A pesar de que la mayoría de la industria de TI implementa soluciones de infraestructura basadas en contenedores y soluciones en la nube, es necesario comprender las limitaciones de estas tecnologías. Tradicionalmente, Docker, Linux Containers (LXC) y Rocket (rkt) no están realmente aislados porque comparten el núcleo del sistema operativo principal en su trabajo. Sí, son efectivos en términos de recursos, pero el número total de vectores de ataque estimados y las pérdidas potenciales por piratería aún son grandes, especialmente en el caso de un entorno de nube multiinquilino en el que se encuentran los contenedores.

La raíz de nuestro problema radica en la delimitación débil de los contenedores en el momento en que el sistema operativo host crea un área de usuario virtual para cada uno de ellos. Sí, la investigación y el desarrollo se han llevado a cabo con el objetivo de crear "contenedores" reales con una caja de arena completa. Y la mayoría de las soluciones resultantes conducen a una reestructuración de los límites entre contenedores para mejorar su aislamiento. En este artículo, veremos cuatro proyectos únicos de IBM, Google, Amazon y OpenStack, respectivamente, que utilizan diferentes métodos para lograr el mismo objetivo: crear un aislamiento confiable. Entonces, IBM Nabla despliega contenedores sobre Unikernel, Google gVisor crea un kernel invitado especializado, Amazon Firecracker utiliza un hipervisor extremadamente liviano para aplicaciones de sandbox, y OpenStack coloca contenedores en una máquina virtual especializada optimizada para herramientas de orquestación.
Resumen de la tecnología moderna de contenedores
Los contenedores son una forma moderna de empaquetar, compartir e implementar una aplicación. A diferencia de una aplicación monolítica, en la que todas las funciones se empaquetan en un solo programa, las aplicaciones de contenedor o los microservicios están destinados a un uso específico y se especializan en una sola tarea.
Un contenedor incluye todas las dependencias (por ejemplo, paquetes, bibliotecas y binarios) que una aplicación necesita para completar su tarea específica. Como resultado, las aplicaciones en contenedores son independientes de la plataforma y pueden ejecutarse en cualquier sistema operativo, independientemente de la versión o los paquetes instalados. Esta conveniencia ahorra a los desarrolladores una gran cantidad de trabajo en la adaptación de diferentes versiones de software para diferentes plataformas o clientes. Aunque conceptualmente no es del todo exacto, a muchas personas les gusta pensar en los contenedores como "máquinas virtuales livianas".
Cuando un contenedor se implementa en un host, los recursos de cada contenedor, como su sistema de archivos, proceso y pila de red, se colocan en un entorno prácticamente aislado al que otros contenedores no pueden acceder. Esta arquitectura permite que cientos y miles de contenedores se ejecuten simultáneamente en un solo clúster, y cada aplicación (o microservicio) se puede escalar fácilmente replicando una gran cantidad de instancias.
En este caso, el diseño del contenedor se basa en dos "bloques de construcción" clave: el espacio de nombres de Linux y los grupos de control de Linux (cgroups).
El espacio de nombres crea un espacio de usuario prácticamente aislado y proporciona a la aplicación recursos dedicados del sistema, como el sistema de archivos, la pila de red, la identificación del proceso y la identificación del usuario. En este espacio de usuario aislado, la aplicación controla el directorio raíz del sistema de archivos y se puede ejecutar como raíz. Este espacio abstracto permite que cada aplicación funcione de forma independiente, sin interferir con otras aplicaciones que viven en el mismo host. Actualmente hay seis espacios de nombres disponibles: montaje, comunicación entre procesos (ipc), sistema de tiempo compartido UNIX (uts), id de proceso (pid), red y usuario. Se propone completar esta lista con dos espacios de nombres adicionales: tiempo y syslog, pero la comunidad de Linux aún no ha decidido las especificaciones finales.
Cgroups proporciona limitación de recursos de hardware, priorización, monitoreo y control de aplicaciones. Un ejemplo de los recursos de hardware que pueden controlar es el procesador, la memoria, el dispositivo y la red. Al combinar el espacio de nombres y los grupos de c, podemos ejecutar múltiples aplicaciones de manera segura en el mismo host, con cada aplicación en su propio entorno aislado, que es la propiedad fundamental del contenedor.
