Percibimos el procesador central como el "cerebro" de una computadora, pero ¿qué significa realmente? ¿Qué sucede exactamente dentro de los miles de millones de transistores que hacen que una computadora funcione? En nuestra nueva miniserie de cuatro artículos, consideraremos el proceso de creación de la arquitectura de los equipos informáticos y hablaremos sobre los principios de su funcionamiento.
En esta serie hablaremos sobre arquitectura de computadoras, diseño de placas de procesador, VLSI (integración a gran escala), fabricación de chips y tendencias futuras en el campo de la tecnología informática. Si estaba interesado en comprender los detalles de los procesadores, entonces es mejor comenzar el estudio con esta serie de artículos.
Comenzaremos con una explicación de muy alto nivel de lo que hace el procesador y cómo los bloques de construcción se conectan en una estructura funcional. En particular, consideraremos los núcleos de procesador, la jerarquía de memoria, la predicción de ramificación y más. Primero, necesitamos dar una definición simple de lo que hace la CPU. La explicación más simple: el procesador sigue un conjunto de instrucciones para realizar una determinada operación en muchos datos entrantes. Por ejemplo, puede leer un valor de la memoria, luego agregarlo a otro valor y finalmente guardar el resultado en la memoria en una dirección diferente. Puede ser algo más complicado, por ejemplo, la división de dos números, si el resultado del cálculo anterior es mayor que cero.
Los programas, como un sistema operativo o un juego, son secuencias de instrucciones que la CPU debe ejecutar. Estas instrucciones se cargan desde la memoria y se ejecutan en un procesador simple uno tras otro hasta que el programa finaliza. Los desarrolladores de software escriben programas en lenguajes de alto nivel, como C ++ o Python, pero el procesador no puede entenderlos. Él entiende solo unos y ceros, por lo que debemos representar de alguna manera el código en este formato.
Los programas se compilan en un conjunto de instrucciones de bajo nivel llamado
lenguaje ensamblador , que forma parte de la arquitectura del conjunto de instrucciones (ISA). Este es un conjunto de instrucciones que la CPU debe comprender y ejecutar. Algunos de los ISA más comunes son x86, MIPS, ARM, RISC-V y PowerPC. De la misma manera que la sintaxis para escribir una función en C ++ difiere de la función que realiza la misma acción en Python, cada ISA tiene su propia sintaxis diferente.
Estas NIA se pueden dividir en dos categorías principales: longitud fija y variable. ISA RISC-V utiliza instrucciones de longitud fija, lo que significa que un número predeterminado de bits en cada instrucción determina de qué tipo es la instrucción. En x86, todo es diferente, usa instrucciones de longitud variable. En x86, las instrucciones se pueden codificar de diferentes maneras con diferentes números de bits para diferentes partes. Debido a esta complejidad, el decodificador de instrucciones en el procesador x86 suele ser la parte más compleja de todo el dispositivo.
Las instrucciones de longitud fija proporcionan una decodificación simple debido a una estructura constante, pero limitan el número total de instrucciones que puede admitir ISA. Si bien las versiones populares de la arquitectura RISC-V tienen aproximadamente 100 instrucciones y todas ellas son de código abierto, la arquitectura x86 es propietaria y nadie sabe cuántas instrucciones contiene. En general, se cree que hay varios miles de instrucciones x86, pero nadie publica el número exacto. A pesar de las diferencias entre los ISA, de hecho, todos tienen la misma funcionalidad básica.
Un ejemplo de algunas instrucciones RISC-V. El código de operación a la derecha tiene 7 bits de longitud y determina el tipo de instrucción. Además, cada instrucción contiene bits que definen los registros utilizados y las funciones realizadas. Entonces, las instrucciones del ensamblador se dividen en código binario para que el procesador lo entienda.Ahora estamos listos para encender la computadora y comenzar a ejecutar programas. La ejecución de la instrucción tiene varias partes básicas, que se dividen en muchas etapas del procesador.
La primera etapa es la transferencia de instrucciones desde la memoria al procesador para comenzar la ejecución. En el segundo paso, la instrucción se decodifica para que la CPU pueda entender qué tipo de instrucción es. Existen muchos tipos, incluidas las instrucciones aritméticas, las instrucciones de bifurcación y las instrucciones de memoria. Después de que la CPU descubre qué tipo de instrucción está ejecutando, los operandos para la instrucción se toman de la memoria o de los registros internos de la CPU. Si desea agregar el número A y el número B, no puede agregar hasta que sepa los valores de A y B. La mayoría de los procesadores modernos son de 64 bits, es decir, el tamaño de cada valor de datos es de 64 bits.
