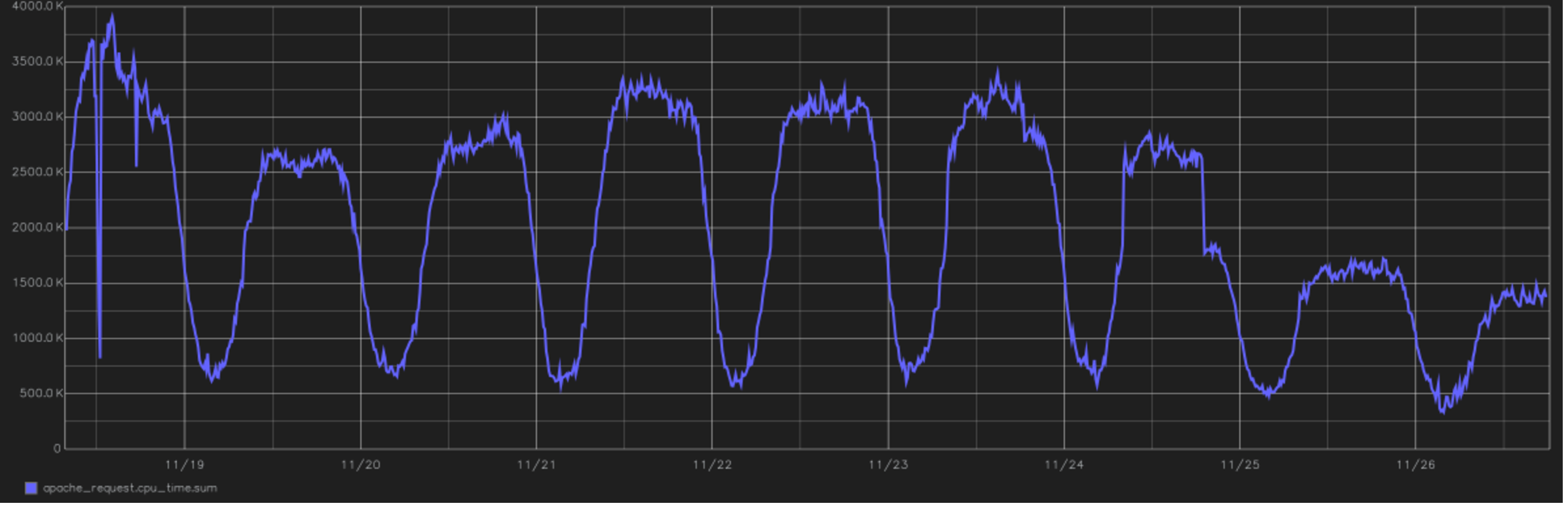
 Este es uno de los mejores relieves del proyecto. En la imagen, un gráfico del tiempo total empleado por la CPU para procesar todas las solicitudes de los usuarios. Al final puedes ver la transición a PHP 7.0. desde la versión 5.6. Este es el año 2016, cambiando por la tarde del 24 de noviembre.
Este es uno de los mejores relieves del proyecto. En la imagen, un gráfico del tiempo total empleado por la CPU para procesar todas las solicitudes de los usuarios. Al final puedes ver la transición a PHP 7.0. desde la versión 5.6. Este es el año 2016, cambiando por la tarde del 24 de noviembre.Desde el punto de vista de los cálculos, Tutu.ru es principalmente una oportunidad para comprar un boleto desde el punto A al punto B. Para hacer esto, trabajamos una gran cantidad de horarios, almacenamos en caché las respuestas de muchos sistemas de líneas aéreas y periódicamente hacemos consultas de unión increíblemente largas a la base de datos. En general, estamos escritos en PHP y hasta hace poco estábamos completamente en él (si el lenguaje está preparado correctamente, incluso puede construir sistemas en tiempo real en él). Recientemente, las áreas críticas para el rendimiento se han refactorizado en Go.
Constantemente tenemos una deuda técnica . Y esto sucede más rápido de lo que nos gustaría. La buena noticia: no tienes que cubrirlo todo. Malo: a medida que crece la funcionalidad admitida, la deuda técnica también crece proporcionalmente.
