Hola Habr! Mi nombre es Sasha y soy desarrollador de backend. En mi tiempo libre estudio ML y me divierto con los datos de hh.ru.
Este artículo trata sobre cómo nosotros, mediante el aprendizaje automático, automatizamos el proceso de asignación de tareas rutinarias para los evaluadores.
Hh.ru tiene un servicio interno para el que se crean tareas en Jira (se llaman HHS dentro de la empresa) si alguien no trabaja o está trabajando incorrectamente. Además, estas tareas son manejadas manualmente por el líder del equipo de control de calidad Alexey y asignadas al equipo cuya área de responsabilidad incluye el mal funcionamiento. Lesha sabe que las tareas aburridas deben ser realizadas por robots. Por lo tanto, me pidió ayuda con respecto a ML.

El siguiente gráfico muestra la cantidad de HHS por mes. Estamos creciendo y el número de tareas está creciendo. Las tareas se crean principalmente durante las horas de trabajo, algunas por día, y esto debe distraerse constantemente.
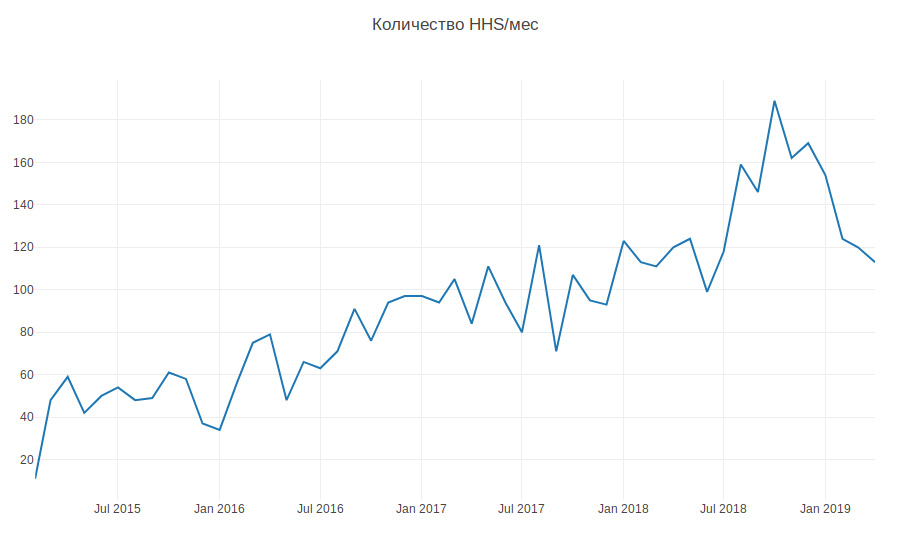
Entonces, según datos históricos, es necesario aprender cómo determinar el equipo de desarrollo al que pertenece el HHS. Esta es una tarea de clasificación de varias clases.
Datos
En las tareas de aprendizaje automático, lo más importante son los datos de calidad. El resultado de la solución al problema depende de ellos. Por lo tanto, cualquier tarea de aprendizaje automático debe comenzar con el estudio de los datos. Desde principios de 2015, hemos acumulado alrededor de 7000 tareas que contienen la siguiente información útil:
- Resumen - Título, Descripción breve
- Descripción: una descripción completa del problema
- Etiquetas: una lista de etiquetas relacionadas con el problema
- Reporter es el nombre del creador de HHS. Esta característica es útil porque las personas trabajan con un conjunto limitado de funcionalidades.
- Creado - Fecha de creación
- El cesionario es la persona a quien se le asigna la tarea. La variable objetivo se generará a partir de este atributo.
Comencemos con la variable objetivo. En primer lugar, cada equipo tiene áreas de responsabilidad. A veces se cruzan, a veces un equipo puede cruzarse en desarrollo con otro. La decisión se basará en el supuesto de que el cesionario, que permaneció con la tarea al momento del cierre, es responsable de su solución. Pero necesitamos predecir no una persona específica, sino un equipo. Afortunadamente, todos los equipos en Jira se mantienen y se pueden mapear. Pero hay una serie de problemas con la definición de un equipo por persona:
- no todos los HHS están relacionados con problemas técnicos, y solo estamos interesados en aquellas tareas que pueden asignarse al equipo de desarrollo. Por lo tanto, debe descartar tareas donde el cesionario no es del departamento técnico
- a veces los equipos dejan de existir. También se eliminan del conjunto de entrenamiento.
