevos datos, porque entonces el cliente recibirá la versión incorrecta de los datos.El siguiente fragmento de código muestra la API abierta proporcionada por la clase NetworkBoundResourcepara sus subclases:
Presta atención a los siguientes detalles importantes de la definición de clase:- Define dos parámetros de tipo,
ResultTypey RequestTypedado que el tipo de datos devuelto por la API puede no corresponder con el tipo de datos utilizado localmente. - Utiliza una clase
ApiResponsepara solicitudes de red. ApiResponseEs un contenedor simple para una clase Retrofit2.Callque convierte las respuestas en instancias LiveData.
La implementación completa de la clase NetworkBoundResourceaparece como parte del proyecto GitHub android-Architecture-components .Una vez creado, NetworkBoundResourcepodemos usarlo para escribir nuestro disco y las implementaciones conectadas a la red Useren la clase UserRepository: