¿Quién crees que configuraría mejor el algoritmo PostgreSQL - DBA o ML? Y si es el segundo, entonces es hora de que pensemos qué hacer cuando los autos nos reemplacen. O no llegará a eso, y las personas aún deben tomar decisiones importantes. Probablemente, el nivel de aislamiento y los requisitos para la estabilidad de la transacción deben permanecer con el administrador. Pero pronto se puede confiar en los índices para determinar la máquina usted mismo.

Andy Pavlo en
HighLoad ++ habló sobre el DBMS del futuro, que puede "tocar" en este momento. Si se perdió este discurso o prefiere recibir información en ruso, debajo del corte está la traducción del discurso.
Se tratará del proyecto de la Universidad Carnegie Mellon sobre la creación de DBMS autónomos. El término "autónomo" significa un sistema que puede desplegarse, configurarse, configurarse automáticamente sin intervención humana. Puede llevar unos diez años desarrollar algo como esto, pero eso es lo que están haciendo Andy y sus alumnos. Por supuesto, se necesitan algoritmos de aprendizaje automático para crear un DBMS autónomo, sin embargo, en este artículo nos centraremos solo en el lado de ingeniería del tema. Considere cómo diseñar un software para que sea independiente.
Sobre el orador: Andy Pavlo es profesor asociado en la Universidad Carnegie Mellon, bajo su liderazgo crea un
DBMS PelotonDB "autogestionado" , así como
ottertune , que ayuda a ajustar las configuraciones de PostgreSQL y MySQL utilizando el aprendizaje automático. Andy y su equipo ahora son verdaderos líderes en bases de datos autogestionadas.
La razón por la que queremos crear un DBMS autónomo es obvia. Administrar estas herramientas DBMS es un proceso muy costoso y que requiere mucho tiempo. El salario promedio de DBA en los Estados Unidos es de aproximadamente 89 mil dólares al año. Traducido a rublos, se obtienen 5,9 millones de rublos al año. Esta cantidad realmente grande le paga a la gente para que solo vigile su software. Alrededor del 50% del costo total de usar la base de datos es pagado por el trabajo de dichos administradores y personal relacionado.
Cuando se trata de proyectos realmente grandes, como los que analizamos en HighLoad ++ y que utilizan decenas de miles de bases de datos, la complejidad de su estructura va más allá de la percepción humana. Todos abordan este problema superficialmente e intentan alcanzar el máximo rendimiento invirtiendo un mínimo esfuerzo en ajustar el sistema.
Puede guardar una suma redonda si configura el DBMS a nivel de aplicación y entorno para garantizar el máximo rendimiento.
Bases de datos autoadaptativas, 1970–1990
La idea de DBMS autónomos no es nueva; su historia se remonta a la década de 1970, cuando las bases de datos relacionales comenzaron a crearse. Luego se les denominó bases de datos autoadaptativas (bases de datos autoadaptativas), y con su ayuda trataron de resolver los problemas clásicos del diseño de bases de datos, sobre los cuales las personas todavía luchan hasta hoy. Esta es la elección de los índices, la partición y la construcción del esquema de la base de datos, así como la ubicación de los datos. En ese momento, se desarrollaron herramientas que ayudaron a los administradores de bases de datos a implementar el DBMS. Estas herramientas, de hecho, funcionaron tal como lo hacen hoy sus contrapartes modernas.
Los administradores rastrean las solicitudes ejecutadas por la aplicación. Luego pasan esta pila de consultas al algoritmo de ajuste, que crea un modelo interno de cómo la aplicación debe usar la base de datos.
Si crea una herramienta que lo ayuda a seleccionar automáticamente índices, luego cree gráficos a partir de los cuales puede ver con qué frecuencia se accede a cada columna. Luego, pase esta información al algoritmo de búsqueda, que buscará en muchas ubicaciones diferentes e intentará determinar cuál de las columnas puede indexarse en la base de datos. El algoritmo utilizará el modelo de costo interno para mostrar que este en particular dará un mejor rendimiento en comparación con otros índices. Luego, el algoritmo dará una sugerencia sobre qué cambios en los índices deben hacerse. En este momento, es hora de participar en la persona, considerar esta propuesta y no solo decidir si es correcta, sino también elegir el momento adecuado para su implementación.

Los DBA deben saber cómo se usa la aplicación cuando hay una caída en la actividad del usuario. Por ejemplo, el domingo a las 3:00 a.m., el nivel más bajo de consultas de la base de datos, por lo que en este momento puede volver a cargar los índices.
Como dije, todas las herramientas de diseño de la época funcionaron de la misma manera:
este es
un problema muy antiguo . El supervisor científico de mi supervisor científico escribió un artículo sobre la selección automática de índices en 1976.
Bases de datos de autoajuste, 1990–2000
En la década de 1990, las personas, de hecho, trabajaron en el mismo problema, solo el nombre cambió de bases de datos adaptativas a autoajustables.
Los algoritmos mejoraron un poco, las herramientas mejoraron un poco, pero a un alto nivel funcionaron de la misma manera que antes. La única empresa a la vanguardia del movimiento de los sistemas de autoajuste fue Microsoft Research con su proyecto de administración automática. Desarrollaron soluciones realmente maravillosas, y a fines de los 90 y principios de los 00 nuevamente presentaron un conjunto de recomendaciones para configurar su base de datos.
La idea clave que propuso Microsoft era diferente de lo que era en el pasado: en lugar de hacer que las herramientas de personalización admitan sus propios modelos, en realidad simplemente reutilizaron el modelo de costo del optimizador de consultas para ayudar a determinar los beneficios de un índice frente a otro. Si lo piensas, tiene sentido. Cuando necesite saber si un solo índice realmente puede acelerar las consultas, no importa qué tan grande sea si el optimizador no lo selecciona. Por lo tanto, el optimizador se usa para averiguar si realmente elegirá algo.

