Hoy queremos hablar sobre una característica tan útil de Yandex.Cloud como máquinas virtuales interrumpidas. Esta es una opción especial que puede elegir al crear una máquina virtual para usar recursos informáticos a un precio reducido. ¿Qué tienen de especial las máquinas virtuales interrumpibles? ¿Por qué son más baratas que las normales y en qué casos es aconsejable usarlas?

Las capacidades de Yandex.Cloud, y más precisamente, el servicio de infraestructura
Yandex Compute Cloud , son notablemente mayores que las utilizadas por los usuarios. Por defecto, se supone que los usuarios deberían poder escalar arbitrariamente. Al menos por estas razones, sin tener en cuenta otros aspectos, los recursos disponibles de la plataforma en la nube superan significativamente la demanda actual. Es a estas capacidades libres que se crean las máquinas virtuales interrumpidas.
Limitaciones principales
Brevemente, la naturaleza de las máquinas virtuales interrumpidas se puede describir de la siguiente manera: el servicio ofrece utilizar sus recursos informáticos gratuitos a un precio más bajo, siempre que estos recursos puedan recuperarse en cualquier momento.
En general, las máquinas virtuales interrumpidas funcionan como máquinas virtuales normales, pero tienen varias limitaciones:
- No están cubiertos por un acuerdo de nivel de servicio (SLA).
- La capacidad de crear y ejecutar no está garantizada.
- Se les puede obligar a detenerse en cualquier momento. La probabilidad de una parada es pequeña, pero no nula, puede cambiar con el tiempo y variar en diferentes zonas de Yandex . Disponibilidad de la nube .
- Una máquina virtual interrumpida no se puede normalizar, sino una máquina interrumpida normal. El indicador correspondiente se establece una vez y no cambia.
- La máquina seguramente se detendrá en un período que no exceda las 24 horas.
En la práctica, en la gran mayoría de los casos, las máquinas virtuales interrumpidas funcionan las 24 horas previstas por las condiciones del servicio. Una parada forzada, por regla general, ocurre solo cuando se crea una gran cantidad de máquinas virtuales comunes en una zona de disponibilidad específica en un corto período de tiempo: un nuevo usuario aparece con necesidades serias o los usuarios actuales se escalan masivamente.
Al mismo tiempo, se puede volver a iniciar una máquina virtual detenida: todos los datos en los discos se guardan durante el apagado automático y manual.
Casos de uso
Las limitaciones para las máquinas virtuales interrumpidas plantean una pregunta lógica: ¿cómo aplicarlas si los recursos se pueden revocar en cualquier momento? Como explicación, aquí hay algunos casos de uso posibles.
Procesamiento por lotes
El procesamiento por lotes implica la ejecución paralela de una gran cantidad de tareas intensivas en recursos. Esta puede ser la conversión de formatos de archivo, procesamiento y reconocimiento de imágenes,
operaciones ETL . La conclusión es que en el procesamiento por lotes hay una cola de trabajos y un conjunto completo de procesos de trabajo (ejecutores) que reciben trabajos de la cola. Si un ejecutor individual que se ejecuta en una máquina interrumpida se detiene, la tarea simplemente se transferirá al siguiente ejecutor. En otras palabras, detener una o incluso varias máquinas virtuales no tendrá un impacto negativo significativo en el proceso y el resultado del procesamiento.

Cuando procesamos datos por lotes, estamos hablando de usar docenas de máquinas virtuales. El uso de máquinas intermitentes proporciona ahorros muy notables. Ahora uno de los principales consumidores de máquinas virtuales discontinuas productivas con 32 núcleos es un cliente de Yandex.Cloud desde hace mucho tiempo, Seismotech. Seismotek procesa datos sísmicos, que son necesarios para la exploración de campos de gas y petróleo. La exploración sísmica implica trabajar con grandes volúmenes de información. Los datos se procesan en un método por lotes. La compañía utiliza simultáneamente más de 60 máquinas interrumpidas: un total de hasta 2000 vCPU y 4000 GB de RAM.
