Hola Mi nombre es Vitaliy Kostousov, trabajo en el equipo de Global Tech Heroes y hoy les hablaré sobre el soporte, uno de los componentes más importantes de cualquier servicio. Puedes hacer una gran aplicación con imágenes geniales y, a veces, bromear adecuadamente con los bots de chat. Puede volcar abiertamente, al principio ofreciendo a los clientes un servicio de bajo costo. Puede contratar un maravilloso SMM-box para el que no se avergonzará y que no tendrá que cambiar con tanta frecuencia como un contador en los años 90.
Pero todo esto puede tropezar bien en ausencia de un soporte sensato para su servicio. Y soporte en un sentido global: desde la resolución de problemas del usuario hasta la garantía de la funcionalidad del software y el hardware. Bueno, en serio, ¿cuánto tiempo la gente usará la aplicación, que ha sido estúpida durante un par de semanas, y los desarrolladores aún no han respondido normalmente a los problemas, el servicio de soporte no está suscrito con respuestas robóticas, y en el centro de llamadas puede escuchar música clásica gratis durante horas?

Como tenemos todo arreglado, lo que usamos en nuestro trabajo para detectar problemas y resolverlos, cuántos de nosotros y todo lo demás está por debajo.
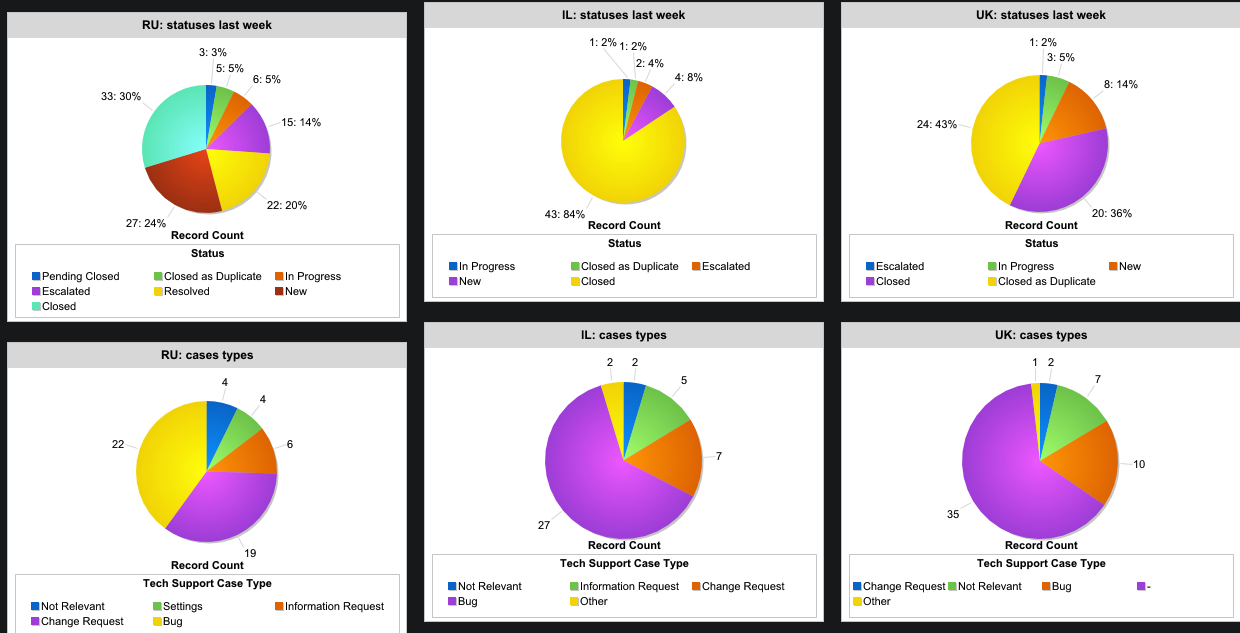
Ahora trabajamos en 3 países: Rusia, el Reino Unido e Israel, y tenemos cientos de miles de usuarios activos, clientes corporativos solo más de 20,000. Hay suficientes solicitudes diarias para nuestras aplicaciones. Y hay controladores y solicitudes de ellos. Y también sistemas internos y monitoreo. Todo esto debería funcionar, y funcionar bien. Para hacer esto, tenemos un equipo de soporte técnico global llamado dentro de “Tech Heroes”: equipos de I + D, operadores de escalamiento e ingenieros, así como el Gerente de incidentes globales. Y esto es lo que enfrentan en su trabajo.
