Ya hay materiales en Habr sobre cómo configurar docker- container para la compilación del proyecto. Por ejemplo, Usar Docker para compilar y ejecutar un proyecto C ++ . En este artículo, como en el anterior, se considerará el tema de la construcción del proyecto, pero aquí me gustaría ir más allá del tutorial y considerar más profundamente los problemas del uso de contenedores en tales tareas, así como la construcción de la infraestructura de construcción con Docker .
Un poco sobre docker
Para mayor claridad de la discusión adicional, es necesario proporcionar una descripción de algunos componentes de la ventana acoplable .
Imagen
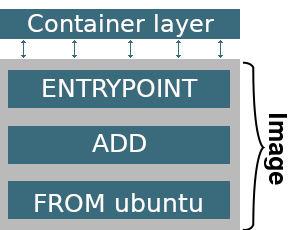
La imagen Docker es una plantilla de solo lectura con instrucciones para crear un contenedor. Para crear la imagen, debe crear un Dockerfile , que describe todos los pasos del ensamblaje. Cada uno de estos pasos crea una capa separada dentro de la imagen . Cada capa posterior se superpone a todas las anteriores y contiene solo los cambios que deben realizarse en la capa anterior.
Por ejemplo, para un Dockerfile :
FROM ubuntu:18.04 ADD app.sh /app ENTRYPOINT /bin/bash /app/app.sh
La imagen del acoplador tendrá la siguiente estructura:

Las capas dentro de la imagen se almacenan en caché y se pueden reutilizar si no se detectan cambios. Si se cambia la capa (agregada / eliminada) , todas las subsiguientes se crean desde cero. Para realizar cambios en la imagen del contenedor (y, en consecuencia, en el entorno del proceso iniciado), es suficiente reparar el Dockerfile y comenzar a construir la imagen.
Contenedor
Un contenedor docker es una instancia de inicio de imagen . Se puede crear, iniciar, detener, eliminar, etc. De manera predeterminada, los contenedores están aislados entre sí y del sistema host. Al inicio, el contenedor inicia un comando, que se puede especificar en ENTRYPOINT o CMD , y se detiene cuando se completa. Una situación aceptable es cuando CMD y ENTRYPOINT están presentes , ya que interactúan como se describe en la documentación .
Cuando crea cada contenedor, se agrega una nueva capa encima de todas las existentes. Se puede escribir en el contenedor actual y se destruye junto con el contenedor. Todas las operaciones de escritura, creación de nuevos archivos durante la operación del contenedor se aplican a esta capa, la imagen siempre permanece sin cambios. Por lo tanto, la estructura de capas del contenedor creado se verá así:
Al usar el docker run , se creará un nuevo contenedor cada vez, con su propia capa para escribir. En las tareas de compilación, esto significa que cada vez que se inicia, creará un nuevo entorno limpio que no tiene nada que ver con ejecuciones anteriores. La lista de contenedores creados se puede ver ejecutando el comando: docker container ls -a .
Recogemos el proyecto en el contenedor.
Para mayor claridad, describimos brevemente el proceso de creación de una aplicación en un contenedor; este proceso se describe con más detalle en el artículo 1 y el artículo 2 .
Los pasos esquemáticamente posibles para construir la aplicación en Docker se pueden representar de la siguiente manera:
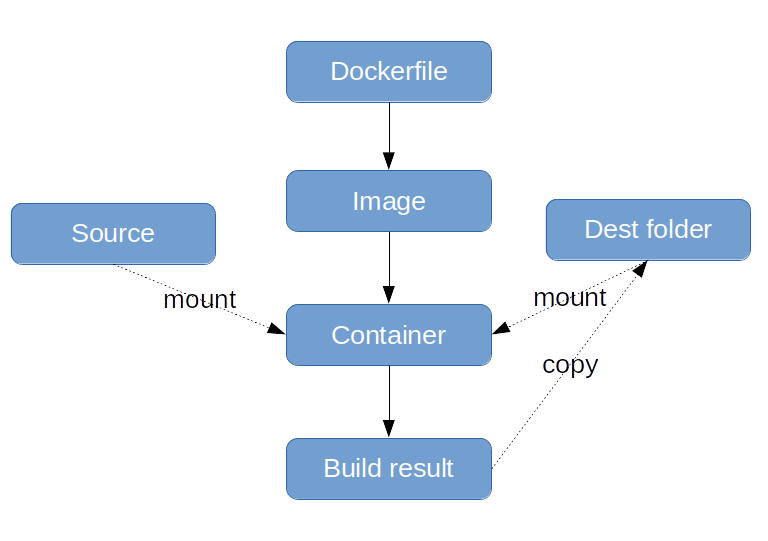
Analicemos los pasos que se muestran:
- Usamos el Dockerfile , que describe el entorno, los comandos para ensamblar y copiar los resultados, y en base a él creamos una imagen del contenedor.
- Usamos la imagen resultante para crear y lanzar el contenedor con el
docker run . Montamos la carpeta de origen y la carpeta donde se copiará el resultado del ensamblaje en el contenedor. - Una vez que se completa el contenedor, los artefactos de ensamblaje se colocarán en el directorio montado.
Un ejemplo se da en el artículo .
Dado que el docker run se usa aquí, para cada lanzamiento se creará un contenedor separado con su propia capa para escribir , por lo que los archivos temporales de ensamblajes anteriores no entrarán en el actual. Recuerde limpiar los contenedores detenidos.
El montaje del directorio de origen facilita la depuración del ensamblaje. Pero conlleva riesgos: puede recopilar una versión del código que no haya pasado el control de calidad o que no se haya agregado al sistema de control de versiones. Para evitar esto, puede clonar el repositorio git dentro del contenedor en cada compilación, como, por ejemplo, en el archivo :
FROM ubuntu:bionic RUN apt-get update \ && apt-get install -y apt-utils RUN apt-get update \ && apt-get install -y make gcc g++ qt5-default git RUN mkdir -p /app/src WORKDIR /app/build # ENTRYPOINT git -C /app/src clone https://github.com/sqglobe/SimpleQtProject.git \ && qmake /app/src/SimpleQtProject/SimpleQtProject.pro \ && make \ && cp SimpleQtProject /app/res/SimpleQtProject-ubuntu-bionic
Aquí, la clonación se realiza en ENTRYPOINT , no en la instrucción RUN , debido al almacenamiento en caché. ENTRYPOINT siempre se ejecuta cuando se inicia el contenedor, y el resultado del comando RUN se puede tomar del caché .
Construir infraestructura
Para construir un proyecto para diferentes sistemas operativos o distribuciones de Linux, se puede usar una determinada configuración de servidores (máquinas de compilación, servidores con un sistema de control de versiones, etc.). En la práctica, tuve que lidiar con la siguiente infraestructura:

