Los usuarios de ClickHouse saben que su principal ventaja es la alta velocidad de procesamiento de consultas analíticas. Pero, ¿cómo podemos hacer tales declaraciones? Esto debería estar respaldado por pruebas de rendimiento confiables. Hablaremos de ellos hoy.
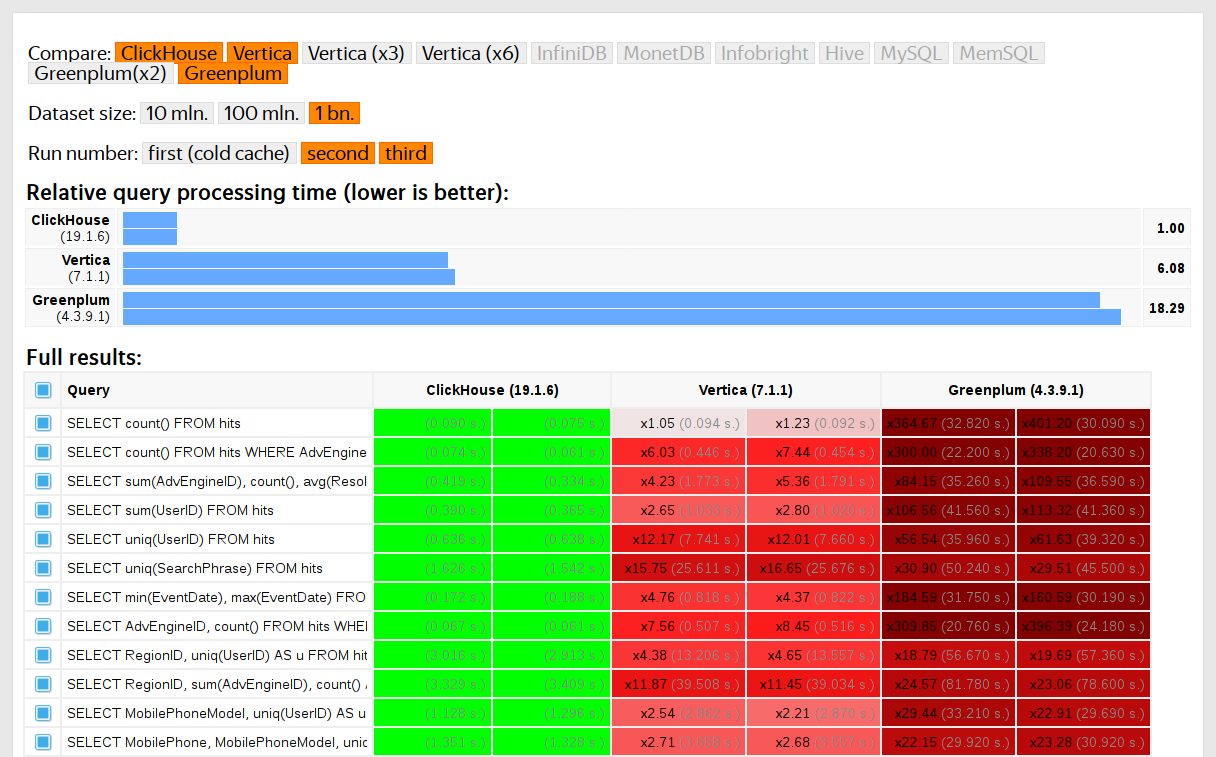
Comenzamos a realizar tales pruebas en 2013, mucho antes de que el producto estuviera disponible en código abierto. Como ahora, estábamos más interesados en la velocidad del servicio de datos Yandex.Metrica. Ya hemos almacenado datos en ClickHouse desde enero de 2009. Parte de los datos se ha escrito en la base de datos desde 2012, y parte, se ha
convertido de
OLAPServer y Metrage , estructuras de datos que se utilizaron en Yandex.Metrica antes. Por lo tanto, para las pruebas, tomamos el primer subconjunto disponible de mil millones de datos de páginas vistas. Todavía no había consultas en Metric, y se nos ocurrieron consultas que nos resultaron más interesantes (todo tipo de filtrado, agregación y clasificación).
