
Hola lectores de Habr! El tema de este artículo será la implementación de la tolerancia a desastres en los sistemas de almacenamiento de AERODISK Engine. Inicialmente, queríamos escribir en un artículo sobre ambos medios: la replicación y el clúster de metro, pero, desafortunadamente, el artículo resultó ser demasiado grande, por lo que dividimos el artículo en dos partes. Pasemos de lo simple a lo complejo. En este artículo, configuraremos y probaremos la replicación síncrona: descarte un centro de datos y también rompamos el canal de comunicación entre los centros de datos y veamos qué sucede.
Nuestros clientes a menudo nos hacen diferentes preguntas sobre la replicación, por lo tanto, antes de pasar a configurar y probar la implementación de la réplica, le diremos un poco sobre qué replicación hay en los sistemas de almacenamiento.
Poco de teoría
La replicación al almacenamiento es un proceso continuo para garantizar la identidad de los datos en múltiples sistemas de almacenamiento simultáneamente. Técnicamente, la replicación se realiza por dos métodos.
La replicación síncrona es la copia de datos del sistema de almacenamiento principal al de respaldo, seguido de la confirmación obligatoria de ambos sistemas de almacenamiento de que los datos se registran y confirman. Es después de la confirmación de ambos lados (en ambos sistemas de almacenamiento) que los datos se consideran registrados, y puede trabajar con ellos. Esto garantiza una identidad de datos garantizada en todos los sistemas de almacenamiento que participan en la réplica.
Las ventajas de este método:
- Los datos son siempre idénticos en todos los sistemas de almacenamiento.
Contras:
- Alto costo de la solución (canales de comunicación rápidos, fibra costosa, transceptores de onda larga, etc.)
- Restricciones de distancia (dentro de unas pocas decenas de kilómetros)
- No hay protección contra la corrupción de datos lógicos (si los datos están dañados (a sabiendas o accidentalmente) en el sistema de almacenamiento principal, entonces se dañarán automática e inmediatamente en el almacenamiento de respaldo, ya que los datos son siempre idénticos (esto es una paradoja)
La replicación asincrónica también está copiando datos del almacenamiento principal a la copia de seguridad, pero con cierto retraso y sin la necesidad de confirmar el registro en el otro lado. Puede trabajar con datos inmediatamente después de escribir en el almacenamiento principal, y en el almacenamiento de respaldo, los datos estarán disponibles después de un tiempo. La identidad de los datos en este caso, por supuesto, no se proporciona en absoluto. Los datos sobre el almacenamiento de respaldo siempre están un poco "en el pasado".
Ventajas de la replicación asincrónica:
- Bajo costo de solución (cualquier canal de comunicación, óptica opcional)
- Sin límite de distancia
- Los datos en el almacenamiento de respaldo no se corrompen si se corrompe en el principal (al menos por un tiempo), si los datos se corrompen, siempre puede detener la réplica para evitar la corrupción de datos en el almacenamiento de respaldo
Contras:
- Los datos en diferentes centros de datos no siempre son idénticos
Por lo tanto, la elección del modo de replicación depende de las tareas de la empresa. Si es crítico para usted que el centro de datos de respaldo tenga exactamente los mismos datos que los datos principales (es decir, el requisito comercial para RPO = 0), tendrá que desembolsar y soportar las limitaciones de la réplica sincrónica. Y si el retraso en el estado de los datos es permisible o simplemente no hay dinero, entonces, definitivamente, debe usar el método asincrónico.
También distinguimos por separado dicho régimen (más precisamente, ya una topología) como un grupo metropolitano. El modo Metrocluster utiliza la replicación sincrónica, pero, a diferencia de una réplica normal, el metrocluster permite que ambos sistemas de almacenamiento funcionen en modo activo. Es decir no tiene una separación de centros de datos activos en espera. Las aplicaciones funcionan simultáneamente con dos sistemas de almacenamiento que se encuentran físicamente en diferentes centros de datos. Los tiempos de inactividad en una topología de este tipo son muy pequeños (RTO, generalmente minutos). En este artículo, no consideraremos nuestra implementación del clúster de metro, ya que este es un tema muy amplio y de gran capacidad, por lo que dedicaremos un artículo separado y siguiente a esta continuación.
También muy a menudo, cuando hablamos de replicación utilizando sistemas de almacenamiento, muchos tienen una pregunta razonable:> “Muchas aplicaciones tienen sus propias herramientas de replicación, ¿por qué usar la replicación en sistemas de almacenamiento? ¿Es mejor o peor?
No hay una respuesta única, así que aquí están los pros y los contras:
Argumentos PARA la replicación de almacenamiento:
- La simplicidad de la solución. De una manera, puede replicar una matriz completa de datos, independientemente del tipo de carga o aplicación. Si utiliza una réplica de aplicaciones, deberá configurar cada aplicación por separado. Si hay más de 2, entonces es extremadamente lento y costoso (la replicación de la aplicación requiere, por regla general, una licencia separada y no gratuita para cada aplicación. Pero más sobre eso a continuación).
- Puede replicar cualquier cosa, cualquier aplicación, cualquier dato, y siempre serán consistentes. Muchas (la mayoría) de las aplicaciones no tienen instalaciones de replicación, y las réplicas desde el lado del almacenamiento son la única forma de brindar protección contra desastres.
- No es necesario pagar de más por la funcionalidad de replicación de aplicaciones. Como regla, cuesta mucho, al igual que las licencias para un sistema de almacenamiento de réplica. Pero debe pagar la licencia de replicación de almacenamiento solo una vez, y debe comprar la licencia para la réplica de la aplicación para cada aplicación por separado. Si hay muchas de esas aplicaciones, entonces cuesta un centavo y el costo de las licencias para la replicación del almacenamiento se convierte en una gota en el cubo.
Argumentos EN CONTRA de la replicación de almacenamiento:
- La réplica que usa las herramientas de la aplicación tiene más funcionalidad desde el punto de vista de las propias aplicaciones, la aplicación conoce mejor sus datos (lo cual es obvio), por lo que hay más opciones para trabajar con ellos.
- Los fabricantes de algunas aplicaciones no garantizan la consistencia de sus datos si la replicación se realiza con herramientas de terceros. * *
* - una tesis controvertida. Por ejemplo, una conocida empresa de fabricación de DBMS, durante mucho tiempo declaró oficialmente que su DBMS normalmente se puede replicar solo por sus medios, y el resto de la replicación (incluido SHD-shnaya) "no es cierto". Pero la vida ha demostrado que esto no es así. Lo más probable (pero esto no es exacto) simplemente no es el intento más honesto de vender más licencias a los clientes.
Como resultado, en la mayoría de los casos, la replicación desde el lado del almacenamiento es mejor, porque Esta es una opción más simple y menos costosa, pero hay casos complejos en los que necesita una funcionalidad específica de la aplicación y necesita trabajar con la replicación a nivel de la aplicación.
Con la teoría terminada, ahora practica
Vamos a configurar una réplica en nuestro laboratorio. En el laboratorio, emulamos dos centros de datos (de hecho, dos bastidores adyacentes que parecen estar en diferentes edificios). El soporte consta de dos sistemas de almacenamiento Engine N2, que están interconectados por cables ópticos. Un servidor físico que ejecuta Windows Server 2016 con 10 Gb Ethernet está conectado a ambos sistemas de almacenamiento. El soporte es bastante simple, pero no cambia la esencia.
