En el artículo, le diré cómo abordamos el problema de tolerancia a fallas de PostgreSQL, por qué esto se ha vuelto importante para nosotros y qué sucedió al final.
Tenemos un servicio altamente cargado: 2.5 millones de usuarios en todo el mundo, 50K + usuarios activos todos los días. Los servidores están ubicados en Amazone en una región de Irlanda: hay constantemente más de 100 servidores diferentes en funcionamiento, casi 50 de ellos con bases de datos.
Todo el backend es una gran aplicación Java monolítica con estado que mantiene una conexión websocket constante con el cliente. Con el trabajo simultáneo de varios usuarios en una placa, todos ven los cambios en tiempo real, porque registramos cada cambio en la base de datos. Tenemos aproximadamente 10K consultas por segundo a nuestras bases de datos. En la carga máxima en Redis, escribimos a 80-100K consultas por segundo.

¿Por qué cambiamos de Redis a PostgreSQL?
Inicialmente, nuestro servicio trabajó con Redis, un repositorio de valores clave que almacena todos los datos en la RAM del servidor.
Pros de Redis:
- Alta tasa de respuesta, como todo se almacena en la memoria;
- Conveniencia de copia de seguridad y replicación.
Contras Redis para nosotros:
- No hay transacciones reales. Intentamos simularlos a nivel de nuestra aplicación. Desafortunadamente, esto no siempre funcionó bien y requería escribir código muy complejo.
- La cantidad de datos está limitada por la cantidad de memoria. A medida que aumenta la cantidad de datos, la memoria crecerá y, al final, nos toparemos con las características de la instancia seleccionada, lo que en AWS requiere detener nuestro servicio para cambiar el tipo de instancia.
- Es necesario mantener constantemente una baja latencia, ya que Tenemos una gran cantidad de solicitudes. El nivel de retraso óptimo para nosotros es de 17-20 ms. A un nivel de 30-40 ms, obtenemos respuestas largas a las solicitudes de nuestra aplicación y la degradación del servicio. Desafortunadamente, esto sucedió con nosotros en septiembre de 2018, cuando una de las instancias de Redis por alguna razón recibió una latencia 2 veces mayor de lo habitual. Para resolver el problema, detuvimos el servicio a mitad del día por mantenimiento no programado y reemplazamos la instancia problemática de Redis.
- Es fácil obtener inconsistencias de datos incluso con errores menores en el código y luego pasar mucho tiempo escribiendo código para corregir estos datos.
Tomamos en cuenta las desventajas y nos dimos cuenta de que necesitamos pasar a algo más conveniente, con transacciones normales y menos dependencia de la latencia. Realicé un estudio, analicé muchas opciones y elegí PostgreSQL.
Nos hemos mudado a una nueva base de datos durante 1,5 años y solo hemos transferido una pequeña parte de los datos, por lo que ahora estamos trabajando simultáneamente con Redis y PostgreSQL. Más información sobre las etapas de mover y cambiar datos entre bases de datos está escrita en un
artículo de mi colega .