La principal diferencia entre una máquina virtual (VM) y un contenedor es que la máquina virtual es virtualización a nivel de hardware, y el contenedor es virtualización a nivel de sistema operativo. El hipervisor VM emula el entorno de hardware para cada máquina, donde el tiempo de ejecución del contenedor ya emula el sistema operativo para cada objeto. Las máquinas virtuales comparten el hardware físico del host y los contenedores comparten tanto el hardware como el núcleo del sistema operativo. Dado que los contenedores generalmente comparten más recursos con el host, su trabajo con los ciclos de almacenamiento, memoria y CPU es mucho más eficiente que con una máquina virtual. Sin embargo, la desventaja de este acceso compartido es un problema en el plano de la seguridad de la información, ya que se establece la confianza entre los contenedores y el host. La figura 1 ilustra la diferencia arquitectónica entre un contenedor y una máquina virtual.
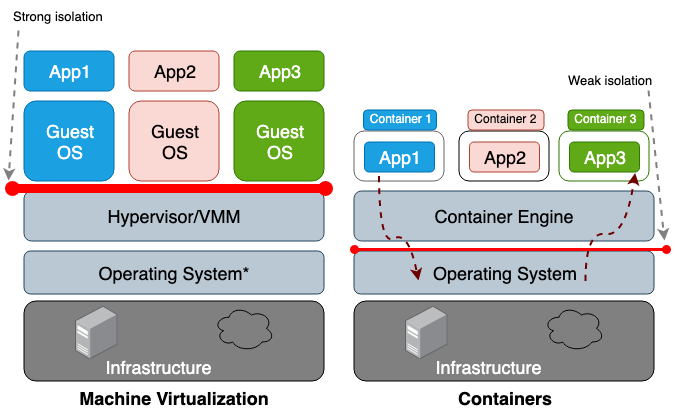
En general, el aislamiento de equipos virtualizados crea un perímetro de seguridad mucho más fuerte que el simple aislamiento de un espacio de nombres. El riesgo de que un atacante abandone con éxito un proceso aislado es mucho mayor que la posibilidad de abandonar con éxito la máquina virtual. La razón del mayor riesgo de ir más allá del entorno de contenedor limitado es el aislamiento deficiente creado por el espacio de nombres y los grupos c. Linux los implementa asociando nuevos campos de propiedad con cada proceso. Estos campos en el sistema de archivos
/proc indican al sistema operativo del host si un proceso puede ver a otro o cuántos recursos de procesador / memoria puede usar un proceso en particular. Al ver procesos y subprocesos en ejecución desde el sistema operativo principal (por ejemplo, el comando top o ps), el proceso del contenedor se parece a cualquier otro. Por lo general, las soluciones tradicionales, como LXC o Docker, no se consideran completamente aisladas porque usan el mismo núcleo dentro del mismo host. Por lo tanto, no es sorprendente que los contenedores tengan un número suficiente de vulnerabilidades. Por ejemplo, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123 y CVE-2019-5736 podrían provocar que un atacante obtenga acceso a datos fuera del contenedor.
La mayoría de las vulnerabilidades del kernel crean un vector para un ataque exitoso, porque generalmente resultan en la escalada de privilegios y permiten que un proceso comprometido obtenga el control fuera de su espacio de nombres previsto. Además de los vectores de ataque en el contexto de vulnerabilidades de software, la configuración incorrecta también puede desempeñar un papel. Por ejemplo, la implementación de imágenes con privilegios excesivos (CAP_SYS_ADMIN, acceso privilegiado) o puntos críticos de montaje (
/var/run/docker.sock ) puede provocar una fuga. Dadas estas consecuencias potencialmente catastróficas, debe comprender el riesgo que corre al implementar el sistema en un espacio multiinquilino o al usar contenedores para almacenar datos confidenciales.
Estos problemas motivan a los investigadores a crear perímetros de seguridad más fuertes. La idea es crear un contenedor de sandbox real que esté lo más aislado posible del sistema operativo principal. La mayoría de estas soluciones incluyen el desarrollo de una arquitectura híbrida que utiliza una distinción estricta entre la aplicación y la máquina virtual, y se enfoca en mejorar la eficiencia de las soluciones de contenedor.
Al momento de escribir este artículo, no había un solo proyecto que pudiera llamarse lo suficientemente maduro como para ser aceptado como estándar, pero en el futuro, los desarrolladores aceptarán indudablemente algunos de estos conceptos como los principales.