Aquí, el usuario accede al servidor web a través del cual se construye el proyecto en máquinas con Ubuntu y Red Hat . A continuación, en cada máquina, el repositorio git se clona con el proyecto en un directorio temporal y se inicia el ensamblaje. El usuario puede descargar los archivos resultantes desde la misma página desde la que inició todo el proceso.
Tal ensamblaje es repetible porque los desarrolladores usan el mismo entorno.
De las desventajas: es necesario mantener una infraestructura completa, administrar varios servidores, eliminar errores en scripts y aplicaciones web , etc.
Simplifica con Docker
Apoyar la infraestructura que se muestra arriba requiere ciertos costos, tanto monetarios como humanos. Si su equipo está trabajando en una pequeña startup, o si usted es el único desarrollador, puede usar contenedores acoplables para implementar su infraestructura de compilación.
Considere un proyecto trivial de Qt que se construye usando qmake - SimpleQtProject . La carpeta acoplable del proyecto especificado contiene varios archivos:
Estos archivos implementan la idea de clonar el código fuente dentro de un contenedor.
Todo el ensamblaje se inicia utilizando el Makefile . Es muy corto y contiene suficientes comentarios. Su base es la creación de una imagen y el lanzamiento del contenedor:
%: %.docker docker build -t simple-qt-$(strip $(subst .docker,, $< )) --file $< . docker run --mount type=bind,source=$(RELEASE_DIR),target=/app/res simple-qt-$(strip $(subst .docker,, $< ))
En esta etapa del ensamblaje, se crea una imagen del contenedor con el nombre que consiste en el prefijo simple-qt- y el nombre del sistema (para centos 7 será simple-qt-centos7 ). Como Dockerfile , se utiliza el archivo correspondiente con el permiso .docker . A continuación, el contenedor se inicia en función de la imagen creada y se monta una carpeta para copiar los artefactos de ensamblaje.
Después de ejecutar el make en el directorio docker , la carpeta docker / releases contendrá los resultados de la compilación para varias plataformas.
Por lo tanto, nuestra infraestructura para construir SimpleQtProject se verá así:

Ventajas de esta configuración:
- Localidad . El desarrollador recopila un proyecto para varias plataformas en su máquina local, esto elimina la necesidad de contener una flota de servidores, configurar la copia de artefactos entre servidores a través de la red, enviar y procesar comandos de red.
- Aislamiento del medio ambiente . El contenedor proporciona un entorno completamente aislado para construir una aplicación específica. Es posible construir proyectos con entornos incompatibles en la misma máquina (por ejemplo, aquellos que requieren diferentes versiones de la misma biblioteca).
- Versionado Al colocar el Dockerfile en el repositorio de git, puede realizar un seguimiento de los cambios en el entorno de compilación con el lanzamiento de nuevas versiones, volver a las versiones anteriores del entorno de compilación, etc.
- Movilidad Si es necesario, esta infraestructura se implementa sin problemas en otra computadora. La tecnología para crear una imagen de contenedor le permite realizar cambios en la imagen en sí muy fácilmente, solo actualice el Dockerfile y comience a construir la imagen.
- Auto documentado . Esencialmente, un Dockerfile contiene pasos para implementar un entorno de ensamblaje. Por lo tanto, si es necesario, implemente dicho entorno, pero ya en un sistema normal, puede usar los comandos de él.
- Ligereza El contenedor comienza en el momento en que comienza el ensamblaje y se detiene automáticamente al finalizar. No desperdicia tiempo de CPU y RAM.
Sin embargo, hay un inconveniente significativo: el ensamblaje del proyecto requerirá el ensamblaje de la imagen del contenedor. Cuando comienzas por primera vez, puede tomar mucho tiempo. Pero con los repetidos, especialmente si el Dockerfile no ha cambiado, la imagen se ensambla usando el caché muchas veces más rápido.
También es necesario recordar limpiar los contenedores detenidos.
Conclusión
En conclusión, me gustaría señalar que Docker no es la única tecnología de contenedorización. Pero hay algunas características que lo distinguen favorablemente para las tareas de ensamblaje del mismo LXC :
- Puede crear un contenedor utilizando un texto Dockerfile . Este es un archivo con sintaxis simple, puede agregarlo al repositorio del proyecto (como siempre lo hago) y tenerlo siempre a mano.
- Cada vez, al iniciar el contenedor Docker con el
docker run obtenemos un entorno limpio , como si estuviéramos haciendo todo por primera vez. Los archivos temporales entre ensamblajes no se guardan. - El contenedor no inicia todo el sistema operativo, sino solo el proceso de ensamblaje necesario.