ClickHouse se probó en comparación con sistemas similares, por ejemplo, Vertica y MonetDB. Para ser sincero, fue realizado por un empleado que no había sido previamente desarrollador de ClickHouse, y los casos particulares en el código no fueron optimizados para obtener resultados. Del mismo modo, obtuvimos un conjunto de datos para pruebas funcionales.
Después de que ClickHouse se uniera al código abierto en 2016, hubo más preguntas para las pruebas.
Desventajas de las pruebas en datos propietarios
Pruebas de rendimiento:
- No son reproducibles desde el exterior, porque su lanzamiento requiere datos cerrados que no se pueden publicar. Por la misma razón, algunas pruebas funcionales no están disponibles para usuarios externos.
- No te desarrolles. Existe la necesidad de una expansión significativa de su conjunto, de modo que sea posible verificar de manera aislada los cambios en la velocidad de las partes individuales del sistema.
- No se ejecutan de manera comprometida para solicitudes de grupo, los desarrolladores externos no pueden verificar su código para la regresión del rendimiento.
Puede resolver estos problemas: descarte las pruebas antiguas y cree otras nuevas basadas en datos abiertos. Entre los datos abiertos, puede tomar
datos sobre vuelos a los EE .
UU. ,
Viajes en taxi en Nueva York o utilizar puntos de referencia TPC-H, TPC-DS,
Star Schema Benchmark . El inconveniente es que estos datos están lejos de los datos de Yandex.Metrica, y me gustaría guardar las solicitudes de prueba.
Es importante utilizar datos reales.
Debe probar el rendimiento del servicio solo en datos reales de producción. Veamos algunos ejemplos.
Ejemplo 1Suponga que llena una base de datos con números pseudoaleatorios distribuidos uniformemente. En este caso, la compresión de datos no funcionará. Pero la compresión de datos es una propiedad importante para los DBMS analíticos. Elegir el algoritmo de compresión correcto y la forma correcta de integrarlo en el sistema es una tarea no trivial en la que no hay una solución correcta, porque la compresión de datos requiere un compromiso entre la velocidad de compresión y descompresión y la relación de compresión potencial. Los sistemas que no saben cómo comprimir datos pierden garantía. Pero si usamos números pseudoaleatorios distribuidos uniformemente para las pruebas, este factor no se considera y todos los demás resultados se distorsionarán.
Conclusión: los datos de prueba deben tener una relación de compresión realista.
Sobre la optimización de los algoritmos de compresión de datos en ClickHouse, hablé en una
publicación anterior .
Ejemplo 2Interesémonos en la velocidad de la consulta SQL:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Esta es una solicitud típica para Yandex.Metrica. ¿Qué es importante para su velocidad?
- ¿Cómo se realiza GROUP BY ?
- Qué estructura de datos se utiliza para calcular la función agregada uniq.
- Cuántos RegionID diferentes son y cuánta RAM requiere cada estado de la función uniq.
Pero también es muy importante que la cantidad de datos para diferentes regiones se distribuya de manera desigual. (Probablemente, se distribuye de acuerdo con la ley de potencia. Construí un gráfico en la escala log-log, pero no estoy seguro). Y si es así, es importante para nosotros que los estados de la función agregada uniq con un pequeño número de valores usen poca memoria. Cuando hay muchas claves de agregación diferentes, el recuento va a unidades de bytes. ¿Cómo obtener los datos generados que tienen todas estas propiedades? Por supuesto, es mejor usar datos reales.
Muchos DBMS implementan una estructura de datos HyperLogLog para el cálculo aproximado de COUNT (DISTINCT), pero todos funcionan relativamente mal porque esta estructura de datos utiliza una cantidad fija de memoria. Y ClickHouse tiene una función que utiliza una
combinación de tres estructuras de datos diferentes , dependiendo del tamaño del conjunto.
