Muchos de los que han trabajado con Spark ML saben que algunas de las cosas que han hecho allí "no son del todo exitosas".
o no hecho en absoluto. La posición de los desarrolladores de Spark es que SparkML es la plataforma base, y todas las extensiones deben ser paquetes separados. Pero esto no siempre es conveniente, porque Data Scientist y los analistas quieren trabajar con herramientas familiares (Jupter, Zeppelin), donde hay más de lo que se necesita. No desean recopilar archivos JAR de 500 megabytes con ensamblaje maven o descargar dependencias en sus manos y agregarlos a los parámetros de inicio de Spark. El trabajo más fino con los sistemas de construcción de proyectos JVM puede requerir muchos esfuerzos adicionales por parte de analistas y científicos de datos acostumbrados a Jupyter / Zeppelin. Pedir claramente a DevOps y a los administradores de clústeres que pongan un montón de paquetes en los nodos de cómputo es claramente una mala idea. Cualquiera que haya escrito extensiones para SparkML por sí mismo sabe cuántas dificultades ocultas existen con clases y métodos importantes (que por alguna razón son privados [ml]), restricciones en los tipos de parámetros almacenados, etc.
Y parece que ahora, con la biblioteca MMLSpark, la vida será un poco más fácil, y el umbral para ingresar al aprendizaje automático escalable con SparkML y Scala es un poco más bajo.
Introduccion
Debido a una serie de dificultades, así como a un conjunto escaso de métodos y soluciones listos para usar en SparkML, muchas compañías escriben sus extensiones para Spark. Un ejemplo es PravdaML , que se está desarrollando en Odnoklassniki y que, a juzgar por una evaluación rápida de lo que está en GitHub, parece muy prometedor. Desafortunadamente, la mayoría de estas soluciones están cerradas o abiertas, pero no tienen la capacidad de instalarse a través de Maven / sbt y la documentación API, lo que hace que sea muy difícil trabajar con ellas.
Hoy nos fijamos en la biblioteca MMLSpark .
Consideraremos, como de costumbre, el ejemplo de la tarea de clasificar a los pasajeros del Titanic. El objetivo es mostrar tantas características de la biblioteca MMLSpark como sea posible, no noquear a SOTA en ImageNet Mostrar aprendizaje automático genial. Entonces el Titanic servirá.

La biblioteca en sí tiene una API nativa para Scala ( documentación ), Python API ( documentación ) y, a juzgar por algunos lugares en el repositorio de GitHub, pronto tendrá una API para R.
Hay buenos ejemplos de computadoras portátiles en el proyecto GitHub (PySpark + Jupyter) , pero iremos por el otro lado. Como escribió Dmitry Bugaychenko, si desarrolla para Spark, es decir, tiene todas las razones para usar Scala para esto, además, Scala le permite definir de manera mucho más eficiente y flexible su propio Transformador y Estimador para incrustarlos en SparkML Pipeline, pero cuán lentamente funciona El código / pandas en UDF (llamado en ejecutables desde la JVM) ya se ha escrito mucho.
Resumen de instalación
Toda la computadora portátil está disponible aquí . Para trabajar con el Titanic, la imagen de Zeppelin Docker que se ejecuta localmente en una computadora portátil con la configuración predeterminada es suficiente para la vista. Docker se puede encontrar aquí . La biblioteca MMLSpark no está en Maven Central, sino en paquetes de chispas, y para agregarla a Zeppelin, debe ejecutar el siguiente bloque al comienzo de la computadora portátil:
%spark.dep z.addRepo("bintray.com").url("http://dl.bintray.com/spark-packages/maven/") z.load("Azure:mmlspark:0.17")
Vale la pena decir que la biblioteca tiene una excelente compatibilidad con versiones anteriores: a diferencia de, por ejemplo, el XGBoost4j-spark, que requiere un mínimo de Spark 2.3+, esto entró en Spark 2.2.1, que vino con la imagen de Zeppelin Docker, y cualquier dificultad No me di cuenta.
