
Hace tres años, escribí
un artículo sobre la biblioteca DI para el lenguaje Swift. Desde entonces, la biblioteca ha cambiado mucho y se ha convertido en el
mejor competidor digno de Swinject, superándolo en muchos aspectos. El artículo está dedicado a las capacidades de la biblioteca, pero también tiene consideraciones teóricas. Entonces, a quienes les interesan los temas de DI, DIP, IoC o que eligen Swinject y Swinject, les pido un gato:
¿Qué es DIP, IoC y con qué se come?
Teoría de DIP y IoC
La teoría es uno de los componentes más importantes en la programación. Sí, puede escribir código sin educación, pero a pesar de esto, los programadores leen artículos constantemente, están interesados en diversas prácticas, etc. Es decir, de una forma u otra obtengo conocimiento teórico para ponerlo en práctica.
Uno de los temas que a las personas les gusta pedir entrevistas es
SOLID . Ningún artículo no trata sobre él en absoluto, no se alarme. Pero necesitamos una carta, ya que está estrechamente relacionada con mi biblioteca. Esta es la letra `D` - Principio de inversión de dependencia.
El principio de inversión de dependencia establece:
- Los módulos de nivel superior no deben depender de los módulos de nivel inferior. Ambos tipos de módulos deberían depender de abstracciones.
- Las abstracciones no deberían depender de los detalles. Los detalles deben depender de las abstracciones.
Muchas personas asumen erróneamente que si usan protocolos / interfaces, entonces se adhieren automáticamente a este principio, pero esto no es del todo cierto.
La primera afirmación dice algo sobre las dependencias entre módulos: los módulos deben depender de abstracciones. Espera, ¿qué es la abstracción? - Es mejor preguntarse no qué es la abstracción, sino qué es la abstracción. Es decir, debe comprender cuál es el proceso, y el resultado de este proceso será una abstracción.
La abstracción es una distracción en el proceso de cognición de partes, propiedades y relaciones no esenciales para resaltar signos esenciales y regulares.
El mismo objeto, dependiendo de los objetivos, puede tener diferentes abstracciones. Por ejemplo, la máquina desde el punto de vista del propietario tiene las siguientes propiedades importantes: color, elegancia, conveniencia. Pero desde el punto de vista del mecánico, todo es algo diferente: marca, modelo, modificación, kilometraje, participación en un accidente. Se acaban de nombrar dos abstracciones diferentes para un objeto: la máquina.
Tenga en cuenta que en Swift es habitual utilizar protocolos para abstracciones, pero esto no es un requisito. Nadie se molesta en hacer una clase, asignarle un conjunto de métodos públicos y dejar en privado los detalles de implementación. En términos de abstracción, nada está roto. Debemos recordar la importante tesis: "la abstracción no está vinculada al lenguaje": este es un proceso que ocurre constantemente en nuestra cabeza, y cómo esto se transfiere al código no es tan importante. Aquí también podemos mencionar la
encapsulación , como un ejemplo de lo que está asociado con el lenguaje. Cada idioma tiene sus propios medios para proporcionarlo. En Swift, estas son clases, campos de acceso y protocolos; en interfaces Obj-C, protocolos y separación de archivos h y m.
La segunda afirmación es más interesante, ya que es ignorada o malentendida. Habla sobre la interacción de abstracciones con detalles, y ¿qué son los detalles? Existe la idea errónea de que los detalles son clases que implementan protocolos; sí, esto es cierto, pero no está completo. Debe comprender que los detalles no están vinculados a los lenguajes de programación: el lenguaje C no tiene protocolos ni clases, pero este principio también actúa en consecuencia. Me es difícil explicar teóricamente cuál es la captura, por lo que daré dos ejemplos y luego intentaré demostrar por qué el segundo ejemplo es más correcto.
Supongamos que hay un auto de clase y un motor de clase. Sucedió que necesitamos conectarlos: la máquina contiene un motor. Nosotros, como programadores competentes, seleccionamos el motor de protocolo, implementamos el protocolo y pasamos la implementación del protocolo a la clase de máquina. Todo parece estar bien y correcto: ahora puede reemplazar fácilmente la implementación del motor y no pensar que algo se romperá. A continuación, se agrega un mecánico del motor al circuito. Le interesan las características completamente diferentes del motor que el automóvil. Estamos ampliando el protocolo y ahora contiene un conjunto de características más amplio que inicialmente. La historia se repite para el propietario del automóvil, para la fábrica que produce motores, etc.