Conclusión: los datos de prueba deben representar las propiedades de la distribución de valores en los datos: cardinalidad (el número de valores en las columnas) y cardinalidad mutua de varias columnas diferentes.
Ejemplo 3Bueno, probemos el rendimiento no del DBMS analítico ClickHouse, sino de algo más simple, por ejemplo, tablas hash. Para las tablas hash, elegir la función hash correcta es muy importante. Para std :: unordered_map, es un poco menos importante, porque es una tabla hash basada en cadena y se utiliza un número primo como el tamaño de la matriz. En la implementación estándar de la biblioteca en gcc y clang, se utiliza una función hash trivial como la función hash predeterminada para los tipos numéricos. Pero std :: unordered_map no es la mejor opción cuando queremos obtener la máxima velocidad. Cuando se usan tablas hash de direccionamiento abierto, la elección correcta de la función hash se convierte en un factor decisivo, y no podemos usar la función hash trivial.
Es fácil encontrar pruebas de rendimiento de tablas hash en datos aleatorios, sin tener en cuenta las funciones hash utilizadas. También es fácil encontrar pruebas de función hash con énfasis en la velocidad de cálculo y algunos criterios de calidad, sin embargo, de forma aislada de las estructuras de datos utilizadas. Pero el hecho es que las tablas hash y HyperLogLog requieren diferentes criterios de calidad para las funciones hash.
Lea más sobre esto en el informe
"Cómo se organizan las tablas hash en ClickHouse" . Está un poco desactualizado ya que no considera las
tablas suizas .
Desafío
Queremos obtener los datos para las pruebas de rendimiento por estructura, igual que los datos de Yandex.Metrica, para los que se almacenan todas las propiedades importantes para los puntos de referencia, pero para que no queden rastros de visitantes reales del sitio en estos datos. Es decir, los datos deben ser anonimizados y se debe almacenar lo siguiente:
- relaciones de compresión
- cardinalidad (número de valores diferentes),
- cardinalidades mutuas de varias columnas diferentes,
- propiedades de las distribuciones de probabilidad con las que puede simular datos (por ejemplo, si creemos que las regiones se distribuyen de acuerdo con una ley de potencia, entonces el exponente - parámetro de distribución - para datos artificiales debería ser casi igual que para los reales).
¿Y qué se necesita para que los datos tengan una relación de compresión similar? Por ejemplo, si se usa LZ4, entonces las subcadenas en los datos binarios deben repetirse aproximadamente a las mismas distancias y las repeticiones deben tener aproximadamente la misma longitud. Para ZSTD, se agrega una coincidencia de entropía de bytes.
El objetivo máximo: hacer que una herramienta esté disponible para personas externas, con la que todos puedan anonimizar su conjunto de datos para su publicación. Para que podamos depurar y probar el rendimiento en los datos de otras personas de forma similar a los datos de producción. Y me gustaría que fuera interesante ver los datos generados.
Esta es una declaración informal del problema. Sin embargo, nadie iba a dar una declaración formal.
Intentos de resolver
La importancia de esta tarea no debe exagerarse para nosotros. De hecho, nunca estuvo en los planes y nadie lo iba a hacer. Simplemente no perdí la esperanza de que algo surgiría solo, y de repente tendría un buen humor y muchas cosas que podrían posponerse hasta más tarde.
Modelos probabilísticos explícitos
La primera idea es seleccionar una familia de distribuciones de probabilidad que la modele para cada columna de la tabla. Luego, en función de las estadísticas de los datos, seleccione los parámetros de ajuste del modelo y genere nuevos datos utilizando la distribución seleccionada. Puede usar un generador de números pseudoaleatorio con una semilla predefinida para obtener un resultado reproducible.
Para los campos de texto, puede usar las cadenas de Markov, un modelo comprensible para el que puede realizar una implementación efectiva.
Es cierto que se requieren algunos trucos:
- Queremos preservar la continuidad de las series de tiempo, lo que significa que para algunos tipos de datos es necesario modelar no el valor en sí, sino la diferencia entre los vecinos.