Equipo y usuarios
Haga inmediatamente una reserva de que los usuarios finales de nuestro equipo se refieren no solo a los clientes y conductores que tienen prioridad (tanto privados como corporativos), sino también a los servicios de marketing, soporte y nuestros departamentos internos. Por supuesto, escriben para apoyar el uso de la aplicación o en las redes sociales. Si el problema es de naturaleza técnica, la tarea dentro de SalesForce nos corresponde de inmediato. Pueden escribir no solo sobre la aplicación y la calidad de su trabajo en su conjunto o sobre algunas funciones en particular, sino también sobre el desempeño de los servicios internos de la compañía. Hay más de 1000 empleados de Gett que hacen preguntas sobre software de trabajo y organización de procesos.
Nuestro equipo consta de 8 personas distribuidas en tres países: Israel, Gran Bretaña y Rusia. Un especialista de Rusia trabaja de forma remota, sus responsabilidades incluyen trabajar con procesos operativos: monitorear y realizar cambios en nuestros servicios principales. Los siete restantes están involucrados en problemas operativos, y muchos otros: pruebas, errores, especificaciones, resuelven rápidamente las llamadas que provienen de especialistas y gerentes operativos, y también monitorean todas nuestras bases de datos, servicios y microservicios. Este equipo procesa todos los boletos, desde cualquier país al que lleguen. En su mayor parte, debe trabajar con problemas locales, pero sucede que hay algún error grave en el trabajo de los servicios globales, luego el trabajo pasa al modo Global.
También debe tener en cuenta que tenemos muchos clientes de b2b en todo el mundo: el sistema tiene configuraciones muy flexibles y la posibilidad de integración comercial con los servicios de la compañía. Es decir, hay muchas más clases de automóviles que los usuarios privados del servicio. Es importante comprender que todo esto afecta tanto la operación de los servicios como el número de operaciones transaccionales. El segmento B2B puede usar una cuenta personal en el sitio web de la compañía.
Software
Existen varios sistemas para trabajar con tickets en el mercado que ya han demostrado su utilidad: LiveAgent, ZenDesk, ZohoDesk y otros. Puede elegir según su conveniencia, puede hacerlo por costumbre, puede hacerlo, comenzando por el tipo de software con el que trabajan sus colegas, para no bloquear un montón de capas y muletas (que también deben ser compatibles y terminados). Por lo tanto, trabajamos para SalesForce, ya que es utilizado por las principales áreas operativas de la empresa (ventas y soporte). Esto le permite rastrear el estado de cada caso desde el lado de su creador. Hay una priorización automática de casos basada en los temas de las apelaciones. SalesForce también está integrado en Jira, y si se crea una tarea o se introduce un error en el desarrollo, su estado también se muestra en el caso. Así es como logramos una comunicación transparente entre Soporte y Desarrollo.
 SalesForce, cliqueable
SalesForce, cliqueableUn sistema de aplicación dedicado le permite rastrear el SLA para cada boleto que nos llega.
Entradas y solicitudes
Específicamente, nuestro equipo está involucrado en el trabajo de la aplicación en sí (tanto para conductores como para pasajeros), microservicios con los que trabajan los especialistas operativos, así como pruebas y monitoreo. Además, siempre hay solicitudes de nuevos informes y monitoreo, que pueden ser útiles para colegas de otros departamentos. Al mismo tiempo, algunos monitoreos son estrictamente para nuestro equipo, si se relacionan exclusivamente con los parámetros técnicos de los servicios y las bases de datos. Parte del monitoreo nos envía alertas, el equipo responsable y el soporte. Si el problema está conectado, por ejemplo, con la aplicación del controlador, el soporte responderá mucho más rápido y notificará a los controladores si es necesario. Por lo tanto, el tiempo de la información se reduce a unos pocos minutos.