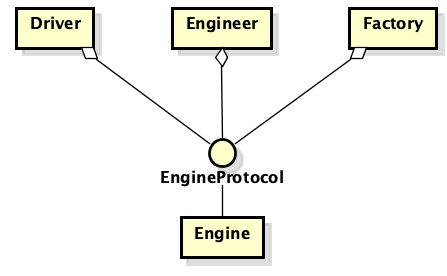
¿Pero dónde está el error en el razonamiento? El problema es que la conexión descrita, a pesar de la disponibilidad de protocolos, es en realidad un "detalle", un "detalle". Más precisamente, en qué nombre y dónde se ubica el protocolo el motor.
Ahora considere la otra opción
correcta .
Como antes, hay dos clases: motor y automóvil. Como antes, deben estar conectados. Pero ahora estamos anunciando el protocolo "Car Engine" o "Heart of a Car". Colocamos en él solo aquellas características que el automóvil necesita del motor. Y colocamos el protocolo no al lado de su implementación de "motor", sino al lado de la máquina. Además, si necesitamos un mecánico, tendremos que crear otro protocolo e implementarlo en el motor. Parece que nada ha cambiado, pero el enfoque es radicalmente diferente: la cuestión no está tanto en los nombres, sino en a quién pertenecen los protocolos y cuál es el protocolo, una "abstracción" o un "detalle".
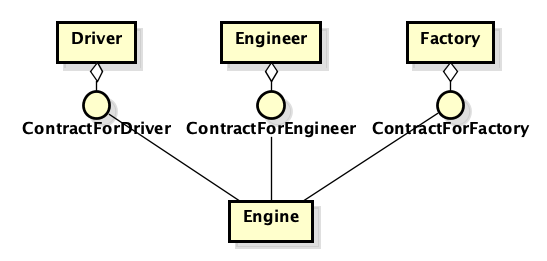
Ahora dibujemos una analogía con otro caso, ya que estos argumentos pueden no ser obvios.
Hay un backend y se necesita cierta funcionalidad. El backend nos ofrece un método amplio que contiene muchos datos y dice: "necesita estos 3 campos de 1000"
Pequeña historiaMuchos pueden decir que esto no sucede. Y estarán relativamente en lo cierto: sucede que el backend se escribe por separado para la aplicación móvil. Sucedió que trabajé para una compañía donde el backend es un servicio con una historia de 10 años que, entre otras cosas, está vinculado a la API del estado. Por muchas razones, no era habitual que la empresa escribiera un método separado para el móvil, y tuve que usar lo que era. Y había un método maravilloso con aproximadamente cien parámetros en la raíz, y algunos de ellos eran diccionarios anidados. Ahora imagine 100 parámetros, el 20% de los cuales tienen parámetros anidados, y dentro de cada uno anidado hay otros 20-30 parámetros que tienen el mismo anidamiento. No recuerdo exactamente, pero el número de parámetros excedió 800 para objetos simples, y para los complejos podría ser mayor que 1000.
No suena muy bien, ¿verdad? Por lo general, el backend escribe un método para tareas específicas para el frontend, y el frontend es el cliente / usuario de estos métodos. Hmm ... Pero si lo piensas bien, el motor es el motor y la interfaz es el automóvil: la máquina necesita algunas características del motor, y no el motor necesita las características del automóvil. Entonces, ¿por qué, a pesar de esto, continuamos escribiendo el protocolo Engine y lo colocamos más cerca de la implementación del motor, y no de la máquina? Se trata de la escala: en la mayoría de los programas de iOS, es muy raro tener que expandir la funcionalidad tanto que tal solución se convierta en un problema.
Y entonces que es DI
Hay una sustitución de conceptos: DI no es una abreviatura de DIP, sino una abreviatura completamente diferente, a pesar de que se cruza muy estrechamente con DIP. DI es una inyección de dependencia o inyección de dependencia, no una inversión. Inversion habla sobre cómo las clases y los protocolos deberían interactuar entre sí, y la implementación le dice de dónde obtenerlos. En general, puede implementarlo de varias maneras, comenzando por las dependencias: constructor, propiedad, método; terminando con aquellos que los crean y qué tan automatizado es este proceso. Los enfoques son diferentes pero, en mi opinión, los más convenientes son los contenedores para inyección de dependencia. En resumen, todo su significado se reduce a una regla simple: le decimos al contenedor dónde y cómo implementarlo y luego todo se implementa de forma independiente. Este enfoque corresponde a la "implementación real de dependencias": esto es cuando las clases en las que están incrustadas las dependencias no saben nada acerca de cómo sucede esto, es decir, son pasivas.
