El curso completo en ruso se puede encontrar en este enlace .
El curso de inglés original está disponible en este enlace .

Nuevas conferencias están programadas cada 2-3 días.
Contenido
- Entrevista con Sebastian Trun
- Introduccion
- Conjunto de datos de perros y gatos
- Imágenes de varios tamaños.
- Imágenes a color. Parte 1
- Imágenes a color. Parte 2
- Operación de convolución en imágenes en color
- La operación de submuestreo por el valor máximo en imágenes en color
- CoLab: gatos y perros
- Softmax y sigmoide
- Cheque
- Extensión de imagen
- Excepción
- CoLab: perros y gatos. Repetición
- Otras técnicas para prevenir el reentrenamiento
- Ejercicios: clasificación de imágenes en color.
- Solución: clasificación de imágenes en color
- Resumen
Entrevista con Sebastian Trun
- Entonces, hoy estamos aquí nuevamente, junto con Sebastian y hablaremos sobre el reciclaje. Este tema es muy interesante para nosotros, especialmente en las partes prácticas del curso actual sobre cómo trabajar con TensorFlow.
- Sebastian, ¿alguna vez has encontrado un sobreajuste? Si dices que no te has encontrado, ¡definitivamente diré que no puedo creerte!
- Entonces, la razón para la reentrenamiento es la denominada compensación de desviación de sesgo (un compromiso entre los valores del parámetro de sesgo y su propagación). Una red neuronal en la que una pequeña cantidad de pesas no puede aprender una cantidad suficiente de ejemplos, una situación similar en el aprendizaje automático se llama distorsión.
- si.
- Una red neuronal con tantos parámetros puede elegir arbitrariamente una solución que no le guste, solo por la gran cantidad de estos parámetros. El resultado de elegir una solución de red neuronal depende de la variabilidad de los datos de origen. Por lo tanto, se puede formular una regla simple: cuantos más parámetros haya en la red con respecto al tamaño (cantidad) de datos, es más probable que obtenga una solución aleatoria en lugar de la correcta. Por ejemplo, te preguntas: "¿Quién es el hombre en esta habitación y quién es la mujer?" Una red neuronal compleja puede decirle que, por ejemplo, todos aquellos cuyos nombres comienzan con T son hombres y nunca se vuelven a entrenar. Hay dos soluciones El primero de ellos utiliza un conjunto de datos de reserva (una pequeña cantidad del conjunto de entrenamiento para validar la precisión del modelo). Puede tomar los datos, dividirlos en dos partes: 90% para entrenamiento y 10% para probar y realizar la llamada validación cruzada, donde verifica la precisión del modelo en los datos que la red neuronal no vio, tan pronto como comienza el valor de error crecer después de cierto ciclo de entrenamiento: es hora de dejar de aprender. La segunda solución es introducir restricciones en la red neuronal. Por ejemplo, para limitar los valores de los parámetros de desplazamientos y pesos, acercándolos cada vez más a cero. Cuanto más limitados sean los pesos, menos entrenado será el modelo.
- Entiendo correctamente que podemos tener conjuntos de datos tanto para capacitación como para pruebas y validación, ¿verdad?
Eso es correcto. Si tiene un conjunto de datos para la validación, debe tener un conjunto de datos que nunca haya tocado o mostrado a su red neuronal. Si le mostró al modelo un determinado conjunto de datos muchas veces, entonces, por supuesto, comenzará el proceso de reciclaje, lo cual es muy malo para nosotros.
- ¿Quizás recuerde los casos más interesantes cuando su modelo fue reentrenado?
- Ah, sí ... hubo un incidente en mi juventud cuando estaba desarrollando una red neuronal para jugar al ajedrez. Fue en 1993. Lo interesante fue que a partir de los datos de ajedrez en los que se entrenó la red neuronal, la red rápidamente determinó que si un experto mueve a la reina al centro del tablero de ajedrez, entonces hay un 60% de posibilidades de ganar. Lo que ella comenzó a hacer fue abrir el "pasaje" con un peón y mover a la reina al centro del tablero de ajedrez. Fue una decisión tan estúpida para cualquier jugador de ajedrez, lo que claramente atestiguó el reciclaje del modelo.
- Genial! Por lo tanto, hemos discutido varias técnicas sobre cómo mejorar nuestros modelos. ¿Cuál crees que es el lado más subestimado del aprendizaje profundo?
- El 90% de su trabajo se subestima, porque el 90% de su trabajo consistirá en la limpieza de datos.
- ¡Aquí estoy completamente de acuerdo contigo!
- Como muestra la práctica, cualquier conjunto de datos contiene algún tipo de basura. Es muy difícil llevar los datos al tipo correcto, para que sean consistentes, es un proceso que lleva mucho tiempo.
- Sí, incluso si trabaja con conjuntos de datos como imágenes o videos, donde, al parecer, toda la información ya está allí, en el interior, todavía es necesario procesar previamente las imágenes.
- ¡Las únicas personas para quienes los datos son ideales son los profesores, porque tienen la oportunidad de pretender en una presentación en PowerPoint que todo es como debe ser y todo es perfecto! En realidad, el 90% de su tiempo estará ocupado por la limpieza de datos.
- Genial Entonces, descubramos más sobre el reciclaje y las técnicas que nos permitirán mejorar nuestros modelos de aprendizaje profundo.
Introduccion
- hola! Y de nuevo, ¡bienvenido al curso!
- En la última lección, desarrollamos una pequeña red neuronal convolucional para clasificar imágenes de elementos de ropa en tonos de gris del conjunto de datos FASHION MNIST. Hemos visto en la práctica que nuestra pequeña red neuronal puede clasificar las imágenes entrantes con una precisión bastante alta. Sin embargo, en el mundo real tenemos que trabajar con imágenes de alta resolución y varios tamaños. Una de las grandes ventajas del SNA es el hecho de que pueden funcionar igual de bien con imágenes en color. Por lo tanto, comenzaremos nuestra lección actual explorando cómo funciona el SNA con imágenes en color.
- Más tarde, en la misma frecuencia, construirá una red neuronal convolucional que puede clasificar imágenes de gatos y perros. En el camino hacia la implementación de una red neuronal convolucional capaz de clasificar imágenes de gatos y perros, también aprenderemos cómo usar diversas técnicas para resolver uno de los problemas más comunes con las redes neuronales: el reentrenamiento. Y al final de esta lección, en la parte práctica, desarrollará su propia red neuronal convolucional para clasificar imágenes en color. ¡Empecemos!
Conjunto de datos de gatos y perros
Hasta ese momento, solo trabajábamos con imágenes en escala de grises y tamaños 28x28 del conjunto de datos FASHION MNIST.

En aplicaciones reales, nos vemos obligados a encontrar imágenes de varios tamaños, por ejemplo, las que se muestran a continuación:

Como mencionamos al comienzo de esta lección, en esta lección desarrollaremos una red neuronal convolucional que puede clasificar imágenes en color de perros y gatos.
Para implementar nuestros planes, utilizaremos imágenes de gatos y perros del conjunto de datos de Microsoft Asirra. Cada imagen en este conjunto de datos se etiqueta como 1 o 0 si hay un perro o un gato en la imagen, respectivamente.

A pesar de que el conjunto de datos de Microsoft Asirra contiene más de 3 millones de imágenes etiquetadas de gatos y perros, solo 25,000 están disponibles públicamente. La capacitación de nuestra red neuronal convolucional en estas 25,000 imágenes llevará mucho tiempo. Es por eso que utilizaremos una pequeña cantidad de imágenes para entrenar nuestra red neuronal convolucional de los 25,000 disponibles.