- Para simular la cardinalidad condicional de las columnas (por ejemplo, que generalmente hay pocas direcciones IP por identificador de visitante), también deberá anotar explícitamente las dependencias entre las columnas (por ejemplo, para generar una dirección IP, se utiliza un hash del identificador de visitante, pero también se agregan algunos otros datos pseudoaleatorios).
- No está claro cómo expresar la dependencia de que un visitante aproximadamente al mismo tiempo a menudo visita URL con dominios coincidentes.
Todo esto se presenta en forma de un programa en el que todas las distribuciones y dependencias están codificadas, el llamado "script C ++". Sin embargo, los modelos de Markov todavía se calculan a partir de la suma de estadísticas, suavizado y rugosidad con ruido. Comencé a escribir este script, pero por alguna razón, después de escribir explícitamente el modelo para diez columnas, de repente se volvió insoportablemente aburrido. Y en la tabla de éxitos en Yandex. Métrica en 2012 había más de 100 columnas.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Este enfoque de la tarea fue un fracaso. Si me acercara a ella más diligentemente, seguro que el guión habría sido escrito.
Ventajas:
Desventajas
- la complejidad de la implementación,
- La solución implementada es adecuada para un solo tipo de datos.
Y me gustaría una solución más general, para que pueda aplicarse no solo a los datos de Yandex.Metrica, sino también para ofuscar cualquier otro dato.
Sin embargo, las mejoras son posibles aquí. No puede seleccionar modelos manualmente, sino implementar un catálogo de modelos y elegir el mejor entre ellos (mejor ajuste + algún tipo de regularización). O tal vez pueda usar los modelos de Markov para todo tipo de campos, y no solo para el texto. Las dependencias entre los datos también se pueden entender automáticamente. Para hacer esto, debe calcular las
entropías relativas (cantidad relativa de información) entre las columnas, o más simplemente, las cardinalidades relativas (algo así como “cuántos valores A diferentes en promedio para un valor B fijo”) para cada par de columnas. Esto dejará en claro, por ejemplo, que URLDomain depende completamente de la URL, y no al revés.
Pero también rechacé esta idea, porque hay demasiadas opciones para lo que debe tenerse en cuenta, y tomará mucho tiempo escribirlo.
Redes neuronales
Ya dije lo importante que es esta tarea para nosotros. Nadie pensó siquiera en detenerse en su implementación. Afortunadamente, el colega Ivan Puzyrevsky luego trabajó como maestro en HSE y al mismo tiempo estaba desarrollando el núcleo de YT. Me preguntó si tenía alguna tarea interesante que pudiera ofrecerse a los estudiantes como tema de diploma. Le ofrecí este y me aseguró que era adecuado. Entonces le di esta tarea a una buena persona "de la calle": Sharif Anvardinov (la NDA está firmada para trabajar con datos).
Le contó todas sus ideas, pero lo más importante, explicó que el problema se puede resolver de cualquier manera. Y una buena opción sería usar esos enfoques que no entiendo en absoluto: por ejemplo, generar un volcado de datos de texto usando LSTM. Parecía alentador gracias al
artículo La efectividad irracional de las redes neuronales recurrentes , que luego me llamó la atención.
La primera característica de la tarea es que necesita generar datos estructurados, no solo texto. No era obvio si una red neuronal recurrente podría generar datos con la estructura deseada. Hay dos formas de resolver esto. El primero es usar modelos separados para generar la estructura y para el "relleno": la red neuronal solo debe generar valores. Pero esta opción fue pospuesta hasta más tarde, después de lo cual nunca lo hicieron. La segunda forma es simplemente generar un volcado de TSV como texto. La práctica ha demostrado que en el texto parte de las líneas no se corresponderá con la estructura, pero estas líneas se pueden tirar al cargar.
La segunda característica: una red neuronal recurrente genera una secuencia de datos, y las dependencias en los datos solo pueden seguir en el orden de esta secuencia. Pero en nuestros datos, tal vez el orden de las columnas se invierte con respecto a las dependencias entre ellas. No hicimos nada con esta función.