64 bits es el ancho del registro del procesador, el canal de datos y / o la dirección de memoria. Para los usuarios comunes, esto significa cuánta información puede procesar una computadora a la vez, y esto se entiende mejor en comparación con un pariente de arquitectura más joven: un procesador de 32 bits. La arquitectura de 64 bits puede procesar el doble de bits de información a la vez (64 bits frente a 32).Habiendo recibido los operandos para la instrucción, el procesador los transfiere a la etapa de ejecución, donde la operación se realiza en los datos entrantes. Esto puede sumar números, realizar manipulaciones lógicas con números o simplemente pasar números sin cambiarlos. Después de calcular el resultado, se puede requerir acceso a la memoria para almacenarlo, o el procesador simplemente puede almacenar el valor en uno de sus registros internos. Después de guardar el resultado, la CPU actualiza el estado de los diversos elementos y pasa a la siguiente instrucción.
Esta explicación, por supuesto, se simplifica enormemente, y la mayoría de los procesadores modernos dividen estas varias etapas en 20 o incluso más etapas pequeñas para aumentar la eficiencia. Esto significa que aunque el procesador comienza y termina con varias instrucciones en cada ciclo, puede llevar 20 o más ciclos ejecutar una instrucción de principio a fin. Tal modelo generalmente se llama tubería ("tubería", generalmente traducida al ruso como "transportador"), porque lleva tiempo llenar la tubería con líquido y completarla, pero después de llenar el flujo (salida de datos) será constante.
Un ejemplo de un transportador de 4 etapas. Los rectángulos multicolores indican instrucciones que son independientes entre sí.El ciclo completo por el que pasa la instrucción es un proceso coordinado con mucho cuidado, pero no todas las instrucciones pueden completarse al mismo tiempo. Por ejemplo, la adición es muy rápida, y dividir o cargar desde la memoria puede tomar miles de ciclos. En lugar de detener todo el procesador hasta completar una instrucción lenta, la mayoría de los procesadores modernos los ejecutan con un cambio de orden. Es decir, determinan cuál de las instrucciones es más ventajosa ejecutar en este momento y almacenan otras instrucciones que aún no están listas. Si la instrucción actual aún no está lista, entonces el procesador puede avanzar en el código para ver si hay algo más listo.
Además de ejecutar con una secuencia de cambios, los procesadores modernos usan una tecnología llamada
arquitectura superescalar . Esto significa que en cualquier momento, el procesador ejecuta simultáneamente muchas instrucciones en cada etapa de la tubería. También puede esperar que cientos más comiencen su ejecución, y para poder ejecutar varias instrucciones simultáneamente dentro de los procesadores, hay varias copias de cada etapa de la tubería. Si el procesador ve que dos instrucciones están listas para la ejecución, y no hay dependencia entre ellas, entonces no espera hasta que se completen por separado, sino que las ejecuta simultáneamente. Una implementación popular de esta arquitectura se llama Multithreading simultáneo (SMT) y también se conoce como Hyper-Threading. Los procesadores Intel y AMD ahora admiten SMT de doble cara, mientras que IBM ha desarrollado chips que admiten hasta ocho SMT.