Proyectos en Hadoop
Hadoop se utiliza para desarrollar y ejecutar programas distribuidos que se ejecutan en grupos de cientos y miles de nodos de bajo costo. Los mecanismos para la replicación de archivos y el reinicio automático de tareas realizadas en nodos fallidos proporcionados por Hadoop aseguran la estabilidad de un sistema distribuido ante fallos de máquinas individuales. Es por eso que, donde se usa Hadoop, al menos parte de los nodos se pueden implementar fácilmente en máquinas virtuales interrumpidas. Si se detienen temprano, las tareas se enviarán a otros nodos.
Conmutación por error de servicios web
La disponibilidad continua del servicio web se puede garantizar mediante el uso de un clúster. Un clúster consta de dos o más servidores. Una de sus tareas en la aplicación a los servicios web es garantizar un funcionamiento estable en el momento de las cargas máximas. Ejemplos típicos: sitios de compras en línea o sitios deportivos donde el crecimiento del tráfico está vinculado a fechas específicas. Para las tiendas, estos pueden ser días festivos tradicionales o períodos de descuentos, y para sitios relacionados con el deporte, pueden ser días de eventos cuando se publican transmisiones en vivo, se publican reseñas y reportajes fotográficos. En esos momentos, el volumen de tráfico puede aumentar significativamente.
El clúster debe hacer frente a la afluencia de visitantes mediante la distribución de tráfico a diferentes nodos. Para un período de crecimiento de carga agudo, pero de corta duración, se puede proporcionar tolerancia a fallas agregando servidores en máquinas virtuales descontinuadas. Esta opción es económica y hace bien su trabajo. Es importante observar una condición: dicho clúster debe ser híbrido, es decir, incluir máquinas virtuales comunes. En este caso, incluso la parada improbable de máquinas interrumpidas no conducirá a una falla del servicio.
Proyectos en Kubernetes
Kubernetes automatiza la implementación, el escalado y la administración de aplicaciones en contenedores en una gran cantidad de nodos. Una de las principales entidades que se puede llamar el bloque de construcción de Kubernetes está en (pod). Pod proporciona el lanzamiento de uno o varios contenedores en un nodo. El planificador de Kubernetes selecciona y asigna un nodo para cada hogar. Si falla un nodo separado con un hogar en funcionamiento, el programador lo transferirá automáticamente a un nodo que esté funcionando en modo normal. Este esquema de mantenimiento de la salud sugiere que parte de los nodos se pueden alojar en máquinas virtuales discontinuas.
Pruebas de integración continua
La práctica de la integración continua se basa en el montaje y las pruebas frecuentes del proyecto. En este caso, se utilizan principalmente pruebas automatizadas. Esquemáticamente, se ve así: se crea un entorno de prueba en una máquina virtual, se carga la última compilación de la aplicación, se realizan pruebas automatizadas, se cargan los resultados de la prueba, se elimina la máquina virtual. Como regla general, la prueba lleva varias decenas de minutos, con menos frecuencia varias horas.
Tradicionalmente, los puntos débiles de la integración continua se consideran costos significativos para respaldar el proceso de integración en sí y la alta demanda de recursos informáticos. Desde este punto de vista y teniendo en cuenta el marco temporal de las pruebas automatizadas, las máquinas virtuales descontinuadas se ven más que adecuadas para una integración continua. Son mucho más baratos, y la probabilidad de que un automóvil se detenga inmediatamente en el momento de la prueba es muy pequeña. Además, incluso si el automóvil todavía está parado, el daño desde el punto de vista del negocio será mínimo.
Úselo junto con otros servicios de Yandex.Cloud
El servicio Yandex Instance Groups le permite monitorear automáticamente el estado de un grupo completo de máquinas virtuales interrumpidas. Puede crear independientemente máquinas virtuales con las características dadas, mantener la cantidad necesaria de máquinas en el grupo y reiniciar las instancias interrumpidas si se detienen. No importa si se ha producido una detención forzada o si han pasado 24 horas desde el inicio. Solo una cosa es importante: se producirá un reinicio si hay recursos disponibles. Yandex Instance Groups hace que trabajar con máquinas virtuales interrumpidas sea más conveniente, pero no puede garantizar que existan capacidades libres necesariamente en una zona de disponibilidad específica.