Hacia el verano, apareció el primer script de Python que generaba datos. A primera vista, la calidad de los datos es decente:
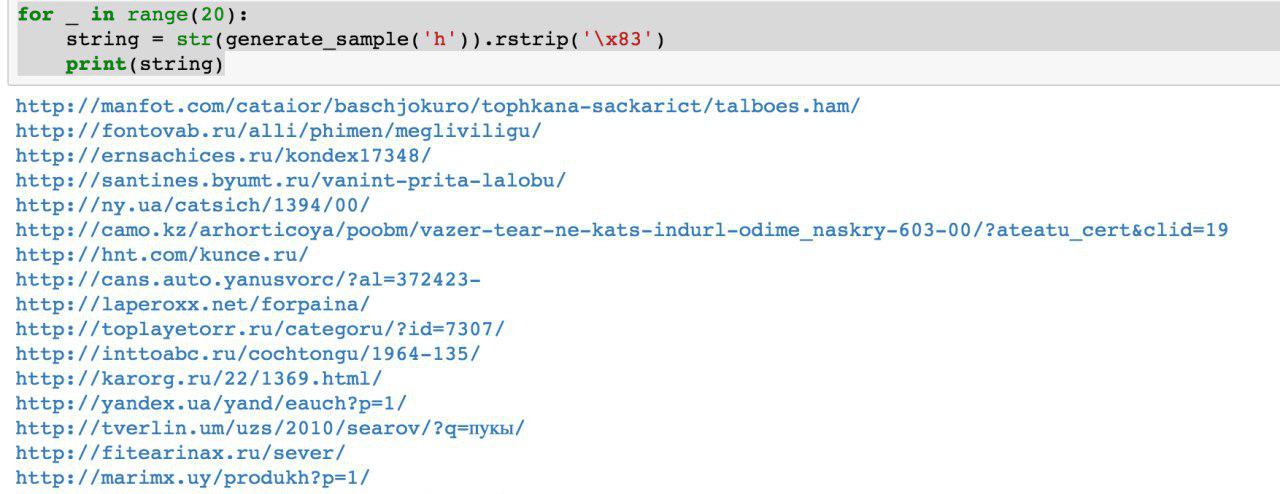
Es cierto que se revelaron dificultades:
- El tamaño del modelo es de aproximadamente un gigabyte. Y tratamos de crear un modelo para datos cuyo tamaño era del orden de varios gigabytes (para empezar). El hecho de que el modelo resultante sea tan grande suscita inquietud: de repente será posible obtener datos reales del mismo en el que se formó. Lo más probable es que no. Pero no entiendo el aprendizaje automático y las redes neuronales y no he leído el código Python de esta persona, entonces, ¿cómo puedo estar seguro? Luego hubo artículos sobre cómo comprimir redes neuronales sin perder calidad, pero esto se dejó sin implementación. Por un lado, esto no parece un problema: puede negarse a publicar el modelo y publicar solo los datos generados. Por otro lado, en el caso del reciclaje, los datos generados pueden contener alguna parte de los datos de origen.
- En una sola máquina con una CPU, la tasa de generación de datos es de aproximadamente 100 líneas por segundo. Teníamos una tarea: generar al menos mil millones de líneas. El cálculo mostró que esto no podía hacerse antes de la defensa del diploma. Y usar otro hardware no es práctico, porque tenía un objetivo: hacer que la herramienta de generación de datos esté disponible para un uso amplio.
Sharif trató de estudiar la calidad de los datos mediante la comparación de estadísticas. Por ejemplo, calculé la frecuencia con la que aparecen diferentes símbolos en la fuente y en los datos generados. El resultado fue sorprendente: los personajes más comunes son Ð y Ñ.
No se preocupe, defendió su diploma perfectamente, después de lo cual nos olvidamos de este trabajo.