- Desafortunadamente, las personas no trabajan para siempre en la empresa, y a veces se mueven de un equipo a otro. Afortunadamente, logramos obtener un historial de cambios en la composición de todos los equipos. Al tener la fecha de creación del HHS y el cesionario, puede encontrar qué equipo participó en la tarea en un momento específico.
Después de filtrar datos irrelevantes, la muestra de capacitación se redujo a 4900 tareas.
Veamos la distribución de tareas entre equipos:
Las tareas deben distribuirse entre 22 equipos.
Signos:
Resumen y descripción son campos de texto.
Primero, deben limpiarse del exceso de caracteres. Para algunas tareas, tiene sentido dejar en las líneas caracteres que llevan información, por ejemplo + y #, para distinguir entre c ++ y c #, pero en este caso decidí dejar solo letras y números, porque no encontró dónde podrían ser útiles otros personajes.
Las palabras deben ser lematizadas. La lematización es la reducción de una palabra a un lema, su forma normal (vocabulario). Por ejemplo, gatos → gato. También probé la derivación, pero con la lematización la calidad fue un poco más alta. La tartamudez es el proceso de encontrar la base de una palabra. Esta base se debe al algoritmo (en diferentes implementaciones son diferentes), por ejemplo, por gatos → gatos. El significado del primero y segundo es yuxtaponer las mismas palabras en diferentes formas.
Usé el contenedor de python para
Yandex Mystem .
Además, el texto debe estar libre de palabras de detención que no llevan una carga útil. Por ejemplo, "era", "yo", "todavía". Pare las palabras que suelo tomar de
NLTK .
Otro enfoque que intento en las tareas de trabajar con texto es una fragmentación de palabras basada en caracteres. Por ejemplo, hay una "búsqueda". Si lo divide en componentes de 3 caracteres, obtendrá las palabras "poi", "ois", "demanda". Esto ayuda a obtener conexiones adicionales. Supongamos que existe la palabra "buscar". La lematización no conduce a "buscar" y "buscar" en una forma general, pero una partición de 3 caracteres resaltará la parte común: "reclamo".
Hice dos fichas. Tokenizer es un método que recibe texto en la entrada, y la salida contiene una lista de tokens, los componentes del texto. El primero resalta palabras y números lematizados. El segundo solo resalta palabras lematizadas, que se dividen en 3 caracteres, es decir en la salida, tiene una lista de tokens de tres caracteres.
Los tokenizadores se usan en
TfidfVectorizer , que se usa para convertir datos de texto (y no solo) en una representación vectorial basada en
tf-idf . Se le proporciona una lista de filas en la entrada, y en la salida obtenemos una matriz M por N, donde M es el número de filas y N es el número de signos. Cada característica es una respuesta de frecuencia de una palabra en un documento, donde la frecuencia se multa si la palabra aparece muchas veces en todos los documentos. Gracias al parámetro ngram_range TfidfVectorizer, agregué
bigrams y trigrams como atributos.
También intenté usar las incorporaciones de palabras obtenidas con Word2vec como características adicionales. La incrustación es una representación vectorial de una palabra. Para cada texto, promedié las incrustaciones de todas sus palabras. Pero esto no dio ningún aumento, por lo que rechacé estas señales.
Para las etiquetas, se utilizó un
CountVectorizer . Las filas con etiquetas se alimentan a la entrada, y en la salida tenemos una matriz donde las filas corresponden a las tareas y las columnas corresponden a las etiquetas. Cada celda contiene el número de ocurrencias de la etiqueta en la tarea. En mi caso, es 1 o 0.
LabelBinarizer se presentó para Reporter. Binariza los atributos de uno a todos. Solo puede haber un creador para cada tarea. En la entrada de LabelBinarizer, se envía una lista de creadores de tareas, y el resultado es una matriz, donde las filas son tareas y las columnas corresponden a los nombres de los creadores de tareas. Resulta que en cada línea hay "1" en la columna correspondiente al creador, y en el resto - "0".