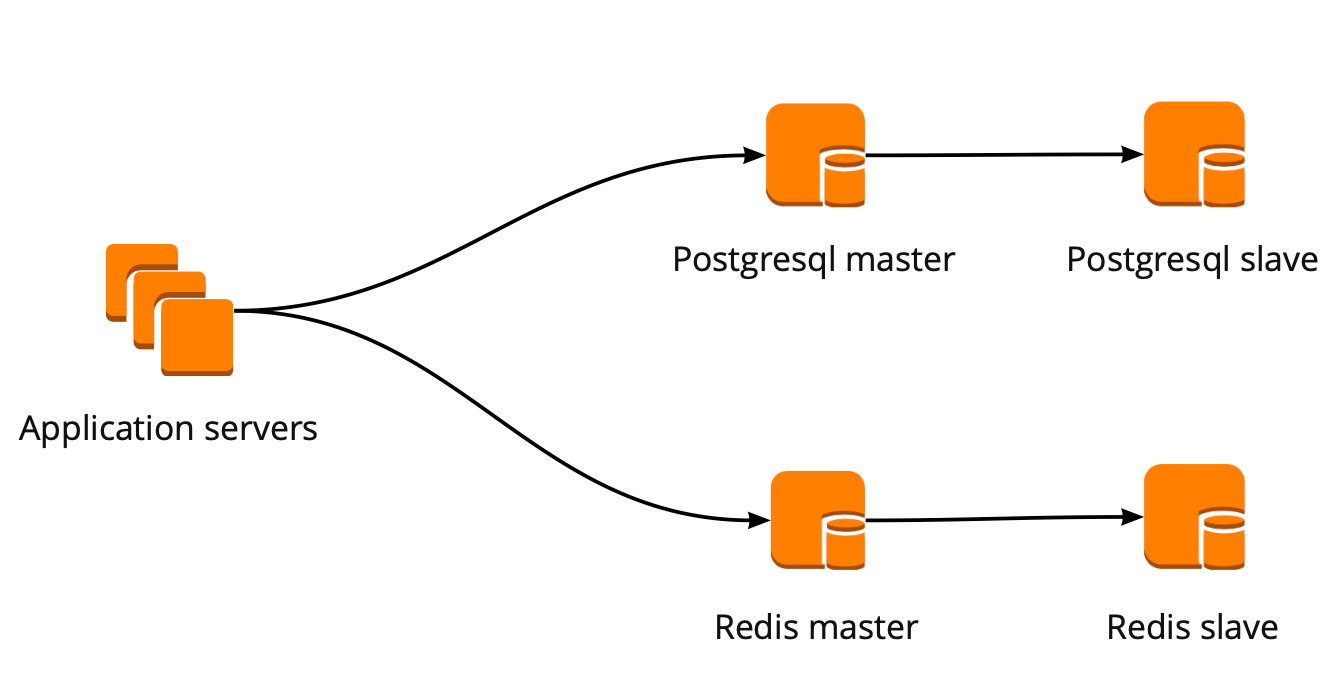
Cuando recién comenzamos a movernos, nuestra aplicación trabajó directamente con la base de datos y recurrió al asistente de Redis y PostgreSQL. El clúster PostgreSQL constaba de una réplica maestra y una réplica asíncrona. Así es como se veía el esquema de operación de la base de datos:
Despliegue de PgBouncer
Mientras nos movíamos, el producto también se desarrolló: aumentó la cantidad de usuarios y la cantidad de servidores que funcionaban con PostgreSQL, y comenzamos a perder conexiones. PostgreSQL crea un proceso separado para cada conexión y consume recursos. Puede aumentar el número de conexiones hasta cierto punto, de lo contrario existe la posibilidad de obtener una operación de base de datos no óptima. La opción ideal en esta situación sería la elección de un administrador de conexión que se pararía frente a la base.
Teníamos dos opciones para el administrador de conexión: Pgpool y PgBouncer. Pero el primero no admite el modo transaccional de trabajar con la base de datos, por lo que elegimos PgBouncer.
Hemos configurado el siguiente esquema de trabajo: nuestra aplicación accede a un PgBouncer, seguido de Masters PostgreSQL, y detrás de cada maestro, una réplica con replicación asincrónica.

Al mismo tiempo, no pudimos almacenar la cantidad total de datos en PostgreSQL, y la velocidad de trabajar con la base de datos fue importante para nosotros, por lo que comenzamos a compartir PostgreSQL a nivel de aplicación. El esquema descrito anteriormente es relativamente conveniente para esto: al agregar un nuevo fragmento de PostgreSQL, es suficiente para actualizar la configuración de PgBouncer y la aplicación puede trabajar inmediatamente con el nuevo fragmento.
