
Primero, definamos el concepto de "cola".
Tome en consideración el tipo de cola
"FIFO" (primero en
entrar , primero en salir). Si toma el valor de
Wikipedia , "este es un tipo de datos abstractos con la disciplina del acceso a los elementos". En resumen, esto significa que no podemos obtener datos de él en un orden aleatorio, sino solo recoger lo que vino primero.
A continuación, ¿debe decidir por qué son necesarios?
1. Para operaciones diferidas. Un ejemplo clásico es el procesamiento de imágenes. Por ejemplo, un usuario cargó una imagen en el sitio que necesitamos procesar, esta operación lleva mucho tiempo, el usuario no quiere esperar tanto. Por lo tanto, cargamos la imagen y luego la transferimos a la cola. Y se procesará cuando cualquier "trabajador" lo obtenga.
2. Para el manejo de cargas máximas. Por ejemplo, hay una parte del sistema que a veces causa mucho tráfico y no requiere una respuesta instantánea. Como opción, generar cualquier informe. Lanzando esta tarea en la cola, le damos la oportunidad de manejarla con una carga uniforme en el sistema.
3. Escalabilidad. Y probablemente la razón más importante, la cola lo hace posible
escalar Esto significa que puede mostrar varios servicios para el procesamiento en paralelo, lo que aumentará considerablemente la productividad.
Ahora veamos los problemas que enfrentaremos si creamos la cola nosotros mismos:
1. Acceso en paralelo. Solo un controlador puede tomar un mensaje de una cola. Es decir, si al mismo tiempo dos servicios solicitan mensajes, cada uno de ellos debe devolver un conjunto único de mensajes. De lo contrario, resulta que un mensaje se procesa dos veces. Lo que podría estar cargado.
2. El mecanismo de deduplicación. El servicio debe tener un sistema que proteja la cola de los duplicados. Puede haber una situación en la que uno y el mismo conjunto de datos se enviarán a la cola por casualidad dos veces. Como resultado, procesaremos lo mismo dos veces. Lo que de nuevo está cargado.
3. Mecanismo de manejo de errores. Digamos que nuestro servicio tomó tres mensajes de la cola. Dos de los cuales procesó con éxito enviando solicitudes de eliminación de la cola. Y el tercero no pudo procesarlo y murió. Un mensaje que está en estado de procesamiento no está disponible para otros servicios. Y no debe permanecer para siempre en estado de procesamiento. Tal mensaje debe pasar a otro controlador por alguna lógica. Pronto se considerará un ejemplo de la implementación de esta lógica utilizando AWS SQS (Simple Queue Service) como ejemplo.
Servicios web de Amazon: servicio de cola simple
Ahora veamos cómo SQS resuelve estos problemas y qué puede hacer.
1. Acceso en paralelo. En la cola, puede establecer el parámetro
Visibilidad de tiempo de espera . Determina cuánto tiempo puede tomar el procesamiento de un mensaje el mayor tiempo posible. Por defecto, son
30 segundos. Cuando un servicio recoge un mensaje, se transfiere al estado
"En vuelo" durante 30 segundos. Si durante este tiempo no hubo un comando para eliminar este mensaje de la cola, vuelve al principio y el siguiente servicio puede recibirlo nuevamente para su procesamiento.
