
El artículo es más técnico que sobre negocios, pero también sacaremos algunas conclusiones desde el punto de vista de los negocios. Se prestará mayor atención a la comparación automática de productos de diferentes fuentes.
El trabajo de la tienda en línea consiste en un número bastante grande de componentes. Y no importa cuál sea el plan, para obtener ganancias en este momento, o para crecer y buscar inversores, o, por ejemplo, para desarrollar áreas relacionadas, al menos tendrá que cerrar estas preguntas:
- Trabajar con proveedores. Para vender algo innecesario, primero debe comprar algo innecesario.
- Gestión de directorios. Alguien tiene una especialización estrecha, mientras que alguien vende cientos de miles de productos diferentes.
- Gestión de precios minoristas. Aquí deberá tener en cuenta los precios de los proveedores, los precios de los competidores y los instrumentos financieros asequibles.
- Trabaja con el almacén. En principio, es posible no tener su propio almacén, sino tomar los productos de los almacenes de los socios, pero de una forma u otra la pregunta es.
- Comercialización Aquí el sitio está lleno de contenido, ubicación en sitios, publicidad (en línea y fuera de línea), promociones y mucho más.
- Recepción y tramitación de pedidos. Centro de atención telefónica, canasta en el sitio, pedidos a través de mensajería instantánea, pedidos a través de plataformas y mercados.
- Entrega
- Contabilidad y otros sistemas internos.
La tienda, de la que hablaremos, no tiene una especialización limitada, pero ofrece un montón de todo, desde cosméticos hasta un mini tractor. Le diré cómo trabajamos con proveedores, monitoreando competidores, gestión de catálogos y precios (mayoristas y minoristas), trabajando con clientes mayoristas. Un pequeño toque sobre el tema del almacén.
Para comprender mejor algunas de las soluciones técnicas, no será superfluo saber que en
en algún momento decidimos que las cosas tecnológicas, si es posible, se harían no por nosotros mismos, sino de manera universal. Y, tal vez, después de varios intentos, saldrá a desarrollar un nuevo negocio. Resulta, condicionalmente, una startup dentro de la empresa.
Por lo tanto, estamos considerando un sistema separado, más o menos universal, con el que se integra el resto de la infraestructura de la compañía.
¿Cuál es el problema de trabajar con proveedores?
Y hay muchos de ellos, de hecho. Solo para dar algunos:
- Hay muchos proveedores per se. Tenemos alrededor de 400. Todos deben tomarse un tiempo.
- No hay una única forma de obtener ofertas de los proveedores. Alguien envía al correo según lo programado, alguien que lo solicita, alguien lo sube al alojamiento de archivos, alguien lo coloca en el sitio. Hay muchas formas, hasta enviar el archivo a través de Skype.
- No hay un formato de datos único. Incluso hice un dibujo sobre este tema (es más bajo, las tablas simbolizan diferentes formatos).
- Existe el concepto de precios minoristas mínimos y precios minoristas mínimos que deben observarse para continuar trabajando con el proveedor. A menudo se proporcionan en su propio formato.
- La nomenclatura de cada proveedor es diferente. Como resultado, el mismo producto se llama de manera diferente y no existe una clave única por la cual puedan compararse fácilmente. Por lo tanto, lo comparamos difícil.
- El sistema de realizar un pedido con el proveedor no está automatizado. Hacemos pedidos de alguien en Skype, de alguien en su cuenta, a alguien a quien le enviamos un archivo exel todas las noches con una lista de pedidos.

Hemos aprendido a hacer frente a estos problemas. Además de esto último, se está trabajando en esto último. Ahora habrá detalles técnicos, y luego considere la siguiente lista.
Recolectando datos
Como era
Los archivos de proveedores se recopilaron manualmente de varias fuentes y se prepararon. La preparación incluyó renombrar según una plantilla específica y editar contenido. Dependiendo del archivo, era necesario eliminar bienes no estándar, bienes que no están en stock, renombrar columnas o convertir divisas, recopilar datos de diferentes pestañas en uno.
Como
En primer lugar, aprendimos a revisar el correo y recoger cartas con archivos adjuntos desde allí. Luego automatizaron el trabajo con enlaces directos y enlaces a unidades Yandex y Google. Esto resolvió el problema de recibir ofertas de aproximadamente el 75% de nuestros proveedores. También notamos que es a través de estos canales que las ofertas se actualizan con mayor frecuencia, por lo que el porcentaje real de automatización es mayor. Todavía tenemos algunos precios en mensajeros.
En segundo lugar, ya no procesamos archivos manualmente. Para hacer esto, hemos ingresado perfiles de proveedores, donde puede especificar qué columna y pestaña usar, cómo determinar la moneda y la disponibilidad, el tiempo de entrega y el horario de trabajo del proveedor.
Resultó flexiblemente. Naturalmente, no tomamos todo en cuenta la primera vez, pero ahora hay suficiente flexibilidad para configurar el procesamiento de los 400 proveedores, dado que todos tienen diferentes formatos de archivo.
En cuanto a los formatos de archivo, entendemos xls, xlsx, csv, xml (yml). En nuestro caso, esto fue suficiente.
También descubrieron cómo filtrar registros. Hicimos una lista de palabras vacías, y si la oferta del proveedor la contiene, entonces no la procesamos. Los detalles técnicos son los siguientes: en una lista pequeña puede y aún mejor "de frente", en listas grandes filtro Bloom más rápido. Experimentamos con él y dejamos todo como está, porque la ganancia se siente en la lista en un orden de magnitud mayor que el nuestro.