PgBouncer Fault Tolerance
Este esquema funcionó hasta que la única instancia de PgBouncer murió. Estamos ubicados en AWS, donde todas las instancias se ejecutan en hardware que muere periódicamente. En tales casos, la instancia simplemente se mueve al nuevo hardware y funciona nuevamente. Esto sucedió con PgBouncer, pero no estuvo disponible. El resultado de esta caída fue la inaccesibilidad de nuestro servicio durante 25 minutos. AWS recomienda el uso de redundancia en el lado del usuario para tales situaciones, que no se implementó con nosotros en ese momento.
Después de eso, pensamos seriamente en la tolerancia a fallas de los clústeres PgBouncer y PostgreSQL, porque una situación similar podría ocurrir nuevamente con cualquier instancia en nuestra cuenta de AWS.
Creamos el esquema de tolerancia a fallos PgBouncer de la siguiente manera: todos los servidores de aplicaciones acceden al equilibrador de carga de red, detrás del cual hay dos PgBouncer. Cada uno de los PgBouncer mira el mismo PostgreSQL maestro de cada fragmento. Si la instancia de AWS falla nuevamente, todo el tráfico se redirige a través de otro PgBouncer. Tolerancia a fallos Network Load Balancer proporciona AWS.
Este esquema le permite agregar fácilmente nuevos servidores PgBouncer.

Crear un clúster de conmutación por error de PostgreSQL
Al resolver este problema, consideramos diferentes opciones: failover auto-escrito, repmgr, AWS RDS, Patroni.
Escrituras autoescritas
Pueden monitorear el trabajo del maestro y, en caso de caída, promover la réplica al maestro y actualizar la configuración de PgBouncer.
Las ventajas de este enfoque son la máxima simplicidad, porque usted mismo escribe scripts y comprende exactamente cómo funcionan.
Contras:
- El maestro podría no morir; en cambio, podría ocurrir una falla en la red. La conmutación por error, sin saber esto, avanzará la réplica al maestro, y el viejo maestro continuará funcionando. Como resultado, obtenemos dos servidores en el rol de maestro y no sabemos cuál de ellos tiene los datos reales más recientes. Esta situación también se llama cerebro dividido;
- Nos quedamos sin una réplica. En nuestra configuración, el maestro y una réplica, después de cambiar la réplica, se mueve al maestro y ya no tenemos réplicas, por lo que debemos agregar manualmente una nueva réplica;
- Necesitamos monitoreo adicional de la operación de failover, mientras que tenemos 12 fragmentos PostgreSQL, lo que significa que debemos monitorear 12 clústeres. Si aumenta el número de fragmentos, debe recordar actualizar la conmutación por error.
La conmutación por error autoescrita parece muy complicada y requiere un soporte no trivial. Con un solo clúster PostgreSQL, esta será la opción más fácil, pero no escala, por lo que no es adecuado para nosotros.
Repmgr
Administrador de replicación para clústeres de PostgreSQL, que puede administrar el funcionamiento de un clúster de PostgreSQL. Al mismo tiempo, no hay una conmutación por error automática "fuera de la caja", por lo que para el trabajo deberá escribir su propio "envoltorio" en la parte superior de la solución final. Por lo tanto, todo puede resultar aún más complicado que con secuencias de comandos autoescritas, por lo que ni siquiera probamos Repmgr.
AWS RDS
Admite todo lo que necesita para nosotros, sabe cómo hacer copias de seguridad y admite un grupo de conexiones. Tiene conmutación automática: a la muerte del maestro, la réplica se convierte en el nuevo maestro, y AWS cambia el registro dns al nuevo maestro, mientras que las réplicas pueden estar en diferentes AZ.
Las desventajas incluyen la falta de configuraciones sutiles. Como ejemplo de ajuste: en nuestras instancias hay restricciones para las conexiones tcp, que, desafortunadamente, no se pueden hacer en RDS:
net.ipv4.tcp_keepalive_time=10 net.ipv4.tcp_keepalive_intvl=1 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_retries2=3
Además, el precio de AWS RDS es casi dos veces más alto que el precio de la instancia regular, que fue la razón principal para rechazar esta decisión.