Nota: la mayor parte de la biblioteca MMLSpark está dedicada a la inferencia de cuadrículas en el clúster, para lo cual CNTK está presente (que, a juzgar por la documentación, debería leer modelos de cntk ya preparados) y un gran bloque OpenCV. Nos centraremos en tareas más mundanas e intentaremos "simular" el caso cuando tengamos grandes matrices de datos tabulares que se encuentran en HDFS en forma de .csv, tablas u otro formato. Entonces, necesitamos preprocesarlos y construir un modelo, mientras que estos datos no caben en la memoria de una máquina. Por lo tanto, realizaremos todas las acciones en el clúster.
Análisis de lectura e inteligencia
En general, Spark + Zeppelin no es malo en absoluto y puede hacer frente a la tarea EDA, pero intentaremos expandir sus capacidades. Primero, importamos las clases que necesitamos:
- Todo desde spark.sql.types para declarar un esquema y leer los datos correctamente
- Todo desde spark.sql.functions para acceder a columnas y usar funciones integradas
- com.microsoft.ml.spark.SummarizeData , que se puede llamar un análogo de pandas.DataFrame.describe
import com.microsoft.ml.spark.SummarizeData import org.apache.spark.sql.functions._ import org.apache.spark.sql.types._
Leemos nuestro archivo:
val titanicSchema = StructType( StructField("Passanger", ShortType) :: StructField("Survived", ShortType) :: StructField("PClass", ShortType) :: StructField("Name", StringType) :: StructField("Sex", StringType) :: StructField("Age", ShortType) :: StructField("SibSp", ShortType) :: StructField("Parch", ShortType) :: StructField("Ticket", StringType) :: StructField("Fare", FloatType) :: StructField("Cabin", StringType) :: StructField("Embarked", StringType) :: Nil ) val train = spark .read .schema(titanicSchema) .option("header", true) .csv("/mountV/titanic/train.csv")
Y ahora mire los datos en sí, así como su tamaño:
println(s"Train shape is: ${train.count} x ${train.columns.length}") train.limit(5).createOrReplaceTempView("trainHead")
Nota: Realmente no hay necesidad de usar createOrReplaceTempView cuando solo puedes escribir .show (5). Pero show tiene un problema: cuando los datos son "amplios", la representación textual de la placa "flota", y nada queda claro.
Obtenga el tamaño de nuestros datos: Train shape is: 891 x 12
Y ahora en la celda sql podemos ver las primeras 5 filas:
%sql select * from trainHead
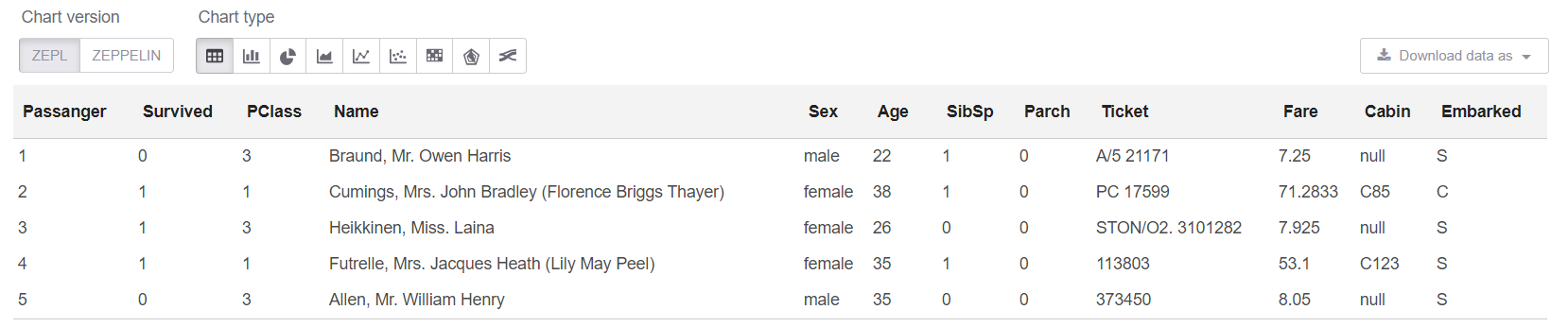
Bueno, veamos el resumen en nuestra tabla:
new SummarizeData() .setBasic(true) .setCounts(true) .setPercentiles(false) .setSample(true) .setErrorThreshold(0.25) .transform(train) .createOrReplaceTempView("summary")
La clase SummarizeData tiene varias ventajas sobre el Dataset.describe simple, ya que le permite contar el número de valores faltantes y únicos, y también le permite establecer la precisión de cálculo de cuantiles. Esto puede ser crítico para datos realmente grandes.