Esquemáticamente, se ve así:
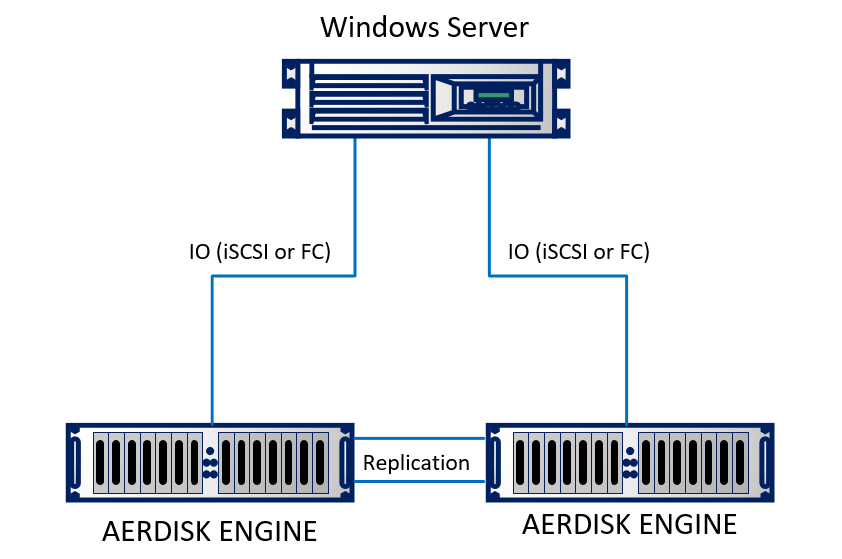
Lógicamente, la replicación se organiza de la siguiente manera:
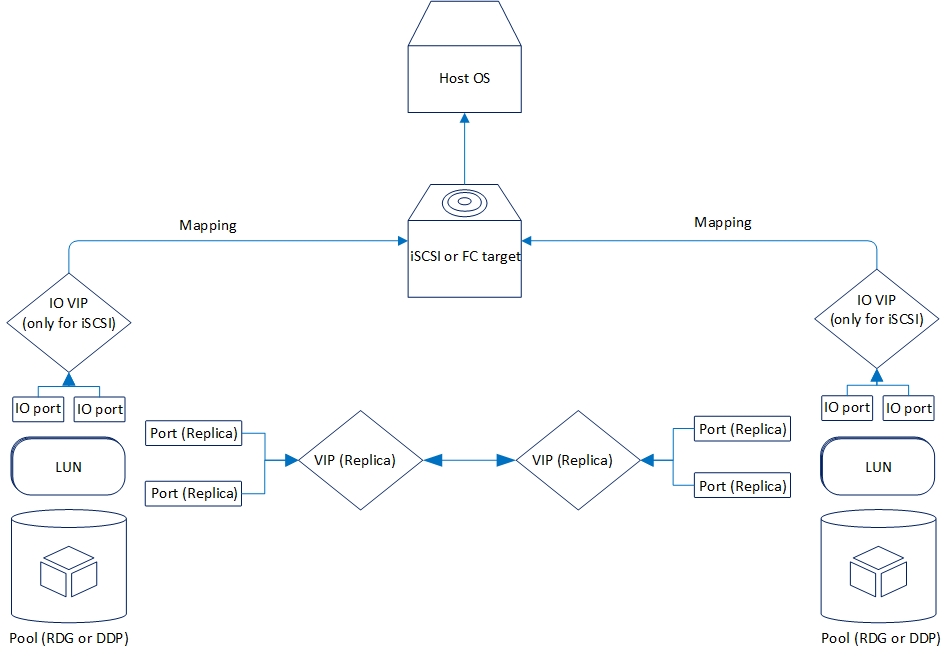
Ahora veamos la funcionalidad de replicación que tenemos ahora.
Se admiten dos modos: asíncrono y sincrónico. Es lógico que el modo síncrono esté limitado por la distancia y el canal de comunicación. En particular, el modo síncrono requiere el uso de fibra como física y Ethernet de 10 gigabits (o superior).
La distancia admitida para la replicación síncrona es de 40 kilómetros; el retraso del canal óptico entre los centros de datos es de hasta 2 milisegundos. En general, funcionará con grandes retrasos, pero luego habrá fuertes frenos durante la grabación (que también es lógico), por lo que si está considerando la replicación sincrónica entre los centros de datos, debe verificar la calidad de la óptica y los retrasos.
Los requisitos de replicación asincrónica no son tan serios. Más precisamente, no lo son en absoluto. Cualquier conexión Ethernet que funcione es adecuada.
Por el momento, el almacenamiento de AERODISK ENGINE admite la replicación de dispositivos de bloque (LUN) utilizando el protocolo Ethernet (cobre u óptica). Para proyectos que necesariamente requieren replicación a través de la fábrica SAN de Fibre Channel, ahora estamos completando la solución adecuada, pero hasta ahora no está lista, por lo que en nuestro caso solo es Ethernet.
La replicación puede funcionar entre cualquier sistema de almacenamiento de la serie ENGINE (N1, N2, N4) desde sistemas inferiores a sistemas anteriores y viceversa.
La funcionalidad de ambos modos de replicación es completamente idéntica. A continuación se muestra más sobre lo que es:
- Replicación "uno a uno" o "uno a uno", es decir, la versión clásica con dos centros de datos, el principal y el de respaldo
- La replicación es "uno a muchos" o "uno a muchos", es decir un LUN se puede replicar en varios sistemas de almacenamiento a la vez
- Activación, desactivación e “inversión” de la replicación, respectivamente, para habilitar, deshabilitar o cambiar la dirección de la replicación.
- La replicación está disponible para los grupos RDG (Raid Distributed Group) y DDP (Dynamic Disk Pool). Sin embargo, el LUN del grupo RDG solo se puede replicar en otro RDG. C DDP es similar.
Hay muchas más funciones pequeñas, pero enumerarlas no tiene mucho sentido, las mencionaremos durante la configuración.
Configuración de replicación
El proceso de configuración es bastante simple y consta de tres etapas.
- Configuración de red
- Configuración de almacenamiento
- Configuración de reglas (enlaces) y mapeo
Un punto importante en la configuración de la replicación es que las dos primeras etapas deben repetirse en un sistema de almacenamiento remoto, la tercera etapa, solo en la principal.
Configuración de recursos de red
El primer paso es configurar los puertos de red a través de los cuales se transmitirá el tráfico de replicación. Para hacer esto, debe habilitar los puertos y establecer direcciones IP en ellos en la sección Adaptadores front-end.
Después de eso, necesitamos crear un grupo (en nuestro caso RDG) e IP virtual para la replicación (VIP). VIP es una dirección IP flotante que está vinculada a dos direcciones "físicas" de controladores de almacenamiento (los puertos que acabamos de configurar). Será la interfaz de replicación principal. También puede operar no con VIP, sino con VLAN si necesita trabajar con tráfico etiquetado.
El proceso de crear un VIP para una réplica no es muy diferente de crear un VIP para E / S (NFS, SMB, iSCSI). En este caso, creamos un VIP (sin VLAN), pero asegúrese de indicar que es para replicación (sin este puntero, no podremos agregar VIP a la regla en el siguiente paso).
