Amigos, buenas tardes!
Continuamos la serie de publicaciones "sin cortes" sobre proyectos relacionados con el desarrollo, a menudo con el prefijo "web". Hablemos hoy sobre las pruebas de estrés. El problema es que a menudo ni el cliente ni el gerente del proyecto entienden por qué es necesario, qué riesgos puede reducir, cómo organizarlo y cómo, y esto, creo, es difícil, interpretar sus resultados en beneficio del negocio. Vertimos café y vámonos ...
¿Por qué cargar pruebas de un proyecto web?
El hecho es que, aunque todavía se escriben autoevaluaciones en algunos proyectos web para mantener la calidad, pocas personas participan en el control del rendimiento en la etapa de desarrollo. Es muy raro ver un proyecto web con pruebas automáticas y puntos de referencia de código. Con mayor frecuencia y por razones razonables, se cumplen las siguientes heurísticas durante el desarrollo, que tienen una buena relación costo-beneficio:
- las consultas a MySQL (usaremos esta base de datos popular como ejemplo) pasan por una API bastante adecuada que usa índices (aunque no vemos cómo el programador usa exactamente los índices, cuál es su cardinalidad)
- Los resultados de la ejecución de consultas de bases de datos y piezas pesadas de código se almacenan en caché
- el desarrollador 3.14 veces verificó la construcción de la página web en el navegador y si no ralentiza el ojo, entonces todo está bien
La heurística a menudo funciona bien, pero cuanto más grande y pesado sea el proyecto, algo
puede salir mal con una probabilidad exponencialmente creciente.
Toma el almacenamiento en caché. Cuando se desarrolla, a menudo no hay tiempo para pensar con qué frecuencia se puede reconstruir el caché. Pero en vano. Si la reconstrucción de un caché, por ejemplo, un catálogo de productos, lleva mucho tiempo y el caché se restablece cuando se agrega un producto, entonces el almacenamiento en caché hará más daño que bien.
Es por eso que, por cierto, no se recomienda utilizar el caché de consultas MySQL incorporado, que sufre un problema similar: si cambia al menos un registro de tabla, el caché de la tabla se restablece por completo (imagine una tabla de 100k líneas y lo absurdo de la situación se vuelve obvio).
Una situación similar con las consultas MySQL. Si las consultas se ejecutan por índices, entonces, en general, las consultas se ejecutarán ... "más rápido". Puede creer que el tiempo de ejecución de tales consultas depende logarítmicamente de la cantidad de datos (O (log (n))). Pero en la práctica a menudo resulta que algunas consultas afectan a otras, utilizando al mismo tiempo los subsistemas generales de la base de datos (ordenando en un disco que comienza a disminuir) y no puede predecir esto de inmediato.
Además, a menudo durante la carga, se revelan características interesantes del sistema operativo, en particular, el desbordamiento del rango de puertos TCP / IP de clientes salientes durante el trabajo intensivo con memcached. O apache se obstruye con solicitudes de procesamiento de imágenes, porque durante la configuración, olvidaron configurar su procesamiento mediante el servidor proxy de almacenamiento en caché nginx.
A veces se olvidan de instalar en MySQL la ruta de las tablas temporales a un disco que asigna datos a la RAM ("/ dev / shm"), por lo que, cuando aumenta la carga, el servidor de la base de datos se establece a partir de clasificaciones intensivas.
Además, cuando se agregan datos al proyecto web, en un volumen cercano al de combate, las consultas y los algoritmos comienzan a mostrar agresivamente su "notación O": si el cartesiano es invisible para una pequeña cantidad de datos, entonces cuando aparece el volumen de combate, el servidor de la base de datos se vuelve rojo debido al voltaje.
Hay muchos más ejemplos, detengámonos en esto por ahora. Lo principal a entender es que la prueba de carga es necesaria. Debido a que es muy costoso, muy largo y poco práctico desde el punto de vista económico, es posible prever todas las opciones posibles para "frenar" un sistema web de tamaño mediano de antemano.
¿Cómo identificar los objetivos de las pruebas de estrés?