En 2007, Microsoft Research publicó
un artículo que establece una retrospectiva de la investigación durante diez años. Y cubre bien todas las tareas complejas que surgieron en cada segmento de la ruta.
Otra tarea que se ha destacado en la era de las bases de datos de autoajuste es
cómo realizar ajustes automáticos en los reguladores. Un controlador de base de datos es algún tipo de parámetro de configuración que cambia el comportamiento del sistema de base de datos en tiempo de ejecución. Por ejemplo, un parámetro que está presente en casi todas las bases de datos es el tamaño del búfer. O, por ejemplo, puede administrar configuraciones como políticas de bloqueo, la frecuencia de la limpieza del disco y similares. Debido al aumento significativo en la complejidad de los reguladores de DBMS en los últimos años, este tema se ha vuelto relevante.
Para mostrar lo mal que están las cosas, haré una revisión que hizo mi estudiante después de estudiar muchas publicaciones de PostgreSQL y MySQL.
En los últimos 15 años, el número de reguladores en PostgreSQL ha aumentado 5 veces, y para MySQL, 7 veces.
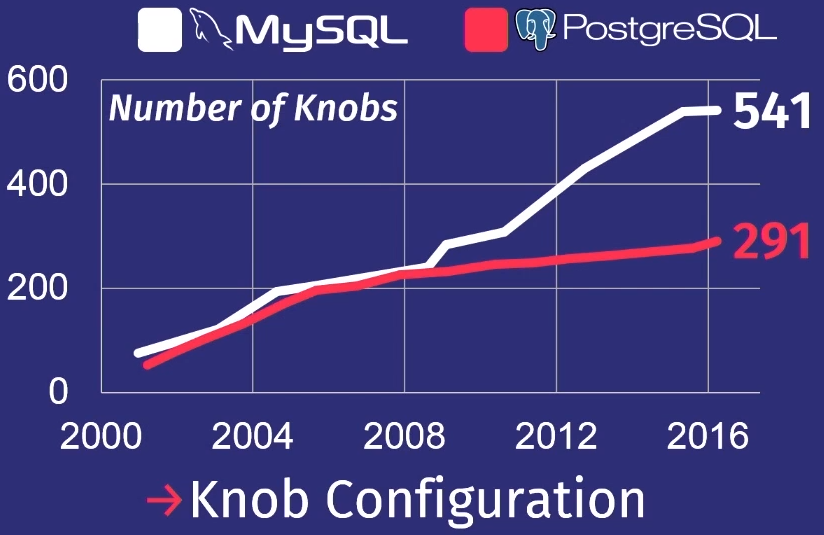
Por supuesto, no todos los reguladores controlan realmente el proceso de ejecución de la tarea. Algunos, por ejemplo, contienen rutas de archivos o direcciones de red, por lo que solo una persona puede configurarlos. Pero unas pocas docenas de ellos realmente pueden afectar el rendimiento. Ningún hombre puede sostener tanto en su cabeza.
Cloud DB, 2010– ...
Además nos encontramos en la era de la década de 2010, en la que estamos hasta nuestros días. Yo lo llamo la era de las bases de datos en la nube. Durante este tiempo, se ha trabajado mucho para automatizar la implementación de una gran cantidad de bases de datos en la nube.
Lo principal que preocupa a los principales proveedores de la nube es cómo alojar a un inquilino o migrar de uno a otro. Cómo determinar cuántos recursos necesitará cada inquilino y luego tratar de distribuirlos entre las máquinas para maximizar la productividad o cumplir el SLA con un costo mínimo.
Amazon, Microsoft y Google resuelven este problema, pero principalmente a nivel operativo. Solo recientemente, los proveedores de servicios en la nube comenzaron a pensar en la necesidad de configurar sistemas de bases de datos individuales. Este trabajo no es visible para los usuarios comunes, pero determina el alto nivel de la empresa.
Resumiendo la investigación de 40 años de bases de datos con sistemas autónomos y no autónomos, podemos concluir que este trabajo todavía no es suficiente.
¿Por qué hoy no podemos tener un sistema verdaderamente autónomo de autogobierno? Hay tres razones para esto.

Primero, todas estas herramientas, excepto la distribución de cargas de trabajo de los proveedores de servicios en la nube, son solo de carácter
consultivo . Es decir, sobre la base de la opción calculada, una persona debe tomar una decisión final y subjetiva sobre si dicha propuesta es correcta. Además, es necesario observar el funcionamiento del sistema durante algún tiempo para decidir si la decisión tomada sigue siendo correcta a medida que se desarrolla el servicio. Y luego aplique el conocimiento a su propio modelo interno de toma de decisiones en el futuro. Esto se puede hacer para una base de datos, pero no para decenas de miles.
El siguiente problema es que
cualquier medida es solo una reacción a algo . En todos los ejemplos que examinamos, el trabajo va con datos sobre la carga de trabajo pasada. Hay un problema, los registros al respecto se transfieren al instrumento y él dice: "Sí, sé cómo resolver este problema". Pero la solución solo se refiere a un problema que ya ha ocurrido. La herramienta no predice eventos futuros y, en consecuencia, no ofrece acciones preparatorias. Una persona puede hacer esto, y lo hace manualmente, pero las herramientas no.
La última razón es que en ninguna de las soluciones
hay una transferencia de conocimiento . Esto es lo que quiero decir: por ejemplo, tomemos una herramienta que funcionó en una aplicación en la primera instancia de la base de datos, si la coloca en otra misma aplicación en otra instancia de la base de datos, podría, en función del conocimiento adquirido al trabajar con la primera base de datos ayuda de datos para configurar una segunda base de datos. De hecho, todas las herramientas comienzan a funcionar desde cero, necesitan recuperar todos los datos sobre lo que está sucediendo. El hombre trabaja de una manera completamente diferente. Si sé cómo configurar una aplicación de cierta manera, puedo ver los mismos patrones en otra aplicación y, posiblemente, configurarla mucho más rápido. Pero ninguno de estos algoritmos, ninguna de estas herramientas todavía funciona de esta manera.
