Discutiremos la implementación del mapa en un lenguaje sin genéricos, consideraremos qué es una tabla hash, cómo está organizada en Go, cuáles son los pros y los contras de esta implementación, y a qué debe prestar atención al usar esta estructura.
Detalles debajo del corte.
Atencion Si ya está familiarizado con las tablas hash en Go, le aconsejo que omita los conceptos básicos y vaya
aquí , de lo contrario, existe el riesgo de cansarse del momento más interesante.
¿Qué es una tabla hash?
Para empezar, te recordaré qué es una tabla hash. Esta es una estructura de datos que le permite almacenar pares clave-valor y, como regla, poseer funciones:
- Mapeo:
map(key) → value
- Inserts:
insert(map, key, value)
- Eliminaciones:
delete(map, key)
- Búsqueda:
lookup(key) → value
Tabla hash en idioma go
Una tabla hash en el idioma go está representada por la palabra clave del mapa y puede declararse de una de las siguientes maneras (más sobre ellas más adelante):
m := make(map[key_type]value_type) m := new(map[key_type]value_type) var m map[key_type]value_type m := map[key_type]value_type{key1: val1, key2: val2}
Las operaciones principales se realizan de la siguiente manera:
- Insertar:
m[key] = value
- Remoción:
delete(m, key)
- Búsqueda:
value = m[key]
o
value, ok = m[key]
Ir alrededor de una mesa en ir
Considere el siguiente programa:
package main import "fmt" func main() { m := map[int]bool{} for i := 0; i < 5; i++ { m[i] = ((i % 2) == 0) } for k, v := range m { fmt.Printf("key: %d, value: %t\n", k, v) } }
Lanzamiento 1:
key: 3, value: false key: 4, value: true key: 0, value: true key: 1, value: false key: 2, value: true
Ejecución 2:
key: 4, value: true key: 0, value: true key: 1, value: false key: 2, value: true key: 3, value: false
Como puede ver, la salida varía de una ejecución a otra. Y todo porque el mapa en Go no está ordenado, es decir, no está ordenado. Esto significa que no necesita confiar en el orden cuando va de un lado a otro. La razón se puede encontrar en el código fuente del lenguaje de tiempo de ejecución:
La ubicación de búsqueda se determina
al azar , ¡recuerda esto! Se rumorea que los desarrolladores de tiempo de ejecución están obligando a los usuarios a no confiar en el orden.
Ir a la tabla de búsqueda
Veamos nuevamente un fragmento de código. Supongamos que queremos crear pares "número" - "número por 10":
package main import ( "fmt" ) func main() { m := map[int]int{0: 0, 1: 10} fmt.Println(m, m[0], m[1], m[2]) }
Lanzamos:
map[0:0 1:10] 0 10 0
Y vemos que cuando intentamos obtener el valor de dos (que olvidamos poner) obtuvimos 0. Encontramos líneas que explican este comportamiento en la
documentación : “Un intento de obtener un valor de mapa con una clave que no está presente en el mapa devolverá el valor cero para el tipo de las entradas en el mapa ", pero traducido al ruso, esto significa que cuando intentamos obtener el valor del mapa, pero no está allí, obtenemos un" valor de tipo cero ", que en el caso del número 0. Qué hacer, si queremos distinguir entre casos 0 y ausencia 2? Para hacer esto, se nos ocurrió una forma especial de "asignación múltiple": una forma en la que, en lugar del valor único habitual, el mapa devuelve un par: el valor en sí y otro booleano que responde a la pregunta de si la clave solicitada está presente en el mapa o no "
Correctamente, el fragmento de código anterior se verá así:
package main import ( "fmt" ) func main() { m := map[int]int{0: 0, 1: 10} m2, ok := m[2] if !ok {
Y al inicio obtenemos:
map[0:0 1:10] 0 10 20
Crea una tabla en Go.
Supongamos que queremos contar el número de apariciones de cada palabra en una cadena, comenzar un diccionario para esto y revisarlo.
package main func main() { var m map[string]int for _, word := range []string{"hello", "world", "from", "the", "best", "language", "in", "the", "world"} { m[word]++ } for k, v := range m { println(k, v) } }
¿Ves una
trampa de Gopher ? - Y lo es!