Mutación de datos comprimidos
Suponga que la declaración del problema se reduce a un punto: necesita generar datos para los cuales las relaciones de compresión serán exactamente las mismas que los datos originales, mientras que los datos deben expandirse exactamente a la misma velocidad. Como hacerlo ¡Necesita editar bytes de datos comprimidos directamente! Entonces, el tamaño de los datos comprimidos no cambiará, pero los datos en sí lo harán. Sí, y todo funcionará rápidamente. Cuando apareció esta idea, inmediatamente quise implementarla, a pesar del hecho de que resuelve algún otro problema en lugar del original. Siempre pasa.
¿Cómo editar un archivo comprimido directamente? Supongamos que solo estamos interesados en LZ4. Los datos comprimidos con LZ4 constan de dos tipos de instrucciones:
- Literales: copie los siguientes N bytes tal como están.
- Coincidencia (coincidencia, la longitud mínima de repetición es 4): repita N bytes que estaban en el archivo a una distancia de M.
Datos de origen:
Hello world HelloDatos comprimidos (condicionalmente):
literals 12 "Hello world " match 5 12 .
En el archivo comprimido, deje la coincidencia como está, y en literales cambiaremos los valores de bytes. Como resultado, después de la descompresión, obtenemos un archivo en el que todas las secuencias repetidas de al menos 4 también se repiten, y se repiten a las mismas distancias, pero al mismo tiempo consisten en un conjunto diferente de bytes (en sentido figurado, no se tomó un solo byte del archivo original en el archivo modificado )
¿Pero cómo cambiar los bytes? Esto no es obvio porque, además de los tipos de columna, los datos también tienen su propia estructura interna implícita, que nos gustaría preservar. Por ejemplo, el texto a menudo se almacena en codificación UTF-8, y también queremos UTF-8 válido en los datos generados. Hice una simple heurística para satisfacer varias condiciones:
- bytes nulos y caracteres de control ASCII se almacenaron tal cual,
- persistió alguna puntuación,
- ASCII se tradujo a ASCII y, por lo demás, se guardó el bit más significativo (o puede escribir explícitamente un conjunto if para diferentes longitudes UTF-8). Entre una clase de bytes, se selecciona un nuevo valor de manera uniforme al azar;
- y también para guardar fragmentos de
https:// y similares, de lo contrario todo parece demasiado tonto.
La peculiaridad de este enfoque es que los datos iniciales en sí mismos actúan como un modelo para los datos, lo que significa que el modelo no se puede publicar. Le permite generar la cantidad de datos no más que el original. A modo de comparación, en enfoques anteriores era posible crear un modelo y generar una cantidad ilimitada de datos sobre la base.
Ejemplo para URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
El resultado me gustó: fue interesante mirar los datos. Pero aún así, algo estaba mal. Las URL todavía están estructuradas, pero en algunos lugares fue demasiado fácil adivinar yandex o avito. Hizo una heurística que a veces reorganiza algunos bytes en algunos lugares.
Otras consideraciones preocupadas. Por ejemplo, la información confidencial se puede representar en una columna de tipo FixedString en forma binaria y, por alguna razón, consiste en caracteres de control ASCII y puntuación, que decidí guardar. Y no considero los tipos de datos.
Otro problema: si los datos del tipo "longitud, valor" se almacenan en una columna (así es como se almacenan las columnas del tipo Cadena), ¿cómo garantizar que la longitud siga siendo correcta después de la mutación? Cuando traté de arreglarlo, la tarea inmediatamente se volvió poco interesante.
Permutaciones aleatorias
Pero el problema no está resuelto. Llevamos a cabo varios experimentos, y solo empeoró. Solo queda no hacer nada y leer páginas aleatorias en Internet, porque el estado de ánimo ya está echado a perder. Afortunadamente, en una de estas páginas había un
análisis del algoritmo para representar la escena de la muerte del protagonista en el juego Wolfenstein 3D.