Algunos pensamientos personalesEn general, personalmente me pareció que Odnoklassniki en PravdaML tenía una mejor implementación del análogo SummarizeData. Microsoft tomó el camino fácil y utiliza org.apache.spark.sql.functions , es solo que todo está convenientemente envuelto en una sola clase. Para Odnoklassniki, esto se implementa a través de su VectorStatCollector , que requiere un código un poco más complejo al llamar (primero debe agregar todas las características en un vector) y puede requerir operaciones adicionales (por ejemplo, VectorAssembler generalmente se niega a digerir DecimalType ). Pero supongo, según mi experiencia con Spark, que SummarizeData de MMLSpark podría bloquearse con errores como StackOverflow en org.apache.spark.sql.catalyst si realmente hay muchas columnas, y el gráfico de cálculo no es pequeño para el momento del lanzamiento ( aunque especialmente para los fanáticos del "extremo" en Spark 2.4, agregaron la capacidad de reducir el optimizador gráfico Catalyst ). Bueno, parece que con una gran cantidad de columnas, la versión de Microsoft será más lenta. Pero esto, por supuesto, debe verificarse por separado.
Limpieza de datos
En el Titanic, todo es como siempre: a un montón de columnas de cadenas les faltan valores. Y algún tipo de error en los datos (parece que esta versión particular de los datos no es muy específica): 25 líneas de los valores faltantes. Primero, arregla esto:
val trainFiltered = train.filter(!(isnan(col("Survived")) || isnull(col("Survived"))))
Procesamiento de datos de cadena
Hasta donde recuerdo, los atributos traídos de los campos Name y Cabin fueron los mejores traídos en el Titanic. Puede suministrarlos mucho, pero nos limitaremos a unos pocos, solo para no dar ejemplos de casi el mismo código.
Por lo general, es conveniente usar expresiones regulares para tales cosas.
Pero queremos en este caso:
- todo se distribuyó, los datos se procesaron en el mismo lugar que estaba;
- todo fue diseñado como SpakrML Transformer o Spark ML Estimator, para que luego se pueda ensamblar en Pipeline.
Nota: Pipeline, en primer lugar, nos garantiza que siempre aplicamos las mismas transformaciones tanto al tren como a la prueba, y también nos permite detectar el error de "mirar hacia el futuro" en la validación cruzada. Y también nos brinda capacidades simples para guardar, cargar y predecir el uso de nuestra tubería.
SparkML tiene una clase "casi universal" para tales tareas: SQLTranformer , pero escribir en SQL es claramente peor que escribir en Scala, aunque solo sea porque es posible detectar la sintaxis o los errores típicos durante la compilación y el resaltado de sintaxis en Idea. Y aquí MMLSpark viene en nuestra ayuda, donde se implementa un UDFTransformer verdaderamente universal:
import com.microsoft.ml.spark.UDFTransformer
Para comenzar, crearemos nuestra función de transformación, que es muy simple hasta el límite, pero nuestro objetivo ahora es mostrar el proceso de creación de UDFTransformer. En principio, basándose en ejemplos tan simples, cualquiera puede agregar lógica a cualquier nivel de complejidad.
val miss = ".*miss\\..*".r val mr = ".*mr\\..*".r val mrs = ".*mrs\\..*".r val master = ".*master.*".r def convertNames(input: String): Option[String] = { Option(input).map(x => { x.toLowerCase match { case miss() => "Miss" case mr() => "Mr" case mrs() => "Mrs" case master() => "Master" case _ => "Unknown" } }) }
(Puede ver de inmediato lo conveniente que es Scala para trabajar con valores faltantes, que, por cierto, no solo son null , sino también Double.NaN , pero hay tal broma algo tan raro como las omisiones en BooleanType variables BooleanType , etc.)