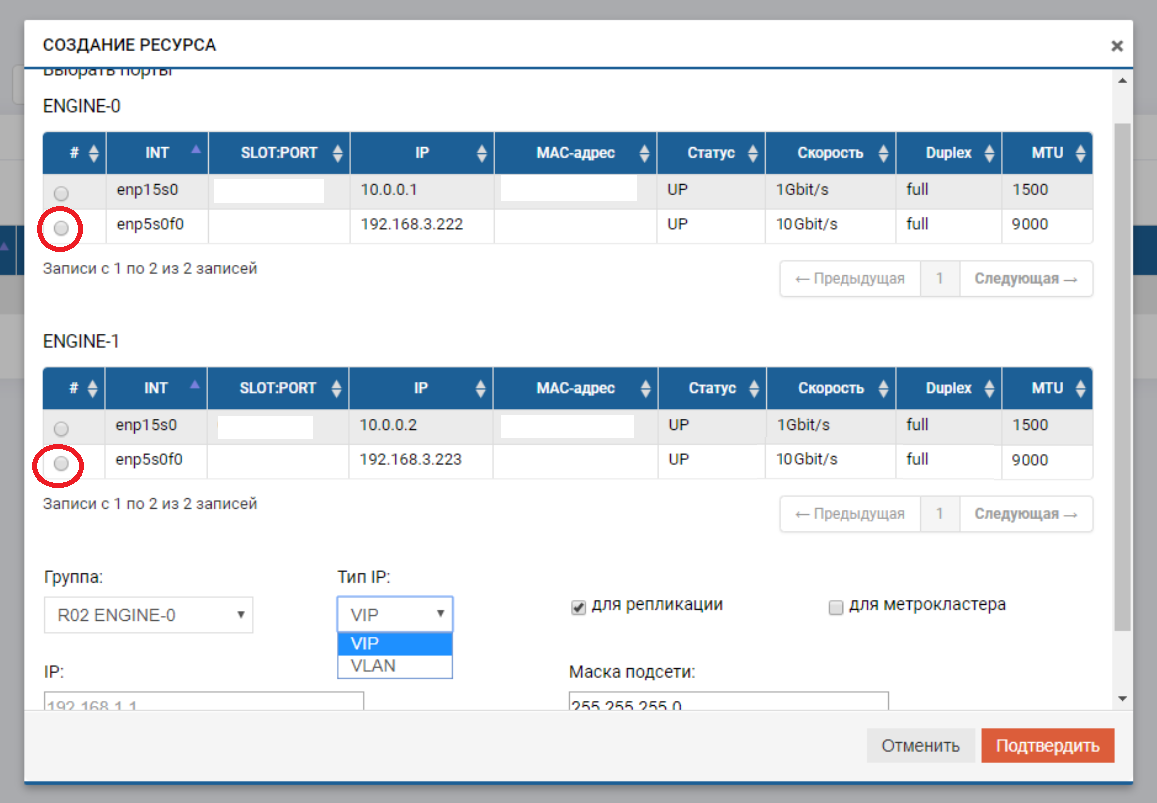
VIP debe estar en la misma subred que los puertos IP entre los cuales "flota".

Repetimos estas configuraciones en el sistema de almacenamiento remoto, con otro IP-shnik, por sí mismo.
Los VIP de diferentes sistemas de almacenamiento pueden estar en diferentes subredes, lo principal es que debe haber enrutamiento entre ellos. En nuestro caso, este ejemplo solo se muestra (192.168.3.XX y 192.168.2.XX)

En esto, se completa la preparación de la parte de la red.
Configurar almacenamiento
La configuración del almacenamiento para una réplica difiere de la habitual solo en que hacemos mapeo a través del menú especial "Mapeo de replicación". De lo contrario, todo es igual que con la configuración habitual. Ahora en orden.
En el grupo R02 creado anteriormente, debe crear un LUN. Crear, llámalo LUN1.
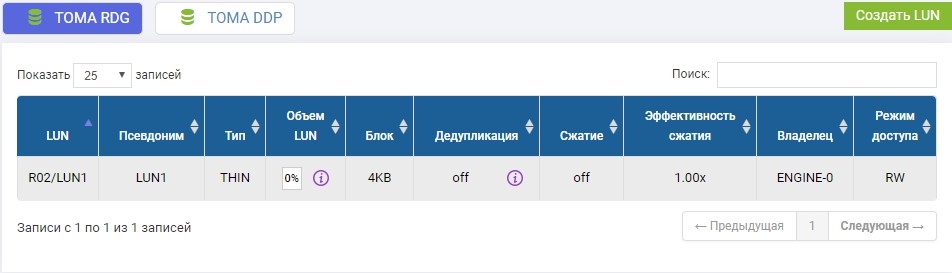
También necesitamos crear el mismo LUN en un sistema de almacenamiento remoto de volumen idéntico. Nosotros creamos Para evitar confusiones, el LUN remoto se llamará LUN1R
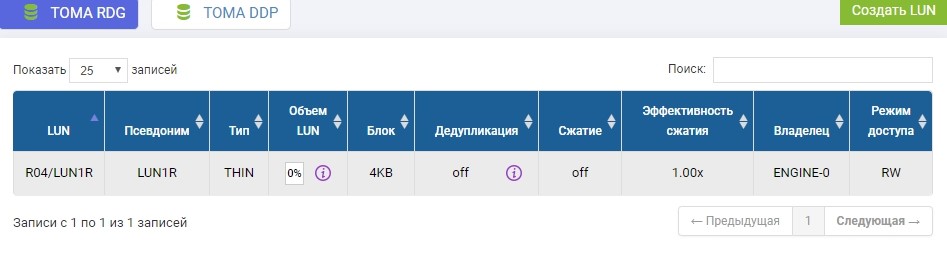
Si necesitáramos tomar un LUN que ya existe, en el momento de la configuración de la réplica, este LUN productivo necesitaría ser desmontado del host, y en el sistema de almacenamiento remoto simplemente cree un LUN vacío de tamaño idéntico.
La configuración de almacenamiento se completa, procedemos a la creación de la regla de replicación.
Configurar reglas de replicación o enlaces de replicación
Después de crear LUN en el almacenamiento, que será el principal en este momento, configuramos la regla de replicación LUN1 en SHD1 en LUN1R en SHD2.
La configuración se realiza en el menú Replicación remota.
Crea una regla. Para hacer esto, especifique el destinatario de la réplica. También especificamos el nombre de la conexión y el tipo de replicación (síncrona o asíncrona).
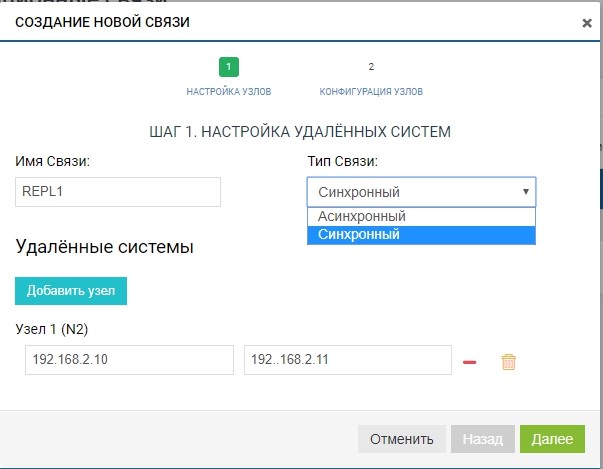
En el campo "sistemas remotos", agregue nuestro SHD2. Para agregar, debe usar el almacenamiento de IP de gestión (MGR) y el nombre del LUN remoto al que replicaremos (en nuestro caso, LUN1R). La administración de IP solo se necesita en la etapa de agregar comunicación; el tráfico de replicación a través de ellas no se transmitirá; para esto, se utilizará el VIP configurado previamente.
