
Hola habrozhiteli! Este libro es adecuado para cualquier desarrollador que quiera comprender el procesamiento de transmisión. Comprender la programación distribuida lo ayudará a comprender mejor Kafka y Kafka Streams. Sería bueno conocer el marco Kafka en sí, pero esto no es necesario: te diré todo lo que necesitas. Gracias a este libro, los desarrolladores experimentados de Kafka, como los novatos, aprenderán cómo crear aplicaciones de transmisión interesantes utilizando la biblioteca Kafka Streams. Los desarrolladores de Java intermedios y de alto nivel familiarizados con conceptos como la serialización aprenderán cómo aplicar sus habilidades para crear aplicaciones de Kafka Streams. El código fuente del libro está escrito en Java 8 y esencialmente utiliza la sintaxis de las expresiones lambda de Java 8, por lo que la capacidad de trabajar con funciones lambda (incluso en otro lenguaje de programación) es útil para usted.
Extracto 5.3. Agregación y operaciones de ventana
En esta sección, pasamos a las partes más prometedoras de Kafka Streams. Hasta ahora hemos cubierto los siguientes aspectos de Kafka Streams:
- crear una topología de procesamiento;
- uso del estado en aplicaciones de transmisión;
- hacer conexiones de flujo de datos;
- diferencias entre secuencias de eventos (KStream) y secuencias de actualización (KTable).
En los siguientes ejemplos, juntaremos todos estos elementos. Además, se familiarizará con las operaciones de ventana, otra gran característica de las aplicaciones de transmisión. Nuestro primer ejemplo será la agregación simple.
5.3.1. Agregación de ventas de stock por industria
La agregación y la agrupación son herramientas vitales para trabajar con la transmisión de datos. Examinar registros individuales a medida que están disponibles a menudo no es suficiente. Para extraer información adicional de los datos, su agrupación y combinación son necesarias.
En este ejemplo, debe probar el traje de un comerciante intradía que necesita rastrear el volumen de ventas de acciones de compañías en varias industrias. En particular, está interesado en las cinco compañías con las mayores ventas de acciones en cada industria.
Para dicha agregación, necesitará varios de los siguientes pasos para traducir los datos a la forma deseada (en términos generales).
- Cree una fuente basada en temas que publique información de comercio de acciones sin procesar. Tendremos que asignar un objeto de tipo StockTransaction a un objeto de tipo ShareVolume. El hecho es que el objeto StockTransaction contiene metadatos de ventas, y solo necesitamos datos sobre la cantidad de acciones vendidas.
- Agrupe los datos de ShareVolume por símbolos de stock. Después de agrupar por símbolos, puede contraer estos datos en subtotales de ventas de acciones. Vale la pena señalar que el método KStream.groupBy devuelve una instancia de tipo KGroupedStream. Y puede obtener una instancia de KTable llamando al método KGroupedStream.reduce más tarde.
¿Qué es la interfaz KGroupedStream?
Los métodos KStream.groupBy y KStream.groupByKey devuelven una instancia de KGroupedStream. KGroupedStream es una representación intermedia de la secuencia de eventos después de la agrupación por clave. No está pensado para trabajar directamente con él. En cambio, KGroupedStream se usa para operaciones de agregación, cuyo resultado siempre es KTable. Y dado que el resultado de las operaciones de agregación es KTable y usan almacenamiento de estado, es posible que no todas las actualizaciones se envíen más adelante.
El método KTable.groupBy devuelve una KGroupedTable similar, una representación intermedia de la secuencia de actualizaciones reagrupadas por clave.
Tomemos un breve descanso y miremos la fig. 5.9, que muestra lo que hemos logrado. Esta topología ya debería serle familiar.
Ahora echemos un vistazo al código de esta topología (se puede encontrar en el archivo src / main / java / bbejeck / chapter_5 / AggregationsAndReducingExample.java) (Listado 5.2).