Nuestro subconjunto de imágenes de entrenamiento consta de 2,000 pcs y 1,000 pcs de imágenes para la validación del modelo. En el conjunto de datos de entrenamiento, 1,000 imágenes contienen gatos y las otras 1,000 imágenes contienen perros. Hablaremos sobre el conjunto de datos para la validación un poco más adelante en esta parte de la lección.
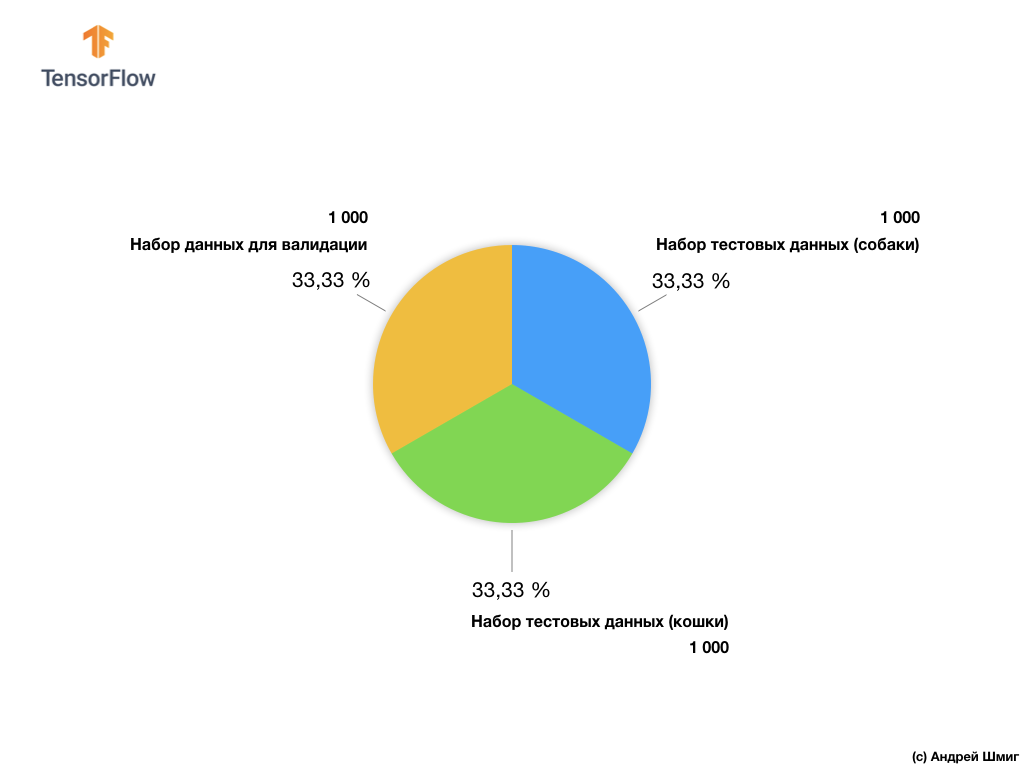
Al trabajar con este conjunto de datos, encontraremos dos dificultades principales: trabajar con imágenes de diferentes tamaños y trabajar con imágenes en color.
Comencemos a explorar cómo trabajar con imágenes de varios tamaños.
Imágenes de varios tamaños.
Nuestra primera prueba será resolver el problema del procesamiento de imágenes de varios tamaños. Esto se debe a que una red neuronal en la entrada necesita datos de tamaño fijo.
Como ejemplo, puede recordar nuestras partes anteriores utilizando el parámetro input_shape al crear una capa Flatten :

Antes de transmitir la imagen de un elemento de ropa a una red neuronal, la convertimos en una matriz 1D de tamaño fijo: 28x28 = 784 elementos (píxeles). Como las imágenes del conjunto de datos Fashion MNIST tenían el mismo tamaño, la matriz unidimensional resultante tenía el mismo tamaño y constaba de 784 elementos.
Sin embargo, al trabajar con imágenes de varios tamaños (alto y ancho) y transformarlas en matrices unidimensionales, obtenemos matrices de diferentes tamaños.
Dado que las redes neuronales en la entrada requieren datos del mismo tamaño, no es suficiente simplemente salirse con la conversión a una matriz unidimensional de valores de píxeles.
Para resolver los problemas de clasificación de imágenes, siempre recurrimos a una de las opciones para unificar los datos de entrada, reduciendo el tamaño de las imágenes a valores comunes (cambio de tamaño).
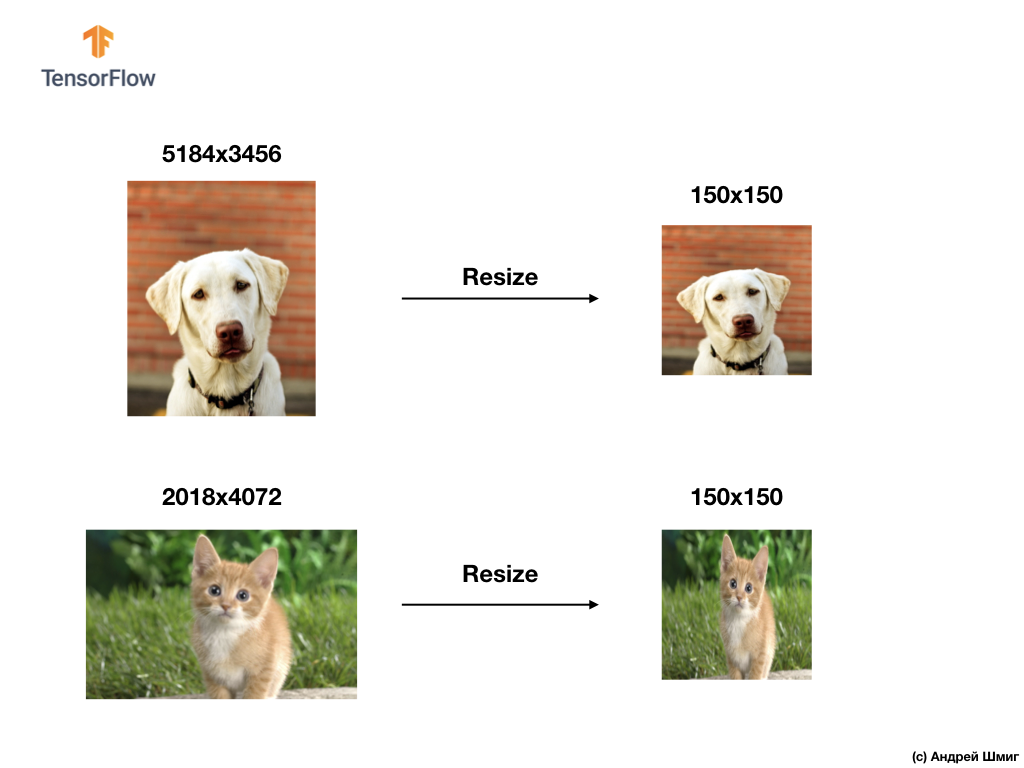
En este tutorial, recurriremos a cambiar el tamaño de todas las imágenes a tamaños de 150 píxeles de alto y 150 píxeles de ancho. Al convertir imágenes a un tamaño único, garantizamos que la imagen del tamaño correcto llegará a la entrada de la red neuronal y, cuando se transfiere a una capa flatten , obtenemos una matriz unidimensional del mismo tamaño.
tf.keras.layers.Flatten(input_shape(150,150,1))
Como resultado, obtuvimos una matriz unidimensional que consta de 150x150 = 22,500 valores (píxeles).
El siguiente problema que enfrentaremos será el problema del color: las imágenes en color. Hablaremos de ellos en la siguiente parte.
Imágenes a color. Parte 1
Para comprender y entender cómo funcionan las redes neuronales convolucionales con imágenes en color, debemos profundizar en cómo funciona exactamente el SNA en general. Actualicemos lo que ya sabemos.
