Los administradores del sistema Sysadminka se reúnen en Chelyabinsk, y en el último de ellos hice un informe sobre nuestra solución para aplicaciones de trabajo en 1C-Bitrix en Kubernetes.
Bitrix, Kubernetes, Ceph: ¿una gran mezcla?
Te diré cómo elaboramos una solución de trabajo a partir de todo esto.
Vamos!

Mitap se llevó a cabo el 18 de abril en Chelyabinsk. Puedes leer sobre nuestros mitaps en Timepad y verlos en YouTube .
Si quiere venir a nosotros con un informe o como oyente, a Wellcome, escriba a vadim.isakanov@gmail.com y Telegram t.me/vadimisakanov.
Mi informe
Diapositivas
Bitrix en Kubernetes Southbridge 1.0 Solución
Hablaré de nuestra solución en el formato "para tontos en Kubernetes", como se hizo en la reunión. Pero supongo que las palabras Bitrix, Docker, Kubernetes, Ceph son conocidas por usted al menos a nivel de artículos de Wikipedia.
¿Qué tienes sobre Bitrix en Kubernetes?
En Internet hay muy poca información sobre el funcionamiento de las aplicaciones en Bitrix en Kubernetes.
Encontré solo tales materiales:
Informe de Alexander Serbul, 1C-Bitrix y Anton Tuzlukov de Qsoft:
Recomiendo escucharlo.
Desarrollo de solución propia del usuario serkyron en Habré .
También encontré tal solución .
III ... en realidad.
Te advierto que no verificamos la calidad de las soluciones utilizando los enlaces anteriores :-)
Por cierto, al preparar nuestra solución, hablé con Alexander Serbul, entonces su informe aún no estaba, así que en mis diapositivas está el elemento "Bitrix no usa Kubernetes".
Pero ya hay muchas imágenes Docker preparadas para que Bitrix funcione en Docker: https://hub.docker.com/search?q=bitrix&type=image
¿Es esto suficiente para crear una solución completa de Bitrix en Kubernetes?
No Hay una gran cantidad de problemas que deben abordarse.
¿Cuáles son los problemas con Bitrix en Kubernetes?
Primero: las imágenes listas para usar de Dockerhub no son adecuadas para Kubernetes
Si queremos construir una arquitectura de microservicios (y en Kubernetes generalmente queremos), la aplicación en Kubernetes debe dividirse en contenedores y garantizar que cada contenedor realice una pequeña función (y lo haga bien). ¿Por qué solo uno? En resumen: cuanto más simple, más confiable.
Si es más auténtico, mire este artículo y video, por favor: https://habr.com/en/company/southbridge/blog/426637/
Las imágenes de Docker en Dockerhub se basan principalmente en el principio de "todo en uno", por lo que todavía teníamos que hacer nuestra propia bicicleta e incluso hacer imágenes desde cero.
Segundo: el código del sitio se edita desde el panel de administración
Creamos una nueva sección en el sitio: se actualizó el código (se agregó un directorio con el nombre de la nueva sección).
Cambió las propiedades del componente desde el panel de administración: el código ha cambiado.
Kubernetes "por defecto" no sabe cómo trabajar con esto, los contenedores deben estar sin estado.
Motivo: cada contenedor (sub) en el clúster procesa solo una parte del tráfico. Si cambia el código en un solo contenedor (abajo), entonces en diferentes pods el código será diferente, el sitio funcionará de manera diferente, se mostrarán diferentes versiones del sitio a diferentes usuarios. No puedes vivir así.
Tercero: debe resolver el problema de la implementación
Si tenemos un monolito y un servidor "clásico", todo es muy simple: implementamos una nueva base de código, migramos la base de datos, cambiamos el tráfico a la nueva versión del código. El cambio ocurre al instante.
Si tenemos un sitio web en Kubernetes, está aserrado en microservicios, hay muchos contenedores con código. Debe recopilar contenedores con la nueva versión del código, implementarlos en lugar de los antiguos, ejecutar correctamente la migración de la base de datos e idealmente hacer esto de forma invisible para los visitantes. Afortunadamente, Kubernetes nos ayuda en esto, apoyando una nube completa de diferentes tipos de implementación.
Cuarto: debe resolver el problema del almacenamiento de estática
Si su sitio pesa "solo" 10 gigabytes y lo implementa completamente en contenedores, obtendrá contenedores que pesen 10 gigabytes, que se implementarán para siempre.
Debe almacenar las partes más "pesadas" del sitio fuera de los contenedores, y surge la pregunta de cómo hacerlo correctamente
Lo que no está en nuestra decisión
No se corta el código completo de Bitrix para microfunciones / microservicios (de modo que el registro es independiente, el módulo de la tienda en línea es independiente, etc.). Almacenamos todo el código base en cada contenedor como un todo.