El código dado difiere en brevedad y en un gran volumen de acciones realizadas en varias líneas. En el primer parámetro del método builder.stream, puede notar algo nuevo para usted: el valor del tipo enumerado AutoOffsetReset.EARLIEST (también hay LATEST), establecido usando el método Consumed.withOffsetResetPolicy. Con este tipo enumerado, puede especificar una estrategia para restablecer las compensaciones para cada uno de KStream o KTable; tiene prioridad sobre el parámetro para restablecer las compensaciones desde la configuración.
GroupByKey y GroupBy
La interfaz de KStream tiene dos métodos para agrupar registros: GroupByKey y GroupBy. Ambos devuelven KGroupedTable, por lo que puede tener una pregunta legítima: ¿cuál es la diferencia entre ellos y cuándo usar cuál?
El método GroupByKey se usa cuando las claves en KStream ya no están vacías. Y lo más importante, la bandera "requiere volver a particionar" nunca se ha establecido.
El método GroupBy supone que ha cambiado las claves para la agrupación, por lo que el indicador de re-partición se establece en verdadero. La realización de conexiones, agregaciones, etc. después del método GroupBy conducirá a una nueva división automática.
Resumen: debe usar GroupByKey en lugar de GroupBy siempre que sea posible.
Lo que hacen los métodos mapValues y groupBy es comprensible, así que eche un vistazo al método sum () (se puede encontrar en el archivo src / main / java / bbejeck / model / ShareVolume.java) (Listado 5.3).
El método ShareVolume.sum devuelve el subtotal del volumen de ventas de acciones, y el resultado de toda la cadena de cálculo es un objeto KTable <String, ShareVolume>. Ahora entiendes qué papel juega KTable. Cuando llegan los objetos ShareVolume, la última actualización actual se guarda en la tabla K correspondiente. Es importante no olvidar que todas las actualizaciones se reflejan en el shareVolumeKTable anterior, pero no todas se envían más.
Además, con la ayuda de esta KTable, realizamos la agregación (por el número de acciones vendidas) para obtener las cinco compañías con las ventas de acciones más altas en cada industria. Nuestras acciones en este caso serán similares a las acciones durante la primera agregación.
- Realice otra operación groupBy para agrupar objetos ShareVolume individuales por sector.
- Proceda a resumir los objetos ShareVolume. Esta vez, el objeto de agregación es una cola prioritaria de un tamaño fijo. Solo cinco compañías con el mayor número de acciones vendidas se mantienen en una cola de tamaño fijo.
- Muestre las líneas del párrafo anterior en un valor de cadena y devuelva las cinco más vendidas por el número de acciones por industria.
- Escriba los resultados en forma de cadena para el tema.
En la fig. 5.10 muestra un gráfico de la topología del movimiento de datos. Como puede ver, la segunda ronda de procesamiento es bastante simple.
Ahora, habiendo entendido claramente la estructura de esta segunda ronda de procesamiento, puede consultar su código fuente (lo encontrará en el archivo src / main / java / bbejeck / chapter_5 / AggregationsAndReducingExample.java) (Listado 5.4).
Hay una variable fixedQueue en este inicializador. Este es un objeto personalizado: un adaptador para java.util.TreeSet, que se utiliza para rastrear N resultados más altos en orden descendente del número de acciones vendidas.
Ya ha encontrado llamadas a groupBy y mapValues, por lo que no nos detendremos en ellas (llamamos al método KTable.toStream, ya que el método KTable.print está en desuso). Pero aún no ha visto la versión KTable del método agregar (), por lo que pasaremos un tiempo discutiéndolo.
Como recordará, KTable se distingue por el hecho de que los registros con las mismas claves se consideran actualizaciones. KTable reemplaza el registro anterior por el nuevo. La agregación ocurre de la misma manera: se agregan los últimos registros con una clave. Cuando llega un registro, se agrega a una instancia de la clase FixedSizePriorityQueue usando un sumador (el segundo parámetro en la llamada al método agregado), pero si ya existe otro registro con la misma clave, el registro anterior se elimina usando el sustractor (el tercer parámetro en la llamada al método agregado).
