El ecosistema TensorFlow contiene una serie de compiladores y optimizadores que trabajan en varios niveles de la pila de software y hardware. Para aquellos que usan Tensorflow diariamente, esta pila de múltiples niveles puede generar errores difíciles de entender, tanto en tiempo de compilación como en tiempo de ejecución, asociados con el uso de varios tipos de hardware (GPU, TPU, plataformas móviles, etc.)
Estos componentes, comenzando con el gráfico de Tensorflow, se pueden representar en la forma de dicho diagrama:
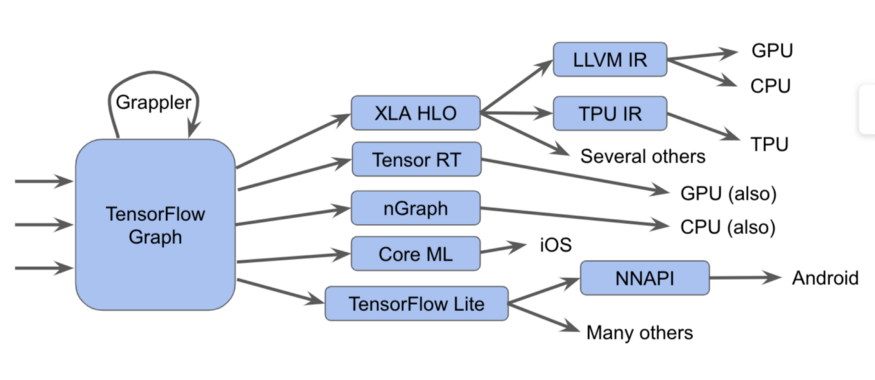 En realidad es más difícil
En realidad es más difícilEn este diagrama, podemos ver que los gráficos de Tensorflow se pueden ejecutar de varias maneras diferentes.
una notaEn TensorFlow 2.0, los gráficos pueden ser implícitos; la ejecución codiciosa puede ejecutar operaciones individualmente, en grupos o en un gráfico completo. Estos gráficos o fragmentos del gráfico deben optimizarse y ejecutarse.
Por ejemplo:
- Enviamos los gráficos al ejecutor de Tensorflow, que llama a núcleos especializados escritos a mano.
- Conviértalos a XLA HLO (representación del optimizador de alto nivel XLA): una representación de alto nivel del optimizador XLA, que, a su vez, puede llamar al compilador LLVM para la CPU o GPU, o continuar usando XLA para TPU , o combinarlos.
- Los convertimos a TensorRT , nGraph u otro formato para un conjunto de instrucciones especializadas implementado en hardware.
- Los convertimos al formato TensorFlow Lite , los ejecutamos en el tiempo de ejecución TensorFlow Lite o los convertimos a código para ejecutarlos en la GPU o DSP a través de la API de redes neuronales de Android (NNAPI) o similar.
También hay métodos más complejos, que incluyen muchos pases de optimización en cada capa, como, por ejemplo, en el marco Grappler, que optimiza las operaciones en TensorFlow.
Aunque estas diversas implementaciones de compiladores y representaciones intermedias mejoran el rendimiento, su diversidad plantea un problema para los usuarios finales, como mensajes de error confusos al emparejar estos subsistemas. Además, los creadores de nuevas pilas de software y hardware deben ajustar los pasos de optimización y conversión para cada nuevo caso.
Y en virtud de todo esto, nos complace anunciar MLIR, una representación intermedia de niveles múltiples. Este es un formato de vista intermedio y bibliotecas de compilación para usar entre una vista de modelo y un compilador de bajo nivel que genera código dependiente del hardware. Al presentar MLIR, queremos dar paso a nuevas investigaciones en el desarrollo de la optimización de compiladores e implementaciones de compiladores basados en componentes de calidad industrial.
Esperamos que MLIR sea de interés para muchos grupos, incluidos:
- investigadores compiladores, así como profesionales que desean optimizar el rendimiento y el consumo de memoria de los modelos de aprendizaje automático;
- fabricantes de hardware que buscan una forma de combinar su hardware con Tensorflow, como TPU, neuroprocesadores móviles en teléfonos inteligentes y otros ASIC personalizados;
- personas que desean brindar a los lenguajes de programación los beneficios proporcionados por la optimización de compiladores y aceleradores de hardware;
¿Qué es el MLIR?