Ya en esta etapa, podemos agregar más de un sistema remoto para la topología "uno a muchos": haga clic en el botón "agregar nodo", como en la figura a continuación.
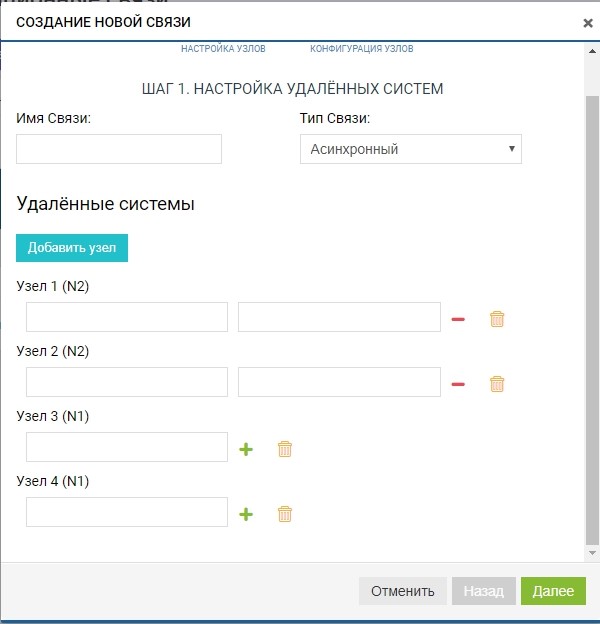
En nuestro caso, el sistema remoto es uno, por lo que estamos limitados a esto.
La regla está lista. Tenga en cuenta que se agrega automáticamente a todos los participantes de la replicación (en nuestro caso, hay dos de ellos). Puede crear tantas reglas como desee, para cualquier número de LUN y en cualquier dirección. Por ejemplo, para equilibrar la carga, podemos replicar parte de los LUN de SHD1 a SHD2, y la otra parte, por el contrario, de SHD2 a SHD1.
SHD1. Inmediatamente después de la creación, comenzó la sincronización.
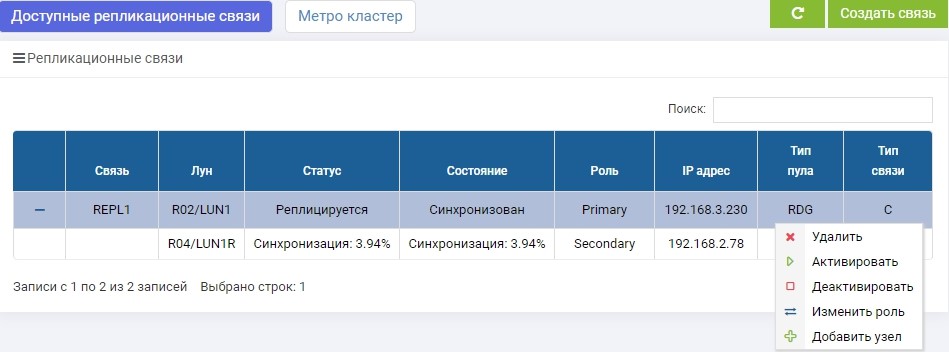
SHD2. Vemos la misma regla, pero la sincronización ya ha finalizado.
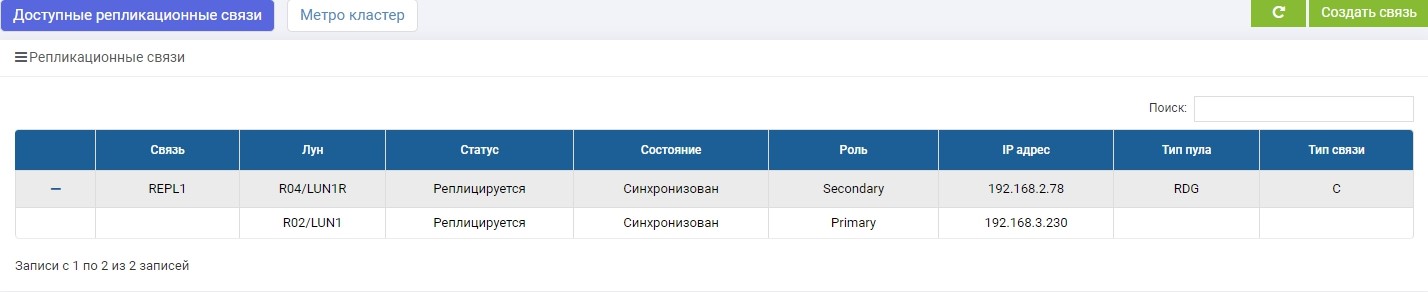
LUN1 en SHD1 tiene el rol de Primario, es decir, está activo. LUN1R en SHD2 está en el rol de Secundario, es decir, está en espera, en caso de falla de SHD1.
Ahora podemos conectar nuestro LUN al host.
Haremos la conexión a través de iSCSI, aunque se puede hacer a través de FC. Configurar el mapeo para iSCSI LUN en una réplica prácticamente no es diferente del escenario habitual, por lo que no discutiremos esto en detalle aquí. En todo caso, este proceso se describe en el artículo de Configuración rápida .
La única diferencia es que creamos mapeo en el menú "Mapeo de replicación".
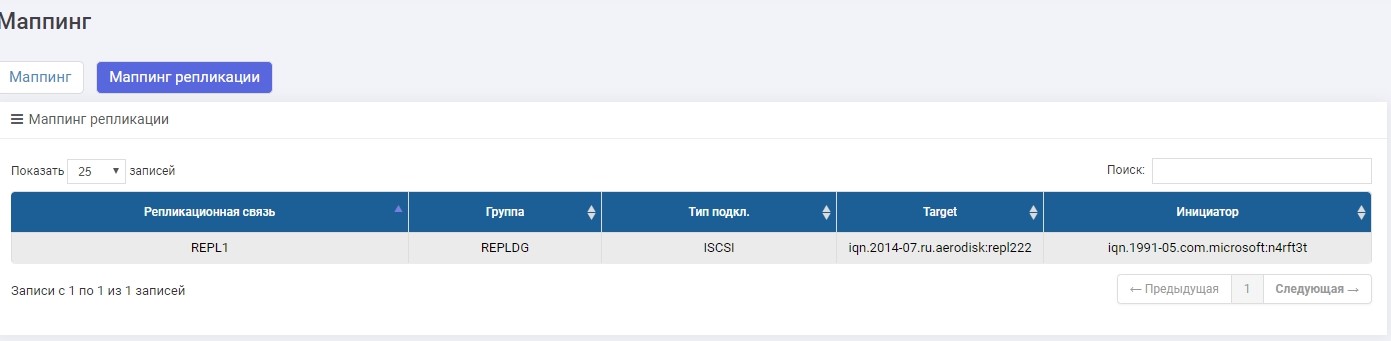
Configure el mapeo, dele LUN al host. El anfitrión vio un LUN.