Cuando intentamos iniciar un programa de este tipo, nos da pánico y aparece el mensaje "asignación a entrada en mapa nulo". Y todo porque el mapa es un tipo de referencia y no es suficiente para declarar una variable, debe inicializarlo:
m := make(map[string]int)
Un poco más abajo, quedará claro por qué esto funciona de esta manera. Al principio, ya se presentaron 4 formas de crear un mapa, dos de las cuales examinamos: esta declaración como variable y creación a través de make. También puede crear utilizando el diseño "
Literales compuestos "
map[key_type]value_type{}
y si lo desea, incluso inicializar inmediatamente con valores, este método también es válido. En cuanto a la creación usando new, en mi opinión, no tiene sentido, porque esta función asigna memoria para una variable y le devuelve un puntero con un valor cero del tipo, que en el caso del mapa será nulo (obtenemos el mismo resultado que en var, más precisamente un puntero a él).
¿Cómo se pasa el mapa a una función?
Supongamos que tenemos una función que intenta cambiar el número que se le pasó. Veamos qué sucede antes y después de la llamada:
package main func foo(n int) { n = 10 } func main() { n := 15 println("n before foo =", n) foo(n) println("n after foo =", n) }
Un ejemplo, creo, es bastante obvio, pero aún incluye la conclusión:
n before foo = 15 n after foo = 15
Como probablemente haya adivinado, la función n vino por valor, no por referencia, por lo que la variable original no ha cambiado.
Hagamos un truco de mapa similar:
package main func foo(m map[int]int) { m[10] = 10 } func main() { m := make(map[int]int) m[10] = 15 println("m[10] before foo =", m[10]) foo(m) println("m[10] after foo =", m[10]) }
Y he aquí y he aquí:
m[10] before foo = 15 m[10] after foo = 10
El valor ha cambiado. "Bueno, ¿Mapa pasa por referencia?", Preguntas.
No No hay enlaces en Go. Es imposible crear 2 variables con 1 dirección, como en C ++ por ejemplo. Pero luego puede crear 2 variables que apuntan a la misma dirección (pero estos son punteros y están en Ir).
Supongamos que tenemos una función fn que inicializa el mapa m. En la función principal, simplemente declaramos una variable, la enviamos a inicializar y observamos lo que sucedió después.
package main import "fmt" func fn(m map[int]int) { m = make(map[int]int) fmt.Println("m == nil in fn?:", m == nil) } func main() { var m map[int]int fn(m) fmt.Println("m == nil in main?:", m == nil) }
Conclusión
m == nil in fn?: false
m == nil in main?: true
Entonces, la variable m se pasó
por valor , por lo tanto, como en el caso de pasar un int regular a la función, no cambió (la copia local del valor en fn cambió). Entonces, ¿por qué cambia el valor en sí mismo? Para responder a esta pregunta, considere el código del lenguaje en tiempo de ejecución:
