Hola Habr! Les presento la traducción del artículo
“Similitud de imagen usando el ranking profundo” de Akarsh Zingade.
Algoritmo de clasificación profunda
No se introdujo el concepto de "
similitud de dos imágenes ", así que vamos a presentar este concepto al menos en el marco del artículo.
La similitud de dos imágenes es el resultado de comparar dos imágenes de acuerdo con ciertos criterios. Su medida cuantitativa determina el grado de similitud entre los diagramas de intensidad de dos imágenes. Usando una medida de similitud, se comparan algunas características que describen las imágenes. Como medida de similitud, la distancia de Hamming, la distancia euclidiana, la distancia de Manhattan, etc.
Clasificación profunda : estudia la similitud de imagen de grano fino, caracterizando la proporción de similitud de imagen finamente dividida utilizando un conjunto de tripletes.
¿Qué es un triplete?
El triplete contiene la imagen de solicitud, la imagen positiva y negativa. Donde una imagen positiva se parece más a una imagen de solicitud que a una negativa.
Un ejemplo de un conjunto de trillizos:
La primera, segunda y tercera línea corresponde a la imagen de la solicitud. La segunda línea (imágenes positivas) se parece más a las imágenes de solicitud que la tercera (imágenes negativas).
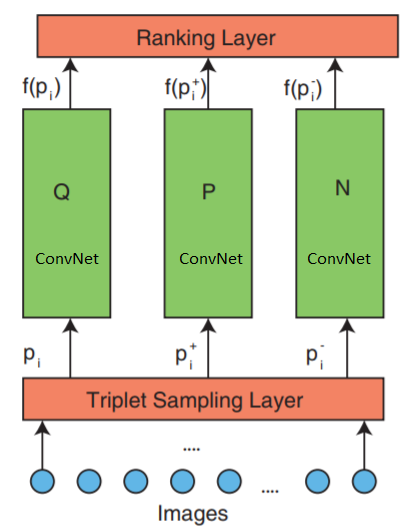
Arquitectura de red de clasificación profunda
La red consta de 3 partes: muestreo de triplete, ConvNet y una capa de clasificación.
La red acepta tripletas de imágenes como entrada. Una imagen triplete contiene una imagen de solicitud
$ en línea $ p_i $ en línea $ imagen positiva
$ en línea $ p_i ^ + $ en línea $ e imagen negativa
$ en línea $ p_i ^ - $ en línea $ que se transmiten independientemente a tres redes neuronales profundas idénticas.
La capa de clasificación más alta: evalúa la función de pérdida de triplete. Este error se corrige en las capas inferiores para minimizar la función de pérdida.
Ahora echemos un vistazo más de cerca a la capa intermedia:
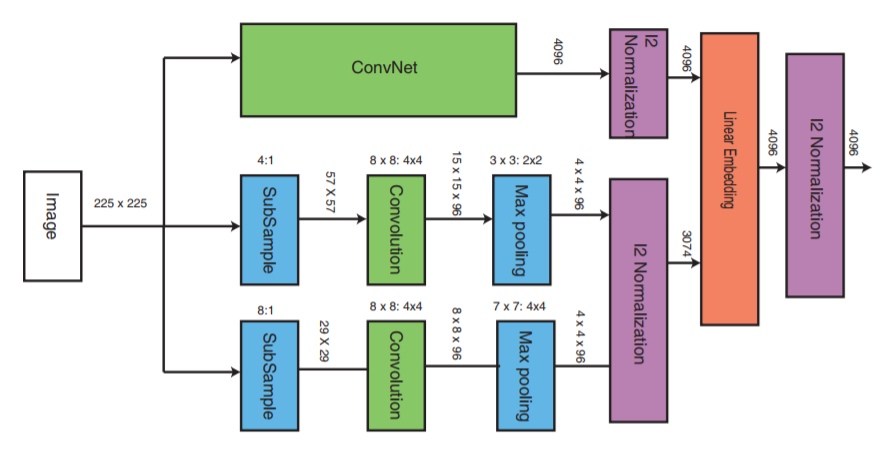
ConvNet puede ser cualquier red neuronal profunda (este artículo discutirá una de las implementaciones de la red neuronal convolucional VGG16). ConvNet contiene capas convolucionales, una capa de agrupación máxima, capas de normalización local y capas completamente conectadas.