En muchos idiomas, se utiliza el siguiente enfoque para esta implementación: en clases / archivos separados, se describen las reglas de implementación que usan la sintaxis del lenguaje, después de lo cual se compilan y se implementan automáticamente. No hay magia: nada sucede automáticamente, solo las bibliotecas están estrechamente integradas con los medios básicos del lenguaje y sobrecargan los métodos de creación. Entonces, para Swift / Obj-C, generalmente se acepta que el punto de partida es el UIViewController, y las bibliotecas pueden integrarse fácilmente en el ViewController creado desde el Storyboard. Es cierto que si no usa el Storyboard, tendrá que hacer parte del trabajo con bolígrafos.
Ah, sí, casi lo olvido: la respuesta a la pregunta principal, "¿por qué necesitamos esto?" Sin lugar a dudas, usted mismo puede encargarse de la inyección de dependencia, prescribir todo con bolígrafos. Pero surgen problemas cuando los gráficos se hacen grandes: hay que mencionar muchas conexiones entre clases, el código comienza a crecer mucho. Por lo tanto, las bibliotecas que implementan automáticamente dependencias recursivas (e incluso cíclicas) se preocupan por sí mismas y, como beneficio adicional, controlan su vida útil. Es decir, la biblioteca no hace nada más que lo natural: simplemente simplifica la vida del desarrollador. Es cierto, no piense que puede escribir una biblioteca de este tipo en un día: una cosa es escribir con lápiz todas las dependencias para un caso particular, es otra cosa enseñarle a una computadora a implementar de manera universal y correcta.
Historia de la biblioteca
La historia no estaría completa si no contara la historia brevemente. Si sigues la biblioteca desde la versión beta, no será tan interesante para ti, pero para aquellos que la ven por primera vez, creo que vale la pena entender cómo apareció y qué objetivos siguió el autor (es decir, yo).
La biblioteca fue mi segundo proyecto, que decidí, para fines de autoeducación, escribir en Swift. Antes de eso pude escribir un registrador, pero no lo subí al dominio público, es mejor y mejor.
Pero con DI, la historia es más interesante. Cuando comencé a hacerlo, pude encontrar solo una biblioteca en Swift: Swinject. En ese momento, ella tenía 500 estrellas y errores que los ciclos normalmente no se procesan. Miré todo esto y ... Mi comportamiento se describe mejor con mi frase favorita "Y luego sufrió Ostap". Revisé 5-6 idiomas, miré lo que hay en estos idiomas, leí artículos sobre este tema y me di cuenta de que se puede hacer mejor. Y ahora, después de casi tres años, puedo decir con confianza que se ha logrado el objetivo, en este momento DITranquillity es el mejor en mi visión del mundo.
Comprendamos qué es una buena biblioteca DI:
- Debe proporcionar todas las implementaciones básicas: constructor, propiedades, métodos.
- No debería afectar el código comercial.
- Ella debe describir claramente lo que salió mal.
- Debe comprender de antemano dónde hay errores, no en tiempo de ejecución.
- Debe integrarse con herramientas básicas (Storyboard)
- Debe tener una sintaxis concisa, concisa.
- Ella debe hacer todo de manera rápida y eficiente.
- (Opcional) Debe ser jerárquico
Es a estos principios a los que trato de adherirme durante el desarrollo de la biblioteca.
Características y beneficios de la biblioteca
Primero, un enlace al repositorio:
github.com/ivlevAstef/DITranquillityLa principal ventaja competitiva, que es bastante importante para mí, es que la biblioteca habla de errores de inicio. Después de iniciar la aplicación y llamar a la función deseada, se informarán todos los problemas, tanto existentes como potenciales. Este es precisamente el significado del nombre de la biblioteca "calma"; de hecho, después de iniciar el programa, la biblioteca garantiza que todas las dependencias requeridas existirán y que no habrá ciclos sin solución. En lugares donde hay ambigüedad, la biblioteca advertirá que puede haber problemas potenciales.
A mí me suena bien. No hay bloqueos durante la ejecución del programa, si el programador olvidó algo, esto se informará de inmediato.
Se utiliza una función de registro para describir los problemas, que recomiendo usar. El registro tiene 4 niveles: error, advertencia, información, detallado. Los tres primeros son bastante importantes. Esto último no es tan importante: escribe todo lo que sucede: qué objeto se registró, qué objeto comenzó a introducirse, qué objeto se creó, etc.
