¿Qué es importante para un equipo de desarrollo que recién comienza a construir un sistema de aprendizaje automático? La arquitectura, los componentes, las capacidades de prueba usando la integración y las pruebas unitarias, hacen un prototipo y obtienen los primeros resultados. Y además de la evaluación de la aportación laboral, la planificación del desarrollo y la implementación.
Este artículo se centrará en el prototipo. El cual fue creado algún tiempo después de hablar con el Gerente de Producto: ¿por qué no "tocamos" Machine Learning? En particular, PNL y análisis de sentimientos?
"¿Por qué no?" Respondí Aún así, llevo más de 15 años desarrollando backend, me gusta trabajar con datos y resolver problemas de rendimiento. Pero aún tenía que averiguar "qué tan profundo es la madriguera del conejo".
Seleccionar componentes
Para delinear de alguna manera el conjunto de componentes que implementan la lógica de nuestro núcleo de ML, echemos un vistazo a un ejemplo simple de la implementación del análisis de sentimientos, uno de los muchos disponibles en GitHub.
Un ejemplo de análisis de sentimientos en Pythonimport collections import nltk import os from sklearn import ( datasets, model_selection, feature_extraction, linear_model ) def extract_features(corpus): '''Extract TF-IDF features from corpus'''
Analizar estos ejemplos es un desafío separado para el desarrollador.
Solo 45 líneas de código y 4 (¡cuatro, Karl!) Bloques lógicos a la vez:
- Descarga de datos para capacitación modelo (líneas 25-26)
- Preparación de datos cargados - extracción de características (líneas 31-34)
- Crear y entrenar un modelo (líneas 36-39)
- Probar un modelo entrenado y generar resultados (líneas 41-45)
Cada uno de estos puntos merece un artículo separado. Y ciertamente requiere registro en un módulo separado. Al menos para las necesidades de pruebas unitarias.
Por separado, vale la pena destacar los componentes de la preparación de datos y la capacitación modelo.
En cada una de las formas de hacer que el modelo sea más preciso, se invierten cientos de horas de trabajo científico y de ingeniería.
Afortunadamente, para comenzar rápidamente con NLP, hay una solución preparada: las
bibliotecas NLTK y
TextBlob . El segundo es un envoltorio sobre NLTK que hace la tarea: realiza la extracción de características del conjunto de entrenamiento y luego entrena el modelo en la primera solicitud de clasificación.
Pero antes de entrenar el modelo, debe preparar datos para él.
Preparando datos
Descargar datos
Si hablamos del prototipo, la carga de datos desde un archivo CSV / TSV es elemental. Simplemente llame a la función
read_csv desde la biblioteca de pandas:
import pandas as pd data = pd.read_csv(data_path, delimiter)
Pero no serán datos listos para usar en el modelo.
En primer lugar, si ignoramos un poco el formato csv, es fácil esperar que cada fuente proporcione datos con sus propias características y, por lo tanto, necesitamos algún tipo de preparación de datos dependiente de la fuente. Incluso para el caso más simple de un archivo CSV, para analizarlo, necesitamos conocer el delimitador.
Además, debe determinar qué entradas son positivas y cuáles negativas. Por supuesto, esta información se indica en la anotación de los conjuntos de datos que queremos usar. Pero el hecho es que en un caso el signo de pos / neg es 0 o 1, en el otro es lógico Verdadero / Falso, en el tercero es solo una cadena pos / neg, y en algunos casos, una tupla de enteros de 0 a 5 Este último es relevante para el caso de la clasificación multiclase, pero ¿quién dijo que dicho conjunto de datos no puede usarse para la clasificación binaria? Solo necesita identificar adecuadamente el borde de los valores positivos y negativos.
Me gustaría probar el modelo en diferentes conjuntos de datos, y se requiere que, después del entrenamiento, el modelo devuelva el resultado en un solo formato. Y para esto, sus datos heterogéneos deben llevarse a una sola forma.
Entonces, hay tres funciones que necesitamos en la etapa de carga de datos:
- La conexión a la fuente de datos es para CSV, en nuestro caso se implementa dentro de la función read_csv;
- Soporte para funciones de formato;
- Preparación de datos preliminares.