Otra cosa importante es el horario de trabajo del proveedor. Nuestros proveedores trabajan en diferentes horarios, además, están ubicados en diferentes países, en los cuales los fines de semana no coinciden. Y el tiempo de entrega generalmente se indica como un número o un rango de números en días hábiles. Cuando formemos los precios minoristas y mayoristas, tendremos que evaluar de alguna manera el momento en que podemos entregar los productos al cliente. Para hacer esto, creamos calendarios configurables, y en la configuración de cada proveedor puede especificar en qué calendarios funciona.
Tuve que hacer una configuración de descuentos y márgenes según la categoría y el fabricante. Sucede que el proveedor tiene un archivo común para todos los socios, pero existen acuerdos de descuento con algunos socios. Gracias a esto, todavía era posible agregar o restar IVA si fuera necesario.
Por cierto, la configuración de las reglas de descuento y marcado nos lleva al siguiente tema. Después de todo, antes de usarlos, debe averiguar qué tipo de producto es.
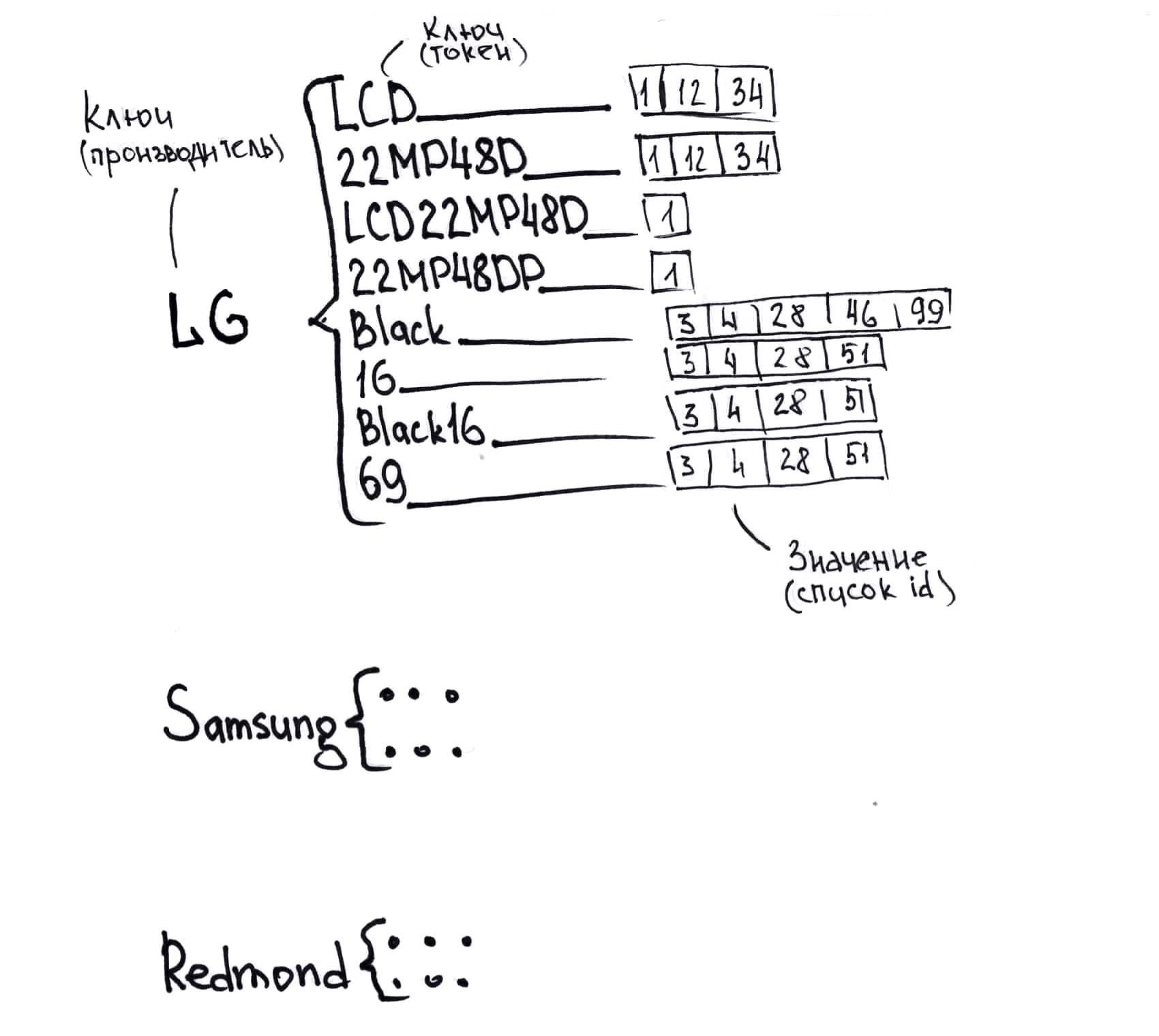
Cómo funciona el mapeo
Un pequeño ejemplo de cómo se puede llamar al mismo producto desde diferentes proveedores, para comprender con qué tiene que trabajar:
Monitor LG LCD 22MP48D-P
21.5 "LG 22MP48D-P Negro (16: 9, 1920x1080, IPS, 60 Hz, DVI + D-Sub (VGA))
COMP - Periféricos informáticos - Monitores LG 22MP48D-P
Monitor LG de hasta 22 "incluido LG 22MP48D-P (21.5", negro, IPS LED 5ms 16: 9 DVI mate 250cd 1920x1080 D-Sub FHD) 22MP48D-P
Monitores LG 22 "LG 22MP48D-P Negro brillante (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) Monitor
Monitores LCD Monitor LCD LG 22 "IPS 22MP48D-P LG 22MP48D-P
Monitor LG 21.5 "LG 22MP48D-P gl. Negro IPS, 1920x1080, 5ms, 250 cd / m2, 1000: 1 (Mega DCR), D-Sub, DVI-D (HDCP), vesa 22MP48D-P.ARUZ
Monitor LG LG 22MP48D-P Negro 22MP48D-P.ARUZ
Monitor LG 22MP48D-P 22MP48D-P
Monitores LG 22MP48D-P Negro brillante 22MP48D-P
Monitor 21.5 "LG Flatron 22MP48D-P gl. Negro (IPS, 1920x1080, 16: 9, 178/178, 250cd / m2, 1000: 1, 5ms, D-Sub, DVI-D) (22MP48D-P) 22MP48D-P
Monitor 22 "LG 22MP48D-P
LG 22MP48D-P IPS DVI
LG LG 21.5 "22MP48D-P IPS LED, 1920x1080, 5ms, 250cd / m2, 5Mln: 1, 178 ° / 178 °, D-Sub, DVI, Inclinación, VESA, Negro brillante 22MP48D-P
LG 21.5 "22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P
Monitor 21.5 '' LG 22MP48D-P Negro
LG MONITOR 21.5 "LG 22MP48D-P Negro brillante (IPS, LED, 1920x1080, 5 ms, 178 ° / 178 °, 250 cd / m, 100M: 1, + DVI) 22MP48D-P
Monitor LCD LG 21.5 '' [16: 9] 1920x1080 (FHD) IPS, no GLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16.7M Color, 5ms, VGA, DVI, Inclinación, 2Y, Negro OK 22MP48D -P
LCD LG 21.5 "22MP48D-P negro {IPS LED 1920x1080 5ms 16: 9 250cd 178 ° / 178 ° DVI D-Sub} 22MP48D-P.ARUZ
IDS_Monitores LG LG 22 "LCD 22MP48D 22MP48D-P
Monitor LG 21.5 "16x9 LG 21.5" 22MP48D-P negro IPS LED 5ms 16: 9 DVI mate 250cd 1920x1080 D-Sub FHD 2.7kg 22MP48D-P.ARUZ
Monitor 21.5 "LG 22MP48D-P [Negro]; 5 ms; 1920x1080, DVI, IPS
Como era