Ahora declare nuestra función UserDefinedFunction el UserDefinedFunction e inmediatamente cree un Transformer basado en ella:
val nameTransformUDF = udf(convertNames _) val nameTransformer = new UDFTransformer() .setUDF(nameTransformUDF) .setInputCol("Name") .setOutputCol("NameType")
Nota: En una computadora portátil Zeppelin, todo es lo mismo, pero cuando todo se junta más adelante en el código de producción, es importante que todos los UDF estén en clases u objetos que se extends Serializable . Lo obvio que a veces puede olvidarse y luego profundizar durante mucho tiempo es lo que está mal al leer los largos rastros de la pila de errores de Spark.
Ahora todavía tenemos el campo Cabin . Echemos un vistazo más de cerca:

Vemos que faltan muchos valores, hay letras, números, diferentes combinaciones, etc. Tomemos el número de cabañas (si hay más de una), así como los números: probablemente tengan algún tipo de lógica, por ejemplo, si la numeración es de un extremo del barco, entonces las cabañas en la proa tenían menos posibilidades. También crearemos funciones, y luego en base a ellas UDFTransformer :
def getCabinsCount(input: String): Int = { Option(input) match { case Some(x) => x.split(" ").length case None => -1 } } val numPattern = "([az])([0-9]+)".r def getNumbersFromCabin(input: String): Int = { Option(input) match { case Some(x) => { x.split(" ")(0).toLowerCase match { case numPattern(sym, num) => Integer.parseInt(num) case _ => -1 } } case None => -2 } } val cabinsCountUDF = udf(getCabinsCount _) val numbersFromCabinUDF = udf(getNumbersFromCabin _) val cabinsCountTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinCount") .setUDF(cabinsCountUDF) val numbersFromCabinTransformer = new UDFTransformer() .setInputCol("Cabin") .setOutputCol("CabinNumber") .setUDF(numbersFromCabinUDF)
