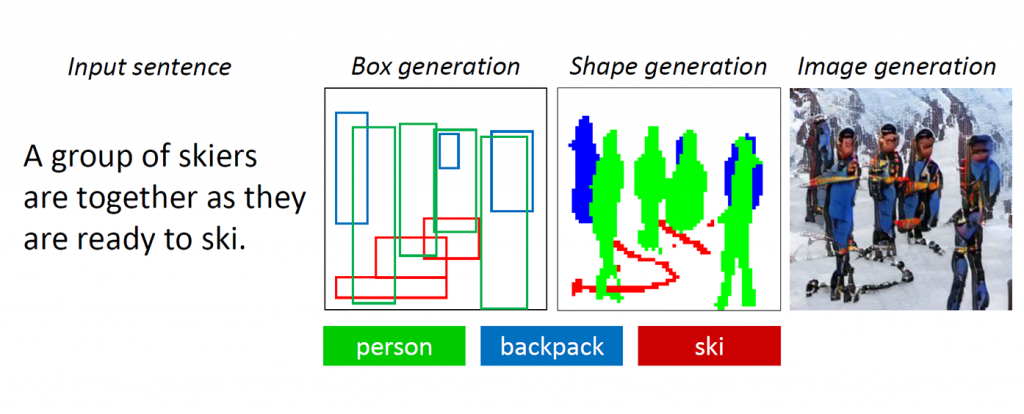
Si le pidieran que dibujara a varias personas en ropa de esquí, de pie en la nieve, es probable que comience con un esquema de tres o cuatro personas razonablemente ubicadas en el centro del lienzo, luego dibuje en los esquís debajo de su pies Aunque no se especificó, es posible que decida agregar una mochila a cada uno de los esquiadores para responder a las expectativas de los esquiadores deportivos. Finalmente, completaría cuidadosamente los detalles, tal vez pintando su ropa de azul, bufandas de color rosa, todo sobre un fondo blanco, haciendo que estas personas sean más realistas y garantizando que su entorno coincida con la descripción. Finalmente, para hacer que la escena sea más vívida, incluso puede dibujar en algunas piedras marrones que sobresalen de la nieve para sugerir que estos esquiadores están en las montañas.
Ahora hay un bot que puede hacer todo eso.
La nueva tecnología de IA que se está desarrollando en Microsoft Research AI puede comprender una descripción en lenguaje natural, esbozar un diseño de la imagen, sintetizar la imagen y luego refinar los detalles en función del diseño y las palabras individuales proporcionadas. En otras palabras, este bot puede generar imágenes a partir de descripciones de texto de subtítulos de escenas cotidianas. Este mecanismo deliberado produjo un impulso significativo en la calidad de imagen generada en comparación con la técnica de vanguardia anterior para la generación de texto a imagen para escenas cotidianas complicadas, de acuerdo con los resultados de las pruebas estándar de la industria informadas en " Texto dirigido por objetos- Síntesis de imagen a través de entrenamiento adversario ”, que se publicará este mes en Long Beach, California, en la Conferencia IEEE 2019 sobre Visión por Computadora y Reconocimiento de Patrones (CVPR 2019). Este es un proyecto de colaboración entre Pengchuan Zhang , Qiuyuan Huang y Jianfeng Gao de Microsoft Research AI , Lei Zhang de Microsoft, Xiaodong He de JD AI Research y Wenbo Li y Siwei Lyu de la Universidad de Albany, SUNY (mientras Wenbo Li trabajó como un pasante en Microsoft Research AI).
Hay dos desafíos principales intrínsecos al problema del robot de dibujo basado en la descripción. La primera es que pueden aparecer muchos tipos de objetos en las escenas cotidianas y el bot debería poder comprenderlos y dibujarlos a todos. Los métodos anteriores de generación de texto a imagen utilizan pares de subtítulos de imagen que solo proporcionan una señal de supervisión de grano muy grueso para generar objetos individuales, limitando su calidad de generación de objetos. En esta nueva tecnología, los investigadores hacen uso del conjunto de datos COCO que contiene etiquetas y mapas de segmentación para 1,5 millones de instancias de objetos en 80 clases de objetos comunes, lo que permite al bot aprender tanto el concepto como la apariencia de estos objetos. Esta señal supervisada de grano fino para la generación de objetos mejora significativamente la calidad de generación para estas clases de objetos comunes.