Monitoreo
Tenemos mucho seguimiento. Tan pronto como uno de ellos funciona, ya sea newrelic (servicios del sistema activos), grafana (monitoreo de escenarios específicos), datadog (tiempo de actividad de la infraestructura), recibimos inmediatamente una notificación en Slack y recibimos una llamada por turno (gracias a pagerduty). Y por un cierto período de tiempo se nombra a una persona. Dado que esto sucede automáticamente, es probable que esta persona en particular no esté disponible actualmente o simplemente no haya respondido, entonces la llamada se reenviará a lo largo de la cadena.
Cuando se activan las alertas, volvemos a verificar el rendimiento de los sistemas y descubrimos la causa de la falla (o aumento de la carga, o una gran cantidad de eventos o llamadas, aquí que volarán). Si entendemos que este es un problema y necesita ser resuelto, enviaremos una carta a grupos de distribución especiales para especialistas operativos.
Por lo tanto, siempre estamos en línea.
Gestión de incidentes
Si su empresa proporciona servicios, la gestión de incidentes no está en ningún lado. Trabajamos de acuerdo con este esquema:
- Detección oportuna de problemas.
- Notificación del problema de las personas responsables.
- Notificación a las partes interesadas en todos los niveles. Es decir, hablamos sobre el problema de los negocios, para que todos allí comprendan exactamente cómo tales problemas afectan a las empresas y las ganancias.
- Mantener la máxima transparencia del trabajo.
- Análisis obligatorio de la causa raíz. Después de todo, tiene el origen del problema, y el siguiente puede prevenirse. Esto es más rápido y más útil que resolverlo nuevamente en la segunda ronda.
El objetivo es aprender sobre los problemas en las etapas cero. Esto es cuando fue usted quien descubrió el problema como el empleado que proporciona la capacidad de trabajo. No cuando el cliente te informó sobre ella. Por lo tanto, utilizamos activamente el kit de herramientas APM (Application Performance Monitoring). Los expresaré una vez más.