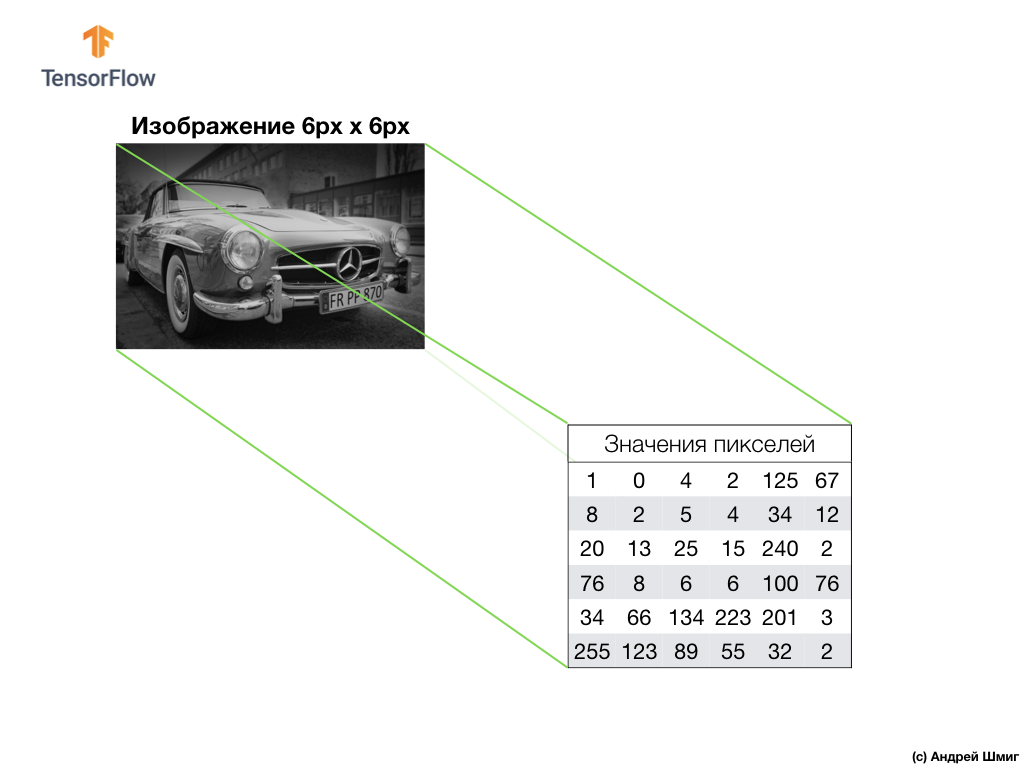
Un ejemplo anterior es una imagen en escala de grises y cómo la computadora la interpreta como una matriz bidimensional de valores de píxeles.
Un ejemplo a continuación es una imagen, esta vez un color, y cómo la computadora lo interpreta como una matriz tridimensional de valores de píxeles.
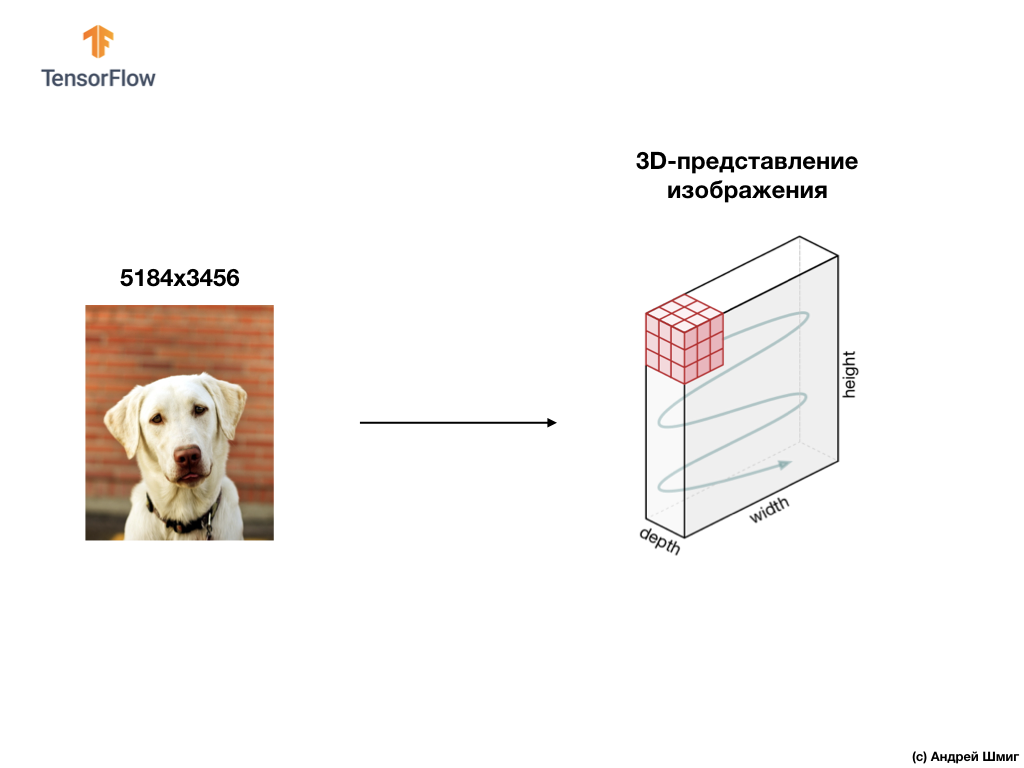
La altura y el ancho de la matriz 3D estarán determinados por la altura y el ancho de la imagen, y la profundidad (profundidad) determina el número de canales de color de la imagen.
La mayoría de las imágenes en color se pueden representar mediante tres canales de color: rojo (rojo), verde (verde) y azul (azul).

Las imágenes que consisten en canales rojo, verde y azul se denominan imágenes RGB. La combinación de estos tres canales da como resultado una imagen en color. En cada una de las imágenes RGB, cada canal está representado por una matriz de píxeles bidimensional separada.
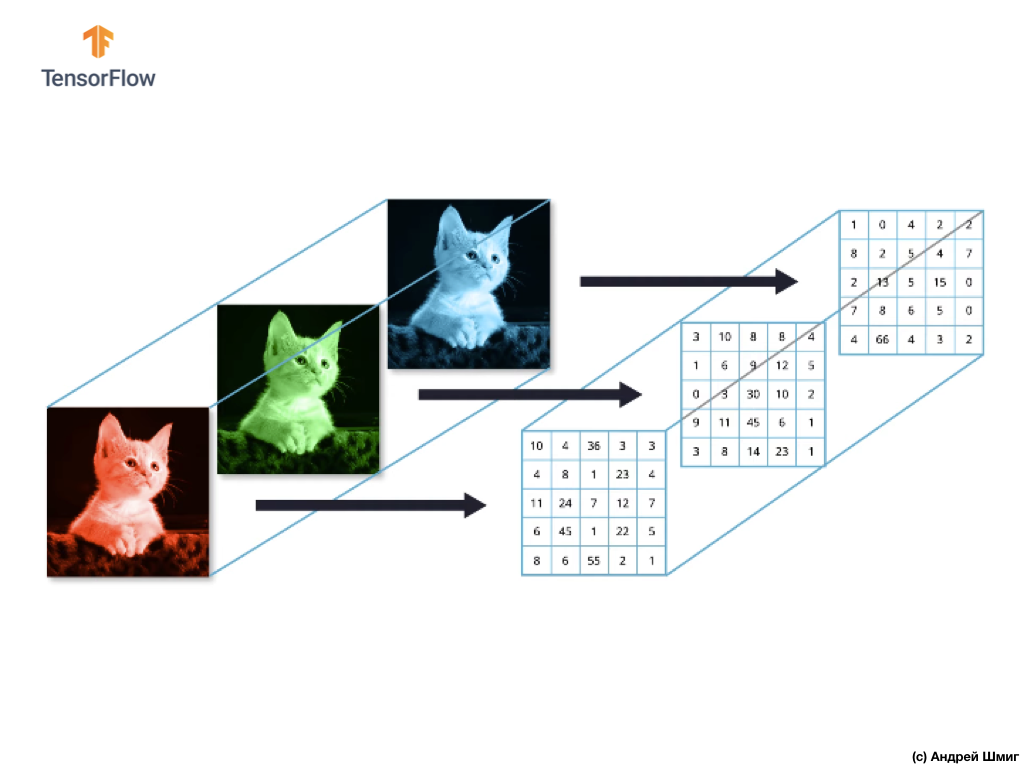
Dado que el número de canales que tenemos es tres, como resultado tendremos tres matrices bidimensionales. Por lo tanto, una imagen en color que consta de 3 canales de color tendrá la siguiente representación:

Imágenes a color. Parte 2
Entonces, dado que nuestra imagen ahora constará de 3 colores, lo que significa que será una matriz tridimensional de valores de píxeles, entonces nuestro código deberá cambiarse en consecuencia.