¿Por qué estoy seguro de que es hora de cambiar? La respuesta a esta pregunta es casi la misma que la pregunta de por qué los súper arreglos de datos o el aprendizaje automático se han vuelto populares.
El equipo se está volviendo de mejor calidad : los recursos de producción aumentan, la capacidad de almacenamiento aumenta, la capacidad de hardware aumenta, lo que acelera los cálculos para los modelos de aprendizaje automático.
Las herramientas de software avanzadas están disponibles para nosotros. Anteriormente, necesitaba ser un experto en MATLAB o álgebra lineal de bajo nivel para escribir algunos algoritmos de aprendizaje automático. Ahora tenemos Torch y Tenso Flow, que hacen que ML esté disponible, y, por supuesto, hemos aprendido a comprender mejor los datos. Las personas saben qué tipo de datos pueden ser necesarios para la toma de decisiones en el futuro, por lo tanto, no descartan tantos datos como antes.
El objetivo de nuestra investigación es cerrar este círculo en DBMS autónomos. Podemos, como las herramientas anteriores, proponer soluciones, pero en lugar de depender de la persona, ya sea que la decisión sea correcta cuando exactamente necesita implementarla, el algoritmo lo hará automáticamente. Y luego, con la ayuda de la retroalimentación, estudiará y mejorará con el tiempo.
Quiero hablar sobre los proyectos en los que estamos trabajando actualmente en la Universidad Carnegie Mellon. En ellos, abordamos el problema de dos maneras diferentes.
En el primero, OtterTune, buscamos formas de ajustar la base de datos, tratándolos como cuadros negros. Es decir, formas de
ajustar los DBMS existentes sin controlar la parte interna del sistema y observar solo la respuesta.
El proyecto Peloton se trata de
crear nuevas bases de datos desde cero , desde el principio, dado que el sistema debería funcionar de forma autónoma. Qué ajustes y algoritmos de optimización deben establecerse, que no se pueden aplicar a los sistemas existentes.
Consideremos ambos proyectos en orden.
Ottertune
El proyecto de ajuste del sistema existente que hemos desarrollado se llama OtterTune.
Imagine que la base de datos está configurada como un servicio. La idea es que descargue las métricas de tiempo de ejecución de las operaciones de bases de datos pesadas que consumen todos los recursos, y la configuración recomendada de los reguladores responde, lo que, en nuestra opinión, aumentará la productividad. Puede ser un tiempo de retraso, ancho de banda o cualquier otra característica que especifique; intentaremos encontrar la mejor opción.

Lo principal que es nuevo en el proyecto OtterTune es la
capacidad de utilizar los datos de las sesiones de ajuste
anteriores y aumentar la eficiencia de las sesiones posteriores. Por ejemplo, tome la configuración de PostgreSQL, que tiene una aplicación que nunca antes habíamos visto. Pero si tiene ciertas características o usa la base de datos de la misma manera que las bases de datos que ya hemos visto en nuestras aplicaciones, entonces ya sabemos cómo configurar esta aplicación de manera más eficiente.
En un nivel superior, el algoritmo de trabajo es el siguiente.
Digamos que hay una base de datos de destino: PostgreSQL, MySQL o VectorWise. Debe instalar el controlador en el mismo dominio, que realizará dos tareas.
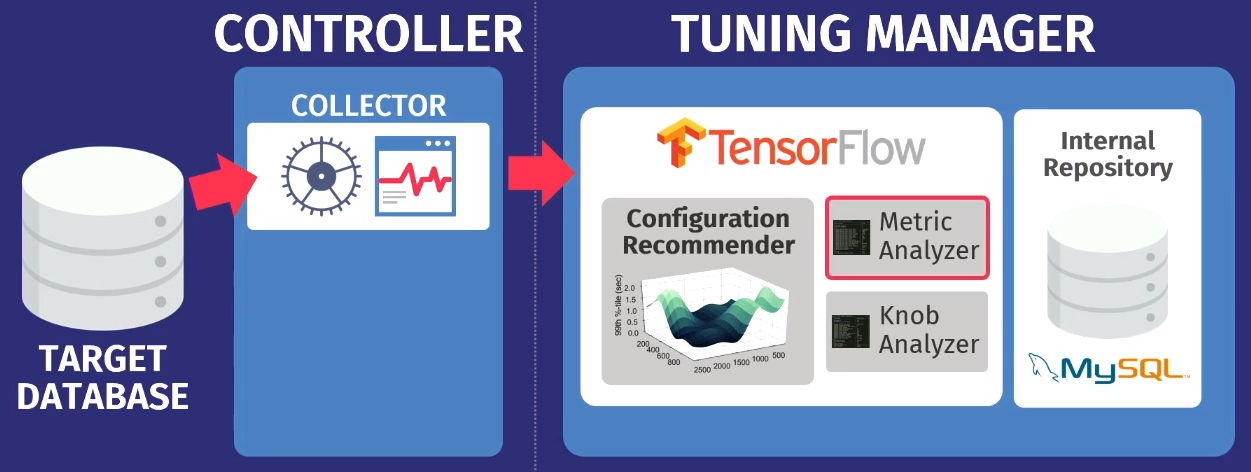
El primero lo realiza el llamado recopilador, una herramienta que recopila datos sobre la configuración actual, es decir, consulta de métricas de tiempo de ejecución desde aplicaciones a la base de datos. Los datos recopilados por el recopilador se cargan en el Tuning Manager, un servicio de ajuste. No importa si la base de datos funciona localmente o en la nube. Después de la descarga, los datos se almacenan en nuestro propio repositorio interno, que almacena todas las sesiones de configuración de prueba realizadas.