NewRelic- Monitoreo de todos nuestros microservicios y puertas de enlace.
- 50x, errores 4xx
- Redis apdex
- DBs Apdex
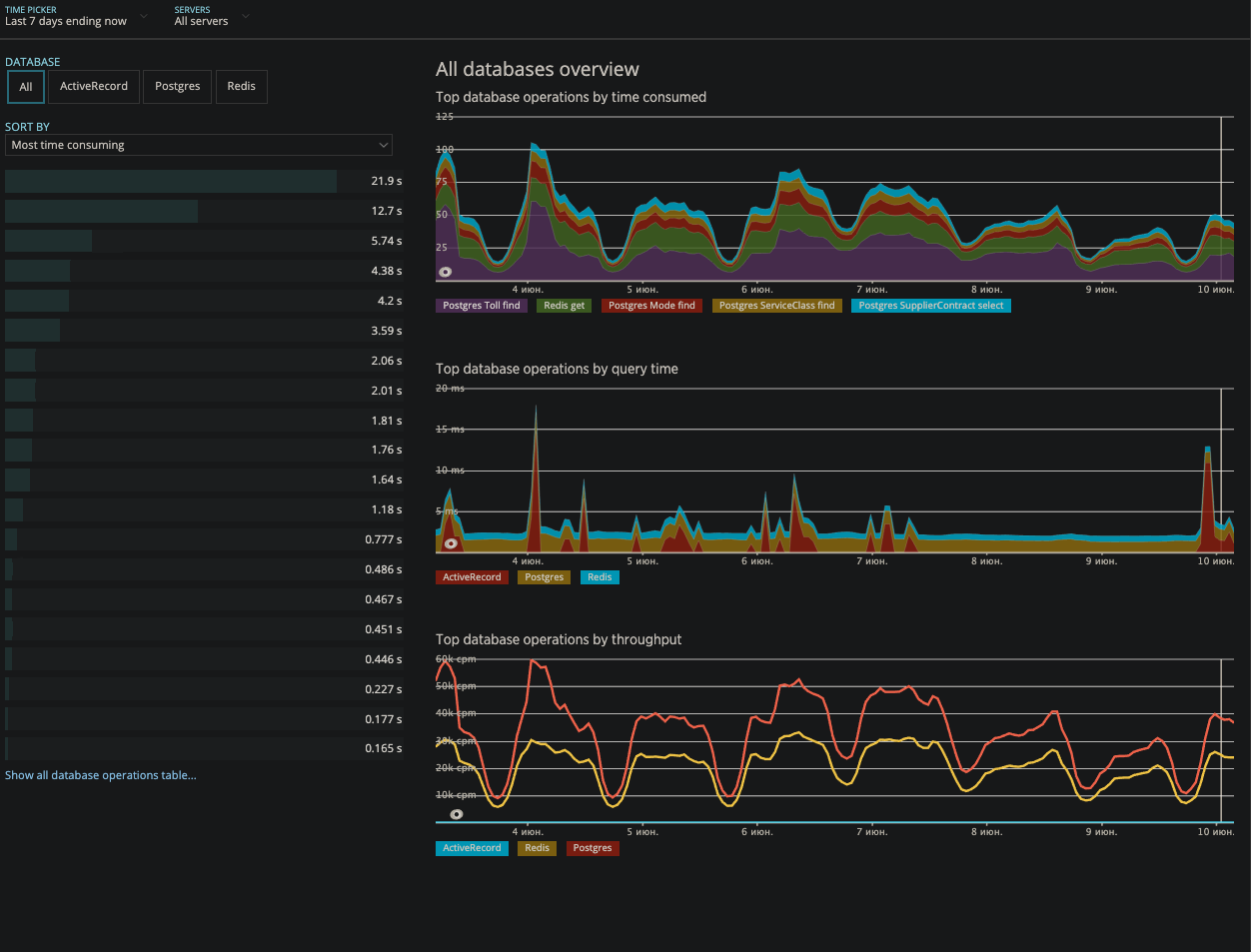 NuevoRelic, cliqueableGrafana
NuevoRelic, cliqueableGrafana Monitoreo de eventos (deja en claro qué dejó de funcionar exactamente o si el comportamiento es diferente al normal).
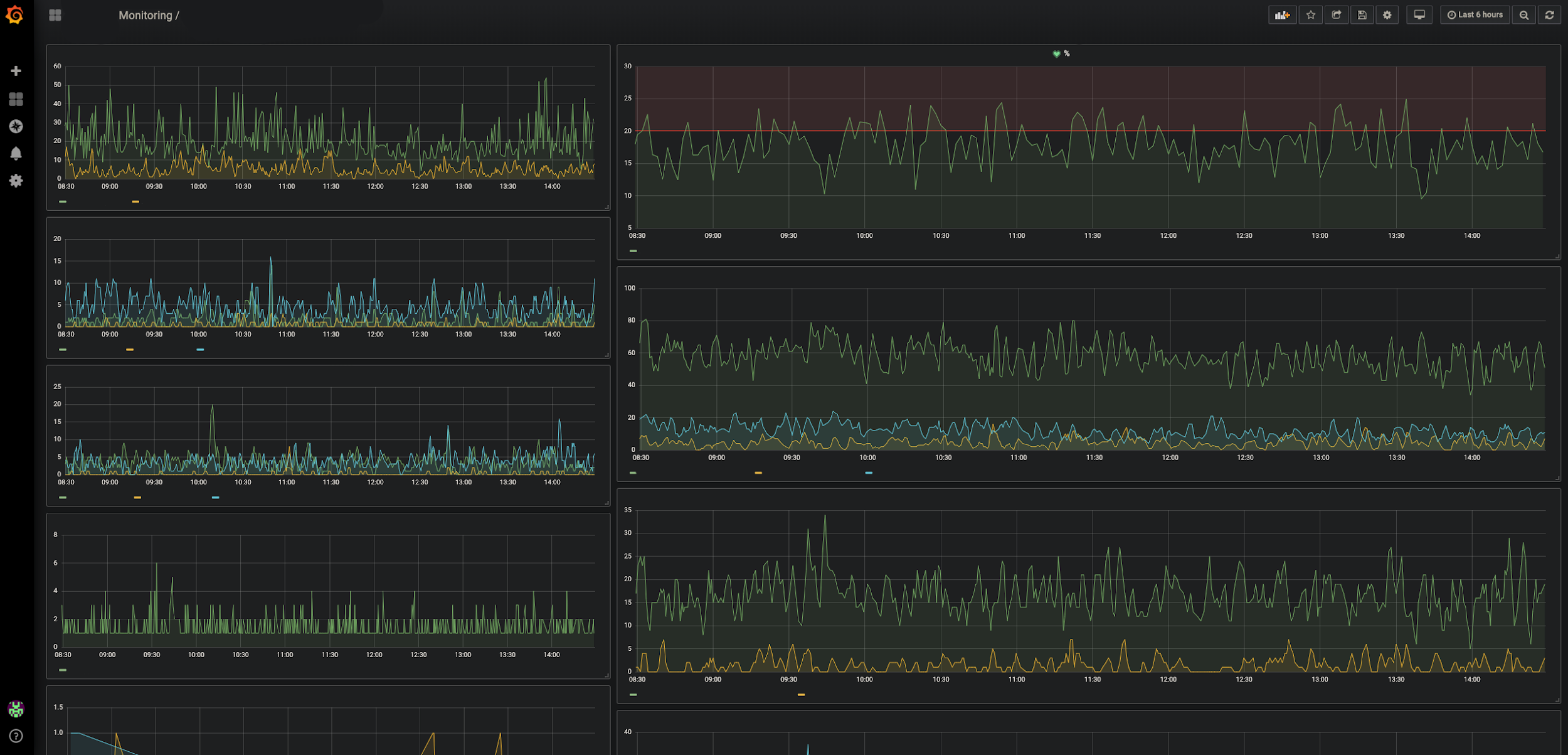 Grafana, cliqueableDataDog
Grafana, cliqueableDataDog . Monitoreo de los componentes de hardware de nuestro sistema (bases de datos, equilibradores de carga).
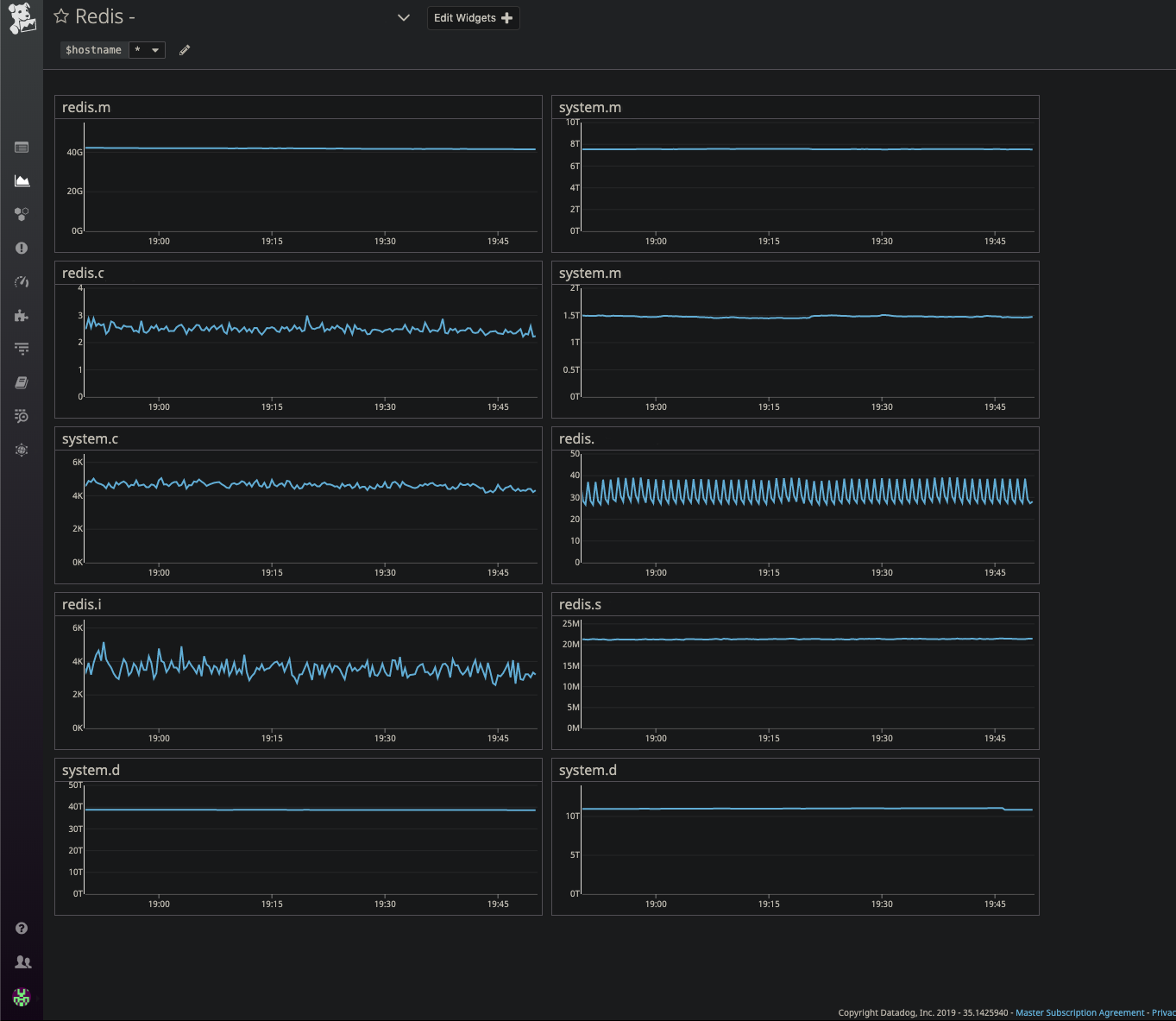 DataDog, cliqueableFreno de aire
DataDog, cliqueableFreno de aire Excepciones de código para aplicaciones / microservicios (hay una lista de excepciones, por ejemplo, al ejecutar código o consultas en la base de datos, si algo sale mal y está en la lista, lo rastreamos).
Kibana : monitoreo de registros de microservicios / aplicaciones (controlador / cliente).
Y para que todo funcione no solo para la detección, sino también para la notificación oportuna (inmediatamente, cuanto más rápido, mejor), todo esto está conectado con una serie de canales de notificación, desde Slack y
PagerDuty hasta buenas notificaciones por correo electrónico. Por lo tanto, todo el equipo aprenderá inmediatamente sobre cualquier anomalía. Las alertas se pueden enviar a diferentes canales. El monitoreo crítico para el funcionamiento de las aplicaciones siempre envía alertas al equipo de soporte técnico y selectivamente a los canales de los equipos de desarrollo responsables de una característica / servicio específico. Todo esto ayuda a optimizar el tiempo de respuesta.
Surgieron dificultades en el siguiente paso, cuando después de encontrar un problema tuvo que notificar rápidamente a la persona responsable del servicio. Y esto no es tan simple de hacer si hay muchos procesos y microservicios, lo que significa que no hay otros menos responsables. Y la alerta puede llegar tarde en la noche, cuando quieras algo, pero simplemente no decides quién es responsable de qué.
