Hola, queridos Habrausers! Este artículo trata sobre la web 3.0, Internet con descentralización. La Web 3.0 introduce el concepto de descentralización como la base de Internet moderna; muchos sistemas y redes de computadoras necesitan propiedades de seguridad y descentralización para sus necesidades. La solución de descentralización se llama tecnología de registro distribuido o blockchain.

Blockchain es un registro distribuido. Se puede considerar como una gran base de datos que vive para siempre y no cambia en la historia, la cadena de bloques se usa como base para aplicaciones o servicios web descentralizados.
En esencia, blockchain no es solo una base de datos, es una oportunidad para aumentar la confianza entre los participantes de la red con la capacidad de ejecutar la lógica empresarial en la red.
El consenso bizantino aumenta la confiabilidad de la red resuelve el problema de consistencia
La escalabilidad que brinda DLT está cambiando las redes comerciales existentes.
Blockchain ofrece nuevas ventajas muy importantes:
- Prevención de errores costosos.
- Transacciones transparentes.
- Digitalización de bienes reales.
- Contratos inteligentes.
- Rapidez y seguridad de los pagos.
Opporty PoE es un proyecto cuyo objetivo es estudiar protocolos criptográficos y mejorar las soluciones existentes de DLT y blockchain.
La mayoría de los sistemas de registro distribuidos públicos no tienen propiedades de escalabilidad; su rendimiento es bastante bajo. Por ejemplo, ethereum procesa solo ~ 20 tx / s.
Se crearon muchas soluciones para aumentar la propiedad de escalabilidad y no perder la descentralización (como saben, solo se pueden conocer 2 de 3: escalabilidad, seguridad, descentralización).
Una de las más efectivas es una solución que usa cadenas laterales.
Concepto de plasma
El concepto es que la cadena raíz procesa una pequeña cantidad de confirmaciones de cadenas secundarias, de modo que la cadena raíz actúa como la capa más segura y final para almacenar todos los estados intermedios. Cada cadena secundaria funciona como su propia cadena de bloques con su propio algoritmo de consenso, pero hay algunas advertencias importantes.
- Los contratos inteligentes se crean en la cadena raíz y actúan como un punto de control en la cadena secundaria en la cadena raíz.
- Se crea una cadena secundaria que funciona como su propia cadena de bloques con su propio consenso. Todos los estados en la cadena de procesos secundarios están protegidos por pruebas de fraude, que aseguran que todas las transiciones entre estados sean válidas y apliquen un protocolo de retiro.
- Los contratos inteligentes específicos para dapp o child-chain (lógica de aplicación) se pueden implementar en la child chain.
- Las herramientas necesarias se pueden transferir de la cadena raíz a la cadena secundaria.
Los validadores tienen incentivos económicos para actuar honestamente y enviar comentarios a la cadena raíz, la capa de la liquidación final de la transacción.
Como resultado, los usuarios de dapp que trabajan en la cadena secundaria no deberían interactuar en absoluto con la cadena raíz. Además, pueden retirar su dinero a la cadena raíz cuando lo deseen, incluso si la cadena secundaria está pirateada. Estas salidas de la cadena infantil permiten a los usuarios almacenar sus fondos de manera segura utilizando pruebas de Merkle, lo que confirma la propiedad de una cierta cantidad de fondos.
Las principales ventajas de Plasma están relacionadas con su capacidad para facilitar significativamente los cálculos que actualmente sobrecargan la cadena principal. Además, la cadena de bloques Ethereum puede procesar conjuntos de datos más extensos y más paralelos. El tiempo tomado de la cadena raíz también se transfiere a los nodos Ethereum, que reciben menores requisitos de procesamiento y almacenamiento.
Plasma Cash es un diseño que proporciona a los tokens de red números de serie únicos que los convierten en tokens únicos. Las ventajas de esto incluyen la ausencia de la necesidad de confirmaciones, un soporte más simple para todos los tipos de tokens (incluidos los tokens no fungibles) y la mitigación contra las salidas masivas de la cadena secundaria.
El problema del plasma está relacionado con el concepto de "salidas masivas" de la cadena infantil. En este escenario, una salida simultánea coordinada de la cadena hija podría conducir a una falta de potencia informática para retirar todos los fondos. Como resultado, los usuarios pueden perder dinero.
Opciones de implementación de plasma

El plasma base tiene muchas opciones de implementación.
Las principales diferencias son:
- almacenar información sobre el método de almacenamiento y presentación del estado,
- tipos de tokens (divisibles indivisibles),
- seguridad de transacción
- tipo de algoritmo de consenso, etc.