Antes de dar recomendaciones, debe realizar dos pasos. Primero, debe mirar las métricas de tiempo de ejecución y descubrir cuáles son realmente importantes. El siguiente ejemplo muestra las métricas devueltas por MySQL pero el
SHOW_GLOBAL_STATUS en InnoDB. No todos son útiles para nuestro análisis. Se sabe que en el aprendizaje automático, una gran cantidad de datos no siempre es buena. Porque entonces se requieren aún más datos para separar el grano de la paja. Como en este caso,
es importante deshacerse de las entidades que realmente no importan .
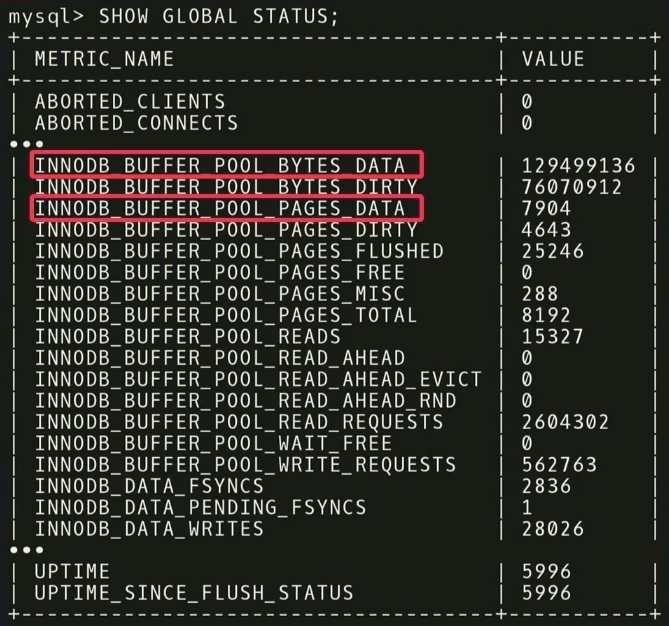
Por ejemplo, hay dos métricas:
INNODB_BUFFER_POOL_BYTES_DATA e
INNODB_BUFFER_POOL_PAGES_DATA . De hecho, esta es la misma métrica, pero en diferentes unidades. Puede realizar un análisis estadístico, ver que las métricas están altamente correlacionadas y concluir que usar ambas es redundante para el análisis. Si descarta uno de ellos, la dimensión de la tarea de aprendizaje disminuirá y el tiempo para recibir una respuesta se reducirá.
En la segunda etapa, hacemos lo mismo, solo con respecto a los reguladores.
Hay 500 reguladores en MySQL y, por supuesto, no todos son realmente significativos, pero diferentes aplicaciones son importantes para diferentes aplicaciones. Es necesario realizar otro análisis estadístico para descubrir qué reguladores realmente afectan la función objetivo.
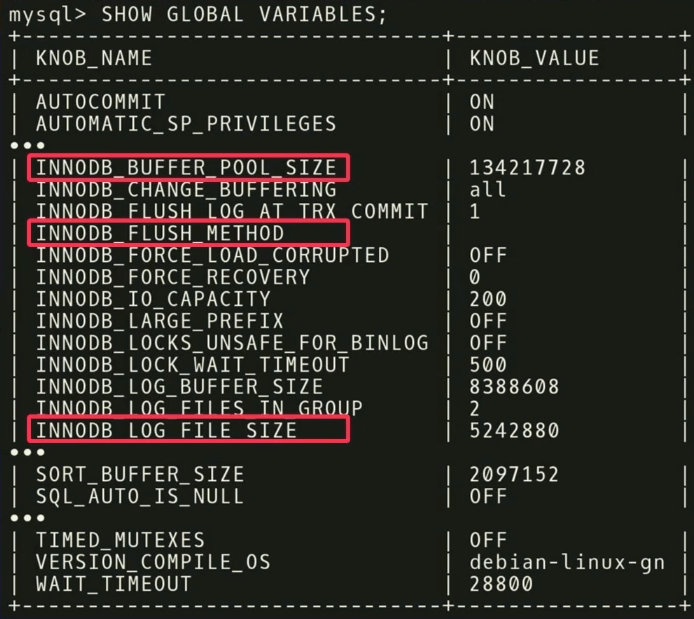
En nuestro ejemplo, encontramos que las tres
INNODB_BUFFER_POOL_SIZE ,
FLUSH_METHOD y
LOG_FILE_SIZE tienen el mayor impacto en el rendimiento. Reducen el tiempo de retraso para una carga de trabajo transaccional.
Hay otros puntos interesantes relacionados con los reguladores. En la captura de pantalla hay un regulador llamado
TIMED_MUTEXES . Si se refiere a la documentación de trabajo de MySQL, en la sección 45.7 se indicará que este regulador está desactualizado. Pero
el algoritmo de aprendizaje automático no puede leer la documentación , por lo que no lo sabe. Él sabe que hay un regulador que se puede encender o apagar, y tomará mucho tiempo entender que esto no afecta nada. Pero puede hacer cálculos por adelantado y descubrir que el regulador no hace nada, y no perder el tiempo configurándolo.
Después del análisis, los datos se transfieren a nuestro algoritmo de configuración utilizando
el modelo de proceso gaussiano , un método bastante antiguo. Probablemente hayas oído hablar del aprendizaje profundo, estamos haciendo algo similar, pero sin redes profundas. Utilizamos
GPflow , un paquete para trabajar con modelos de procesos gaussianos desarrollados en Rusia basados en TensorFlow. El algoritmo emite una recomendación que debería mejorar la función objetivo; estos datos se transfieren nuevamente al agente de instalación que trabaja dentro del controlador. El agente aplica los cambios realizando un reinicio (desafortunadamente, tendrá que reiniciar la base de datos) y luego el proceso se repite nuevamente. Se recopilan algunas métricas de tiempo de ejecución más, se transfieren al algoritmo, se realiza un análisis de la posibilidad de mejorar y aumentar la productividad, se emite una recomendación, y así sucesivamente, una y otra vez.