Comenzamos nuestra revisión con Unikernel, el sistema altamente especializado más antiguo que empaqueta una aplicación en una imagen usando un conjunto mínimo de bibliotecas del sistema operativo. El concepto de Unikernel en sí demostró ser fundamental para muchos proyectos cuyo objetivo era crear imágenes seguras, compactas y optimizadas. Después de eso, pasaremos a considerar IBM Nabla, un proyecto para lanzar aplicaciones Unikernel, incluidos los contenedores. Además, tenemos Google gVisor, un proyecto para lanzar contenedores en el espacio del kernel del usuario. A continuación, pasaremos a soluciones de contenedor basadas en máquinas virtuales: Amazon Firecracker y OpenStack Kata. Para resumir esta publicación comparando todas las soluciones anteriores.
Unikernel
El desarrollo de tecnologías de virtualización nos ha permitido pasar a la computación en la nube. Los hipervisores como Xen y KVM han sentado las bases de lo que ahora conocemos como Amazon Web Services (AWS) y Google Cloud Platform (GCP). Y aunque los hipervisores modernos pueden trabajar con cientos de máquinas virtuales combinadas en un solo clúster, los sistemas operativos tradicionales de propósito general no están demasiado adaptados y optimizados para funcionar en dicho entorno. El SO de propósito general está destinado, en primer lugar, a admitir y trabajar con tantas aplicaciones diferentes como sea posible, por lo tanto, sus núcleos incluyen todo tipo de controladores, bibliotecas, protocolos, programadores, etc. Sin embargo, la mayoría de las máquinas virtuales que ahora se implementan en algún lugar de la nube se utilizan para ejecutar una sola aplicación, por ejemplo, para proporcionar DNS, un proxy o algún tipo de base de datos. Dado que una aplicación de este tipo solo se basa en su trabajo en una parte pequeña y específica del núcleo del sistema operativo, todas sus otras "faldas" simplemente desperdician recursos del sistema y, por el solo hecho de su existencia, aumentan el número de vectores para un posible ataque. De hecho, cuanto más grande es la base del código, más difícil es eliminar todas las deficiencias y más vulnerabilidades, errores y otras debilidades potenciales. Este problema alienta a los especialistas a desarrollar sistemas operativos altamente especializados con un conjunto mínimo de funcionalidades del núcleo, es decir, crear herramientas para admitir una aplicación específica.
Por primera vez, la idea de Unikernel nació en los años 90. Luego tomó forma como una imagen especializada de una máquina con un solo espacio de direcciones que puede trabajar directamente en hipervisores. Empaqueta las aplicaciones y funciones principales y dependientes del núcleo en una sola imagen. Nemesis y Exokernel son las dos primeras versiones de investigación del proyecto Unikernel. El proceso de empaquetado y despliegue se muestra en la Figura 2.
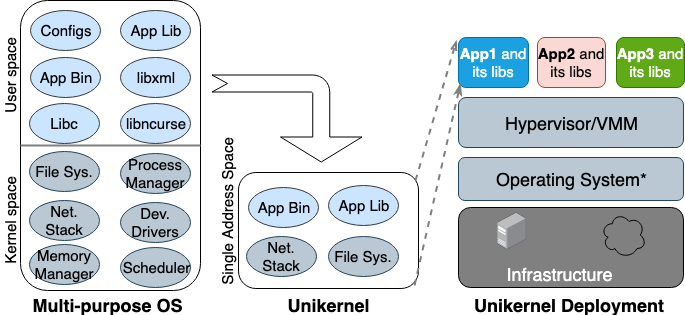 Figura 2. Sistemas operativos multipropósito diseñados para admitir todo tipo de aplicaciones, por lo que muchas bibliotecas y controladores se cargan por adelantado. Los Unikernels son sistemas operativos altamente especializados que están diseñados para admitir una aplicación específica.
Figura 2. Sistemas operativos multipropósito diseñados para admitir todo tipo de aplicaciones, por lo que muchas bibliotecas y controladores se cargan por adelantado. Los Unikernels son sistemas operativos altamente especializados que están diseñados para admitir una aplicación específica.
Unikernel divide el núcleo en varias bibliotecas y coloca solo los componentes necesarios en la imagen. Al igual que las máquinas virtuales normales, unikernel se implementa y se ejecuta en el hipervisor VM. Debido a su pequeño tamaño, puede cargarse rápidamente y también escalar rápidamente. Las características más importantes de Unikernel son una mayor seguridad, un tamaño reducido, un alto grado de optimización y una carga rápida. Dado que estas imágenes contienen solo bibliotecas dependientes de la aplicación, y el shell del sistema operativo no es accesible si no estaba conectado a propósito, la cantidad de vectores de ataque que los atacantes pueden usar en ellas es mínima.