Patroni
Esta es una plantilla de Python para administrar PostgreSQL con buena documentación, failover automático y código fuente de github.
Pros de Patroni:
- Cada parámetro de configuración está pintado, está claro cómo funciona;
- La conmutación por error automática funciona de fábrica;
- Está escrito en python, y dado que nosotros mismos escribimos mucho en python, será más fácil para nosotros lidiar con los problemas y, posiblemente, incluso ayudar al desarrollo del proyecto;
- Controla completamente PostgreSQL, le permite cambiar la configuración en todos los nodos del clúster a la vez, y si se requiere reiniciar el clúster para aplicar la nueva configuración, esto se puede hacer nuevamente usando Patroni.
Contras:
- De la documentación no está claro cómo trabajar con PgBouncer. Aunque es difícil llamarlo un menos, porque la tarea de Patroni es administrar PostgreSQL, y cómo van a ser las conexiones con Patroni es nuestro problema;
- Hay pocos ejemplos de implementación de Patroni en grandes volúmenes, mientras que muchos ejemplos de implementación desde cero.
Como resultado, para crear un clúster de conmutación por error, elegimos Patroni.
Proceso de Implementación Patroni
Antes de Patroni, teníamos 12 fragmentos de PostgreSQL en configuración, un maestro y una réplica con replicación asincrónica. Los servidores de aplicaciones accedieron a las bases de datos a través del Network Load Balancer, detrás del cual había dos instancias con PgBouncer, y detrás de ellos estaban todos los servidores PostgreSQL.
Para implementar Patroni, necesitábamos seleccionar un repositorio de configuración de clúster distribuido. Patroni trabaja con sistemas de almacenamiento de configuración distribuida como etcd, Zookeeper, Consul. Solo tenemos un clúster de cónsul completo en prod que funciona en conjunto con Vault y ya no lo usamos. Una gran razón para comenzar a usar Consul para el propósito previsto.
Cómo trabaja Patroni con el cónsul
Tenemos un grupo Cónsul, que consta de tres nodos, y un grupo Patroni, que consiste en un líder y una réplica (en Patroni, un maestro se llama líder del grupo, y los esclavos se llaman réplicas). Cada instancia de un clúster Patroni envía constantemente información de estado del clúster al cónsul. Por lo tanto, desde Cónsul siempre puede averiguar la configuración actual del clúster Patroni y quién es el líder en este momento.

Para conectar Patroni a Consul, es suficiente estudiar la documentación oficial, que dice que debe especificar el host en formato http o https, dependiendo de cómo trabajemos con Consul, y el esquema de conexión, opcionalmente:
host: the host:port for the Consul endpoint, in format: http(s)://host:port scheme: (optional) http or https, defaults to http
Parece simple, pero aquí comienzan las trampas. Con Consul estamos trabajando en una conexión segura a través de https y nuestra configuración de conexión se verá así:
consul: host: https://server.production.consul:8080 verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Pero eso no funciona. Al principio, Patroni no puede conectarse con el cónsul, porque de todos modos intenta seguir http.
El código fuente de Patroni ayudó a resolver el problema. Lo bueno es que está escrito en python. Resulta que el parámetro del host no se analiza en absoluto, y el protocolo debe especificarse en el esquema. Aquí está el bloque de configuración de trabajo para trabajar con Consul con nosotros:
consul: host: server.production.consul:8080 scheme: https verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Cónsul-plantilla
Por lo tanto, hemos elegido el almacenamiento para una configuración. Ahora debe comprender cómo PgBouncer cambiará su configuración al cambiar el líder en el clúster Patroni. La documentación no responde a esta pregunta, porque allí, en principio, no se describe el trabajo con PgBouncer.
