Objetivos y requisitos para probar "Contabilidad 1C"
El objetivo principal de las pruebas es comparar el comportamiento del sistema 1C en dos DBMS diferentes en otras condiciones idénticas. Es decir La configuración de las bases de datos 1C y la población de datos inicial debe ser la misma durante cada prueba.
Los principales parámetros que se deben obtener durante las pruebas:
- El tiempo de ejecución de cada prueba (eliminado por el Departamento de Desarrollo 1C)
- Los administradores de DBMS eliminan la carga en el DBMS y el entorno del servidor durante la prueba, así como también el entorno del servidor por los administradores del sistema.
Las pruebas del sistema 1C deben llevarse a cabo teniendo en cuenta la arquitectura cliente-servidor, por lo tanto, es necesario emular a un usuario o varios usuarios en el sistema para calcular la entrada de información en la interfaz y almacenar esta información en la base de datos. Al mismo tiempo, es necesario que se publique una gran cantidad de información periódica durante un largo período de tiempo para crear totales en los registros de acumulación.
Para realizar las pruebas, se desarrolló un algoritmo en forma de script para la prueba de script, para la configuración de 1C Accounting 3.0, en el que se realiza la entrada en serie de los datos de prueba en el sistema 1C. El script le permite especificar varias configuraciones para las acciones realizadas y la cantidad de datos de prueba. Descripción detallada a continuación.
Descripción de la configuración y características de los entornos probados.
En Fortis decidimos verificar los resultados, incluido el uso de la conocida
prueba de Gilev .
También nos animaron a realizar pruebas, incluidas algunas publicaciones sobre los resultados de los cambios de rendimiento durante la transición de MS SQL Server a PostgreSQL. Tales como:
1C Battle: PostgreSQL 9.10 vs MS SQL 2016 .
Entonces, aquí está la infraestructura para las pruebas:
Los servidores para MS SQL y PostgreSQL eran virtuales y se ejecutaban alternativamente para la prueba deseada. 1C estaba en un servidor separado.
DetallesEspecificación del hipervisor:Modelo: Supermicro SYS-6028R-TRT
CPU: CPU Intel® Xeon® E5-2630 v3 @ 2.40GHz (2 calcetines * 16 CPU HT = 32CPU)
RAM: 212 GB
SO: VMWare ESXi 6.5
PowerProfile: rendimiento
Subsistema de disco de hipervisor:Controlador: Adaptec 6805, tamaño de caché: 512 MB
Volumen: RAID 10, 5.7 TB
Tamaño de banda: 1024 KB
Write-cache: activado
Lectura de caché: apagado