El segundo desafío radica en la comprensión y generación de las relaciones entre múltiples objetos en una escena. Se ha logrado un gran éxito en la generación de imágenes que solo contienen un objeto principal para varios dominios específicos, como caras, pájaros y objetos comunes. Sin embargo, generar escenas más complejas que contengan múltiples objetos con relaciones semánticamente significativas entre esos objetos sigue siendo un desafío importante en la tecnología de generación de texto a imagen. Este nuevo robot de dibujo aprendió a generar el diseño de objetos a partir de patrones de coincidencia en el conjunto de datos COCO para luego generar una imagen condicionada en el diseño pregenerado.
Generación de imágenes atenta por objetos
En el núcleo del robot de dibujo de Microsoft Research AI se encuentra una tecnología conocida como Red Adversarial Generativa, o GAN. La GAN consta de dos modelos de aprendizaje automático: un generador que genera imágenes a partir de descripciones de texto y un discriminador que usa descripciones de texto para juzgar la autenticidad de las imágenes generadas. El generador intenta obtener imágenes falsas más allá del discriminador; el discriminador por otro lado nunca quiere ser engañado. Trabajando juntos, el discriminador empuja al generador hacia la perfección.
El robot de dibujo fue entrenado en un conjunto de datos de 100,000 imágenes, cada una con etiquetas de objetos sobresalientes y mapas de segmentación y cinco subtítulos diferentes, permitiendo a los modelos concebir objetos individuales y relaciones semánticas entre objetos. La GAN, por ejemplo, aprende cómo debe ser un perro al comparar imágenes con y sin descripciones de perros.

Figura 1: Una escena compleja con múltiples objetos y relaciones.
Las GAN funcionan bien al generar imágenes que contienen solo un objeto destacado, como un rostro humano, pájaros o perros, pero la calidad se estanca con escenas cotidianas más complejas, como una escena descrita como "Una mujer que usa un casco monta un caballo" (ver Figura 1.) Esto se debe a que tales escenas contienen múltiples objetos (mujer, casco, caballo) y ricas relaciones semánticas entre ellas (mujer con casco, mujer con caballo). El bot primero debe comprender estos conceptos y colocarlos en la imagen con un diseño significativo. Después de eso, se requiere una señal más supervisada capaz de enseñar la generación de objetos y la generación de diseño para cumplir con esta tarea de generación de imágenes y comprensión del lenguaje.
A medida que los humanos dibujan estas escenas complicadas, primero decidimos sobre los objetos principales a dibujar y hacemos un diseño colocando cuadros delimitadores para estos objetos en el lienzo. Luego nos enfocamos en cada objeto, verificando repetidamente las palabras correspondientes que describen este objeto. Para capturar este rasgo humano, los investigadores crearon lo que llamaron una GAN atenta dirigida por objetos, u ObjGAN, para modelar matemáticamente el comportamiento humano de la atención centrada en objetos. ObjGAN hace esto dividiendo el texto de entrada en palabras individuales y haciendo coincidir esas palabras con objetos específicos en la imagen.
Los humanos suelen verificar dos aspectos para refinar el dibujo: el realismo de los objetos individuales y la calidad de los parches de imagen. ObjGAN también imita este comportamiento mediante la introducción de dos discriminadores: un discriminador por objeto y un discriminador por parche. El discriminador en cuanto al objeto está tratando de determinar si el objeto generado es realista o no y si el objeto es consistente con la descripción de la oración. El discriminador de parche está tratando de determinar si este parche es realista o no y si este parche es consistente con la descripción de la oración.
Trabajo relacionado: visualización de la historia
Los modelos de generación de texto a imagen de última generación pueden generar imágenes realistas de aves basadas en una descripción de una sola oración. Sin embargo, la generación de texto a imagen puede ir mucho más allá de la síntesis de una sola imagen basada en una oración. En " StoryGAN: A GAN condicional secuencial para visualización de historias ", Jianfeng Gao de Microsoft Research, junto con Zhe Gan, Jingjing Liu y Yu Cheng de Microsoft Dynamics 365 AI Research, Yitong Li, David Carlson y Lawrence Carin de Duke University, Yelong Shen de Tencent AI Research y Yuexin Wu de la Universidad Carnegie Mellon van un paso más allá y proponen una nueva tarea, llamada Visualización de historias. Dado un párrafo de varias oraciones, se puede visualizar una historia completa, generando una secuencia de imágenes, una para cada oración. Esta es una tarea desafiante, ya que el robot de dibujo no solo debe imaginar un escenario que se ajuste a la historia, modelar las interacciones entre los diferentes personajes que aparecen en la historia, sino que también debe ser capaz de mantener la consistencia global en escenas y personajes dinámicos. Este desafío no ha sido abordado por ningún método de generación de imágenes o videos.