La comparación incluyó 1C (módulo de pago de terceros). En cuanto a la conveniencia / velocidad / precisión, dicho sistema permitió mantener un catálogo con 60 mil productos disponibles en este nivel por 6 personas. Es decir, todos los días, obsoletos y desaparecidos de las ofertas de los proveedores, se crearon tantos productos coincidentes como nuevos. Muy aproximadamente - 0.5% del tamaño del catálogo, es decir 300 productos
Cómo se convirtió: una descripción general del enfoque
Un poco más arriba, di un ejemplo de lo que necesitamos hacer coincidir. Al explorar el tema de la coincidencia, me sorprendió un poco que ElasticSearch sea popular para la tarea de la coincidencia, en mi opinión, tiene limitaciones conceptuales. En cuanto a nuestra pila de tecnología, usamos MS SQL Server para el almacenamiento de datos, pero la comparación funciona en nuestra propia infraestructura, y dado que hay muchos datos y necesitamos procesarlos rápidamente, usamos estructuras de datos optimizadas para una tarea específica e intentamos no acceder al disco o la base de datos sin la necesidad y otros sistemas lentos.
Obviamente, el problema de comparación se puede resolver de muchas maneras, y obviamente, ninguno de ellos dará una precisión absoluta. Por lo tanto, la idea principal es intentar combinar estos métodos, clasificarlos por precisión y velocidad y aplicarlos en orden descendente de precisión, teniendo en cuenta la velocidad.
El plan de ejecución para cada uno de nuestros algoritmos (con una reserva sobre casos degenerados) puede representarse brevemente mediante la siguiente secuencia general:
Tokenización Rompemos la línea de origen en partes independientes significativas. Se puede hacer una vez y seguir utilizándose en todos los algoritmos.
Normalización de tokens. En el buen sentido, debe llevar las palabras del lenguaje natural al número general y la declinación, y los identificadores como "ABC15MX" (esto es cirílico, si es que) deberían convertirse al latín. Y trae todo al mismo registro.
Categorización de tokens. Tratando de entender lo que significa cada parte. Por ejemplo, puede seleccionar una categoría, fabricante, color, etc.
Busca el mejor candidato para un partido.
Una estimación de la probabilidad de que la línea original y el mejor candidato indiquen el mismo producto.
Los primeros dos puntos son comunes para todos los algoritmos que están disponibles actualmente, y luego comienzan las improvisaciones.
Tokenización Aquí hicimos exactamente eso, dividimos la línea en partes de acuerdo con caracteres especiales como espacio, barra diagonal, etc. El conjunto de caracteres a lo largo del tiempo resultó ser significativo, pero no utilizamos nada complicado en el algoritmo mismo.
Entonces necesitamos normalizar los tokens. Conviértalos a minúsculas. En lugar de llevar todo al caso nominativo, simplemente cortamos los finales. También tenemos un pequeño diccionario y traducimos nuestros tokens al inglés. Entre otras cosas, la traducción nos salva de sinónimos, de significado similar, las palabras rusas se traducen al inglés de la misma manera. Cuando no logramos traducir, cambiamos los caracteres cirílicos similares en escritura al latín. (No resultó en absoluto superfluo, como resultó. Incluso donde no esperes un truco sucio, por ejemplo, en la línea "Samsung UE43NU7100U", podría ocurrir un cirílico E).

