Sobre el artículo
Esta publicación es una nota breve para los programadores que desean obtener más información sobre cómo la GPU maneja la ramificación. Puede considerarlo una introducción a este tema. Recomiendo comenzar con [
1 ], [
2 ] y [
8 ] para tener una idea de cómo se ve el modelo de ejecución de GPU en términos generales, porque consideraremos solo un detalle por separado. Para lectores curiosos, hay todos los enlaces al final de la publicación. Si encuentra errores, contácteme.
Contenido
- Sobre el artículo
- Contenido
- Vocabulario
- ¿En qué se diferencia el núcleo de la GPU del núcleo de la CPU?
- ¿Qué es la consistencia / discrepancia?
- Ejemplos de procesamiento de máscara de ejecución
- ISA ficticio
- AMD GCN ISA
- AVX512
- ¿Cómo lidiar con la discrepancia?
- Referencias
Vocabulario
- GPU - Unidad de procesamiento de gráficos, GPU
- Clasificación de Flynn
- SIMD: datos múltiples de instrucciones individuales, flujo de instrucciones único, flujo de datos múltiples
- SIMT - Instrucciones múltiples hilos múltiples, flujo de instrucciones individuales, hilos múltiples
- Wave (SIM): una secuencia ejecutada en el modo SIMD
- Línea (carril): un flujo de datos separado en el modelo SIMD
- SMT: subprocesamiento múltiple simultáneo, subprocesamiento múltiple simultáneo (Intel Hyper-threading) [ 2 ]
- Varios subprocesos comparten recursos informáticos básicos
- IMT - Intercalado multihilo, multihilo alterno [ 2 ]
- Varios subprocesos comparten los recursos informáticos totales del núcleo, pero solo uno
- BB: bloque básico, un bloque básico: una secuencia lineal de instrucciones con un solo salto al final
- ILP - Paralelismo a nivel de instrucción, paralelismo a nivel de instrucción [ 3 ]
- ISA - Arquitectura del conjunto de instrucciones, arquitectura del conjunto de instrucciones
En mi publicación me adheriré a esta clasificación inventada. Se asemeja más o menos a cómo se organiza una GPU moderna.
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1
Otros nombres:
- El núcleo puede llamarse CU, SM, EU
- Una ola se puede llamar un frente de onda, un subproceso de hardware (subproceso HW), deformación, un contexto
- Una línea se puede llamar un subproceso de programa (subproceso SW)
¿En qué se diferencia el núcleo de la GPU del núcleo de la CPU?
Cualquier generación actual de núcleos de GPU es menos potente que los procesadores centrales: ILP simple / multi-edición [
6 ] y prefetch [
5 ], sin predicción o predicción de transiciones / retornos. Todo esto, junto con pequeños cachés, libera un área bastante grande en el chip, que está lleno de muchos núcleos. Los mecanismos de carga / almacenamiento de memoria pueden hacer frente al ancho del canal en un orden de magnitud mayor (esto no se aplica a las GPU integradas / móviles) que las CPU convencionales, pero debe pagar por esto con altas latencias. Para ocultar la latencia, la GPU usa SMT [
2 ]: mientras una onda está inactiva, otras usan los recursos informáticos gratuitos del núcleo. Por lo general, el número de ondas procesadas por un núcleo depende de los registros utilizados y se determina dinámicamente mediante la asignación de un archivo de registro fijo [
8 ]. La planificación para la ejecución de instrucciones es híbrida: dinámica-estática [
6 ] [
11 4.4]. Los núcleos SMT ejecutados en modo SIMD alcanzan valores FLOPS altos (operaciones de punto flotante por segundo, flops, número de operaciones de punto flotante por segundo).
 Gráfico de leyenda Negro - inactivo, blanco - activo, gris - apagado, azul - inactivo, rojo - pendienteFigura 1. Historial de ejecución 4: 2
Gráfico de leyenda Negro - inactivo, blanco - activo, gris - apagado, azul - inactivo, rojo - pendienteFigura 1. Historial de ejecución 4: 2La imagen muestra el historial de la máscara de ejecución, donde el eje x muestra el tiempo que va de izquierda a derecha, y el eje y muestra el identificador de la línea que va de arriba a abajo. Si aún no comprende esto, vuelva al dibujo después de leer las siguientes secciones.
Esta es una ilustración de cómo puede verse el historial de ejecución del núcleo de la GPU en una configuración ficticia: cuatro ondas comparten una muestra y dos ALU. El planificador de ondas en cada ciclo emite dos instrucciones de dos ondas. Cuando una onda está inactiva cuando se realiza un acceso a la memoria o una operación ALU larga, el programador cambia a otro par de ondas, debido a que la ALU está constantemente ocupada por casi el 100%.
Figura 2. Historial de ejecución 4: 1Un ejemplo con la misma carga, pero esta vez en cada ciclo de la instrucción solo se emite una onda. Observe que la segunda ALU está muriendo de hambre.
Figura 3. Historial de ejecución 4: 4Esta vez, se emiten cuatro instrucciones en cada ciclo. Tenga en cuenta que hay demasiadas solicitudes para ALU, por lo que dos ondas casi siempre están esperando (de hecho, esto es un error del algoritmo de planificación).