Para Creado, se considera la diferencia en días entre la fecha en que se creó la tarea y la fecha actual.
Como resultado, se obtuvieron los siguientes signos:
- tf-idf para Resumen en palabras y números (4855, 4593)
- tf-idf para Resumen en particiones de tres caracteres (4855, 15518)
- tf-idf para Descripción en palabras y números (4855, 33297)
- tf-idf para Descripción en particiones de tres caracteres (4855, 75359)
- Número de entradas para etiquetas (4855, 505)
- signos binarios para Reporter (4855, 205)
- vida útil de la tarea (4855, 1)
Todos estos signos se combinan en una matriz grande (4855, 129478), en la que se llevará a cabo la capacitación.
Por separado, vale la pena señalar los nombres de los signos. Porque algunos modelos de aprendizaje automático pueden identificar características que tienen el mayor impacto en el reconocimiento de clase, debe usar esto. TfidfVectorizer, CountVectorizer, LabelBinarizer tienen métodos get_feature_names que muestran una lista de características cuyo orden corresponde a columnas de matrices de datos.
Selección del modelo de predicción
Muy a menudo
XGBoost da buenos resultados. Y comenzó con eso. Pero generé una gran cantidad de características, cuya cantidad excede significativamente el tamaño de la muestra de entrenamiento. En este caso, la probabilidad de reentrenar XGBoost es alta. El resultado no es muy bueno. La alta dimensión es una digestión
logística bien digerida. Ella mostró una mayor calidad.
También intenté, como ejercicio, construir un modelo en una red neuronal en Tensorflow usando
este excelente tutorial, pero resultó peor que con una regresión logística.
Selección de hiperparámetros
También jugué con los hiperparámetros XGBoost y Tensorflow, pero lo dejo fuera de la publicación, porque El resultado de la regresión logística no fue superado. Al final torcí todos los bolígrafos que podrían ser. Como resultado, todos los parámetros permanecieron predeterminados, excepto dos: solver = 'liblinear' y C = 3.0
Otro parámetro que puede afectar el resultado es el tamaño de la muestra de entrenamiento. Porque Estoy tratando con datos históricos, y en el transcurso de varios años la historia puede cambiar seriamente, por ejemplo, la responsabilidad de algo puede ir a otro equipo, luego los datos más recientes pueden ser más útiles, y los datos antiguos pueden incluso disminuir la calidad. A este respecto, se me ocurrió la heurística: cuanto más antiguos son los datos, menos contribución deben hacer para modelar la capacitación. Dependiendo de la edad, los datos se multiplican por un cierto coeficiente, que se toma de la función. Generé varias funciones para atenuar los datos y utilicé la que dio el mayor aumento en las pruebas.
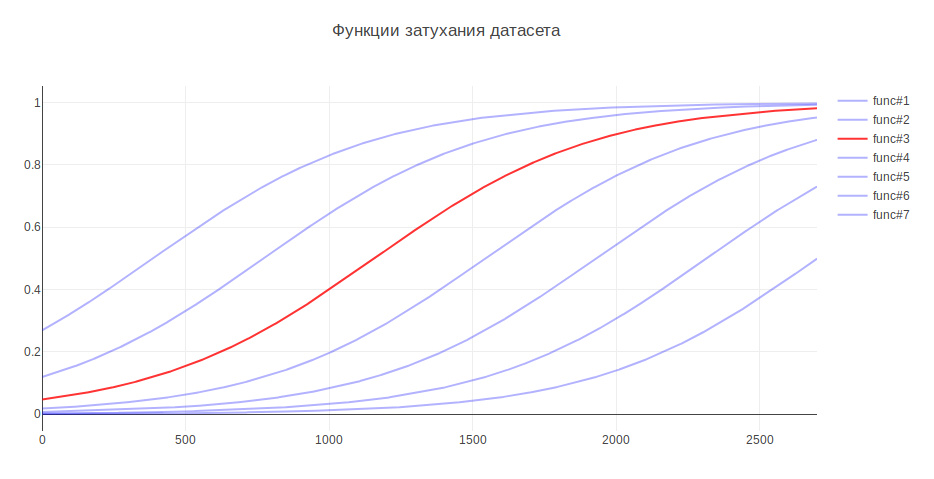
Debido a esto, la calidad de la clasificación aumentó en un 3%
Evaluación de calidad
En los problemas de clasificación, debemos pensar en lo que es más importante para nosotros: ¿
precisión o integridad ? En mi caso, si el algoritmo está mal, entonces no hay nada malo, tenemos muy buen conocimiento entre los equipos y la tarea se transferirá a los responsables, o al principal en el control de calidad. Además, el algoritmo no comete errores al azar, pero encuentra un comando cercano al problema. Por lo tanto, se decidió tomar el 100% para completar. Y para medir la calidad, se eligió la métrica de precisión: la proporción de respuestas correctas, que para el modelo final fue del 76%.