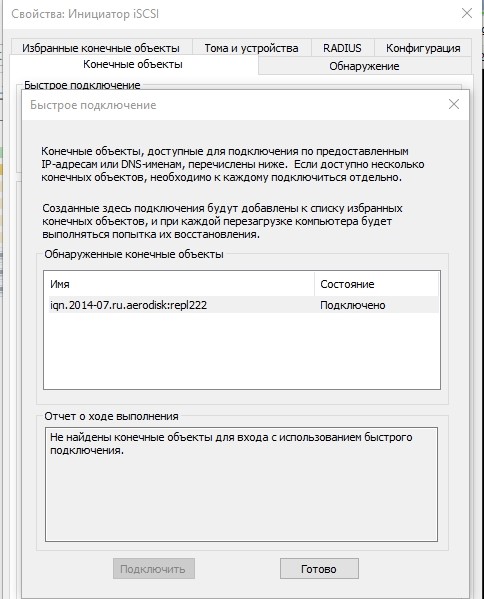
Formatee al sistema de archivos local.
Eso es todo, la configuración está completa. A continuación irán las pruebas.
Prueba
Probaremos tres escenarios principales.
- Cambio de roles del personal Secundario> Primario. Es necesario un cambio de rol regular en caso de que, por ejemplo, necesitemos principalmente un centro de datos para realizar algunas operaciones preventivas, y durante este tiempo, para que los datos estén disponibles, transferimos la carga al centro de datos de respaldo.
- Conmutación por error de roles Secundario> Primario (falla del centro de datos). Este es el escenario principal para el que hay replicación, que puede ayudar a sobrevivir a una falla completa del centro de datos sin detener a la compañía por mucho tiempo.
- Canales de comunicación rotos entre centros de datos. Verificando el comportamiento correcto de los dos sistemas de almacenamiento en condiciones en que, por alguna razón, el canal de comunicación entre los centros de datos no está disponible (por ejemplo, la excavadora cavó en el lugar equivocado y rasgó la óptica oscura).
Para comenzar, comenzaremos a escribir datos en nuestro LUN (escribimos archivos con datos aleatorios). Inmediatamente vemos que se está utilizando el canal de comunicación entre los sistemas de almacenamiento. Esto es fácil de entender si abre la supervisión de carga de los puertos responsables de la replicación.
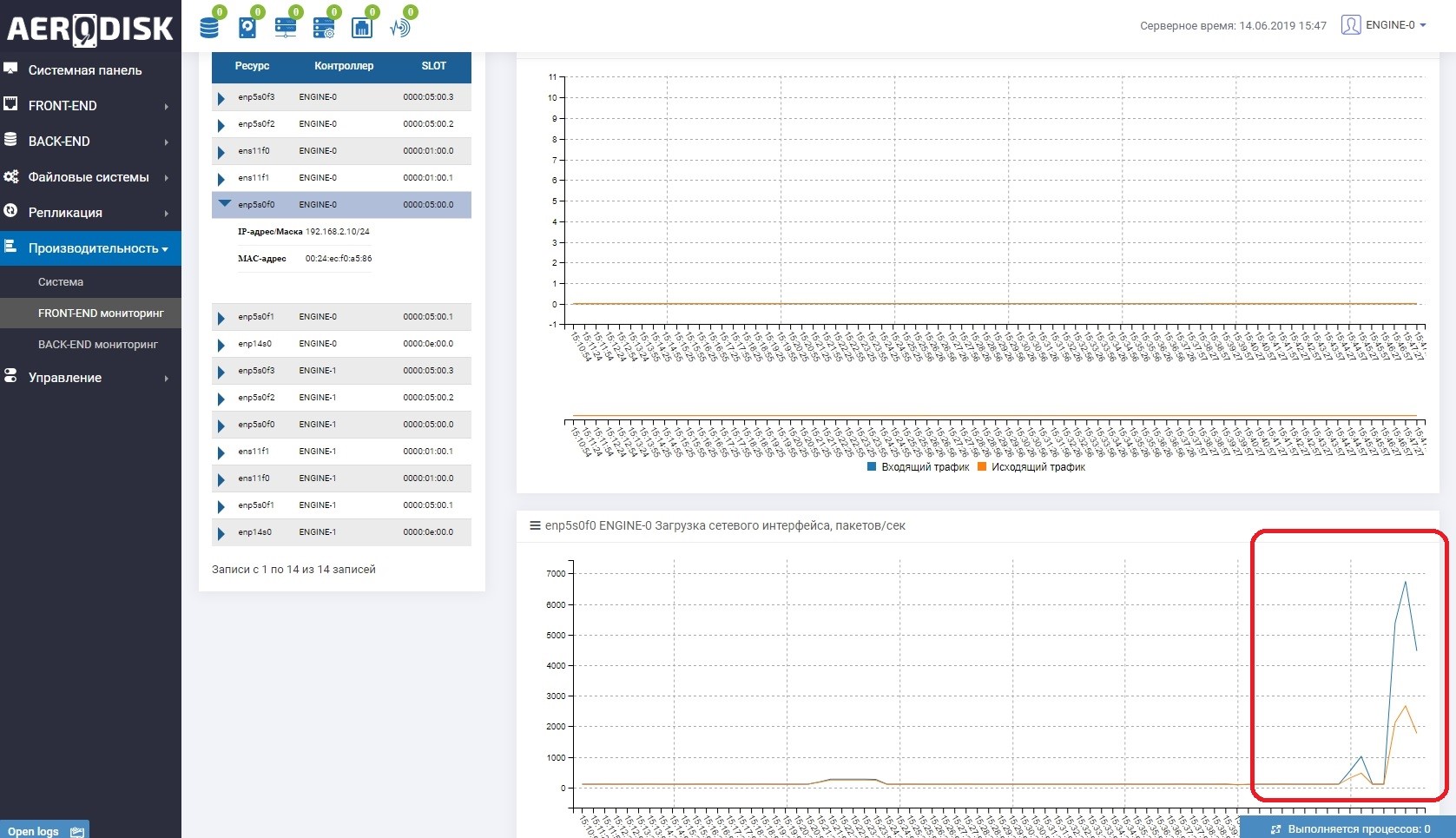
En ambos sistemas de almacenamiento ahora hay datos "útiles", podemos comenzar la prueba.
Por si acaso, echemos un vistazo a las sumas hash de uno de los archivos y anótelo.
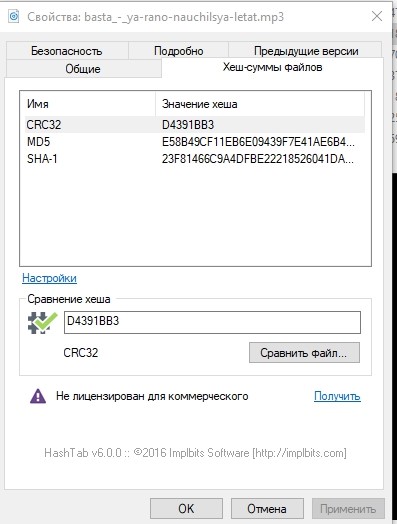
Cambio de roles del personal
La operación de cambiar roles (cambiar la dirección de replicación) se puede realizar desde cualquier sistema de almacenamiento, pero aún debe ir a ambos, ya que deberá deshabilitar la asignación en Primaria y habilitarla en Secundaria (que se convertirá en Primaria).
Quizás ahora surge una pregunta razonable: ¿por qué no automatizar esto? Respondemos: todo es simple, la replicación es una herramienta simple de tolerancia a desastres basada únicamente en operaciones manuales. Para automatizar estas operaciones, hay un modo de clúster metropolitano, totalmente automatizado, pero su configuración es mucho más complicada. Escribiremos sobre la configuración del clúster de metro en el próximo artículo.