Ruedas: 6 piezas HGST HUS726T6TAL,
Tamaño del sector: 512 bytes
Escribir caché: en
PostgreSQL se configuró de la siguiente manera:- postgresql.conf:
La configuración básica se realizó utilizando la calculadora: pgconfigurator.cybertec.at , los parámetros huge_pages, checkpoint_timeout, max_wal_size, min_wal_size, random_page_cost cambiaron en función de la información recibida de las fuentes mencionadas al final de la publicación. El valor del parámetro temp_buffers aumentó, según la sugerencia de que 1C usa activamente tablas temporales:
listen_addresses = '*' max_connections = 1000
- Kernel, parámetros del sistema operativo:
La configuración se establece en el formato de archivo de perfil para el demonio sintonizado:
[sysctl]
- Sistema de archivos:
Todo el contenido del archivo postgresql.conf:
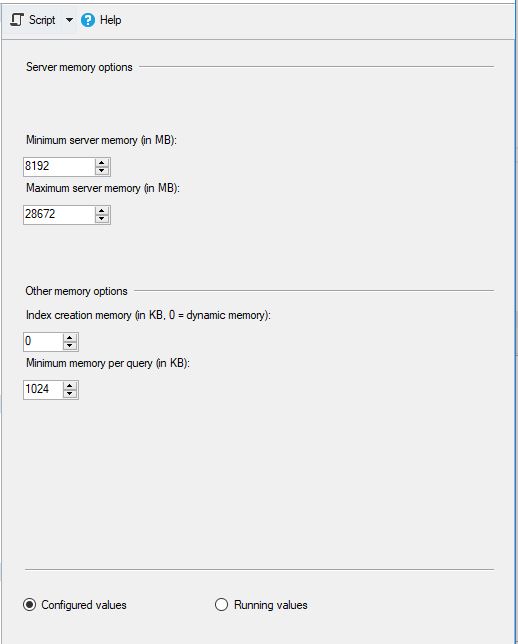
MS SQL se configuró de la siguiente manera: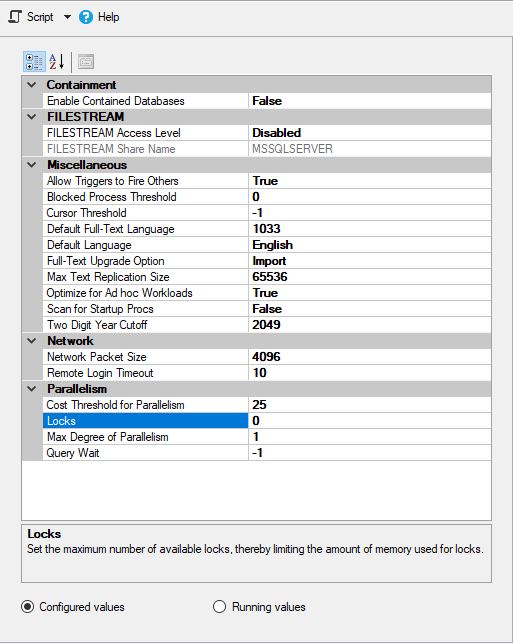
y
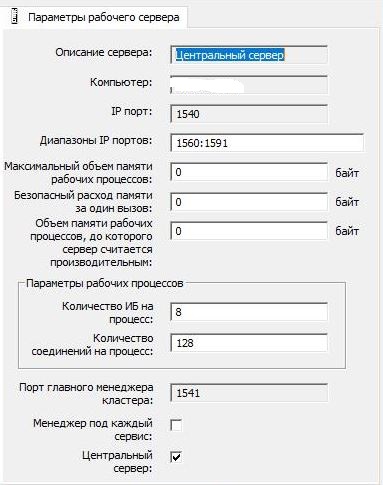
La configuración del clúster 1C se dejó estándar:

y
No había ningún programa antivirus en los servidores y no se instaló ningún tercero.
Para MS SQL, tempdb se movió a una unidad lógica separada. Sin embargo, los archivos de datos y los archivos de registro de transacciones para las bases de datos se ubicaron en la misma unidad lógica (es decir, los archivos de datos y los registros de transacciones no se dividieron en unidades lógicas separadas).
La indexación de unidades en Windows, donde se encontraba MS SQL Server, se deshabilitó en todas las unidades lógicas (como es habitual en la mayoría de los casos en entornos prodovskih).
Descripción del algoritmo principal del script para pruebas automatizadas.El principal período de prueba estimado es de 1 año, durante el cual se crean documentos e información de referencia para cada día de acuerdo con los parámetros especificados.
En cada día de ejecución, se lanzan bloques de entrada y salida de información:
- Bloque 1 "_" - "Recepción de bienes y servicios"
- Se abre el Directorio de contrapartes
- Se crea un nuevo elemento del directorio "Contratistas" con una vista de "Proveedor"
- Se crea un nuevo elemento del directorio "Contratos" con la vista "Con el proveedor" para una nueva contraparte
- Se abre el directorio "Nomenclatura"
- Se crea un conjunto de elementos del directorio "Nomenclatura" con el tipo "Producto"
- Se crea un conjunto de elementos del directorio "Nomenclatura" con el tipo "Servicio"
- Se abre la lista de documentos "Recibos de bienes y servicios".