Si observa el código que usamos en nuestra última lección cuando resolvimos el problema de clasificar elementos de ropa en imágenes, podemos ver que indicamos la dimensión de los datos de entrada:
model = Sequential() model.add(Conv2D(32, 3, padding='same', activation='relu', input_shape=(28,28,1)))
Los dos primeros parámetros de la tupla (28,28,1) son los valores de la altura y el ancho de la imagen. Las imágenes en el conjunto de datos Fashion MNIST tenían un tamaño de 28x28 píxeles. El último parámetro en la tupla (28,28,1) denota el número de canales de color. En el conjunto de datos Fashion MNIST, las imágenes solo estaban en tonos de gris - 1 canal de color.
Ahora que la tarea se ha vuelto un poco más complicada, y nuestras imágenes de gatos y perros se han hecho de diferentes tamaños (pero convertidas en una sola - 150x150 píxeles) y contienen 3 canales de color, entonces la tupla de valores también debería ser diferente:
model = Sequential() model.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(150,150,3)))
En la siguiente parte, veremos cómo se calcula la convolución en presencia de tres canales de color en la imagen.
Operación de convolución en imágenes en color
En lecciones pasadas, aprendimos cómo realizar una operación de convolución en imágenes en escala de grises. Pero, ¿cómo realizar una operación de convolución en imágenes en color? Comencemos repitiendo cómo se realiza la operación de convolución en imágenes en escala de grises.
Todo comienza con un filtro (núcleo) de cierto tamaño.
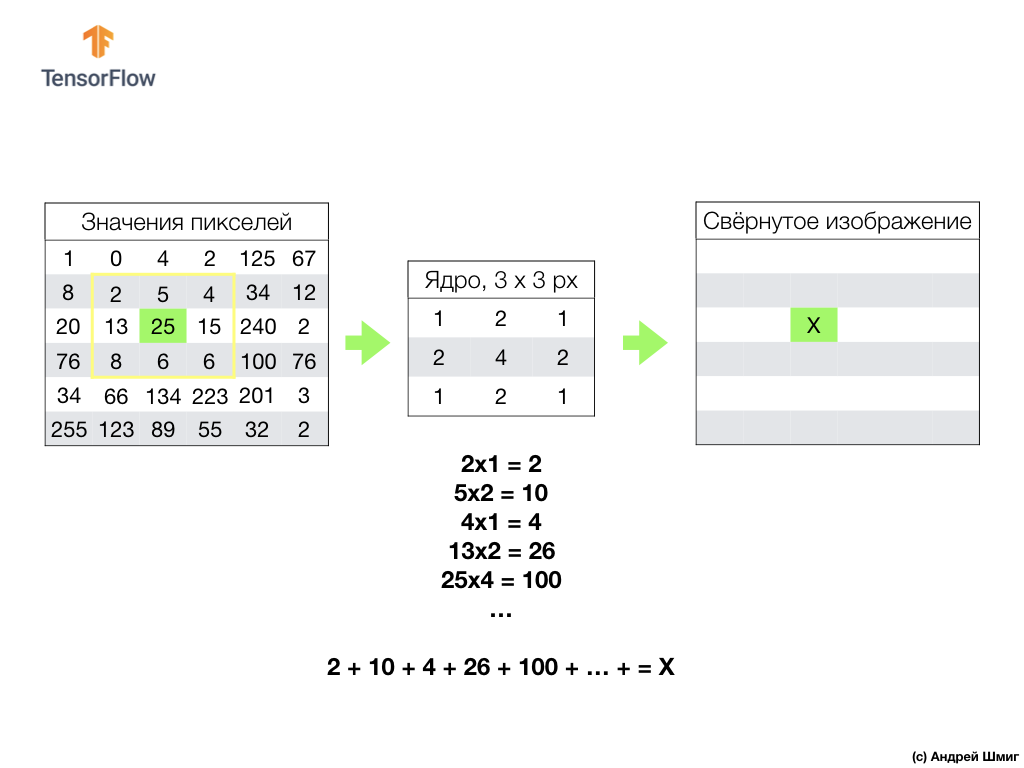
El filtro se encuentra en un píxel de imagen específico para convertir, luego cada valor de filtro se multiplica por el valor de píxel correspondiente en la imagen y se suman todos estos valores. El valor final del píxel se establece en la nueva imagen en el lugar donde se encontraba el píxel original convertido. La operación se repite para cada píxel de la imagen original.
También vale la pena recordar que durante la operación de convolución, para no perder información en los bordes de la imagen, podemos aplicar la alineación y rellenar los bordes de la imagen con ceros:

Ahora veamos cómo podemos realizar la operación de convolución en imágenes en color.
Al igual que cuando se convierte una imagen en tonos de gris, comenzamos eligiendo el tamaño del filtro (núcleo) de cierto tamaño.

La única diferencia ahora será que ahora el filtro en sí será tridimensional, y el valor del parámetro de profundidad será igual al valor del número de canales de color en la imagen - 3 (en nuestro caso, RGB). Para cada "capa" del canal de color, también aplicaremos la operación de convolución con un filtro del tamaño seleccionado. Veamos cómo será un ejemplo.