Aquí es importante comprender lo que realmente muestra a usted y al cliente el nivel de calidad del sistema web durante las pruebas de resistencia. No hay nada mejor que ejemplos concretos de objetivos de pruebas de estrés, buenos y malos:
- Hizo 1 millón de visitas. Tiempo promedio de construcción de la página web = 1 seg. ¿Qué muestra esto? Nada ¿Cuánto duraron las pruebas de carga? El tiempo de ejecución de una sola solicitud puede ser de 1 ms o 600 segundos, y no está claro qué proporciones son mayores. Y cuántos errores hubo (la respuesta nginx en el estilo de "Error 50x") tampoco está claro :-)
- Hizo 1 millón de visitas. Tiempo medio de construcción de la página web = 1 segundo, el número de errores HTTP es 0.5% ¿Qué muestra esto? Hasta ahora, un poco útil, pero mejor. La cantidad de errores inadecuados que el cliente puede detectar, ya sabemos lo que es excelente y puede comenzar a prepararse e ir a la farmacia. La mediana es una métrica más resistente a los "valores atípicos" que el promedio (estimación más "robusta"), por lo tanto, es indudablemente mejor que el promedio aritmético. Pero hagamos que las métricas sean aún más útiles.
- Se hicieron 1 millón de visitas por día. El 25% de los golpes se hicieron en menos de 10 ms, el 50% de los golpes se hicieron en menos de 1 segundo (esta es la mediana o el percentil 50), el 75% de los golpes se hicieron en menos de 1,5 segundos, el 95% de los golpes se hicieron en menos de 1 segundo 5 segundos y el número de errores HTTP es 0.5% ¡ Eso es! Vemos la proporción de errores inadecuados que el cliente puede detectar, pero también vemos la proporción de solicitudes que se ejecutan por encima de un cierto umbral.
Como puede ver, la elección de métricas adecuadas para evaluar la velocidad de un proyecto web durante la prueba de carga es muy, muy importante. Solo hay un principio: las métricas deben ser absolutamente claras tanto para el cliente como para usted, y mostrar una calidad clara y bien. De hecho, la métrica más obvia y correcta es la distribución de la velocidad de procesamiento de golpes a lo largo del tiempo. Si logra hacer esto en sus pruebas de estrés, será excelente. Además, puede comparar 2 pruebas de estrés por la naturaleza de la distribución de los golpes de tiempo y ver cómo mejoró y dónde. ¡La visualización es poder!
Nada está claro: percentiles, medianas, cuantiles, borradores, distribución ...
¡Todo es simple! Ahora dibujaré y mostraré en un hermoso entorno para el análisis de datos: Jupyter notebook / Python.
Digamos que se hicieron 10 visitas al sitio web con tal tiempo en milisegundos:
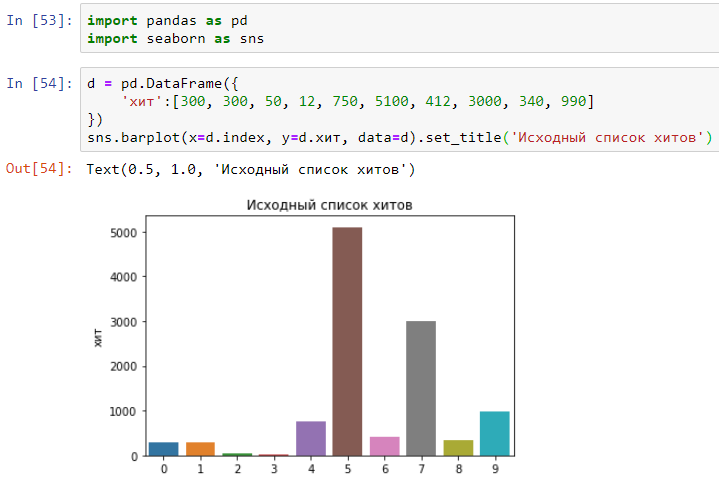
Ahora ordena el tiempo que lleva completar los golpes en orden ascendente:

Estamos a un paso de comprender la mediana, los percentiles 25 y 75. Todo es simple: dividimos el gráfico por la mitad y en el medio habrá una "mediana" (número 1 en el gráfico). El primer trimestre del gráfico corresponderá al percentil 25 (número 2 en el gráfico) y el tercer trimestre corresponderá al percentil 75 (número 3 en el gráfico). En consecuencia, se obtienen otros percentiles (o, como también se les llama, cuantiles): 90, 95, 99, etc.