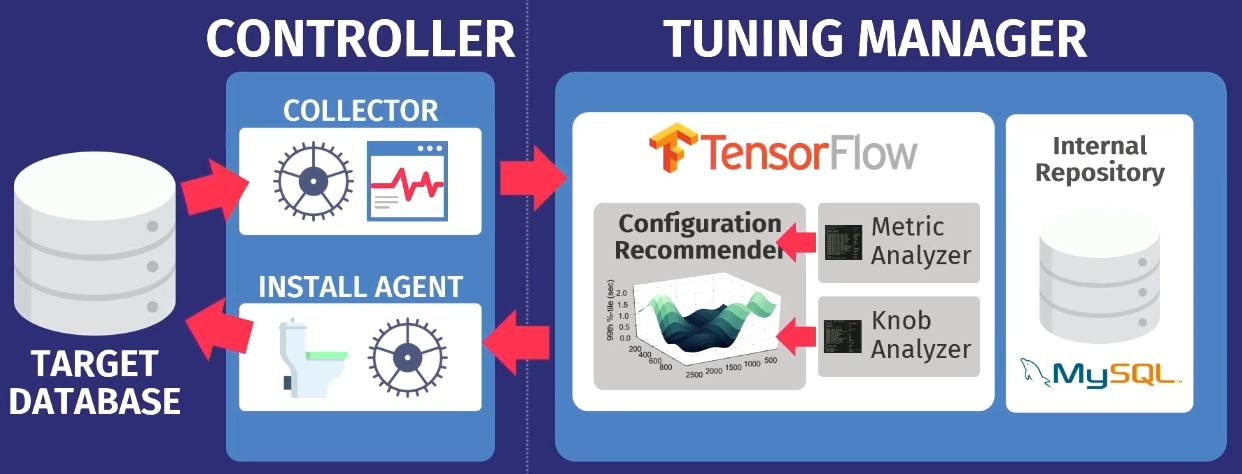
Una característica clave de OtterTune es que los algoritmos solo necesitan información sobre las métricas de tiempo de ejecución como entrada. No necesitamos ver sus datos y solicitudes de usuarios. Solo necesitamos rastrear las operaciones de lectura y escritura. Este es un argumento poderoso: los datos que le pertenecen a usted o sus clientes no serán revelados a terceros. No necesitamos ver ninguna solicitud, el algoritmo funciona únicamente en función de las métricas de tiempo de ejecución, ya que ofrece recomendaciones para los reguladores y no para el diseño físico.
Echemos un vistazo a la demostración de OtterTune. En el sitio web del proyecto, ejecutaremos Postgres 9.6 y cargaremos el sistema con la prueba TPC-C. Comencemos con la configuración inicial de PostgreSQL, que se implementa cuando se instala en Ubuntu.
Primero, ejecute la prueba TPC-C durante cinco minutos, recopile las métricas de tiempo de ejecución necesarias, cárguelas al servicio OtterTune, obtenga recomendaciones, aplique los cambios y luego repita el proceso. Volveremos a esto más tarde. El sistema de base de datos se ejecuta en una computadora, el servicio Tensor Flow en otra, y carga los datos aquí.
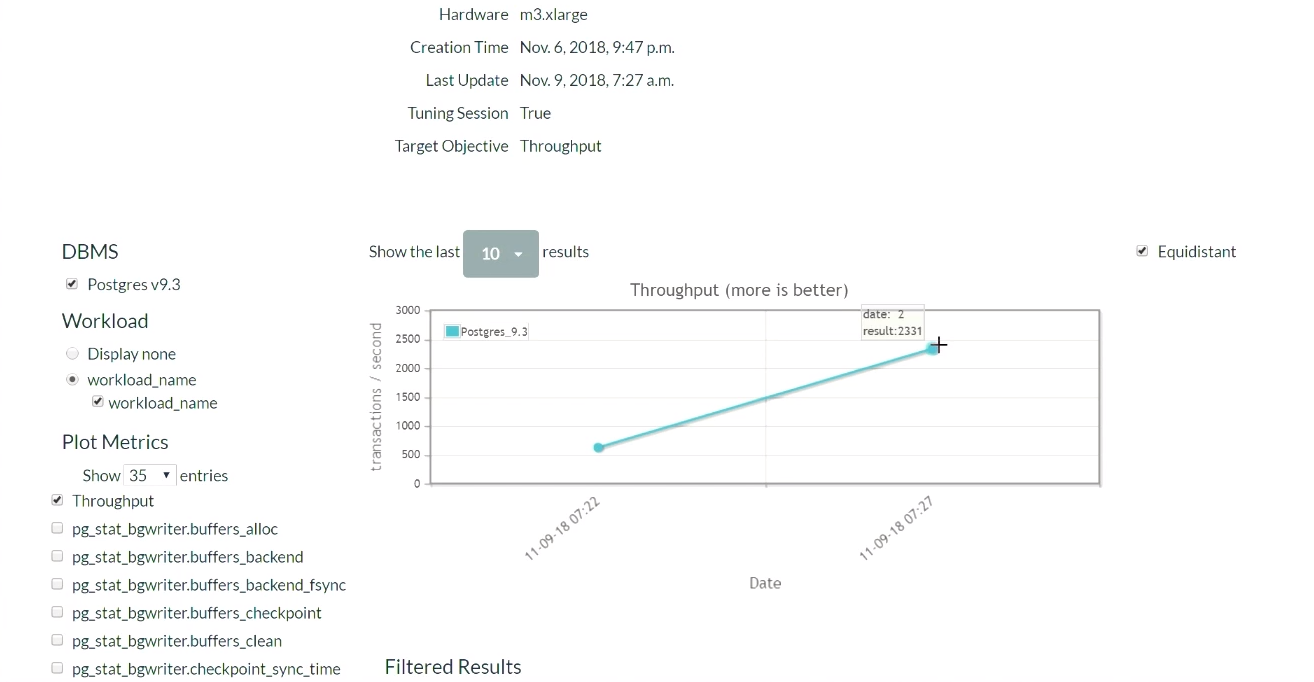
Cinco minutos después, actualizamos la página (en
este momento comienza una demostración de esta parte de los resultados). Cuando comenzamos, en la configuración predeterminada de PostgreSQL, había 623 transacciones por segundo. Luego, después de recibir la recomendación y aplicar los cambios una vez, el número de transacciones
aumentó a 2300 por segundo . Vale la pena reconocer que esta demostración ya se ha lanzado varias veces, por lo que el sistema ya tiene un conjunto de datos recopilados previamente. Por eso la solución es tan rápida. ¿Qué pasaría si el sistema no tuviera los datos recopilados previamente? Este algoritmo es una especie de función paso a paso, y gradualmente llegaría a este nivel.