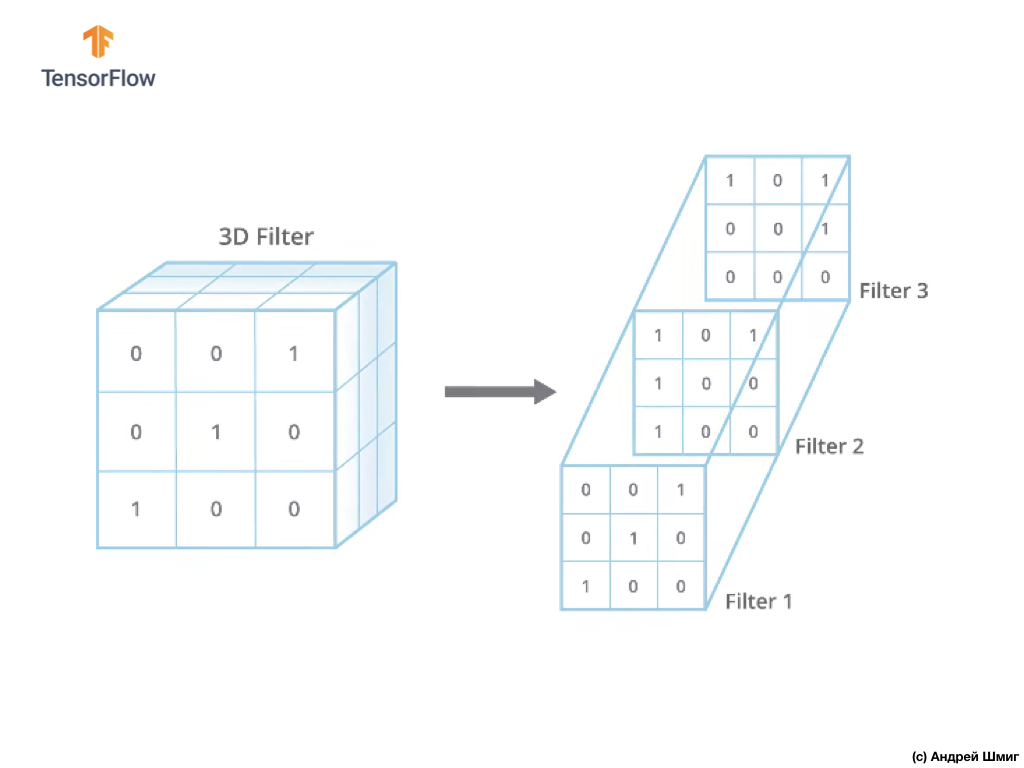
Imagine que tenemos una imagen RGB y queremos aplicar la operación de convolución con el siguiente filtro 3D. Vale la pena prestar atención al hecho de que nuestro filtro consta de 3 filtros bidimensionales. Para simplificar, imaginemos que nuestra imagen RGB tiene un tamaño de 5x5 píxeles.

Recuerde también que cada canal de color es una matriz bidimensional de valores de color de píxeles.
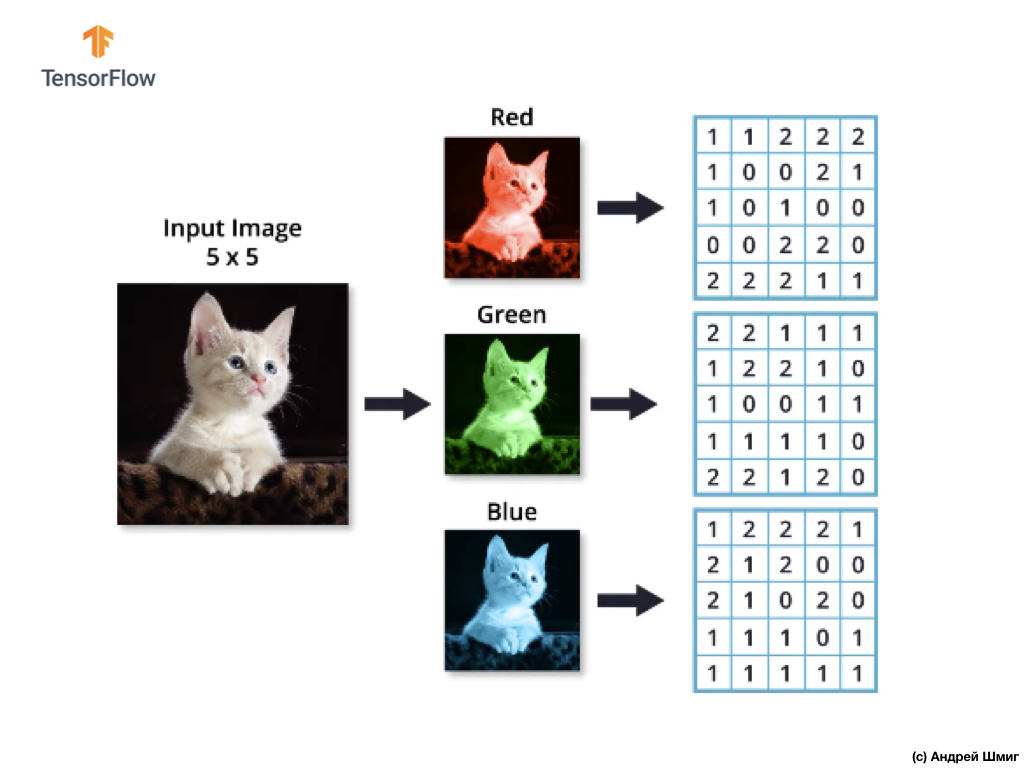
Al igual que con la operación de convolución sobre imágenes en tonos de gris, así como con imágenes en color, realizaremos la alineación y complementaremos la imagen en los bordes con ceros para evitar la pérdida de información en los bordes.
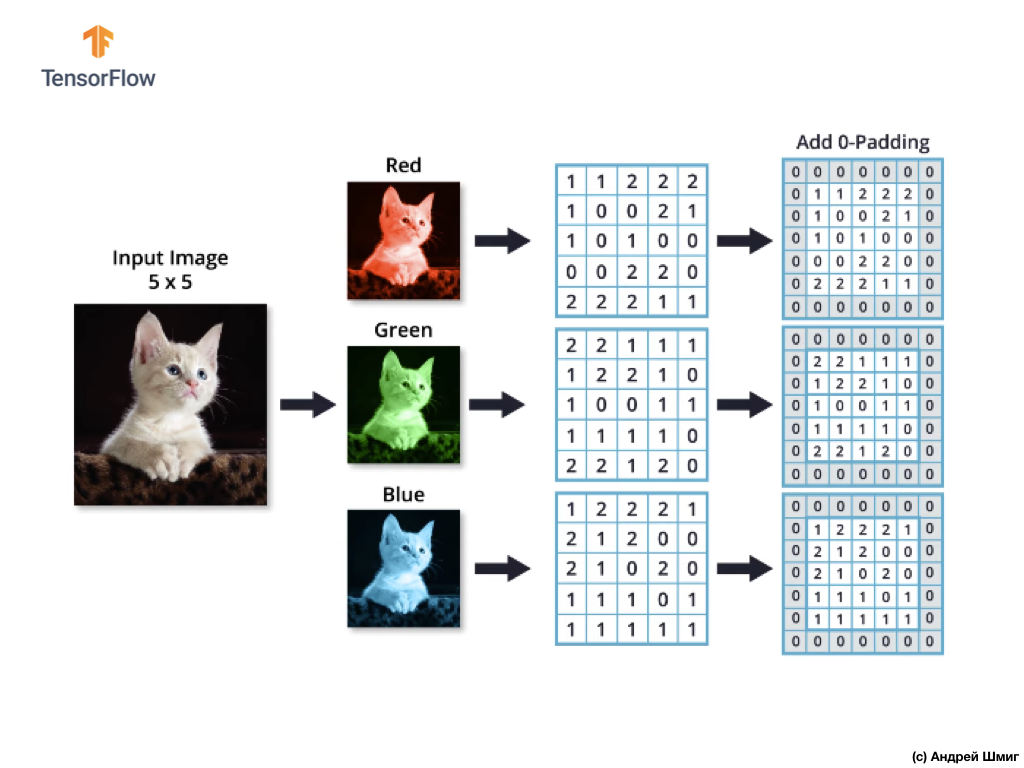
¡Ahora estamos listos para la operación de convolución!
El mecanismo de convolución para imágenes en color será similar al proceso que realizamos con imágenes en escala de grises. La única diferencia entre las operaciones realizadas en imágenes en escala de grises y en color es que la operación de convolución ahora debe realizarse 3 veces para cada canal de color.