Todo esto significa que nuestro agregador, FixedSizePriorityQueue, no agrega todos los valores con una clave, sino que almacena la suma móvil de las cantidades N de los tipos de acciones más vendidas. Cada entrada contiene el número total de acciones vendidas hasta el momento. KTable le proporcionará información sobre las acciones de las empresas que más se venden actualmente; no se requiere la agregación continua de cada actualización.
Aprendimos a hacer dos cosas importantes:
- agrupar valores en KTable por una clave común a ellos;
- Realice operaciones útiles como convolución y agregación en estos valores agrupados.
La capacidad de realizar estas operaciones es importante para comprender el significado de los datos que se mueven a través de la aplicación Kafka Streams y descubrir qué información llevan.
También hemos reunido algunos de los conceptos clave discutidos anteriormente en este libro. En el Capítulo 4, hablamos sobre la importancia de un estado local a prueba de fallas para una aplicación de transmisión. El primer ejemplo en este capítulo mostró por qué el estado local es tan importante: permite rastrear la información que ya ha visto. El acceso local evita demoras en la red, haciendo que la aplicación sea más productiva y resistente a errores.
Al realizar cualquier operación de convolución o agregación, debe especificar el nombre del almacén de estado. Las operaciones de convolución y agregación devuelven una instancia de KTable, y KTable usa un almacén de estado para reemplazar los resultados antiguos por otros nuevos. Como ha visto, no todas las actualizaciones se envían más adelante, y esto es importante, ya que las operaciones de agregación están diseñadas para obtener la información final. Si no se aplica el estado local, KTable enviará aún más todos los resultados de agregación y convolución.
A continuación, observamos la ejecución de operaciones como la agregación, dentro de un período específico de tiempo, las llamadas operaciones de ventanas.
5.3.2. Operaciones de ventana
En la sección anterior, presentamos la convolución y agregación "continua". La aplicación realizó una convolución continua de ventas de acciones con la agregación posterior de las cinco acciones más vendidas.
A veces es necesaria tal agregación continua y convolución de resultados. Y a veces solo necesita realizar operaciones en un período de tiempo determinado. Por ejemplo, calcule cuántas transacciones en bolsa se han realizado con acciones de una empresa en particular en los últimos 10 minutos. O cuántos usuarios hicieron clic en un nuevo banner publicitario en los últimos 15 minutos. Una aplicación puede realizar tales operaciones varias veces, pero con resultados relacionados solo con intervalos de tiempo específicos (ventanas de tiempo).
Contar transacciones de cambio por comprador
En el siguiente ejemplo, participaremos en el seguimiento de las transacciones de cambio para varios operadores, ya sean grandes organizaciones o financistas individuales inteligentes.
Hay dos posibles razones para este seguimiento. Uno de ellos es la necesidad de saber qué compran / venden los líderes del mercado. Si estos grandes jugadores e inversores sofisticados ven oportunidades para sí mismos, tiene sentido seguir su estrategia. La segunda razón es el deseo de notar cualquier posible signo de transacciones ilegales utilizando información privilegiada. Para hacer esto, deberá analizar la correlación de los picos grandes en las ventas con comunicados de prensa importantes.
Dicho seguimiento consta de pasos tales como:
- crear una secuencia para leer del tema de transacciones de acciones;
- agrupación de registros entrantes por ID de cliente y símbolo de stock del stock. Una llamada al método groupBy devuelve una instancia de la clase KGroupedStream;
- KGroupedStream.windowedBy devuelve un flujo de datos limitado por una ventana temporal, que permite la agregación de ventanas. Dependiendo del tipo de ventana, se devuelve TimeWindowedKStream o SessionWindowedKStream;
- Contando transacciones para una operación de agregación. El flujo de datos de la ventana determina si un registro particular se tiene en cuenta en este cálculo;
- escribir resultados en un tema o enviarlos a la consola durante el desarrollo.