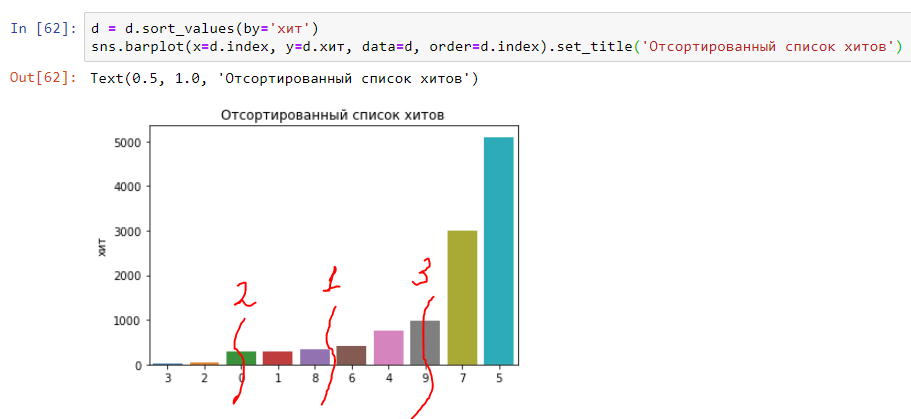
Y se verá como la distribución (histograma) sobre el tiempo de ejecución de los golpes anteriores. Como puede ver, todo es muy claro y simple:
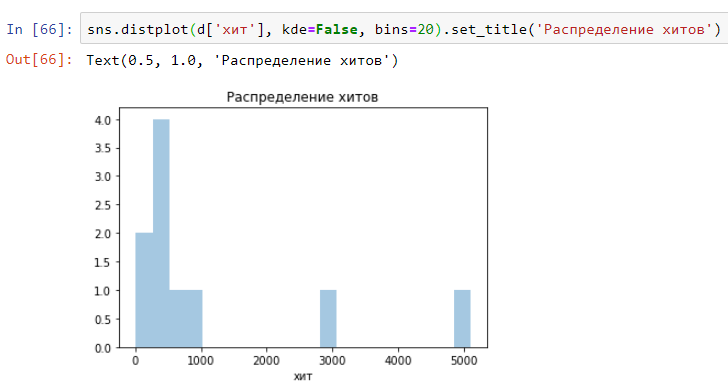
Y así es como puede construir rápidamente una distribución (histograma) basada en el registro de solicitud de prueba de carga. Modifique a su formato de registro:
Y obtienes algo como esto:

Espero que ahora todo esté claro y en su lugar. Si no, pregunte en los comentarios.
Tiempo de prueba de estrés
La gente a menudo pregunta: ¿cuánto debería durar la prueba de carga de un proyecto web? Hay una heurística simple: en el sistema operativo, las tareas programadas a menudo se realizan una vez al día: copias de seguridad, rotación de registros, etc., por lo tanto, el tiempo para llevar a cabo las pruebas de carga no debe ser inferior a, correctamente, un día. Si el proyecto web está basado en Bitrix, entonces la plataforma también tiene muchas tareas programadas y es recomendable cargar el sistema web durante al menos un día.
Balanceo de carga
Si ya tiene un sitio web operado, puede, sí, tomar los registros de visitas desde allí y cargar el nuevo sistema web usándolos. Pero a menudo resuelven el problema de cargar solo el sistema web desarrollado. Para planificar el equilibrio de carga, el modelo de dividir las posibles cadenas de visitas a un sitio en acciones suele ser una buena opción. Por ejemplo:
- Inicio - Noticias - Noticias detalladas = 50%
- Inicio - Descripción general del catálogo - Catálogo detallado = 30%
- Catálogo detallado - Descripción general del catálogo - Catálogo detallado = 15%
- Resultados de búsqueda - Catálogo detallado = 5%
En el software para crear una carga (a menudo usamos Jmeter), se crean tantos flujos de carga para cada cadena que, teniendo en cuenta el intervalo entre los golpes en la cadena, el número total de golpes de cada cadena por unidad de tiempo se correlaciona como: 50%, 30%, 15%, 5% .
El cálculo de intervalos y flujos de carga es fácil de hacer en Excel o en una hoja con un lápiz.
Estructura de la cadena de carga
Es importante tener en cuenta las características del ciclo de vida del usuario del sistema web. A menudo, los usuarios inician sesión y luego van al sitio web. Para hacer esto, debe colocar las acciones que conducen a la autorización al comienzo de la cadena de carga:
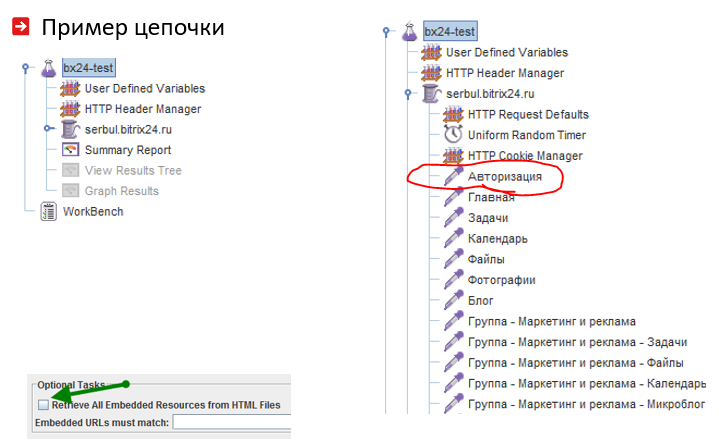
Está claro para el caballo que es imposible extraer solo una página detallada del catálogo durante las pruebas de estrés, por lo tanto, es útil leer y rotar su lista del archivo CSV:

Entre golpes, por supuesto, debe hacer pausas aleatorias, por lo que nos acercamos a la carga creada por usuarios reales. No se olvide de guardar y devolver valores de cookies al servidor:

Las variables globales de las cadenas de carga, incluido su número de subprocesos, son fáciles de configurar. Ciertas variables globales se pueden usar en diferentes lugares en las cadenas de carga:


¿Cómo hacer que las pruebas de estrés terminen de manera segura?