Es decir, no solo es difícil para los atacantes obtener un punto de apoyo en estos núcleos únicos, sino que su influencia también se limita a una instancia central. Dado que el tamaño de las imágenes de Unikernel es de solo unos pocos megabytes, se descargan en decenas de milisegundos y, literalmente, cientos de instancias pueden ejecutarse en un solo host. Al utilizar la asignación de memoria en el mismo espacio de direcciones en lugar de una tabla de páginas multinivel, como es el caso en la mayoría de los sistemas operativos modernos, las aplicaciones unikernel tienen un menor retraso de acceso a la memoria en comparación con la misma aplicación que se ejecuta en una máquina virtual normal. Debido a que las aplicaciones se unen con el núcleo al construir la imagen, los compiladores simplemente pueden realizar una verificación de tipo estático para optimizar los archivos binarios.
Unikernel.org mantiene una lista de proyectos unikernel. Pero con todas sus características y propiedades distintivas, unikernel no se usa ampliamente. Cuando Docker adquirió Unikernel Systems en 2016, la comunidad decidió que la compañía ahora empacaría contenedores en ellos. Pero han pasado tres años y todavía no hay signos de integración. Una de las principales razones de esta implementación lenta es que todavía no existe una herramienta madura para crear aplicaciones Unikernel, y la mayoría de estas aplicaciones solo pueden funcionar en ciertos hipervisores. Además, portar una aplicación a unikernel puede requerir reescribir manualmente el código en otros idiomas, incluida la reescritura de bibliotecas de kernel dependientes. También es importante que el monitoreo o la depuración en unikernels sea imposible o tenga un impacto significativo en el rendimiento.
Todas estas restricciones evitan que los desarrolladores cambien a esta tecnología. Cabe señalar que unikernel y contenedores tienen muchas propiedades similares. Tanto el primero como el segundo son imágenes inmutables altamente enfocadas, lo que significa que los componentes dentro de ellos no pueden actualizarse o repararse, es decir, siempre debe crear una nueva imagen para el parche de la aplicación. Hoy, Unikernel es similar al antecesor de Docker: entonces el tiempo de ejecución del contenedor no estaba disponible y los desarrolladores tuvieron que usar las herramientas básicas para crear un entorno de aplicación aislado (chroot, unshare y cgroups).
Ibm nabla
Una vez, los investigadores de IBM propusieron el concepto de "Unikernel como un proceso", es decir, la aplicación unikernel que se ejecutaría como un proceso en un hipervisor especializado. El proyecto de IBM "contenedores Nabla" fortaleció el perímetro de seguridad de unikernel, reemplazando el hipervisor universal (por ejemplo, QEMU) con su propio desarrollo llamado Nabla Tender. La razón detrás de este enfoque es que las llamadas entre unikernel y el hipervisor aún proporcionan la mayoría de los vectores de ataque. Es por eso que el uso de un hipervisor dedicado a unikernel con menos llamadas al sistema permitidas puede fortalecer significativamente el perímetro de seguridad. Nabla Tender intercepta las llamadas que desvían las rutas al hipervisor y ya las traduce en solicitudes del sistema. Al mismo tiempo, la política seccomp Linux bloquea todas las demás llamadas al sistema que no son necesarias para que Tender funcione. Por lo tanto, Unikernel junto con Nabla Tender se ejecuta como un proceso en el espacio de usuario del host. A continuación, en la figura # 3, se muestra cómo Nabla crea una interfaz delgada entre unikernel y el host.