Desempeño económico
Como mencionamos, las máquinas virtuales interrumpibles pueden reducir el costo del uso de recursos informáticos. Dentro de Yandex, comenzamos a trabajar en una función similar hace varios años. Para dividir las tareas informáticas en ejecutables garantizados e interrumpibles, se requerían inversiones considerables. Pero no fue en vano: al final, aumentamos el nivel de utilización útil de la infraestructura del servidor del 30-40% al 70-80%.

Ahora hay capacidades similares disponibles para todos los usuarios de Yandex.Cloud con solo hacer clic en un botón. Un ejemplo simple: si transfiere la mitad de las máquinas virtuales usadas con una carga de kernel cien por ciento al formato de interrupción, puede ahorrar hasta un 35-40% del presupuesto.
A un costo reducido, los recursos de CPU y RAM están disponibles. El espacio en disco y las direcciones IP se pagan a tarifas regulares. Esto es lo que muestra un cálculo simple para la plataforma Cascade Lake.
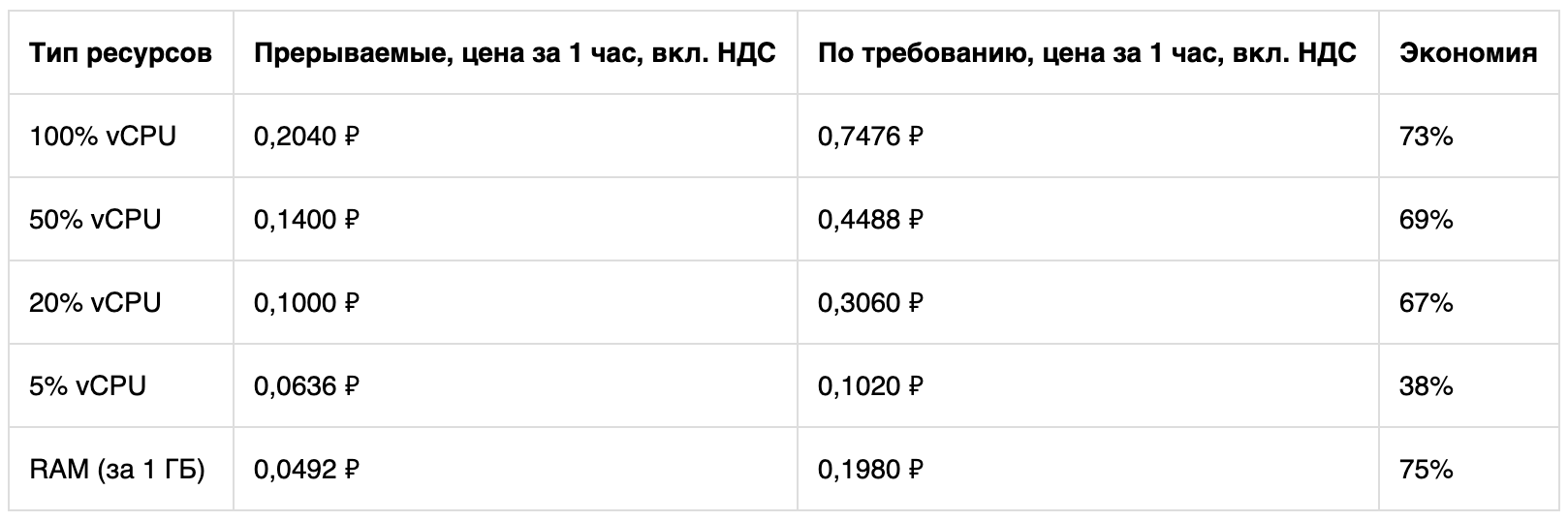
Si lo desea, puede comparar el costo de usar máquinas virtuales en diferentes modos usando una
calculadora .
Esperamos haber podido aportar un poco de claridad y dar algunos ejemplos útiles en los casos en que puede usar máquinas virtuales interrumpibles para reducir el costo de los recursos informáticos sin perder calidad en la realización de tareas.
Otras publicaciones sobre Cloud en Habré