En general, la deuda técnica es el costo de cometer un error al tomar una decisión. No predijo algo como el arquitecto, es decir, cometió un error de pronóstico o tomó una decisión en condiciones de información insuficiente. En algún momento, comprende que necesita cambiar algo en el código (a menudo a nivel de arquitectura). Entonces puedes cambiar de inmediato, pero puedes esperar. Si espera, los intereses se apresuraron a la deuda tecnológica. Por lo tanto, es una buena práctica reestructurarlo de vez en cuando. Bueno, o declararte en bancarrota y escribir todo el bloque nuevamente.
Cómo comenzó todo: monolito y funciones generales
El proyecto Tutu.ru comenzó en 2003 como un sitio web habitual de Runet de aquellos tiempos. Es decir, era un montón de archivos en lugar de una base de datos, una página PHP en el frente de HTML + JS. Hubo un par de excelentes trucos de mi colega Yuri, pero será mejor que se lo cuente algún día. Me uní al proyecto en 2006, primero como consultor externo que podía ayudar tanto con el asesoramiento como con un código, y luego, en 2009, me transferí al estado como director técnico. En primer lugar, era necesario ordenar las cosas en la dirección de los boletos aéreos: era la parte más cargada y más compleja de la arquitectura.
En 2006, les recuerdo que había un horario de trenes y la oportunidad de comprar un boleto de tren. Decidimos hacer la sección de boletos aéreos como un proyecto separado, es decir, todo esto se unió solo en el frente. Los tres proyectos (horarios de trenes, ferrocarriles y aéreos) finalmente se escribieron a su manera. En ese momento, el código nos parecía normal, pero algo inacabado. No perfeccionista. Luego se hizo viejo, se cubrió con muletas y en la dirección del ferrocarril se convirtió en una calabaza en 2010.
En el ferrocarril, no tuvimos tiempo para dar deuda técnica. La refactorización no era realista: los problemas estaban en la arquitectura. Decidimos demoler y rehacer todo de nuevo, pero también fue difícil en un proyecto en vivo. Como resultado, solo se dejaron las URL antiguas en el frente, y luego se reescribió bloque por bloque. Como base, tomamos los enfoques utilizados un año antes en el desarrollo del sector de la aviación.
Reescrito en PHP. Luego quedó claro que esta no era la única forma, pero no había alternativas razonables para nosotros. Lo eligieron porque ya tenían experiencia y logros, estaba claro que este es un buen lenguaje en manos de los desarrolladores senior. De las alternativas, C y C ++ fueron increíblemente productivas, pero cualquier reconstrucción o introducción de cambios les pareció una pesadilla. De acuerdo, no se recuerda. Eran una pesadilla.
MS y todo .NET desde el punto de vista de un proyecto de alta carga ni siquiera se consideraron. Entonces no había más opciones que las basadas en Linux. Java es una buena opción, pero exige recursos de la memoria, nunca perdona los errores menores y luego no hizo posible lanzar lanzamientos rápidamente, bueno, o no lo sabíamos. Incluso ahora no consideramos Python como un back-end, solo para tareas de manipulación de datos. JS - puramente debajo del frente. No había desarrolladores de Ruby on Rails entonces (y ahora). Go se fue. Todavía existía Perl, pero los expertos lo calificaron como poco prometedor para el desarrollo web, por lo que también lo abandonaron. PHP queda.
La siguiente historia holiv es PostgreSQL vs. MySQL. En algún lugar mejor, en otro lugar. En general, fue una buena práctica elegir lo que resultó mejor, por lo que elegimos MySQL y sus bifurcaciones.
El enfoque de desarrollo era monolítico, entonces simplemente no había otros enfoques, sino con la estructura ortogonal de las bibliotecas. Estos son los inicios del enfoque moderno centrado en la API, cuando cada biblioteca tiene una fachada exterior, para lo cual puede extraer directamente dentro del código desde otras partes del proyecto. Las bibliotecas se escribieron en "capas" cuando cada nivel tiene un formato específico en la entrada y pasa un cierto formato al código, y las pruebas unitarias giran entre ellos. Es decir, algo así como un desarrollo basado en pruebas, pero pixelado y aterrador.