En busca de una solución, encontramos un artículo (no recuerdo el nombre, desafortunadamente), donde estaba escrito que la plantilla de Cónsul ayudó mucho a conectar a PgBouncer y Patroni. Esto nos llevó a estudiar el trabajo de la plantilla Consul.
Resultó que la plantilla de Consul supervisa constantemente la configuración del clúster PostgreSQL en Consul. Cuando el líder cambia, actualiza la configuración de PgBouncer y envía un comando para reiniciarlo.
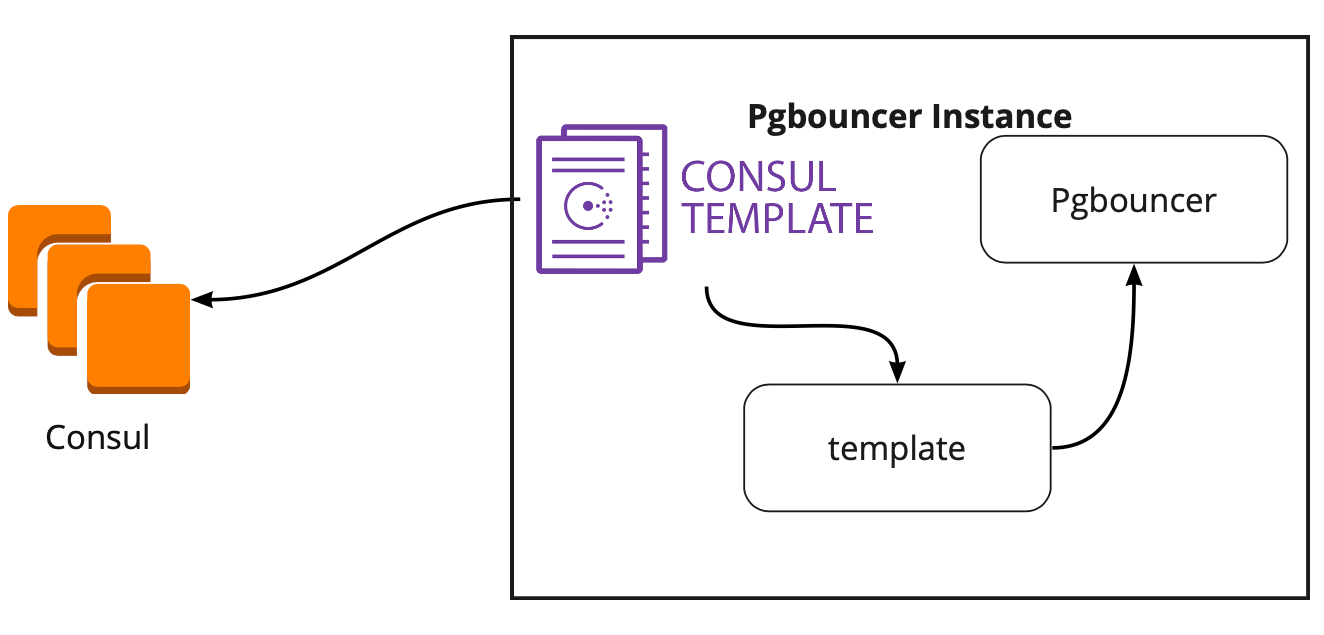
La gran ventaja de la plantilla es que se almacena como código, por lo que al agregar un nuevo fragmento, es suficiente realizar una nueva confirmación y actualizar la plantilla en modo automático, lo que respalda el principio de Infraestructura como código.
Nueva arquitectura con Patroni
Como resultado, obtuvimos este esquema de trabajo:

Todos los servidores de aplicaciones acceden al equilibrador → PgBouncer de dos instancias están detrás de él → en cada instancia se lanza una plantilla onsul, que monitorea el estado de cada clúster Patroni y monitorea la relevancia de la configuración de PgBouncer, que envía solicitudes al líder actual de cada clúster.