Las principales variaciones de plasma:
- Basado en UTXO: cada transacción consta de entradas y salidas: una transacción puede realizarse y gastarse, la lista de transacciones no gastadas es un estado de la propia cadena secundaria.
- Basado en cuenta: simplemente contiene un reflejo de cada cuenta-cuenta y su saldo, este tipo se usa en ethereum ya que cada cuenta puede ser de dos tipos: una cuenta de usuario y una cuenta de contrato inteligente. La ventaja de este tipo de almacenamiento de estado es su simplicidad, y la desventaja es que esta opción no es escalable (la propiedad especial nonce se usa para evitar que la transacción se ejecute dos veces).
El propósito de este artículo es explicar las estructuras de datos que se usan en la cadena de bloques de Plasma Cash.
Para comprender exactamente cómo funciona el compromiso, debe aclarar el concepto del árbol de Merkle.
Merkle árboles su uso en plasma
Los árboles Merkle son una estructura de datos extremadamente importante en el mundo blockchain. En esencia, los árboles Merkle nos dan la capacidad de capturar algunos conjuntos de datos de una manera que los oculta, pero permite a los usuarios probar que parte de la información estaba en el conjunto. Por ejemplo, si tengo diez números, puedo crear pruebas para estos números y luego probar que un número en particular estaba en este conjunto de números. Estas pruebas tienen un tamaño constante pequeño, lo que las hace baratas de publicar en Ethereum.
Puede usar esto para un conjunto de transacciones. También puede probar que una transacción en particular se encuentra en este conjunto de transacciones. Esto es exactamente lo que hace el operador. Cada bloque consta de un conjunto de transacciones que se convierten en un árbol Merkle. La raíz de este árbol es la prueba, que se publica en Ethereum junto con cada bloque de plasma.
Los usuarios deberían poder retirar sus fondos de la cadena de plasma. Cuando los usuarios desean salir de la cadena de plasma, envían la transacción de "salida" a Ethereum.
Plasma Cash usa el árbol Merkle especial que hace posible no validar todo el bloque sino validar solo aquellas ramas que corresponden al token del usuario.
Es decir, para transferir un token, debe revisar el historial y escanear solo los tokens que un determinado usuario necesita, al transferir un token, el usuario simplemente pasa el historial completo a otro usuario y ya puede autenticar toda la historia, y lo más importante, hacerlo muy rápidamente.

Estructuras de datos de Plasma Cash para almacenar el estado y el historial
Sin embargo, es necesario usar solo algunos árboles de Merkle, porque es necesario obtener prueba de inclusión y también prueba de no inclusión de la transacción en el bloque, por ejemplo
- Escaso árbol de merkle
- Patricia trie
Opporty completó su implementación de Sparse Merkle Tree y Patricia Trie
Un árbol de Merkle escaso es similar a un árbol de Merkle estándar, excepto que los datos que contiene están indexados y cada punto de datos se coloca en una hoja que coincide con el índice de ese punto de datos.
Digamos que tenemos un árbol Merkle con cuatro hojas. Llenaremos este árbol con algunas letras (A, D) para demostración. La letra A es la primera letra del alfabeto, por lo que debemos ponerla en la primera hoja. Del mismo modo, podemos poner D en la cuarta hoja.
Entonces, ¿qué sucede en la segunda y tercera hojas? Solo los dejamos vacíos. Más precisamente, se coloca un valor especial (por ejemplo, cero) en lugar de colocar la letra.
El árbol finalmente se ve así:

La prueba de inclusión funciona igual que en un árbol Merkle normal. ¿Qué sucede si queremos demostrar que C no es parte de este árbol Merkle? Es facil! Sabemos que si C fuera parte de un árbol, estaría en la tercera hoja. Si C no es parte del árbol, entonces la tercera hoja debe ser cero.
Todo lo que se necesita es la prueba estándar de la inclusión de Merkle, que muestra que la tercera hoja es cero.
¡La mejor parte de un árbol Merkle escaso es que realmente representan tiendas de valores clave dentro del árbol Merkle!