Map in Go es solo un puntero a la estructura hmap. Esta es la respuesta a la pregunta de por qué, a pesar del hecho de que el mapa se pasa a la función por valor, los valores en sí mismos cambian: todo se trata del puntero. La estructura hmap también contiene lo siguiente: la cantidad de elementos, la cantidad de “cubos” (presentados como un logaritmo para acelerar los cálculos), semilla para aleatorizar hashes (para que sea más difícil de agregar, intente recoger claves para que haya colisiones continuas), todo tipo de campos de servicio y lo más importante, un puntero a los depósitos donde se almacenan los valores. Miremos la imagen:
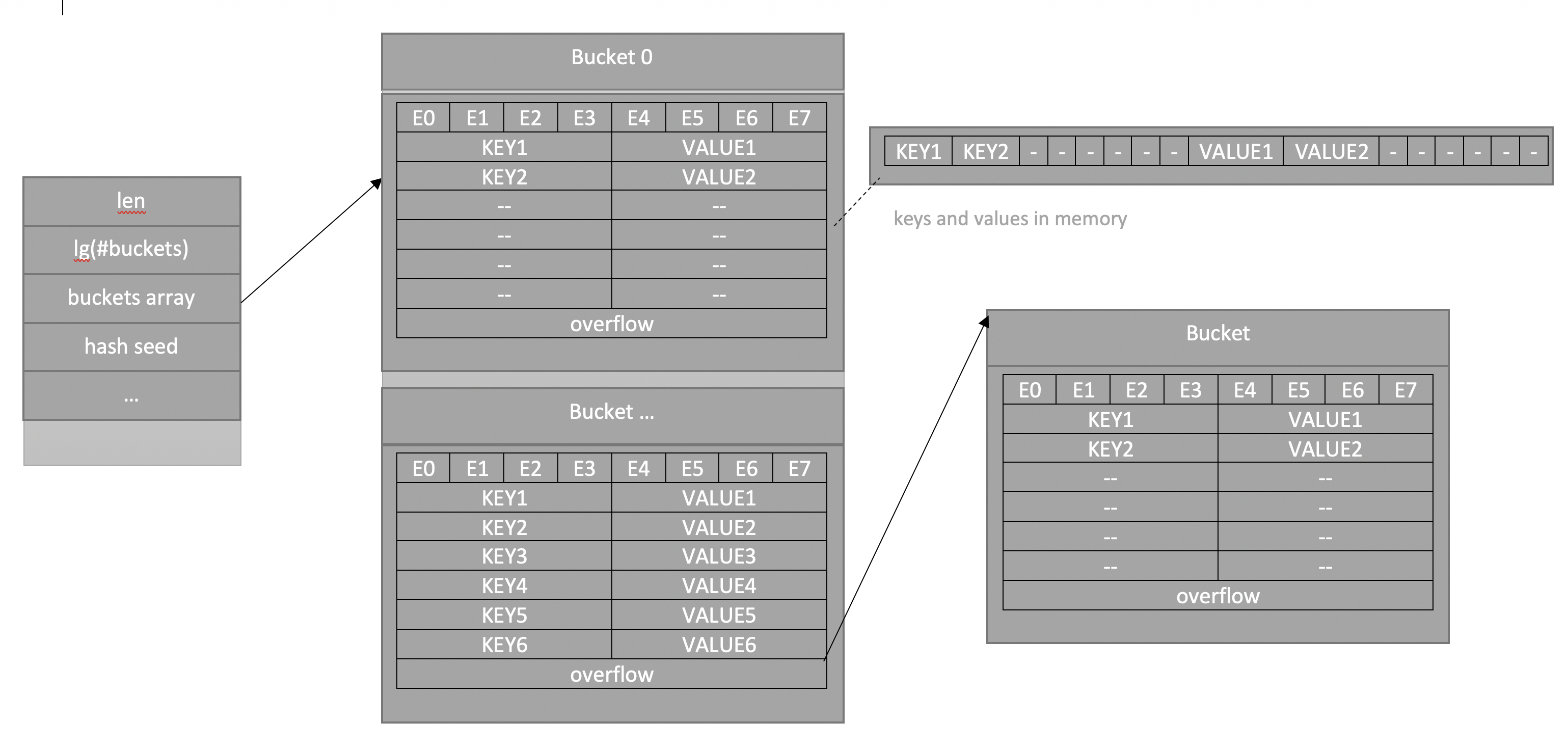
La imagen muestra una imagen esquemática de la estructura en la memoria: hay un encabezado hmap, cuyo puntero es un mapa en Go (se crea cuando se declara con var, pero no se inicializa, lo que hace que el programa se bloquee al intentar insertarlo). El campo de cubos es un depósito de pares clave-valor, hay varios cubos de este tipo, cada uno contiene 8 pares. Primero en el "cubo" son las ranuras para bits de hash adicionales (e0..e7 se llama e - porque
los bits de hash
adicionales ). A continuación se muestran primero las claves y los valores como una lista de todas las claves, luego una lista de todos los valores.
De acuerdo con el hash de la función, se determina en qué “cubeta” ponemos el valor, dentro de cada “cubeta” puede haber hasta 8 colisiones, al final de cada “cubeta” hay un puntero a una adicional, si la anterior se desborda.
¿Cómo crece el mapa?
En el código fuente puedes encontrar la línea:
es decir, si hay un promedio de más de 6.5 elementos en cada segmento, se produce un aumento en la matriz de segmentos. Al mismo tiempo, la matriz se asigna 2 veces más, y los datos antiguos se copian en pequeñas porciones cada inserción o eliminación, para no crear demoras muy grandes. Por lo tanto, todas las operaciones serán un poco más lentas en el proceso de evacuación de datos (al buscar, también tenemos que buscar en dos lugares). Después de una evacuación exitosa, comienzan a utilizarse nuevos datos.
Tomando la dirección del elemento del mapa.
Otro punto interesante: al comienzo del uso del lenguaje que quería hacer así:
package main import ( "fmt" ) func main() { m := make(map[int]int) m[1] = 10 a := &m[1] fmt.Println(m[1], *a) }
Pero Go dice: "no se puede tomar la dirección de m [1]". La explicación de por qué es imposible tomar la dirección del valor radica en el procedimiento de evacuación de datos. Imagine que tomamos la dirección del valor, y luego el mapa creció, se asignó nueva memoria, se evacuaron los datos, se eliminaron los antiguos, el puntero se volvió incorrecto, por lo que tales operaciones están prohibidas.