Pero esto no es todo lo que presume la biblioteca:
- Seguridad total del hilo: cualquier operación se puede hacer desde cualquier hilo y todo funcionará. La mayoría de las personas no necesitan esto, por lo que en términos de seguridad de subprocesos, se trabajó para optimizar la velocidad de ejecución. Pero la biblioteca de la competencia, a pesar de las promesas, cae si comienzas a registrarte y recibir un objeto al mismo tiempo
- Rápida velocidad de ejecución. En un dispositivo real, DITranquillity es el doble de rápido que su competidor. Verdadero en el simulador, la velocidad de ejecución es casi equivalente. Enlace de prueba
- Tamaño pequeño: la biblioteca pesa menos que Swinject + SwinjectStoryboad + SwinjectAutoregistration, pero supera este conjunto de capacidades
- Una nota concisa, concisa, aunque adictiva
- Jerarquía Para proyectos grandes, que consisten en muchos módulos, esta es una gran ventaja, ya que la biblioteca puede encontrar las clases necesarias por distancia desde el módulo actual. Es decir, si tiene su propia implementación de un protocolo en cada módulo, en cada módulo obtendrá la implementación deseada sin hacer ningún esfuerzo
Demostración
Y entonces comencemos. Como la última vez que se considerará el proyecto:
SampleHabr . Específicamente, no comencé a cambiar el ejemplo, por lo que puede comparar cómo ha cambiado todo. Y el ejemplo muestra muchas características de la biblioteca.
Por si acaso, para que no haya malentendidos, ya que el proyecto está en exhibición, utiliza muchas características. Pero nadie se molesta en usar la biblioteca de manera simplificada: descargó, creó un contenedor, registró un par de clases, usó el contenedor.
Primero necesitamos crear un marco (opcional):
public class AppFramework: DIFramework {
Y al comienzo del programa, cree su propio contenedor, con la adición de este marco:
let container = DIContainer()
Storyboard
A continuación, debe crear una pantalla básica. Por lo general, se usan Storyboards para esto, y en este ejemplo lo usaré, pero nadie se molesta en usar UIViewControllers.
Para empezar, necesitamos registrar un Storyboard. Para hacer esto, cree una "parte" (opcional: puede escribir todo el código en el marco) con el Storyboard registrado en él:
import DITranquillity class AppPart: DIPart { static func load(container: DIContainer) { container.registerStoryboard(name: "Main", bundle: nil) .lifetime(.single)
Y agregue una parte a AppFramework:
container.append(part: AppPart.self)
Como puede ver, la biblioteca tiene una sintaxis conveniente para registrar Storyboard, y recomiendo usarlo. En principio, puede escribir código equivalente sin este método, pero será más grande y no podrá admitir StoryboardReferences. Es decir, este Storyboard no funcionará desde otro.
Ahora lo único que queda es crear un Storyboard y mostrar la pantalla de inicio. Esto se hace en AppDelegate, después de verificar el contenedor:
window = UIWindow(frame: UIScreen.main.bounds)
Crear un Storyboard usando una biblioteca no es mucho más complicado de lo habitual. En este ejemplo, podría perderse el nombre, ya que solo tenemos un Storyboard: la biblioteca habría adivinado que lo tenía en mente. Pero en algunos proyectos hay muchos Storyboards, así que no te pierdas el nombre nuevamente.
Presentador y ViewController
Ir a la pantalla en sí. No cargaremos el proyecto con arquitecturas complejas, pero usaremos el MVP habitual. Además, soy tan vago que no crearé un protocolo para un presentador. El protocolo será un poco más tarde para otra clase, aquí es importante mostrar cómo registrarse y vincular Presenter y ViewController.
Para hacer esto, agregue el siguiente código a AppPart:
container.register(YourPresenter.init) container.register(YourViewController.self) .injection(\.presenter)
Estas tres líneas nos permitirán registrar dos clases y establecer una conexión entre ellas.
La gente curiosa puede preguntarse: ¿por qué la sintaxis que Swinject tiene en una biblioteca separada es la principal del proyecto? La respuesta radica en los objetivos: gracias a esta sintaxis, la biblioteca almacena todos los enlaces por adelantado, en lugar de calcularlos en tiempo de ejecución. Esta sintaxis le brinda acceso a muchas funciones que no están disponibles para otras bibliotecas.
Iniciamos la aplicación, y todo funciona, se crean todas las clases.