Después de un tiempo y cinco iteraciones, el mejor resultado fue 2600. Pasamos de 600 transacciones por segundo y pudimos alcanzar un valor de 2600. Apareció una pequeña caída porque el algoritmo decidió probar una forma diferente de ajustar los reguladores después de lograr buenos resultados. El resultado fue un margen, por lo que no se produjo una gran caída en el rendimiento. Habiendo recibido un resultado negativo, el algoritmo se reconfiguró y comenzó a buscar otras formas de regulación.
Concluimos que no debe tener miedo de comenzar una mala estrategia en el trabajo, porque el algoritmo explorará el espacio de la solución y probará varias configuraciones para lograr las condiciones del acuerdo de SLA. Aunque siempre puede configurar el servicio para que el algoritmo seleccione solo soluciones mejoradas. Y con el tiempo, recibirá todos los mejores y mejores resultados.
Ahora volvamos al tema de nuestra conversación. Le contaré sobre los resultados existentes de un
artículo publicado en Sigmod. Configuramos MySQL y PostgreSQL para TPC-C usando OtterTune, para aumentar el rendimiento.
Compare las configuraciones de estos DBMS, implementados por defecto durante la primera instalación en Ubuntu. A continuación, ejecute algunos scripts de configuración de código abierto que puede obtener de Percona y algunas otras empresas de consultoría que trabajan con PostgreSQL. Estas secuencias de comandos utilizan procedimientos heurísticos, como la regla de que debe establecer un cierto tamaño de búfer para su hardware. También tenemos una configuración de Amazon RDS, que ya tiene preajustes de Amazon para el equipo en el que está trabajando. Luego compare esto con el resultado de configurar manualmente DBA costosos, pero con la condición de que tengan 20 minutos y la capacidad de establecer los parámetros que desee. Y el último paso es lanzar OtterTune.
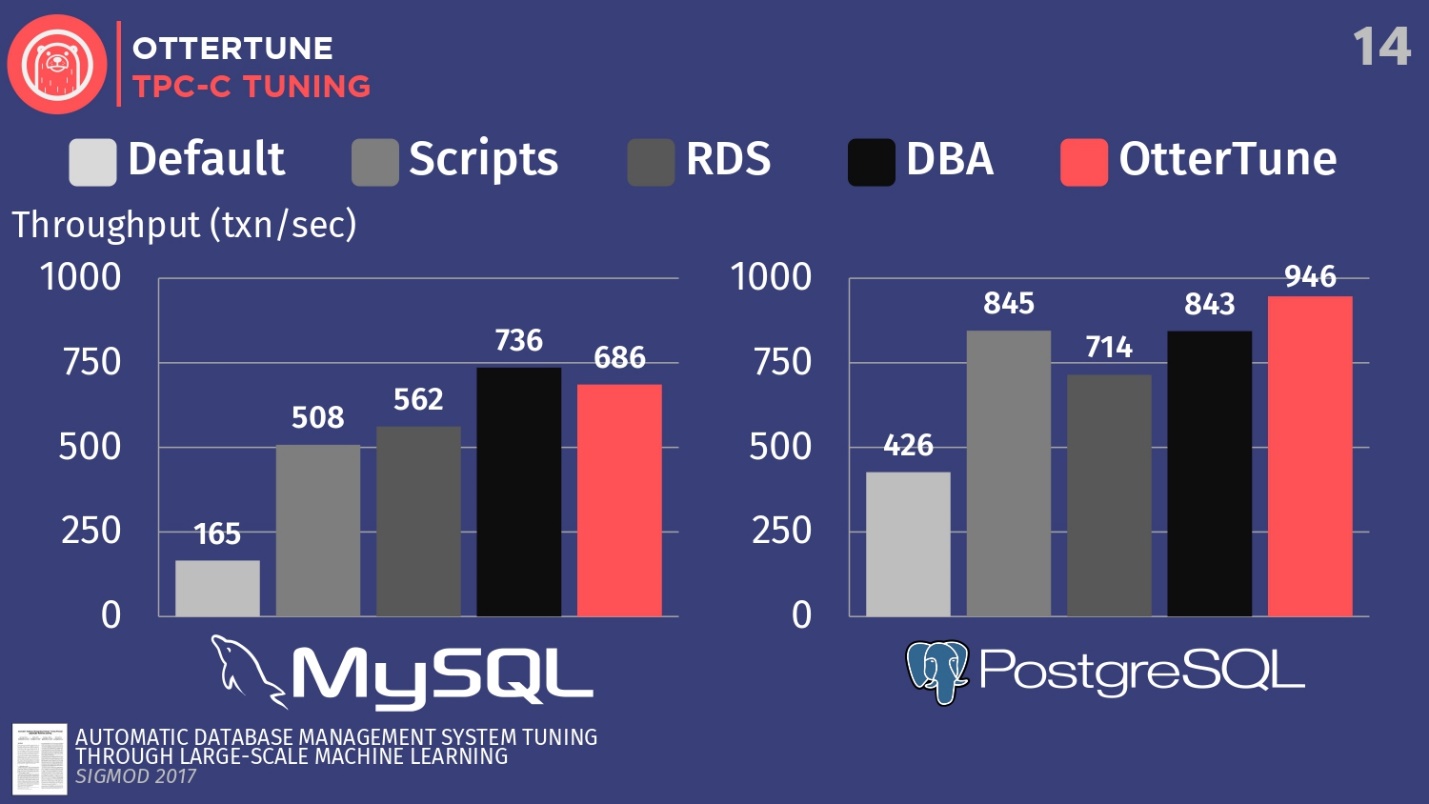
Para MySQL, puede ver que la configuración predeterminada está muy por detrás, los scripts funcionan un poco mejor, RDS es un poco mejor. En este caso, el administrador de la base de datos, el principal administrador de MySQL de Facebook, mostró el mejor resultado.