Por lo tanto, creamos un directorio conveniente que enumera todos los propietarios de servicios (generalmente en toda la empresa). Como ha demostrado la práctica, esto solo nos ayudó a reducir el tiempo para resolver cada incidente en aproximadamente un 20%.
La mejor receta para un desastre en curso en este caso es dejar el incidente sin una persona a cargo.
Hay una persona especial, Global Incident Manager, que trabaja como centro de incidentes graves. Se dedica a monitorear y cambiar los sistemas básicos para eliminar los errores que pueden conducir a los huesos del negocio, y es responsable ante los altos funcionarios de la empresa, proporcionándoles informes detallados sobre el análisis de las causas raíz.
Por lo tanto, en resumen, el proceso de gestión de incidentes se ve así:
- Determinamos las causas del incidente.
- Encontramos a la persona a cargo.
- Estamos coordinando esfuerzos con él para solucionar el problema lo más rápido posible.
- Tomamos todas las decisiones necesarias durante el incidente.
- Informamos al negocio sobre esto, les traemos todos los problemas.
- Cuando el polvo se dispersa, comenzamos el análisis de causa raíz, RCA (análisis de causa raíz).
Estamos creando informes de incidentes en Jira, hay un módulo correspondiente,
Incidentes , hemos agregado una serie de campos adicionales allí.
Solo hay tres etapas de RCA.
1. RCA inicialEsta es la descripción de nivel superior de la causa del problema (ya sea un problema con la base de datos, con la infraestructura o con el código). Este informe es preparado por el oficial de soporte que manejó el incidente. El informe debe completarse dentro de las 24 horas posteriores a la finalización del incidente.
2. I + D RCALa parte más importante del proceso debe completarse dentro de las 48 horas posteriores a la finalización del incidente. Aquí hay un análisis técnico completo de la causa raíz: por qué sucedió, por qué no se encontró (los evaluadores pasaron por alto o no hay un monitoreo apropiado), ¿existe la posibilidad de que vuelva a suceder y qué hacer para evitar que vuelva a suceder?
3. AccionesSegún el segundo párrafo, se forman las subtareas correspondientes, el incidente permanece abierto hasta que se cierre la última de estas subtareas. Nadie quiere que esta tarea tome un kanban durante mucho tiempo, por lo que esto motiva a resolver todo más rápido.
Así es como nosotros en Gett trabajamos con incidentes.
Figuras y Tecnologías
Trabajamos, por supuesto, 24/7 con un SLA de 99.99%. La pila principal que tenemos en GoLang / Ruby, proporciona la velocidad necesaria para procesar algoritmos complejos. Hay más de 150 microservicios en total, y todos ellos también están en GoLang y Ruby. Utilizamos MySQL, Postgres y Presto como bases de datos. Tenemos almacenamiento en AWS.
La carga más grave en nuestros servicios recae en las vacaciones de Año Nuevo y las 2 semanas anteriores. La condición de los competidores también afecta, por ejemplo, uno de ellos abandonó la aplicación, lo que significa que nuestras máquinas se llamarán con más frecuencia.
También hay picos en el trabajo interno que afectan a los usuarios finales. Por ejemplo, cuando actualizamos la base de datos o realizamos trabajos técnicos del lado de proveedores y vendedores, o implementamos nuevos servicios para la producción (no los viernes, sí), o encargamos funciones que afectan de inmediato a un gran número de usuarios o transacciones.
También somos personas, y a veces sucede que la configuración incorrecta o la intervención manual conducen a errores operativos, por lo que desarrollamos un plan para este caso:

No, eso no. Aquí:
- Verificamos datos en servicios, registros y auditorías.
- Probamos y realizamos operaciones de actualización en Scrum.
- Preparamos una tarea para el equipo y supervisamos la ejecución de la tarea en producción.
Si está interesado en algún detalle, no dude en hacer preguntas en los comentarios, le responderemos aquí o en una publicación detallada por separado.