Datos
Bueno, ahora necesitamos agregar una clase y un protocolo para recibir datos del servidor:
public protocol Server { func get(method: String) -> Data? } class ServerImpl: Server { init(domain: String) { ... } func get(method: String) -> Data? { ... } }
Y por belleza, crearemos una clase DI ServerPart separada para el servidor, en la que la registraremos. Permítame recordarle que esto no es necesario y puede registrarse directamente en el contenedor, pero no estamos buscando formas fáciles :)
import DITranquillity class ServerPart: DIPart { static func load(container: DIContainer) { container.register{ ServerImpl(domain: "https:
En este código, todo no es tan transparente como en los anteriores y requiere aclaración. En primer lugar, dentro del registro de funciones, se crea una clase con un parámetro pasado.
En segundo lugar, existe la función `as`: dice que otro tipo de acceso será la clase: el protocolo. El extraño final de esta operación en forma de `{$ 0}` es parte del nombre `check:`. Es decir, este código garantiza que ServerImpl sea un sucesor del servidor. Pero hay otra sintaxis: `as (Server.self)` que hará lo mismo, pero sin verificar. Para ver qué generará el compilador en ambos casos, puede eliminar la implementación del protocolo.
Puede haber varias funciones `as`; esto significará que el tipo está disponible con cualquiera de estos nombres. Le llamo la atención de que este será un registro, lo que significa que si la clase es un singleton, entonces la misma instancia estará disponible para cualquier tipo especificado.
En principio, si desea protegerse de la posibilidad de crear una clase por tipo de implementación, o si aún no se ha acostumbrado a esta sintaxis, puede escribir:
container.register{ ServerImpl(domain: "https://github.com/") as Server }
Que será un equivalente, pero sin la capacidad de especificar varios tipos separados.
Ahora puede implementar el servidor en Presenter, para esto arreglaremos Presenter para que acepte Servidor:
class YourPresenter { init(server: Server) { ... } }
Iniciamos el programa, y recae en las funciones `validar` en AppDelegate, con el mensaje de que no se encontró el tipo` Servidor`, pero es requerido por `YourPresenter`. Que pasa Tenga en cuenta que el error ocurrió al comienzo de la ejecución del programa, y no en un post factum. Y la razón es bastante simple: olvidaron agregar `ServerPart` al` AppFramework`:
container.append(part: ServerPart.self)
Comenzamos, todo funciona.
Registrador
Antes de esto, había un conocimiento de las oportunidades que no son muy impresionantes y que muchos tienen. Ahora habrá una demostración de que otras bibliotecas en Swift no saben cómo.
Se creó un
proyecto separado debajo del registrador.
Primero, comprendamos qué será un registrador. Con fines educativos, no haremos un sistema engañado, por lo que el registrador es un protocolo con un método y varias implementaciones:
public protocol Logger { func log(_ msg: String) } class ConsoleLogger: Logger { func log(_ msg: String) { ... } } class FileLogger: Logger { init(file: String) { ... } func log(_ msg: String) { ... } } class ServerLogger: Logger { init(server: String) { ... } func log(_ msg: String) { ... } } class MainLogger: Logger { init(loggers: [Logger]) { ... } func log(_ msg: String) { ... } }
Total, tenemos:
- Protocolo público
- 3 implementaciones de registrador diferentes, cada una de las cuales escribe en un lugar diferente
- Un registrador central que llama a la función de registro para todos los demás
El proyecto creó `LoggerFramework` y` LoggerPart`. No escribiré su código, pero escribiré solo las partes internas de `LoggerPart`:
container.register{ ConsoleLogger() } .as(Logger.self) .lifetime(.single) container.register{ FileLogger(file: "file.log") } .as(Logger.self) .lifetime(.single) container.register{ ServerLogger(server: "http://server.com/") } .as(Logger.self) .lifetime(.single) container.register{ MainLogger(loggers: many($0)) } .as(Logger.self) .default() .lifetime(.single)
Ya hemos visto los primeros 3 registros, y el último plantea preguntas.
Se pasa un parámetro a la entrada. Ya se mostró uno similar cuando se creó el presentador, aunque había un registro abreviado: el método `init` se acaba de usar, pero nadie se molesta en escribir así:
container.register { YourPresenter(server: $0) }
Si hubiera varios parámetros, uno podría usar `$ 1`,` $ 2`, `$ 3`, etc. hasta el 16.