Deshabilite la asignación en el almacenamiento principal para asegurarse de que se detiene la grabación.
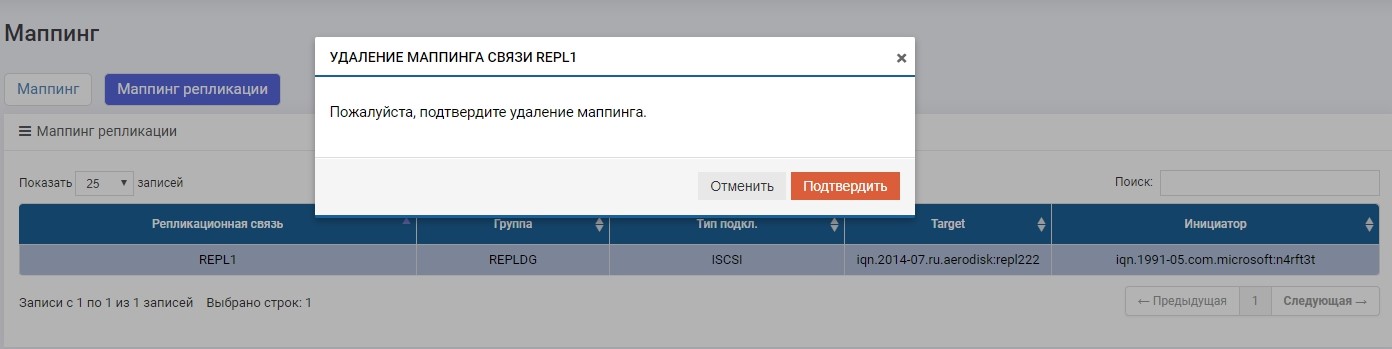
Luego, en uno de los sistemas de almacenamiento (no importa, en el primario o en el de respaldo) en el menú Replicación remota, seleccione nuestra conexión REPL1 y haga clic en "Cambiar rol".
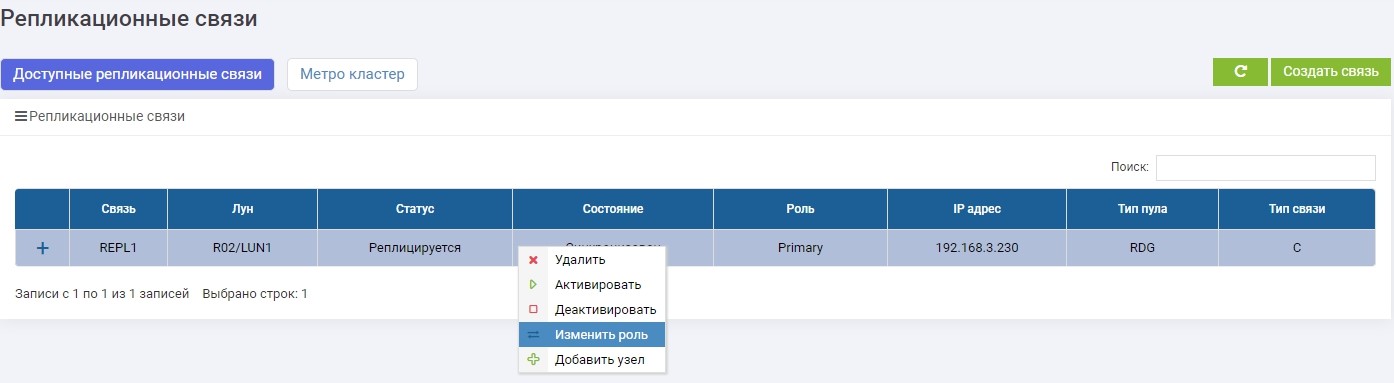
Después de unos segundos, LUN1R (almacenamiento de respaldo) se convierte en Primario.
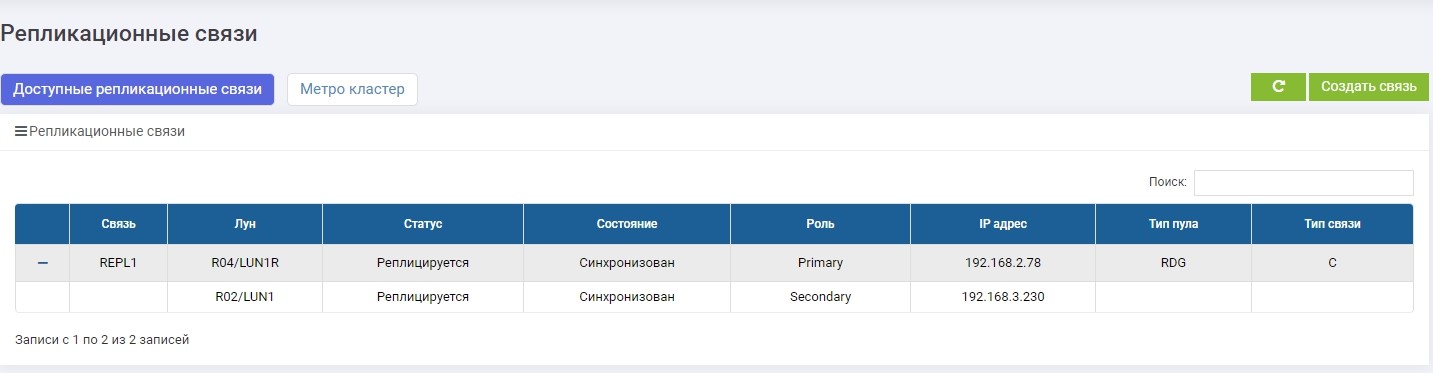
Hacemos mapeo LUN1R con SHD2.
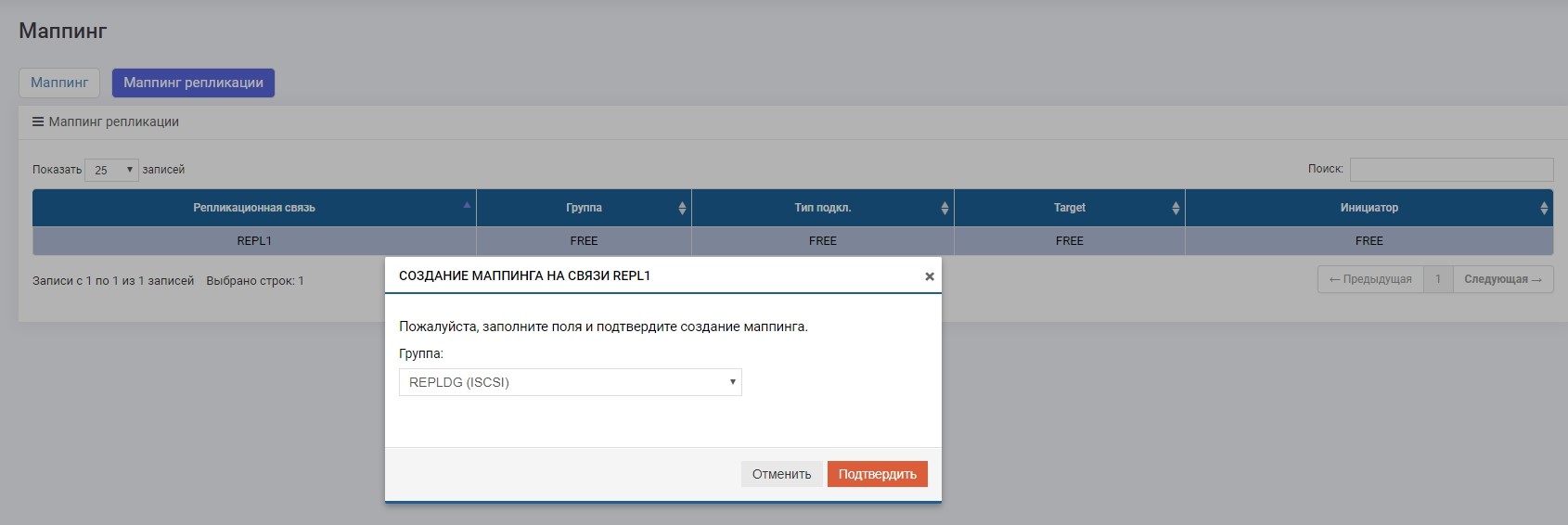
Después de eso, nuestra unidad E: se aferra automáticamente al host, solo que esta vez "voló" con LUN1R.