La topología de esta aplicación es simple, pero su imagen visual no duele. Echa un vistazo a la foto. 5.11.
Además consideraremos la funcionalidad de las operaciones de ventana y el código correspondiente.
Tipos de ventanas
Hay tres tipos de ventanas en Kafka Streams:
- sesión
- Tumbling (caída);
- deslizamiento / "salto" (deslizamiento / salto).
Cuál elegir depende de los requisitos comerciales. Las ventanas de "caída" y "salto" están limitadas en el tiempo, mientras que las restricciones de sesión están asociadas con las acciones del usuario: la duración de la (s) sesión (s) se determina únicamente por la forma activa en que se comporta el usuario. Lo principal es no olvidar que todos los tipos de ventanas se basan en sellos de registros de fecha / hora y no en la hora del sistema.
A continuación, implementamos nuestra topología con cada uno de los tipos de ventana. El código completo se dará solo en el primer ejemplo, nada cambiará para otros tipos de ventanas, excepto para el tipo de operación de la ventana.
Ventanas de sesión
Las ventanas de sesión son muy diferentes de todos los demás tipos de ventanas. Están limitados no tanto por el tiempo como por la actividad del usuario (o la actividad de la entidad que desea rastrear). Las ventanas de sesión están delimitadas por períodos de inactividad.
La figura 5.12 ilustra el concepto de ventanas de sesión. Una sesión más pequeña se fusionará con la sesión a su izquierda. Y la sesión de la derecha será separada, ya que sigue un largo período de inactividad. Las ventanas de sesión se basan en las acciones del usuario, pero aplique marcas de fecha / hora de los registros para determinar a qué sesión pertenece el registro.
Uso de Windows de sesión para rastrear transacciones de Exchange
Utilizaremos ventanas de sesión para capturar información sobre transacciones de intercambio. La implementación de las ventanas de sesión se muestra en el Listado 5.5 (que se puede encontrar en src / main / java / bbejeck / chapter_5 / CountingWindowingAndKTableJoinExample.java).
Ya ha cumplido con la mayoría de las operaciones de esta topología, por lo que no es necesario considerarlas aquí nuevamente. Pero hay varios elementos nuevos que discutiremos ahora.
Para cualquier operación groupBy, generalmente se realiza algún tipo de operación de agregación (agregación, convolución o conteo). Puede realizar una agregación acumulativa con un total acumulativo o una agregación de ventana, en la que los registros se tienen en cuenta dentro de una ventana de tiempo determinada.
El código en el Listado 5.5 cuenta el número de transacciones dentro de las ventanas de sesión. En la fig. 5.13 estas acciones se analizan paso a paso.
Al llamar a windowedBy (SessionWindows.with (twentySeconds) .until (fifteenMinutes)) creamos una ventana de sesión con un intervalo inactivo de 20 segundos y un intervalo de retención de 15 minutos. Un intervalo de inactividad de 20 segundos significa que la aplicación incluirá cualquier registro que llegue dentro de los 20 segundos desde el final o el comienzo de la sesión actual en la sesión actual (activa).
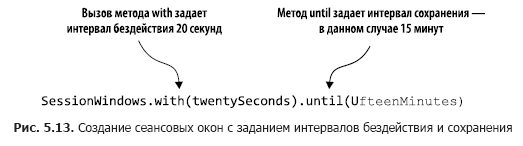
A continuación, indicamos qué operación de agregación realizar en la ventana de sesión, en este caso, contar. Si el registro entrante cae fuera del intervalo de inactividad (a cada lado de la marca de fecha / hora), la aplicación crea una nueva sesión. El intervalo de guardado significa mantener la sesión durante un tiempo determinado y permite datos tardíos que van más allá del período de inactividad de la sesión, pero que aún pueden adjuntarse. Además, el inicio y el final de una nueva sesión resultante de la fusión corresponden a la marca de fecha / hora más temprana y más reciente.