Así es como se ve en el código.
import numpy as np
Se
creó la clase
CsvSentimentDataLoader , que en el constructor pasa la ruta a csv, el separador, los nombres del texto y los atributos de clasificación, así como una lista de valores que aconsejan el valor positivo del texto.
La carga en sí ocurre en el método
load_data .
Dividimos los datos en conjuntos de prueba y entrenamiento.
Ok, subimos los datos, pero aún necesitamos dividirlos en los conjuntos de entrenamiento y prueba.
Esto se hace con la función
train_test_split de la biblioteca
sklearn . Esta función puede tomar muchos parámetros como entrada, determinando cómo se dividirá exactamente este conjunto de datos en tren y prueba. Estos parámetros afectan significativamente el entrenamiento resultante y los conjuntos de pruebas, y probablemente sea conveniente para nosotros crear una clase (llamémosla SimpleDataSplitter) que administrará estos parámetros y agregará la llamada a esta función.
from sklearn.model_selection import train_test_split
Ahora esta clase incluye la implementación más simple, que, cuando se divide, tendrá en cuenta solo un parámetro: el porcentaje de registros que deben tomarse como un conjunto de pruebas.
Conjuntos de datos
Para entrenar el modelo, utilicé conjuntos de datos disponibles gratuitamente en formato CSV:
Y para hacerlo aún más conveniente, para cada uno de los conjuntos de datos hice una clase que carga datos del archivo CSV correspondiente y los divide en conjuntos de entrenamiento y prueba.
import os import collections import logging from web.data.loaders import CsvSentimentDataLoader from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter log = logging.getLogger() class AmazonAlexaDataset(): def __init__(self): self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv')) self.delim = '\t' self.text_attr = 'verified_reviews' self.rate_attr = 'feedback' self.pos_rates = [1] self.data = None self.train = None self.test = None def load_data(self): loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates) splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3) self.data = loader.load_data() x_train, x_test, y_train, y_test = splitter.split_data(self.data) self.train = [x for x in zip(x_train, y_train)] self.test = [x for x in zip(x_test, y_test)]
Sí, para la carga de datos, resultó un poco más de 5 líneas de código en el ejemplo original.
Pero ahora es posible crear nuevos conjuntos de datos haciendo malabares con las fuentes de datos y los algoritmos de preparación de conjuntos de entrenamiento.
Además, los componentes individuales son mucho más convenientes para las pruebas unitarias.
Nosotros entrenamos el modelo
El modelo ha estado aprendiendo durante bastante tiempo. Y esto debe hacerse una vez, al comienzo de la aplicación.
Para estos fines, se creó un pequeño contenedor que le permite descargar y preparar datos, así como entrenar el modelo en el momento de la inicialización de la aplicación.
class TextBlobWrapper(): def __init__(self): self.log = logging.getLogger() self.is_model_trained = False self.classifier = None def init_app(self): self.log.info('>>>>> TextBlob initialization started') self.ensure_model_is_trained() self.log.info('>>>>> TextBlob initialization completed') def ensure_model_is_trained(self): if not self.is_model_trained: ds = SentimentLabelledDataset() ds.load_data()
Primero obtenemos datos de entrenamiento y prueba, luego hacemos extracción de características, y finalmente entrenamos el clasificador y verificamos la precisión en el conjunto de prueba.
Prueba
Tras la inicialización, obtenemos un registro, a juzgar por el cual, los datos se descargaron y el modelo se entrenó con éxito. Y entrenado con muy buena precisión (para empezar): 0.8878.
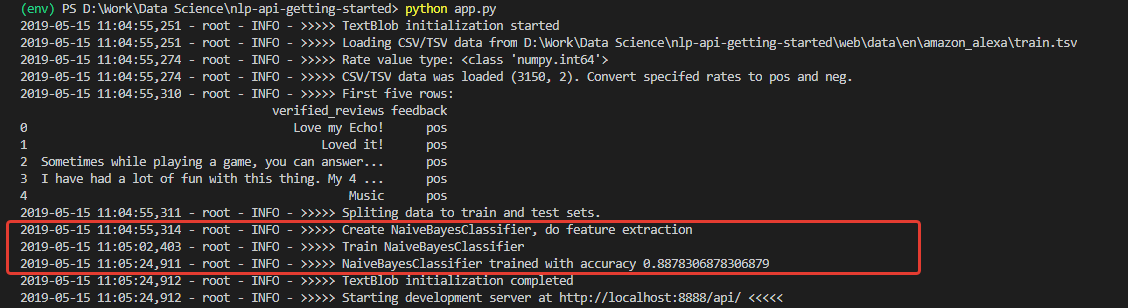
Habiendo recibido tales números, estaba muy entusiasmado. Pero mi alegría, desafortunadamente, no fue larga. El modelo entrenado en este conjunto es un optimista impenetrable y, en principio, no puede reconocer comentarios negativos.
