
Hace algún tiempo, realizamos un monitoreo sin agente y alarmas para ello. Este es un análogo de CloudWatch en AWS con una API compatible. Ahora estamos trabajando en equilibradores y escalado automático. Pero aunque no proporcionamos dicho servicio, ofrecemos a nuestros clientes que lo hagan ellos mismos, utilizando nuestro monitoreo y etiquetas (API de etiquetado de recursos de AWS) como un descubrimiento de servicio simple como fuente de datos. Mostraremos cómo hacer esto en esta publicación.
Un ejemplo de una infraestructura mínima de un servicio web simple: DNS -> 2 balanceadores -> 2 backend. Esta infraestructura puede considerarse el mínimo necesario para la operación y mantenimiento tolerante a fallas. Por esta razón, no "comprimiremos" esta infraestructura aún más, dejando, por ejemplo, solo un back-end. Pero me gustaría aumentar el número de servidores de fondo y reducirlo a dos. Esta será nuestra tarea. Todos los ejemplos están disponibles en el repositorio .
Infraestructura básica
No nos detendremos en detalle en la configuración de la infraestructura anterior, solo mostraremos cómo crearla. Preferimos implementar infraestructura usando Terraform. Ayuda a crear rápidamente todo lo que necesita (VPC, subred, grupo de seguridad, máquinas virtuales) y repetir este procedimiento una y otra vez.
Guión para elevar la infraestructura básica:
main.tfvariable "ec2_url" {} variable "access_key" {} variable "secret_key" {} variable "region" {} variable "vpc_cidr_block" {} variable "instance_type" {} variable "big_instance_type" {} variable "az" {} variable "ami" {} variable "client_ip" {} variable "material" {} provider "aws" { endpoints { ec2 = "${var.ec2_url}" } skip_credentials_validation = true skip_requesting_account_id = true skip_region_validation = true access_key = "${var.access_key}" secret_key = "${var.secret_key}" region = "${var.region}" } resource "aws_vpc" "vpc" { cidr_block = "${var.vpc_cidr_block}" } resource "aws_subnet" "subnet" { availability_zone = "${var.az}" vpc_id = "${aws_vpc.vpc.id}" cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}" } resource "aws_security_group" "sg" { name = "auto-scaling" vpc_id = "${aws_vpc.vpc.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } ingress { from_port = 8080 to_port = 8080 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_key_pair" "key" { key_name = "auto-scaling-new" public_key = "${var.material}" } resource "aws_instance" "compute" { count = 5 ami = "${var.ami}" instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}" key_name = "${aws_key_pair.key.key_name}" subnet_id = "${aws_subnet.subnet.id}" availability_zone = "${var.az}" security_groups = ["${aws_security_group.sg.id}"] } resource "aws_eip" "pub_ip" { instance = "${aws_instance.compute.0.id}" vpc = true } output "awx" { value = "${aws_eip.pub_ip.public_ip}" } output "haproxy_id" { value = ["${slice(aws_instance.compute.*.id, 1, 3)}"] } output "awx_id" { value = "${aws_instance.compute.0.id}" } output "backend_id" { value = ["${slice(aws_instance.compute.*.id, 3, 5)}"] }
Parece que todas las entidades descritas en esta configuración deberían ser entendidas por el usuario promedio de las nubes modernas. Las variables específicas de nuestra nube y para una tarea específica se mueven a un archivo separado: terraform.tfvars:
terraform.tfvars ec2_url = "https://api.cloud.croc.ru" access_key = "project:user@customer" secret_key = "secret-key" region = "croc" az = "ru-msk-vol51" instance_type = "m1.2small" big_instance_type = "m1.large" vpc_cidr_block = "10.10.0.0/16" ami = "cmi-3F5B011E"
Lanzar Terraform:
aplicar terraform yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat <ssh_publick_key_path>)"
Configuración de monitoreo
Las máquinas virtuales lanzadas anteriormente son monitoreadas automáticamente por nuestra nube. Estos datos de monitoreo serán la fuente de información para futuras escalas automáticas. Confiando en ciertas métricas podemos aumentar o disminuir la potencia.
El monitoreo en nuestra nube le permite configurar alarmas de acuerdo con diferentes condiciones para diferentes métricas. Es muy conveniente. No necesitamos analizar las métricas en ningún intervalo y tomar una decisión; esto se hará mediante monitoreo en la nube. En este ejemplo, utilizaremos alarmas para las métricas de la CPU, pero en nuestro monitoreo también se pueden configurar para métricas tales como: utilización de la red (velocidad / pps), utilización del disco (velocidad / iops).
alarma de vigilancia de nubes export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm \ --alarm-name "scaling-low_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average \ --period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm\ --alarm-name "scaling-high_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average\ --period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; done
Descripción de algunos parámetros que pueden ser incomprensibles:
--profile - perfil de configuración aws-cli, descrito en ~ / .aws / config. Por lo general, se establecen diferentes claves de acceso en diferentes perfiles.