Veamos algunas entradas del método de conteo para ver cómo funcionan las sesiones (Tabla 5.1).
Al recibir los registros, buscamos sesiones ya existentes con la misma clave, la hora de finalización es menor que la marca de fecha / hora actual: el intervalo de inactividad y la hora de inicio es mayor que la marca de fecha / hora actual + intervalo de inactividad. Con esto en mente, cuatro registros de la tabla. 5.1 fusionarse en una sola sesión de la siguiente manera.
1. El registro 1 es lo primero, por lo que la hora de inicio es igual a la hora de finalización y es 00:00:00.
2. Luego viene el registro 2, y buscamos sesiones que finalicen no antes de las 23:59:55 y comiencen no más tarde de las 00:00:35. Busque el registro 1 y combine las sesiones 1 y 2. Tome la hora de inicio de la sesión 1 (antes) y la hora de finalización de la sesión 2 (más tarde), para que nuestra nueva sesión comience a las 00:00:00 y termine a las 00:00:15.
3. Llega el registro 3, buscamos sesiones entre 00:00:30 y 00:01:10 y no encontramos ninguna. Agregue una segunda sesión para la clave 123-345-654, FFBE, comenzando y terminando a las 00:00:50.
4. Llega el registro 4 y buscamos sesiones entre las 23:59:45 y las 00:00:25. Esta vez hay dos sesiones: 1 y 2. Las tres sesiones se combinan en una, con una hora de inicio de 00:00:00 y una hora de finalización de 00:00:15.
De lo que se dice en esta sección, vale la pena recordar los siguientes matices importantes:
- Las sesiones no son ventanas de tamaño fijo. La duración de una sesión está determinada por la actividad dentro de un período de tiempo determinado;
- Las marcas de fecha / hora en los datos determinan si un evento cae en una sesión existente o en un período de inactividad.
Además, analizaremos el siguiente tipo de ventanas: ventanas de "salto mortal".
Ventanas que caen
Las ventanas "caídas" capturan eventos que caen dentro de un cierto período de tiempo. Imagine que necesita capturar todas las transacciones de intercambio de una empresa cada 20 segundos, para que pueda recopilar todos los eventos durante este período de tiempo. Al final del intervalo de 20 segundos, la ventana "cae" y cambia a un nuevo intervalo de observación de 20 segundos. La figura 5.14 ilustra esta situación.
Como puede ver, todos los eventos recibidos en los últimos 20 segundos se incluyen en la ventana. Al final de este período de tiempo, se crea una nueva ventana.
El listado 5.6 muestra el código que demuestra el uso de ventanas giratorias para capturar transacciones de intercambio cada 20 segundos (puede encontrarlo en src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java).
Gracias a este pequeño cambio en la llamada al método TimeWindows.of, puede usar la ventana de caída. En este ejemplo, no hay llamada al método until (), como resultado de lo cual se utilizará el intervalo de guardado predeterminado de 24 horas.
Finalmente, es hora de pasar a la última de las opciones de ventana: saltar ventanas.
Ventanas deslizantes ("saltantes")
Las ventanas deslizantes / de "salto" son similares a las "caídas", pero con una ligera diferencia. Las ventanas deslizantes no esperan el final del intervalo de tiempo antes de crear una nueva ventana para manejar eventos recientes. Comienzan nuevos cálculos después de un intervalo de espera más corto que la duración de la ventana.
Para ilustrar las diferencias entre las ventanas "salto mortal" y "salto", volvamos al ejemplo con el cálculo de las transacciones de cambio. Nuestro objetivo, como antes, es contar el número de transacciones, pero no queremos esperar todo el tiempo antes de actualizar el contador. En cambio, actualizaremos el contador a intervalos más cortos. Por ejemplo, continuaremos contando el número de transacciones cada 20 segundos, pero para actualizar el contador cada 5 segundos, como se muestra en la Fig. 5.15. Al mismo tiempo, tenemos tres ventanas de resultados con datos superpuestos.