- Se crea un nuevo documento "Entrada de bienes y servicios" en el que las partes tabulares "Bienes" y "Servicios" se completan con los conjuntos de datos creados
- El informe "Tarjeta de cuenta 41" se genera para el mes actual (si se indica el intervalo para la formación adicional)
- Bloque 2 "_" - "Venta de bienes y servicios"
- Se abre el Directorio de contrapartes
- Se crea un nuevo elemento del directorio "Contrapartes" con la vista "Comprador"
- Se crea un nuevo elemento del directorio "Contratos" con la vista "Con el comprador" para una nueva contraparte
- Se abre una lista de documentos "Ventas de bienes y servicios".
- Se crea un nuevo documento "Ventas de bienes y servicios" en el que las partes tabulares "Bienes" y "Servicios" se completan de acuerdo con los parámetros especificados a partir de datos creados previamente
- El informe "Tarjeta de cuenta 41" se genera para el mes actual (si se indica el intervalo para la formación adicional)
- Se genera el informe "Tarjeta de cuenta 41" para el mes actual
Al final de cada mes en el que se realizó la creación de documentos, se realizan bloques de entrada y salida de información:
- El informe "Tarjeta de cuenta 41" se genera desde el comienzo del año hasta el final del mes.
- El informe "Balance de facturación" se genera desde el comienzo del año hasta el final del mes.
- Se está llevando a cabo el procedimiento reglamentario "Cierre del mes".
El resultado de la ejecución proporciona información sobre el tiempo de la prueba en horas, minutos, segundos y milisegundos.
Características clave del script de prueba:- Capacidad para deshabilitar / habilitar unidades individuales
- Capacidad para especificar el número total de documentos para cada uno de los bloques.
- Capacidad para especificar el número de documentos para cada bloque por día.
- Capacidad para indicar la cantidad de bienes y servicios dentro de los documentos.
- Capacidad para establecer listas de indicadores cuantitativos y de precios para el registro. Sirve para crear diferentes conjuntos de valores en documentos
El plan de prueba básico para cada una de las bases de datos:- "La primera prueba". , « »
- — 20 . 1 . : 50 «», 50 «», 100 «», 50 «» + «», 50 «» + «», 2 « ». 1 1
- « ». ,
- — 50-60 . 3 . : 90 «», 90 «», 540 «», 90 «» + «», 90 «» + «», 3 « ». 3 3