Hermosa animación: la pantalla se llena de sangre. El artículo explica que esto es en realidad una permutación pseudoaleatoria. Permutación aleatoria: una transformación uno a uno de un conjunto seleccionada al azar. Es decir, la visualización de todo el conjunto en el que no se repiten los resultados para diferentes argumentos. En otras palabras, esta es una forma de iterar sobre todos los elementos de un conjunto en un orden aleatorio. Es un proceso que se muestra en la imagen: pintamos sobre cada píxel, seleccionados al azar de todos, sin repetición. Si solo escogiéramos un píxel aleatorio en cada paso, nos llevaría mucho tiempo pintar sobre el último.
El juego utiliza un algoritmo muy simple para la permutación pseudoaleatoria:
LFSR (registro de desplazamiento de retroalimentación lineal). Al igual que los generadores de números pseudoaleatorios, las permutaciones aleatorias, o más bien sus familias, parametrizadas por la clave, pueden ser criptográficamente fuertes; esto es exactamente lo que necesitamos para convertir los datos. Aunque puede haber detalles obvios. Por ejemplo, parece que el cifrado criptográficamente fuerte de N bytes a N bytes con una clave prefijada y un vector de inicialización puede usarse como una permutación pseudoaleatoria de muchas cadenas de N bytes. De hecho, tal transformación es uno a uno y parece aleatoria. Pero si usamos la misma transformación para todos nuestros datos, entonces el resultado puede estar sujeto a análisis, porque el mismo vector de inicialización y los valores clave se usan varias veces. Esto es similar al modo de cifrado de bloque del
Libro de códigos electrónico .
¿Cuáles son las formas de obtener una permutación pseudoaleatoria? Puede tomar transformaciones simples uno a uno y ensamblar una función bastante compleja a partir de ellas que se verá aleatoria. Permíteme darte un ejemplo de algunas de mis transformaciones individuales favoritas:
- multiplicación por un número impar (por ejemplo, un primo grande) en aritmética del complemento a dos,
- xor-shift:
x ^= x >> N , - CRC-N, donde N es el número de bits del argumento.
Entonces, por ejemplo, a partir de tres multiplicaciones y dos operaciones xor-shift, se
ensambla el finalizador
murmurhash . Esta operación es una permutación pseudoaleatoria. Pero por si acaso, observo que las funciones hash, incluso N bits en N bits, no tienen que ser mutuamente únicas.
O aquí hay otro
ejemplo interesante
de la teoría de números elementales del sitio de Jeff Preshing.
¿Cómo podemos usar permutaciones pseudoaleatorias para nuestra tarea? Puede convertir todos los campos numéricos usándolos. Entonces será posible preservar todas las cardinalidades y cardinalidades mutuas de todas las combinaciones de campos. Es decir, COUNT (DISTINCT) devolverá el mismo valor que antes de la conversión, y con cualquier GROUP BY.
Vale la pena señalar que la preservación de todas las cardinalidades es ligeramente contraria a la declaración del problema del anonimato de datos. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , ,
.
, . , 10, . ?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . Y así sucesivamente. .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c
Hackers News , .
Redis — . ,
.
. — , . , .
- :
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - . xor :
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
, F 4 , .
: , , — , , !
. , , , . :
- , , Electronic Codebook mode of operation;
- ( ) , , .
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
P( | ) = 0.9
P( | ) = 0.05
P( | ) = 0.01
.... ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
— . — , . , , — .@Mail.Ru — — - . ) — AUTO.ria.ua
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
https://www.yandex.ru/images/cats/?id=xxxxxx . , URL, , . :
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . - , 8 .
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ..., . :
- | . -
- — .: Lore - dfghf — . - ) 473682 -
- ! » - —
- ! » ,
- . c @Mail.Ru -
- , 2010 | .
- ! : 820 0000 ., -
- - DoramaTv.ru - . - ..
- . 2013 , -> 80 .
- - (. , ,
- . 5, 69, W* - ., , World of Tanks
- , . 2 @Mail.Ru
- , .
Resultado
, - , - . , . clickhouse obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
clickhouse obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse obfuscator --help
, . , ? , , . , , . , (
--help ) .
, .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzClickHouse. , ClickHouse .