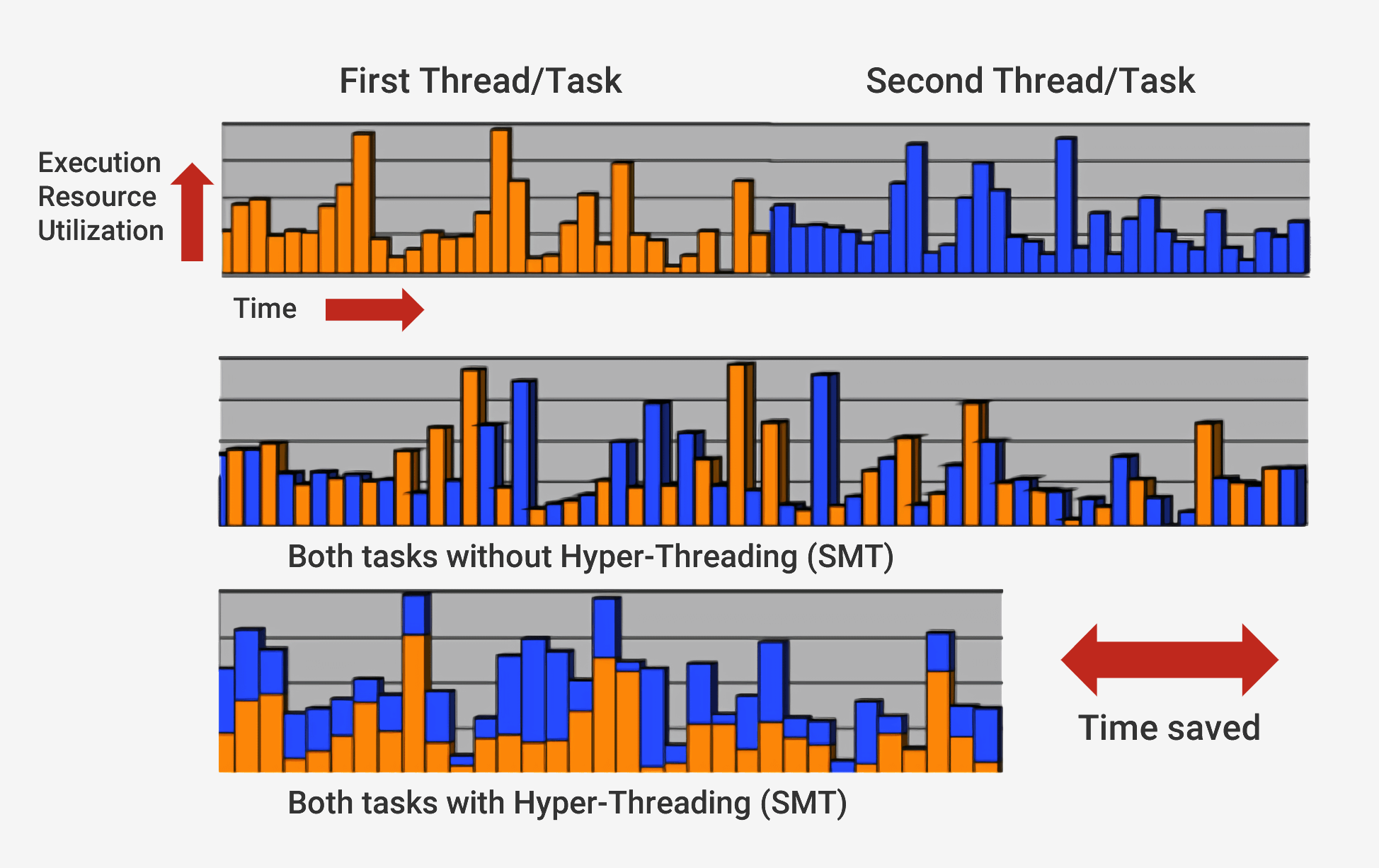
Para completar esta ejecución cuidadosamente coordinada, el procesador, además del núcleo base, tiene muchos elementos adicionales. El procesador tiene cientos de módulos separados, cada uno de los cuales tiene una función específica, pero solo consideraremos los conceptos básicos. Los más importantes y rentables son los cachés y el predictor de transiciones. Hay otras estructuras adicionales que no consideraremos: reordenar los búferes, registrar tablas de cambio de nombre y estaciones de respaldo.
La necesidad de cachés a veces puede ser confusa, ya que almacenan datos, como RAM o SSD. Pero los cachés difieren en latencia y velocidad de acceso. Aunque la memoria RAM es extremadamente rápida, es mucho más lenta de lo que necesita la CPU. Se pueden requerir cientos de ciclos para responder con la transferencia de datos de RAM, y el procesador no tendrá nada que hacer en este momento. Y si no hay datos en la RAM, puede tomar decenas de miles de ciclos para acceder a ellos desde el SSD. Sin cachés, los procesadores se detendrían constantemente.
Los procesadores suelen tener tres niveles de caché que conforman la denominada
jerarquía de memoria . El caché L1 es el más pequeño y más rápido, L2 está en el medio y L3 es el más grande y más lento de todos los cachés. Por encima de los cachés en la jerarquía hay pequeños registros que almacenan el único valor de datos durante los cálculos. En orden de magnitud, estos registros son los dispositivos de almacenamiento más rápidos del sistema. Cuando el compilador convierte un programa de alto nivel en lenguaje ensamblador, determina la mejor manera de usar estos registros.