Tampoco almacenamos la base en Kubernetes (sin embargo, implementé soluciones con la base en Kubernetes para entornos de desarrollador, pero no para producción).
Los administradores del sitio aún notarán que el sitio funciona en Kubernetes. La función "comprobación del sistema" no funciona correctamente, para editar el código del sitio desde el panel de administración, primero debe hacer clic en el botón "Quiero editar el código".
Decidimos los problemas, decidimos la necesidad de implementar microservicios, el objetivo es claro: obtener un sistema de trabajo para trabajar en aplicaciones Bitrix en Kubernetes, al tiempo que se preservan las capacidades de Bitrix y las ventajas de Kubernetes. Comenzamos la implementación.
Arquitectura
Una gran cantidad de hogares "en funcionamiento" con un servidor web (trabajadores).
Uno debajo con coronas de corona (necesariamente solo una).
Una actualización para editar el código del sitio desde el panel de administración (solo se requiere una).
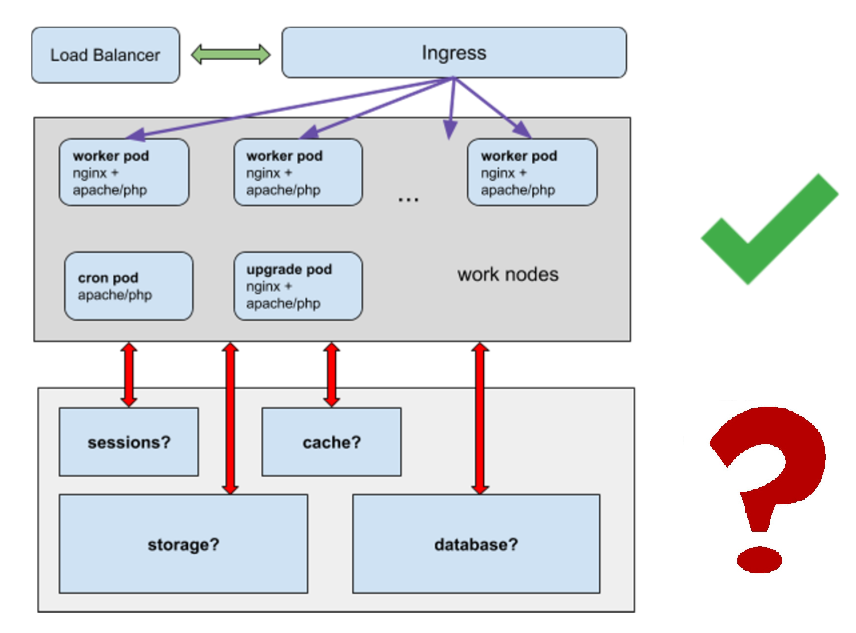
Solucionamos problemas:
- ¿Dónde almacenar sesiones?
- ¿Dónde almacenar el caché?
- ¿Dónde almacenar estadísticas, no colocar gigabytes de estadísticas en un montón de contenedores?
- ¿Cómo funcionará la base de datos?
Imagen de Docker
Comenzamos construyendo una imagen Docker.
La opción ideal es que tengamos una imagen universal, sobre la base de que obtenemos vainas de trabajadores y vainas con soportes, y vainas de actualización.
Hicimos tal imagen .
Incluye nginx, apache / php-fpm (se puede seleccionar durante el ensamblaje), msmtp para enviar correo y cron.
Al ensamblar la imagen, la base del código completo del sitio se copia en el directorio / app (con la excepción de aquellas partes que colocaremos en un almacenamiento compartido separado).
Microservicio, servicios
hogares de trabajadores:
- Contenedor con nginx + apache / php-fpm + contenedor msmtp
- msmtp no funcionó en un microservicio separado, Bitrix comienza a resentirse de que no puede enviar correo directamente
- Cada contenedor tiene una base de código completa.
- Prohibición de cambiar el código en contenedores.
cron bajo:
- contenedor con apache, php, cron
- base de código completa incluida
- prohibición de cambiar el código en contenedores
actualizar bajo:
- contenedor con nginx + apache / php-fpm + contenedor msmtp
- no está prohibido cambiar el código en los contenedores
almacenamiento de sesión
Almacenamiento en caché de Bitrix
Más importante: almacenamos contraseñas para conectarse a todo, desde la base de datos hasta el correo en secretos kubernetes. Obtenemos una bonificación, las contraseñas son visibles solo para aquellos a quienes les damos acceso a secretos, y no para todos los que tienen acceso a la base de código del proyecto.
Almacenamiento estático
Puede usar cualquier cosa: ceph, nfs (pero no se recomiendan nfs para la producción), almacenamiento en red de proveedores "en la nube", etc.