Todo esto se alojó en varios servidores, lo que hizo posible escalar bajo carga. Pero al mismo tiempo, la base del código de diferentes proyectos se cruzó con bastante fuerza a nivel del sistema. De hecho, esto significaba que los cambios en el proyecto ferroviario podrían afectar a nuestro propio avión. Y tocado a menudo. Por ejemplo, en el ferrocarril era necesario ampliar el trabajo con pagos; esta es una revisión de la biblioteca compartida. Y el avión funciona con él, por lo tanto, se necesitan pruebas conjuntas. Examinamos las dependencias con pruebas, y esto fue más o menos normal. Incluso en 2009, el método estaba bastante avanzado. Pero aún así, la carga podría agregar otro de un recurso. Hubo una intersección en las bases de datos, lo que condujo a efectos desagradables en forma de frenos en todo el sitio con problemas locales en un producto. Railway mató el avión varias veces en el disco debido a las fuertes consultas a la base de datos.
Escalamos agregando instancias y equilibrando entre ellas. Monolito como es.
Edad del neumático
Luego seguimos un camino bastante marginal. Por un lado, comenzamos a aislar los servicios (hoy este enfoque se llama microservicio, pero no conocíamos la palabra "micro"), pero para la interacción comenzamos a usar el bus para la transferencia de datos, en lugar de REST o gRPC, como lo hacen ahora. Elegimos AMQP como protocolo y RabbitMQ como agente de mensajes. En ese momento, habíamos dominado el lanzamiento de demonios para PHP (sí, hay una implementación de fork () completamente funcional y todo lo demás para trabajar con procesos), ya que durante mucho tiempo en el monolito utilizamos Gearman para paralelizar las solicitudes a los sistemas de reserva .
Hicieron un corredor encima del conejo, y resultó que todo esto realmente no vive bajo carga. Algún tipo de pérdidas de red, retransmisiones, retrasos. Por ejemplo, un grupo de varios intermediarios "listos para usar" se comporta de manera algo diferente a lo indicado por el desarrollador (nunca sucedió antes, y de nuevo). En general, aprendieron mucho. Pero al final, obtuvimos los SLA requeridos para los servicios. Por ejemplo, el servicio RPS más cargado tiene a 400 rps, el percentil 99 de ida y vuelta de cliente a cliente, incluido el bus y el procesamiento del servicio del orden de 35 ms. Ahora en total en el autobús observamos unos 18 krps.
Luego vino la dirección de los autobuses. Inmediatamente lo escribimos sin un monolito en la arquitectura del servicio. Como todo estaba escrito desde cero, resultó muy bien, rápida y convenientemente, aunque era necesario refinar constantemente las herramientas para un nuevo enfoque. Sí, todo esto giraba en máquinas virtuales, dentro de las cuales los demonios PHP se comunican a través del bus. Los demonios comenzaron dentro de los contenedores Docker, pero no había soluciones para la orquestación como Openshift o Kubernetes. En 2014, apenas comenzábamos a hablar de ello, pero no consideramos ese enfoque de ventas.
Si compara cuántos boletos de autobús se venden en comparación con los boletos de avión o tren, obtendrá una gota en el cubo. Y en trenes y aviones, mudarse a una nueva arquitectura era difícil, porque había una funcionalidad funcional, una carga real, y siempre había una opción entre hacer algo nuevo o gastar dinero en pagar una deuda técnica.
Pasar a los servicios es algo bueno, pero largo, pero ahora debe lidiar con la carga y la confiabilidad. Por lo tanto, en paralelo, comenzaron a tomar medidas específicas para mejorar la vida del monolito. Los backends se dividieron en tipos de productos, es decir, comenzaron a controlar de manera más flexible el enrutamiento de las solicitudes según su tipo: aire por separado del ferrocarril, etc. Fue posible predecir la carga, escalar de forma independiente. Cuando supieron que en los ferrocarriles, por ejemplo, el pico de las ventas de Año Nuevo, se agregaron varias instancias de máquinas virtuales. Luego comenzó exactamente 45 días antes del último día hábil del año, y del 14 al 15 de noviembre tuvimos una doble carga. Ahora FPK y otras compañías han realizado muchos boletos con el inicio de las ventas durante 60, 90 e incluso 120 días, y este pico se ha extendido. Pero el último día hábil de abril siempre habrá una carga en los trenes eléctricos antes de mayo, y todavía hay picos. Pero sobre la estacionalidad de los boletos y las formas de migración de la desmovilización, mis colegas del ferrocarril lo dirán mejor, y continuaré sobre la arquitectura.