Cuando la CPU solicita datos de la memoria, primero verifica si estos datos ya están almacenados en el caché L1. Si es así, puede acceder a ellos en solo un par de ciclos. Si no están allí, el procesador verifica L2 y luego el caché L3. Los cachés se implementan de tal manera que, en general, son transparentes para el núcleo. El núcleo simplemente solicita datos en la dirección de memoria especificada, y el nivel en la jerarquía en el que existe los responde. Al pasar a niveles posteriores en la jerarquía de memoria, el tamaño y los retrasos generalmente aumentan en órdenes de magnitud. Al final, si la CPU no encuentra datos en ninguna de las memorias caché, accede a la memoria principal (RAM).
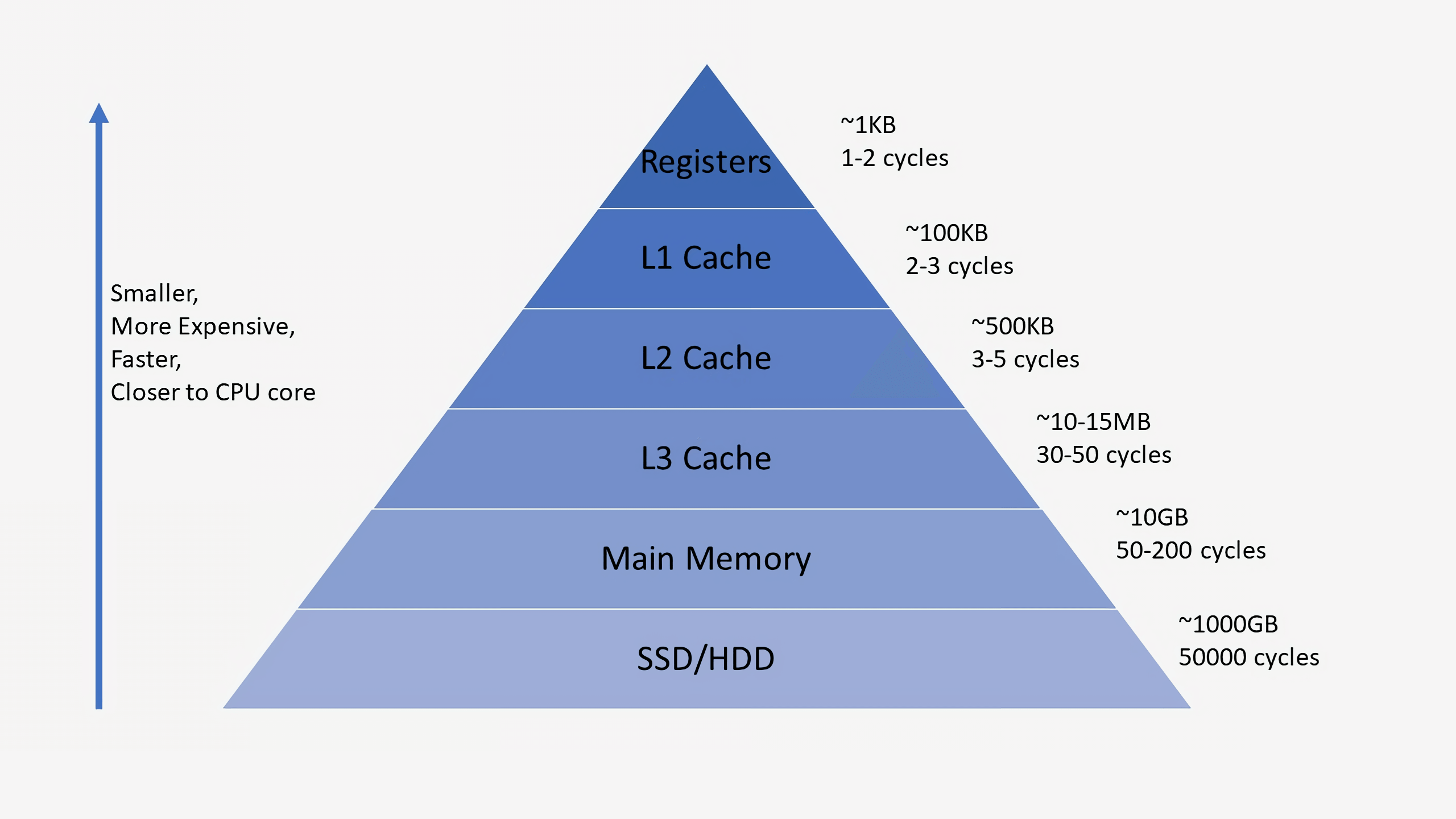
En un procesador normal, cada núcleo tiene dos cachés L1: uno para datos y otro para instrucciones. Los cachés L1 generalmente tienen una capacidad total de aproximadamente 100 kilobytes y el tamaño varía mucho según el chip y la generación del procesador. Además, generalmente cada núcleo tiene su propio caché L2, aunque en algunas arquitecturas puede ser común a dos núcleos. Los cachés L2 son típicamente de varios cientos de kilobytes de tamaño. Finalmente, hay un único caché L3 común a todos los núcleos, con un tamaño del orden de decenas de megabytes.