Prueba manual
Antes de iniciar el programa, lanzamos este circuito en un entorno de prueba pequeño y verificamos el funcionamiento de la conmutación automática. Abrieron el tablero, movieron la pegatina y en ese momento "mataron" al líder del grupo. En AWS, simplemente apague la instancia a través de la consola.

La pegatina regresó en 10-20 segundos, y luego nuevamente comenzó a moverse normalmente. Esto significa que el clúster Patroni funcionó correctamente: cambió el líder, envió la información al Cónsul y la plantilla del Cónsul inmediatamente recogió esta información, reemplazó la configuración de PgBouncer y envió el comando para recargar.
¿Cómo sobrevivir bajo una carga alta y mantener un tiempo de inactividad mínimo?
¡Todo funciona muy bien! Pero surgen nuevas preguntas: ¿Cómo funcionará bajo alta carga? ¿Cómo llevar todo de forma rápida y segura a producción?
El entorno de prueba en el que realizamos pruebas de carga nos ayuda a responder la primera pregunta. Es completamente idéntico a la producción en arquitectura y ha generado datos de prueba, que son aproximadamente iguales en volumen a la producción. Decidimos simplemente "matar" a uno de los asistentes de PostgreSQL durante la prueba y ver qué sucede. Pero antes de eso, es importante verificar el desplazamiento automático, ya que en este entorno tenemos varios fragmentos PostgreSQL, por lo que obtendremos excelentes pruebas de los scripts de configuración antes de vender.
Ambas tareas parecen ambiciosas, pero tenemos PostgreSQL 9.6. ¿Tal vez vamos a actualizar inmediatamente a 11.2?
Decidimos hacer esto en 2 etapas: primero actualice a 11.2, luego inicie Patroni.
Actualización de PostgreSQL
Para actualizar rápidamente la versión de PostgreSQL, debe usar la opción
-k , que crea un enlace duro en el disco y no es necesario copiar sus datos. En bases de 300-400 GB, la actualización lleva 1 segundo.
Tenemos muchos fragmentos, por lo que la actualización debe hacerse automáticamente. Para hacer esto, escribimos el libro de jugadas Ansible, que realiza todo el proceso de actualización para nosotros:
/usr/lib/postgresql/11/bin/pg_upgrade \ <b>--link \</b> --old-datadir='' --new-datadir='' \ --old-bindir='' --new-bindir='' \ --old-options=' -c config_file=' \ --new-options=' -c config_file='
Es importante tener en cuenta aquí que antes de comenzar la actualización, es necesario ejecutarlo con el parámetro
--check para estar seguro de la posibilidad de una actualización. Nuestro script también hace la sustitución de configuraciones para la actualización. El guión que completamos en 30 segundos, este es un excelente resultado.
Lanzar Patroni
Para resolver el segundo problema, solo mira la configuración de Patroni. En el repositorio oficial hay una configuración de ejemplo con initdb, que se encarga de inicializar una nueva base de datos cuando se inicia Patroni por primera vez. Pero como tenemos una base de datos preparada, acabamos de eliminar esta sección de la configuración.
Cuando comenzamos a instalar Patroni en un clúster PostgreSQL listo para usar y ejecutarlo, nos enfrentamos a un nuevo problema: ambos servidores comenzaron como líderes. Patroni no sabe nada sobre el estado inicial del clúster e intenta iniciar ambos servidores como dos clústeres separados con el mismo nombre. Para resolver este problema, elimine el directorio de datos en el esclavo:
rm -rf /var/lib/postgresql/
¡Esto debe hacerse solo en esclavo!Al conectar una réplica limpia, Patroni crea un líder de respaldo base y lo restaura a la réplica, y luego se pone al día con el estado actual mediante registros de wal.
Otra dificultad que encontramos es que todos los clústeres de PostgreSQL se denominan main por defecto. Cuando cada grupo no sabe nada del otro, esto es normal. Pero cuando desea utilizar Patroni, todos los clústeres deben tener un nombre único. La solución es cambiar el nombre del clúster en la configuración de PostgreSQL.