En la práctica, casi siempre, las pruebas de carga en los primeros minutos u horas bloquean el sistema web, todo comienza a humear, luego se quema, el sitio no se abre, MySQL cae en un intercambio y no se permite conectarse, LA en los servidores se acerca a 100, los desarrolladores comienzan a correr con las palabras "esto no debería haber sucedido", y los administradores de sistemas con una sonrisa generalmente responden "¡hay justicia en la vida!" y comenzar a beber cerveza en la sala de servidores.
Pero para comprender por qué todo se ha caído y qué reparar, para mostrar al cliente los resultados de una prueba de carga "exitosa" en un día, primero debe permitir el registro de las principales métricas de la vida útil del sistema operativo; esto es fácil de hacer en los productos de clase munun / cacti gratuitos.
Enumeraré lo que sucede durante el colapso de un sistema web con mayor frecuencia y cómo se puede solucionar.
En primer lugar, el servidor web apache o php-fpm está "obstruido" con solicitudes:

La mayoría de las veces esto sucede debido al colapso de MySQL: el número de flujos de consultas pendientes aumenta:

¿Cuál es la razón de esto? A menudo, desde arriba se olvidan de restringir la cantidad de flujos de consultas o apache a MySQL, lo que hace que las aplicaciones se salgan de la RAM en un intercambio lento con convulsiones:
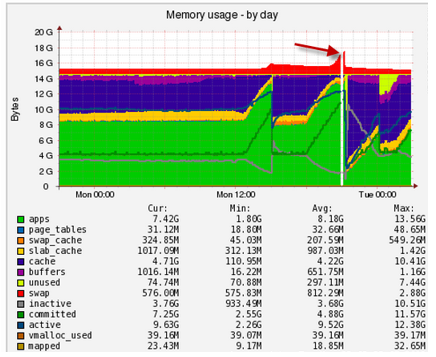
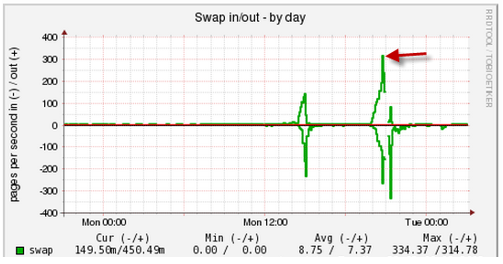
Aquí puede ver la actividad repentina al trabajar con un intercambio, debe comprender quién cayó en el intercambio y dónde:
Sin embargo, a veces el problema está del lado del subsistema de disco lento. En este caso, LA aumenta bruscamente y el porcentaje de utilización del disco se acerca a 100 (gráfico inferior derecho):


Obviamente, revelé solo una parte de lo más interesante que puede comenzar con un proyecto web durante las pruebas de estrés. Pero lo principal es establecer la dirección correcta y construir el proceso correcto. Pregunte en los comentarios qué apareció durante la carga, intentaré ayudarlo.
Interpretación de los resultados de la prueba de esfuerzo.
Por lo general, después de 5-10 reinicios y ajustes, las pruebas de carga comienzan su vuelo y se completan con éxito. Como resultado, debe tener un conjunto de aproximadamente estos registros para su posterior análisis:
- registro de solicitudes a nginx con el tiempo de la solicitud del cliente (en este caso será cargar software), el tiempo de proxy de nginx a apache / php-fpm
- nginx error log
- registro de solicitudes apache / php-fpm con tiempo de procesamiento de solicitudes y estado de respuesta HTTP
- registro de errores de apache / php-fpm
- Registro lento de MySQL
- Registro de errores de MySQL
Además, debería haber gráficos analíticos durante el último día sobre el uso de CPU, discos, MySQL, RAM, trabajadores de apache, etc. (ver ejemplos anteriores de gráficos munin).