El almacenamiento deberá estar conectado en contenedores al directorio / upload / del sitio y otros directorios con estática.
Base de datos
Para simplificar, recomendamos mover la base fuera de Kubernetes. La base en Kubernetes es una tarea compleja separada, hará que el circuito sea mucho más complicado.
Almacenamiento de sesión
Usamos memcached :)
Hace un buen trabajo al almacenar sesiones, clústeres y es compatible de forma nativa como session.save_path en php. Tal sistema se resolvió muchas veces en la arquitectura monolítica clásica, cuando creamos clústeres con una gran cantidad de servidores web. Para la implementación usamos helm.
$ helm install stable/memcached --name session
php.ini: aquí en la configuración de imagen se configuran para almacenar sesiones en memcached
Utilizamos las Variables de entorno para transferir datos de host con https://kubernetes.io/docs/tasks/inject-data-application/define-environment-variable-container/ .
Esto le permite usar el mismo código en los entornos dev, stage, test, prod (los nombres de host de memcached en ellos serán diferentes, por lo que debemos transferir un nombre de host único para las sesiones a cada entorno).
Almacenamiento en caché de Bitrix
Necesitamos un almacenamiento a prueba de fallas en el que todos los hogares puedan escribir y del que podamos leer.
También usamos memcached.
Esta solución es recomendada por los propios Bitrix.
$ helm install stable/memcached --name cache
bitrix / .settings_extra.php: aquí en Bitrix se establece donde almacenamos el caché
También utilizamos variables de entorno.
Krontaski
Hay diferentes enfoques para hacer crontabs en Kubernetes.
- despliegue separado con un hogar
- cronjob para realizar crontask (si es una aplicación web, con wget https: // $ host $ cronjobname , o kubectl exec dentro de uno de los hogares de los trabajadores, etc.)
- etc.
Puede discutir sobre lo más correcto, pero en este caso elegimos la opción "implementación separada con pods para crontask"
Cómo hacerlo:
- agregue coronas a través de ConfigMap o mediante config / addcron
- en un caso, ejecute un contenedor idéntico al trabajador sub + permita la ejecución de tareas de corona en él
- Se utiliza la misma base de código, gracias a la unificación, el ensamblaje del contenedor es simple
Qué bien obtenemos:
- tenemos crontaski trabajando en un entorno idéntico al entorno de desarrollo (docker)
- Krontaski no necesita ser "reescrito" para Kubernetes, funcionan en la misma forma y en la misma base de código que antes
- los miembros de la corona pueden agregar todos los miembros del equipo con derechos de compromiso a la rama de producción, y no solo los administradores
Módulo Southbridge K8SDeploy y código de edición desde el panel de administración
Estábamos hablando de actualización bajo?
¿Y cómo dirigir el tráfico allí?
Hurra, escribimos un módulo para esto en php :) Este es un pequeño módulo clásico para Bitrix. Todavía no está disponible públicamente, pero planeamos abrirlo.
El módulo se instala como un módulo normal en Bitrix:

Y se ve así:
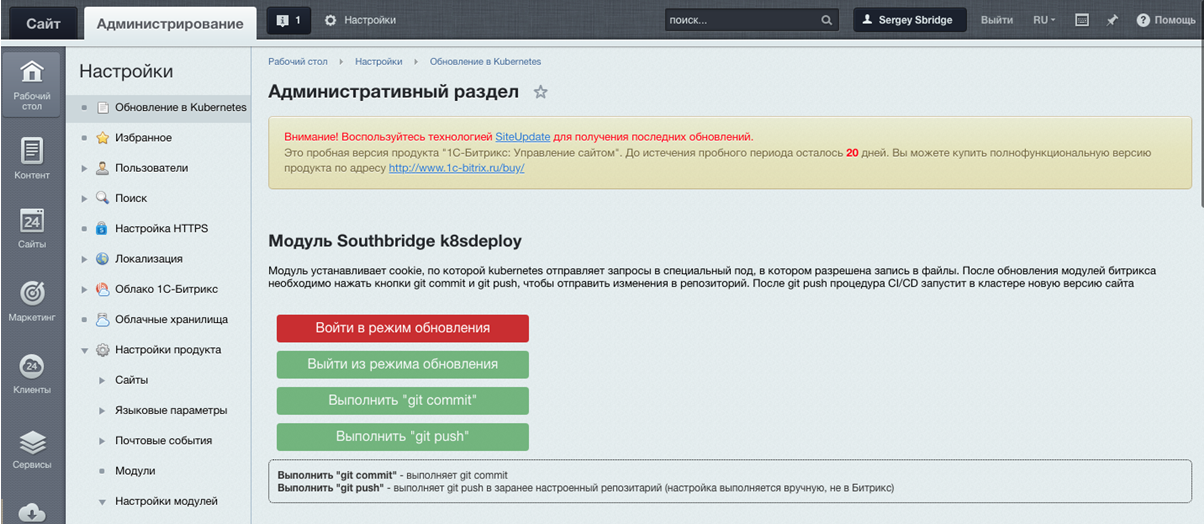
Le permite configurar una cookie que identifica al administrador del sitio y le permite a Kubernetes enviar tráfico para actualizarse.