Prueba de carga
Lanzamos una prueba que simula el trabajo de los usuarios en los tableros. Cuando la carga alcanzó nuestro valor diario promedio, repetimos exactamente la misma prueba, apagamos una instancia con el líder PostgreSQL. La conmutación por error automática funcionó como esperábamos: Patroni cambió el líder, Consul-template actualizó la configuración de PgBouncer y envió el comando para recargar. De acuerdo con nuestros gráficos en Grafana, estaba claro que hay demoras de 20-30 segundos y una pequeña cantidad de errores de los servidores relacionados con la conexión a la base de datos. Esta es una situación normal, tales valores son válidos para nuestra conmutación por error y definitivamente mejores que el tiempo de inactividad del servicio.
La producción de Patroni a la producción.
Como resultado, obtuvimos el siguiente plan:
- Implemente la plantilla Consul en el servidor PgBouncer y ejecútela;
- PostgreSQL actualiza a la versión 11.2;
- Cambio de nombre del clúster;
- Iniciando un grupo Patroni.
Al mismo tiempo, nuestro esquema le permite hacer el primer elemento en casi cualquier momento, podemos turnarnos para eliminar cada PgBouncer del trabajo y ejecutar una implementación en él y lanzar la plantilla de cónsul. Entonces lo hicimos.
Para un rodaje rápido, utilizamos Ansible, ya que ya verificamos todo el libro de jugadas en un entorno de prueba, y el tiempo de ejecución del guión completo fue de 1.5 a 2 minutos por cada fragmento. Podríamos desplegar todo alternativamente para cada fragmento sin detener nuestro servicio, pero tendríamos que apagar cada PostgreSQL durante unos minutos. En este caso, los usuarios cuyos datos se encuentran en este fragmento no podrían funcionar completamente en este momento, y esto es inaceptable para nosotros.
La solución a esta situación fue el mantenimiento planificado, que se realiza cada 3 meses. Esta es una ventana para el trabajo programado cuando apagamos completamente nuestro servicio y actualizamos las instancias de la base de datos. Faltaba una semana para la próxima ventana, y decidimos esperar y prepararnos más. Durante la espera, también nos aseguramos: para cada fragmento de PostgreSQL levantamos una réplica de repuesto en caso de falla para guardar los últimos datos, y agregamos una nueva instancia para cada fragmento, que debería convertirse en una nueva réplica en el clúster Patroni para no ejecutar un comando para eliminar datos . Todo esto ayudó a minimizar el riesgo de error.

Reiniciamos nuestro servicio, todo funcionó como debería, los usuarios continuaron trabajando, pero en los gráficos notamos una carga anormalmente alta en el servidor Consul.
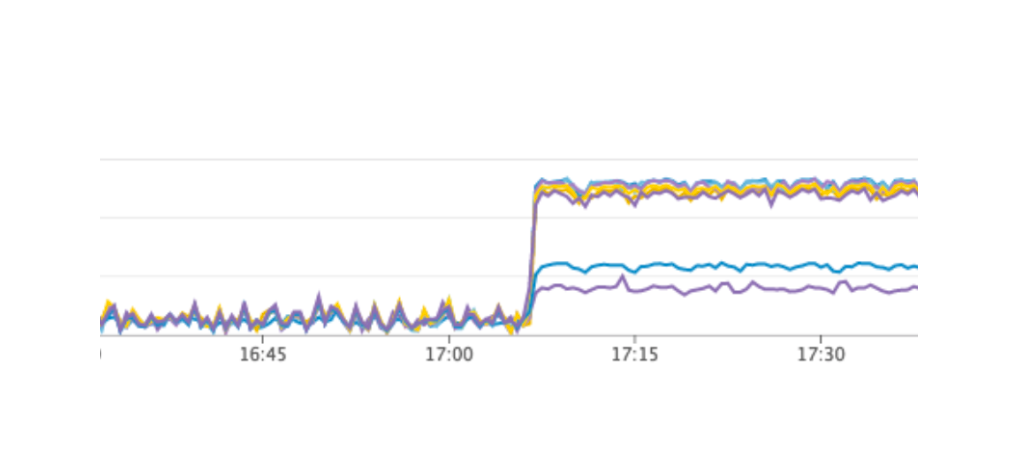
¿Por qué no lo vimos en el entorno de prueba? Este problema ilustra muy bien que es necesario seguir el principio de Infraestructura como código y refinar toda la infraestructura, comenzando con entornos de prueba y terminando con la producción. De lo contrario, es muy fácil obtener el tipo de problema que tenemos. Que paso Consul primero apareció en producción y luego en entornos de prueba, como resultado, en entornos de prueba, la versión de Consul fue más alta que en producción. Solo en una de las versiones, se resolvió una fuga de CPU al trabajar con consul-template. Por lo tanto, acabamos de actualizar Consul, resolviendo así el problema.