--dimensiones: el parámetro determina para qué recurso se creará la alarma, en el ejemplo anterior, para la instancia con el identificador de la variable $ instance_id.
--namespace - espacio de nombres desde el cual se seleccionará la métrica de monitoreo.
--metric-name: el nombre de la métrica de supervisión.
--statistic: el nombre del método de agregación de valores de métrica.
--period: intervalo de tiempo entre la supervisión de eventos de recopilación de valores
- períodos de evaluación: el número de intervalos necesarios para activar una alarma.
- umbral - valor umbral métrico para evaluar el estado de la alarma.
- operador de comparación - un método que se utiliza para evaluar el valor de una métrica en relación con un valor umbral.
En el ejemplo anterior, se crean dos alarmas para cada instancia de back-end. Scaling-low- <instance-id> entrará en estado de alarma cuando la CPU cargue menos del 15% durante 3 minutos. Scaling-high- <instance-id> entrará en estado de alarma cuando la CPU cargue más del 80% durante 3 minutos.
Personalización de etiqueta
Después de configurar la supervisión, nos enfrentamos a la siguiente tarea: el descubrimiento de instancias y sus nombres (descubrimiento de servicio). Necesitamos entender de alguna manera cuántas instancias de back-end hemos lanzado ahora, y también necesitamos saber sus nombres. En un mundo fuera de la nube, por ejemplo, la plantilla de cónsul y cónsul sería una buena opción para generar una configuración de equilibrador. Pero hay etiquetas en nuestra nube. Las etiquetas nos ayudarán a clasificar los recursos. Al solicitar información para una etiqueta específica (describe-tags), podemos entender cuántas instancias tenemos actualmente en el grupo y qué identificación tienen. De manera predeterminada, se usa una identificación de instancia única como nombre de host. Gracias al DNS interno que funciona dentro de la VPC, estos ID / nombres de host se resuelven en las instancias de IP internas.
Establecemos etiquetas para instancias de backend y balanceadores:
etiquetas de creación ec2 export EC2_URL="https://api.cloud.croc.ru" aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "<awx_instance_id>" \ --tags Key=env,Value=auto-scaling Key=role,Value=awx for i in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=backend ; done; for i in <haproxy_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;
Donde:
--resources - una lista de identificadores de recursos para los que se establecerán etiquetas.
--tags es una lista de pares clave-valor.
Un ejemplo de etiquetas de descripción está disponible en la documentación de CROC Cloud.
Configuración de autoescalado
Ahora que la nube está monitoreando, y sabemos cómo trabajar con etiquetas, solo podemos sondear el estado de las alarmas configuradas para su activación. Aquí necesitamos una entidad que se dedique a tareas de monitoreo y monitoreo de monitoreo periódico para crear / eliminar instancias. Aquí se pueden aplicar varias herramientas de automatización. Usaremos AWX. AWX es una versión de código abierto de la torre comercial Ansible , un producto para administrar centralmente la infraestructura de Ansible. La tarea principal es lanzar periódicamente nuestro libro de jugadas ansible.
Un ejemplo de una implementación de AWX está disponible en la página wiki en el repositorio oficial. La configuración de AWX también se describe en la documentación de Ansible Tower. Para que AWX comience a ejecutar libros de jugadas personalizados, debe configurarlo creando las siguientes entidades:
- redentials de tres tipos:
- Credenciales de AWS: para autorizar operaciones relacionadas con CROC Cloud.
- Credenciales de la máquina: claves ssh para acceder a instancias recién creadas.
- Credenciales SCM: para autorización en el sistema de control de versiones. - Project es una entidad que empujará el repositorio git del libro de jugadas.
- Scripts: script de inventario dinámico para ansible.
- Inventory es una entidad que invocará el script de inventario dinámico antes de lanzar el libro de jugadas.
- Plantilla: la configuración de una llamada específica de libro de jugadas, consiste en un conjunto de Credenciales, Inventario y libro de jugadas de Project.
- Flujo de trabajo: una secuencia de llamadas a libros de jugadas.
El proceso de autoescalado se puede dividir en dos partes:
- scale_up: crea una instancia cuando se activa al menos una alarma alta;
- scale_down - terminación de una instancia si una alarma baja ha funcionado para ella.