Aquí hay parte del código del protocolo PoE que implementa la construcción Sparse Merkle Tree.
class SparseTree { //... buildTree() { if (Object.keys(this.leaves).length > 0) { this.levels = [] this.levels.unshift(this.leaves) for (let level = 0; level < this.depth; level++) { let currentLevel = this.levels[0] let nextLevel = {} Object.keys(currentLevel).forEach((leafKey) => { let leafHash = currentLevel[leafKey] let isEvenLeaf = this.isEvenLeaf(leafKey) let parentLeafKey = leafKey.slice(0, -1) let neighborLeafKey = parentLeafKey + (isEvenLeaf ? '1' : '0') let neighborLeafHash = currentLevel[neighborLeafKey] if (!neighborLeafHash) { neighborLeafHash = this.defaultHashes[level] } if (!nextLevel[parentLeafKey]) { let parentLeafHash = isEvenLeaf ? ethUtil.sha3(Buffer.concat([leafHash, neighborLeafHash])) : ethUtil.sha3(Buffer.concat([neighborLeafHash, leafHash])) if (level == this.depth - 1) { nextLevel['merkleRoot'] = parentLeafHash } else { nextLevel[parentLeafKey] = parentLeafHash } } }) this.levels.unshift(nextLevel) } } } }
Este código es bastante trivial. Tenemos una tienda de valores clave con prueba de inclusión / no inclusión.
En cada iteración, se llena un nivel específico del árbol final, comenzando con el último. Dependiendo de qué clave de la hoja actual sea par o impar, tomamos dos hojas adyacentes y consideramos el hash del nivel actual. Si llegamos al final, escribimos un MerkleRoot único, un hash común.
¡Debe comprender que este árbol ya está lleno de valores inicialmente vacíos! Y si almacenamos una gran cantidad de token IDS. ¡tenemos un gran tamaño de árbol y se tarda mucho en generarlo!
Hay muchas soluciones para esta falta de optimización, pero Opporty decidió cambiar este árbol a Patricia Trie.
Patricia Trie es una mezcla de Radix Trie y Merkle Trie.
¡La clave de datos Radix Trie almacenará la ruta de datos en sí misma! ¡Esto le permite crear una estructura de datos optimizada para la memoria!
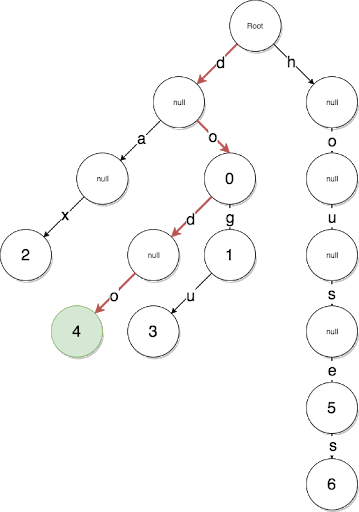
Implementación de la oportunidad
buildNode(childNodes, key = '', level = 0) { let node = {key} this.iterations++ if (childNodes.length == 1) { let nodeKey = level == 0 ? childNodes[0].key : childNodes[0].key.slice(level - 1) node.key = nodeKey let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(nodeKey)), childNodes[0].hash]) node.hash = ethUtil.sha3(nodeHashes) return node } let leftChilds = [] let rightChilds = [] childNodes.forEach((node) => { if (node.key[level] == '1') { rightChilds.push(node) } else { leftChilds.push(node) } }) if (leftChilds.length && rightChilds.length) { node.leftChild = this.buildNode(leftChilds, '0', level + 1) node.rightChild = this.buildNode(rightChilds, '1', level + 1) let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(node.key)), node.leftChild.hash, node.rightChild.hash]) node.hash = ethUtil.sha3(nodeHashes) } else if (leftChilds.length && !rightChilds.length) { node = this.buildNode(leftChilds, key + '0', level + 1) } else if (!leftChilds.length && rightChilds.length) { node = this.buildNode(rightChilds, key + '1', level + 1) } else if (!leftChilds.length && !rightChilds.length) { throw new Error('invalid tree') } return node }
Es decir, pasamos recursivamente y construimos subárboles secundarios izquierdo y derecho por separado. Al mismo tiempo, ¡construir la llave es como un camino en este árbol!
¡Esta solución es aún más trivial y funciona más rápido mientras se optimiza bastante! De hecho, el árbol de Patricia se puede optimizar aún más mediante la introducción de nuevos tipos de nodos: nodo de extensión, nodo de rama, etc., como se hace en el protocolo ethereum, pero esta implementación satisface todas nuestras condiciones: obtuvimos una estructura de datos rápida y con optimización de memoria.
Al implementar estas estructuras de datos, Opporty hizo posible escalar Plasma Cash ya que permite verificar el historial del token y la inclusión de no incluir el token en el árbol. Esto le permite acelerar en gran medida la validación de los bloques y la propia cadena de plasma del niño.
Enlaces utiles:
- Papel blanco plasma
- Git Hub
- Descripción de casos de uso y arquitectura
- Papel de red de rayos