¡Saludo, Khabrovites! La traducción del siguiente artículo fue preparada específicamente para estudiantes del curso de la
Plataforma de Infraestructura basada en Kubernetes , que comenzará las clases mañana. Empecemos

Autoescalado en Kubernetes
El escalado automático le permite aumentar y disminuir automáticamente las cargas de trabajo según el uso de los recursos.
El escalado automático de Kubernetes tiene dos dimensiones:
- Cluster Autoscaler, que es responsable de escalar nodos;
- Horizontal Pod Autoscaler (HPA), que escala automáticamente el número de hogares en un conjunto de implementación o réplica.
El autoescalado del clúster se puede usar junto con el autoescalado horizontal del hogar para controlar dinámicamente los recursos informáticos y el grado de concurrencia del sistema requerido para cumplir con los acuerdos de nivel de servicio (SLA).
El escalado automático de clúster depende en gran medida de las capacidades del proveedor de infraestructura en la nube que aloja el clúster, y HPA puede operar independientemente del proveedor IaaS / PaaS.
Desarrollo HPA
El autoescalado horizontal del hogar ha sufrido cambios importantes desde la introducción de Kubernetes v1.1. La primera versión de hogares escalados HPA basada en el consumo de CPU medido, y más tarde en función del uso de memoria. Kubernetes 1.6 introdujo una nueva API llamada Métricas personalizadas, que proporcionó acceso HPA a las métricas personalizadas. Kubernetes 1.7 agregó un nivel de agregación que permite que aplicaciones de terceros extiendan la API de Kubernetes registrándose como complementos de API.
Gracias a la API de métricas personalizadas y al nivel de agregación, los sistemas de monitoreo como Prometheus pueden proporcionar métricas específicas de la aplicación al controlador HPA.
El autoescalado horizontal del hogar se implementa como un bucle de control que consulta periódicamente la API de métricas de recursos (API de métricas de recursos) para métricas clave, como el uso de CPU y memoria, y la API de métricas personalizadas (API de métricas personalizadas) para métricas de aplicaciones específicas.
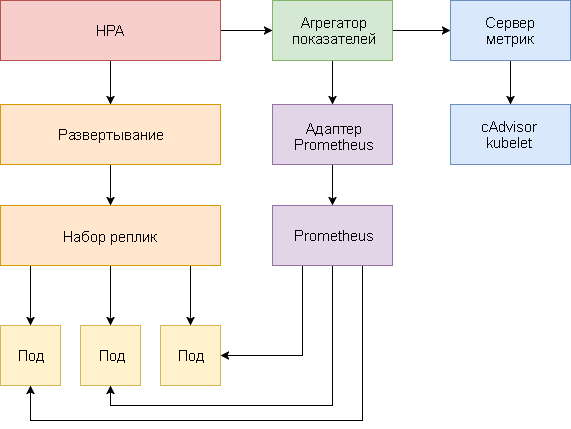
A continuación se muestra una guía paso a paso para configurar HPA v2 para Kubernetes 1.9 y versiones posteriores.
- Instale el complemento del servidor de métricas, que proporciona métricas clave.
- Inicie una aplicación de demostración para ver cómo funciona el autoescalado basado en el uso de la CPU y la memoria.
- Implemente Prometheus y el servidor API personalizado. Registre un servidor API personalizado en el nivel de agregación.
- Configure HPA utilizando métricas personalizadas proporcionadas por la aplicación de demostración.
Antes de comenzar, debe instalar Go versión 1.8 (o posterior) y clonar el
repositorio k8s-prom-hpa en
GOPATH :
cd $GOPATH git clone https:
1. Configurar el servidor de métricas
Kubernetes
Metric Server es el agregador de datos de utilización de recursos dentro del clúster que reemplaza a
Heapster . El servidor de métricas recopila información de uso de CPU y memoria para nodos y hogares de
kubernetes.summary_api . Summary API es una API de memoria eficiente para transmitir métricas de datos de Kubelet / cAdvisor a un servidor.
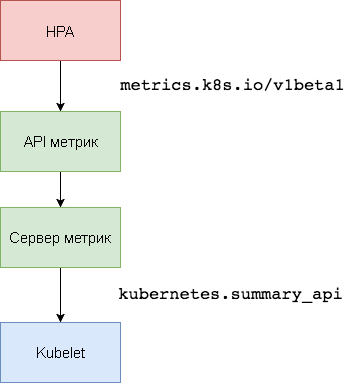
En la primera versión de HPA, se necesitaba un agregador Heapster para obtener la CPU y la memoria. En HPA v2 y Kubernetes 1.8, solo se requiere un servidor métrico con
horizontal-pod-autoscaler-use-rest-clients habilitado. Esta opción está habilitada por defecto en Kubernetes 1.9. GKE 1.9 viene con un servidor de métricas preinstalado.
Expanda el servidor de métricas en el espacio de nombres del
kube-system :
kubectl create -f ./metrics-server
Después de 1 minuto, el
metric-server comenzará a transmitir datos sobre el uso de la CPU y la memoria por parte de nodos y pods.