Cuando el procesador ejecuta el código, se almacenan en caché las instrucciones y los valores de datos más utilizados. Esto acelera significativamente la ejecución, ya que el procesador no necesita ir constantemente a la memoria principal para obtener los datos necesarios. En la segunda y tercera parte de la serie, hablaremos más sobre cómo se implementan estos sistemas de memoria.
Además de los cachés, uno de los bloques de construcción más importantes de un procesador moderno es un
predictor de transición preciso. Las instrucciones de transición (ramificación) son similares a las construcciones if para el procesador. Un conjunto de instrucciones se ejecuta si la condición es verdadera y la otra si es falsa. Por ejemplo, necesitamos comparar dos números, y si son iguales, realice una función, y si no son iguales, realice otra. Estas instrucciones de bifurcación son extremadamente comunes y pueden representar aproximadamente el 20% de todas las instrucciones en un programa.
A primera vista, parece que estas instrucciones de ramificación no deberían causar problemas, pero su ejecución adecuada puede ser muy difícil para el procesador. En cualquier momento, el procesador puede estar ejecutando simultáneamente diez o veinte instrucciones, por lo que es muy importante saber
qué instrucciones ejecutar. Puede tomar 5 ciclos para determinar que la instrucción actual es una transición, y otros 10 ciclos para determinar si la condición es verdadera. En este momento, el procesador ya puede comenzar a ejecutar docenas de instrucciones adicionales, sin siquiera saber si estas instrucciones son realmente adecuadas para la ejecución.
Para solucionar este problema, todos los procesadores modernos de alto rendimiento utilizan una técnica llamada especulación. Esto significa que el procesador realiza un seguimiento de las instrucciones de la rama y se pregunta si la rama condicional se ejecutará o no. Si la predicción es correcta, el procesador ya ha comenzado a ejecutar las siguientes instrucciones, y esto proporciona un aumento en el rendimiento. Si la predicción es incorrecta, el procesador detiene la ejecución, elimina todas las instrucciones incorrectas que comenzó a ejecutar y comienza de nuevo desde el punto correcto.
Tales predictores de rama son algunos de los tipos más simples de aprendizaje automático porque el predictor estudia el comportamiento de las ramas durante la ejecución. Si predice incorrectamente con demasiada frecuencia, comienza a aprender el comportamiento correcto. Décadas de investigación en técnicas de predicción de transición han dado como resultado una precisión de predicción de más del 90% en los procesadores modernos.
Aunque la anticipación proporciona un gran aumento en el rendimiento, ya que el procesador puede ejecutar instrucciones que ya están listas, en lugar de esperar en la cola para que se complete la ejecución, también crea vulnerabilidades de seguridad. El famoso ataque Spectre explota errores en la predicción y anticipación de las transiciones. El atacante usa un código especialmente seleccionado para forzar al procesador a ejecutar el código de manera proactiva, lo que resulta en una pérdida de valores de la memoria. Para evitar la fuga de datos, fue necesario rehacer el diseño de ciertos aspectos de anticipación, lo que condujo a una ligera caída en el rendimiento.
En las últimas décadas, la arquitectura utilizada en los procesadores modernos ha recorrido un largo camino. La innovación y el desarrollo de una estructura bien pensada han llevado a una mayor productividad y un uso más óptimo del hardware. Sin embargo, los desarrolladores de los procesadores centrales guardan cuidadosamente los secretos de sus tecnologías, por lo que no podemos descubrir exactamente qué sucede dentro de ellos. Sin embargo, los principios fundamentales de los procesadores están estandarizados para todas las arquitecturas y modelos. Intel puede agregar sus ingredientes secretos para aumentar la proporción de aciertos de caché, y AMD puede agregar un predictor de transición mejorado, pero los procesadores de ambas compañías realizan la misma tarea.
En este primer vistazo y revisión, cubrimos los conceptos básicos de cómo funcionan los procesadores. En la siguiente parte, le diremos cómo desarrollar los componentes que componen los procesadores, hablaremos sobre elementos lógicos, frecuencias de reloj, administración de energía, circuitos y más.
Lectura recomendada