Pequeño trabajo shemka.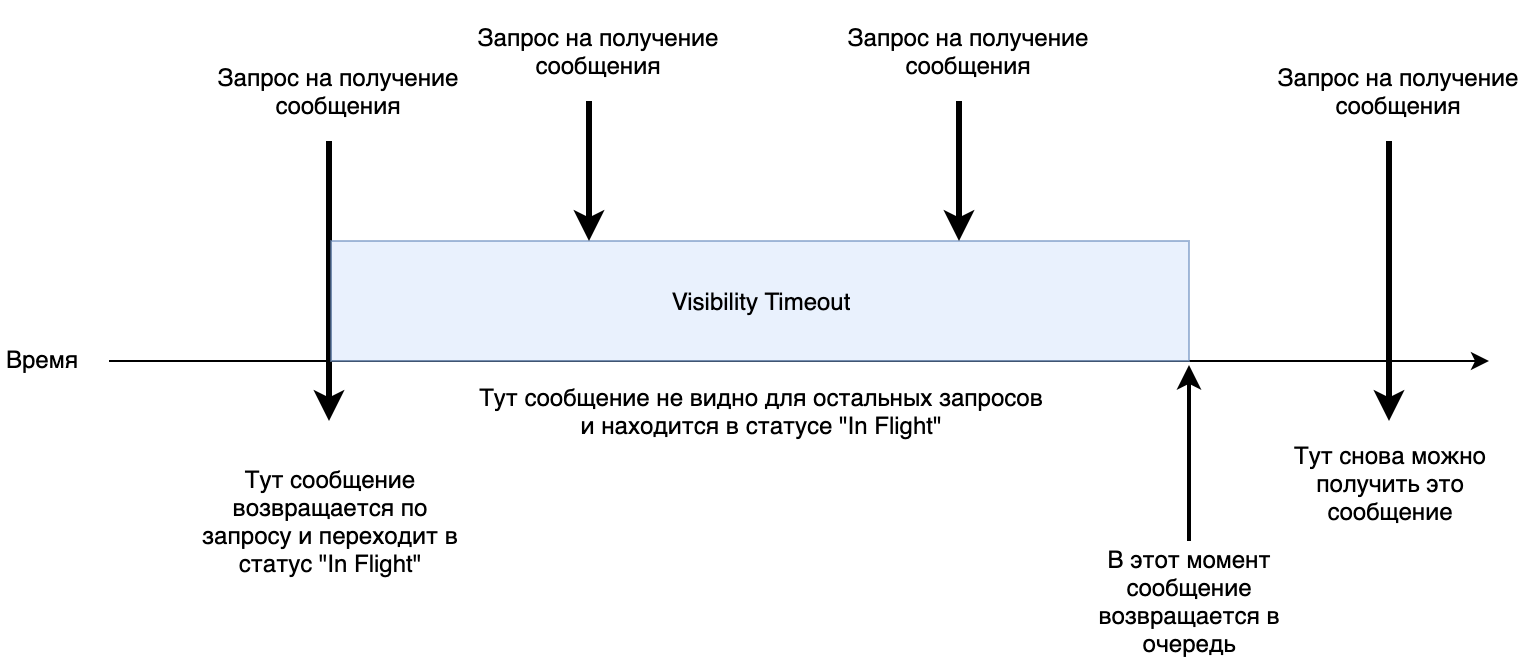
Aviso: ten cuidado. SQS en algunos casos puede enviar un mensaje duplicado (Elemento "Entrega al menos una vez"). Por lo tanto, su servicio debe ser idempotente para el procesamiento.
2. Mecanismo de manejo de errores. En SQS, puede configurar el segundo turno para mensajes "muertos" (Dead Letter Queue). Es decir, aquellos que no pudieron procesar nuestro servicio se enviarán a una cola separada, que puede eliminar a su discreción. También puede establecer después de qué número de intentos fallidos el mensaje irá a la cola "inactiva". Un intento fallido es la expiración del "Tiempo de espera de visibilidad". Es decir, si no se ha enviado una solicitud de eliminación durante este tiempo, dicho mensaje se considerará no procesado y volverá a la cola principal o irá a "inactivo".
3. Deduplicación de mensajes. SQS también tiene un sistema de protección duplicado. Cada mensaje tiene un
"Id de deduplicación" , SQS no pondrá en cola un mensaje con
repitió el "Id de deduplicación" durante 5 minutos. Debe especificar un "Id. De deduplicación" en cada mensaje o habilitar la generación de id basada en contenido. Esto significa que un hash generado en función de su contenido entrará en el "Id. De deduplicación". El parámetro
"Deduplicación basada en contenido". Más acerca de la deduplicaciónAviso: Tenga cuidado si envía dos mensajes idénticos en 5 minutos y tiene activada la "Desduplicación basada en contenido". SQS no agregará un segundo mensaje a la cola.