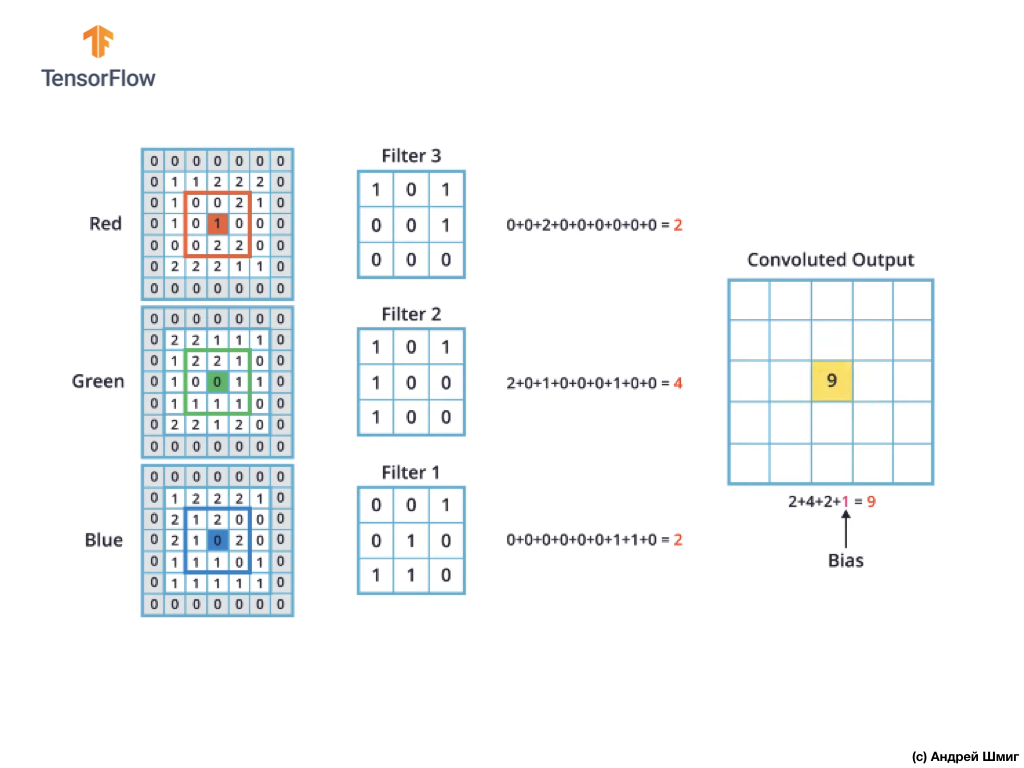
Luego, después de haber realizado la operación de convolución en cada canal de color, sume los tres valores obtenidos y agregue 1 a ellos (el valor estándar utilizado al realizar operaciones de este tipo). El nuevo valor resultante se fija en la misma posición en la nueva imagen, en qué posición estaba el píxel convertido actual.
Realizamos una operación de conversión similar (una operación de convolución) para cada píxel en nuestra imagen original y para cada canal de color.
En este ejemplo particular, la imagen resultante tiene el mismo tamaño en altura y ancho que nuestra imagen RGB original.
Como puede ver, la aplicación de la operación de convolución con un solo filtro 3D da como resultado un único valor de salida.
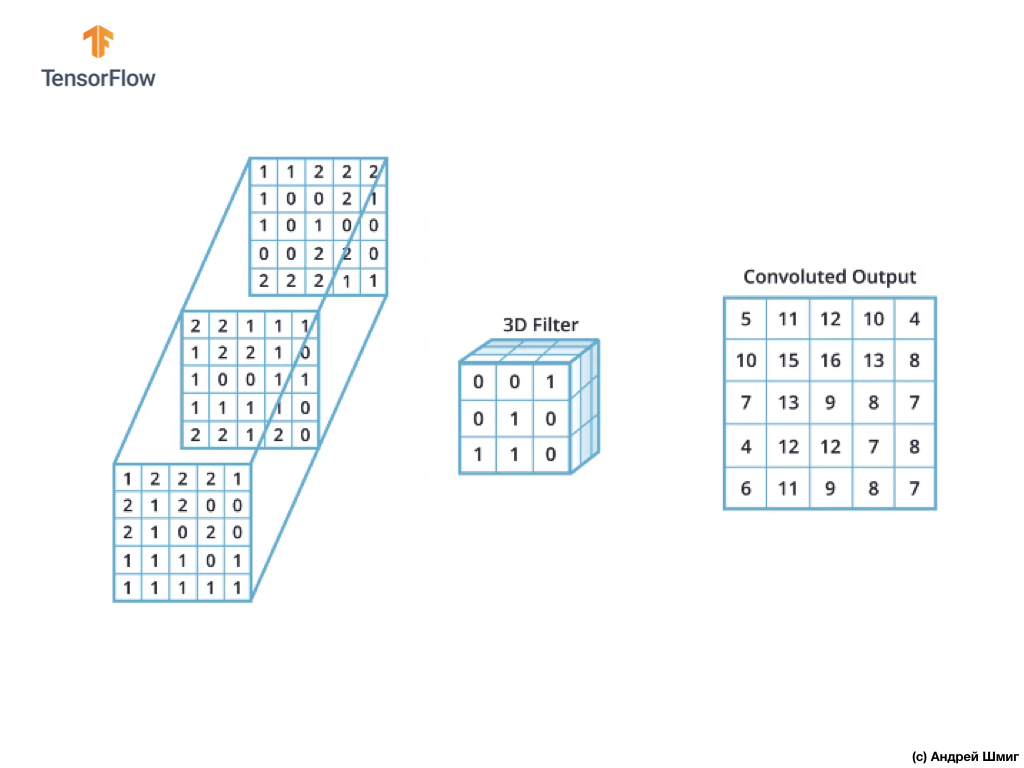
Sin embargo, cuando se trabaja con redes neuronales convolucionales, es una práctica común usar más de un filtro 3D. Si utilizamos más de un filtro 3D, el resultado será varios valores de salida: cada valor es el resultado de un filtro.
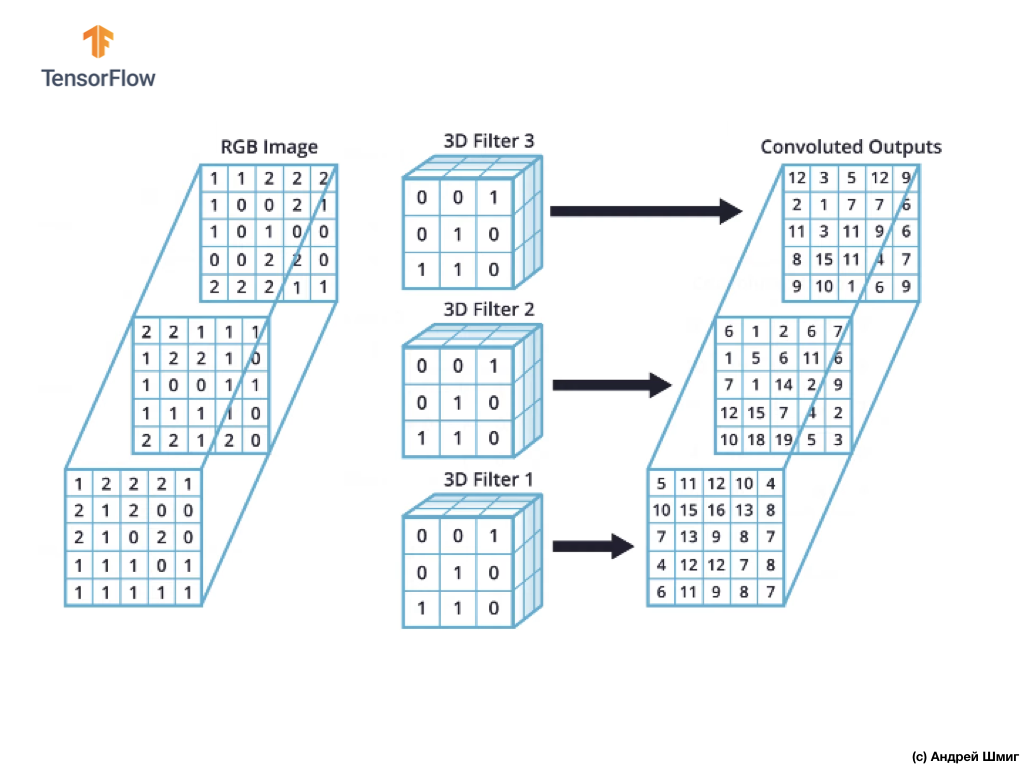
En nuestro ejemplo anterior, dado que usamos 3 filtros, la representación 3D resultante tendrá una profundidad de 3: cada capa corresponderá al valor de salida de la conversión de un filtro sobre la imagen con todos sus canales de color.