En algún lugar en 2014, comenzaron a derbanar una gran base de datos de muchos pequeños. Esto era importante porque estaba creciendo peligrosamente y la caída era crítica. Comenzamos a asignar pequeñas bases de datos separadas (para 5-10 tablas) para una funcionalidad específica, de modo que otros servicios afectarían menos interrupciones, y para que todo esto se pudiera escalar más fácilmente. Vale la pena señalar que para el equilibrio y la escala de carga utilizamos réplicas para la lectura. Recuperar réplicas para una gran base después de un error de replicación podría llevar horas, y todo este tiempo tuve que "volar en libertad condicional y en un ala". Los recuerdos de tales períodos todavía causan un escalofrío desagradable en algún lugar entre las orejas. Ahora tenemos alrededor de 200 instancias de bases diferentes, y administrar tantas instalaciones con nuestras manos es un trabajo laborioso y poco confiable. Por lo tanto, utilizamos Github Orchestrator, que automatiza el trabajo con réplicas y proxySql para distribuir la carga y proteger contra fallas de una base de datos en particular.
Como ahora
En general, gradualmente comenzamos a asignar tareas asincrónicas y separar sus lanzamientos en el controlador de eventos para que uno no interfiera con el otro.
Cuando salió PHP 7, vimos en las pruebas un gran progreso en el rendimiento y en la reducción del consumo de recursos. Pasar a esto tuvo lugar con un poco de hemorroides, todo el proyecto desde el comienzo de las pruebas hasta la traducción completa de toda la producción tomó un poco más de seis meses, pero después de eso, el consumo de recursos se redujo a casi la mitad. Cronología de carga de CPU: en la parte superior de la publicación.
El monolito ha sobrevivido hasta nuestros días y, en mi opinión, es aproximadamente el 40% de la base del código. Vale la pena decir que la tarea de reemplazar todo el monolito con servicios no está establecida explícitamente. Nos estamos moviendo pragmáticamente: todo lo nuevo se hace en microservicios, si necesita refinar la funcionalidad anterior en un monolito, entonces tratamos de transferirla a la arquitectura de servicio, si solo el refinamiento no es realmente muy pequeño. Al mismo tiempo, el monolito está cubierto en pruebas para que podamos implementarlo dos veces por semana con un nivel de calidad suficiente. Las características están cubiertas de diferentes maneras, las pruebas unitarias son bastante completas, las pruebas de IU y las pruebas de aceptación cubren casi toda la funcionalidad del portal (tenemos alrededor de 15,000 casos de prueba), las pruebas API están más o menos completas. Casi no hacemos pruebas de carga. Más precisamente, nuestra puesta en escena es similar a la producción en la estructura, pero no en potencia, y está alineada con el mismo monitoreo. Generamos una carga, si vemos que la ejecución anterior en la versión anterior difiere en los tiempos, vemos cuán crítica es. Si la nueva versión y la anterior son aproximadamente iguales, las publicamos en el producto. En cualquier caso, todas las funciones se desactivan debajo del interruptor para que pueda apagarlo en cualquier momento si algo sale mal.
Las funciones pesadas siempre se prueban para el 1% de los usuarios. Luego pasamos al 2%, 5%, 10% y así llegamos a todos los usuarios. Es decir, siempre podemos ver la carga atípica antes de que la marejada mate los servidores y desconectemos por adelantado.