Aviso: Tenga cuidado, por ejemplo, si no hay conexión en el dispositivo y no recibe una respuesta y luego envía una segunda solicitud después de 5 minutos, se creará un duplicado.
4. Encuesta larga. Encuesta larga SQS admite este tipo de conexión con un tiempo de espera máximo de 20 segundos. Lo que nos permite ahorrar en tráfico y "sacudidas" del servicio.
5. Métricas. Amazon también proporciona métricas de cola detalladas. Como la cantidad de mensajes recibidos / enviados / eliminados, el tamaño en KB de estos mensajes, etc. También puede conectar SQS al servicio de registro de CloudWatch. Allí puedes ver aún más. También allí puede configurar las llamadas
"alarmas" y puede configurar acciones para cualquier evento.
Obtenga más información sobre cómo conectarse a SQS. Y
documentación de CloudWatch
Ahora veamos la configuración de la cola:
Los principales:
Tiempo de espera de visibilidad predeterminado: la cantidad de segundos / minutos / horas durante los cuales el mensaje después de recibir no estará visible para recibir. El tiempo máximo de procesamiento es de 12 horas.
Período de retención de mensajes: la cantidad de segundos / minutos / horas / días, lo que significa cuánto tiempo se guardarán los mensajes sin procesar en la cola. Máximo - 14 días.
Tamaño máximo del mensaje: tamaño máximo del mensaje en KB. El valor es de 1 KB a 256 KB.
Demora de entrega: puede establecer el tiempo de demora para entregar un mensaje a la cola. De 0 segundos a 15 minutos (de hecho, los mensajes estarán en la cola, pero no serán visibles para recibir).
Tiempo de espera del mensaje de recepción: tiempo, cuánto tiempo durará la conexión en caso de que usemos "Encuesta larga" para recibir nuevos mensajes.
Deduplicación basada en contenido: el indicador, si se establece en verdadero, se agregará un "Id. De deduplicación" a cada mensaje en forma de hash SHA-256 generado a partir del contenido.
Configuración de cola muerta
Use la política Redrive: una bandera, si está configurada, los mensajes serán redirigidos después de varios intentos.
Cola de letra muerta: el nombre de la cola "muerta" a la que se enviarán los mensajes sin formato.
Número máximo de recibos: el número de intentos de procesamiento fallidos, después del cual el mensaje se enviará a la cola "inactiva"
Aviso: también tenga en cuenta que podemos enviar todos los parámetros principales junto con cada mensaje por separado. Por ejemplo, cada mensaje individual puede tener su propio tiempo de espera de visibilidad o retraso de entrega.
Ahora un poco sobre los mensajes en sí y sus propiedades:
Un mensaje tiene varios parámetros:
1. Cuerpo del mensaje: cualquier texto
2. Id. De grupo de mensajes es algo así como una etiqueta, un canal, requerido para todos los mensajes. Se garantiza que cada uno de estos grupos se procesará en modo FIFO.
3. Id. De deduplicación del mensaje: cadena para identificar duplicados. Si se establece el modo "Deduplicación basada en contenido", el parámetro es opcional.
También hay atributos de mensaje
Los atributos consisten en un nombre, tipo y valor.
1. Nombre - cadena
2. Tipo: hay varios tipos: cadena, número, binario. El tipo viene simplemente como una cadena, y es posible agregar un postfix al tipo. En este caso, el tipo vendrá con este postfix a través del punto, por ejemplo string.example_postfix
3. Valor - cadena
Aviso: tenga en cuenta que el número máximo de atributos es 10 Detalles
PD: Este artículo proporciona una breve descripción de la cola, así como un poco sobre las capacidades y la mecánica de SQS. El siguiente artículo estará dedicado a
AWS Lambda y, a continuación, a su intercambio práctico.