Como mecanismo de validación, primero utilicé la validación cruzada: cuando la muestra se divide en N partes y la calidad se verifica en una parte, y el entrenamiento se realiza en el resto, y así N veces, hasta que cada parte esté en la función de prueba. El resultado se promedia. Pero en mi caso, este enfoque no encajaba, porque El orden de los datos está cambiando y, como ya se sabe, la calidad depende de la frescura de los datos. Por lo tanto, estudié todo el tiempo en los viejos, y fui validado en los nuevos.
Veamos qué comandos confunde el algoritmo con mayor frecuencia:

En primer lugar están Marketing y Pandora. Esto no es sorprendente ya que El segundo equipo surgió del primero y se llevó la responsabilidad de muchas funcionalidades. Si considera al resto del equipo, también puede ver los motivos asociados con la cocina interna de la empresa.
A modo de comparación, quiero mirar modelos aleatorios. Si asigna una persona responsable al azar, la calidad será de aproximadamente el 5%, y si para la clase más común, entonces - 29%
Los signos mas significativos
LogisticRegression para cada clase devuelve coeficientes de atributo. Cuanto mayor sea el valor, mayor será la contribución que este atributo hizo a esta clase.
Debajo del spoiler, la salida de los principales signos. Los prefijos indican de dónde provienen los signos:
- sum - tf-idf para Resumen en palabras y números
- sum2 - tf-idf para resumen en divisiones de tres caracteres
- desc - tf-idf para Descripción en palabras y números
- desc2 - tf-idf para Descripción en particiones de tres caracteres
- laboratorio - campo de etiquetas
- rep - Reportero de campo
SignosA-Team: sum_site (1.28), lab_responses_and_invitations (1.37), lab_failure_to empleador (1.07), lab_makeup (1.03), sum_work (1.54), lab_hhs (1.19), lab_feedback (1.06), rep_name (1.16), sum_ window (1.13), sum_ break (1.04), rep_name_1 (1.22), lab_responses_seeker (1.0), lab_site (0.92)
API: lab_delete_account (1.12), sum_comment_resume (0.94), rep_name_2 (0.9), rep_name_3 (0.83), rep_name_4 (0.89), rep_name_5 (0.91), lab_measurements_managers (0.87), lab_comments_to_result (1.6), account_6 (0.86 ), sum_view (0.91), desc_comment (1.02), rep_name_6 (0.85), desc_resume (0.86), sum_api (1.01)
Android: sum_android (1.77), lab_ios (1.66), sum_application (2.9), sum_hr_mobile (1.4), lab_android (3.55), sum_hr (1.36), lab_mobile_application (3.33), sum_mobile (1.4), rep_name_2 (1.34), sum2_ril (1.27 ), sum_android_application (1.28), sum2_pril_rilo (1.19), sum2_pril_ril (1.27), sum2_pril_lozh (1.19), sum2_lo_lozh_log (1.19)
Facturación: rep_name_7 (3.88), desc_account (3.23), rep_name_8 (3.15), lab_billing_wtf (2.46), rep_name_9 (4.51), rep_name_10 (2.88), sum_account (3.16), lab_billing (2.41), rep_name_11 (2.27), labpb36 ), sum_service (2.33), lab_payment_services (1.92), sum_act (2.26), rep_name_12 (1.92), rep_name_13 (2.4)