Actualización Para obtener más información sobre las dificultades de planificar la ejecución de las instrucciones, consulte [
12 ].
En el mundo real, las GPU tienen diferentes configuraciones de núcleo: algunas pueden tener hasta 40 ondas por núcleo y 4 ALU, otras tienen 7 ondas fijas y 2 ALU. Todo esto depende de muchos factores y se determina gracias al minucioso proceso de simulación de arquitectura.
Además, las ALU SIMD reales pueden tener un ancho más estrecho que las ondas que sirven, y luego se requieren varios ciclos para procesar una instrucción emitida; El factor se llama "carillón" de longitud [
3 ].
¿Qué es la consistencia / discrepancia?
Echemos un vistazo al siguiente fragmento de código:
Ejemplo 1
uint lane_id = get_lane_id(); if (lane_id & 1) {
Aquí vemos una secuencia de instrucciones en las que la ruta de ejecución depende del identificador de la línea que se está ejecutando. Obviamente, diferentes líneas tienen diferentes significados. ¿Qué va a pasar? Existen diferentes enfoques para resolver este problema [
4 ], pero al final todos hacen lo mismo. Uno de esos enfoques es la máscara de ejecución, que cubriré. Este enfoque se usó en las GPU Nvidia antes de Volta y en las GPU AMD GCN. El punto principal de la máscara de ejecución es que almacenamos un bit para cada línea en la onda. Si el bit de ejecución de línea correspondiente es 0, entonces no se verán afectados los registros para la próxima instrucción emitida. De hecho, la línea no debería sentir la influencia de toda la instrucción ejecutada, porque su bit de ejecución es 0. Esto funciona de la siguiente manera: la onda viaja a lo largo del gráfico de flujo de control en el orden de búsqueda de profundidad, guardando el historial de las transiciones seleccionadas hasta que se establecen los bits. Creo que es mejor mostrarlo con un ejemplo.
Supongamos que tenemos ondas con un ancho de 8. Así es como se ve la máscara de ejecución para el fragmento de código:
Ejemplo 1. Historia de la máscara de ejecución.
Ahora considere ejemplos más complejos:
Ejemplo 2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) {
Ejemplo 3
uint lane_id = get_lane_id(); if (lane_id < 16) {
Puede notar que la historia es necesaria. Cuando se usa el enfoque de máscara de ejecución, el equipo generalmente usa algún tipo de pila. El enfoque ingenuo es almacenar una pila de tuplas (exec_mask, address) y agregar instrucciones de convergencia que extraigan la máscara de la pila y cambien el puntero de instrucción para la onda. En este caso, la onda tendrá suficiente información para evitar el CFG completo para cada línea.
En términos de rendimiento, solo se necesitan un par de bucles para procesar una instrucción de flujo de control debido a todo este almacenamiento de datos. Y no olvide que la pila tiene una profundidad limitada.
Actualización Gracias a
@craigkolb, leí un artículo [
13 ], que señala que las instrucciones de horquilla / unión de AMD GCN primero seleccionan una ruta de menos hilos [
11 4.6], lo que garantiza que la profundidad de la pila de máscara es igual a log2.
Actualización Obviamente, casi siempre es posible incrustar todo en un sombreador / estructura CFG en un sombreador y, por lo tanto, almacenar todo el historial de máscaras de ejecución en registros y planear bypass / convergencia estática CFG [
15 ]. Después de mirar el backend LLVM para AMDGPU, no encontré ninguna evidencia de manejo de pila emitido constantemente por el compilador.
Soporte de hardware de máscara de tiempo de ejecución
Ahora eche un vistazo a estos gráficos de flujo de control de Wikipedia:
Figura 4. Algunos de los tipos de gráficos de flujo de control¿Cuál es el conjunto mínimo de instrucciones de control de máscara que necesitamos para manejar todos los casos? Así es como se ve en mi ISA artificial con paralelización implícita, control de máscara explícito y sincronización totalmente dinámica de conflictos de datos:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE
Echemos un vistazo al caso d).
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret
No soy especialista en analizar flujos de control o diseñar ISA, así que estoy seguro de que hay un caso en el que mi ISA artificial no podrá hacer frente, pero esto no es importante, porque un CFG estructurado debería ser suficiente para todos.
Actualización Lea más sobre el soporte de GCN para las instrucciones de flujo de control aquí: [
11 ] ch.4, y sobre la implementación de LLVM aquí: [
15 ].
Conclusión
- Divergencia: la diferencia resultante en los caminos elegidos por diferentes líneas de la misma onda
- Consistencia: sin discrepancia.
Ejemplos de procesamiento de máscara de ejecución
ISA ficticio
Compilé los fragmentos de código anteriores en mi ISA artificial y los ejecuté en un simulador en SIMD32. Vea cómo maneja la máscara de ejecución.
Actualización Tenga en cuenta que un simulador artificial siempre elige el camino verdadero, y esta no es la mejor manera.
