Hola a todos, quiero compartir con el público cierta cantidad de información, que me pareció difícil de encontrar en Internet.
Qué es un árbol, ver
Wikipedia .
 Fig. 1 Ejemplo de un árbol.
Fig. 1 Ejemplo de un árbol.Entonces, ¿por qué necesitas atravesar el árbol en múltiples hilos? En mi caso, era la necesidad de buscar archivos en el disco. Está claro que físicamente el disco funciona en una secuencia, pero sin embargo, la búsqueda de archivos de subprocesos múltiples puede acelerar, en el caso de que una sola secuencia busque un archivo en una jerarquía de niveles múltiples, y el archivo deseado se encuentra en una carpeta adyacente con un nivel. Otra prueba de la relevancia del uso de la búsqueda multiproceso es su implementación en muchos productos comerciales exitosos. No excluyo que sean posibles otras variantes de la aplicación del algoritmo, escriba en los comentarios.
Para empezar, propongo considerar la animación:
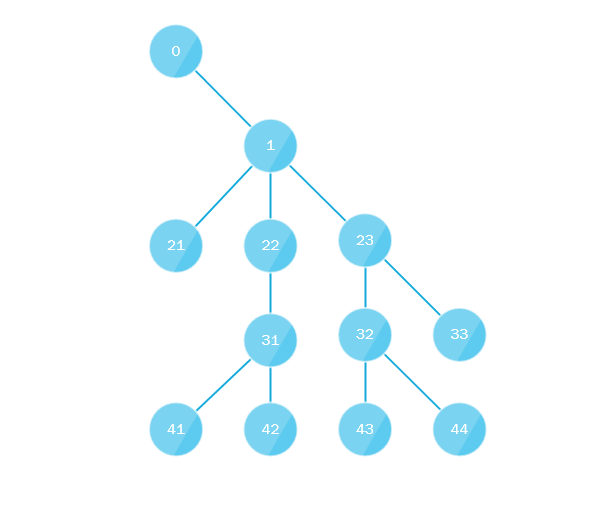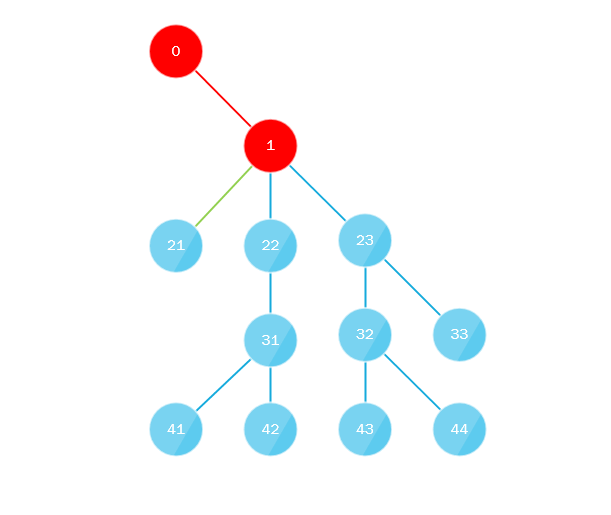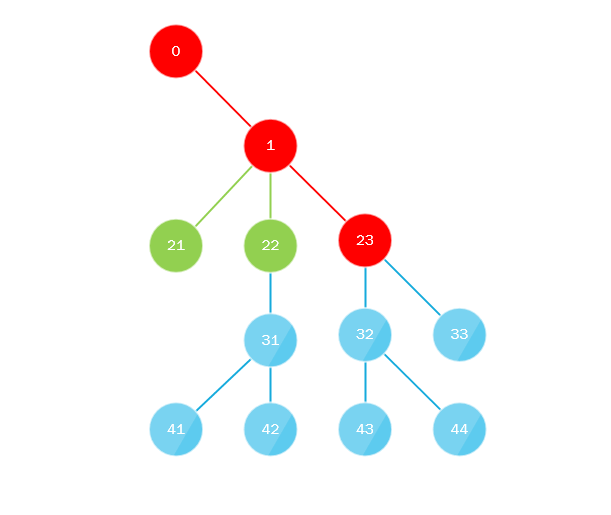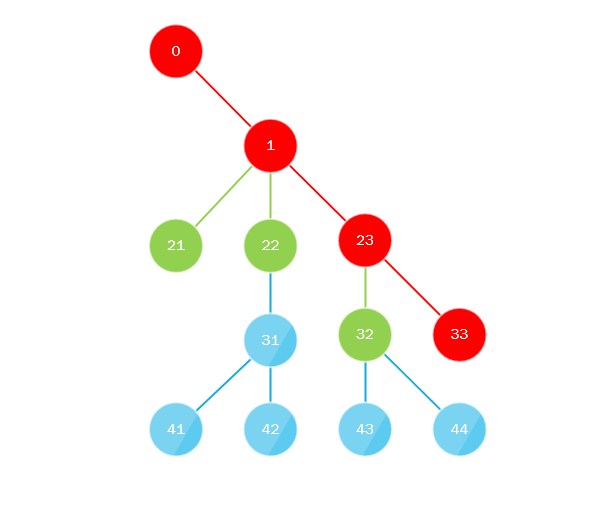
¿Qué está pasando aquí? Toda la esencia del algoritmo es que:
- La primera secuencia pasa por alto el árbol desde la raíz hasta toda la profundidad a lo largo del camino de "extrema izquierda", es decir siempre se mueve hacia la izquierda cuando se mueve hacia adentro o, en otras palabras, siempre selecciona el último nodo secundario.
- Paralelamente, el primer subproceso recopila todos los nodos secundarios que faltan y los envía a la cola (oa la pila) donde los lleva otro subproceso, la cola o la pila deben implementar un enfoque de subprocesos múltiples, y el algoritmo se repite, sustituyendo el nodo recién tomado en lugar de la raíz.
De hecho, en general, el algoritmo se ve así (un color - un hilo):
De hecho, en general, el algoritmo se ve así (un color - un hilo):

Implementación de software Java
Doy un ejemplo de un código que podría ser útil para alguien, lo busqué durante mucho tiempo, pero no lo encontré:
import java.io.File; import java.util.concurrent.BlockingQueue; import java.util.concurrent.Executor; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingDeque; public class MultiThreadTreeWalker extends Thread { private static BlockingQueue<File> nodesToReview = new LinkedBlockingDeque<>(); private File f; public MultiThreadTreeWalker(File f) { this.f = f; } public MultiThreadTreeWalker() { } public static void main(String[] args) { Executor ex = Executors.newFixedThreadPool(2); MultiThreadTreeWalker mw = new MultiThreadTreeWalker(new File("C:\\")); mw.run(); for (int i = 0;i<2;i++) { ex.execute(new MultiThreadTreeWalker()); } } @Override public void run() { if (f != null) {
Conclusión
Como puede ver, el subprocesamiento múltiple en Java se puede implementar de manera bastante simple a través de BlockingQueue, una estructura de datos que proporciona acceso de varios subprocesos a los datos almacenados.
En general, eso es todo, en resumen, escribir comentarios sobre qué otros métodos o métodos de recorrido de árboles existen, me gustaría escuchar la opinión del gurú en este asunto. Escribe preguntas, deseos.
Enlace a GitHub . También hay un motor de búsqueda JavaFX cerca, si alguien quiere probar, solo me alegraré.