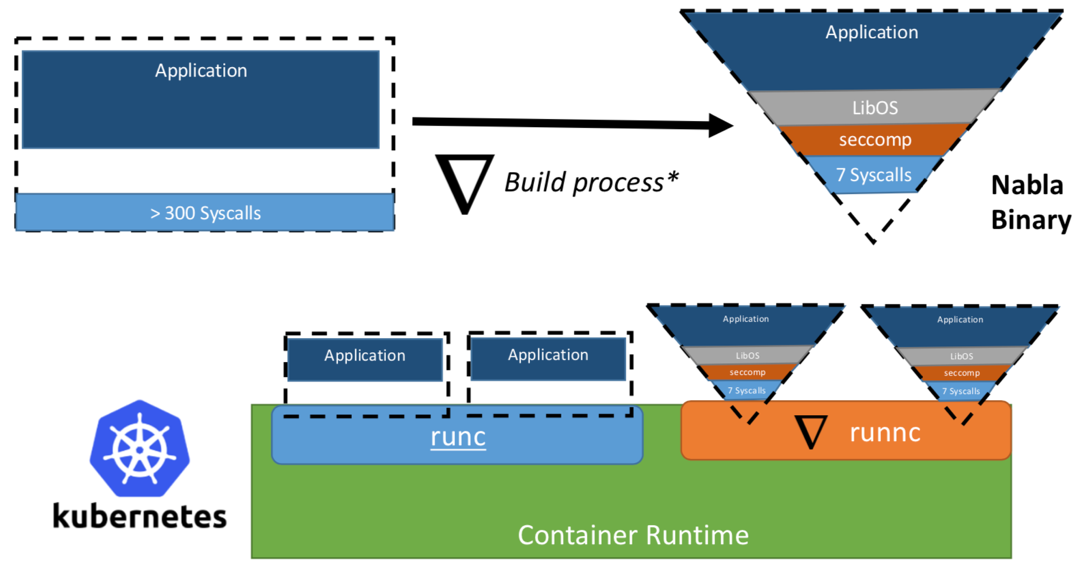 Figura 3. Para vincular Nabla con las plataformas de tiempo de ejecución de contenedores existentes, Nabla utiliza un entorno compatible con OCI, que a su vez se puede conectar a Docker o Kubernetes.
Figura 3. Para vincular Nabla con las plataformas de tiempo de ejecución de contenedores existentes, Nabla utiliza un entorno compatible con OCI, que a su vez se puede conectar a Docker o Kubernetes.Los desarrolladores afirman que Nabla Tender utiliza menos de siete llamadas al sistema en su trabajo para interactuar con el host. Dado que las llamadas al sistema sirven como una especie de puente entre los procesos en el espacio del usuario y el núcleo del sistema operativo, mientras menos llamadas tengamos disponibles, menor será el número de vectores disponibles para atacar el núcleo. Otra ventaja de ejecutar unikernel como proceso es que puede depurar dichas aplicaciones usando una gran cantidad de herramientas, por ejemplo, usando gdb.
Para trabajar con plataformas de orquestación de contenedores, Nabla proporciona un
runnc dedicado que se implementa utilizando el estándar Open Container Initiative (OCI). Este último define una API entre clientes (por ejemplo, Docker, Kubectl) y el entorno de tiempo de ejecución (por ejemplo, runc). Nabla también viene con un constructor de imágenes que
runnc luego podrá ejecutar. Sin embargo, debido a las diferencias en el sistema de archivos entre unikernels y contenedores tradicionales, las imágenes de Nabla no cumplen con las especificaciones de imagen OCI y, por lo tanto, las imágenes de Docker no son compatibles con
runnc . Al momento de escribir, el proyecto aún se encuentra en las primeras etapas de desarrollo. Existen otras restricciones, por ejemplo, la falta de soporte para montar / acceder a sistemas de archivos host, agregar varias interfaces de red (necesarias para Kubernetes) o usar imágenes de otras imágenes unikernel (por ejemplo, MirageOS).
Google gVisor
Google gVisor es una tecnología de espacio aislado que utiliza el motor de aplicaciones de Google Cloud Platform (GCP), las funciones de la nube y CloudML. En algún momento, Google se dio cuenta del riesgo de ejecutar aplicaciones no confiables en la infraestructura de la nube pública y la ineficiencia de las aplicaciones de sandbox que usan máquinas virtuales. Como resultado, se desarrolló un núcleo de espacio de usuario para un entorno aislado de aplicaciones poco confiables. gVisor coloca estas aplicaciones en el sandbox, interceptando todas las llamadas del sistema desde ellas al kernel host y procesándolas en el entorno del usuario utilizando el kernel gVisor Sentry. En esencia, funciona como una combinación de un núcleo invitado y un hipervisor. La Figura 4 muestra la arquitectura gVisor.