Ahora comencemos con los valores faltantes, es decir, la edad. Primero, aprovechemos las capacidades de visualización de Zeppelin:
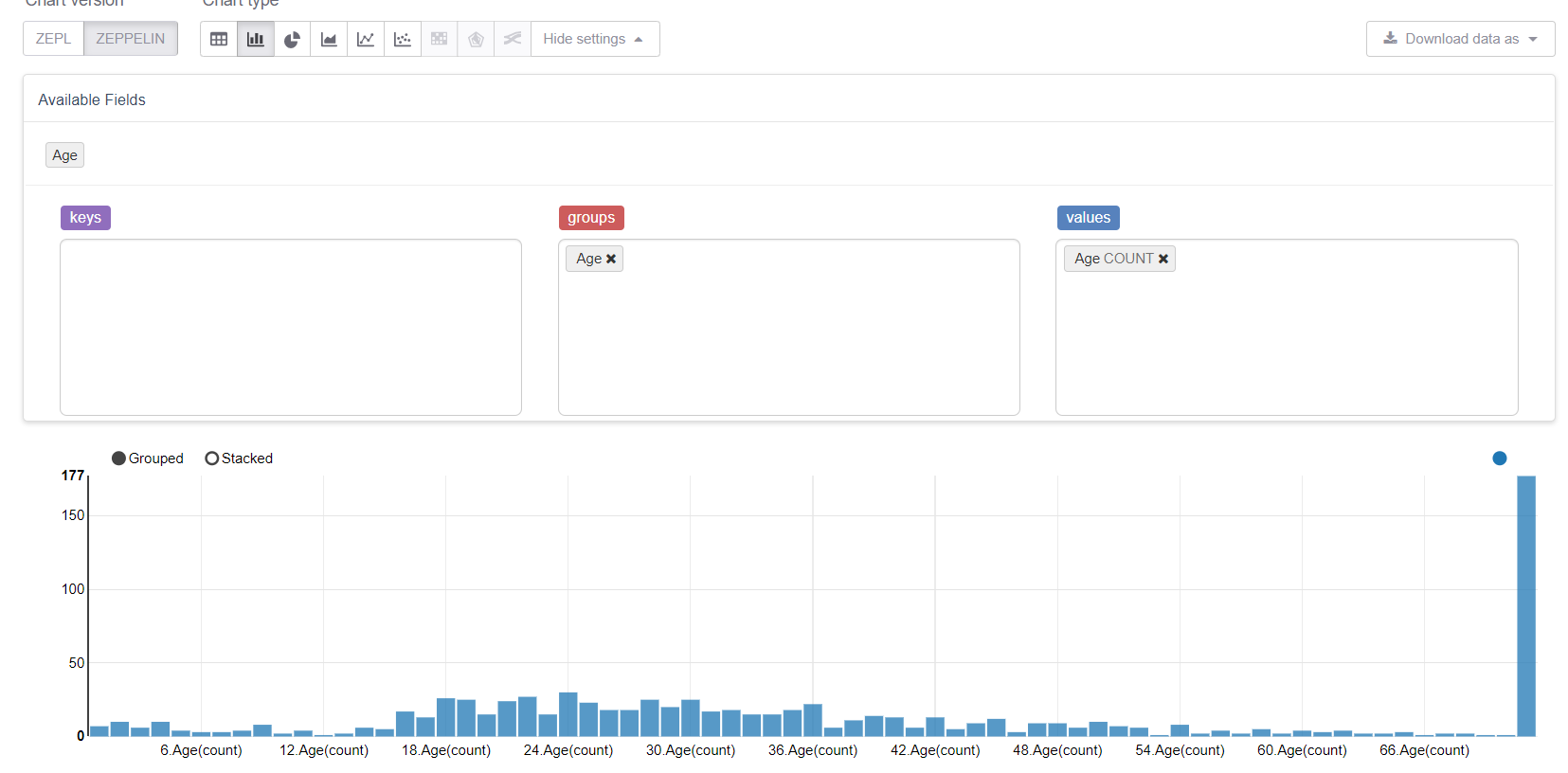
Y vea cómo los valores perdidos lo estropean todo. Sería lógico reemplazarlos con un medio (o mediana), pero nuestro objetivo es considerar todas las características de la biblioteca MMLSpark. Por lo tanto, escribiremos nuestro propio Estimator , que consideraría los grupos / promedios en la muestra de entrenamiento y los reemplazaría con las brechas correspondientes.
Necesitaremos:
import org.apache.spark.sql.{Dataset, DataFrame} import org.apache.spark.ml.{Estimator, Model} import org.apache.spark.ml.param.{Param, ParamMap} import org.apache.spark.ml.util.Identifiable import org.apache.spark.ml.util.DefaultParamsWritable import com.microsoft.ml.spark.{HasInputCol, HasOutputCol} import com.microsoft.ml.spark.ConstructorWritable import com.microsoft.ml.spark.ConstructorReadable import com.microsoft.ml.spark.Wrappable
Prestemos atención a ConstructorWritable , que simplifica enormemente la vida. Si nuestro Model es un modelo "entrenado" que devuelve el método fit(), , que está completamente determinado por su constructor (y esto es probablemente el 99% de los casos), entonces no podemos escribir la serialización con nuestras manos. Esto realmente simplifica y acelera enormemente el desarrollo, elimina errores y también reduce el umbral de entrada para DataScientist y analistas que generalmente no son programadores profesionales.