Reiniciar el clúster Patroni
Sin embargo, tenemos un nuevo problema del que ni siquiera éramos conscientes. Al actualizar Consul, simplemente eliminamos el nodo Consul del clúster utilizando el comando cónsul leave → Patroni se conecta a otro servidor Consul → todo funciona. Pero cuando llegamos a la última instancia del grupo Cónsul y le enviamos el comando de abandono, todos los grupos Patroni simplemente se reiniciaron, y en los registros vimos el siguiente error:
ERROR: get_cluster Traceback (most recent call last): ... RetryFailedError: 'Exceeded retry deadline' ERROR: Error communicating with DCS <b>LOG: database system is shut down</b>
El clúster Patroni no pudo obtener información sobre su clúster y se reinició.
Para encontrar una solución, contactamos a los autores de Patroni a través del número en github. Sugirieron mejoras en nuestros archivos de configuración:
consul: consul.checks: [] bootstrap: dcs: retry_timeout: 8
Pudimos repetir el problema en un entorno de prueba y probamos estos parámetros allí, pero, desafortunadamente, no funcionaron.
El problema aún no se ha resuelto. Planeamos probar las siguientes soluciones:
- Utilice el Cónsul-agente en cada instancia del clúster Patroni;
- Soluciona el problema en el código.
Entendemos dónde se produjo el error: el problema probablemente sea usar el tiempo de espera predeterminado, que no se anula a través del archivo de configuración. Cuando se elimina el último servidor Consul del clúster, todo el clúster Consul se congela durante más de un segundo, debido a esto Patroni no puede obtener el estado del clúster y reinicia completamente el clúster completo.
Afortunadamente, no encontramos más errores.
Resultados de usar Patroni
Después del exitoso lanzamiento de Patroni, agregamos una réplica adicional en cada clúster. Ahora en cada grupo hay una apariencia de quórum: un líder y dos réplicas, para asegurarse contra el caso de cerebro dividido al cambiar.
Patroni ha estado trabajando en producción durante más de tres meses. Durante este tiempo, ya ha logrado ayudarnos. Recientemente, el líder de uno de los clústeres murió en AWS, la conmutación por error automática funcionó y los usuarios continuaron trabajando. Patroni completó su tarea principal.
Un pequeño resumen del uso de Patroni:- La conveniencia del cambio de una configuración. Es suficiente cambiar la configuración en una instancia y se colocará sobre todo el clúster. Si se requiere un reinicio para aplicar la nueva configuración, Patroni lo informará. Patroni puede reiniciar todo el clúster con un solo comando, lo que también es muy conveniente.
- La conmutación por error automática funciona y ya ha logrado ayudarnos.
- Actualización de PostgreSQL sin tiempo de inactividad de la aplicación. Primero debe actualizar las réplicas a la nueva versión, luego cambiar el líder en el clúster Patroni y actualizar el líder anterior. En este caso, se realizan las pruebas necesarias de conmutación por error automática.