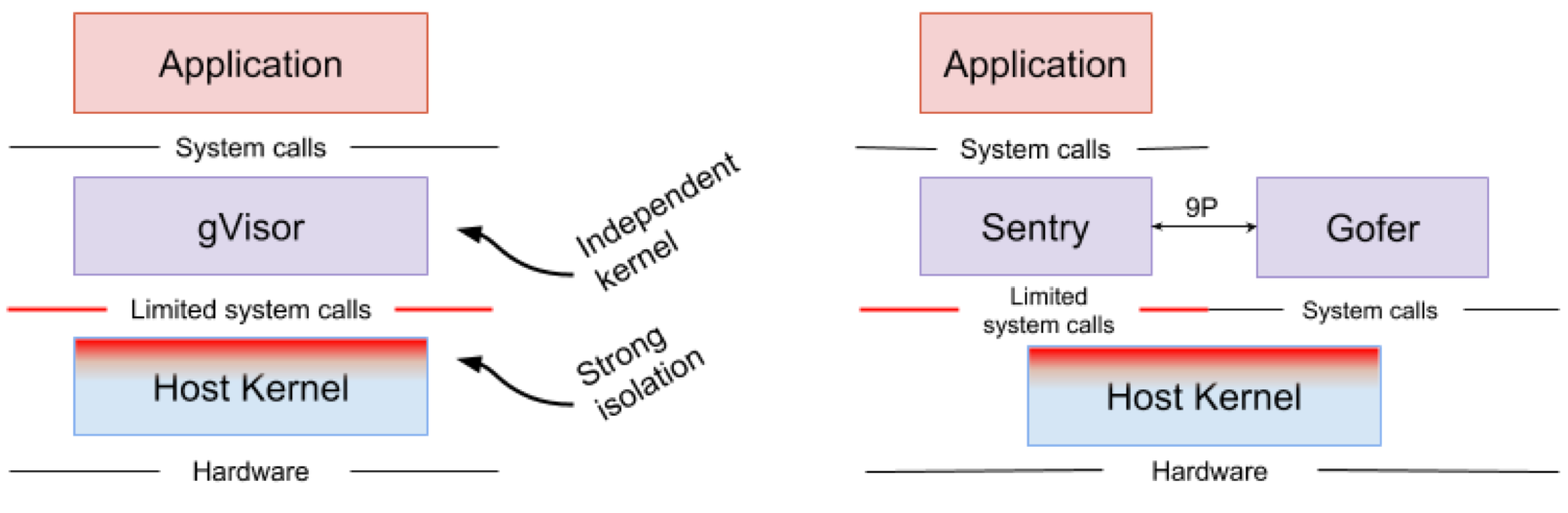 Figura 4. Implementación del kernel gVisor // Los sistemas de archivos Sentry y gVisor Gofer utilizan una pequeña cantidad de llamadas del sistema para interactuar con el host
Figura 4. Implementación del kernel gVisor // Los sistemas de archivos Sentry y gVisor Gofer utilizan una pequeña cantidad de llamadas del sistema para interactuar con el hostgVisor crea un fuerte perímetro de seguridad entre la aplicación y su host. Limita las llamadas al sistema que las aplicaciones pueden usar en el espacio del usuario. Sin depender de la virtualización, gVisor funciona como un proceso de host que interactúa entre una aplicación independiente y un host. Sentry admite la mayoría de las llamadas al sistema Linux y las características principales del núcleo, como la entrega de señal, la administración de memoria, la pila de red y el modelo de transmisión. Sentry implementa más del 70% de las 319 llamadas al sistema Linux para admitir aplicaciones de espacio aislado. Sin embargo, Sentry utiliza menos de 20 llamadas al sistema Linux para interactuar con el núcleo del host. Vale la pena señalar que gVisor y Nabla tienen una estrategia muy similar: proteger el sistema operativo host y ambas soluciones utilizan menos del 10% de las llamadas al sistema Linux para interactuar con el núcleo. Pero debe comprender que gVisor crea un núcleo multipropósito y, por ejemplo, Nabla se basa en núcleos únicos. Al mismo tiempo, ambas soluciones lanzan un núcleo invitado especializado en el espacio de usuario para admitir aplicaciones aisladas en las que confían.
Alguien puede preguntarse por qué gVisor necesita su propio núcleo, cuando el núcleo de Linux ya es de código abierto y de fácil acceso. , gVisor, Golang, , Linux, C. Golang. gVisor — Docker, Kubernetes OCI. Docker gVisor, gVisor runsc. Kubernetes «» gVisor «»-.
gVisor , . gVisor , , , . ( , Nabla , unikernel . Nabla hypercall). gVisor (passthrough), , , , GPU, . , gVisor 70% Linux, , , gVisor.