Si, por ejemplo, en lugar de 3 filtros, decidimos usar 16, entonces la representación 3D de salida contendría 16 capas de profundidad.
En el código, podemos controlar la cantidad de filtros creados al pasar el valor apropiado para el parámetro de filters :
tf.keras.layers.Conv2D(filters, kernel_size, ...)
También podemos especificar el tamaño del filtro a través del parámetro kernel_size . Por ejemplo, para crear 3 filtros de tamaño 3x3, como fue el caso en nuestro ejemplo anterior, podemos escribir el código de la siguiente manera:
tf.keras.layers.Conv2D(3, (3,3), ...)
Recuerde que durante el entrenamiento de la red neuronal convolucional, los valores en los filtros 3D se actualizarán para minimizar el valor de la función de pérdida.
Ahora que sabemos cómo realizar la operación de convolución en imágenes en color, es hora de descubrir cómo aplicar la operación de submuestreo al resultado máximo por el valor máximo (la misma agrupación máxima).
La operación de submuestreo por el valor máximo en imágenes en color
Aprendamos ahora cómo realizar la operación de submuestreo con el valor máximo en imágenes en color. De hecho, la operación de submuestreo por el valor máximo funciona de la misma manera que funciona con imágenes en tonos de gris con una ligera diferencia: la operación de submuestreo ahora debe aplicarse a cada representación de salida que recibimos como resultado de la aplicación de filtros. Veamos un ejemplo.
Para simplificar, imaginemos que nuestra vista de salida se ve así:
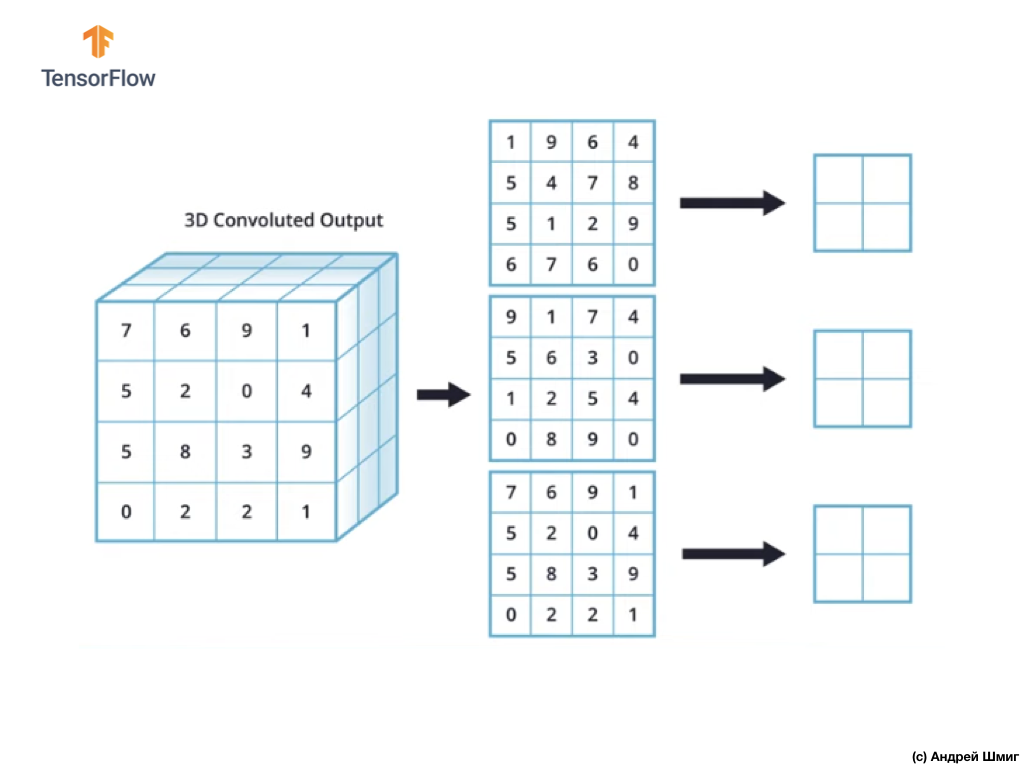
Como antes, utilizaremos un kernel 2x2 y el paso 2 para realizar la operación de submuestreo en el valor máximo. La operación de submuestreo por el valor máximo comienza con la "instalación" de un núcleo de 2x2 en la esquina superior izquierda de cada representación de salida (la representación que se obtuvo después de aplicar la operación de convolución).

Ahora podemos comenzar la operación de submuestreo en el valor máximo. Por ejemplo, en nuestra primera representación de salida, los siguientes valores cayeron en el núcleo 2x2: 1, 9, 5, 4. Dado que el valor máximo en este núcleo es 9, es el que se envía a la nueva representación de salida. Se repite una operación similar para cada representación de entrada.
Como resultado, deberíamos obtener el siguiente resultado:

Después de realizar la operación de submuestreo por el valor máximo, el resultado es 3 matrices bidimensionales, cada una de las cuales es 2 veces más pequeña que la representación de entrada original.
Por lo tanto, en este caso particular, al realizar la operación de submuestreo por el valor máximo sobre la representación de entrada tridimensional, obtenemos una representación de salida tridimensional de la misma profundidad, pero con los valores de altura y anchura la mitad de los valores iniciales.
Entonces, esta es toda la teoría que necesitaremos para seguir trabajando. ¡Ahora veamos cómo funciona esto en código!
CoLab: gatos y perros
Original CoLab en inglés está disponible en este enlace .
CoLab en ruso está disponible en este enlace .
En este tutorial, discutiremos cómo clasificar las imágenes de gatos y perros. Desarrollaremos un clasificador de imágenes utilizando el modelo tf.keras.Sequential y usaremos tf.keras.Sequential para cargar los datos.
Ideas para ser cubiertas en esta parte:
Obtendremos experiencia práctica en el desarrollo de un clasificador y desarrollaremos una comprensión intuitiva de los siguientes conceptos:
- Construir un modelo de flujo de datos ( tuberías de entrada de datos ) usando
tf.keras.preprocessing.image.ImageDataGenerator (¿Cómo trabajar eficientemente con datos en el disco interactuando con el modelo?) - Reciclaje: ¿qué es y cómo determinarlo?
Antes de comenzar ...
Antes de comenzar el código en el editor, le recomendamos que restablezca todas las configuraciones en Runtime -> Restablecer todo en el menú superior. Tal acción ayudará a evitar problemas con la falta de memoria, si trabajó en paralelo o está trabajando con varios editores.
Importar paquetes
Comencemos importando los paquetes que necesita:
os - leer archivos y estructuras de directorios;numpy : para algunas operaciones matriciales fuera de TensorFlow;matplotlib.pyplot : trazar y mostrar imágenes de un conjunto de datos de prueba y validación.
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt import numpy as np
Importar TensorFlow :
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Carga de datos
Comenzamos el desarrollo de nuestro clasificador cargando un conjunto de datos. El conjunto de datos que utilizamos es una versión filtrada del conjunto de datos Dogs vs Cats del servicio Kaggle (al final, Microsoft Research proporciona este conjunto de datos).