Por si acaso, compare las cantidades de hash.
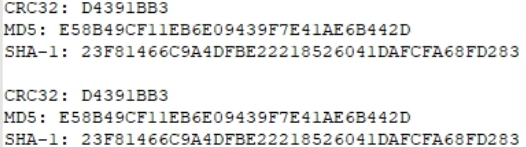
Idéntico Prueba aprobada
Conmutación por error Falla del centro de datos
Por el momento, el almacenamiento principal después del cambio regular es SHD2 y LUN1R, respectivamente. Para simular un accidente, apagamos los dos controladores SHD2.
El acceso a él ya no es.
Observamos lo que está sucediendo en el almacenamiento 1 (copia de seguridad en este momento).

Vemos que el LUN primario (LUN1R) no está disponible. Apareció un mensaje de error en los registros, en el panel de información, así como en la propia regla de replicación. En consecuencia, los datos del host no están disponibles actualmente.
Cambie el rol de LUN1 a Primario.
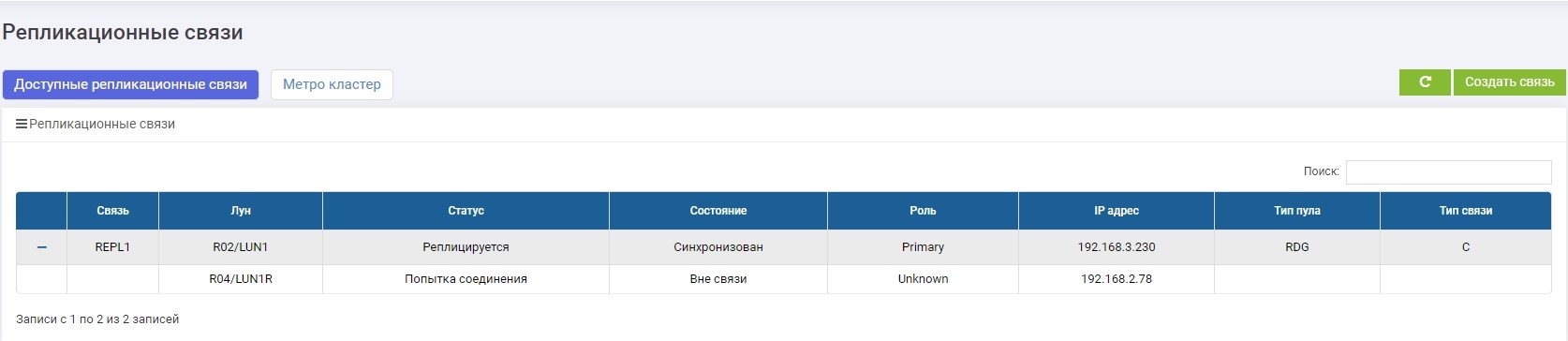
Asignación de asuntos al anfitrión.

Asegúrese de que la unidad E aparezca en el host.
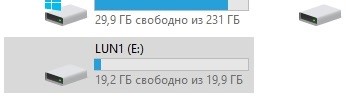
Comprueba el hash.
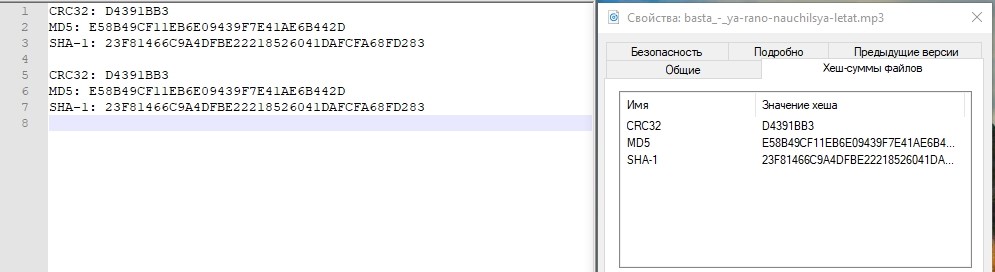
Todo esta bien. El centro de almacenamiento experimentó una caída en el centro de datos, que estaba activo. El tiempo aproximado que pasamos conectando la "reversión" de la replicación y conectando el LUN desde el centro de datos de respaldo fue de aproximadamente 3 minutos. Está claro que en el producto real todo es mucho más complicado, y además de las acciones con sistemas de almacenamiento, debe realizar muchas más operaciones en la red, en los hosts y en las aplicaciones. Y en la vida, este período de tiempo será mucho más largo.
Aquí quiero escribir que todo, la prueba se completó con éxito, pero no nos apresuremos. El almacenamiento principal "miente", sabemos que cuando ella "cayó", estaba en el papel de Primaria. ¿Qué pasa si ella se enciende de repente? Habrá dos roles principales, que es igual a la corrupción de datos? Lo comprobaremos ahora.
De repente vamos a encender el almacenamiento subyacente.
Se carga durante varios minutos y después de eso vuelve a funcionar después de una breve sincronización, pero ya en el rol de Secundario.

Todo esta bien El cerebro partido no sucedió. Pensamos en esto, y siempre después de que la caída del sistema de almacenamiento se eleva en el rol de Secundario, independientemente de qué rol fuera "en la vida". Ahora podemos decir con certeza que la prueba de falla del centro de datos fue exitosa.
Falla de los canales de comunicación entre los centros de datos.
La tarea principal de esta prueba es asegurarse de que el sistema de almacenamiento no comenzará a enloquecer si pierde temporalmente los canales de comunicación entre los dos sistemas de almacenamiento y luego vuelve a aparecer.
Entonces Desconectamos los cables entre los sistemas de almacenamiento (imagine que una excavadora los cavó).
En Primaria vemos que no hay conexión con Secundaria.