Defina nuestra clase de Estimator . De hecho, lo más importante aquí es el método de fit , el resto son puntos técnicos:
class GroupImputerEstimator(override val uid: String) extends Estimator[GroupImputerModel] with HasInputCol with HasOutputCol with Wrappable with DefaultParamsWritable { def this() = this(Identifiable.randomUID("GroupImputer")) val groupCol: Param[String] = new Param[String]( this, "groupCol", "Groupping column" ) def setGroupCol(v: String): this.type = super.set(groupCol, v) def getGroupCol: String = $(groupCol) override def fit(dataset: Dataset[_]): GroupImputerModel = { val meanDF = dataset .toDF .groupBy($(groupCol)) .agg(mean(col($(inputCol))).alias("groupMean")) .select(col($(groupCol)), col("groupMean")) new GroupImputerModel( uid, meanDF, getInputCol, getOutputCol, getGroupCol ) } override def transformSchema(schema: StructType): StructType = schema .add( StructField( $(outputCol), schema.filter(x => x.name == $(inputCol))(0).dataType ) ) override def copy(extra: ParamMap): Estimator[GroupImputerModel] = { val to = new GroupImputerEstimator(this.uid) copyValues(to, extra).asInstanceOf[GroupImputerEstimator] } }
Nota: No utilicé defaultCopy, porque cuando llamé, por alguna razón, juró que no tenía un constructor. \ <init> (java.lang.String), aunque parece que esto no debería haber sucedido. Bueno, en cualquier caso, la implementación de la copy fácil.
Ahora necesita implementar el Model , una clase que describe el modelo entrenado e implementa el método de transform . Lo crearemos en función de la función de coalesce integrada en org.apache.spark.sql.functions :
class GroupImputerModel( val uid: String, val meanDF: DataFrame, val inputCol: String, val outputCol: String, val groupCol: String ) extends Model[GroupImputerModel] with ConstructorWritable[GroupImputerModel] { val ttag: TypeTag[GroupImputerModel] = typeTag[GroupImputerModel] def objectsToSave: List[Any] = List(uid, meanDF, inputCol, outputCol, groupCol) override def copy(extra: ParamMap): GroupImputerModel = new GroupImputerModel(uid, meanDF, inputCol, outputCol, groupCol) override def transform(dataset: Dataset[_]): DataFrame = { dataset .toDF .join(meanDF, Seq(groupCol), "left") .withColumn( outputCol, coalesce(col(inputCol), col("groupMean")) .cast(IntegerType)) .drop("groupMean") } override def transformSchema (schema: StructType): StructType = schema .add( StructField(outputCol, schema.filter(x => x.name == inputCol)(0).dataType) ) }
El último objeto que necesitamos declarar es un Reader , que implementamos usando la clase MMLSpark ConstructorReadable :
object GroupImputerModel extends ConstructorReadable[GroupImputerModel]
Creación de tuberías
En Pipeline, me gustaría mostrar tanto las clases habituales de SparkML como lo increíblemente conveniente de MMLSpark - MultiColumnAdapter , que le permite aplicar transformadores SparkML a muchas columnas a la vez (por ejemplo, StringIndexer y OneHotEncoder toman exactamente una columna a la entrada, lo que los convierte anuncio en dolor):
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler} import org.apache.spark.ml.Pipeline import com.microsoft.ml.spark.{MultiColumnAdapter, LightGBMClassifier}
Primero, declararemos qué columnas tenemos:
val catCols = Array("Sex", "Embarked", "NameType") val numCols = Array("PClass", "AgeNoMissings", "SibSp", "Parch", "CabinCount", "CabinNumber")
Ahora cree un codificador de cadena:
val stringEncoder = new MultiColumnAdapter() .setBaseStage(new StringIndexer().setHandleInvalid("keep")) .setInputCols(catCols) .setOutputCols(catCols.map(x => x + "_freqEncoded"))
Nota: A diferencia de scikit-learn en SparkML, StringIndexer funciona según el principio del codificador de frecuencia, y puede usarse para especificar una relación de orden (es decir, categoría 0 <categoría 1, y esto tiene sentido): este enfoque a menudo funciona bien para Árboles decisivos.