Ver métricas de nodo:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
Ver indicadores de frecuencia cardíaca:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2. Autoescalado basado en el uso de CPU y memoria
Para probar la escala automática horizontal del hogar (HPA), puede usar una pequeña aplicación web basada en Golang.
Expanda
podinfo en el espacio de nombres
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
Póngase en contacto con
podinfo utilizando el servicio NodePort en
http://<K8S_PUBLIC_IP>:31198 .
Especifique un HPA que servirá al menos dos réplicas y escalará a diez réplicas si la utilización promedio de la CPU excede el 80% o si el consumo de memoria es superior a 200 MiB:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
Crear HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml
Después de un par de segundos, el controlador HPA se pondrá en contacto con el servidor métrico y recibirá información sobre el uso de la CPU y la memoria:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
Para aumentar el uso de la CPU, realice una prueba de carga con rakyll / hey:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
Puede monitorear los eventos HPA de la siguiente manera:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Elimine podinfo temporalmente (deberá volver a implementarlo en uno de los siguientes pasos de esta guía).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3. Configuración personalizada del servidor de métricas
Para el escalado basado en métricas personalizadas, se necesitan dos componentes. La primera, la base de datos de la serie temporal
Prometheus , recopila las métricas de las aplicaciones y las guarda. El segundo componente, el
adaptador k8s-prometheus , complementa los Kubernetes API de métricas personalizadas con las métricas proporcionadas por el constructor.
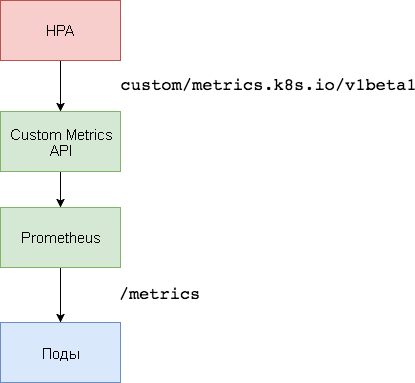
Se utiliza un espacio de nombres dedicado para implementar Prometheus y el adaptador.
Cree un espacio de nombres de
monitoring :
kubectl create -f ./namespaces.yaml
Expanda Prometheus v2 en el espacio de nombres de
monitoring :
kubectl create -f ./prometheus
Genere los certificados TLS necesarios para el adaptador Prometheus:
make certs
Implemente el adaptador Prometheus para la API de métricas personalizadas:
kubectl create -f ./custom-metrics-api
Obtenga una lista de métricas especiales proporcionadas por Prometheus:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
Luego extraiga los datos de uso del sistema de archivos para todos los pods en el espacio de nombres de
monitoring :
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4. Autoescalado basado en métricas personalizadas
Cree el servicio de podinfo
podinfo e
podinfo en el espacio de nombres
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
La aplicación
podinfo pasará la métrica especial
http_requests_total . El adaptador Prometheus eliminará el sufijo
_total y marcará esta métrica como un contador.
Obtenga el número total de consultas por segundo de la API de métricas personalizadas:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
La letra
m significa
milli-units , por lo que, por ejemplo, 901
901m es 901 milisegundos.
Cree un HPA que ampliará la implementación de podinfo si el número de solicitudes supera las 10 solicitudes por segundo:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
Expanda HPA
podinfo en el espacio de nombres
default :
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
Después de unos segundos, la HPA obtendrá el valor
http_requests de la API de métricas:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
Aplique la carga para el servicio podinfo con 25 solicitudes por segundo:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
Después de unos minutos, el HPA comenzará a escalar la implementación:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Con el número actual de solicitudes por segundo, la implementación nunca alcanzará un máximo de 10 pods. Tres réplicas son suficientes para garantizar que el número de solicitudes por segundo para cada pod sea inferior a 10.
Después de completar las pruebas de carga, HPA reducirá la escala de implementación al número inicial de réplicas:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Es posible que haya notado que el escalador automático no responde de inmediato a los cambios en las métricas. Por defecto, se sincronizan cada 30 segundos. Además, el escalamiento ocurre solo si no ha habido un aumento o disminución en las cargas de trabajo durante los últimos 3-5 minutos. Esto ayuda a evitar decisiones conflictivas y deja tiempo para conectar el autoescalador de clúster.
Conclusión
No todos los sistemas pueden exigir el cumplimiento de SLA basándose únicamente en la utilización de la CPU o la memoria (o ambas). La mayoría de los servidores web y servidores móviles para manejar picos de tráfico necesitan escalado automático en función de la cantidad de solicitudes por segundo.
Para aplicaciones ETL (de la carga de transformación de extracción inglesa: "extracción, transformación, carga"), se puede activar el escalado automático, por ejemplo, cuando se excede la longitud umbral especificada de la cola de trabajos.
En todos los casos, la instrumentación de aplicaciones con Prometheus y el resaltado de los indicadores necesarios para el escalado automático le permiten ajustar las aplicaciones para mejorar el procesamiento de los picos de tráfico y garantizar una alta disponibilidad de la infraestructura.
Ideas, preguntas, comentarios? ¡Únase a la discusión en
Slack !
Aquí hay tal material. ¡Esperamos tus comentarios y nos vemos en el
curso !