Cuando se completan los cambios, debe presionar git push, los cambios de código se enviarán a git, luego el sistema recopilará la imagen con la nueva versión del código y la "rodará" a través del clúster, reemplazando las vainas antiguas.
Sí, es un poco muleta, pero al mismo tiempo, mantenemos la arquitectura de microservicio y no les quitamos a los usuarios de Bitrix una oportunidad favorita para corregir el código desde el panel de administración. Al final, esta es una opción, puede resolver el problema de editar código de una manera diferente.
Tabla de timón
Para construir aplicaciones en Kubernetes, usualmente usamos el administrador de paquetes Helm.
Para nuestra solución Bitrix en Kubernetes, Sergey Bondarev, nuestro administrador principal del sistema, escribió un gráfico especial de Helm.
Construye hogares de trabajo, ugrade, cron, configura entradas, servicios, transfiere variables de secretos de Kubernetes a hogares.
Almacenamos el código en Gitlab, y también ejecutamos el ensamblaje Helm desde Gitlab.
En resumen, se ve así
$ helm upgrade --install project .helm --set image=registrygitlab.local/k8s/bitrix -f .helm/values.yaml --wait --timeout 300 --debug --tiller-namespace=production
Helm también le permite hacer una reversión "sin problemas", si algo salió mal durante la implementación. Es agradable cuando no estás en pánico "arregla el código para ftp, porque el producto ha caído", y Kubernetes lo hace automáticamente, sin tiempo de inactividad.
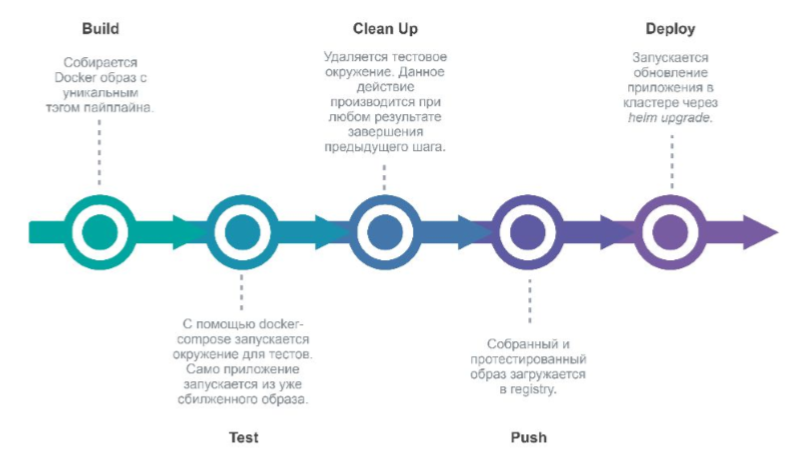
Implementar
Sí, somos fanáticos de Gitlab y Gitlab CI, úsalo :)
Al comprometerse con Gitlab en el repositorio del proyecto, Gitlab lanza una tubería que implementará la nueva versión del entorno.
Etapas:
- construir (construir una nueva imagen de Docker)
- prueba (prueba)
- limpiar (eliminar el entorno de prueba)
- push (enviarlo al registro de Docker)
- desplegar (implementamos la aplicación en Kubernetes a través de Helm).
¡Hurra, estamos listos para presentarlo!
Bueno, o haga preguntas, si las hay.
Entonces que hemos hecho
Desde un punto de vista técnico:
- Bitrix dockerizado;
- "Corte" Bitrix en contenedores, cada uno de los cuales realiza un mínimo de funciones;
- logrado estado sin estado de contenedores;
- resolvió el problema con la actualización de Bitrix en Kubernetes;
- todas las funciones de Bitrix continuaron funcionando (casi todas);
- despliegue trabajado en Kubernetes y reversión entre versiones.
Desde una perspectiva empresarial:
- tolerancia a fallas;
- Herramientas de Kubernetes (fácil integración con Gitlab CI, implementación sin problemas, etc.);
- contraseñas secretas (visibles solo para quienes tienen acceso directo a las contraseñas);
- Es conveniente crear entornos adicionales (para desarrollo, pruebas, etc.) dentro de una única infraestructura.