Categorización de tokens. Podemos destacar la categoría, fabricante, modelo, artículo, EAN, color. Tenemos un directorio donde se estructuran los datos. Tenemos datos sobre competidores que nos proporcionan las plataformas de negociación. Cuando los procesamos, cuando es posible, estructuramos los datos. Podemos corregir errores o errores tipográficos, por ejemplo, el fabricante o el color, que ocurren solo una vez en todas nuestras fuentes, sin tener en cuenta el fabricante y el color, respectivamente. Como resultado, tenemos un gran diccionario de posibles fabricantes, modelos, artículos, colores y la categorización de tokens es solo una búsqueda de diccionario para O (1). Teóricamente, puede tener una lista abierta de categorías y algún tipo de algoritmo de clasificación inteligente, pero nuestro enfoque básico funciona bien y la categorización no es un cuello de botella.
Cabe señalar que a veces el proveedor proporciona datos ya estructurados, por ejemplo, el artículo está en una celda separada en la tabla, o el proveedor hace un descuento en la venta minorista en las ventas mayoristas, y los precios minoristas se pueden obtener en formato yml (xml). Luego guardamos la estructura de datos y dividimos heurísticamente los tokens en categorías solo de datos no estructurados.
Y ahora sobre qué algoritmos y en qué orden usamos.
Coincidencias exactas y casi exactas
El caso más simple. Las líneas se dividieron en fichas, las llevaron a una forma. Luego se les ocurrió una función hash que no es sensible al orden de los tokens. Además, al hacer coincidir por hash, podemos mantener todos los datos en la memoria, podemos permitirnos los 16 megabytes condicionales por diccionario con un millón de claves. En la práctica, el algoritmo funcionó mejor que las simples comparaciones de cadenas.
En cuanto al hashing, el uso de "exclusivo o" se sugiere, y una función como esta:
public static long GetLongHashCode(IEnumerable<string> tokens) { long hash = 0; foreach (var token in tokens.Distinct()) { hash ^= GetLongHashCode(token); } return hash; }
Lo más interesante en esta etapa es obtener un hash de una sola línea. En la práctica, resultó que 32 bits son pequeños, se obtienen muchas colisiones. Y también, que no puede simplemente tomar el código fuente de la función del marco y cambiar el tipo del valor de retorno, hay menos colisiones para líneas individuales, pero después de la "exclusiva o" todavía ocurren, así que escribimos el nuestro. De hecho, simplemente agregaron a la función desde el marco de no linealidad de los datos de entrada. Definitivamente fue mejor, con la nueva función con una colisión, nos encontramos solo una vez en nuestros millones de registros, grabados y pospuestos hasta tiempos mejores.
Por lo tanto, estamos buscando coincidencias sin tener en cuenta el orden de las palabras y su forma. Tal búsqueda funciona para O (1).
Desafortunadamente, rara vez, pero también sucede: "ABC 42 Tipo 16" y "ABC 16 Tipo 42", y estos son dos productos diferentes. También aprendimos a lidiar con tales cosas, pero más sobre eso más adelante.
Productos confirmados humanos a juego
Tenemos productos que se hacen coincidir manualmente (la mayoría de las veces son productos que se hacen coincidir automáticamente, pero que se han verificado manualmente). De hecho, estamos haciendo lo mismo en este caso, solo que ahora hemos agregado un diccionario de hashes coincidentes, cuya búsqueda no cambió la complejidad temporal del algoritmo.
Las líneas coincidentes manuales simplemente se encuentran en la base de datos, por si acaso, dichos datos sin procesar le permitirán cambiar el algoritmo de hash en el futuro, volver a calcular todo y no perder nada.
Mapeo de atributos
Los dos primeros algoritmos son rápidos y precisos, pero no suficientes. A continuación, aplicamos la coincidencia de atributos.
Anteriormente, ya presentamos los datos en forma de tokens normalizados e incluso los clasificamos en categorías. En este capítulo, llamo atributos de categorías de tokens.
El atributo más confiable es EAN (https://ru.wikipedia.org/wiki/European_Article_Number). Las coincidencias EAN le brindan casi una garantía del 100% de que son el mismo producto. Sin embargo, el desajuste de EAN no dice nada, porque un producto puede tener diferentes EAN. Todo estaría bien, pero en nuestros datos el EAN es raro, por lo tanto, su influencia en la comparación a nivel de error.
El artículo es menos confiable. Algo extraño a menudo se obtiene directamente de los datos estructurados del proveedor, pero en cualquier caso en esta etapa lo usamos.
Como en la última etapa, aquí usamos diccionarios (busca O (1)), y el hash de (fabricante + modelo + artículo) se usa como clave. Hashing le permite realizar todas las operaciones en la memoria. En este caso, también tenemos en cuenta el color, si coincide o no existe, creemos que los productos coincidieron.
Busca el mejor partido
Los pasos anteriores fueron simples, rápidos y bastante confiables, pero desafortunadamente cubren menos de la mitad de las comparaciones.
En la búsqueda de la mejor coincidencia, hay una idea simple: la coincidencia de tokens raros tiene un gran peso, la coincidencia de tokens frecuentes es pequeña. Los tokens que contienen números se valoran más que los tokens de letras. Los tokens que coinciden en el mismo orden se valoran más que los tokens que se reorganizan. Los partidos largos son mejores que los cortos.
Ahora queda por llegar una estructura de datos rápida que pueda tener todo esto en cuenta al mismo tiempo y se ajuste a la memoria de un directorio de un par de millones de registros.