Ejemplo 1
 Figura 5. La historia del ejemplo 1
Figura 5. La historia del ejemplo 1¿Notaste un área negra? Esta vez desperdiciado. Algunas líneas esperan a que otras completen la iteración.
Ejemplo 2
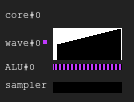 Figura 6. Historia del ejemplo 2
Figura 6. Historia del ejemplo 2Ejemplo 3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16)
 Figura 7. Historia del ejemplo 3
Figura 7. Historia del ejemplo 3AMD GCN ISA
Actualización GCN también utiliza el procesamiento de máscara explícito, más sobre esto se puede encontrar aquí: [
11 4.x]. Decidí mostrar algunos ejemplos de su ISA, gracias a
Shader-playground esto es fácil de hacer. Quizás algún día encuentre un simulador y logre obtener diagramas.
Tenga en cuenta que el compilador es inteligente, por lo que puede obtener otros resultados. Traté de engañar al compilador para que no optimizara mis ramas colocando bucles de puntero y luego limpiando el código del ensamblador; No soy un especialista en GCN, por lo que se pueden omitir algunos
nop importantes.
También tenga en cuenta que las instrucciones S_CBRANCH_I / G_FORK y S_CBRANCH_JOIN no se usan en estos fragmentos porque son simples y el compilador no las admite. Por lo tanto, desafortunadamente, no fue posible considerar la pila de máscaras. Si sabe cómo hacer que el compilador emita el procesamiento de la pila, dígamelo.
Actualización Echa un vistazo a esta
charla @ SiNGUL4RiTY sobre la implementación de un flujo de control vectorizado en el back-end LLVM utilizado por AMD.
Ejemplo 1
Ejemplo 2
Ejemplo 3
AVX512
Actualización @tom_forsyth me señaló que la extensión AVX512 también tiene un procesamiento de máscara explícito, así que aquí hay algunos ejemplos. Se pueden encontrar más detalles sobre esto en [
14 ], 15.xy 15.6.1. No es exactamente una GPU, pero todavía tiene un SIMD16 real con 32 bits. Los fragmentos de código se crearon utilizando el godbolt ISPC (–target = avx512knl-i32x16) y están muy rediseñados, por lo que pueden no ser 100% verdaderos.
Ejemplo 1
Ejemplo 2
Ejemplo 3
¿Cómo lidiar con la discrepancia?
Traté de crear una ilustración simple pero completa de cómo surge la ineficiencia al combinar líneas divergentes.
Imagine una pieza simple de código:
uint thread_id = get_thread_id()
Creemos 256 hilos y midamos su tiempo de ejecución:
Figura 8. Duración de hilos divergentesEl eje x es el identificador de la secuencia del programa, el eje y son los ciclos de reloj; diferentes columnas muestran cuánto tiempo se pierde al agrupar flujos con diferentes longitudes de onda en comparación con la ejecución de un solo subproceso.
El tiempo de ejecución de la onda es igual al tiempo de ejecución máximo entre las líneas que contiene. Puede ver que el rendimiento ya cae drásticamente con SIMD8, y una mayor expansión solo lo empeora un poco.
Figura 9. Tiempo de ejecución de subprocesos consistentesLas mismas columnas se muestran en esta figura, pero esta vez el número de iteraciones se ordena por identificadores de flujo, es decir, los flujos con un número similar de iteraciones se transmiten a una sola onda.
Para este ejemplo, la ejecución se acelera potencialmente a la mitad.
Por supuesto, el ejemplo es demasiado simple, pero espero que entienda el punto: la discrepancia en la ejecución se deriva de la discrepancia de los datos, por lo que los CFG deben ser simples y consistentes.
Por ejemplo, si está escribiendo un rastreador de rayos, puede beneficiarse de agrupar los rayos con la misma dirección y posición, porque lo más probable es que pasen por los mismos nodos en el BVH. Ver [
10 ] y otros artículos relacionados para más detalles.
También vale la pena mencionar que existen técnicas para tratar las discrepancias a nivel de hardware, por ejemplo, Dynamic Warp Formation [
7 ] y ejecución prevista para ramas pequeñas.
Referencias
[1]
Un viaje a través de la tubería de gráficos[2]
Kayvon Fatahalian: COMPUTACIÓN PARALELA[3]
Arquitectura de computadoras Un enfoque cuantitativo[4]
Reconvergencia SIMT sin pila a bajo costo[5]
Disección de la jerarquía de memoria de GPU a través de microbenchmarking[6]
Disección de la arquitectura NVIDIA Volta GPU a través de microbenchmarking[7]
Formación dinámica de urdimbre y programación para un flujo de control de GPU eficiente[8]
Maurizio Cerrato: arquitecturas de GPU[9]
Simulador de GPU de juguete[10]
Reducción de la divergencia de ramas en los programas de GPU[11]
Arquitectura del conjunto de instrucciones "Vega"[12]
Joshua Barczak: Simulación de ejecución de sombreador para GCN[13]
Vector tangente: una digresión sobre la divergencia[14]
Intel 64 e IA-32 Architectures Manual del desarrollador de software[15]
Vectorización de flujo de control divergente para aplicaciones SIMD