Pero este parámetro llama a la función `many`. Y aquí comienza la diversión. Hay dos modificadores `many` y` tag` en la biblioteca.
Texto ocultoHay un tercer modificador `arg`, pero no es seguro
El modificador `many` dice que necesita obtener todos los objetos correspondientes al tipo deseado. En este caso, se espera el protocolo Logger, por lo que todas las clases que heredan de este protocolo se encontrarán y crearán, con una excepción, en sí misma, es decir, de forma recursiva. No se creará durante la inicialización, aunque puede hacerlo de manera segura cuando se implementa a través de una propiedad.
La etiqueta, a su vez, es un tipo separado que debe especificarse tanto durante el uso como durante el registro. Es decir, las etiquetas son criterios adicionales si no hay suficientes tipos básicos.
Puedes leer más sobre esto:
ModificadoresLa presencia de modificadores, especialmente `muchos`, hace que la biblioteca sea mejor que otras. Por ejemplo, puede implementar el patrón Observador en un nivel completamente diferente. Debido a estas 4 letras, en el proyecto fue posible eliminar 30-50 líneas de código de cada Observador en el proyecto y resolver el problema con la pregunta: dónde y cuándo deberían agregarse objetos al Observable. El negocio claro no es la única aplicación, sino significativa.
Bueno, terminaremos la presentación de las características mediante la introducción de un registrador en YourPresenter:
container.register(YourPresenter.init) .injection { $0.logger = $1 }
Aquí, por ejemplo, está escrito de manera un poco diferente que antes; esto se hace para un ejemplo de una sintaxis diferente.
Tenga en cuenta que la propiedad del registrador es opcional:
internal var logger: Logger?
Y esto no aparece en la sintaxis de la biblioteca. A diferencia de la primera versión, ahora todas las operaciones para el tipo habitual, opcional y opcional forzado tienen el mismo aspecto. Además, la lógica interna es diferente: si el tipo es opcional y no está registrado en el contenedor, el programa no se bloqueará, sino que continuará su ejecución.
Resumen
Los resultados son similares a la última vez, solo la sintaxis se ha vuelto más corta y más funcional.
Lo que se revisó:
¿Qué más puede hacer la biblioteca?
Planes
En primer lugar, se planea pasar a verificar el gráfico en la etapa de compilación, es decir, una mayor integración con el compilador. Hay una implementación preliminar usando SourceKitten, pero dicha implementación tiene serias dificultades con la inferencia de tipos, por lo que se planea cambiar a ast-dump; en 5, comenzó a trabajar en grandes proyectos. Aquí quiero agradecer a
Nekitosss por la gran contribución en esta dirección.
En segundo lugar, me gustaría integrarme con los servicios de visualización. Este será un proyecto ligeramente diferente, pero estrechamente relacionado con la biblioteca. Cual es el punto? Ahora la biblioteca almacena todo el gráfico de conexiones, es decir, en teoría, todo lo que está registrado en la biblioteca se puede mostrar como un diagrama de clase / componente UML. Y sería bueno ver a veces este diagrama.
Esta funcionalidad está planificada en dos partes: la primera parte le permitirá agregar una API para obtener toda la información, y la segunda ya es la integración con varios servicios.
La opción más simple es mostrar un gráfico de enlaces en forma de texto, pero no he visto opciones legibles; de ser así, sugiera opciones en los comentarios.
WatchOS - Yo mismo no escribo proyectos para ellos. Para su vida escribió solo una vez, y luego pequeño. Pero me gustaría hacer una estrecha integración, como con el Storyboard.
Eso es todo gracias por su atención. Realmente espero comentarios y respuestas a la encuesta.
Sobre miIvlev Alexander Evgenievich - líder senior / equipo en el equipo iOS. He trabajado en comercio durante 7 años, con iOS 4.5 años, antes de eso era desarrollador de C ++. Pero la experiencia total de programación es de más de 15 años: en la escuela me familiaricé con este mundo increíble y me dejé llevar tanto que intercambié juegos , comida, un baño, un sueño para escribir código. Según uno de mis artículos, puedes adivinar que soy una antigua Olimpiada; en consecuencia, no fue difícil para mí escribir un trabajo competente con gráficos. Especialidad: sistemas de medición de información, y en un momento estaba obsesionado con el subprocesamiento múltiple y el paralelismo: sí, escribo código en el que hago suposiciones y errores sobre temas similares, pero entiendo las áreas problemáticas y entiendo perfectamente dónde puede descuidar el mutex y dónde No vale la pena.