OtterTune perdido para el hombre . Pero el hecho es que hay un cierto regulador que desactiva la sincronización de la limpieza de registros, y esto no es importante para Facebook. Sin embargo, hemos denegado el acceso a este regulador OtterTune porque los algoritmos no saben si acepta perder los últimos cinco milisegundos de datos. En nuestra opinión, esta decisión debe ser tomada por una persona. Quizás Facebook esté de acuerdo con tales pérdidas, no lo sabemos. Si ajustamos este regulador de la misma manera, podemos competir con la persona.
Este ejemplo muestra cómo tratamos de ser conservadores en que la persona debe tomar la decisión final. Porque hay ciertos aspectos de las bases de datos que el algoritmo ML no conoce.
En el caso de PostgreSQL, los scripts de configuración funcionan bien. RDS hace un poco peor. Pero, vale la pena señalar que los indicadores OtterTune en esto superaron a la persona. El histograma muestra los resultados obtenidos después de que el Asesor Experto Senior de PostgreSQL de Wisconsin creó la base de datos. En este ejemplo, OtterTune pudo encontrar el equilibrio óptimo entre el tamaño del archivo de registro y el tamaño del grupo de búferes, equilibrando la cantidad de memoria utilizada por estos dos componentes y asegurando el mejor rendimiento.
La conclusión principal es que el servicio OtterTune utiliza algoritmos y aprendizaje automático que pueden lograr el mismo o mejor rendimiento en comparación con los muy, muy costosos DBA. Y esto se aplica no solo a una instancia de la base de datos, sino que podemos escalar el trabajo a decenas de miles de copias, porque es solo software, solo datos.
Pelotón
El segundo proyecto del que me gustaría hablar se llama Peloton. Este es un sistema de datos completamente nuevo que creamos desde cero en Carnegie Mellon. Lo llamamos un DBMS autogestionado.
La idea es averiguar qué cambios para mejor se pueden hacer si controla todo el paquete de software. Cómo mejorar la configuración de lo que OtterTune puede hacer, debido al conocimiento sobre cada fragmento del sistema, sobre todo el ciclo del programa.

Cómo funcionará: integramos los
componentes del aprendizaje automático con refuerzo en el sistema de base de datos, y podemos observar todos los aspectos de su comportamiento en tiempo de ejecución, y luego dar recomendaciones. Y no estamos limitados a las recomendaciones sobre el ajuste de los reguladores, como sucede en el servicio OtterTune, nos gustaría realizar todo el conjunto estándar de acciones de las que hablé anteriormente: seleccionar índices, elegir esquemas de partición, escalado vertical y horizontal, etc.
Es probable que cambie el nombre del sistema Peloton. No sé cómo en Rusia, pero en nuestros Estados Unidos, el término " pelotón" significa "intrépido" y "terminar", y en francés significa "pelotón". Pero en los Estados Unidos hay una compañía de bicicletas estáticas Peloton que tiene mucho dinero. Cada vez que aparece una mención de ellos, por ejemplo, la apertura de una nueva tienda o un nuevo anuncio en la televisión, todos mis amigos me escriben: "Mira, robaron tu idea, robaron tu nombre". Los anuncios muestran a personas hermosas que montan sus bicicletas estáticas, y simplemente no podemos competir con esto. Y recientemente, Uber anunció un nuevo planificador de recursos llamado Peloton, por lo que ya no podemos llamarlo nuestro sistema. Pero todavía no tenemos un nombre nuevo, por lo que en esta historia seguiré usando la versión actual del nombre.Considere cómo funciona este sistema a un alto nivel. Por ejemplo, tome la base de datos de destino, repito, este es nuestro software, esto es con lo que trabajamos. Recopilamos el mismo historial de carga de trabajo que mostré anteriormente. La diferencia es que vamos a generar modelos de pronóstico que nos permitan predecir cuáles serán los futuros ciclos de carga de trabajo, cuáles serán los requisitos de carga de trabajo futuros. Es por eso que llamamos a este sistema un DBMS autogestionable.
La idea básica de un DBMS autogestionado es similar a la idea de un automóvil con control automático.
Un vehículo no tripulado mira delante de sí mismo y puede ver lo que se encuentra frente a él en la carretera, puede predecir cómo llegar a su destino. Un sistema de base de datos independiente funciona de la misma manera. Debería poder mirar hacia el futuro y llegar a una conclusión sobre cómo se verá la carga de trabajo en una semana o en una hora. Luego pasamos estos datos pronosticados al componente de planificación (lo llamamos cerebro) que se ejecuta en Tensor Flow.
El proceso hace eco del trabajo de AlphaGo de Londres como parte del proyecto Google Deep Mind, en el nivel superior todo funciona en un escenario similar: Monte Carlo busca en el árbol, el resultado de la búsqueda son varias acciones que deben realizarse para lograr el objetivo deseado.
El siguiente algoritmo determina aproximadamente el esquema de operación:
- Los datos de origen son un conjunto de acciones requeridas, por ejemplo, eliminar un índice, agregar un índice, escala vertical y horizontal, y similares.