Cuando fue necesario, tomamos (y tomaremos) de 4 a 5 meses para un proyecto de reingeniería, cuando el equipo se concentra en una tarea específica. Esta es una buena manera de cortar el nudo gordiano cuando la refactorización local ya no ayuda. Así lo hicimos hace unos años con el aire: rehicimos la arquitectura, lo hicimos, obtuvimos inmediatamente una aceleración instantánea en el desarrollo, pudimos lanzar muchas características nuevas. Dos meses después de la reingeniería, crecieron en un orden de magnitud para los clientes debido a las características. Comenzaron a administrar los precios con mayor precisión, conectando socios, todo se volvió más rápido. Alegría Debo decir que ahora es el momento de volver a hacer lo mismo, pero este es el destino: las formas de crear aplicaciones están cambiando, aparecen nuevas soluciones, enfoques y herramientas. Para mantenerse en el negocio, necesita crecer.
La tarea principal de la reingeniería para nosotros es acelerar aún más el desarrollo. Si no se necesita nada nuevo, entonces no se necesita reingeniería. No es necesario inventar uno nuevo: no tiene sentido invertir en modernización. Y así, mientras se mantiene una pila y arquitectura modernas, las personas se ponen a trabajar más rápido, una nueva se conecta más rápido, el sistema se comporta de manera más predecible, los desarrolladores están más interesados en trabajar en un proyecto. Ahora hay una tarea para terminar el monolito sin tirarlo por completo, para que cada producto pueda cargar actualizaciones, sin depender de otros. Es decir, obtener un CI / CD específico en un monolito.
Hoy usamos no solo conejo, sino también REST y gRPC para intercambiar información entre servicios. Algunos de los microservicios están escritos en Golang: la velocidad computacional y el manejo de la memoria son excelentes allí. Hubo una llamada para implementar el soporte de nodeJS, pero al final dejamos el nodo solo para la representación del servidor, y la lógica de negocios se dejó en PHP y Go. En principio, el enfoque elegido nos permite desarrollar servicios en casi cualquier idioma, pero decidimos limitar el zoológico para no aumentar la complejidad del sistema.
Ahora vamos a microservicios que funcionarán en contenedores Docker bajo la orquestación OpenShift. La tarea dentro de un año y medio: el 90% de todos los giros dentro de la plataforma. Por qué Por lo tanto, es más rápido de implementar, más rápido verificar versiones, hay menos diferencia en la venta desde el entorno de desarrollo. El desarrollador puede pensar más en la característica que implementa, y no en cómo implementar el entorno, cómo configurarlo, dónde comenzarlo, es decir, más beneficios. Nuevamente, problemas operativos: hay muchos microservicios, deben ser automatizados por la administración. Manualmente: costos muy altos, los riesgos de errores con el control manual y la plataforma proporciona una escala normal.
Cada año tenemos un aumento en la carga de trabajo: en un 30-40%: cada vez más personas dominan los trucos con Internet, dejan de ir a las cajas físicas, estamos agregando nuevos productos y características a los existentes. Ahora, aproximadamente 1 millón de usuarios al día llega al portal. Por supuesto, no todos los usuarios generan la misma carga. Algo no requiere recursos computacionales en absoluto y, por ejemplo, las búsquedas son un componente bastante intensivo en recursos. Allí, una sola marca "más o menos tres días" en la aviación aumenta la carga en 49 veces (al mirar hacia adelante y hacia atrás, la matriz es 7 por 7). Todo lo demás en comparación con la búsqueda de un boleto dentro de los sistemas ferroviarios y aéreos es bastante simple. Lo más fácil en recursos es la
aventura y la
búsqueda de recorridos (no existe el caché más fácil en términos de arquitectura, pero aún hay muchos menos recorridos que combinaciones de boletos), luego
el horario del tren (se almacena fácilmente en caché por medios estándar), y solo entonces todo lo demás .
Por supuesto, la deuda técnica aún se acumula. De todos lados. Lo principal es entender a tiempo dónde puede lograr refactorizar, y todo estará bien, donde no tendrá que tocar nada (a veces sucede: vivimos con Legacy si no hay cambios planeados), pero en algún lugar debemos apresurarnos y reingeniería nosotros mismos, porque sin este futuro No será. Por supuesto, cometemos errores, pero en general, Tutu.ru ha existido durante 16 años, y me gusta la dinámica del proyecto.