MLIR es esencialmente una infraestructura flexible para compiladores de optimización modernos. Esto significa que consiste en una especificación de representación intermedia (IR) y un conjunto de herramientas para transformar esta representación. Cuando hablamos de compiladores, pasar de una vista de nivel superior a una vista de nivel inferior se denomina reducción, y utilizaremos este término en el futuro.
MLIR está construido bajo la influencia de LLVM y presta descaradamente muchas buenas ideas. Tiene un sistema de tipo flexible y está diseñado para representar, analizar y transformar gráficos, combinando muchos niveles de abstracción en un nivel de compilación. Estas abstracciones incluyen operaciones de Tensorflow, regiones de bucles poliédricos anidados, instrucciones de LLVM y operaciones y tipos de punto fijo.
Dialectos de MLIR
Para separar los diversos objetivos de software y hardware, MLIR tiene "dialectos", que incluyen:
- TensorFlow IR, que incluye todo lo que se puede hacer en los gráficos de TensorFlow
- XLA HLO IR, diseñado para obtener todos los beneficios proporcionados por el compilador XLA, cuyo resultado podemos obtener código para TPU, y no solo.
- Un dialecto de afinidad experimental diseñado específicamente para representaciones poliédricas y optimizaciones.
- LLVM IR, 1: 1 que coincide con la vista LLVM nativa, lo que permite a MLIR generar código para la GPU y la CPU utilizando LLVM.
- TensorFlow Lite diseñado para generar código para plataformas móviles
Cada dialecto contiene un conjunto de operaciones específicas, que utilizan invariantes, tales como: "es un operador binario, y su entrada y salida son del mismo tipo".
Extensiones MLIR
MLIR no tiene una lista fija e incorporada de operaciones intrínsecas globales. Los dialectos pueden definir tipos completamente personalizados, y de esta manera MLIR puede modelar cosas como el sistema de tipo IR LLVM (que tiene agregados de primera clase), abstracciones de lenguaje de dominio, como tipos cuantificados, importantes para los aceleradores optimizados de ML y, en el futuro, incluso un sistema de tipo Swift o Clang.
Si desea adjuntar un nuevo compilador de bajo nivel a este sistema, puede crear un nuevo dialecto y descender del dialecto del gráfico TensorFlow a su dialecto. Esto simplifica el camino para desarrolladores de hardware y desarrolladores de compiladores. Puede orientar el dialecto a diferentes niveles del mismo modelo, los optimizadores de alto nivel serán responsables de partes específicas de IR.
Para los investigadores de compiladores y desarrolladores de marcos, MLIR le permite crear transformaciones en cada nivel, puede definir sus propias operaciones y abstracciones en IR, lo que le permite modelar mejor las tareas de su aplicación. Por lo tanto, MLIR es más que una infraestructura de compilador pura, que es LLVM.
Aunque MLIR funciona como un compilador para ML, ¡también permite el uso de tecnologías de aprendizaje automático! Esto es muy importante para los ingenieros que desarrollan bibliotecas numéricas, y no pueden proporcionar soporte para la variedad completa de modelos y hardware de ML. La flexibilidad de MLIR facilita la exploración de estrategias para el descenso de código cuando se mueve entre niveles de abstracción.
Que sigue
Hemos abierto un
repositorio de GitHub e invitamos a todos los interesados (¡consulte nuestra guía!). Lanzaremos algo más que esta caja de herramientas: las especificaciones de dialecto TensorFlow y TF Lite, en los próximos meses. Podemos
darle más información, para obtener más información, vea la
presentación de Chris Luttner y nuestro
README en Github .
Si desea mantenerse al tanto de todo lo relacionado con MLIR, únase a nuestra
nueva lista de correo , que pronto se centrará en los anuncios de lanzamientos futuros de nuestro proyecto. Quédate con nosotros!