El listado 5.7 muestra el código para especificar ventanas deslizantes (se puede encontrar en src / main / java / bbejeck / chapter_5 / CountingWindowingAndKtableJoinExample.java).
«» «» advanceBy(). 15 .
, . , , :
, KTable KStream .
5.3.3. KStream KTable
4 KStream. KTable KStream. . KStream — , KTable — , KTable.
. , .
- KTable KStream , , .
- KTable, . KTable .
- .
, .
KTable KStream
KTable KStream .
- KTable.toStream().
- KStream.map , Windowed TransactionSummary.
( src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) ( 5.8).
KStream.map, KStream .
, KTable .
KTable
, KTable ( src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) ( 5.9).
, Serde , Serde. EARLIEST .
— .
. , ( src/main/java/bbejeck/chapter_5/CountingWindowingAndKtableJoinExample.java) ( 5.10).
leftJoin . 4, JoinWindow , KStream-KTable KTable . : KTable, . : KTable KStream .
KStream.
5.3.4. GlobalKTable
, . 4 KStream, — KStream KTable. . , Kafka Streams . , , ( 4, « » 4.2.4).
— , ; . , , .
, , , . Kafka Streams GlobalKTable.
GlobalKTable , . , , . GlobalKTable . .
KStream GlobalKTable
5.3.2 . :
{customerId='074-09-3705', stockTicker='GUTM'}, 17 {customerId='037-34-5184', stockTicker='CORK'}, 16
Aunque estos resultados fueron consistentes con el objetivo, sería más conveniente si también se mostraran el nombre del cliente y el nombre completo de la empresa. Para agregar el nombre de un cliente y el nombre de una empresa, puede realizar conexiones normales, pero deberá hacer dos asignaciones clave y volver a particionar. Con GlobalKTable puede evitar el costo de tales operaciones.
Para hacer esto, utilizaremos el objeto countStream del Listado 5.11 (el código correspondiente se puede encontrar en el archivo src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java), conectándolo con dos objetos GlobalKTable.
Ya hemos discutido esto antes, así que no lo repetiré. Pero noto que el código en toStream (). La función Map se abstrae en el objeto de la función en aras de la legibilidad en lugar de la expresión lambda incrustada.
El siguiente paso es declarar dos instancias de GlobalKTable (el código que se muestra se puede encontrar en src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java) (Listado 5.12).
Tenga en cuenta que los nombres de los temas se describen utilizando tipos enumerados.
Ahora que hemos preparado todos los componentes, queda por escribir el código para la conexión (que se puede encontrar en el archivo src / main / java / bbejeck / chapter_5 / GlobalKTableExample.java) (Listado 5.13).
Aunque hay dos compuestos en este código, están organizados en una cadena, ya que ninguno de sus resultados se usa por separado. Los resultados se muestran al final de toda la operación.
Cuando inicie la operación de conexión anterior, obtendrá los siguientes resultados:
{customer='Barney, Smith' company="Exxon", transactions= 17}
La esencia no ha cambiado, pero estos resultados parecen más claros.
Contando el Capítulo 4, ya has visto varios tipos de conexiones en acción. Se enumeran en la tabla. 5.2. Esta tabla refleja la conectividad relevante a la versión 1.0.0 de Kafka Streams; algo cambiará en futuras versiones.
En conclusión, le recordaré lo principal: puede conectar secuencias de eventos (KStream) y actualizaciones de secuencias (KTable) utilizando el estado local. Además, si el tamaño de los datos de referencia no es demasiado grande, puede usar el objeto GlobalKTable. GlobalKTable replica todas las secciones en cada uno de los nodos de la aplicación Kafka Streams, asegurando así la disponibilidad de todos los datos, independientemente de la sección a la que corresponda la clave.
A continuación veremos la posibilidad de Kafka Streams, gracias a la cual puede observar los cambios de estado sin consumir datos del tema Kafka.