La razón de esto está en los datos del conjunto de entrenamiento. El número de críticas positivas en el conjunto supera el 90%. En consecuencia, con una precisión del modelo de aproximadamente el 88%, las revisiones negativas simplemente caen dentro del 12% esperado de las clasificaciones incorrectas.
En otras palabras, con tal conjunto de entrenamiento, es simplemente imposible entrenar al modelo para que reconozca los comentarios negativos.
Para asegurarme realmente de esto, hice una prueba unitaria que ejecuta la clasificación por separado para 100 frases positivas y 100 negativas de otro conjunto de datos; para probar, tomé el
Conjunto de datos de oraciones etiquetadas de sentimiento de la Universidad de California.
@loggingtestcase.capturelogs(None, level='INFO') def test_classifier_on_separate_set(self, logs): tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset ds = SentimentLabelledDataset() # Test dataset ds.load_data() # Check poisitives true_pos = 0 data = ds.data.to_numpy() seach_mask = np.isin(data[:, 1], ['pos']) data = data[seach_mask][:100] for e in data[:]: # Model train will be performed on first classification call r = tb.do_sentiment_classification(e[0]) if r == e[1]: true_pos += 1 self.assertLessEqual(true_pos, 100) print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
El algoritmo para probar la clasificación de valores positivos es el siguiente:
- Descargar datos de prueba;
- Tome 100 publicaciones etiquetadas 'pos'
- Ejecutamos cada uno de ellos a través del modelo y contamos el número de resultados correctos
- Muestra el resultado final en la consola.
Del mismo modo, se realiza un recuento de comentarios negativos.
Como se esperaba, todos los comentarios negativos fueron reconocidos como positivos.
Y si entrena el modelo en el conjunto de datos utilizado para las pruebas, ¿
etiqueta de sentimiento ? Allí, la distribución de comentarios negativos y positivos es exactamente de 50 a 50.
Cambia el código y prueba, ejecuta Algo ya La precisión real de 200 entradas de un conjunto de terceros es del 76%, mientras que la precisión de la clasificación de comentarios negativos es del 79%.
Por supuesto, el 76% lo hará para un prototipo, pero no lo suficiente para la producción. Esto significa que se requerirán medidas adicionales para mejorar la precisión del algoritmo. Pero este es un tema para otro informe.
Resumen
En primer lugar, obtuvimos una aplicación con una docena de clases y más de 200 líneas de código, que es un poco más que el ejemplo original de 30 líneas. Y debe ser honesto: estos son solo indicios de la estructura, la primera aclaración de los límites de la aplicación futura. Prototipo.
Y este prototipo permitió darse cuenta de cuán lejos está la distancia entre los enfoques del código desde el punto de vista de los especialistas en Machine Learning y desde el punto de vista de los desarrolladores de aplicaciones tradicionales. Y esta, en mi opinión, es la principal dificultad para los desarrolladores que deciden probar el aprendizaje automático.
Lo siguiente que puede poner a un principiante en un estupor: los datos no son menos importantes que el modelo seleccionado. Esto se ha demostrado claramente.
Además, siempre existe la posibilidad de que un modelo entrenado en algunos datos se muestre de manera inadecuada en otros, o en algún momento su precisión comenzará a degradarse.
En consecuencia, se requieren métricas para monitorear el estado del modelo, flexibilidad al trabajar con datos, capacidades técnicas para ajustar el aprendizaje sobre la marcha. Y así sucesivamente.
En cuanto a mí, todo esto debe tenerse en cuenta al diseñar la arquitectura y los procesos de desarrollo del edificio.
En general, la "madriguera del conejo" no solo era muy profunda, sino que también era extremadamente inteligente. Pero lo más interesante para mí, como desarrollador, es estudiar este tema en el futuro.