Brandy: evaluación de talento de laboratorio (2.17), nombre_rep_14 (1.87), nombre_rep_15 (3.36), lab_clickme (1.72), nombre_rep_16 (1.44), nombre_rep_17 (1.63), nombre_rep_18 (1.29), suma_página (1.24), suma_brand (1.39) laboratorio ), sum_constructor (1.59), lab_brand de la página (1.33), sum_description (1.23), sum_description_of la compañía (1.17), lab_article (1.15)
Clickme: desc_act (0.73), sum_adv_hh (0.65), sum_adv_hh_ru (0.65), sum_hh (0.77), lab_hhs (1.27), lab_bs (1.91), rep_name_19 (1.17), rep_name_20 (1.29), rep_name_21 (1.9), rep_name_ ), sum_advertising (0.67), sum_placing (0.65), sum_adv (0.65), sum_hh_ua (0.64), sum_click_31 (0.64)
Comercialización: lab_region (0.9), lab_site_site (1.23), sum_mail (1.32), lab_managers_of vacantes (0.93), sum_calender (0.93), rep_name_22 (1.33), lab_queries (1.25), rep_name_6 (1.53), lab_product_1.55 (repa1_5 ), sum_yandex (1.26), sum_distribution_vacancy (0.85), sum_distribution (0.85), sum_category (0.85), sum_error_function (0.83)
Mercurio: lab_services (1.76), sum_captcha (2.02), lab_search_services (1.89), lab_lawyers (2.1), lab_authorization_worker (1.68), lab_proforientation (2.53), lab_ready_summary (2.21), rep_name_24 (1.7725_mail ), sum_user (1.57), rep_name_26 (1.43), lab_moderation_of vacantes (1.58), desc_password (1.39), rep_name_27 (1.36)
Mobile_site: sum_mobile_version (1.32), sum_version_site (1.26), lab_application (1.51), lab_statistics (1.32), sum_mobile_version_site (1.25), lab_mobile_version (5.1), sum_version (1.41), rep_name_28 (1.24), 1 ), lab_jtb (1.07), rep_name_16 (1.12), rep_name_29 (1.05), sum_site (0.95), rep_name_30 (0.92)
TMS: rep_name_31 (1.39), lab_talantix (4.28), rep_name_32 (1.55), rep_name_33 (2.59), sum_valuation_talantix (0.74), lab_search (0.57), lab_search (0.63), rep_name_34 (0.64), lab_port (0.56) ), lab_tms (0.74), respuesta sum_hh (0.57), lab_mailing (0.64), sum_talantix (0.6), sum2_po (0.56)
Talantix: sum_system (0.86), rep_name_16 (1.37), sum_talantix (1.16), lab_mail (0.94), lab_xor (0.8), lab_talantix (3.19), rep_name_35 (1.07), rep_name_18 (1.33), lab_personal_data (0.79) ), sum_talantics (0.89), sum_proceed (0.78), lab_mail (0.77), sum_response_stop_view (0.73), rep_name_6 (0.72)
Servicios web: sum_vacancy (1.36), desc_pattern (1.32), sum_archive (1.3), lab_patterns (1.39), sum_number_phone (1.44), rep_name_36 (1.28), lab_lawyers (2.1), lab_invitation (1.27), lab_invitation (2) ), lab_selected_summages (1.2), lab_key_keys (1.22), sum_find (1.18), sum_phone (1.16), sum_folder (1.17)
iOS: sum_application (1.41), desc_application (1.13), lab_andriod (1.73), rep_name_37 (1.05), lab_mobile_application (1.88), lab_ios (4.55), rep_name_6 (1.41), rep_name_38 (1.35), sum_mobile_application ), sum_mobile (0.98), rep_name_39 (0.74), sum_resum_hide (0.88), rep_name_40 (0.81), lab_Duplication of vacants (0.76)