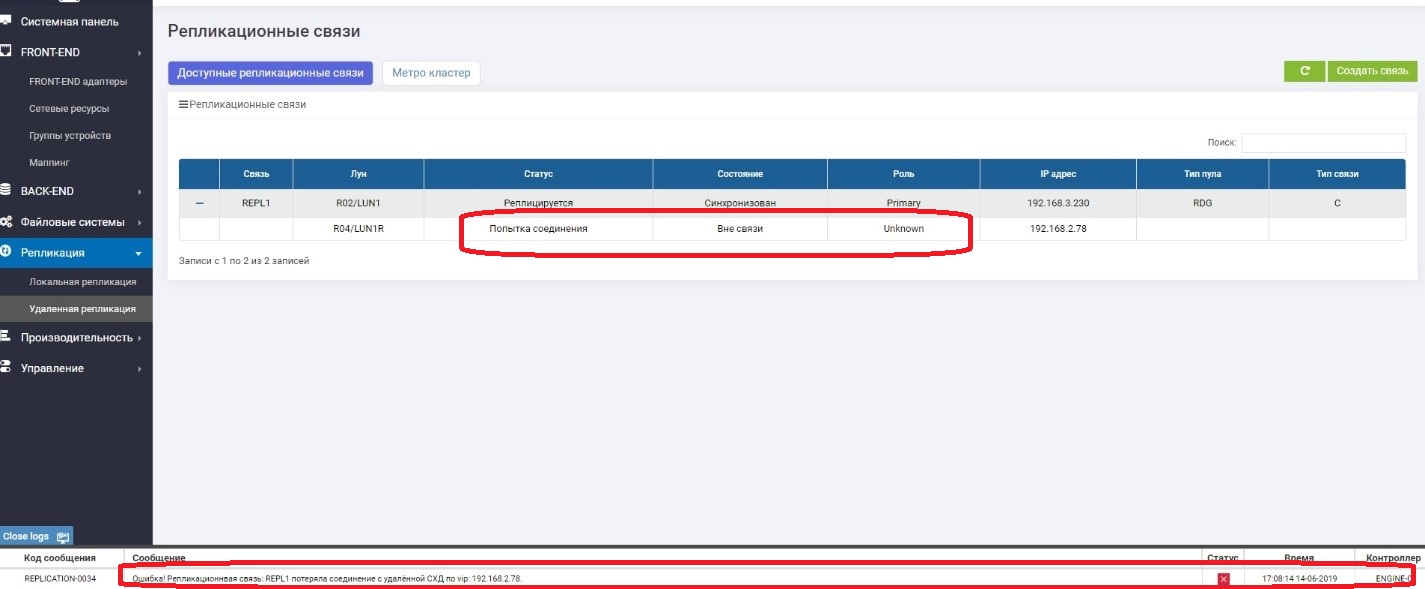
En Secundario, vemos que no hay conexión con Primario.
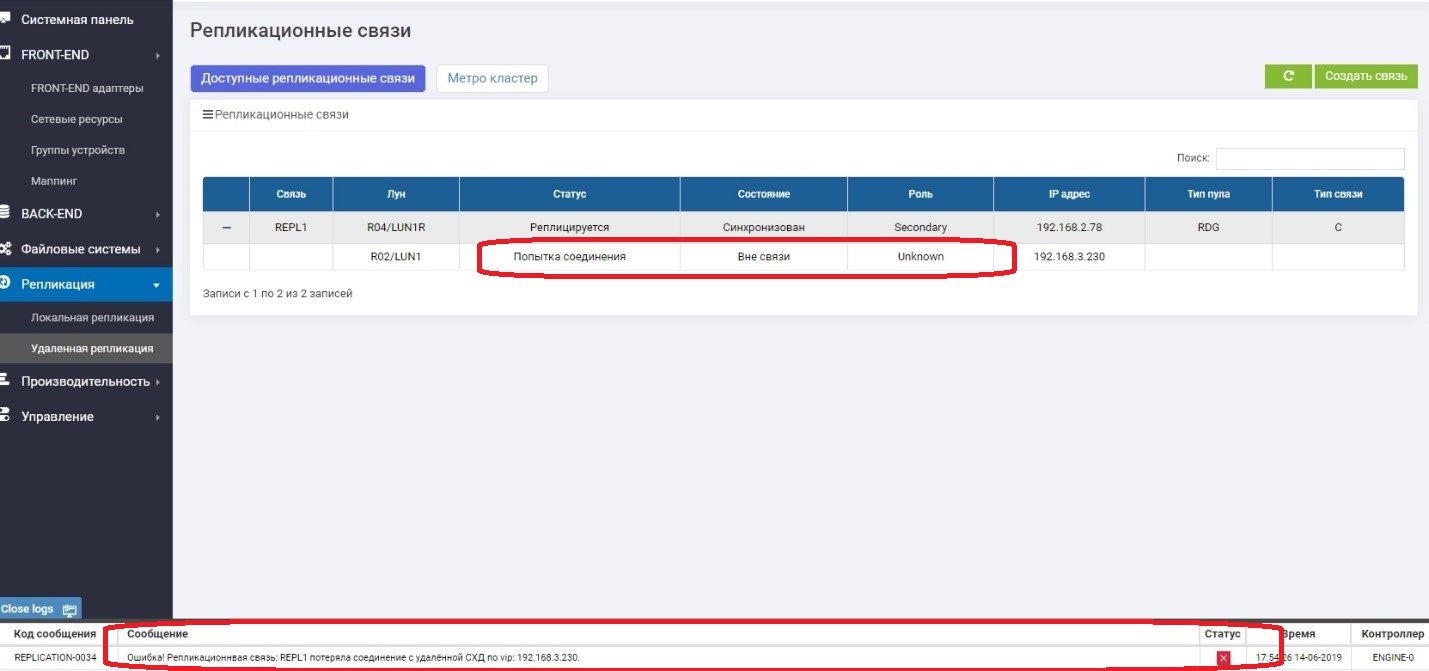
Todo funciona bien y seguimos escribiendo datos en el sistema de almacenamiento principal, es decir, ya se garantiza que diferirán del sistema de respaldo, es decir, se han "ido".
En unos minutos estamos arreglando el canal de comunicación. Tan pronto como los sistemas de almacenamiento se hayan visto, la sincronización de datos se activa automáticamente. No se requiere nada del administrador.

.
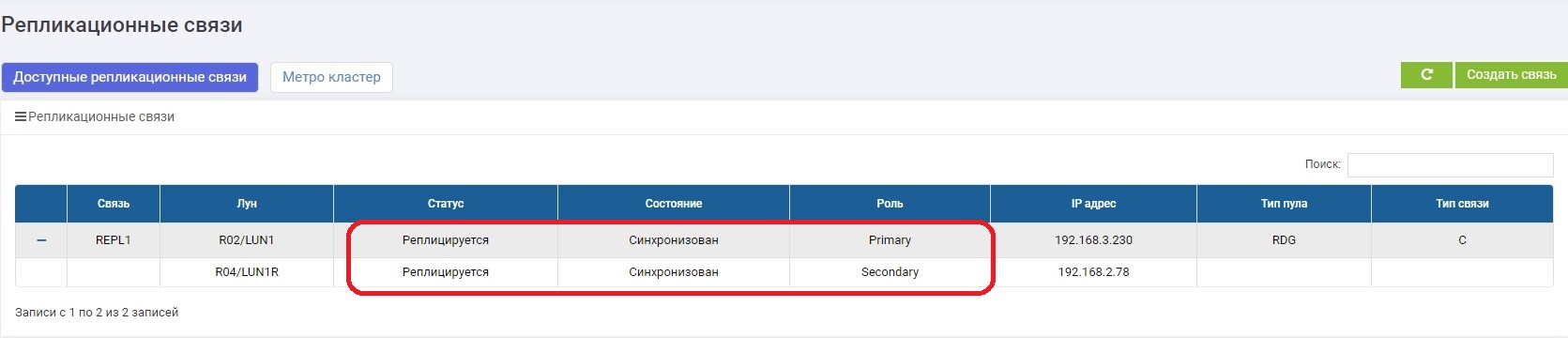
, , .
– , , . .
, - . . , .
active-active, , .
, .
.