Como parte de la parte scale_up, necesitará:
- Interrogar al servicio de monitoreo en la nube sobre la presencia de alarmas altas en el estado "Alarma";
- Detenga scale_up antes de lo programado si todas las alarmas altas están en el estado "OK";
- crear una nueva instancia con los atributos necesarios (etiqueta, subred, grupo_seguridad, etc.);
- crear alarmas altas y bajas para una instancia en ejecución;
- configurar nuestra aplicación dentro de una nueva instancia (en nuestro caso será solo nginx con una página de prueba);
- actualice la configuración de haproxy, realice una recarga para que las solicitudes comiencen a ir a la nueva instancia.
create-instance.yaml --- - name: get alarm statuses describe_alarms: region: "croc" alarm_name_prefix: "scaling-high" alarm_state: "alarm" register: describe_alarms_query - name: stop if no alarms fired fail: msg: zero high alarms in alarm state when: describe_alarms_query.meta | length == 0 - name: create instance ec2: region: "croc" wait: yes state: present count: 1 key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}" instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}" image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}" group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}" vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}" user_data: | #!/bin/sh sudo yum install epel-release -y sudo yum install nginx -y cat <<EOF > /etc/nginx/conf.d/dummy.conf server { listen 8080; location / { return 200 '{"message": "$HOSTNAME is up"}'; } } EOF sudo systemctl restart nginx loop: "{{ hostvars[groups['tag_role_backend'][0]] }}" register: new - name: create tag entry ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc state: present resource: "{{ item.id }}" tags: role: backend loop: "{{ new.instances }}" - name: create low alarms ec2_metric_alarm: state: present region: croc name: "scaling-low_{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: "<=" threshold: 15 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}" - name: create high alarms ec2_metric_alarm: state: present region: croc name: "scaling-high_{{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: ">=" threshold: 80.0 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}"
En create-instance.yaml, lo que sucede es: crear una instancia con los parámetros correctos, etiquetar esta instancia y crear las alarmas necesarias. El script de instalación y configuración de nginx también se pasa a través de los datos del usuario. Los datos de usuario son procesados por el servicio de inicio en la nube, que permite una configuración flexible de la instancia durante el inicio sin recurrir a otras herramientas de automatización.
En update-lb.yaml, el archivo /etc/haproxy/haproxy.cfg se recrea en la instancia de haproxy y el servicio de recarga haproxy:
update-lb.yaml - name: update haproxy configs template: src: haproxy.cfg.j2 dest: /etc/haproxy/haproxy.cfg - name: add new backend host to haproxy systemd: name: haproxy state: restarted
Donde haproxy.cfg.j2 es la plantilla del archivo de configuración del servicio haproxy:
haproxy.cfg.j2 # {{ ansible_managed }} global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats timeout 30s user haproxy group haproxy daemon defaults log global mode http option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend loadbalancing bind *:80 mode http default_backend backendnodes backend backendnodes balance roundrobin option httpchk HEAD / {% for host in groups['tag_role_backend'] %} server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check {% endfor %}
Dado que la opción httpchk opción se define en la sección de back-end de haproxy, el servicio de haproxy sondeará automáticamente los estados de las instancias de back-end y solo equilibrará el tráfico entre las comprobaciones de estado anteriores.
En la parte scale_down necesitas:
- comprobar estado alarma baja;
- termina prematuramente la reproducción si no hay alarmas bajas en el estado "Alarma";
- terminar todas las instancias para las cuales la alarma baja está en la clase Alarma;
- prohibir la terminación del último par de instancias, incluso si sus alarmas están en estado de alarma;
- eliminar las instancias que eliminamos de la configuración del equilibrador de carga.
destroy-instance.yaml - name: look for alarm status describe_alarms: region: "croc" alarm_name_prefix: "scaling-low" alarm_state: "alarm" register: describe_alarms_query - name: count alarmed instances set_fact: alarmed_count: "{{ describe_alarms_query.meta | length }}" alarmed_ids: "{{ describe_alarms_query.meta }}" - name: stop if no alarms fail: msg: no alarms fired when: alarmed_count | int == 0 - name: count all described instances set_fact: all_count: "{{ groups['tag_role_backend'] | length }}" - name: fail if last two instance remaining fail: msg: cant destroy last two instances when: all_count | int == 2 - name: destroy tags for marked instances ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc resource: "{{ alarmed_ids[0].split('_')[1] }}" state: absent tags: role: backend - name: destroy instances ec2: region: croc state: absent instance_ids: "{{ alarmed_ids[0].split('_')[1] }}" - name: destroy low alarms ec2_metric_alarm: state: absent region: croc name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}" - name: destroy high alarms ec2_metric_alarm: state: absent region: croc name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"
En destroy-instance.yaml, las alarmas se eliminan, la instancia y su etiqueta se finalizan, y se verifican las condiciones que prohíben la finalización de instancias recientes.