- Se genera una secuencia de acciones, que finalmente conduce al logro de la función objetivo máxima.
- Todos los criterios, excepto el primero, se descartan y se aplican los cambios.
- El sistema observa el efecto resultante, luego el proceso se repite una y otra vez.

No recurras constantemente a la metáfora de un automóvil no tripulado, pero así es como funcionan. Esto se llama el horizonte de planificación.
Después de mirar el horizonte en el camino, nos establecemos un punto imaginario para alcanzar, y luego comenzamos a planificar una secuencia de acciones para llegar a este punto en el horizonte: acelerar, reducir la velocidad, girar a la izquierda, girar a la derecha, etc. Luego, descartamos mentalmente todas las acciones, excepto la primera que debe realizarse, la realizamos y luego repetimos el proceso nuevamente. Los UAV ejecutan dicho algoritmo 30 veces por segundo. Para las bases de datos, este proceso es un poco más lento, pero la idea sigue siendo la misma.
Decidimos crear nuestro propio sistema de base de datos
desde cero, en lugar de construir algo sobre PostgreSQL o MySQL , porque, para ser sincero, son demasiado lentos en comparación con lo que nos gustaría hacer. PostgreSQL es hermoso, me encanta y lo uso en mis cursos universitarios, pero lleva demasiado tiempo crear índices, porque todos los datos provienen de discos.
En analogías con automóviles, un DBMS autónomo en PostgreSQL se puede comparar con un vagón no tripulado. La camioneta podrá reconocer al perro frente a la carretera y rodearlo, pero no si se salió corriendo a la carretera directamente en frente del automóvil. Entonces una colisión es inevitable, porque el camión no es suficientemente maniobrable. Decidimos crear un sistema desde cero para poder aplicar los cambios lo más rápido posible y descubrir cuál es la configuración correcta.
Ahora hemos resuelto el primer problema y publicado
un artículo sobre la combinación de aprendizaje profundo y regresión lineal clásica para la selección automática y la predicción de cargas de trabajo.
Pero hay un problema mayor, para el cual todavía no tenemos una buena solución:
catálogos de acción . La pregunta no es cómo elegir acciones, porque los chicos de Microsoft ya lo han hecho. La pregunta es cómo determinar si una acción es mejor que otra, en términos de lo que sucede antes y después de la implementación. Cómo revertir una acción si el índice creado por el comando de una persona no es óptimo, cómo puede cancelar esta acción e indicar el motivo de la cancelación. Además, hay una serie de otras tareas en términos de la interacción de nuestro propio sistema con el mundo exterior, para las cuales aún no tenemos una solución, pero estamos trabajando en ellas.
Por cierto, contaré una historia entretenida sobre una conocida empresa de bases de datos. Esta empresa tenía una herramienta de selección de índice automática, y la herramienta tenía un problema. Un cliente canceló constantemente todos los índices que la herramienta recomendaba y aplicaba. Esta cancelación se produjo con tanta frecuencia que la herramienta se colgó. No sabía cuál debería ser la estrategia de comportamiento adicional, porque cualquier solución ofrecida a una persona recibió una evaluación negativa. Cuando los desarrolladores recurrieron al cliente y le preguntaron: "¿Por qué cancelan todas las recomendaciones y sugerencias sobre los índices?", El cliente respondió que simplemente no le gustaban sus nombres. La gente es estúpida, pero tienes que lidiar con ellos. Y para este problema, tampoco tengo solución.Diseñando un DBMS autónomo
Dados dos enfoques diferentes para crear sistemas de bases de datos autónomas, hablemos ahora sobre cómo diseñar un DBMS para que sea autónomo.
Detengámonos en tres temas:
- cómo ajustar los reguladores,
- cómo recopilar métricas internas,
- Cómo diseñar acciones.
Una vez más, volviendo a los puntos clave: el sistema de base de datos debe proporcionar la información correcta a los algoritmos de aprendizaje automático para la posterior adopción de mejores decisiones. La cantidad de datos inútiles que transmitimos debe reducirse para aumentar la velocidad de recepción de respuestas.
, , , .
PG_SETTINGS , .
, , , .. , .
, , , , .
, , , .
:
- . , , .
- . , , -1 0, .
- , . , . 64- , 0 2 64 . , .
, . , 10 , , 10 . , .
- , . , , . , , , .
, , , . , . , , , — . , .
, , , . , .
, , . , : , , , , . - Oracle, , .

, , .
, , . , , , . - , , , . : PostgreSQL , .

, , , .
- , , , . , , . RocksDB, MyRocks MySQL.
RocksDB . , . , , , . RocksDB, .

, , , , . MyRocks . — :
ROCKSDB_BITES_READ, ROCKSDB_BITES_WRITTEN . , , . , . , .

, , , .
, , open source. , .
, ,
. MySQL , . , . 5 , 10 , , . 5 , — .
, . — PostgreSQL .
— . , . , , , , .
. , — SLA. , .
, . , . , . , .

, - , . , , - , . , , , — , -, , .
, , , .
, . , , , , 5- . downtime, .
, , , , , . , , , , .
Oracle autonomous database
Oracle . 2017 Oracle , . , Oracle, , « , Oracle 20 ».
. , , , , , . CIDR , . , : «, , , . , , , Oracle ?» , — ., , , Oracle. , .
,
— , , , - .
—
, . , , , 2000- . , Oracle , . , : , — - .
, . , , .
—
. , . : JOIN. . . , . .
Oracle. Microsoft 2017 SQL Server, . IBM DB2 00- , «LEO» — . , 1970-, Ingres. , JOIN, , . .
, , .
, , . , , . , , .
, , — , , , . , , , . , , .., .
HighLoad++ , HighLoad++ Siberia . , 39 , , highload- - .
HighLoad++ , . , UseData Conf — 16 , . , .