Las otras dos partes reciben imágenes con una frecuencia de muestreo reducida y llevan a cabo la etapa de convolución y la agrupación máxima. A continuación, tiene lugar la etapa de normalización de las tres partes y al final se combinan con una capa lineal con normalización posterior.
Formación de triplete
Hay varias formas de crear un archivo de triplete, por ejemplo, usar una evaluación experta. Pero este artículo utilizará el siguiente algoritmo:
- Cada imagen de la clase forma una imagen de solicitud.
- Cada imagen, excepto la imagen de solicitud, formará una imagen positiva. Pero puede limitar el número de imágenes positivas para cada solicitud de imagen
- Una imagen negativa se selecciona aleatoriamente de cualquier clase que no sea una clase de imagen de solicitud
Función de pérdida de triplete
El objetivo es entrenar una función que asigne una pequeña distancia para las imágenes más similares y una gran distancia para las diferentes. Esto se puede expresar como:
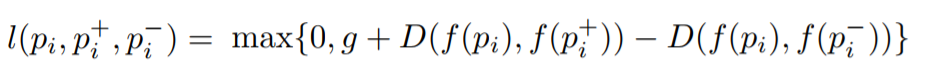
Donde
l es el coeficiente de pérdida para los tripletes,
g es el coeficiente de espacio entre la distancia entre dos pares de imágenes: (
$ en línea $ p_i $ en línea $ ,
$ en línea $ p_i ^ + $ en línea $ ) y (
$ en línea $ p_i $ en línea $ ,
$ en línea $ p_i ^ - $ en línea $ ),
f : función de incrustación que muestra la imagen en un vector,
$ en línea $ p_i $ en línea $ Es la imagen de la solicitud,
$ en línea $ p_i ^ + $ en línea $ Es una imagen positiva,
$ en línea $ p_i ^ - $ en línea $ Es una imagen negativa, y
D es la distancia euclidiana entre dos puntos euclidianos.
Implementación de algoritmos de clasificación profunda
Implementación con Keras.
Se utilizan tres redes paralelas para la consulta, imagen positiva y negativa.
Hay tres partes principales para la implementación, estas son:
- Implementación de tres redes neuronales multiescala paralelas
- Implementación de la función de pérdida
- Generación de triplete
Aprender tres redes profundas paralelas consumirá muchos recursos de memoria. En lugar de tres redes profundas paralelas que reciben una imagen de solicitud, una imagen positiva y una negativa, estas imágenes se alimentarán secuencialmente a una red neuronal profunda en la entrada de una red neuronal. El tensor transferido a la capa de pérdida contendrá un archivo adjunto de imagen en cada fila. Cada línea corresponde a cada imagen de entrada en un paquete. Dado que la imagen de solicitud, la imagen positiva y la imagen negativa se transmiten secuencialmente, la primera línea corresponderá a la imagen de solicitud, la segunda a la imagen positiva y la tercera a la imagen negativa, y luego se repetirá hasta el final del paquete. Por lo tanto, la capa de clasificación recibe una incrustación de todas las imágenes. Después de eso, se calcula la función de pérdida.
Para implementar la capa de clasificación, necesitamos escribir nuestra propia función de pérdida, que calculará la distancia euclidiana entre la imagen solicitada y la imagen positiva, así como la distancia euclidiana entre la imagen solicitada y la imagen negativa.
Implementación de la función de cálculo de pérdidas._EPSILON = K.epsilon() def _loss_tensor(y_true, y_pred): y_pred = K.clip(y_pred, _EPSILON, 1.0-_EPSILON) loss = tf.convert_to_tensor(0,dtype=tf.float32)
El tamaño del paquete siempre debe ser un múltiplo de 3. Dado que un triplete contiene 3 imágenes, y las imágenes de triplete se transmiten secuencialmente (enviamos cada imagen a una red neuronal profunda secuencialmente)
El resto del código está aquí.