Eliminamos explícitamente las etiquetas después de eliminar instancias debido al hecho de que después de eliminar una instancia, las etiquetas asociadas con ella se eliminan pospuestas y están disponibles por otro minuto.
AWX
Establecer tareas, plantillas
El siguiente conjunto de tareas creará las entidades necesarias en AWX:
awx-configure.yaml --- - name: Create tower organization tower_organization: name: "scaling-org" description: "scaling-org organization" state: present - name: Add tower cloud credential tower_credential: name: cloud description: croc cloud api creds organization: scaling-org kind: aws state: present username: "{{ croc_user }}" password: "{{ croc_password }}" - name: Add tower github credential tower_credential: name: ghe organization: scaling-org kind: scm state: present username: "{{ ghe_user }}" password: "{{ ghe_password }}" - name: Add tower ssh credential tower_credential: name: ssh description: ssh creds organization: scaling-org kind: ssh state: present username: "ec2-user" ssh_key_data: "{{ lookup('file', 'private.key') }}" - name: Add tower project tower_project: name: "auto-scaling" scm_type: git scm_credential: ghe scm_url: <repo-name> organization: "scaling-org" scm_branch: master state: present - name: create inventory tower_inventory: name: dynamic-inventory organization: "scaling-org" state: present - name: copy inventory script to awx copy: src: "{{ role_path }}/files/ec2.py" dest: /root/ec2.py - name: create inventory source shell: | export SCRIPT=$(tower-cli inventory_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}') tower-cli inventory_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2_URL":"api.cloud.croc.ru","AWS_REGION": "croc"}' --overwrite True - name: Create create-instance template tower_job_template: name: "create-instance" job_type: "run" inventory: "dynamic-inventory" credential: "cloud" project: "auto-scaling" playbook: "create-instance.yaml" state: "present" register: create_instance - name: Create update-lb template tower_job_template: name: "update-lb" job_type: "run" inventory: "dynamic-inventory" credential: "ssh" project: "auto-scaling" playbook: "update-lb.yaml" credential: "ssh" state: "present" register: update_lb - name: Create destroy-instance template tower_job_template: name: "destroy-instance" job_type: "run" inventory: "dynamic-inventory" project: "auto-scaling" credential: "cloud" playbook: "destroy-instance.yaml" credential: "ssh" state: "present" register: destroy_instance - name: create workflow tower_workflow_template: name: auto_scaling organization: scaling-org schema: "{{ lookup('template', 'schema.j2')}}" - name: set scheduling shell: | tower-cli schedule create -n "3min" --workflow "auto_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"
El fragmento anterior creará una plantilla para cada uno de los libros de jugadas ansibles utilizados. Cada plantilla configura el lanzamiento de un libro de jugadas con un conjunto de credenciales e inventario definidos.
Crear una tubería para llamadas a libros de jugadas permitirá la plantilla de flujo de trabajo. La configuración del flujo de trabajo para el escalado automático se presenta a continuación:
schema.j2 - failure_nodes: - id: 101 job_template: {{ destroy_instance.id }} success_nodes: - id: 102 job_template: {{ update_lb.id }} id: 103 job_template: {{ create_instance.id }} success_nodes: - id: 104 job_template: {{ update_lb.id }}
La plantilla anterior muestra el diagrama de flujo de trabajo, es decir secuencia de ejecución de plantilla. En este flujo de trabajo, cada paso siguiente (success_nodes) se realizará solo si el anterior se completa con éxito. En la imagen se muestra una representación gráfica del flujo de trabajo:
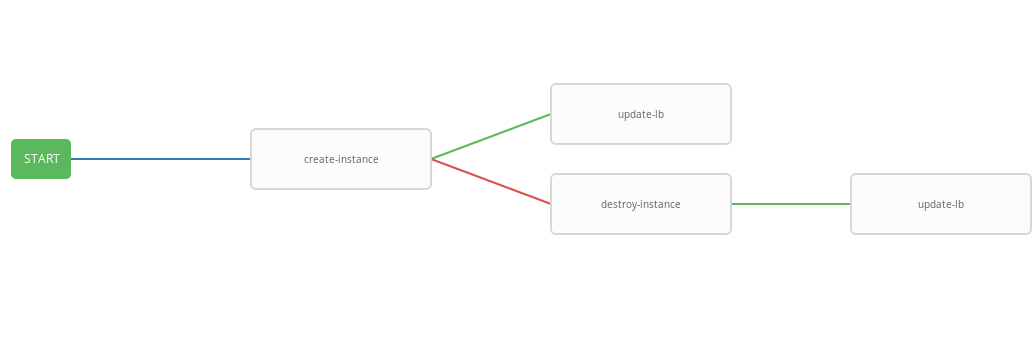
Como resultado, se creó un flujo de trabajo generalizado que ejecuta el libro de jugadas create-instace y, dependiendo del estado de ejecución, destruye los libros de jugadas de instancia y / o actualización-lb. El flujo de trabajo integrado es conveniente para ejecutarse en un horario determinado. El proceso de autoescalado comenzará cada tres minutos, iniciando y finalizando instancias dependiendo del estado de la alarma.