Imputer nuestro Imputer :
val missingImputer = new GroupImputerEstimator() .setInputCol("Age") .setOutputCol("AgeNoMissings") .setGroupCol("Sex")
Y VectorAssembler , ya que los clasificadores SparkML se sienten más cómodos trabajando con VectorType :
val assembler = new VectorAssembler() .setInputCols(stringEncoder.getOutputCols ++ numCols) .setOutputCol("features")
Ahora utilizaremos el refuerzo de gradiente suministrado con MMLSpark - LightGBM, que se incluye en el "Big Three" de las mejores implementaciones de este algoritmo junto con XGBoost y CatBoost. Funciona muchas veces más rápido, mejor y más estable que la implementación de GBM que tiene SparkML (incluso teniendo en cuenta que el puerto JVM todavía está en desarrollo activo):
val catColIndices = Array(0, 1, 2) val lgbClf = new LightGBMClassifier() .setFeaturesCol("features") .setLabelCol("Survived") .setProbabilityCol("predictedProb") .setPredictionCol("predictedLabel") .setRawPredictionCol("rawPrediction") .setIsUnbalance(true) .setCategoricalSlotIndexes(catColIndices) .setObjective("binary")
Nota: LightGBM admite trabajar con variables categóricas (casi como catboost), por lo que le indicamos de antemano dónde están los atributos de categoría en nuestro vector, y él mismo descubrirá qué hacer con ellos y cómo codificarlos.
Más información sobre las características de LightGBM para Spark- En los nodos que ejecutan RadHat LightGBM, cualquier versión, excepto la más reciente, se bloqueará debido al hecho de que no le gusta la versión
glibc . Sin embargo, esto se solucionó recientemente cuando se instala a través de Maven, MMLSpark extrae la penúltima versión de LightGBM cuando se instala a través de Maven, por lo que debe agregar la dependencia de la última versión en RadHat con sus manos. - LightGBM en su trabajo crea un socket en el controlador para la comunicación con los ejecutivos, y lo hace usando el
new java.net.ServerSocket(0) , y por lo tanto se utiliza un puerto aleatorio de los puertos efímeros del sistema operativo. Si el rango de puertos efímeros difiere del rango de puertos abiertos por el firewall, entonces puede quemar mucho Puede obtener un efecto interesante cuando LightGBM a veces funciona (cuando elijo un buen puerto), y a veces no. Y habrá errores como ConnectionTimeOut , que también pueden indicar, por ejemplo, la opción cuando GC se cuelga de los ejecutivos o algo así. En general, no repitas mis errores.
Bueno, finalmente, declara nuestra tubería:
val pipeline = new Pipeline() .setStages( Array( missingImputer, nameTransformer, cabinsCountTransformer, numbersFromCabinTransformer, stringEncoder, assembler, lgbClf ) )
Entrenamiento
Romperemos nuestro conjunto de entrenamiento en un tren y una prueba y revisaremos nuestra tubería. Aquí puede evaluar la conveniencia de la tubería, ya que es completamente independiente de la partición y garantiza que aplicaremos las mismas transformaciones para entrenar y probar, y todos los parámetros de transformación se aprenderán en el tren:
val Array(trainDF, testDF) = trainFiltered.randomSplit(Array(0.8, 0.2)) println(s"Train rows: ${trainDF.count}\nTest rows: ${testDF.count}")
Para el cálculo conveniente de las métricas, utilizaremos otra clase de MMLSpark: ComputeModelStatistics :
import com.microsoft.ml.spark.ComputeModelStatistics import com.microsoft.ml.spark.metrics.MetricConstants val modelEvaluator = new ComputeModelStatistics() .setLabelCol("Survived") .setScoresCol("predictedProb") .setScoredLabelsCol("predictedLabel") .setEvaluationMetric(MetricConstants.ClassificationMetrics)
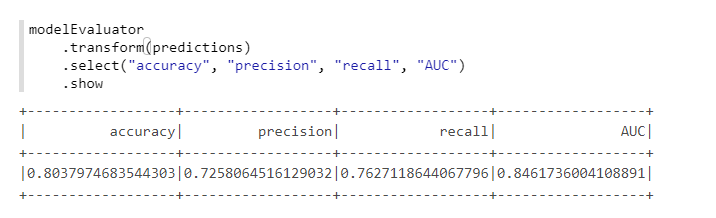
No está mal, dado que no cambiamos la configuración predeterminada.