Se nos ocurrió la idea de presentar nuestro catálogo en forma de diccionario de diccionarios, en el primer nivel, la clave será un hash del fabricante (los datos en el catálogo están estructurados, conocemos al fabricante), el valor es el diccionario. Ahora el segundo nivel. La clave en el segundo nivel será el hash del token, el valor es la lista de elementos de identificación del catálogo donde se encuentra este token. Y en este caso, utilizamos la inclusión de combinaciones de tokens en el orden en que aparecen en nuestro catálogo. Decidimos qué usar como combinación y qué no, dependiendo del número de tokens, su longitud, etc., esto es un compromiso entre la velocidad, la precisión y la memoria requerida. En la figura, simplifiqué esta estructura, sin hashes y sin normalización.
Si en promedio se usan 20 tokens para cada producto, entonces en nuestras listas, que tienen los valores del diccionario adjunto, se producirá un enlace al producto en promedio 20 veces. No habrá más de 20 veces diferentes tokens que productos en el catálogo. Aproximadamente, puede calcular la memoria requerida para un catálogo de un millón de registros: 20 millones de claves, 4 bytes cada uno, 20 millones de identificación del producto, 4 bytes cada uno, gastos generales para organizar diccionarios y listas (el orden es el mismo, pero dado que el tamaño de las listas y los diccionarios No sabemos de antemano, pero aumenta sobre la marcha, multiplicar por dos). Total: 480 megabytes. En realidad, resultó un poco más de tokens para productos, y necesitamos hasta 800 megabytes por catálogo en un millón de productos. Lo que es aceptable, las capacidades del hierro moderno le permiten almacenar simultáneamente en la memoria más de cien directorios de este tamaño.
De vuelta al algoritmo. Al tener una cadena que necesitamos hacer coincidir, podemos determinar el fabricante (tenemos un algoritmo de categorización) y luego obtener tokens usando el mismo algoritmo que para los productos del catálogo. Aquí quiero decir, incluyendo combinaciones de tokens.
Entonces todo es relativamente simple. Para cada ficha, podemos encontrar rápidamente todos los productos en los que se encuentra, estimar el peso de cada coincidencia, teniendo en cuenta todo lo que hablamos anteriormente: longitud, frecuencia, presencia de números o caracteres especiales, y evaluar la "similitud" de todos los candidatos encontrados. En realidad, también hay optimizaciones aquí, no consideramos a todos los candidatos, primero creamos una pequeña lista de coincidencias de tokens con un gran peso, y no aplicamos coincidencias de tokens con un bajo peso a todos los productos, sino solo a esta lista.
Seleccionamos la mejor coincidencia, observamos la coincidencia de los tokens que se clasificaron y consideramos el puntaje de comparación. Además, tenemos dos valores de umbral P1 y P2, P1 <P2. Si la evaluación resultó ser mayor que el valor umbral P2: no se requiere la participación humana, todo sucede automáticamente. Si está entre dos valores, ofrecemos ver la comparación manualmente, antes de eso no participará en la fijación de precios. Si es menor que P1, lo más probable es que dicho producto no esté en el catálogo, no devolvemos nada.
Volver a las líneas "ABC 42 Tipo 16" y "ABC 16 Tipo 42". La solución es sorprendentemente simple: si varios productos tienen los mismos hash, entonces no los igualamos por hash. Y el último algoritmo tendrá en cuenta el orden de los tokens. Teóricamente, tales líneas en la lista de precios del proveedor no pueden coincidir con nada arbitrario, donde los números 16 y 42 no aparecen en absoluto. De hecho, no encontramos tal necesidad.
Velocidad y precisión
Ahora por la velocidad de todo. El tiempo requerido para preparar los diccionarios linealmente depende del tamaño del catálogo. El tiempo requerido directamente para la comparación depende linealmente del número de bienes que se comparan. Todas las estructuras de datos involucradas en la búsqueda no cambian después de la creación. Esto nos da la oportunidad de usar multihilo en la etapa de coincidencia. El trabajo preparatorio para el catálogo de un millón de registros lleva entre 40 y 80 segundos. La comparación funciona a una velocidad de 20-40 mil registros por segundo y no depende del tamaño del directorio. Entonces, sin embargo, debe guardar los resultados. El enfoque elegido es generalmente beneficioso para grandes volúmenes, pero un archivo con una docena de registros será desproporcionadamente largo. Por lo tanto, usamos el caché y contamos nuestras estructuras de búsqueda una vez cada 15 minutos.
Es cierto que los datos para la comparación deben leerse en alguna parte (la mayoría de las veces es un archivo de Excel), y las oraciones coincidentes deben guardarse en alguna parte, y esto también lleva tiempo. Entonces, el número total es de 2-4 mil registros por segundo.
Para evaluar la precisión, preparamos un conjunto de pruebas de aproximadamente 20,000 comparaciones verificadas manualmente de diferentes proveedores de diferentes categorías. Después de cada cambio, el algoritmo se probó con estos datos. Los resultados son los siguientes:
- los productos están en el catálogo y se compararon correctamente - 84%
- el producto está en el catálogo, pero no ha sido igualado, se requiere coincidencia manual - 16%
- los productos están en el catálogo y se compararon incorrectamente - 0.2%
- el producto no está en el catálogo y el programa lo identificó correctamente: 98.5%
- el producto no está en el catálogo, pero el programa lo comparó con uno de los productos: 1.5%
En el 80% de los casos en que el producto fue emparejado, no se requiere confirmación manual (confirmamos automáticamente la comparación), entre las ofertas confirmadas automáticamente se encuentra el 0.1% de los errores.