5.3.5. Estado de solicitud
Ya hemos realizado varias operaciones relacionadas con el estado y siempre enviamos los resultados a la consola (para fines de desarrollo) o los escribimos en el tema (para operaciones industriales). Al escribir resultados en un tema, debe usar el consumidor Kafka para verlos.
La lectura de datos de estos temas puede considerarse una especie de vistas materializadas. Para nuestras tareas, podemos usar la definición de una vista materializada de Wikipedia: “... un objeto de base de datos físico que contiene los resultados de una consulta. Por ejemplo, puede ser una copia local de datos eliminados, o un subconjunto de las filas y / o columnas de una tabla o resultados de unión, o una tabla dinámica obtenida mediante agregación ”(https://en.wikipedia.org/wiki/Materialized_view).
Kafka Streams también le permite realizar consultas interactivas en tiendas estatales, lo que le permite leer directamente estas vistas materializadas. Es importante tener en cuenta que la solicitud a la tienda estatal tiene el carácter de una operación de solo lectura. Gracias a esto, no puede tener miedo de convertir accidentalmente el estado en una aplicación inconsistente durante el procesamiento de datos.
La capacidad de consultar directamente los almacenes de estado es importante. Significa que puede crear aplicaciones: paneles sin tener que recibir primero datos de un consumidor de Kafka. Aumenta la eficiencia de la aplicación, debido al hecho de que no es necesario volver a registrar datos:
- Debido a la localidad de los datos, puede acceder rápidamente a ellos.
- Se excluye la duplicación de datos, ya que no se escriben en el almacenamiento externo.
Lo principal que me gustaría que recuerde: puede ejecutar directamente solicitudes de estado desde la aplicación. No puede sobreestimar las oportunidades que esto le brinda. En lugar de consumir datos de Kafka y almacenar registros en la base de datos para la aplicación, puede consultar almacenes de estado con el mismo resultado. Las solicitudes directas a las tiendas estatales significan menos código (sin consumidor) y menos software (no se necesita una tabla de base de datos para almacenar los resultados).
Hemos cubierto una cantidad considerable de información en este capítulo, por lo que detendremos temporalmente nuestra discusión sobre consultas interactivas a las tiendas estatales. Pero no se preocupe: en el Capítulo 9 crearemos una aplicación simple: un panel de información con consultas interactivas. Para demostrar consultas interactivas y las posibilidades de agregarlas a las aplicaciones de Kafka Streams, utilizará algunos de los ejemplos de este y los capítulos anteriores.
Resumen
- Los objetos KStream representan secuencias de eventos comparables a las inserciones de bases de datos. Los objetos de KTable representan flujos de actualización, son más similares a las actualizaciones en la base de datos. El tamaño del objeto KTable no crece; los registros antiguos se reemplazan por otros nuevos.
- Los objetos KTable son necesarios para las operaciones de agregación.
- Con las operaciones de ventana, puede dividir los datos agregados en cestas de tiempo.
- Gracias a los objetos de GlobalKTable, puede acceder a los datos de referencia en cualquier lugar de la aplicación, independientemente de la sección.
- Las conexiones entre objetos KStream, KTable y GlobalKTable son posibles.
Hasta ahora, nos hemos centrado en crear aplicaciones Kafka Streams utilizando el DSL KStream de alto nivel. Aunque un enfoque de alto nivel le permite crear programas limpios y concisos, su uso es un compromiso definitivo. Trabajar con DSL KStream significa aumentar la concisión del código al reducir el grado de control. En el próximo capítulo, veremos la API de bajo nivel de los nodos del controlador e intentaremos otras compensaciones. Los programas serán más largos de lo que eran hasta ahora, pero tendremos la oportunidad de crear casi cualquier nodo de procesamiento que podamos necesitar.
→ Se pueden encontrar más detalles sobre el libro en
el sitio web del editor→ Para Khabrozhiteley 25% de descuento en cupones -
Kafka Streams→ Tras el pago de la versión en papel del libro, se envía un libro electrónico por correo electrónico.