Amazon Firecracker
Amazon Firecracker — , AWS Lambda AWS Fargate. , « » (MicroVM) multi-tenant . Firecracker Lambda Fargate EC2 , . , , . Firecracker , , . Firecracker , . Linux ext4 . Amazon Firecracker 2017 , 2018 .
unikernel, Firecracker . micro-VM , . , micro-VM Firecracker 5 ~125 2 CPU + 256 RAM. 5 Firecracker .
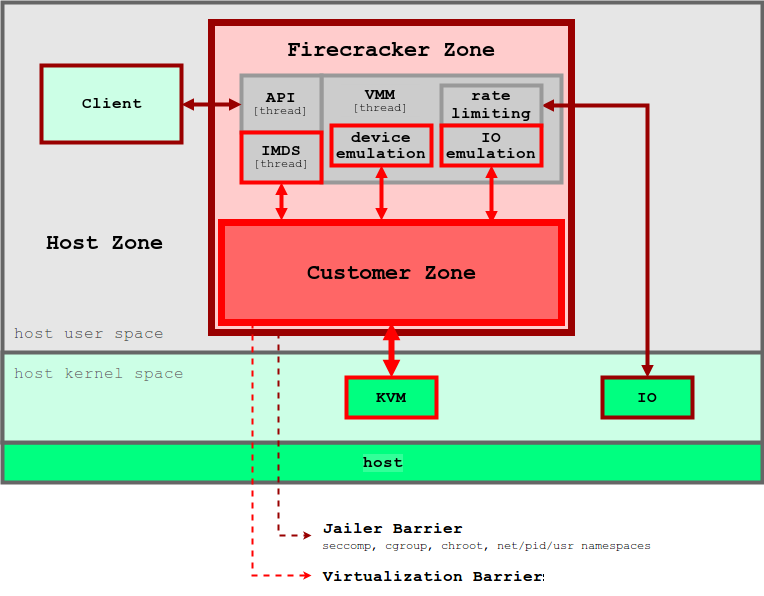 5. Firecracker
5. FirecrackerFirecracker KVM, . Firecracker seccomp, cgroups namespaces, , , . Firecracker . , API microVM. virtIO ( ). Firecracker microVM: virtio-block, virtio-net, serial console 1-button , microVM. . , , microVM File Block Devices, . , cgroups. , .
Firecracker Docker Kubernetes. Firecracker , , , . . , , OCI .
OpenStack Kata
, 2015 Intel Clear Containers. Clear Containers Intel VT QEMU-KVM