Arquitectura: sum_statistics_response (1.1), rep_name_41 (1.4), lab_graphics_views_and_responses_ vacantes (1.04), lab_creation_of vacantes (1.16), lab_quotas (1.0), sum_special offer (1.02), rep_name_42 (1.33) 1.01_01_01_01_101_01_01_101_01 ), nombre_representante_43 (1.09), dependiente de suma (0.83), estadística_sum (0.83), trabajador_respuestas_ lab (0.76), suma_500ka (0.74)
Banco de sueldos: lab_500 (1.18), lab_authorization (0.79), sum_500 (1.04), rep_name_44 (0.85), sum_500_site (1.03), lab_site (1.54), lab_visibility_resume (1.54), lab_price list (1.26), lab_setting_visibility_7_resume (resume sum_error (0.79), lab_delivered_orders (1.33), rep_name_43 (0.74), sum_ie_11 (0.69), sum_500_error (0.66), sum2_site_ite (0.65)
Productos móviles: lab_mobile_application (1.69), lab_backs (1.65), sum_hr_mobile (0.81), lab_applicant (0.88), lab_employer (0.84), sum_mobile (0.81), rep_name_45 (1.2), desc_d0 (0.87), rep_name_46 (1.rr), sum_ 0.79), sum_incorrect_search_work (0.61), desc_application (0.71), rep_name_47 (0.69), rep_name_28 (0.61), sum_work_search (0.59)
Pandora: sum_receive (2.68), desc_receive (1.72), lab_sms (1.59), sum_ letter (2.75), sum_notification_response (1.38), sum_password (1.52), lab_recover_password (1.52), lab_mail_mail (1.31, mail, buzón (1.91) ), lab_mail (1.72), lab_mail (3.37), desc_mail (1.69), desc_mail (1.47), rep_name_6 (1.32)
Pimientos: lab_saving_summary (1.43), sum_summing (2.02), sum_oron (1.57), sum_oron_vacancy (1.66), desc_resum (1.19), lab_summing (1.39), sum_code (1.2), lab_applicant (1.34), sum_index (1.47), sum_index ), lab_creation_summary (1.28), rep_name_45 (1.82), sum_civilness (1.47), sum_save_summary (1.18), lab_invital_index (1.13)
Búsqueda-1: sum2_poi_is_search (1.86), sum_loop (3.59), lab_questions_o_search (3.86), sum2_poi (1.86), desc_overs (2.49), lab_observing_summary (2.2), lab_observer (2.32), lab_loop (4.3oopropo_1) (1.62), sum_synonym (1.71), sum_sample (1.62), sum2_isk (1.58), sum2_is_isk (1.57), lab_auto-update_sum (1.57)
Búsqueda-2: rep_name_48 (1.13), desc_d1 (1.1), lab_premium_in_search (1.02), lab_views_of vacantes (1.4), sum_search (1.4), desc_d0 (1.2), lab_show_contacts (1.17), rep_name_49 (1.12950, lab13 (1.05), lab_search_of vacantes (1.62), lab_responses_and_invations (1.61), sum_response (1.09), lab_selected_summary (1.37), lab_filter_of_responses (1.08)
Superproductos: lab_contact_information (1.78), desc_address (1.46), rep_name_46 (1.84), sum_address (1.74), lab_selected_resumes (1.45), lab_reviews_worker (1.29), sum_right_shot (1.29), sum_right_range (1.29) ), sum_error_position (1.33), rep_name_42 (1.32), sum_quota (1.14), desc_address_office (1.14), rep_name_51 (1.09)
Las señales reflejan aproximadamente lo que están haciendo los equipos.
Uso del modelo
Con esto, se completa la construcción del modelo y es posible construir un programa sobre la base.