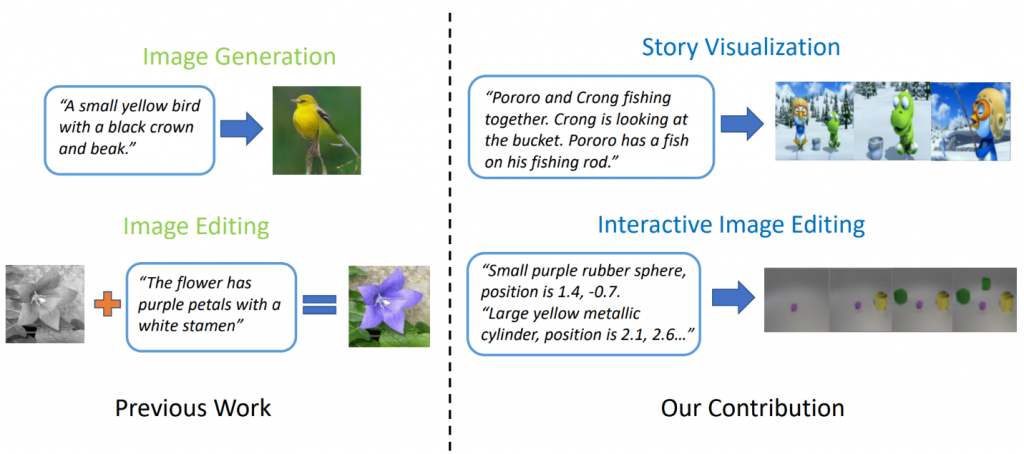
Figura 2: Visualización de la historia vs. Generación simple de imágenes.
Los investigadores crearon un nuevo modelo de generación de secuencia de historia a imagen, StoryGAN, basado en el marco secuencial condicional GAN. Este modelo es único porque consiste en un codificador de contexto profundo que rastrea dinámicamente el flujo de la historia y dos discriminadores en los niveles de la historia y la imagen para mejorar la calidad de la imagen y la consistencia de las secuencias generadas. StoryGAN también puede extenderse naturalmente para la edición interactiva de imágenes, donde una imagen de entrada puede editarse secuencialmente según las instrucciones del texto. En este caso, una secuencia de instrucciones para el usuario servirá como entrada de "historia". En consecuencia, los investigadores modificaron los conjuntos de datos existentes para crear los conjuntos de datos CLEVR-SV y Pororo-SV, como se muestra en la Figura 2.
Aplicaciones prácticas: una historia real
La tecnología de generación de texto a imagen podría encontrar aplicaciones prácticas que actúen como una especie de asistente de boceto para pintores y diseñadores de interiores, o como una herramienta para la edición de fotos activada por voz. Con más potencia informática, los investigadores imaginan la tecnología que genera películas animadas basadas en guiones, aumentando el trabajo que hacen los cineastas animados al eliminar parte del trabajo manual involucrado.
Por ahora, las imágenes generadas aún están lejos de ser realistas. Los objetos individuales casi siempre revelan fallas, como caras borrosas o autobuses con formas distorsionadas. Estos defectos son una clara indicación de que una computadora, no un humano, creó las imágenes. Sin embargo, la calidad de las imágenes ObjGAN es significativamente mejor que las imágenes GAN mejores de su clase y sirven como un hito en el camino hacia una inteligencia genérica, similar a la humana, que aumenta las capacidades humanas.
Para que las IA y los humanos compartan el mismo mundo, cada uno debe tener una forma de interactuar con el otro. El lenguaje y la visión son las dos modalidades más importantes para que los humanos y las máquinas interactúen entre sí. La generación de texto a imagen es una tarea importante que promueve la investigación de inteligencia multimodal con visión del lenguaje.
Los investigadores que crearon este emocionante trabajo esperan compartir estos hallazgos con los asistentes a CVPR en Long Beach y escuchar lo que piensas. Mientras tanto, no dude en consultar su código de código abierto para ObjGAN y StoryGAN en GitHub