¿Cómo se implementa el mapa sin genéricos?
Ni una interfaz vacía, ni la generación de código tienen nada que ver con eso; todo es reemplazarlo en tiempo de compilación. Considere en qué se convierten las funciones familiares de Go:
v := m["k"] → func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer v, ok := m["k"] → func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) m["k"] = 9001 → func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer delete(m, "k") → func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)
Vemos que hay funciones de mapaccess para accesos, para escribir y eliminar mapassign y mapdelete, respectivamente. Todas las operaciones usan un puntero inseguro, que no le importa a qué tipo apunta, y la información sobre cada valor se describe mediante un
descriptor de tipo .
type mapType struct { key *_type elem *_type ...} type _type struct { size uintptr alg *typeAlg ...} type typeAlg struct { hash func(unsafe.Pointer, uintptr) uintptr equal func(unsafe.Pointer, unsafe.Pointer) bool...}
MapType almacena los descriptores (_type) de la clave y el valor. Para un descriptor de tipo, se definen las operaciones (typeAlg) de comparación, tomar un hash, tamaño, etc., por lo que siempre sabemos cómo producirlas.
Un poco más sobre cómo funciona. Cuando escribimos v = m [k] (tratando de obtener el valor de v de la clave k), el compilador genera algo como lo siguiente:
kPointer := unsafe.Pointer(&k) vPointer := mapaccess1(typeOf(m), m, kPointer) v = *(*typeOfvalue)vPointer
Es decir, tomamos un puntero a una clave, la estructura mapType, desde la cual descubrimos qué descriptores de la clave y el valor, el puntero a hmap (es decir, map) y lo pasamos todo a mapaccess1, que devolverá un puntero al valor. Lanzamos el puntero al tipo deseado, desreferenciamos y obtenemos el valor.
Ahora veamos el código de búsqueda del tiempo de ejecución (que está ligeramente adaptado para la lectura):
func lookup(t *mapType, m *mapHeader, key unsafe.Pointer) unsafe.Pointer {
La función busca la clave en el mapa y devuelve un puntero al valor correspondiente, los argumentos ya nos son familiares: esto es mapType, que almacena descriptores de los tipos y valores de clave, se asigna a sí mismo (mapHeader) y un puntero a la memoria que almacena la clave. Devolvemos un puntero a la memoria que almacena el valor.
if m == nil || m.count == 0 { return zero }
A continuación, verificamos si el puntero al encabezado del mapa no es nulo, si hay 0 elementos allí y devolvemos un valor nulo, si es así.
hash := t.key.hash(key, m.seed)
Calculamos el hash de la clave (sabemos cómo calcular una clave dada a partir de un descriptor de tipo). Luego tratamos de entender a qué "cubeta" debe ir y ver (el resto de la división entre el número de "cubetas", los cálculos se aceleran ligeramente). Luego calculamos el hash adicional (tomamos los 8 bits más significativos del hash) y determinamos la posición del “cubo” en la memoria (aritmética de direcciones).
for { for i := 0; i < 8; i++ { if b.extra[i] != extra {
La búsqueda, si nos fijamos, no es tan complicada: pasamos por las cadenas de "cubos", pasando al siguiente, si no lo encuentra. La búsqueda en el "depósito" comienza con una comparación rápida del hash adicional (es por eso que estos e0 ... e7 al comienzo de cada uno son un hash "mini" del par para una comparación rápida). Si no coincide, vaya más allá, si lo hace, entonces verificamos con más cuidado: determinamos dónde se encuentra la clave sospechosa de ser buscada en la memoria, comparamos si es igual a lo que se solicitó. Si es igual, determine la posición del valor en la memoria y regrese. Como puedes ver, nada sobrenatural.
Conclusión
Use mapas, pero sepa y entienda cómo funcionan. Puede evitar el rastrillo si comprende algunas de las sutilezas: por qué no puede tomar la dirección del valor, por qué todo cae durante la declaración sin inicialización, por qué es mejor asignar memoria por adelantado si se conoce el número de elementos (evitaremos las evacuaciones) y mucho más.
Referencias
"Ir mapas en acción", Andrew Gerrand"Cómo el tiempo de ejecución go implementa mapas de manera eficiente", Dave Cheney"Entendiendo el tipo en ir", William KennedyImplementación del mapa interior, Keith Randallcódigo fuente del mapa, Go Runtimeespecificaciones de golangir efectivogopher imágenes