- « ». . .
- — 40-60 . 2 . : 50 «», 50 «», 300 «», 50 «» + «», 50 «» + «». 3 3
:- , :
- « » « »
- 1 "*.dt"
- « »
- MS SQL Server:
:
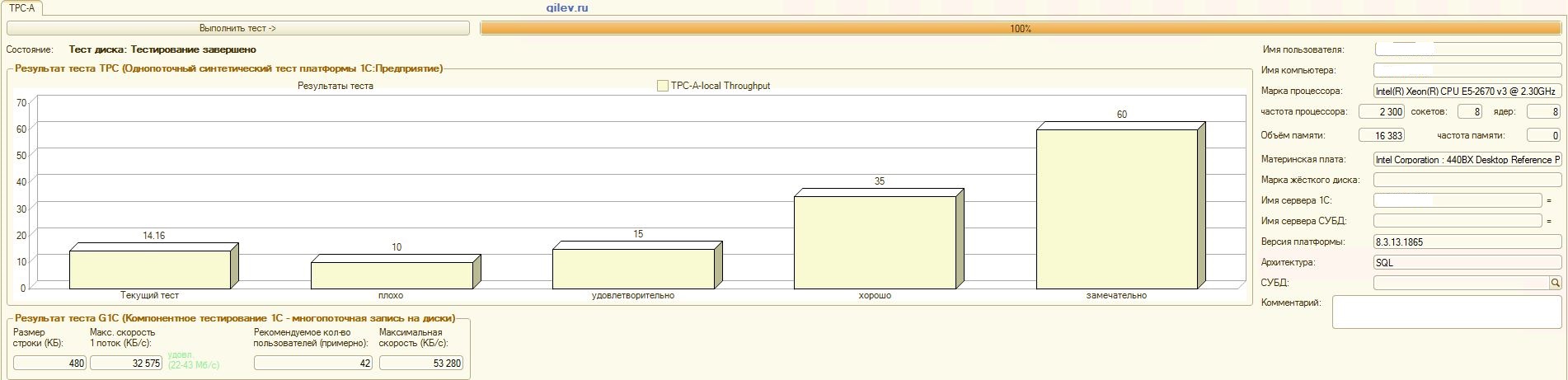
:
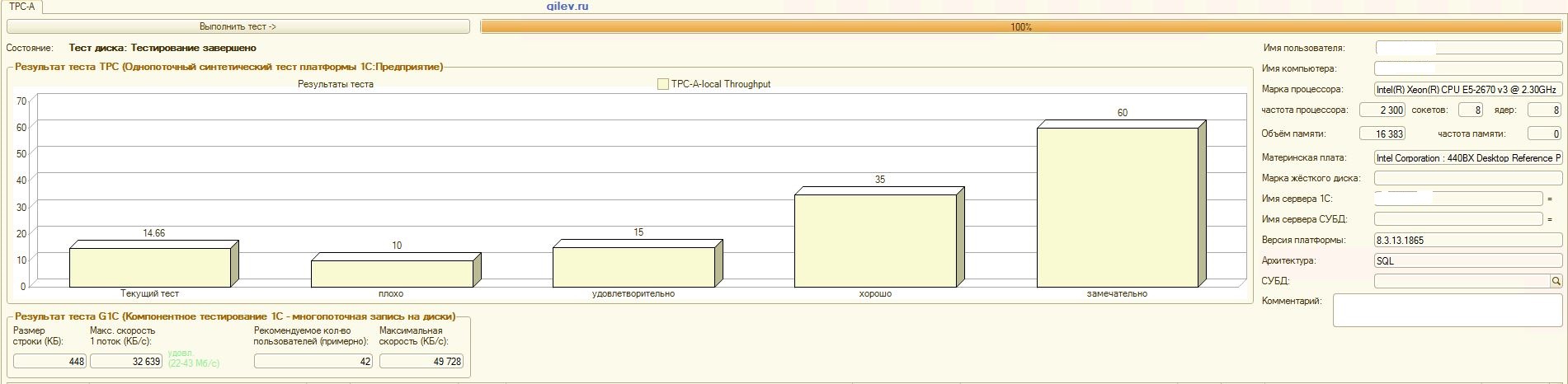
:

PostgreSQL,
, , , :
:
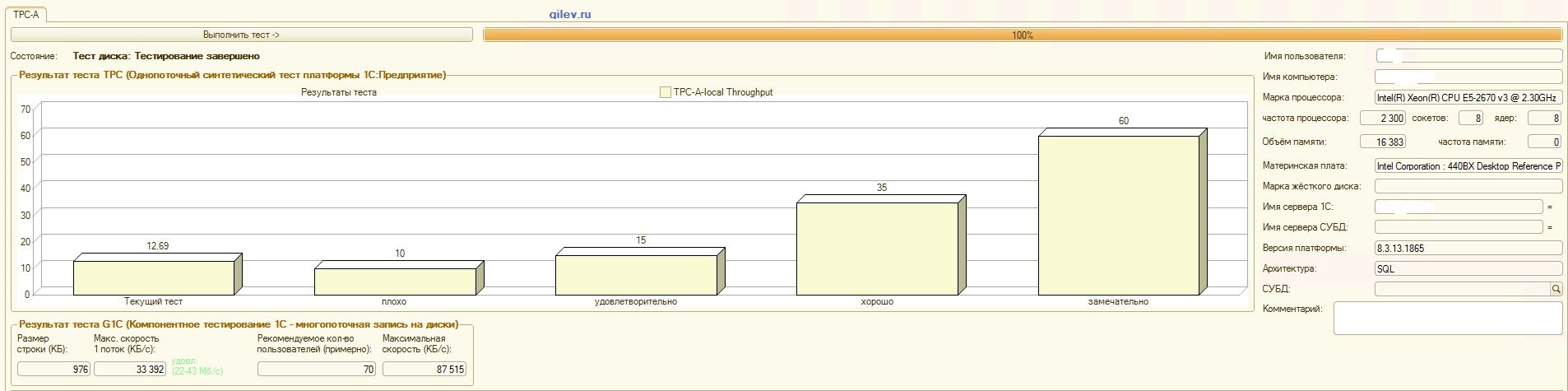
:
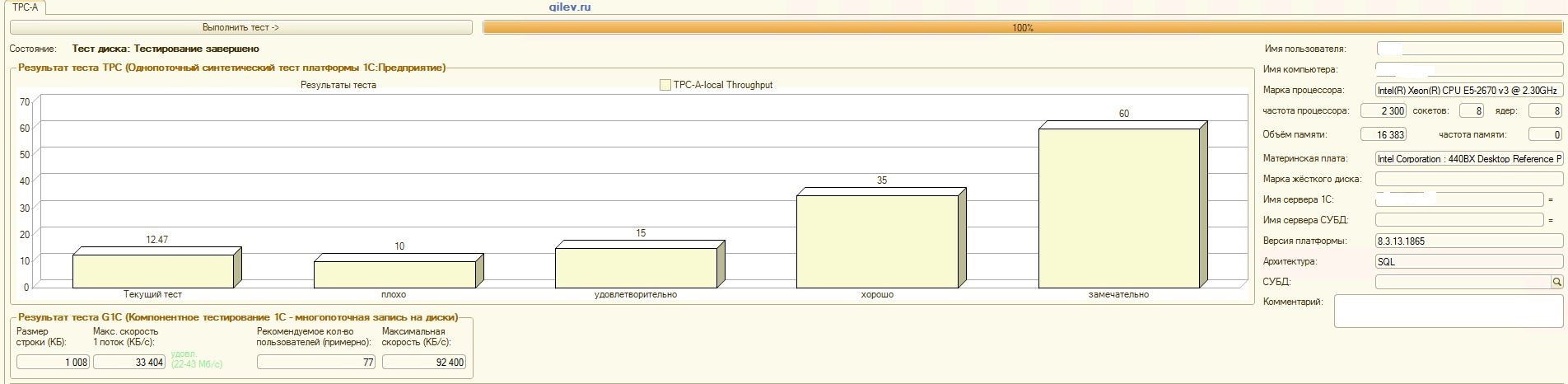
:

:
,
PostgreSQL MS SQL 14,82% . , PostgreSQL , MS SQL.
1 :
,
1 MS SQL, PostgreSQL .
.
, . , , , MS SQL PostgreSQL. , CentOS, .
, PostgreSQL- . MS SQL 3 , MS SQL . MS SQL.
MS SQL PostgreSQL, 1 , .
, , PostgreSQL MS SQL, , ,
1 MS SQL, PostgreSQL .
, 1 .
1 , . , , 1.
, , 1 8.3 15% PostgreSQL MS SQL. , . , ,
1 8.3 MS SQL PostgreSQL 15%. , 15% , , .
, , 100 , 4. , , 100 (, 1 ), ( ) .
, MS SQL Server 2019 Developer PostgreSQL 12, CentOS, MS SQL Windows Server. PostgreSQL Windows, PostgreSQL .
, 1. , , MS SQL PostgreSQL , . , . , .NET , , , . . .
, . PostgreSQL MS SQL , MS SQL PostgreSQL .
MS SQL,
.
Windows.
: PostgreSQL , MS SQL .
. ( ) . (, , ), ( , , ) . ( ) . , .
. , 7, 50. . . , , .
- 1 , :
- Fortis, CentOS, PostgreSQL ,
uaggster BP1988 MS SQL Windows.
Epílogo
.
?
Fuentes