Por cierto, resulta que el 0.1% de los errores es mucho. Para un millón de registros coincidentes, esto es mil registros coincidentes incorrectamente. Y esto es mucho porque los compradores encuentran exactamente esos registros mejores. Bueno, cómo no pedir un tractor por el precio de los faros de este tractor. Sin embargo, estos mil errores están al comienzo del trabajo en un millón de propuestas, se corrigieron gradualmente. La cuarentena de precios sospechosos, que cierra este problema, apareció más tarde, los primeros meses que trabajamos sin ella.
Hay otra categoría de errores que no está relacionada con la comparación; estos son los precios incorrectos de nuestros proveedores. Esto es en parte por qué no tenemos en cuenta el precio en comparación. Decidimos que, dado que tenemos información adicional en forma de precio, la usaremos para tratar de determinar no solo nuestros propios errores, sino también los de los demás.
Busca los precios equivocados
Esta es la parte en la que estamos experimentando activamente. La versión básica es, y no le permite vender el teléfono al precio de un estuche, pero tengo la sensación de que es mejor.
Para cada producto encontramos los límites de los precios aceptables de los proveedores. Dependiendo de los datos disponibles, tenemos en cuenta los precios de los proveedores de este producto, los precios de los competidores, los precios de los proveedores de bienes de este fabricante en esta categoría. Aquellos precios que no caen dentro de las fronteras están en cuarentena e ignorados en todos nuestros algoritmos. Manualmente, puede marcar un precio tan sospechoso como normal, luego lo recordamos para este producto y contamos los límites de los precios aceptables.
El algoritmo directo para calcular los precios máximos y mínimos aceptables ahora cambia constantemente, estamos buscando un compromiso entre la cantidad de falsos positivos y la cantidad de precios incorrectos detectados.
Usamos valores medios en los cálculos (los promedios dan el peor resultado) y todavía no analizamos la forma de distribución. El análisis de la forma de distribución es solo el lugar donde, me parece, el algoritmo puede mejorarse.
Trabajar con la base de datos
De todo lo anterior, podemos concluir que actualizamos los datos sobre proveedores y competidores a menudo y de muchas maneras, y trabajar con la base de datos puede convertirse en un cuello de botella. En principio, inicialmente llamamos la atención sobre esto e intentamos lograr el máximo rendimiento. Cuando trabajamos con una gran cantidad de registros, hacemos lo siguiente:
- eliminamos índices de la tabla con la que trabajamos
- deshabilitar la indexación de texto completo en esta tabla
- eliminar todos los registros con una determinada condición (por ejemplo, todas las ofertas de proveedores específicos que estamos procesando actualmente)
- inserte nuevos registros con BULK COPY
- recrear índices
- habilitar la indexación de texto completo
La copia masiva funciona a una velocidad de 10-40 mil registros por segundo, por lo que queda por ver una extensión tan grande, pero es tan aceptable.
La eliminación de registros lleva aproximadamente el mismo tiempo que la inserción. Todavía se necesita tiempo para recrear los índices.
Por cierto, para cada directorio tenemos una base de datos separada. Los creamos sobre la marcha. Y ahora te diré por qué tenemos más de un catálogo.
¿Cuál es el problema de la catalogación?
Y hay muchos de ellos también. Ahora enumeraremos:
- El catálogo contiene alrededor de 400 mil productos de categorías completamente diferentes. Es imposible comprender profesionalmente cada una de las categorías.
- Debe seguir un cierto estilo, seguir las reglas generales para el nombre del catálogo, nombrar subcategorías, etc. Por lo tanto, estamos tratando de lograr una estructura de directorio coherente y lógica.
- Puede crear el mismo producto varias veces, y esto es un problema. Sin una herramienta que analice nombres similares, constantemente se crean duplicados.
- Es razonable agregar al catálogo aquellos bienes que los proveedores tienen en stock. En este caso, debe tener prioridades para las categorías de productos.
- Necesitamos varios directorios. Uno de los nuestros, lo llevamos a cabo nosotros mismos, el otro: el catálogo de agregadores, lo actualizamos por api. El significado del segundo catálogo es que la plataforma del agregador funciona solo con su propio catálogo y, en consecuencia, acepta ofertas en su nomenclatura. Este es otro lugar donde resultó que necesita una comparación.
Pensamos que era lógico y correcto mantener un directorio en el mismo lugar donde se hacen las comparaciones. Entonces podemos decir a los usuarios que administran el directorio lo que tiene el proveedor, pero no en el directorio.
¿Cómo mantenemos un catálogo?
Se tratará del catálogo sin características detalladas, las características son una gran historia separada, sobre eso en otro momento.
Como propiedades básicas, elegimos lo siguiente:
- productor
- categoría
- el modelo
- número de artículo
- color
- Ean
Primero, hicimos una API para obtener el catálogo de una fuente externa, y luego trabajamos en la conveniencia de crear, editar y eliminar registros.
Cómo funciona la búsqueda
La conveniencia de administrar un catálogo, en primer lugar, es la capacidad de encontrar rápidamente un producto en un catálogo o la oferta de un proveedor, y existen matices. Por ejemplo, debe poder buscar la línea “LG 21.5” 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P ”para“ 2MP48 ”.
Una búsqueda de servidor sql de texto completo fuera de la caja no es adecuada, porque no sabe cómo hacerlo, y la búsqueda con LIKE '% 2MP48%' es demasiado lenta.