qemu-lite . 2017 Clear Containers Hyper RunV, OCI, Kata. Clear Containers, Kata .
Kata OCI, (CRI) (CNI). (, passthrough, MacVTap, bridge, tc mirroring) , , . 6 , Kata .
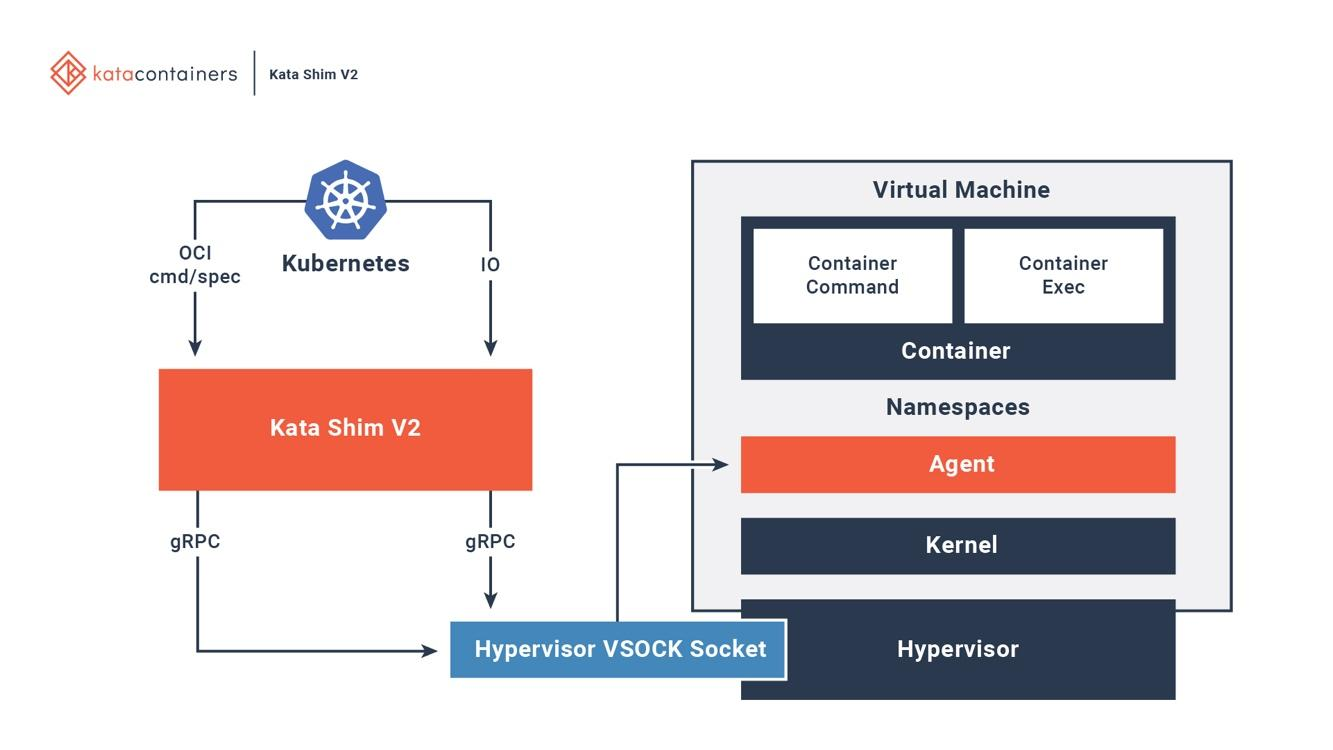 6. Kata Docker Kubernetes
6. Kata Docker KubernetesKata . Kata Kata Shim, API (, docker kubectl) VSock. Kata . NEMU — QEMU ~80% . VM-Templating Kata VM . , , , CVE-2015-2877. « » (, , , virtio), .
Kata Firecracker — «» , . , . Firecracker — , , Kata — , . Kata Firecracker. , .
Conclusión
, — .
IBM Nabla — unikernel, .
Google gVisor — , .
Amazon Firecracker — , .
OpenStack Kata — , .
, , . . Nabla , , unikernel-, MirageOS IncludeOS. gVisor Docker Kubernetes, - . Firecracker , . Kata OCI KVM, Xen. .
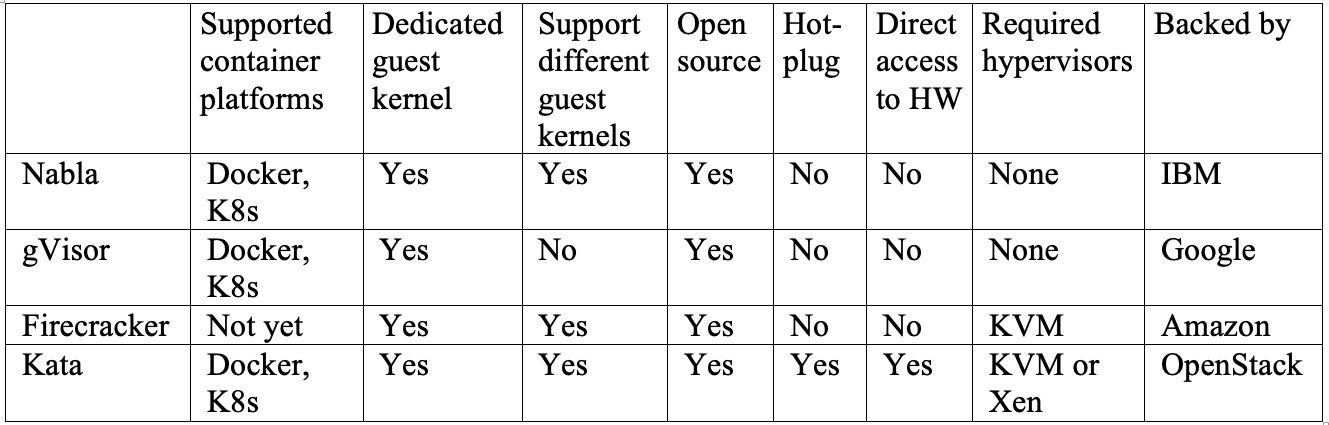
, , , , .