Selección de hiperparámetros
Para seleccionar hiperparámetros en MMLSpark, hay una cosa interesante TuneHyperparameters , TuneHyperparameters , que implementa una búsqueda aleatoria en la cuadrícula. Sin embargo, desafortunadamente, todavía no es compatible con Pipeline , por lo que usaremos el SparkML CrossValidator habitual:
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator} import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator val paramSpace = new ParamGridBuilder() .addGrid(lgbClf.maxDepth, Array(3, 5)) .addGrid(lgbClf.learningRate, Array(0.05, 0.1)) .addGrid(lgbClf.numIterations, Array(100, 300)) .build println(s"Size of ParamsGrid: ${paramSpace.size}")
Desafortunadamente, no encontré una forma conveniente de ver los resultados junto con los parámetros en los que se obtuvieron. Por lo tanto, es necesario usar diseños "monstruosos":
crossValidator .getEstimatorParamMaps .zip(bestModel.avgMetrics) .foreach(x => { println( "\n" + x._1 .toSeq .foldLeft(new StringBuilder())( (a, b) => a .append(s"\n\t${b.param.name} : ${b.value}")) .toString + s"\n\tMetric: ${x._2}" ) })
Lo que nos da algo como esto:
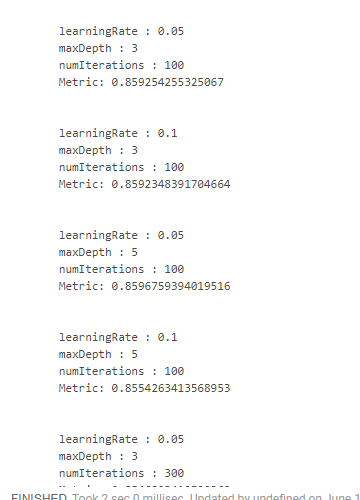
Obtuvimos el mejor resultado al reducir la velocidad de aprendizaje y aumentar la profundidad de los árboles. Sobre esta base, sería posible ajustar el espacio de búsqueda y llegar a un resultado aún más óptimo, pero simplemente no tenemos ese objetivo.
Conclusión
De hecho, mientras que MMLSpark tiene la versión 0.17 y todavía contiene errores separados. Pero de todas las extensiones de Spark que he visto, MMLSpark en mi opinión tiene la documentación más completa y el proceso de instalación e implementación más comprensible. Microsoft todavía no lo ha promocionado realmente, solo hubo un informe sobre los Databricks , pero fue más sobre DeepLearning y no sobre cosas tan rutinarias sobre las que escribí.
Personalmente, en nuestras tareas, esta biblioteca ayudó mucho, permitiéndome recorrer un poco menos la jungla de las fuentes de Spark y no usar el reflejo para acceder a métodos privados [ml], y un colega encontró la biblioteca casi por accidente. Al mismo tiempo, debido al hecho de que la biblioteca está en desarrollo activo, la estructura del archivo fuente papilla llena algo confuso Bueno, debido al hecho de que no hay ejemplos especiales u otra documentación (excepto Scaladoc desnudo), al principio tuve que arrastrarme a la fuente todo el tiempo.
Por lo tanto, realmente espero que este mini tutorial (a pesar de toda su obviedad y simplicidad) sea útil para alguien y ayude a ahorrar mucho tiempo y esfuerzo.