Con estos artefactos, puede, utilizando un script awk simple al comienzo de la publicación, construir distribuciones (histogramas) sobre estos registros y calcular el número y los tipos de errores HTTP. De hecho, puede generar un informe sobre el éxito de las pruebas de resistencia sobre este contenido que es muy amplio y útil para los negocios y la toma de decisiones:
Durante el día hizo 1 millón de visitas. El 25% de los golpes se hicieron en menos de 50 ms, el 50% de los golpes se hicieron en menos de 0,5 segundos (mediana), el 75% de los golpes se hicieron en menos de 1 segundo, el 95% de los golpes se hicieron en menos de 5 segundos, la cantidad de errores HTTP - 0.01%. Los datos de prueba: catálogo, usuarios, noticias, artículos se inundaron en un volumen cercano al esperado. Un desarrollador se pegó un tiro.
Cadenas de carga:
Inicio - Noticias - Noticias detalladas = 50%
Inicio - Descripción general del catálogo - Catálogo detallado = 30%
Catálogo detallado - Descripción general del catálogo - Catálogo detallado = 15%
Resultados de búsqueda - Catálogo detallado = 5%
Tablas de uso de recursos del servidor:
...
Este es un informe bueno y comprensible sobre las pruebas de carga del sistema web. Para los amantes del dolor agudo, aún puede recomendar durante las pruebas de carga incluir cada minuto la importación-exportación de datos a un sitio web desde sistemas de clase SAP, 1C, etc. y conexiones síncronas a través de sockets TCP / IP con servicios de intercambio externo, por ejemplo, criptomonedas :-)
Pero, para ser honesto, si la importación-exportación se realiza de manera cuidadosa y honesta, entonces las pruebas de carga y en tales condiciones mostrarán cifras aceptables para los negocios.
¿De dónde vienen las pruebas de estrés?
Por cierto, sí, no destacamos este momento. Por razones triviales, la falta de equilibrio entre los trabajadores nginx - apache - mysql generalmente aparece. Es decir los trabajadores no están limitados de lo anterior, como resultado, 500 trabajadores (cada uno a veces 100 MB cada uno) pueden subir inmediatamente en apache y 500 hilos con solicitudes llegarán a MySQL de inmediato, lo que provocará un aumento en los errores HTTP 50x y un posible colapso.
Aquí se recomienda limitar la cantidad de trabajadores de apache / php-fpm a la cantidad que cabe en la RAM y, de manera similar, limitar la cantidad de hilos en MySQL para proteger contra el desbordamiento de la RAM disponible. La idea es simple: deje que los clientes esperen frente a nginx, puede reducir la velocidad un poco en los sockets TCP / IP asincrónicos y sin bloqueo, que se "rompen" inmediatamente en apache / MySQL.
De las razones más molestas, puede haber PHP predeterminado. En este caso, debe habilitar la colección coredump y usar gdb para ver por qué sucede esto. En la mayoría de los casos, el problema puede evitarse mediante la actualización / configuración de PHP.
Lo que queda detrás de escena
Hay rumores persistentes de que la interfaz moderna para la web ha vivido su vida de manera tan activa que la prueba de carga clásica del backend presentada en esta publicación ya no cubre todos los riesgos posibles de congelar la construcción de una página web en las tripas de Angular / React / Vue.js, por lo tanto
no utilice un extremo frontal pesado y opaco, mal probado, puede, si es necesario, adaptar las cadenas de carga a esta situación.
En cualquier caso, si los resultados de las pruebas de resistencia en el backend mostraron buenos números y el sitio web continúa desacelerándose en el navegador, ya está claro a quién "golpear la descarada cara roja" :-)
En serio, en las próximas publicaciones esperamos cubrir este importante tema.
Resumen y conclusiones
Total: no hay nada complicado en organizar y realizar pruebas de carga de un sistema web útil para el desarrollo y los negocios.
Las pruebas de carga, debidamente organizadas, siempre deben llevarse a cabo; de lo contrario, existe el riesgo de encontrarse con problemas importantes durante la operación de combate, que no se pueden eliminar en unos pocos días.
Para realizar pruebas de estrés, es importante atraer no solo desarrolladores, sino también expertos en sistemas operativos y administradores de sistemas con experiencia en hardware, y luego los problemas de "caer en un intercambio" o "desbordar el rango local de direcciones IP" no causarán sangrado de los ojos y desmayos.
¡Buena suerte amigos y hagan preguntas en los comentarios!