Nuestra solución es bastante estándar, utilizamos N-gramos. Más precisamente, luego trigramas. Y ya por trigramas construimos un índice de texto completo y realizamos una búsqueda de texto completo. No estoy seguro de que usemos el espacio de manera muy racional en este caso, pero en términos de velocidad, esta solución surgió, dependiendo de la solicitud, funciona de 50 a 500 milisegundos, a veces hasta un segundo en una matriz de tres millones de registros.
Permítanme explicar, la línea "LG 21.5" 22MP48D-P (16: 9, IPS, VGA, DVI) 22MP48D-P "se convierte en la línea" lg2 g21 21515521522 22m 2mp mp4 p48 48d 8dp dp1 p16 169 69i 9ip ips psv svg vga gad adv dvi vi2 i22 ”, que se almacena en un campo separado que participa en el índice de texto completo.
Por cierto, los trigramas siguen siendo útiles para nosotros.
Crea un nuevo producto
En su mayor parte, los productos en el catálogo se crean por sugerencia del proveedor. Es decir, ya tenemos información de que el proveedor ofrece “LG LCD Monitor 21.5 '' [16: 9] 1920x1080 (FHD) IPS, no GLARE, 250cd / m2, H178 ° / V178 °, 1000: 1, 16.7M Color, 5 ms, VGA, DVI, inclinación, 2 años, negro OK 22MP48D-P ”a un precio de $ 120, y tiene de 5 a 10 unidades en stock.
Al crear un producto, antes que nada, debemos asegurarnos de que dicho producto aún no se haya creado en el catálogo. Resolvemos este problema en cuatro etapas.
En primer lugar, si tenemos un producto en el catálogo, es muy probable que la propuesta del proveedor coincida con este producto automáticamente.
En segundo lugar, antes de mostrarle al usuario el formulario para crear un nuevo producto, realizaremos una búsqueda por trigramas y mostraremos los resultados más relevantes. (técnicamente esto se hace usando CONTAINSTABLE).
En tercer lugar, a medida que completemos los campos para un nuevo producto, mostraremos productos existentes similares. Esto resuelve dos problemas: ayuda a evitar duplicados y mantener el estilo en los nombres, se pueden usar productos similares como modelo.
Y cuarto, recuerda, ¿dividimos las líneas en fichas, las normalizamos, contamos hashes? Haremos lo mismo y simplemente no dejaremos crear productos con los mismos hashes.
En esta etapa, tratamos de ayudar al usuario. Por la línea que está en la lista de precios, intentaremos determinar el fabricante, la categoría, el artículo, el EAN y el color de los productos. Primero, por tokens (podemos dividirlos en categorías), luego, si no funciona, encontraremos el producto más similar por trigramas. Y, si es lo suficientemente similar, complete el fabricante y la categoría.
La edición del producto funciona casi igual, pero no todo es aplicable.
Cómo establecemos nuestros precios
La tarea es esta: mantener un equilibrio entre la cantidad y el margen de ventas, de hecho, para lograr el máximo beneficio. Todos los demás aspectos del trabajo de la tienda también se refieren a esto, pero lo que sucede exactamente en la etapa de fijación de precios tiene el mayor impacto.
Como mínimo, necesitaremos información sobre ofertas de proveedores y competidores. También vale la pena considerar los precios mínimos minoristas y mayoristas y los costos de entrega, así como los instrumentos financieros: préstamos y cuotas.
Recopilamos precios de la competencia.
Para empezar, tenemos muchos perfiles de nuestros propios precios. Hay un perfil para minoristas, hay varios para clientes mayoristas. Todos ellos son creados y configurados en nuestro sistema.
En consecuencia, los competidores para cada perfil son diferentes. En el comercio minorista - otras tiendas minoristas, en ventas mayoristas - nuestros mismos proveedores.
Todo está claro con los proveedores, pero para el comercio minorista recopilamos datos de la competencia de varias maneras. En primer lugar, algunos agregadores proporcionan información sobre todos los precios de todos los productos que se encuentran en el sitio. En nuestra propia nomenclatura, pero podemos combinar productos, por lo que funciona automáticamente. Y esto es casi suficiente por ahora. En segundo lugar, tenemos analizadores de la competencia. Como todavía no están automatizados y existen en forma de aplicaciones de consola (que a veces se bloquean), rara vez las usamos.
Personaliza tu perfil
En el perfil, tenemos la oportunidad de configurar diferentes rangos de márgenes dependiendo del precio de los bienes del proveedor, categoría, fabricante, proveedor.
Todavía es posible indicar con qué proveedores en qué categoría o fabricante estamos trabajando, y con cuáles, no con qué competidores, tenemos en cuenta.Luego establecemos instrumentos financieros, indicamos qué cuotas hay disponibles y cuánto tomará el banco para sí mismo.Y ya dentro de los márgenes de los márgenes, formamos nuestros propios precios, tratando de mantener el mismo equilibrio en primer lugar, y hacer que nuestros productos de almacén se vendan mejor en segundo lugar. Esto es así en pocas palabras, pero de hecho no pretendo explicar con palabras simples lo que está sucediendo allí.Te puedo decir lo que no está sucediendo. Desafortunadamente, todavía no sabemos cómo pronosticar la demanda y tener en cuenta el costo de almacenar productos en un almacén.Integración con sistemas de terceros.