En el pasado, CoLab y yo usamos un conjunto de datos del propio módulo TensorFlow Dataset , que es extremadamente conveniente para el trabajo y las pruebas. En este CoLab, sin embargo, utilizaremos la clase tf.keras.preprocessing.image.ImageDataGenerator para leer datos del disco. Por lo tanto, primero debemos descargar el conjunto de datos Dog VS Cats y descomprimirlo.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip' zip_dir = tf.keras.utils.get_file('cats_and_dogs_filterted.zip', origin=_URL, extract=True)
El conjunto de datos que descargamos tiene la siguiente estructura:
cats_and_dogs_filtered |__ train |______ cats: [cat.0.jpg, cat.1.jpg, cat.2.jpg ...] |______ dogs: [dog.0.jpg, dog.1.jpg, dog.2.jpg ...] |__ validation |______ cats: [cat.2000.jpg, cat.2001.jpg, cat.2002.jpg ...] |______ dogs: [dog.2000.jpg, dog.2001.jpg, dog.2002.jpg ...]
Para obtener una lista completa de directorios, puede usar el siguiente comando:
zip_dir_base = os.path.dirname(zip_dir) !find $zip_dir_base -type d -print
Como resultado, obtenemos algo similar:
/root/.keras/datasets /root/.keras/datasets/cats_and_dogs_filtered /root/.keras/datasets/cats_and_dogs_filtered/train /root/.keras/datasets/cats_and_dogs_filtered/train/dogs /root/.keras/datasets/cats_and_dogs_filtered/train/cats /root/.keras/datasets/cats_and_dogs_filtered/validation /root/.keras/datasets/cats_and_dogs_filtered/validation/dogs /root/.keras/datasets/cats_and_dogs_filtered/validation/cats
Ahora asigne las rutas correctas a los directorios con los conjuntos de datos para capacitación y validación de las variables:
base_dir = os.path.join(os.path.dirname(zip_dir), 'cats_and_dogs_filtered') train_dir = os.path.join(base_dir, 'train') validation_dir = os.path.join(base_dir, 'validation') train_cats_dir = os.path.join(train_dir, 'cats') train_dogs_dir = os.path.join(train_dir, 'dogs') validation_cats_dir = os.path.join(validation_dir, 'cats') validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Comprender los datos y su estructura.
Veamos cuántas imágenes de gatos y perros tenemos en los conjuntos de datos de prueba y validación (directorios).
num_cats_tr = len(os.listdir(train_cats_dir)) num_dogs_tr = len(os.listdir(train_dogs_dir)) num_cats_val = len(os.listdir(validation_cats_dir)) num_dogs_val = len(os.listdir(validation_dogs_dir)) total_train = num_cats_tr + num_dogs_tr total_val = num_cats_val + num_dogs_val
print(' : ', num_cats_tr) print(' : ', num_dogs_tr) print(' : ', num_cats_val) print(' : ', num_dogs_val) print('--') print(' : ', total_train) print(' : ', total_val)
La salida del último bloque será la siguiente:
: 1000 : 1000 : 500 : 500 -- : 2000 : 1000
Establecer parámetros del modelo
Para mayor comodidad, colocaremos la instalación de las variables que necesitamos para un mayor procesamiento de datos y capacitación de modelos en un anuncio separado:
BATCH_SIZE = 100
Preparación de datos
Antes de que las imágenes se puedan usar como entrada para nuestra red, deben convertirse a tensores con valores de coma flotante. Lista de pasos a seguir para hacer esto:
- Leer imágenes del disco
- Decodifique el contenido de la imagen y conviértalo al formato deseado teniendo en cuenta el perfil RGB
- Convertir a tensores con valores de coma flotante
- Para normalizar los valores del tensor del intervalo de 0 a 255 al intervalo de 0 a 1, ya que las redes neuronales funcionan mejor con valores de entrada pequeños.
Afortunadamente, todas estas operaciones se pueden realizar utilizando la clase tf.keras.preprocessing.image.ImageDataGenerator .
Podemos hacer todo esto usando varias líneas de código:
train_image_generator = ImageDataGenerator(rescale=1./255) validation_image_generator = ImageDataGenerator(rescale=1./255)
Después de haber definido los generadores para un conjunto de datos de prueba y validación, el método flow_from_directory cargará imágenes del disco, normalizará los datos y redimensionará las imágenes con solo una línea de código:
train_data_gen = train_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=train_dir, shuffle=True, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Conclusión
Found 2000 images belonging to 2 classes.
Generador de datos de validación:
val_data_gen = validation_image_generator.flow_from_directory(batch_size=BATCH_SIZE, directory=validation_dir, shuffle=False, target_size=(IMG_SHAPE,IMG_SHAPE), class_mode='binary')
Conclusión
Found 1000 images belonging to 2 classes.
Visualice las imágenes del conjunto de entrenamiento.
Podemos visualizar imágenes de un conjunto de datos de entrenamiento usando matplotlib :
sample_training_images, _ = next(train_data_gen)
La next función devuelve un bloque de imágenes del conjunto de datos. Un bloque es una tupla de (muchas imágenes, muchas etiquetas) . En este momento, dejaremos caer las etiquetas, ya que no las necesitamos, estamos interesados en las imágenes mismas.
plotImages(sample_training_images[:5])
Ejemplo de salida (2 imágenes en lugar de las 5):

Creación de modelos
Describimos el modelo
El modelo consta de 4 bloques de convolución, después de cada uno de los cuales hay un bloque con una capa de submuestra. A continuación, tenemos una capa totalmente conectada con 512 neuronas y una relu activación relu . El modelo dará una distribución de probabilidad para dos clases, perros y gatos, utilizando softmax .
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(IMG_SHAPE, IMG_SHAPE, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ])
Compilación de modelos
Como antes, usaremos el optimizador adam . Usamos sparse_categorical_crossentropy como una función de pérdida. También queremos monitorear la precisión del modelo en cada iteración de entrenamiento, por lo que pasamos el valor de accuracy al parámetro de metrics :
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Vista modelo
Echemos un vistazo a la estructura de nuestro modelo por niveles utilizando el método de resumen :
model.summary()
Conclusión
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 2) 1026 ================================================================= Total params: 3,453,634 Trainable params: 3,453,634 Non-trainable params: 0
!
( ImageDataGenerator ) fit_generator fit :
EPOCHS = 100 history = model.fit_generator( train_data_gen, steps_per_epoch=int(np.ceil(total_train / float(BATCH_SIZE))), epochs=EPOCHS, validation_data=val_data_gen, validation_steps=int(np.ceil(total_val / float(BATCH_SIZE))) )
:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8,8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.savefig('./foo.png') plt.show()
Conclusión
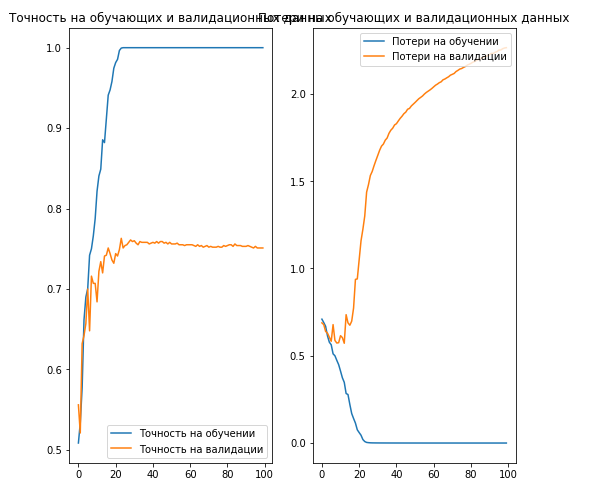
, 70% ( ).
. , .
… .
... y un llamado a la acción estándar: regístrese, ponga un plus y comparta :)
YouTube
Telegrama
VKontakte