Prueba de trabajo
Ahora verifique el funcionamiento del sistema configurado. Primero, instale la utilidad wrk para la evaluación comparativa http.
instalación incorrecta ssh -A ec2-user@<aws_instance_ip> sudo su - cd /opt yum groupinstall 'Development Tools' yum install -y openssl-devel git git clone https://github.com/wg/wrk.git wrk cd wrk make install wrk /usr/local/bin exit
Utilizaremos el monitoreo en la nube para monitorear el uso de los recursos de la instancia durante la carga:
monitoreo function CPUUtilizationMonitoring() { local AWS_CLI_PROFILE="<aws_cli_profile>" local CLOUDWATCH_URL="https://monitoring.cloud.croc.ru" local API_URL="https://api.cloud.croc.ru" local STATS="" local ALARM_STATUS="" local IDS=$(aws --profile $AWS_CLI_PROFILE --endpoint-url $API_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]*' | tr '\n' ' ') for instance_id in $IDS; do STATS="$STATS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)"; ALARMS_STATUS="$ALARMS_STATUS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance_id | grep -i statevalue)" done echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t echo $ALARMS_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t } export -f CPUUtilizationMonitoring watch -n 60 bash -c CPUUtilizationMonitoring
El script anterior una vez cada 60 segundos toma información sobre el valor promedio de la métrica de CPUUtilization para el último minuto y sondea el estado de las alarmas para instancias de back-end.
Ahora puede ejecutar wrk y observar la utilización de los recursos de las instancias de backend bajo carga:
Wrk Run ssh -A ec2-user@<awx_instance_ip> wrk -t12 -c100 -d500s http://<haproxy_instance_id> exit
El último comando lanzará el punto de referencia durante 500 segundos, utilizando 12 hilos y abriendo 100 conexiones http.
Con el tiempo, el script de monitoreo debe mostrar que durante el punto de referencia el valor estadístico de la métrica de CPUUtilization aumenta hasta alcanzar el 300%. 180 segundos después del inicio del punto de referencia, el indicador StateValue debería cambiar al estado de alarma. Una vez cada dos minutos, comienza el flujo de trabajo de autoescalado. Por defecto, la ejecución paralela del mismo flujo de trabajo está prohibida. Es decir, cada dos minutos, se agregará una tarea para ejecutar un flujo de trabajo a la cola y se iniciará solo después de que se complete el anterior. Por lo tanto, durante el trabajo de wrk, habrá un aumento constante de recursos hasta que las alarmas altas de todas las instancias de back-end entren en estado OK. Al finalizar, el flujo de trabajo de wrk scale_down finaliza todas las instancias del backend excepto dos.
Ejemplo de salida de un script de supervisión:
seguimiento de resultados # start test i-43477460 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # start http load i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 111.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # alarm state i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 282.0 i-43477460 |i-AC5D9EE0 "StateValue": "alarm"| "StateValue": "alarm" # two new instances created i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "Average": 185.0 | "Average": 215.0 | "Average": 245.0 | i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm" # only two instances left after load has been stopped i-935BAB40 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-935BAB40 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok"
También en CROC Cloud, puede ver los gráficos utilizados en la publicación de monitoreo en la página de instancia en la pestaña correspondiente.
Ver alarmas está disponible en la página de monitoreo en la pestaña de alarmas.
Conclusión
El escalado automático es un escenario bastante popular, pero, desafortunadamente, todavía no está en nuestra nube (pero solo por ahora). Sin embargo, tenemos muchas API potentes para hacer cosas similares y muchas otras, utilizando herramientas populares, casi estándar, como Terraform, ansible, aws-cli y otras.