Una parte importante desde el punto de vista comercial, pero poco interesante desde un punto de vista técnico. En pocas palabras, diré que podemos enviar datos a sistemas de terceros (incluidos los incrementales, es decir, entendemos lo que ha cambiado desde el último intercambio) y podemos hacer listas de correo.Los boletines son personalizables, por lo que (y no solo eso) entregamos nuestras ofertas a clientes mayoristas.Otra forma de trabajar con clientes mayoristas es el portal b2b. Todavía está en desarrollo activo, funcionará literalmente en un mes.Cuentas, cambio de registro
Otra pregunta poco interesante desde un punto de vista técnico. Cada usuario tiene una cuenta.En resumen, se puede decir lo siguiente: si se usa ORM, entonces tiene un mecanismo de seguimiento de cambios incorporado. Si ingresa (y en nuestro caso es EF Core e incluso hay una API allí), puede iniciar sesión en casi dos líneas.Para el historial de cambios, creamos una interfaz, y ahora puede rastrear quién cambió qué en la configuración del sistema, quién editó o comparó ciertos productos, etc.Según los registros, se pueden considerar las estadísticas, que es lo que estamos haciendo. Sabemos quién creó o editó cuántos productos, cuántas comparaciones se confirmaron manualmente y cuántos se rechazaron, puede ver cada cambio.Un poco sobre el dispositivo del sistema general
Tenemos una base de datos para cuentas y elementos independientes del catálogo, una base de datos para registros y una base de datos para cada directorio. Esto facilita las consultas de directorio, y el análisis de datos es más fácil, y el código es más comprensible.Por cierto, el sistema de registro es auto-escrito, realmente necesitamos agrupar los registros relacionados con una solicitud o una tarea pesada, además, necesitamos una funcionalidad básica para analizarlos. Con soluciones llave en mano, esto resultó ser difícil, además de que esta es otra dependencia que necesita ser soportada.La interfaz web está hecha en ASP.NET Core y bootstrap, y el servicio de Windows realiza operaciones pesadas.Otra característica que ha beneficiado al proyecto, en mi opinión, son los diferentes modelos para leer y escribir datos. No implementamos CQRS completo, pero tomamos uno de los conceptos a partir de ahí. Escribimos en la base de datos a través de los repositorios, pero los objetos que se usan para grabar nunca dejan los métodos de actualización / creación / eliminación. La actualización masiva se realiza a través de BULK COPY. Se hicieron un modelo separado y una capa separada de acceso a datos para la lectura, por lo que solo leemos lo que necesitamos en un momento particular. Resultó que puede usar ORM, evitando consultas pesadas, accediendo a la base de datos en momentos inciertos (como con carga diferida), problemas N + 1. Y también usamos el modelo para leer como DTO.De las principales dependencias, tenemos ASP.NET Core, varios paquetes nuget de terceros y MS SQL Server. Si bien es posible, tratamos de no depender de muchos sistemas de terceros. Para implementar completamente el proyecto localmente, simplemente instale SQL Server, tome el código fuente del sistema de control de versiones y cree el proyecto. Las bases de datos necesarias se crearán automáticamente, pero no se necesita nada más. Puede que tenga que cambiar una o dos líneas en la configuración.Lo que no
Todavía no hemos hecho un sistema de conocimiento del proyecto. Queremos hacer wikis y consejos en su lugar. No crearon una interfaz intuitiva simple, la que no está mal, pero un poco confundida para una persona no preparada. CI / CD hasta ahora solo en los planes.No manejó las características detalladas de los bienes. También planeamos, pero aún no hay una fecha límite específica.
Resumen comercial
Desde el comienzo del desarrollo activo hasta el lanzamiento en producción, dos personas trabajaron en el proyecto durante 7 meses. Al principio, teníamos un prototipo hecho en nuestro tiempo libre. La integración más difícil se dio a los sistemas existentes.Durante los tres meses que estamos en producción, el número de bienes disponibles para clientes mayoristas ha crecido de 70 mil a 230 mil, el número de bienes en el sitio, de 60 mil a 140 mil. El sitio siempre llega tarde porque necesita características, imágenes, descripciones de productos. Descargamos 106 mil ofertas en el agregador en lugar de 40 mil hace tres meses. El número de personas que trabajan con el catálogo no ha cambiado.Trabajamos con 425 proveedores, este número casi se ha duplicado en tres meses. Rastreamos precios de más de mil competidores. Bueno, a medida que lo rastreamos, tenemos un sistema para analizar, pero en la mayoría de los casos tomamos datos ya preparados de quienes nos los proporcionan regularmente.Lamentablemente, no puedo informarle sobre ventas, yo mismo no tengo datos confiables. La demanda es estacional, y es imposible comparar directamente el mes con el mes anterior. Y en un año ha pasado demasiado para resaltar la influencia de nuestro sistema de todos los factores. Muy, muy condicional, más o menos un kilómetro, el crecimiento del catálogo, los precios más flexibles y competitivos y el crecimiento de las ventas asociadas ya han pagado el desarrollo y la implementación.Otro resultado: obtuvimos un proyecto que esencialmente no está relacionado con la infraestructura de una tienda en particular, y usted puede hacer un servicio público. Fue concebido desde el principio, y este plan casi funcionó. Desafortunadamente, la solución en caja ha fallado. Para ofrecer un proyecto como un servicio en el que pueda registrarse, marque la casilla "Acepto" y que funcione "tal cual", sin adaptarse al cliente, debe rediseñar la interfaz, agregar flexibilidad y crear un wiki. Y para hacer que la infraestructura sea fácilmente escalable y eliminar un solo punto de falla. Ahora solo tenemos copias de seguridad periódicas de los medios para garantizar la fiabilidad. Como solución empresarial, creo que estamos listos para resolver problemas comerciales. La pequeña empresa es encontrar un negocio.Por cierto, ya hemos atraído a un cliente externo, que tiene la funcionalidad más básica. Los chicos necesitaban una herramienta para comparar bienes, y los inconvenientes asociados con el desarrollo activo no los asustaron.