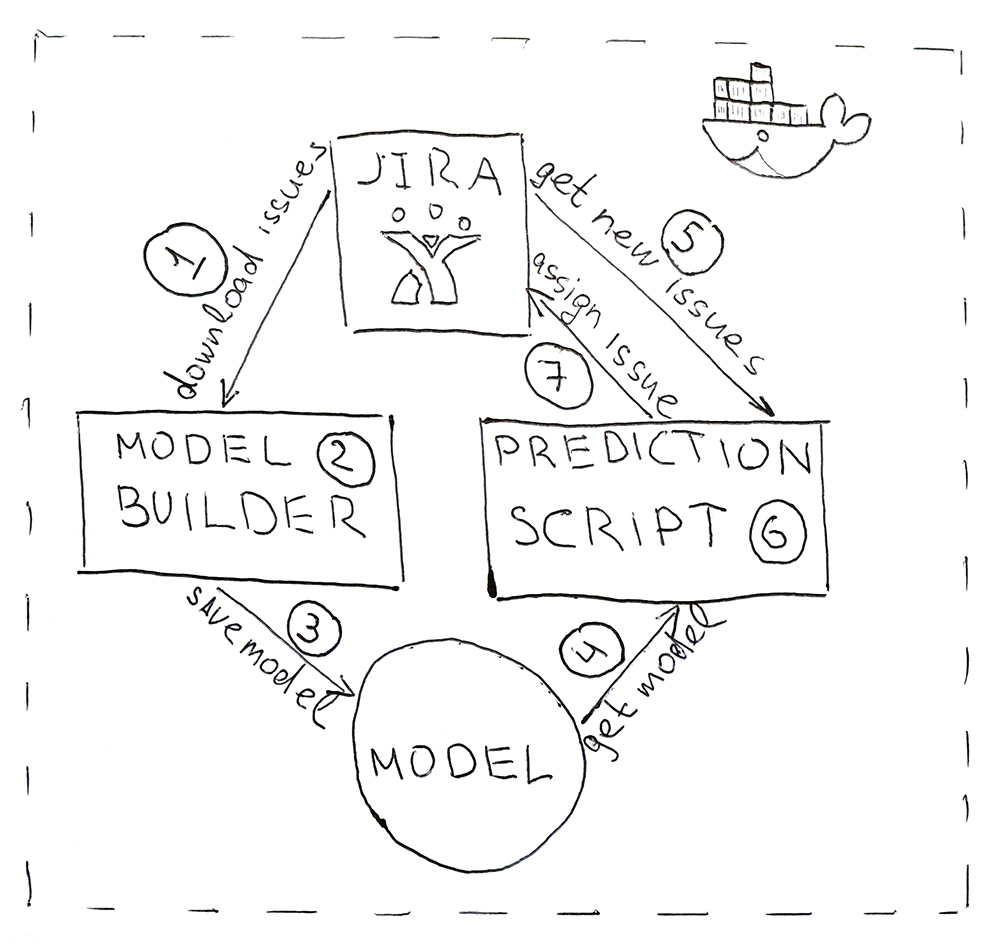
El programa consta de dos scripts de Python. El primero construye un modelo, y el segundo hace predicciones.
- Jira proporciona una API a través de la cual puede descargar tareas ya completadas (HHS). Una vez al día, se inicia el script y los descarga.
- Los datos descargados se convierten en etiquetas. Primero, los datos se superan para entrenamiento y prueba y se envían al modelo ML para su validación, para garantizar que la calidad no comience a disminuir de principio a comienzo. Y luego, la segunda vez, el modelo recibe capacitación sobre todos los datos. Todo el proceso dura unos 10 minutos.
- El modelo entrenado se guarda en el disco duro. Usé la utilidad eneldo para serializar objetos. Además del modelo en sí, también es necesario guardar todos los objetos que se utilizaron para obtener las características. Esto es para obtener carteles en el mismo espacio para el nuevo HHS.
- Usando el mismo eneldo, el modelo se carga en el script para la predicción, que se ejecuta una vez cada 5 minutos.
- Ir a Jira para el nuevo HHS.
- Recibimos los letreros y los pasamos al modelo, que devolverá para cada HHS el nombre de la clase, el nombre del equipo.
- Encontramos a la persona responsable del equipo y le asignamos una tarea a través de la API de Jira. Puede ser un probador, si el equipo no tiene un probador, entonces es un líder del equipo.
Para que el programa sea conveniente de implementar y tenga las mismas versiones de biblioteca que durante el desarrollo, los scripts se empaquetan en un contenedor Docker.
Como resultado, automatizamos el proceso de rutina. La precisión del 76% no es demasiado grande, pero en este caso las fallas no son críticas. Todas las tareas encuentran a sus ejecutantes, y lo más importante, para esto, ya no necesita distraerse varias veces al día para comprender la esencia de las tareas y buscar a los responsables. ¡Todo funciona automáticamente! ¡Hurra!